
 Peranti teknologi
AI
Bagaimanakah pembelajaran mesin tanpa pengawasan boleh memberi manfaat kepada automasi industri?
Peranti teknologi
AI
Bagaimanakah pembelajaran mesin tanpa pengawasan boleh memberi manfaat kepada automasi industri?
Bagaimanakah pembelajaran mesin tanpa pengawasan boleh memberi manfaat kepada automasi industri?

Persekitaran industri moden dipenuhi dengan penderia dan komponen pintar, yang kesemuanya bersama-sama menghasilkan banyak data. Data ini, yang belum diterokai di kebanyakan kilang hari ini, menguasai pelbagai aplikasi baharu yang menarik. Malah, menurut IBM, purata kilang menjana 1TB data pengeluaran setiap hari. Walau bagaimanapun, hanya kira-kira 1% data bertukar menjadi cerapan yang boleh diambil tindakan.

Pembelajaran mesin (ML) ialah teknologi asas yang direka untuk memanfaatkan data ini dan membuka kunci sejumlah besar nilai. Menggunakan data latihan, sistem pembelajaran mesin boleh membina model matematik yang mengajar sistem untuk melaksanakan tugas tertentu tanpa arahan yang jelas.
ML menggunakan algoritma yang bertindak ke atas data untuk membuat keputusan sebahagian besarnya tanpa campur tangan manusia. Bentuk pembelajaran mesin yang paling biasa dalam automasi industri ialah pembelajaran mesin diselia, yang menggunakan sejumlah besar data sejarah yang dilabelkan oleh manusia untuk melatih model (iaitu, latihan algoritma diselia manusia).
Ini berguna untuk masalah yang terkenal seperti kecacatan galas, kegagalan pelinciran atau kecacatan produk. Apabila pembelajaran mesin yang diselia tidak mencukupi ialah apabila data sejarah yang mencukupi tidak tersedia, pelabelan terlalu memakan masa atau mahal, atau pengguna tidak pasti apa yang mereka cari dalam data. Di sinilah pembelajaran mesin yang tidak diselia dimainkan.
Pembelajaran mesin tanpa seliaan bertujuan untuk beroperasi pada data tidak berlabel menggunakan algoritma yang mahir dalam mengecam corak dan menentukan anomali dalam data. Pembelajaran mesin tanpa pengawasan yang digunakan dengan betul menyediakan pelbagai kes penggunaan automasi industri, daripada pemantauan keadaan dan ujian prestasi kepada keselamatan siber dan pengurusan aset.
Pembelajaran Terselia lwn. Pembelajaran Tanpa Selia
Pembelajaran mesin yang diselia lebih mudah dilaksanakan berbanding pembelajaran mesin yang tidak diselia. Dengan model yang terlatih dengan betul, ia boleh memberikan hasil yang sangat konsisten dan boleh dipercayai. Pembelajaran mesin yang diselia mungkin memerlukan sejumlah besar data sejarah - seperti yang diperlukan untuk memasukkan semua kes yang berkaitan, iaitu, untuk mengesan kecacatan produk, data tersebut perlu mengandungi bilangan kes produk yang rosak yang mencukupi. Pelabelan set data besar-besaran ini boleh memakan masa dan mahal. Tambahan pula, model latihan adalah satu seni. Ia memerlukan sejumlah besar data, disusun dengan betul, untuk menghasilkan hasil yang baik.
Kini, proses menanda aras algoritma ML yang berbeza telah dipermudahkan dengan ketara menggunakan alatan seperti AutoML. Pada masa yang sama, terlalu mengekang proses latihan boleh mengakibatkan model yang berprestasi baik pada set latihan tetapi berprestasi buruk pada data sebenar. Satu lagi kelemahan utama ialah pembelajaran mesin yang diselia tidak begitu berkesan untuk mengenal pasti arah aliran yang tidak dijangka dalam data atau menemui fenomena baharu. Untuk jenis aplikasi ini, pembelajaran mesin tanpa pengawasan boleh memberikan hasil yang lebih baik.
Teknik Pembelajaran Mesin Tanpa Selia Biasa
Berbanding dengan pembelajaran mesin diselia, pembelajaran mesin tanpa pengawasan hanya beroperasi pada input tidak berlabel . Ia menyediakan alat yang berkuasa untuk penerokaan data untuk menemui corak dan korelasi yang tidak diketahui tanpa bantuan manusia. Keupayaan untuk beroperasi pada data tidak berlabel menjimatkan masa dan wang serta membolehkan pembelajaran mesin tanpa pengawasan beroperasi pada data sebaik sahaja input dijana.
