
 Peranti teknologi
AI
Google telah mencipta sistem terjemahan mesin untuk 1,000+ bahasa 'ekor panjang' dan sudah menyokong beberapa bahasa khusus
Peranti teknologi
AI
Google telah mencipta sistem terjemahan mesin untuk 1,000+ bahasa 'ekor panjang' dan sudah menyokong beberapa bahasa khusus
Google telah mencipta sistem terjemahan mesin untuk 1,000+ bahasa 'ekor panjang' dan sudah menyokong beberapa bahasa khusus

Kualiti sistem terjemahan mesin (MT) akademik dan komersial telah meningkat secara mendadak sepanjang dekad yang lalu. Peningkatan ini sebahagian besarnya disebabkan oleh kemajuan dalam pembelajaran mesin dan ketersediaan set data perlombongan web berskala besar. Pada masa yang sama, kemunculan model pembelajaran mendalam (DL) dan E2E, set data bahasa tunggal selari berskala besar yang diperoleh daripada perlombongan web, kaedah peningkatan data seperti terjemahan balik dan latihan kendiri, dan pelbagai skala besar. pemodelan bahasa telah menghasilkan keupayaan untuk menyokong lebih daripada 100 sistem terjemahan mesin berkualiti tinggi untuk bahasa.
Walau bagaimanapun, walaupun terdapat kemajuan besar dalam terjemahan mesin sumber rendah, bilangan bahasa yang telah dibina secara meluas dan sistem terjemahan mesin umum adalah terhad kepada kira-kira 100 , dan mereka jelas hanya tersedia hari ini beberapa daripada lebih 7,000 bahasa yang dituturkan di dunia. Selain bilangan bahasa yang terhad, pengedaran bahasa yang disokong oleh sistem terjemahan mesin semasa juga sangat condong ke arah bahasa Eropah.
Kita dapat melihat bahawa walaupun populasi mereka besar, terdapat lebih sedikit perkhidmatan untuk bahasa yang dituturkan di Afrika, Asia Selatan dan Tenggara serta bahasa asli Amerika. Contohnya, Terjemahan Google menyokong Frisian, Malta, Icelandic dan Corsica, yang kesemuanya mempunyai kurang daripada 1 juta penutur asli. Sebagai perbandingan, populasi dialek Bihar yang tidak dilayan oleh Terjemahan Google adalah kira-kira 51 juta, populasi Oromo adalah kira-kira 24 juta, populasi Quechua adalah kira-kira 9 juta, dan populasi Tigrinya adalah kira-kira 9 juta (2022). Bahasa-bahasa ini dikenali sebagai bahasa "ekor panjang", dan kekurangan data memerlukan penerapan teknik pembelajaran mesin yang boleh melangkaui bahasa dengan data latihan yang mencukupi.
Membina sistem penterjemahan mesin untuk bahasa ekor panjang ini sebahagian besarnya terhad oleh kekurangan set data digital yang tersedia dan alatan NLP seperti model pengenalan bahasa (LangID). Ini ada di mana-mana untuk bahasa sumber tinggi.
Dalam kertas kerja Google baru-baru ini "Membina Sistem Terjemahan Mesin untuk Seribu Bahasa Seterusnya", lebih daripada dua dozen penyelidik menunjukkan usaha mereka untuk membina mesin praktikal yang menyokong lebih daripada 1,000 bahasa keputusan.

Alamat kertas: https://arxiv.org/pdf/2205.03983.pdf
Khusus Secara khusus, penyelidik menerangkan keputusan mereka daripada tiga bidang penyelidikan berikut.
Pertama, set data yang dilombong web yang bersih dicipta untuk 1500+ bahasa melalui latihan pra-separa penyeliaan untuk pengecaman bahasa dan teknik penapisan dipacu data.
Kedua, melalui model berbilang bahasa berskala besar yang dilatih dengan data selari yang diselia untuk lebih daripada 100 bahasa sumber tinggi dan set data eka bahasa untuk 1000+ bahasa lain, Mencipta terjemahan mesin yang praktikal dan berkesan model untuk bahasa yang kurang mendapat perkhidmatan.
Ketiga, kaji pengehadan metrik penilaian dalam bahasa ini, jalankan analisis kualitatif keluaran model terjemahan mesin dan fokus pada beberapa corak ralat biasa model sedemikian.
