
 Peranti teknologi
AI
Seni Reka Bentuk Sistem: Apabila aplikasi HPC dan AI menjadi arus perdana, ke mana harus pergi seni bina GPU?
Peranti teknologi
AI
Seni Reka Bentuk Sistem: Apabila aplikasi HPC dan AI menjadi arus perdana, ke mana harus pergi seni bina GPU?
Seni Reka Bentuk Sistem: Apabila aplikasi HPC dan AI menjadi arus perdana, ke mana harus pergi seni bina GPU?


Kami telah menyebut bertahun-tahun yang lalu bahawa melatih beban kerja AI menggunakan rangkaian neural konvolusi dengan data yang mencukupi menjadi Arus Perdana, dan HPC utama (tinggi -performance computing) di seluruh dunia telah menyerahkan beban ini kepada pemprosesan GPU NVIDIA selama bertahun-tahun. Untuk tugasan seperti simulasi dan pemodelan, prestasi GPU agak cemerlang. Pada dasarnya, simulasi/pemodelan HPC dan latihan AI sebenarnya adalah sejenis penumpuan harmonik, dan GPU, sebagai pemproses selari secara besar-besaran, amat baik dalam melaksanakan jenis kerja ini.
Tetapi sejak 2012, revolusi AI secara rasmi meletus, dan perisian pengecaman imej meningkatkan ketepatan ke tahap melebihi manusia buat kali pertama. Jadi kami sangat ingin tahu tentang berapa lama kesamaan pemprosesan cekap HPC dan AI pada GPU yang serupa boleh bertahan. Jadi pada musim panas 2019, melalui penghalusan dan lelaran model, kami cuba menggunakan unit matematik ketepatan campuran untuk mencapai keputusan yang sama seperti pengiraan FP64 dalam penanda aras Linpack. Sebelum NVIDIA melancarkan GPU GA100 "Ampere" pada tahun berikutnya, kami sekali lagi cuba menguji prestasi pemprosesan HPC dan AI. Pada masa itu, Nvidia belum lagi melancarkan GPU A100 "Ampere", jadi syarikat gergasi kad grafik itu belum secara rasmi condong ke arah melatih model AI pada teras tensor ketepatan campuran. Jawapannya sudah tentu sekarang jelas. Beban kerja HPC pada unit vektor FP64 memerlukan beberapa pelarasan seni bina untuk memanfaatkan prestasi GPU. Tetapi pada masa itu, semuanya masih boleh dilakukan.
Dengan pelancaran GPU GH100 "Hopper" Nvidia awal tahun ini, terdapat jurang yang lebih luas dalam peningkatan prestasi antara generasi antara AI dan HPC. Bukan itu sahaja, pada persidangan GTC 2022 musim luruh baru-baru ini, pengasas bersama NVIDIA dan CET Huang Jensen berkata bahawa beban kerja AI itu sendiri juga telah menjadi berbeza, memaksa NVIDIA untuk mula meneroka perniagaan CPU-atau, lebih tepat, ia sepatutnya dipanggil pengawal memori lanjutan Dioptimumkan berorientasikan GPU.
Kami akan membincangkan isu ini secara terperinci kemudian.
Dua bunga mekar, satu di setiap sisi
Mari kita mulakan dengan pertimbangan yang paling jelas. Jika Nvidia mahu GPUnya mempunyai prestasi FP64 yang lebih kukuh untuk menyokong aplikasi HPC titik terapung 64-bit seperti pemodelan cuaca, pengiraan dinamik bendalir, analisis unsur terhingga, kromodinamik kuantum dan simulasi matematik intensiti tinggi yang lain, maka pemecut Idea reka bentuk haruslah seperti ini: cipta produk yang tidak mempunyai sebarang teras tensor atau teras FP32 CUDA (terutamanya digunakan sebagai pelorek grafik dalam seni bina CUDA).