Kerugiannya ialah pembelajaran mesin tanpa pengawasan adalah lebih kompleks daripada pembelajaran mesin yang diselia. Ia lebih mahal, memerlukan tahap kepakaran yang lebih tinggi, dan secara amnya memerlukan lebih banyak data. Outputnya cenderung kurang dipercayai berbanding ML yang diselia, dan akhirnya memerlukan penyeliaan manusia untuk hasil yang optimum.
Tiga bentuk penting teknik pembelajaran mesin tanpa pengawasan ialah pengelompokan, pengesanan anomali dan pengurangan dimensi data.
Penghimpunan
Seperti namanya, pengelompokan melibatkan menganalisis set data untuk mengenal pasti ciri yang dikongsi antara data dan mengumpulkan kejadian serupa bersama-sama . Oleh kerana pengelompokan ialah teknik ML tanpa pengawasan, algoritma (bukan manusia) menentukan kriteria kedudukan. Oleh itu, pengelompokan boleh membawa kepada penemuan yang mengejutkan dan merupakan alat penerokaan data yang sangat baik.
Berikan contoh mudah: bayangkan tiga orang diminta mengisih buah-buahan di bahagian pengeluaran. Satu mungkin menyusun mengikut jenis buah -- sitrus, buah batu, buah tropika, dll.; Setiap kaedah menyerlahkan set ciri yang berbeza.
Kluster boleh dibahagikan kepada banyak jenis. Yang paling biasa ialah:
Penghimpunan Eksklusif: Tis data diperuntukkan secara eksklusif kepada gugusan.
Kelompok kabur atau bertindih (Penghimpunan Kabur): Tindasan data boleh diberikan kepada berbilang kelompok. Sebagai contoh, oren adalah kedua-dua buah sitrus dan tropika. Dalam kes algoritma ML tanpa pengawasan yang beroperasi pada data tidak berlabel, adalah mungkin untuk menetapkan kebarangkalian bahawa blok data tergolong dalam kumpulan A berbanding kumpulan B dengan betul.
Penghimpunan hierarki: Teknik ini melibatkan membina struktur hierarki data berkelompok dan bukannya satu set kelompok. Oren ialah buah sitrus, tetapi ia juga termasuk dalam kumpulan buah sfera yang lebih besar dan boleh diserap lebih lanjut oleh semua kumpulan buah.
Mari kita lihat satu set algoritma pengelompokan yang paling popular:
- K-means
K- algoritma min (K-means) mengklasifikasikan data ke dalam kelompok K, di mana nilai K dipratetap oleh pengguna. Pada permulaan proses, algoritma secara rawak memberikan titik data K sebagai centroid untuk kelompok K. Seterusnya, ia mengira min antara setiap titik data dan pusat gugusannya. Ini mengakibatkan penggunaan data kepada kluster. Pada ketika ini, algoritma mengira semula centroid dan mengulangi pengiraan min. Ia mengulangi proses pengiraan centroid dan menyusun semula kelompok sehingga ia mencapai penyelesaian tetap (lihat Rajah 1).

Rajah 1: Algoritma K-means membahagikan set data kepada kelompok K dan mula-mula memilih titik data K secara rawak sebagai centroids , dan kemudian mengedarkan baki kejadian secara rawak ke seluruh kelompok.
Algoritma K-means adalah mudah dan cekap. Ia sangat berguna untuk pengecaman corak dan perlombongan data. Kelemahannya ialah ia memerlukan pengetahuan lanjutan tentang set data untuk mengoptimumkan persediaan. Ia juga dipengaruhi secara tidak seimbang oleh outlier.
- K-median
Algoritma K-median ialah saudara terdekat bagi K-means . Ia pada dasarnya menggunakan proses yang sama, kecuali daripada mengira min setiap titik data, ia mengira median. Oleh itu, algoritma kurang sensitif kepada outlier.
Berikut ialah beberapa kes penggunaan biasa untuk analisis kelompok:
- Pengkelompokan sangat berkesan untuk kes penggunaan seperti segmentasi. Ini sering dikaitkan dengan analisis pelanggan. Ia juga boleh digunakan pada kelas aset, bukan sahaja untuk menganalisis kualiti dan prestasi produk, tetapi juga untuk mengenal pasti corak penggunaan yang mungkin memberi kesan kepada prestasi produk dan hayat perkhidmatan. Ini berguna untuk syarikat OEM yang mengurus "fleet" aset, seperti robot mudah alih automatik di gudang pintar atau dron untuk pemeriksaan dan pengumpulan data.
