

Apabila model pembelajaran mesin menjadi lebih popular untuk meramal dan menganalisis data, penggunaan algoritma hutan rawak semakin mendapat momentum. Random Forest ialah algoritma pembelajaran diselia yang digunakan untuk tugas regresi dan pengelasan dalam bidang pembelajaran mesin. Ia berfungsi dengan membina sejumlah besar pokok keputusan pada masa latihan dan mengeluarkan kelas, sama ada mod kelas (pengkelasan) atau ramalan purata satu pokok (regresi).
Dalam artikel ini, kita akan membincangkan cara melaksanakan algoritma Random Forest menggunakan set data dunia sebenar dalam talian. Kami juga akan memberikan penerangan dan penerangan kod terperinci bagi setiap langkah, serta penilaian prestasi model dan visualisasi.
Dataset yang akan kami gunakan ialah "Set Data Kanser Payudara Wisconsin (Diagnostik)", yang tersedia secara umum dan boleh diakses melalui Repositori Pembelajaran Mesin UCI. Set data mempunyai 569 kejadian dengan 30 atribut dan dua kategori - malignan dan jinak. Matlamat kami adalah untuk mengklasifikasikan kejadian ini berdasarkan 30 sifat dan menentukan sama ada ia adalah jinak atau malignan. Anda boleh memuat turun set data daripada https://www.kaggle.com/datasets/uciml/breast-cancer-wisconsin-data.
Pertama, kami akan mengimport perpustakaan yang diperlukan:
import pandas as pd import numpy as np import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
Seterusnya, kami akan memuatkan set data :
df = pd.read_csv(r"C:UsersUserDownloadsdatabreast_cancer_wisconsin_diagnostic_dataset.csv") df
Output:
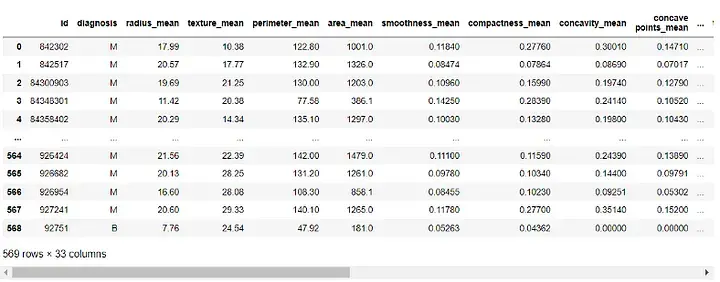
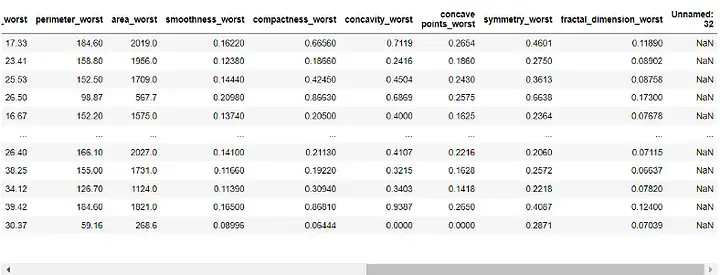
Sebelum membina model, kita perlu praproses data. Oleh kerana lajur 'id' dan 'Tanpa Nama: 32' tidak berguna kepada model kami, kami akan mengalih keluarnya:
df = df.drop([ 'id' , 'Unnamed: 32' ], axis=1) df
Output:
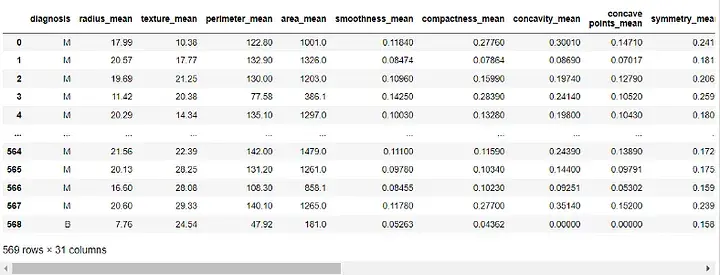
Seterusnya, kami akan menetapkan lajur "Diagnostik" kepada pembolehubah sasaran kami dan mengalih keluarnya daripada ciri kami:
target = df['diagnosis']
features = df.drop('diagnosis', axis=1)Kami kini akan membahagikan set data kami kepada set latihan dan ujian. Kami akan menggunakan 70% daripada data untuk latihan dan 30% untuk ujian:
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.3, random_state=42)
melalui prapemprosesan data kami dan dibahagikan kepada set latihan dan ujian, kami kini boleh membina model hutan rawak kami:
rf = RandomForestClassifier(n_estimators=100, random_state=42) rf.fit(X_train, y_train)
Di sini kami menetapkan bilangan pokok keputusan dalam hutan kepada 100 dan menetapkan Rawak untuk memastikan kebolehulangan hasil .