Tetapi saya khuatir hanya beberapa ratus pelanggan sahaja yang sanggup membeli produk sedemikian, jadi harga satu cip mungkin berpuluh ribu malah ratusan ribu ringgit Hanya dengan cara ini kos reka bentuk dan pembuatan ditanggung. Untuk membina perniagaan yang lebih besar dan lebih menguntungkan, Nvidia mesti mereka bentuk seni bina yang lebih umum yang keupayaan matematik vektornya lebih kuat daripada CPU.
Jadi sejak NVIDIA memutuskan untuk mereka bentuk produk secara serius untuk aplikasi HPC 15 tahun lalu, mereka telah memfokuskan pada senario HPC menggunakan operasi matematik titik terapung FP32 - termasuk penggunaan dalam pemprosesan seismik, pemprosesan isyarat dan beban kerja genomik. data ketepatan dan tugas pemprosesan, dan secara beransur-ansur meningkatkan keupayaan FP64 GPU.
Pemecut K10 yang dilancarkan pada Julai 2012 dilengkapi dengan dua GPU "Kepler" GK104, iaitu GPU yang sama persis digunakan dalam kad grafik permainan. Ia mempunyai 1536 teras CUDA FP32 dan tidak menggunakan sebarang teras FP64 khusus. Sokongan FP64nya dilakukan semata-mata dalam perisian, jadi tiada peningkatan prestasi yang ketara: GPU dwi GK104 dilakukan pada 4.58 teraflops pada tugasan FP32 dan 190 gigaflops pada FP64, nisbah 24 berbanding 1. K20X, yang dikeluarkan pada Persidangan Pengkomputeran Super SC12 pada penghujung 2012, menggunakan GPU GK110, dengan prestasi FP32 sebanyak 3.95 teraflops dan prestasi FP64 sebanyak 1.31 teraflops, nisbah meningkat kepada 3 berbanding 1. Pada masa ini, produk mempunyai ketersediaan awal untuk aplikasi HPC dan pengguna melatih model AI dalam ruang pengkomputeran akademik/hiperskala. Kad pemecut GPU K80 menggunakan dua GPU GK110B Ini kerana NVIDIA tidak menambah sokongan FP64 pada GPU "Maxwell" paling tinggi pada masa itu, jadi GK110 B menjadi pilihan yang paling popular dan kos efektif pada masa itu. Prestasi FP32 K80 ialah 8.74 teraflops dan prestasi FP64 ialah 2.91 teraflops, masih mengekalkan nisbah 3 berbanding 1.
Sehingga kepada GPU GP100 "Pascal", jurang antara HPC dan AI telah semakin melebar dengan pengenalan penunjuk ketepatan campuran FP16, tetapi nisbah vektor FP32 kepada vektor FP64 telah terus ditukar kepada 2:1 , dan dalam "Volta" Ia telah dikekalkan dalam GPU yang lebih baharu seperti "Ampere" GA100 dan "Hopper" GH100 selepas GV100. Dalam seni bina Volta, NVIDIA memperkenalkan buat pertama kalinya unit matematik matriks Tensor Core dengan matriks tetap Lei, yang meningkatkan keupayaan pengkomputeran titik terapung (dan integer) dengan ketara dan terus mengekalkan unit vektor dalam seni bina.
