
 Peranti teknologi
AI
ViP3D: Ramalan trajektori visual hujung ke hujung melalui pertanyaan ejen 3D
Peranti teknologi
AI
ViP3D: Ramalan trajektori visual hujung ke hujung melalui pertanyaan ejen 3D
ViP3D: Ramalan trajektori visual hujung ke hujung melalui pertanyaan ejen 3D

kertas arXiv "ViP3D: Ramalan Trajektori Visual hujung ke hujung melalui Pertanyaan Agen 3D", dimuat naik pada 2, 22 Ogos, Universiti Tsinghua, Shanghai (Yao) Institut Penyelidikan Qizhi, CMU, Fudan, Li Auto dan MIT, dsb. kerja bersama.

Saluran paip pemanduan autonomi sedia ada memisahkan modul persepsi daripada modul ramalan. Kedua-dua modul berkomunikasi melalui ciri yang dipilih secara manual seperti kotak ejen dan trajektori sebagai antara muka. Disebabkan oleh pemisahan ini, modul ramalan hanya menerima sebahagian maklumat daripada modul persepsi. Lebih buruk lagi, ralat daripada modul persepsi boleh merambat dan terkumpul, memberi kesan buruk kepada keputusan ramalan.
Kerja ini mencadangkan ViP3D, saluran paip ramalan trajektori visual yang menggunakan maklumat kaya video asal untuk meramalkan trajektori masa depan ejen dalam tempat kejadian. ViP3D menggunakan pertanyaan ejen yang jarang di seluruh saluran paip, menjadikannya boleh dibezakan sepenuhnya dan boleh ditafsir. Selain itu, indeks penilaian baharu untuk tugas ramalan trajektori visual hujung-ke-hujung dicadangkan, Ketepatan Ramalan Hujung-ke-hujung (EPA, Ketepatan Ramalan Hujung-ke-hujung) , yang mempertimbangkan persepsi secara menyeluruh dan ketepatan ramalan Pada masa yang sama, trajektori yang diramalkan dan trajektori kebenaran tanah dijaringkan.
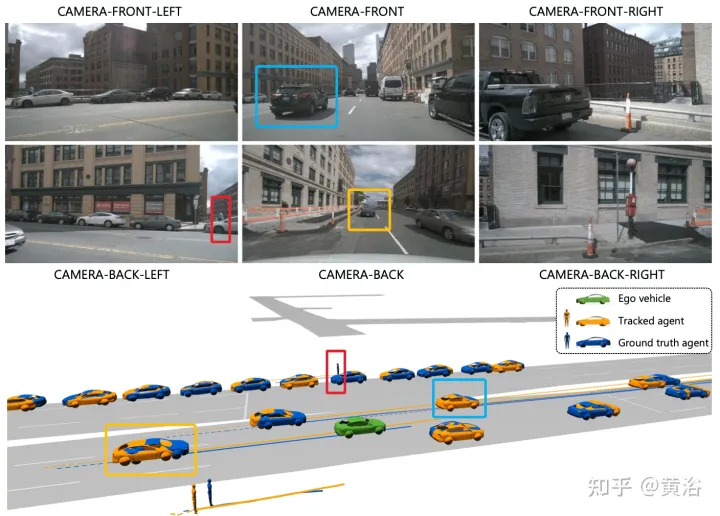
Gambar menunjukkan perbandingan antara saluran paip berbilang langkah tradisional dan ViP3D: saluran paip tradisional melibatkan berbilang modul tidak boleh dibezakan, seperti pengesanan, penjejakan dan ramalan ViP3D mengambil video berbilang tontonan sebagai input, dalam cara hujung ke hujung Menjana trajektori yang diramalkan yang menggunakan maklumat visual secara berkesan, seperti isyarat membelok kenderaan.
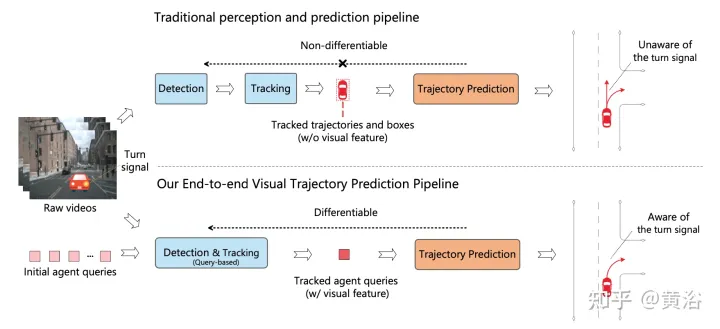
