
 Peranti teknologi
AI
Mengapa model berasaskan pokok masih mengatasi pembelajaran mendalam pada data jadual
Peranti teknologi
AI
Mengapa model berasaskan pokok masih mengatasi pembelajaran mendalam pada data jadual
Mengapa model berasaskan pokok masih mengatasi pembelajaran mendalam pada data jadual

Dalam artikel ini, saya akan menerangkan secara terperinci kertas kerja "Mengapa model berasaskan pokok masih mengatasi pembelajaran mendalam pada data jadual" Kertas kerja ini menerangkan pemerhatian yang telah diperhatikan oleh pengamal pembelajaran mesin di seluruh dunia dalam pelbagai bidang diperhatikan - model berasaskan pokok adalah lebih baik dalam menganalisis data jadual daripada pembelajaran mendalam/rangkaian saraf.
Nota pada kertas
Kertas ini telah melalui banyak prapemprosesan. Contohnya, perkara seperti mengalih keluar data yang hilang boleh menghalang prestasi pokok, tetapi hutan rawak bagus untuk situasi data yang hilang jika data anda sangat kemas: mengandungi banyak ciri dan dimensi. Kekukuhan dan kelebihan RF menjadikannya lebih unggul daripada penyelesaian yang lebih "maju", yang terdedah kepada masalah.

Kebanyakan kerja yang lain adalah agak standard. Saya secara peribadi tidak suka menggunakan terlalu banyak teknik pra-pemprosesan kerana ini boleh menyebabkan kehilangan banyak nuansa set data, tetapi langkah-langkah yang diambil dalam kertas pada dasarnya menghasilkan set data yang sama. Walau bagaimanapun, adalah penting untuk ambil perhatian bahawa kaedah pemprosesan yang sama digunakan semasa menilai keputusan akhir.
Kertas ini juga menggunakan carian rawak untuk penalaan hiperparameter. Ini juga merupakan standard industri, tetapi dalam pengalaman saya carian Bayesian lebih sesuai untuk mencari dalam ruang carian yang lebih luas.
Memahami perkara ini, kita boleh menyelami persoalan utama kita - mengapa kaedah berasaskan pokok mengatasi pembelajaran mendalam
1. Rangkaian saraf cenderung menjadi penyelesaian yang terlalu lancar
Ini sebab pertama yang penulis kongsikan mengapa rangkaian neural pembelajaran mendalam tidak boleh bersaing dengan hutan rawak. Ringkasnya, rangkaian saraf mempunyai masa yang sukar untuk mencipta kesesuaian terbaik apabila ia berkaitan dengan sempadan fungsi/keputusan yang tidak lancar. Hutan rawak lebih baik dalam corak pelik/bergerigi/tidak teratur.

Jika saya meneka sebabnya, ini mungkin penggunaan kecerunan dalam rangkaian saraf, dan kecerunan bergantung pada ruang carian yang boleh dibezakan, yang mengikut definisi adalah lancar, Jadi ia adalah mustahil untuk membezakan antara titik tajam dan beberapa fungsi rawak. Jadi saya mengesyorkan mempelajari konsep AI seperti Algoritma Evolusi, Carian Tradisional dan lebih banyak konsep asas kerana konsep ini boleh membawa kepada hasil yang hebat dalam pelbagai situasi apabila NN gagal.