Teras tensor ini digunakan untuk memproses matriks yang lebih besar dan lebih besar, tetapi ketepatan operasi khusus semakin rendah, jadi jenis peralatan ini telah mencapai daya pemprosesan beban AI yang sangat berlebihan. Ini sudah tentu tidak dapat dipisahkan daripada sifat statistik kabur pembelajaran mesin itu sendiri, dan ia juga meninggalkan jurang yang besar dengan matematik ketepatan tinggi yang diperlukan oleh kebanyakan algoritma HPC. Rajah di bawah menunjukkan perwakilan logaritma bagi jurang prestasi antara AI dan HPC Saya percaya anda sudah dapat melihat perbezaan aliran antara kedua-duanya:
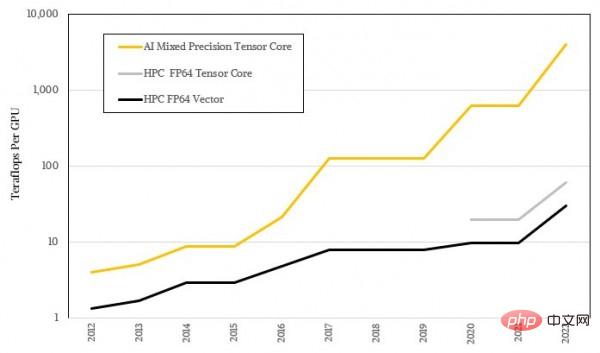
Bentuk logaritma tidak kelihatan cukup menarik, mari kita lihat semula menggunakan nisbah sebenar:
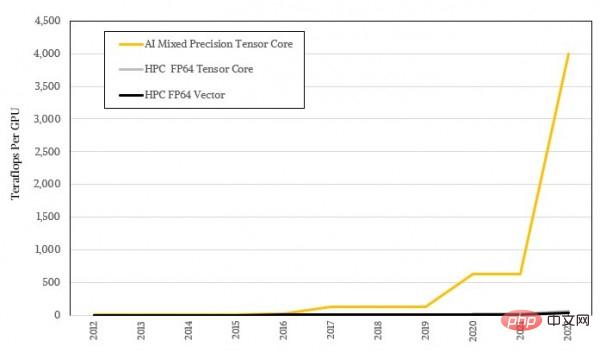
System The Art of Design: Apabila aplikasi HPC dan AI menjadi arus perdana, ke manakah harus pergi seni bina GPU?
Bukan semua aplikasi HPC boleh dilaraskan untuk teras tensor, dan bukan semua aplikasi boleh memindahkan operasi matematik kepada teras tensor, jadi NVIDIA masih mengekalkan beberapa unit vektor dalam seni bina GPUnya. Di samping itu, banyak organisasi HPC sebenarnya tidak dapat menghasilkan penyelesai berulang seperti HPL-AI. Penyelesai HPL-AI yang digunakan dalam ujian penanda aras Linpack menggunakan HPL Linpack biasa dengan operasi FP16 ditambah FP32, dan sedikit operasi FP64 untuk menumpu kepada jawapan yang sama seperti pengiraan kekerasan FP64 tulen. Penyelesai berulang ini mampu memberikan kelajuan berkesan sebanyak 6.2x pada superkomputer Frontier Oak Ridge National Laboratory dan 4.5x pada superkomputer Fugaku RIKEN Laboratory. Jika lebih banyak aplikasi HPC boleh menerima penyelesai HPL-AI mereka sendiri, maka masalah "pemisahan" AI dan HPC akan diselesaikan.
Tetapi pada masa yang sama, untuk banyak beban kerja, prestasi FP64 kekal sebagai satu-satunya faktor penentu. Dan Nvidia, yang telah menghasilkan banyak wang dengan kuasa pengkomputeran AI yang berkuasa, pasti tidak akan mempunyai banyak masa untuk menjaga pasaran HPC dalam tempoh yang singkat.
Dua lagi bunga mekar, dan satu cabang setiap satu
Dapat dilihat bahawa seni bina GPU NVIDIA terutamanya mengejar prestasi AI yang lebih tinggi sambil mengekalkan prestasi HPC yang boleh diterima, dan pendekatan serampang dua mata membimbing pelanggan setiap Perkakasan dikemas kini setiap tiga tahun. Daripada perspektif prestasi FP64 tulen, daya pemprosesan FP64 bagi GPU Nvidia meningkat 22.9 kali dalam tempoh sepuluh tahun dari 2012 hingga 2022, daripada 1.3 teraflop K20X kepada 30 teraflop H100. Jika unit matriks teras tensor boleh digunakan dengan penyelesai lelaran, peningkatan boleh mencapai 45.8 kali ganda. Tetapi jika anda seorang pengguna latihan AI yang hanya memerlukan pengkomputeran selari skala besar berketepatan rendah, maka perubahan prestasi daripada FP32 kepada FP8 adalah dibesar-besarkan Kuasa pengkomputeran FP32 telah ditingkatkan daripada 3.95 teraflop terawal kepada 4 petaflop FP8 jarang. matriks, iaitu peningkatan 1012.7 kali. Dan jika kita membandingkannya dengan algoritma AI yang dikodkan FP64 pada GPU K20X pada masa itu (amalan arus perdana pada masa itu), peningkatan prestasi dalam sepuluh tahun yang lalu hanya menyedihkan 2 kali ganda.
