
 Peranti teknologi
AI
Ringkasan mata pengetahuan penting yang berkaitan dengan model regresi pembelajaran mesin
Peranti teknologi
AI
Ringkasan mata pengetahuan penting yang berkaitan dengan model regresi pembelajaran mesin
Ringkasan mata pengetahuan penting yang berkaitan dengan model regresi pembelajaran mesin

1. Apakah andaian regresi linear?
Regression linear mempunyai empat andaian:
- Linear: Perlu ada hubungan linear antara pembolehubah bebas (x) dan pembolehubah bersandar (y), yang bermaksud bahawa perubahan dalam nilai x juga harus mengubah nilai y ke arah yang sama.
- Kemerdekaan: Ciri harus bebas antara satu sama lain, yang bermaksud multikolineariti minimum.
- Kenormalan: Sisa hendaklah diagihkan secara normal.
- Homoskedastisitas: Varians titik data di sekeliling garis regresi hendaklah sama untuk semua nilai.
2. Apakah baki dan bagaimana ia digunakan untuk menilai model regresi?
Ralat baki merujuk kepada ralat antara nilai yang diramalkan dan nilai yang diperhatikan. Ia mengukur jarak titik data dari garis regresi. Ia dikira dengan menolak nilai ramalan daripada nilai yang diperhatikan.
Plot sisa ialah cara terbaik untuk menilai model regresi. Ia adalah graf yang menunjukkan semua baki pada paksi menegak dan ciri pada paksi-x. Jika titik data bertaburan secara rawak pada baris tanpa corak, maka model regresi linear sesuai dengan data dengan baik, jika tidak, kita harus menggunakan model bukan linear.