Para penyelidik berharap kerja ini akan memberikan pandangan yang berguna kepada pengamal yang bekerja membina sistem terjemahan mesin untuk bahasa yang kurang diselidiki pada masa ini. Di samping itu, penyelidik berharap kerja ini boleh membawa kepada arah penyelidikan yang menangani kelemahan model berbilang bahasa berskala besar dalam tetapan data yang jarang.
Pada persidangan I/O pada 12 Mei, Google mengumumkan bahawa sistem terjemahannya telah menambah 24 bahasa baharu, termasuk beberapa bahasa asli Amerika yang khusus Contohnya, dialek Bihar, Oromo. Quechua dan Tigrinya yang disebutkan di atas.

Kertas Keseluruhan
Kerja ini terbahagi kepada empat bab utama di sini kita hanya membincangkan setiap satu bab. Kandungan setiap bab diperkenalkan secara ringkas.
Buat set data teks web 1000 bahasa
Bab ini memperincikan usaha penyelidik untuk merangkak teks satu bahasa untuk 1500+ bahasa Kaedah yang digunakan dalam proses set data. Kaedah ini memfokuskan pada memulihkan data berketepatan tinggi (iaitu, bahagian tinggi teks bersih dalam bahasa), jadi sebahagian besarnya adalah pelbagai kaedah penapisan.
Secara umumnya, kaedah yang digunakan oleh penyelidik termasuk yang berikut:
- Alih keluar bahasa dengan kualiti data latihan yang lemah dan prestasi LangID yang lemah daripada model LangID dan latih model LangID CLD3 1629 bahasa dan model LangID (SSLID) separa seliaan
- Lakukan operasi pengelompokan mengikut kadar ralat bahasa dalam model CLD3; 🎜 > Tapis ayat menggunakan konsistensi dokumen;
- Tapis semua korpora menggunakan senarai perkataan ambang peratusan
- Gunakan LangID separa diselia; (SSLID) ) untuk menapis semua korpora;
- Gunakan ingatan relatif untuk mengesan bahasa luar dan menapis menggunakan Term-Frequency-Inverse-Internet-Frequency (TF-IIF) ;
- Gunakan skor Keanomalian Frekuensi Token untuk mengesan bahasa terpencil dan mereka bentuk penapis secara manual untuknya;
- Hadapi semua korpora pada peringkat ayat Lakukan deduplikasi operasi.
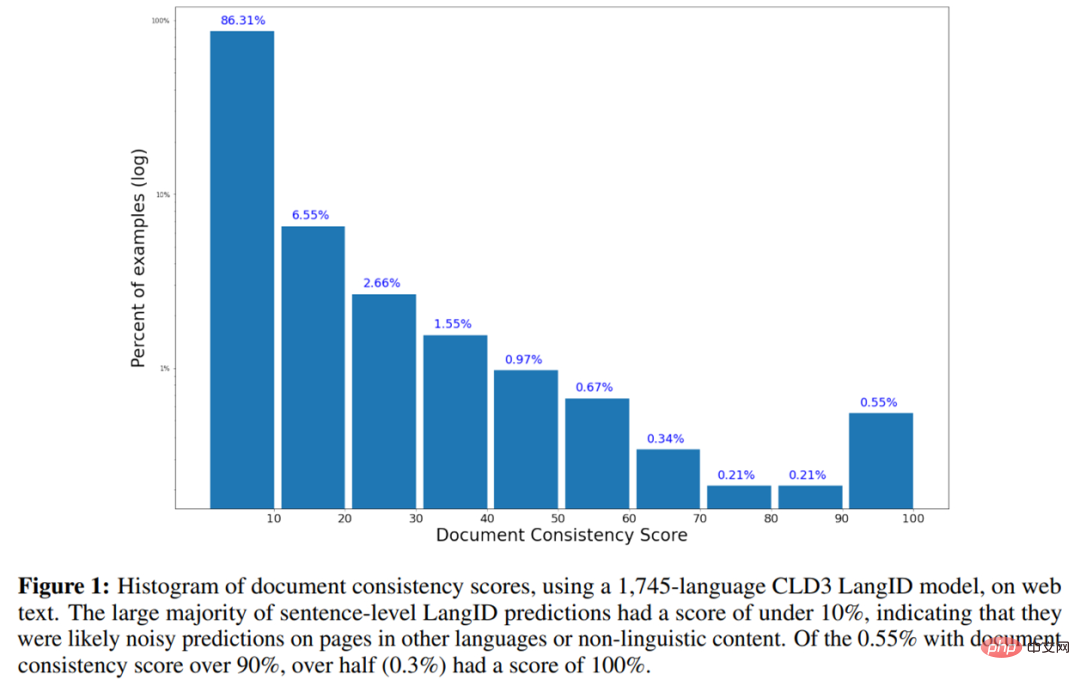
- Berikut ialah histogram skor ketekalan dokumen menggunakan model CLD3 LangID bagi 1745-bahasa pada teks web.