- Ia boleh digunakan untuk pembahagian imej sebagai sebahagian daripada operasi pemprosesan imej.
- Analisis kluster juga boleh digunakan sebagai langkah pra-pemprosesan untuk membantu menyediakan data untuk aplikasi ML yang diselia.
Pengesanan Anomali
Pengesanan anomali adalah penting untuk pelbagai kes penggunaan daripada pengesanan kecacatan kepada pemantauan keadaan kepada keselamatan siber. Ini adalah tugas utama dalam pembelajaran mesin tanpa pengawasan. Terdapat beberapa algoritma pengesanan anomali yang digunakan dalam pembelajaran mesin tanpa pengawasan, mari kita lihat dua algoritma yang paling popular:
- Algoritma Hutan Pengasingan
Kaedah standard pengesanan anomali adalah untuk mewujudkan satu set nilai normal dan kemudian menganalisis setiap data untuk melihat sama ada dan sejauh mana ia menyimpang daripada nilai normal. Ini adalah proses yang sangat memakan masa apabila bekerja dengan set data besar-besaran jenis yang digunakan dalam ML. Algoritma hutan pengasingan mengambil pendekatan yang bertentangan. Ia mentakrifkan outlier sebagai tidak biasa atau sangat berbeza daripada kejadian lain dalam set data. Oleh itu, mereka lebih mudah diasingkan daripada set data yang lain pada keadaan lain.
Algoritma hutan pengasingan mempunyai keperluan memori yang minimum dan masa yang diperlukan adalah berkaitan secara linear dengan saiz set data. Mereka boleh mengendalikan data berdimensi tinggi walaupun ia melibatkan atribut yang tidak berkaitan.
- Local Outlier Factor (LOF)
Salah satu cabaran untuk mengenal pasti outlier hanya dengan jaraknya dari centroid Ya, titik data yang berada dalam jarak dekat dari gugusan kecil mungkin terpencil, manakala titik yang kelihatan jauh dari gugusan besar mungkin tidak. Algoritma LOF direka untuk membuat perbezaan ini.
LOF mentakrifkan outlier sebagai titik data dengan sisihan ketumpatan setempat yang jauh lebih besar daripada titik data jirannya (lihat Rajah 2). Walaupun seperti K-means ia memerlukan beberapa persediaan pengguna lebih awal, ia boleh menjadi sangat berkesan. Ia juga boleh digunakan untuk pengesanan kebaharuan apabila digunakan sebagai algoritma separa diselia dan dilatih pada data biasa sahaja.
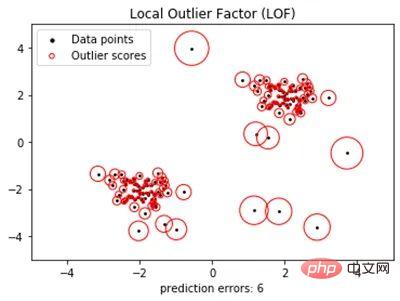
Rajah 2: Local Outlier Factor (LOF) menggunakan sisihan ketumpatan setempat bagi setiap titik data untuk mengira skor anomali , dengan itu membezakan titik data biasa daripada outlier.
Berikut ialah beberapa kes penggunaan untuk pengesanan anomali:
- Penyelenggaraan Ramalan: Kebanyakan peralatan industri dibina untuk bertahan dengan masa henti yang minimum. Oleh itu, data sejarah yang ada selalunya terhad. Oleh kerana ML yang tidak diawasi boleh mengesan gelagat anomali walaupun dalam set data yang terhad, ia berkemungkinan mengenal pasti kekurangan pembangunan dalam kes ini. Di sini juga, ia boleh digunakan untuk pengurusan armada, memberikan amaran awal tentang kecacatan sambil meminimumkan jumlah data yang perlu disemak.
- Jaminan/Pemeriksaan Kualiti: Jentera yang tidak dikendalikan dengan betul boleh menghasilkan produk yang tidak berkualiti. Pembelajaran mesin tanpa pengawasan boleh digunakan untuk memantau fungsi dan proses untuk membenderakan sebarang anomali. Tidak seperti proses QA standard, ia boleh melakukan ini tanpa pelabelan dan latihan.