3. Bagaimana untuk membezakan antara model regresi linear dan model regresi bukan linear?
Kedua-duanya adalah jenis masalah regresi. Perbezaan antara kedua-duanya ialah data mereka dilatih.
Model regresi linear mengandaikan hubungan linear antara ciri dan label, yang bermaksud jika kita mengambil semua titik data dan memplotkannya ke dalam garisan linear (lurus) ia harus sesuai dengan data.
Model regresi bukan linear mengandaikan bahawa tiada hubungan linear antara pembolehubah. Garisan bukan linear (curvilinear) harus memisahkan dan sesuai dengan data dengan betul.
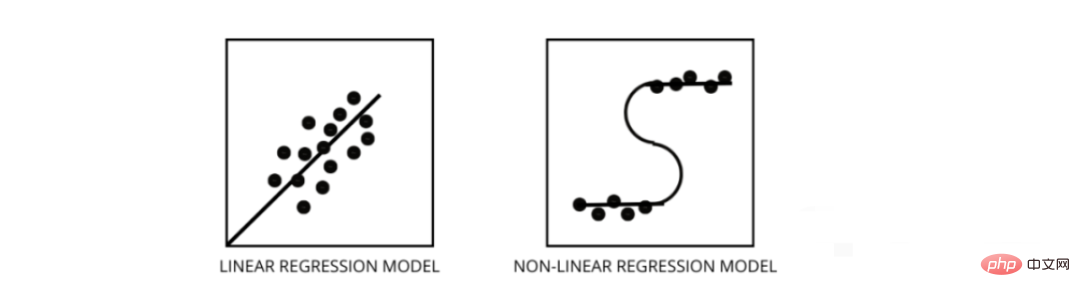
Tiga cara terbaik untuk mengetahui sama ada data anda adalah linear atau bukan linear -
- Plot Baki
- Angka Sebaran
- Dengan mengandaikan data adalah linear, model linear dilatih dan dinilai mengikut ketepatan.
4. Apakah multikolineariti dan bagaimana ia mempengaruhi prestasi model?
Multikolineariti berlaku apabila ciri-ciri tertentu sangat berkorelasi antara satu sama lain. Korelasi merujuk kepada ukuran yang menunjukkan bagaimana satu pembolehubah dipengaruhi oleh perubahan dalam pembolehubah lain.
Jika peningkatan dalam ciri a membawa kepada peningkatan dalam ciri b, maka kedua-dua ciri tersebut berkorelasi secara positif. Jika peningkatan dalam a menyebabkan penurunan dalam ciri b, maka kedua-dua ciri tersebut berkorelasi negatif. Mempunyai dua pembolehubah yang sangat berkorelasi pada data latihan boleh membawa kepada multikolineariti kerana model itu tidak dapat mencari corak dalam data, mengakibatkan prestasi model yang lemah. Oleh itu, sebelum melatih model, kita mesti terlebih dahulu cuba menghapuskan multikolineariti.
5. Bagaimanakah outlier mempengaruhi prestasi model regresi linear?
Outlier ialah titik data yang nilainya berbeza daripada julat purata titik data. Dalam erti kata lain, mata ini berbeza daripada data atau di luar kriteria ke-3.
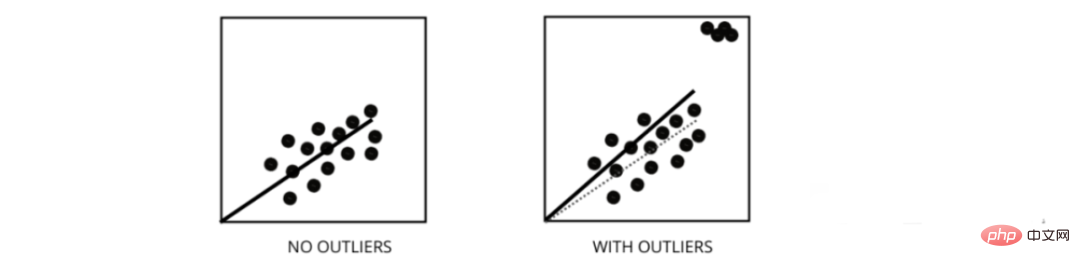
Model regresi linear cuba mencari garisan paling sesuai yang mengurangkan baki. Jika data mengandungi outlier, garisan paling sesuai akan beralih sedikit ke arah outlier, meningkatkan kadar ralat dan menghasilkan model dengan MSE yang sangat tinggi.
6. Apakah perbezaan antara MSE dan MAE?
MSE bermaksud ralat min kuasa dua, iaitu perbezaan kuasa dua antara nilai sebenar dan nilai ramalan. Dan MAE ialah perbezaan mutlak antara nilai sasaran dan nilai ramalan.
MSE menghukum kesilapan besar, MAE tidak. Apabila nilai MSE dan MAE berkurangan, model ini cenderung kepada garisan yang lebih sesuai.
7. Apakah regularisasi L1 dan L2 dan bilakah ia perlu digunakan?
Dalam pembelajaran mesin, matlamat utama kami adalah untuk mencipta model umum yang boleh berprestasi lebih baik pada data latihan dan ujian, tetapi apabila terdapat sangat sedikit data, model regresi linear asas cenderung untuk menyesuaikan diri, jadi kami akan menggunakan penyelarasan l1 dan l2.
Penyaturan L1 atau regresi laso menambah nilai mutlak cerun sebagai istilah penalti dalam fungsi kos. Membantu mengalih keluar outlier dengan mengalih keluar semua titik data dengan nilai cerun kurang daripada ambang.
Penyaturan L2 atau regresi rabung menambah tempoh penalti yang sama dengan kuasa dua saiz pekali. Ia menghukum ciri dengan nilai cerun yang lebih tinggi.
l1 dan l2 berguna apabila terdapat sedikit data latihan, varians yang tinggi, ciri yang diramalkan adalah lebih besar daripada nilai yang diperhatikan dan wujud multikolineariti dalam data.
8. Apakah maksud heteroskedastisitas?
Ia merujuk kepada situasi di mana varians titik data di sekeliling garisan paling sesuai tidak sama dalam julat. Ia mengakibatkan penyebaran sisa yang tidak sekata. Jika ia terdapat dalam data, maka model cenderung untuk meramalkan output tidak sah. Salah satu cara terbaik untuk menguji heteroskedastisitas adalah dengan memplot sisa.
Salah satu punca terbesar heteroskedastisitas dalam data ialah perbezaan besar antara ciri julat. Sebagai contoh, jika kita mempunyai lajur dari 1 hingga 100000, maka meningkatkan nilai sebanyak 10% tidak akan mengubah nilai yang lebih rendah, tetapi akan membuat perbezaan yang sangat besar pada nilai yang lebih tinggi, dengan itu menghasilkan perbezaan titik data yang besar .
9. Apakah peranan faktor inflasi varians?
Faktor inflasi varians (vif) digunakan untuk mengetahui sejauh mana pembolehubah bebas boleh diramal menggunakan pembolehubah bebas yang lain.
Mari kita ambil contoh data dengan ciri v1, v2, v3, v4, v5 dan v6. Sekarang, untuk mengira vif v1, pertimbangkan ia sebagai pembolehubah peramal dan cuba ramalkannya menggunakan semua pembolehubah peramal yang lain.
Jika nilai VIF adalah kecil, lebih baik untuk mengalih keluar pembolehubah daripada data. Kerana nilai yang lebih kecil menunjukkan korelasi yang tinggi antara pembolehubah.
10. Bagaimanakah regresi berperingkat berfungsi
Regresi berperingkat ialah kaedah mencipta model regresi dengan mengalih keluar atau menambah pembolehubah peramal dengan bantuan ujian hipotesis. Ia meramalkan pembolehubah bersandar dengan menguji secara berulang-ulang kepentingan setiap pembolehubah bebas dan mengalih keluar atau menambah beberapa ciri selepas setiap lelaran. Ia berjalan n kali dan cuba mencari gabungan terbaik parameter yang meramalkan pembolehubah bersandar dengan ralat terkecil antara nilai yang diperhatikan dan diramalkan.
Ia boleh mengurus sejumlah besar data dengan sangat cekap dan menyelesaikan masalah dimensi tinggi.
11 Sebagai tambahan kepada MSE dan MAE, adakah terdapat petunjuk regresi penting lain?