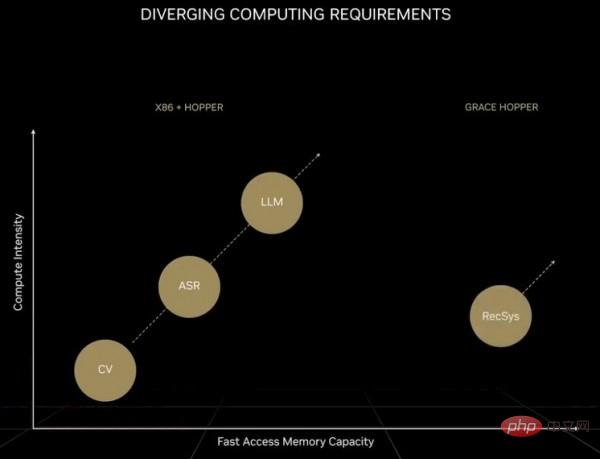
Jelas sekali, perbezaan prestasi antara kedua-duanya tidak boleh digambarkan sebagai besar. Huang Renxun sendiri juga menyebut bahawa kem AI semasa itu sendiri terbahagi kepada dua lagi. Satu jenis ialah model asas gergasi yang disokong oleh model pengubah, juga dikenali sebagai model bahasa besar. Bilangan parameter model sedemikian berkembang pesat, dan permintaan untuk perkakasan juga meningkat. Berbanding dengan model rangkaian saraf sebelumnya, model transformer hari ini sepenuhnya mewakili era lain, seperti yang ditunjukkan dalam gambar berikut:

Harap maafkan gambar ini kerana agak kabur, tetapi Perkara ini adalah: Untuk set pertama model AI yang tidak termasuk transformer, keperluan pengkomputeran meningkat 8 kali dalam dua tahun tetapi untuk model AI yang termasuk transformer, keperluan pengkomputeran meningkat sebanyak 275 kali dalam dua tahun; . Jika operasi titik terapung digunakan untuk pemprosesan, mesti ada 100,000 GPU dalam sistem untuk memenuhi permintaan (ini bukan masalah besar). Walau bagaimanapun, beralih kepada ketepatan FP4 akan menggandakan jumlah pengiraan Pada masa hadapan, apabila GPU menggunakan transistor 1.8nm, kuasa pengkomputeran akan meningkat sebanyak kira-kira 2.5 kali, jadi masih terdapat jurang kira-kira 55 kali. Jika operasi FP2 boleh dilaksanakan (dengan mengandaikan ketepatan sedemikian mencukupi untuk menyelesaikan masalah), jumlah pengiraan boleh dikurangkan separuh, tetapi itu memerlukan penggunaan sekurang-kurangnya 250,000 GPU. Selain itu, model pengubah bahasa yang besar selalunya sukar untuk dikembangkan, terutamanya tidak dapat dilaksanakan secara ekonomi. Oleh itu, model jenis ini telah menjadi eksklusif kepada syarikat gergasi, sama seperti senjata nuklear hanya berada di tangan negara yang berkuasa.