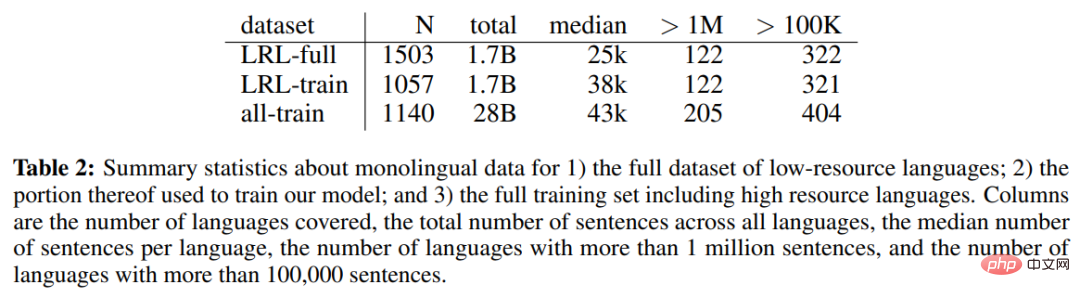
Jadual 2 di bawah menunjukkan data bahasa tunggal set data bahasa sumber rendah (LRL) lengkap, sebahagian daripada data bahasa tunggal digunakan untuk melatih model, dan termasuk statistik bahasa tunggal untuk set latihan lengkap termasuk bahasa sumber tinggi.
Direktori bab adalah seperti berikut:
ialah bahasa ekor panjang Membina Model Terjemahan Mesin
 Untuk data ekabahasa yang dilombong daripada web, cabaran seterusnya ialah mencipta model terjemahan mesin am berkualiti tinggi daripada jumlah ekabahasa yang terhad data latihan. Untuk tujuan ini, para penyelidik menggunakan pendekatan pragmatik untuk memanfaatkan semua data selari yang tersedia untuk bahasa sumber yang lebih tinggi untuk meningkatkan kualiti bahasa ekor panjang di mana hanya data eka bahasa tersedia. Mereka memanggil persediaan ini "sumber sifar" kerana tiada pengawasan langsung untuk bahasa ekor panjang.
Untuk data ekabahasa yang dilombong daripada web, cabaran seterusnya ialah mencipta model terjemahan mesin am berkualiti tinggi daripada jumlah ekabahasa yang terhad data latihan. Untuk tujuan ini, para penyelidik menggunakan pendekatan pragmatik untuk memanfaatkan semua data selari yang tersedia untuk bahasa sumber yang lebih tinggi untuk meningkatkan kualiti bahasa ekor panjang di mana hanya data eka bahasa tersedia. Mereka memanggil persediaan ini "sumber sifar" kerana tiada pengawasan langsung untuk bahasa ekor panjang.
Penyelidik telah menggunakan beberapa teknik yang dibangunkan untuk terjemahan mesin sejak beberapa tahun lalu untuk meningkatkan kualiti terjemahan sumber sifar bagi bahasa ekor panjang. Teknik ini termasuk pembelajaran diselia sendiri daripada data eka bahasa, pembelajaran seliaan berbilang bahasa berskala besar, terjemahan belakang berskala besar dan latihan kendiri, model berkapasiti tinggi. Mereka memanfaatkan alatan ini untuk mencipta model terjemahan mesin yang mampu menterjemah 1000+ bahasa, memanfaatkan korpora selari sedia ada yang meliputi kira-kira 100 bahasa dan set data ekabahasa 1000 bahasa yang dibina daripada web.