Kami menggunakan masalah regresi untuk memperkenalkan penunjuk ini, di mana input kami adalah pengalaman kerja dan output adalah gaji. Graf di bawah menunjukkan garis regresi linear yang dilukis untuk meramalkan gaji.

1 Min ralat mutlak (MAE):

Min ralat mutlak (MAE) ialah ukuran regresi yang paling mudah. . Ia menambah perbezaan antara setiap nilai sebenar dan ramalan dan membahagikannya dengan bilangan pemerhatian. Untuk model regresi dianggap sebagai model yang baik, MAE hendaklah sekecil mungkin.
Kelebihan MAE ialah:
Mudah dan mudah difahami. Hasilnya akan mempunyai unit yang sama dengan output. Sebagai contoh: Jika unit lajur output ialah LPA, maka jika MAE ialah 1.2, maka kita boleh mentafsirkan hasilnya sebagai +1.2LPA atau -1.2LPA, MAE secara relatifnya stabil kepada outlier (berbanding dengan beberapa penunjuk regresi lain, MAE dipengaruhi oleh kesan terpencil kurang).
Kelemahan MAE ialah:
MAE menggunakan fungsi modular, tetapi fungsi modular tidak boleh dibezakan pada semua titik, jadi ia tidak boleh digunakan sebagai fungsi kehilangan dalam banyak kes.
2. Ralat min kuasa dua (MSE):

MSE mengambil perbezaan antara setiap nilai sebenar dan nilai ramalan, kemudian kuasa duakan perbezaan dan menambahnya bersama-sama, akhirnya membahagikan dengan bilangan pemerhatian. Untuk model regresi dianggap sebagai model yang baik, MSE hendaklah sekecil mungkin.
Kelebihan MSE: Fungsi segi empat sama boleh dibezakan di semua titik, jadi ia boleh digunakan sebagai fungsi kehilangan.
Kelemahan MSE: Memandangkan MSE menggunakan fungsi segi empat sama, unit hasilnya ialah kuasa dua keluaran. Oleh itu, sukar untuk mentafsir keputusan. Memandangkan ia menggunakan fungsi segi empat sama, jika terdapat outlier dalam data, perbezaan juga akan menjadi kuasa dua, dan oleh itu, MSE tidak stabil untuk outlier.
3. Ralat purata kuasa dua akar (RMSE):

Ralat purata kuasa dua akar (RMSE) mengambil perbezaan antara setiap nilai sebenar dan nilai ramalan nilai, kemudian kuasa duakan perbezaan dan tambahkannya, dan akhirnya bahagikan dengan bilangan pemerhatian. Kemudian ambil punca kuasa dua hasilnya. Oleh itu, RMSE ialah punca kuasa dua MSE. Untuk model regresi dianggap sebagai model yang baik, RMSE hendaklah sekecil mungkin.
RMSE menyelesaikan masalah MSE, unit akan sama dengan output kerana ia mengambil punca kuasa dua, tetapi masih kurang stabil kepada outlier.
Penunjuk di atas bergantung pada konteks masalah yang kita selesaikan Kita tidak boleh menilai kualiti model dengan hanya melihat nilai MAE, MSE dan RMSE tanpa memahami masalah sebenar.
4. Skor R2:

Jika kita tiada data input, tetapi ingin tahu berapa gaji yang dia boleh dapat dalam syarikat ini, maka kita boleh Perkara terbaik untuk dilakukan ialah memberi mereka purata semua gaji pekerja.