- Pengenalpastian anomali imej: Ini amat berguna dalam pengimejan perubatan untuk mengenal pasti patologi berbahaya.
- Keselamatan Siber: Salah satu cabaran terbesar dalam keselamatan siber ialah ancaman sentiasa berubah. Dalam kes ini, pengesanan anomali melalui ML tanpa pengawasan boleh menjadi sangat berkesan. Satu teknik keselamatan standard ialah memantau aliran data. Jika PLC yang biasanya menghantar arahan kepada komponen lain tiba-tiba mula menerima aliran tetap arahan daripada peranti atipikal atau alamat IP, ini mungkin menunjukkan pencerobohan. Tetapi bagaimana jika kod berniat jahat itu datang daripada sumber yang dipercayai (atau pelakon jahat menipu sumber yang dipercayai)? Pembelajaran tanpa pengawasan boleh mengesan pelakon jahat dengan mencari tingkah laku atipikal dalam peranti yang menerima arahan.
- Analisis data ujian: Ujian memainkan peranan penting dalam kedua-dua reka bentuk dan pengeluaran. Dua cabaran terbesar yang terlibat ialah jumlah data yang terlibat, dan keupayaan untuk menganalisis data tanpa memperkenalkan kecenderungan yang wujud. Pembelajaran mesin tanpa pengawasan boleh menyelesaikan kedua-dua cabaran. Ia boleh menjadi faedah tertentu semasa proses pembangunan atau penyelesaian masalah pengeluaran apabila pasukan ujian tidak pasti apa yang mereka cari.
Pengurangan dimensi
Pembelajaran mesin adalah berdasarkan jumlah data yang besar, selalunya jumlah yang sangat besar. Satu perkara untuk menapis set data dengan sepuluh hingga berdozen ciri. Set data dengan beribu-ribu ciri (dan ia pasti wujud) boleh menjadi sangat menggembirakan. Oleh itu, langkah pertama dalam ML boleh menjadi pengurangan dimensi untuk mengurangkan data kepada ciri yang paling bermakna.
Algoritma biasa yang digunakan untuk pengurangan dimensi, pengecaman corak dan penerokaan data ialah Analisis Komponen Utama (PCA). Perbincangan terperinci tentang algoritma ini adalah di luar skop artikel ini. Boleh dikatakan ia boleh membantu mengenal pasti subset data yang saling ortogon, iaitu ia boleh dialih keluar daripada set data tanpa menjejaskan analisis utama. PCA mempunyai beberapa kes penggunaan yang menarik:
- Prapemprosesan Data: Apabila ia berkaitan dengan pembelajaran mesin, falsafah yang sering dinyatakan ialah lebih banyak adalah lebih baik. Yang berkata, kadangkala lebih banyak, terutamanya dalam kes data yang tidak relevan/berlebihan. Dalam kes ini, pembelajaran mesin tanpa pengawasan boleh digunakan untuk mengalih keluar ciri yang tidak diperlukan (dimensi data), mempercepatkan masa pemprosesan dan meningkatkan hasil. Dalam kes sistem visual, pembelajaran mesin tanpa pengawasan boleh digunakan untuk pengurangan hingar.
- Mampatan Imej: PCA sangat baik untuk mengurangkan dimensi set data sambil mengekalkan maklumat yang bermakna. Ini menjadikan algoritma sangat baik pada pemampatan imej.
- Pengecaman Corak: Ciri yang sama yang dibincangkan di atas menjadikan PCA berguna untuk tugas seperti pengecaman muka dan pengecaman imej kompleks lain.
Pembelajaran mesin tanpa pengawasan tidak lebih baik atau lebih buruk daripada pembelajaran mesin yang diselia. Untuk projek yang betul, ia boleh menjadi sangat berkesan. Walau bagaimanapun, peraturan terbaik adalah untuk menjadikannya mudah, jadi pembelajaran mesin tanpa pengawasan biasanya hanya digunakan pada masalah yang tidak dapat diselesaikan oleh pembelajaran mesin yang diawasi.
Fikirkan tentang soalan berikut untuk menentukan pendekatan pembelajaran mesin yang terbaik untuk projek anda:
- Apakah soalan itu?
- Apakah kes perniagaan? Apakah matlamat kuantifikasi? Berapa cepat projek itu akan memberikan pulangan pelaburan? Bagaimanakah ini dibandingkan dengan pembelajaran diselia atau penyelesaian lain yang lebih tradisional?