Secara khusus, penyelidik mula-mula menekankan kepentingan kapasiti model dalam model berbilang bahasa dengan membandingkan prestasi 1.5 bilion dan 6 bilion parameter Transformers pada terjemahan sumber sifar (3.2), dan kemudian meningkatkan bilangan bahasa yang diselia sendiri kepada 1000, mengesahkan bahawa apabila lebih banyak data eka bahasa daripada bahasa yang sama tersedia, prestasi bertambah baik untuk kebanyakan bahasa ekor panjang (3.3). Walaupun model 1000 bahasa penyelidik menunjukkan prestasi yang munasabah, mereka menggabungkan penambahan data berskala besar untuk memahami kekuatan dan batasan pendekatan mereka.
Selain itu, penyelidik memperhalusi model generatif pada subset 30 bahasa dengan sejumlah besar data sintetik melalui latihan kendiri dan terjemahan belakang (3.4). Mereka seterusnya menerangkan kaedah praktikal untuk menapis data sintetik untuk meningkatkan keteguhan model yang diperhalusi ini kepada halusinasi dan terjemahan bahasa yang salah (3.5).
Kami juga menggunakan penyulingan peringkat jujukan untuk memperhalusi model ini kepada seni bina yang lebih kecil dan lebih mudah untuk alasan dan menyerlahkan jurang prestasi antara model guru dan pelajar (3.6).
Jadual kandungan bab adalah seperti berikut:
Penilaian
 Untuk menilai model terjemahan mesin mereka, para penyelidik mula-mula menterjemah ayat bahasa Inggeris ke dalam bahasa ini dan membina set penilaian (4.1) untuk 38 bahasa ekor panjang yang dipilih. Mereka menyerlahkan batasan BLEU dalam tetapan ekor panjang dan menilai bahasa ini menggunakan CHRF (4.2).
Untuk menilai model terjemahan mesin mereka, para penyelidik mula-mula menterjemah ayat bahasa Inggeris ke dalam bahasa ini dan membina set penilaian (4.1) untuk 38 bahasa ekor panjang yang dipilih. Mereka menyerlahkan batasan BLEU dalam tetapan ekor panjang dan menilai bahasa ini menggunakan CHRF (4.2).
Para penyelidik juga mencadangkan anggaran metrik bebas rujukan berdasarkan terjemahan pergi balik untuk memahami kualiti model dalam bahasa di mana set rujukan tidak tersedia, dan Kualiti daripada model seperti yang diukur oleh metrik ini dilaporkan (4.3). Mereka melakukan penilaian manusia terhadap model pada subset 28 bahasa dan melaporkan hasilnya, mengesahkan bahawa adalah mungkin untuk membina sistem terjemahan mesin yang berguna mengikut pendekatan yang diterangkan dalam kertas (4.4).
Untuk memahami kelemahan model sumber sifar berbilang bahasa berskala besar, penyelidik menjalankan analisis ralat kualitatif pada beberapa bahasa. Didapati model tersebut sering mengelirukan perkataan dan konsep yang serupa dalam pengedaran, seperti "harimau" menjadi "buaya kecil" (4.5). Dan di bawah tetapan sumber yang lebih rendah (4.6), keupayaan model untuk menterjemah token berkurangan pada token yang kelihatan kurang kerap.
Para penyelidik juga mendapati bahawa model ini selalunya tidak dapat menterjemah input pendek atau satu perkataan (4.7) dengan tepat. Penyelidikan ke atas model yang diperhalusi menunjukkan bahawa semua model lebih berkemungkinan untuk menguatkan bias atau hingar yang terdapat dalam data latihan (4.8).
Jadual kandungan Bab adalah seperti berikut:

Eksperimen dan nota tambahan
Para penyelidik menjalankan beberapa eksperimen tambahan pada model di atas, menunjukkan bahawa mereka secara amnya berprestasi lebih baik dalam menterjemah secara langsung antara bahasa yang serupa tanpa menggunakan bahasa Inggeris sebagai pangsi (5.1), dan bahawa mereka boleh digunakan antara bahasa yang berbeza. skrip Transliterasi sampel sifar bagi (5.2).
Mereka menerangkan helah praktikal untuk menambahkan tanda baca terminal pada sebarang input, dipanggil "helah tempoh", yang boleh digunakan untuk meningkatkan kualiti terjemahan (5.3) .
Selain itu, kami menunjukkan bahawa model ini teguh kepada penggunaan glif Unicode bukan standard dalam beberapa tetapi bukan semua bahasa (5.4), dan meneroka beberapa fon bukan Unicode ( 5.5).