Skor R2 memberikan nilai antara 0 dan 1 dan boleh ditafsirkan untuk sebarang konteks. Ia boleh difahami sebagai kualiti kesesuaian.
SSR ialah jumlah ralat kuasa dua bagi garis regresi, dan SSM ialah jumlah ralat kuasa dua bagi purata bergerak. Kami membandingkan garis regresi dengan garis min.

- Jika skor R2 ialah 0, bermakna model kami mempunyai hasil yang sama dengan purata, jadi model kami perlu diperbaiki.
- Jika skor R2 ialah 1, bahagian kanan persamaan menjadi 0, yang hanya boleh berlaku jika model kami sesuai dengan setiap titik data tanpa ralat.
- Jika skor R2 negatif, ini bermakna bahagian kanan persamaan lebih besar daripada 1, yang boleh berlaku apabila SSR > SSM. Ini bermakna model kami adalah paling teruk daripada purata, bermakna model kami lebih teruk daripada mengambil purata untuk meramalkan
Jika skor R2 model kami ialah 0.8, ini bermakna ia boleh dikatakan bahawa model boleh Menerangkan 80% varians keluaran. Iaitu, 80% daripada variasi gaji boleh dijelaskan oleh input (tahun bekerja), tetapi baki 20% tidak diketahui.
Jika model kami mempunyai 2 ciri, tahun bekerja dan markah temu duga, maka model kami boleh menerangkan 80% daripada perubahan gaji menggunakan dua ciri input ini.
Kelemahan R2:
Apabila bilangan ciri input meningkat, R2 akan cenderung meningkat dengan sewajarnya atau kekal sama, tetapi tidak akan berkurangan, walaupun ciri input tidak berguna untuk kita model penting (cth., menambahkan suhu pada hari temu duga kepada contoh kami, R2 tidak akan berkurangan walaupun suhu tidak penting kepada output).
5. Markah R2 terlaras:
Dalam formula di atas, R2 ialah R2, n ialah bilangan cerapan (baris), dan p ialah bilangan ciri bebas. R2 terlaras menyelesaikan masalah R2.
Apabila kami menambah ciri yang kurang penting untuk model kami, seperti menambah suhu untuk meramalkan gaji.....

Apabila menambah ciri yang penting kepada model, seperti menambah markah temu duga untuk meramal gaji...

Perkara di atas ialah masalah regresi Mata pengetahuan penting dan pengenalan pelbagai petunjuk penting yang digunakan untuk menyelesaikan masalah regresi serta kelebihan dan kekurangannya, saya harap ia akan membantu anda.
Atas ialah kandungan terperinci Ringkasan mata pengetahuan penting yang berkaitan dengan model regresi pembelajaran mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1207
24
52
1207
24

 Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Dalam bidang pembelajaran mesin dan sains data, kebolehtafsiran model sentiasa menjadi tumpuan penyelidik dan pengamal. Dengan aplikasi meluas model yang kompleks seperti kaedah pembelajaran mendalam dan ensemble, memahami proses membuat keputusan model menjadi sangat penting. AI|XAI yang boleh dijelaskan membantu membina kepercayaan dan keyakinan dalam model pembelajaran mesin dengan meningkatkan ketelusan model. Meningkatkan ketelusan model boleh dicapai melalui kaedah seperti penggunaan meluas pelbagai model yang kompleks, serta proses membuat keputusan yang digunakan untuk menerangkan model. Kaedah ini termasuk analisis kepentingan ciri, anggaran selang ramalan model, algoritma kebolehtafsiran tempatan, dsb. Analisis kepentingan ciri boleh menerangkan proses membuat keputusan model dengan menilai tahap pengaruh model ke atas ciri input. Anggaran selang ramalan model
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Melebihi DPO secara menyeluruh: Pasukan Chen Danqi mencadangkan pengoptimuman pilihan mudah SimPO, dan turut memperhalusi model sumber terbuka 8B terkuat
Jun 01, 2024 pm 04:41 PM
Untuk menyelaraskan model bahasa besar (LLM) dengan nilai dan niat manusia, adalah penting untuk mempelajari maklum balas manusia untuk memastikan bahawa ia berguna, jujur dan tidak berbahaya. Dari segi penjajaran LLM, kaedah yang berkesan ialah pembelajaran pengukuhan berdasarkan maklum balas manusia (RLHF). Walaupun keputusan kaedah RLHF adalah cemerlang, terdapat beberapa cabaran pengoptimuman yang terlibat. Ini melibatkan latihan model ganjaran dan kemudian mengoptimumkan model dasar untuk memaksimumkan ganjaran tersebut. Baru-baru ini, beberapa penyelidik telah meneroka algoritma luar talian yang lebih mudah, salah satunya ialah pengoptimuman keutamaan langsung (DPO). DPO mempelajari model dasar secara langsung berdasarkan data keutamaan dengan meparameterkan fungsi ganjaran dalam RLHF, sekali gus menghapuskan keperluan untuk model ganjaran yang jelas. Kaedah ini mudah dan stabil
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Tiada data OpenAI diperlukan, sertai senarai model kod besar! UIUC mengeluarkan StarCoder-15B-Instruct
Jun 13, 2024 pm 01:59 PM
Di barisan hadapan teknologi perisian, kumpulan UIUC Zhang Lingming, bersama penyelidik dari organisasi BigCode, baru-baru ini mengumumkan model kod besar StarCoder2-15B-Instruct. Pencapaian inovatif ini mencapai kejayaan ketara dalam tugas penjanaan kod, berjaya mengatasi CodeLlama-70B-Instruct dan mencapai bahagian atas senarai prestasi penjanaan kod. Keunikan StarCoder2-15B-Instruct terletak pada strategi penjajaran diri yang tulen Keseluruhan proses latihan adalah terbuka, telus, dan sepenuhnya autonomi dan boleh dikawal. Model ini menjana beribu-ribu arahan melalui StarCoder2-15B sebagai tindak balas kepada penalaan halus model asas StarCoder-15B tanpa bergantung pada anotasi manual yang mahal.
 AI yang boleh dijelaskan: Menerangkan model AI/ML yang kompleks
Jun 03, 2024 pm 10:08 PM
AI yang boleh dijelaskan: Menerangkan model AI/ML yang kompleks
Jun 03, 2024 pm 10:08 PM
Penterjemah |. Disemak oleh Li Rui |. Chonglou Model kecerdasan buatan (AI) dan pembelajaran mesin (ML) semakin kompleks hari ini, dan output yang dihasilkan oleh model ini adalah kotak hitam – tidak dapat dijelaskan kepada pihak berkepentingan. AI Boleh Dijelaskan (XAI) bertujuan untuk menyelesaikan masalah ini dengan membolehkan pihak berkepentingan memahami cara model ini berfungsi, memastikan mereka memahami cara model ini sebenarnya membuat keputusan, dan memastikan ketelusan dalam sistem AI, Amanah dan akauntabiliti untuk menyelesaikan masalah ini. Artikel ini meneroka pelbagai teknik kecerdasan buatan (XAI) yang boleh dijelaskan untuk menggambarkan prinsip asasnya. Beberapa sebab mengapa AI boleh dijelaskan adalah penting Kepercayaan dan ketelusan: Untuk sistem AI diterima secara meluas dan dipercayai, pengguna perlu memahami cara keputusan dibuat
 Adakah Flash Attention stabil? Meta dan Harvard mendapati bahawa sisihan berat model mereka berubah-ubah mengikut urutan magnitud
May 30, 2024 pm 01:24 PM
Adakah Flash Attention stabil? Meta dan Harvard mendapati bahawa sisihan berat model mereka berubah-ubah mengikut urutan magnitud
May 30, 2024 pm 01:24 PM
MetaFAIR bekerjasama dengan Harvard untuk menyediakan rangka kerja penyelidikan baharu untuk mengoptimumkan bias data yang dijana apabila pembelajaran mesin berskala besar dilakukan. Adalah diketahui bahawa latihan model bahasa besar sering mengambil masa berbulan-bulan dan menggunakan ratusan atau bahkan ribuan GPU. Mengambil model LLaMA270B sebagai contoh, latihannya memerlukan sejumlah 1,720,320 jam GPU. Melatih model besar memberikan cabaran sistemik yang unik disebabkan oleh skala dan kerumitan beban kerja ini. Baru-baru ini, banyak institusi telah melaporkan ketidakstabilan dalam proses latihan apabila melatih model AI generatif SOTA Mereka biasanya muncul dalam bentuk lonjakan kerugian Contohnya, model PaLM Google mengalami sehingga 20 lonjakan kerugian semasa proses latihan. Bias berangka adalah punca ketidaktepatan latihan ini,