- Apakah jenis data input yang tersedia? Berapa banyak yang anda ada? Adakah ia berkaitan dengan soalan yang ingin anda jawab? Adakah terdapat proses yang telah menghasilkan data berlabel, sebagai contoh, adakah terdapat proses QA yang mengenal pasti produk yang rosak? Adakah terdapat pangkalan data penyelenggaraan yang merekodkan kegagalan peralatan?
- Adakah ia sesuai untuk pembelajaran mesin tanpa pengawasan?
Akhir sekali, berikut ialah beberapa petua untuk membantu memastikan kejayaan:
- Buat kerja rumah anda dan bangunkan strategi sebelum memulakan projek.
- Mulakan kecil dan betulkan pepijat pada skala yang lebih kecil.
- Pastikan penyelesaiannya berskala, anda tidak mahu berakhir di api penyucian projek perintis.
- Pertimbangkan bekerja dengan rakan kongsi. Semua jenis pembelajaran mesin memerlukan kepakaran. Cari alat dan rakan kongsi yang betul untuk mengautomasikan. Jangan cipta semula roda. Anda boleh membayar untuk membina kemahiran yang diperlukan secara dalaman, atau anda boleh mengarahkan sumber anda ke arah menyampaikan produk dan perkhidmatan yang anda lakukan dengan terbaik sambil membenarkan rakan kongsi dan ekosistem anda mengendalikan beban berat.
Data yang dikumpul dalam tetapan industri boleh menjadi sumber yang berharga, tetapi hanya jika digunakan dengan sewajarnya. Pembelajaran mesin tanpa pengawasan boleh menjadi alat yang berkuasa untuk menganalisis set data untuk mengekstrak cerapan yang boleh diambil tindakan. Mengguna pakai teknologi ini boleh mencabar, tetapi ia boleh memberikan kelebihan daya saing yang ketara dalam dunia yang mencabar.
Atas ialah kandungan terperinci Bagaimanakah pembelajaran mesin tanpa pengawasan boleh memberi manfaat kepada automasi industri?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Cadangan Aplikasi Pertukaran Mata Wang Digital 10 Teratas, Top Sepuluh Pertukaran Mata Wang Maya dalam Bulatan Mata Wang
Apr 22, 2025 pm 03:03 PM
Cadangan Aplikasi Pertukaran Mata Wang Digital 10 Teratas, Top Sepuluh Pertukaran Mata Wang Maya dalam Bulatan Mata Wang
Apr 22, 2025 pm 03:03 PM
Aplikasi yang disyorkan di atas sepuluh pertukaran mata wang digital: 1. Okx, 2. Binance, 3.
 Apakah platform perdagangan mata wang digital pada tahun 2025? Kedudukan terbaru dari sepuluh aplikasi mata wang digital teratas
Apr 22, 2025 pm 03:09 PM
Apakah platform perdagangan mata wang digital pada tahun 2025? Kedudukan terbaru dari sepuluh aplikasi mata wang digital teratas
Apr 22, 2025 pm 03:09 PM
Aplikasi yang disyorkan untuk platform tontonan mata wang maya yang teratas: 1. Okx, 2.
 10 Teratas Aplikasi Mata Wang Maya Digital: Pertukaran mata wang digital teratas dalam Perdagangan Bulatan Mata Wang
Apr 22, 2025 pm 03:00 PM
10 Teratas Aplikasi Mata Wang Maya Digital: Pertukaran mata wang digital teratas dalam Perdagangan Bulatan Mata Wang
Apr 22, 2025 pm 03:00 PM
Sepuluh aplikasi mata wang maya digital teratas ialah: 1. Okx, 2. Binance, 3. Gate.io, 4. Coinbase, 5 Kraken, 6. Huobi, 7. Kucoin, 8. Pertukaran ini dipilih berdasarkan faktor -faktor seperti jumlah urus niaga, pengalaman pengguna dan keselamatan, dan semuanya menyediakan pelbagai perkhidmatan perdagangan mata wang digital dan pengalaman perdagangan yang cekap.