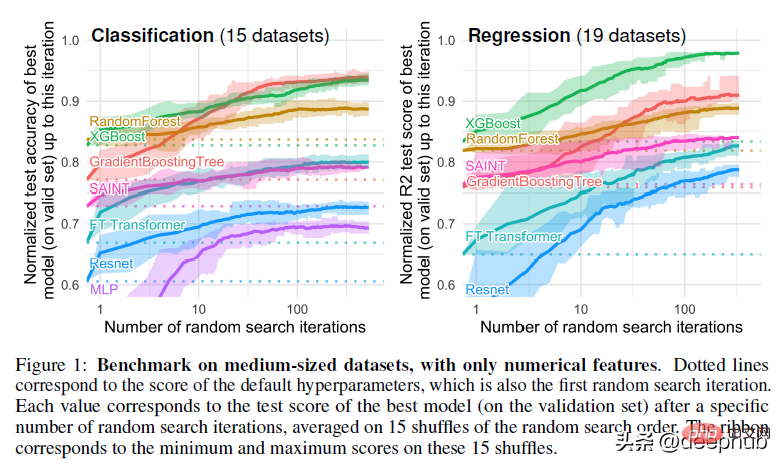
Untuk contoh yang lebih spesifik tentang perbezaan sempadan keputusan antara kaedah berasaskan pokok (RandomForests) dan pelajar mendalam, lihat rajah di bawah -
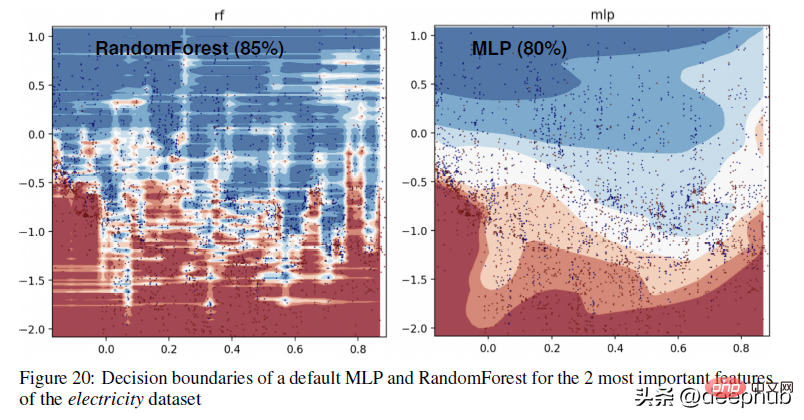
dalam lampiran , penulis menerangkan visualisasi di atas seperti berikut:
Dalam bahagian ini, kita dapat melihat bahawa RandomForest dapat mempelajari corak tidak sekata pada paksi-x (bersesuaian dengan ciri-ciri tarikh) yang MLP tidak dapat belajar. Kami menunjukkan perbezaan ini dalam hiperparameter lalai, yang merupakan tingkah laku tipikal rangkaian saraf, tetapi dalam praktiknya adalah sukar (walaupun tidak mustahil) untuk mencari hiperparameter yang berjaya mempelajari corak ini.
2. Sifat tidak bermaklumat akan menjejaskan rangkaian neural seperti MLP
Satu lagi faktor penting, terutamanya bagi set data besar yang mengekodkan berbilang perhubungan secara serentak. Jika anda menyalurkan ciri yang tidak berkaitan ke rangkaian saraf, hasilnya akan menjadi buruk (dan anda akan membazirkan lebih banyak sumber untuk melatih model anda). Inilah sebabnya mengapa sangat penting untuk menghabiskan banyak masa pada penerokaan EDA/domain. Ini akan membantu memahami ciri dan memastikan semuanya berjalan lancar.
Pengarang kertas menguji prestasi model apabila menambah rawak dan mengalih keluar ciri yang tidak berguna. Berdasarkan keputusan mereka, 2 hasil yang sangat menarik ditemui
Mengalih keluar sejumlah besar ciri mengurangkan jurang prestasi antara model. Ini jelas menunjukkan bahawa salah satu kelebihan model pokok ialah keupayaan mereka menilai sama ada ciri berguna dan mengelakkan pengaruh ciri tidak berguna.
Menambahkan ciri rawak pada set data menunjukkan bahawa rangkaian saraf merosot jauh lebih teruk daripada kaedah berasaskan pokok. ResNet terutamanya mengalami sifat tidak berguna ini. Penambahbaikan transformer mungkin kerana mekanisme perhatian di dalamnya akan membantu pada tahap tertentu.