Direktori bab adalah seperti berikut:

Untuk butiran penyelidikan lanjut, sila rujuk asal kertas.
Atas ialah kandungan terperinci Google telah mencipta sistem terjemahan mesin untuk 1,000+ bahasa 'ekor panjang' dan sudah menyokong beberapa bahasa khusus. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Cara Mengulas DeepSeek
Feb 19, 2025 pm 05:42 PM
Cara Mengulas DeepSeek
Feb 19, 2025 pm 05:42 PM
DeepSeek adalah alat pengambilan maklumat yang kuat. .
 Cara Mencari DeepSeek
Feb 19, 2025 pm 05:39 PM
Cara Mencari DeepSeek
Feb 19, 2025 pm 05:39 PM
DeepSeek adalah enjin carian proprietari yang hanya mencari dalam pangkalan data atau sistem tertentu, lebih cepat dan lebih tepat. Apabila menggunakannya, pengguna dinasihatkan untuk membaca dokumen itu, cuba strategi carian yang berbeza, dapatkan bantuan dan maklum balas mengenai pengalaman pengguna untuk memanfaatkan kelebihan mereka.
 Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Artikel ini memperkenalkan proses pendaftaran versi web Web Open Exchange (GATE.IO) dan aplikasi Perdagangan Gate secara terperinci. Sama ada pendaftaran web atau pendaftaran aplikasi, anda perlu melawat laman web rasmi atau App Store untuk memuat turun aplikasi tulen, kemudian isi nama pengguna, kata laluan, e -mel, nombor telefon bimbit dan maklumat lain, dan lengkap e -mel atau pengesahan telefon bimbit.
 Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung? Bybit adalah pertukaran cryptocurrency yang menyediakan perkhidmatan perdagangan kepada pengguna. Aplikasi mudah alih Exchange tidak boleh dimuat turun terus melalui AppStore atau GooglePlay untuk sebab -sebab berikut: 1. Aplikasi pertukaran cryptocurrency sering tidak memenuhi keperluan ini kerana ia melibatkan perkhidmatan kewangan dan memerlukan peraturan dan standard keselamatan tertentu. 2. Undang -undang dan Peraturan Pematuhan di banyak negara, aktiviti yang berkaitan dengan urus niaga cryptocurrency dikawal atau terhad. Untuk mematuhi peraturan ini, aplikasi bybit hanya boleh digunakan melalui laman web rasmi atau saluran yang diberi kuasa lain
 Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Artikel ini mencadangkan sepuluh platform perdagangan cryptocurrency teratas yang memberi perhatian kepada, termasuk Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI dan Xbit yang desentralisasi. Platform ini mempunyai kelebihan mereka sendiri dari segi kuantiti mata wang transaksi, jenis urus niaga, keselamatan, pematuhan, dan ciri khas. Memilih platform yang sesuai memerlukan pertimbangan yang komprehensif berdasarkan pengalaman perdagangan anda sendiri, toleransi risiko dan keutamaan pelaburan. Semoga artikel ini membantu anda mencari saman terbaik untuk diri sendiri
 Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Adalah penting untuk memilih saluran rasmi untuk memuat turun aplikasi dan memastikan keselamatan akaun anda.
 WEB OPEN DOOR EXCHANGE WEB PAGE LOGIN VERSI VERSI UNTUK GATEIO Laman Web Rasmi Pintu Masuk
Mar 04, 2025 pm 11:48 PM
WEB OPEN DOOR EXCHANGE WEB PAGE LOGIN VERSI VERSI UNTUK GATEIO Laman Web Rasmi Pintu Masuk
Mar 04, 2025 pm 11:48 PM
Pengenalan terperinci kepada operasi log masuk versi Web Open Exchange, termasuk langkah masuk dan proses pemulihan kata laluan.
 Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Untuk mengakses versi Login Laman Web Binance yang terkini, ikuti langkah mudah ini. Pergi ke laman web rasmi dan klik butang "Login" di sudut kanan atas. Pilih kaedah log masuk anda yang sedia ada. Masukkan nombor mudah alih berdaftar atau e -mel dan kata laluan anda dan pengesahan lengkap (seperti kod pengesahan mudah alih atau Google Authenticator). Selepas pengesahan yang berjaya, anda boleh mengakses Portal Log masuk laman web rasmi Binance.