Bagi sistem pengesyoran sebagai "enjin ekonomi digital", ia memerlukan bukan sahaja peningkatan eksponen dalam jumlah pengiraan, tetapi juga skala data yang jauh melebihi kapasiti memori model bahasa yang besar atau bahkan sebuah GPU. Huang Renxun menyebut dalam ucaptama GTC beliau sebelum ini:
“Berbanding dengan model bahasa yang besar, jumlah data yang dihadapi oleh setiap unit pengkomputeran semasa memproses sistem pengesyoran adalah susunan magnitud yang lebih besar. Jelas sekali sistem pengesyoran itu bukan sahaja memerlukan kelajuan memori yang lebih pantas, tetapi juga memerlukan 10 kali ganda kelajuan memori model bahasa yang besar Kapasiti memori model tersebut Walaupun model bahasa yang besar terus berkembang secara eksponen dari semasa ke semasa dan memerlukan kuasa pengkomputeran yang berterusan, sistem pengesyoran juga mengekalkan kadar pertumbuhan ini dan terus menggunakan lebih banyak sistem pengesyoran sistem boleh dikatakan dua jenis model AI yang paling penting hari ini, dan mempunyai keperluan pengkomputeran yang berbeza boleh menskalakan kepada berbilion pengguna dan berbilion item, setiap artikel, setiap video, setiap siaran sosial data dan perlu diproses oleh berbilang GPU Semasa memproses sistem pengesyoran, beberapa bahagian rangkaian diperlukan untuk melaksanakan pemprosesan selari data , dan memerlukan bahagian rangkaian yang lain untuk melaksanakan pemprosesan selari model, yang meletakkan keperluan yang lebih tinggi pada pelbagai bahagian daripada komputer. NVIDIA membangunkan CPU pelayan Arm "Grace" dan menggabungkannya dengan GPU Hopper. Kami juga bergurau bahawa jika jumlah memori utama yang diperlukan adalah sangat besar, Grace sebenarnya hanyalah pengawal memori Hopper. Tetapi dalam jangka masa panjang, mungkin hanya menyambungkan sekumpulan port CXL yang menjalankan protokol NVLink ke dalam GPU generasi seterusnya Hooper.
Jadi cip super Grace-Hopper yang dihasilkan oleh NVIDIA adalah setara dengan meletakkan gugusan CPU peringkat "kanak-kanak" ke dalam gugusan pecutan GPU peringkat "dewasa" yang besar. CPU Lengan ini boleh menyokong beban kerja C++ dan Fortran tradisional, tetapi pada harga: prestasi bahagian CPU dalam kluster hibrid hanyalah satu per sepuluh daripada prestasi GPU dalam kluster, tetapi kosnya adalah 3 hingga 3 kali ganda. daripada kluster CPU tulen konvensional 5 kali.
Sebenarnya, kami menghormati dan memahami sebarang pilihan kejuruteraan yang dibuat oleh NVIDIA. Grace adalah CPU yang sangat baik, dan Hopper juga merupakan GPU yang sangat baik Gabungan kedua-duanya pasti akan menghasilkan hasil yang baik. Tetapi apa yang berlaku sekarang ialah kami menghadapi tiga beban kerja yang berbeza pada platform yang sama, masing-masing menarik seni bina ke arah yang berbeza. Pengkomputeran berprestasi tinggi, model bahasa yang besar dan sistem pengesyoran, ketiga-tiga saudara ini mempunyai ciri-ciri mereka sendiri, dan adalah mustahil untuk mengoptimumkan seni bina pada masa yang sama dengan cara yang kos efektif. 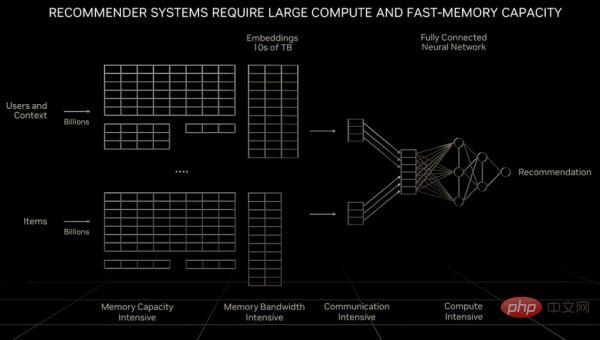
Atas ialah kandungan terperinci Seni Reka Bentuk Sistem: Apabila aplikasi HPC dan AI menjadi arus perdana, ke mana harus pergi seni bina GPU?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
Perintah untuk memulakan semula perkhidmatan SSH ialah: Sistem Restart SSHD. Langkah -langkah terperinci: 1. Akses terminal dan sambungkan ke pelayan; 2. Masukkan arahan: SistemCtl Restart SSHD; 3. Sahkan Status Perkhidmatan: Status Sistem SSHD.
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