Kini, kita boleh menilai prestasi model. Kami akan menggunakan skor ketepatan, matriks kekeliruan dan laporan klasifikasi untuk penilaian:
y_pred = rf.predict(X_test)
# 准确度分数
print("Accuracy Score:", accuracy_score(y_test, y_pred))
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:n", conf_matrix)
# Classification Report
class_report = classification_report(y_test, y_pred)
print("Classification Report:n", class_report)Output:
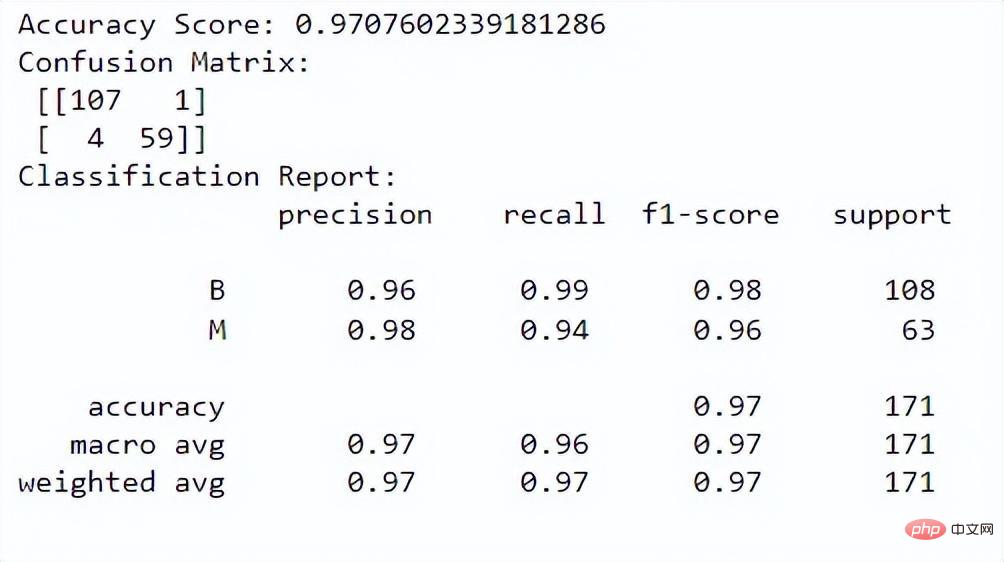
Skor ketepatan memberitahu kami prestasi model pada mengelaskan kejadian dengan betul. Matriks kekeliruan memberi kami pemahaman yang lebih baik tentang prestasi pengelasan model kami. Laporan klasifikasi memberi kami ketepatan, ingatan semula, skor f1 dan nilai sokongan untuk kedua-dua kelas.
Akhir sekali, kita dapat menggambarkan kepentingan setiap ciri dalam model. Kita boleh melakukannya dengan mencipta carta bar yang menunjukkan nilai kepentingan ciri:
importance = rf.feature_importances_ feat_imp = pd.Series(importance, index=features.columns) feat_imp = feat_imp.sort_values(ascending=False)
plt.figure(figsize=(12,8))
feat_imp.plot(kind='bar')
plt.ylabel('Feature Importance Score')
plt.title("Feature Importance")
plt.show()Output:
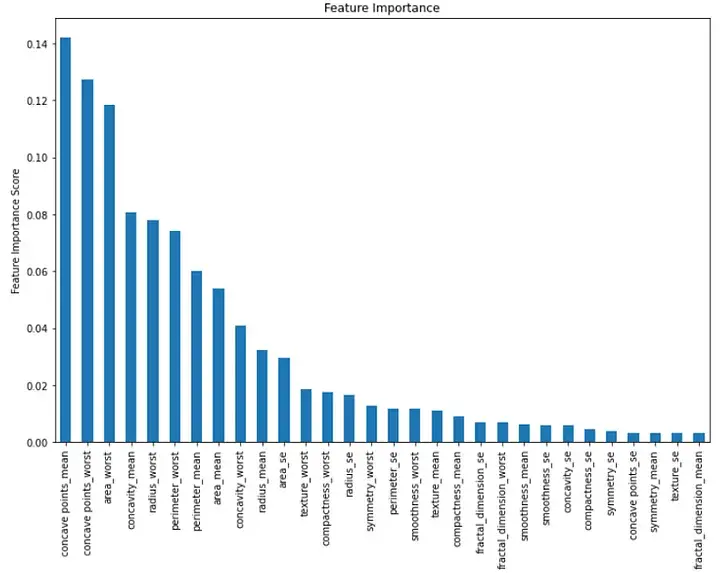
Carta bar ini menunjukkan kepentingan setiap ciri dalam tertib menurun. Kita dapat melihat bahawa tiga ciri penting pertama ialah "min concavity", "worst concavity" dan "worst region".
Ringkasnya, melaksanakan algoritma hutan rawak dalam pembelajaran mesin ialah alat yang berkuasa untuk tugasan pengelasan. Kami boleh menggunakan ini untuk mengklasifikasikan kejadian berdasarkan berbilang ciri dan menilai prestasi model kami. Dalam makalah ini, kami menggunakan set data dunia nyata dalam talian dan memberikan penjelasan dan penerangan kod terperinci bagi setiap langkah, serta penilaian prestasi model dan visualisasi.
Atas ialah kandungan terperinci Panduan untuk melaksanakan algoritma hutan rawak dalam pembelajaran mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perbezaan antara nohup dan &
Perbezaan antara nohup dan &
 Mengapa saya tidak boleh mengakses penyemak imbas Ethereum?
Mengapa saya tidak boleh mengakses penyemak imbas Ethereum?
 Apakah maksud pycharm apabila berjalan secara selari?
Apakah maksud pycharm apabila berjalan secara selari?
 Cara menggunakan fungsi bulan
Cara menggunakan fungsi bulan
 Tiada perkhidmatan pada data mudah alih
Tiada perkhidmatan pada data mudah alih
 Bagaimana untuk mengalih keluar kunci keselamatan Firefox
Bagaimana untuk mengalih keluar kunci keselamatan Firefox
 Bagaimana untuk menyemak penggunaan memori jvm
Bagaimana untuk menyemak penggunaan memori jvm
 Penjelasan terperinci tentang arahan linux dd
Penjelasan terperinci tentang arahan linux dd








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