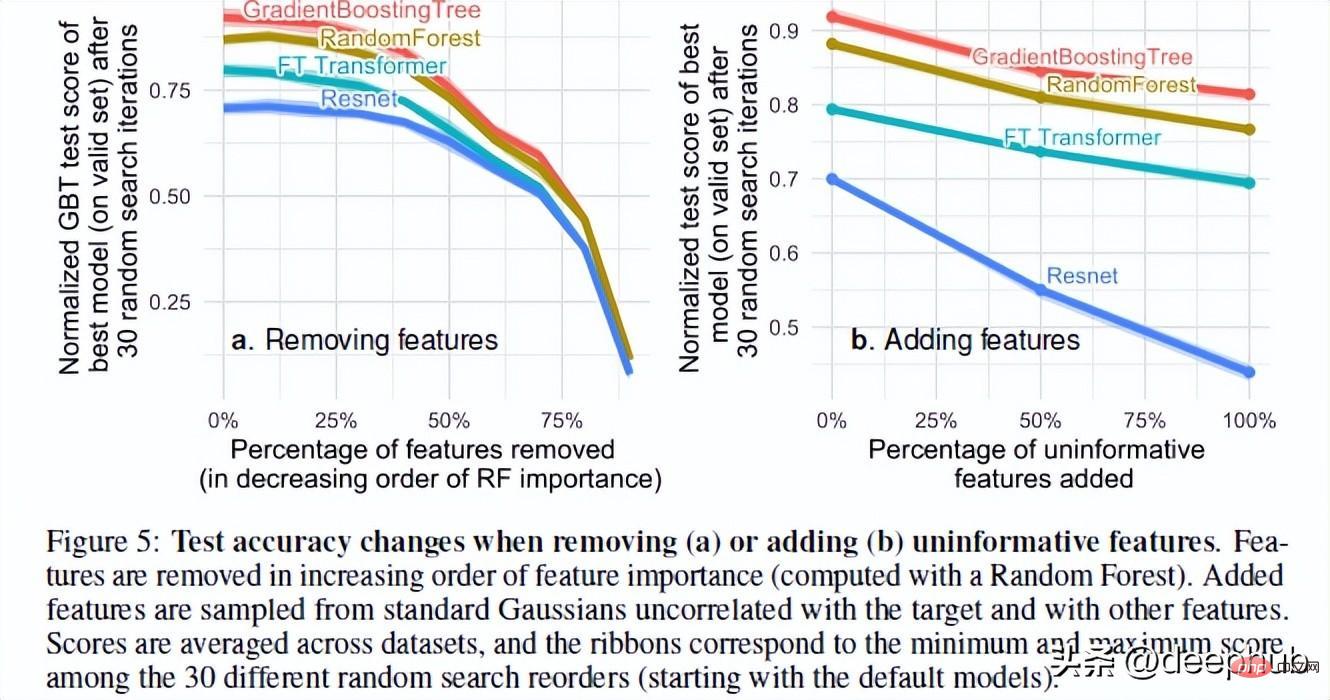
Satu penjelasan yang mungkin untuk fenomena ini ialah cara pepohon keputusan direka bentuk. Sesiapa yang telah mengikuti kursus AI akan mengetahui konsep perolehan maklumat dan entropi dalam pepohon keputusan. Ini membolehkan pepohon keputusan memilih laluan terbaik dengan membandingkan ciri yang selebihnya.
Kembali kepada topik, terdapat satu perkara terakhir yang menjadikan RF berprestasi lebih baik daripada NN apabila ia berkaitan dengan data jadual. Itulah invarian putaran.
3. NN adalah invarian putaran, tetapi data sebenar tidak
Rangkaian saraf adalah invarian putaran. Ini bermakna jika anda melakukan operasi putaran pada set data anda, ia tidak akan mengubah prestasinya. Selepas memutar set data, prestasi dan kedudukan model yang berbeza berubah dengan ketara Walaupun ResNets sentiasa yang paling teruk, ia mengekalkan prestasi asalnya selepas berputar, manakala semua model lain berubah dengan ketara.
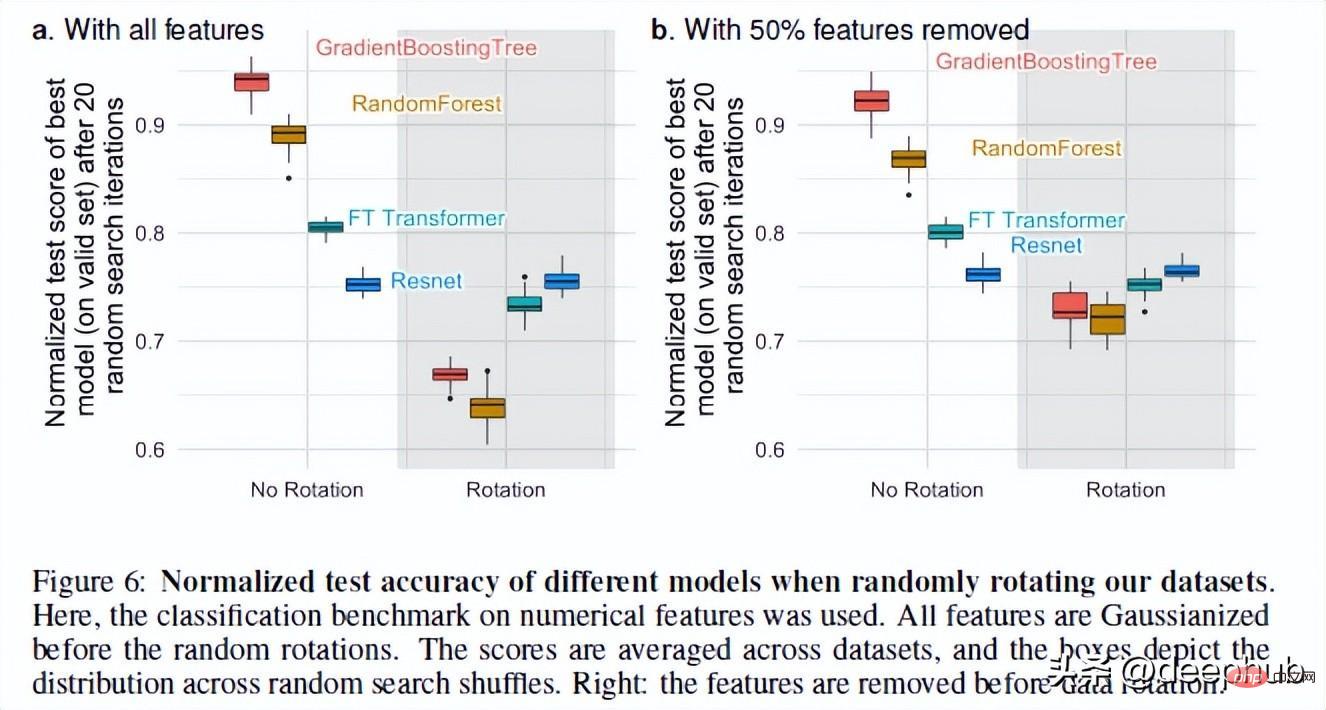
Ini sangat menarik: apakah sebenarnya maksud memutar set data Tiada penjelasan terperinci dalam keseluruhan kertas kerja (saya telah menghubungi pengarang dan akan menindaklanjuti fenomena ini) . Jika anda mempunyai sebarang pemikiran, sila kongsikannya dalam komen juga.
Tetapi operasi ini membolehkan kita melihat sebab varians putaran penting. Menurut pengarang, mengambil kombinasi linear ciri (yang menjadikan ResNets invarian) sebenarnya boleh menyalahgambarkan ciri dan hubungannya.
Mendapatkan bias data yang optimum dengan mengekodkan data asal, yang mungkin mencampurkan ciri dengan sifat statistik yang sangat berbeza dan tidak boleh dipulihkan oleh model invarian putaran, akan menyediakan model dengan prestasi yang Lebih Baik.