 Meme Coin Exchange Ranking Meme Coin Exchange Utama Top 10 tempat
Apr 22, 2025 am 09:57 AM
Meme Coin Exchange Ranking Meme Coin Exchange Utama Top 10 tempat
Apr 22, 2025 am 09:57 AM
Platform yang paling sesuai untuk duit syiling meme perdagangan termasuk: 1. Binance, yang terbesar di dunia, dengan kecairan yang tinggi dan yuran pengendalian yang rendah; 2. Okx, enjin perdagangan yang cekap, menyokong pelbagai syiling meme; 3. 4. Redim (Solana dex), kos rendah, digabungkan dengan buku pesanan serum; 5. Pancakeswap (BSC DEX), yuran transaksi yang rendah dan kelajuan cepat; 6. Orca (Solana dex), Pengoptimuman Pengalaman Pengguna; 7. Coinbase, keselamatan tinggi, sesuai untuk pemula; 8. Huobi, terkenal di Asia, pasangan perdagangan yang kaya; 9. Dexrabbit, pintar
 Cadangan aplikasi pertukaran mata wang maya yang boleh dipercayai dan mudah digunakan Ranking terbaru sepuluh pertukaran dalam bulatan mata wang
Apr 22, 2025 pm 01:21 PM
Cadangan aplikasi pertukaran mata wang maya yang boleh dipercayai dan mudah digunakan Ranking terbaru sepuluh pertukaran dalam bulatan mata wang
Apr 22, 2025 pm 01:21 PM
Aplikasi pertukaran mata wang maya yang boleh dipercayai dan mudah digunakan ialah: 1. Binance, 2 Okx, 3. Gate.io, 4 Coinbase, 5. Kraken, 6. Huobi Global, 7 Bitfinex, 8. Kucoin, 9. Bittrex, 10. Platform ini dipilih sebagai yang terbaik untuk jumlah transaksi, pengalaman pengguna dan keselamatan mereka, dan semua tawaran pendaftaran, pengesahan, deposit, pengeluaran dan operasi transaksi.
 Apakah laman web perisian tontonan pasaran percuma? Kedudukan sepuluh perisian tontonan pasaran bebas teratas dalam bulatan mata wang
Apr 22, 2025 am 10:57 AM
Apakah laman web perisian tontonan pasaran percuma? Kedudukan sepuluh perisian tontonan pasaran bebas teratas dalam bulatan mata wang
Apr 22, 2025 am 10:57 AM
Tiga teratas sepuluh perisian tontonan pasaran bebas teratas dalam bulatan mata wang adalah OKX, Binance dan Gate.io. 1. OKX menyediakan antara muka mudah dan data masa nyata, menyokong pelbagai carta dan analisis pasaran. 2. Binance mempunyai fungsi yang kuat, data yang tepat, dan sesuai untuk semua jenis peniaga. 3. Gate.io terkenal dengan kestabilan dan komprehensifnya, dan sesuai untuk pelabur jangka panjang dan jangka pendek.
 Sepuluh cadangan platform percuma untuk data masa nyata mengenai pasaran bulatan mata wang dikeluarkan
Apr 22, 2025 am 08:12 AM
Sepuluh cadangan platform percuma untuk data masa nyata mengenai pasaran bulatan mata wang dikeluarkan
Apr 22, 2025 am 08:12 AM
Platform data cryptocurrency yang sesuai untuk pemula termasuk coinmarketcap dan sangkakala bukan kecil. 1. CoinMarketCap menyediakan harga masa nyata global, nilai pasaran, dan kedudukan volum perdagangan untuk keperluan analisis pemula dan asas. 2. Petikan bukan kecil menyediakan antara muka yang mesra Cina, sesuai untuk pengguna Cina untuk cepat menyaring projek berpotensi berisiko rendah.
 Apakah aplikasi perdagangan mata wang digital sesuai untuk pemula? Ketahui mengenai bulatan duit syiling dalam satu artikel
Apr 22, 2025 am 08:45 AM
Apakah aplikasi perdagangan mata wang digital sesuai untuk pemula? Ketahui mengenai bulatan duit syiling dalam satu artikel
Apr 22, 2025 am 08:45 AM
Apabila memilih platform perdagangan mata wang digital yang sesuai untuk pemula, anda perlu mempertimbangkan keselamatan, kemudahan penggunaan, sumber pendidikan dan ketelusan kos: 1. Keutamaan diberikan kepada platform yang menyediakan penyimpanan sejuk, pengesahan dua faktor dan insurans aset; 2. Aplikasi dengan antara muka yang mudah dan operasi yang jelas lebih sesuai untuk pemula; 3. Platform harus menyediakan alat pembelajaran seperti tutorial dan analisis pasaran; 4. Perhatikan kos tersembunyi seperti yuran transaksi dan yuran pengeluaran tunai.