Ringkasan
Ini adalah kertas kerja yang sangat menarik Walaupun pembelajaran mendalam telah mencapai kemajuan besar pada set data teks dan imej, ia pada asasnya tidak mempunyai kelebihan pada data jadual. Makalah ini menggunakan 45 set data daripada domain yang berbeza untuk ujian, dan keputusan menunjukkan bahawa walaupun tanpa mengambil kira kelajuan unggulnya, model berasaskan pokok masih tercanggih pada data sederhana (~10K sampel).
Atas ialah kandungan terperinci Mengapa model berasaskan pokok masih mengatasi pembelajaran mendalam pada data jadual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Kaedah dan langkah untuk menggunakan BERT untuk analisis sentimen dalam Python
Jan 22, 2024 pm 04:24 PM
Kaedah dan langkah untuk menggunakan BERT untuk analisis sentimen dalam Python
Jan 22, 2024 pm 04:24 PM
BERT ialah model bahasa pembelajaran mendalam pra-latihan yang dicadangkan oleh Google pada 2018. Nama penuh ialah BidirectionalEncoderRepresentationsfromTransformers, yang berdasarkan seni bina Transformer dan mempunyai ciri pengekodan dwiarah. Berbanding dengan model pengekodan sehala tradisional, BERT boleh mempertimbangkan maklumat kontekstual pada masa yang sama semasa memproses teks, jadi ia berfungsi dengan baik dalam tugas pemprosesan bahasa semula jadi. Dwiarahnya membolehkan BERT memahami dengan lebih baik hubungan semantik dalam ayat, dengan itu meningkatkan keupayaan ekspresif model. Melalui kaedah pra-latihan dan penalaan halus, BERT boleh digunakan untuk pelbagai tugas pemprosesan bahasa semula jadi, seperti analisis sentimen, penamaan.
 YOLO adalah abadi! YOLOv9 dikeluarkan: prestasi dan kelajuan SOTA~
Feb 26, 2024 am 11:31 AM
YOLO adalah abadi! YOLOv9 dikeluarkan: prestasi dan kelajuan SOTA~
Feb 26, 2024 am 11:31 AM
Kaedah pembelajaran mendalam hari ini memberi tumpuan kepada mereka bentuk fungsi objektif yang paling sesuai supaya keputusan ramalan model paling hampir dengan situasi sebenar. Pada masa yang sama, seni bina yang sesuai mesti direka bentuk untuk mendapatkan maklumat yang mencukupi untuk ramalan. Kaedah sedia ada mengabaikan fakta bahawa apabila data input mengalami pengekstrakan ciri lapisan demi lapisan dan transformasi spatial, sejumlah besar maklumat akan hilang. Artikel ini akan menyelidiki isu penting apabila menghantar data melalui rangkaian dalam, iaitu kesesakan maklumat dan fungsi boleh balik. Berdasarkan ini, konsep maklumat kecerunan boleh atur cara (PGI) dicadangkan untuk menghadapi pelbagai perubahan yang diperlukan oleh rangkaian dalam untuk mencapai pelbagai objektif. PGI boleh menyediakan maklumat input lengkap untuk tugas sasaran untuk mengira fungsi objektif, dengan itu mendapatkan maklumat kecerunan yang boleh dipercayai untuk mengemas kini berat rangkaian. Di samping itu, rangka kerja rangkaian ringan baharu direka bentuk
 Di luar ORB-SLAM3! SL-SLAM: Adegan bertekstur lemah ringan, kegelisahan teruk dan lemah semuanya dikendalikan
May 30, 2024 am 09:35 AM
Di luar ORB-SLAM3! SL-SLAM: Adegan bertekstur lemah ringan, kegelisahan teruk dan lemah semuanya dikendalikan
May 30, 2024 am 09:35 AM
Ditulis sebelum ini, hari ini kita membincangkan bagaimana teknologi pembelajaran mendalam boleh meningkatkan prestasi SLAM berasaskan penglihatan (penyetempatan dan pemetaan serentak) dalam persekitaran yang kompleks. Dengan menggabungkan kaedah pengekstrakan ciri dalam dan pemadanan kedalaman, di sini kami memperkenalkan sistem SLAM visual hibrid serba boleh yang direka untuk meningkatkan penyesuaian dalam senario yang mencabar seperti keadaan cahaya malap, pencahayaan dinamik, kawasan bertekstur lemah dan seks yang teruk. Sistem kami menyokong berbilang mod, termasuk konfigurasi monokular, stereo, monokular-inersia dan stereo-inersia lanjutan. Selain itu, ia juga menganalisis cara menggabungkan SLAM visual dengan kaedah pembelajaran mendalam untuk memberi inspirasi kepada penyelidikan lain. Melalui percubaan yang meluas pada set data awam dan data sampel sendiri, kami menunjukkan keunggulan SL-SLAM dari segi ketepatan kedudukan dan keteguhan penjejakan.
 Pembenaman ruang terpendam: penjelasan dan demonstrasi
Jan 22, 2024 pm 05:30 PM
Pembenaman ruang terpendam: penjelasan dan demonstrasi
Jan 22, 2024 pm 05:30 PM
Pembenaman Ruang Terpendam (LatentSpaceEmbedding) ialah proses memetakan data berdimensi tinggi kepada ruang berdimensi rendah. Dalam bidang pembelajaran mesin dan pembelajaran mendalam, pembenaman ruang terpendam biasanya merupakan model rangkaian saraf yang memetakan data input berdimensi tinggi ke dalam set perwakilan vektor berdimensi rendah ini sering dipanggil "vektor terpendam" atau "terpendam pengekodan". Tujuan pembenaman ruang terpendam adalah untuk menangkap ciri penting dalam data dan mewakilinya ke dalam bentuk yang lebih ringkas dan mudah difahami. Melalui pembenaman ruang terpendam, kami boleh melakukan operasi seperti memvisualisasikan, mengelaskan dan mengelompokkan data dalam ruang dimensi rendah untuk memahami dan menggunakan data dengan lebih baik. Pembenaman ruang terpendam mempunyai aplikasi yang luas dalam banyak bidang, seperti penjanaan imej, pengekstrakan ciri, pengurangan dimensi, dsb. Pembenaman ruang terpendam adalah yang utama
 Fahami dalam satu artikel: kaitan dan perbezaan antara AI, pembelajaran mesin dan pembelajaran mendalam
Mar 02, 2024 am 11:19 AM
Fahami dalam satu artikel: kaitan dan perbezaan antara AI, pembelajaran mesin dan pembelajaran mendalam
Mar 02, 2024 am 11:19 AM
Dalam gelombang perubahan teknologi yang pesat hari ini, Kecerdasan Buatan (AI), Pembelajaran Mesin (ML) dan Pembelajaran Dalam (DL) adalah seperti bintang terang, menerajui gelombang baharu teknologi maklumat. Ketiga-tiga perkataan ini sering muncul dalam pelbagai perbincangan dan aplikasi praktikal yang canggih, tetapi bagi kebanyakan peneroka yang baru dalam bidang ini, makna khusus dan hubungan dalaman mereka mungkin masih diselubungi misteri. Jadi mari kita lihat gambar ini dahulu. Dapat dilihat bahawa terdapat korelasi rapat dan hubungan progresif antara pembelajaran mendalam, pembelajaran mesin dan kecerdasan buatan. Pembelajaran mendalam ialah bidang khusus pembelajaran mesin dan pembelajaran mesin
 Super kuat! 10 algoritma pembelajaran mendalam teratas!
Mar 15, 2024 pm 03:46 PM
Super kuat! 10 algoritma pembelajaran mendalam teratas!
Mar 15, 2024 pm 03:46 PM
Hampir 20 tahun telah berlalu sejak konsep pembelajaran mendalam dicadangkan pada tahun 2006. Pembelajaran mendalam, sebagai revolusi dalam bidang kecerdasan buatan, telah melahirkan banyak algoritma yang berpengaruh. Jadi, pada pendapat anda, apakah 10 algoritma teratas untuk pembelajaran mendalam? Berikut adalah algoritma teratas untuk pembelajaran mendalam pada pendapat saya Mereka semua menduduki kedudukan penting dari segi inovasi, nilai aplikasi dan pengaruh. 1. Latar belakang rangkaian saraf dalam (DNN): Rangkaian saraf dalam (DNN), juga dipanggil perceptron berbilang lapisan, adalah algoritma pembelajaran mendalam yang paling biasa Apabila ia mula-mula dicipta, ia dipersoalkan kerana kesesakan kuasa pengkomputeran tahun, kuasa pengkomputeran, Kejayaan datang dengan letupan data. DNN ialah model rangkaian saraf yang mengandungi berbilang lapisan tersembunyi. Dalam model ini, setiap lapisan menghantar input ke lapisan seterusnya dan
 1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
Alamat kertas: https://arxiv.org/abs/2307.09283 Alamat kod: https://github.com/THU-MIG/RepViTRepViT berprestasi baik dalam seni bina ViT mudah alih dan menunjukkan kelebihan yang ketara. Seterusnya, kami meneroka sumbangan kajian ini. Disebutkan dalam artikel bahawa ViT ringan biasanya berprestasi lebih baik daripada CNN ringan pada tugas visual, terutamanya disebabkan oleh modul perhatian diri berbilang kepala (MSHA) mereka yang membolehkan model mempelajari perwakilan global. Walau bagaimanapun, perbezaan seni bina antara ViT ringan dan CNN ringan belum dikaji sepenuhnya. Dalam kajian ini, penulis menyepadukan ViT ringan ke dalam yang berkesan
 Cara menggunakan model hibrid CNN dan Transformer untuk meningkatkan prestasi
Jan 24, 2024 am 10:33 AM
Cara menggunakan model hibrid CNN dan Transformer untuk meningkatkan prestasi
Jan 24, 2024 am 10:33 AM
Rangkaian Neural Konvolusi (CNN) dan Transformer ialah dua model pembelajaran mendalam berbeza yang telah menunjukkan prestasi cemerlang pada tugasan yang berbeza. CNN digunakan terutamanya untuk tugas penglihatan komputer seperti klasifikasi imej, pengesanan sasaran dan pembahagian imej. Ia mengekstrak ciri tempatan pada imej melalui operasi lilitan, dan melakukan pengurangan dimensi ciri dan invarian ruang melalui operasi pengumpulan. Sebaliknya, Transformer digunakan terutamanya untuk tugas pemprosesan bahasa semula jadi (NLP) seperti terjemahan mesin, klasifikasi teks dan pengecaman pertuturan. Ia menggunakan mekanisme perhatian kendiri untuk memodelkan kebergantungan dalam jujukan, mengelakkan pengiraan berjujukan dalam rangkaian saraf berulang tradisional. Walaupun kedua-dua model ini digunakan untuk tugasan yang berbeza, ia mempunyai persamaan dalam pemodelan jujukan, jadi