ViP3D bertujuan untuk menyelesaikan masalah ramalan trajektori video asal secara menyeluruh. Khususnya, diberikan video berbilang tontonan dan peta definisi tinggi, ViP3D meramalkan trajektori masa depan semua ejen dalam tempat kejadian.
Proses keseluruhan ViP3D ditunjukkan dalam rajah: Pertama, penjejak berasaskan pertanyaan memproses video berbilang tontonan daripada kamera sekeliling untuk mendapatkan pertanyaan ejen yang dijejaki dengan ciri visual. Ciri visual dalam pertanyaan ejen menangkap dinamik pergerakan dan ciri visual ejen, serta hubungan antara ejen. Selepas itu, peramal trajektori mengambil pertanyaan ejen penjejakan sebagai input, mengaitkannya dengan ciri peta HD, dan akhirnya mengeluarkan trajektori yang diramalkan.
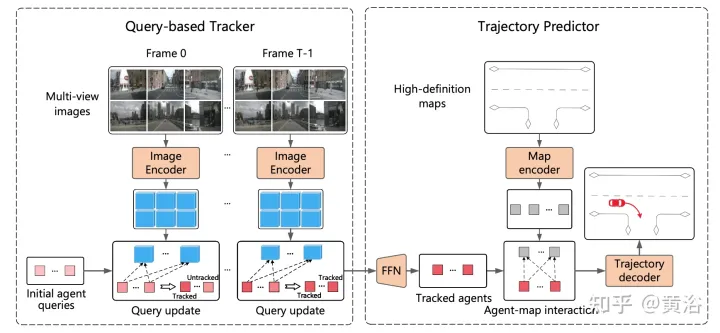
Penjejak berasaskan pertanyaan mengekstrak ciri visual daripada video mentah kamera sekeliling. Khususnya, untuk setiap bingkai, ciri imej diekstrak mengikut DETR3D. Untuk pengagregatan ciri domain masa, penjejak berasaskan pertanyaan direka bentuk mengikut MOTR ("Motr: Penjejakan berbilang objek hujung ke hujung dengan pengubah". arXiv 2105.03247, 2021), termasuk dua langkah utama : kemas kini ciri pertanyaan dan penyeliaan pertanyaan. Pertanyaan ejen akan dikemas kini dari semasa ke semasa untuk memodelkan dinamik pergerakan ejen.
Kebanyakan kaedah ramalan trajektori sedia ada boleh dibahagikan kepada tiga bahagian: pengekodan ejen, pengekodan peta dan penyahkodan trajektori. Selepas penjejakan berasaskan pertanyaan, pertanyaan ejen yang dijejaki diperoleh, yang boleh dianggap sebagai ciri ejen yang diperoleh melalui pengekodan ejen. Oleh itu, tugas yang tinggal ialah pengekodan peta dan penyahkodan trajektori.
Wakilkan ejen ramalan dan kebenaran sebagai set tidak tertib Sˆ dan S, di mana setiap ejen diwakili oleh koordinat ejen langkah masa semasa dan K kemungkinan trajektori masa hadapan. Bagi setiap jenis ejen c, hitung ketepatan ramalan antara Scˆ dan Sc. Takrifkan kos antara ejen ramalan dan ejen sebenar sebagai:

Dengan cara ini, EPA antara Scˆ dan Sc ditakrifkan sebagai:

Keputusan percubaan adalah seperti berikut:
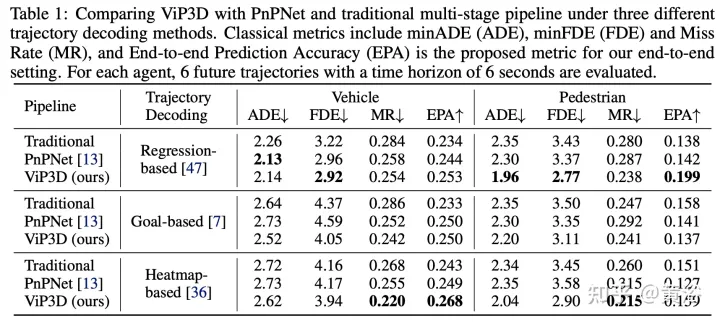
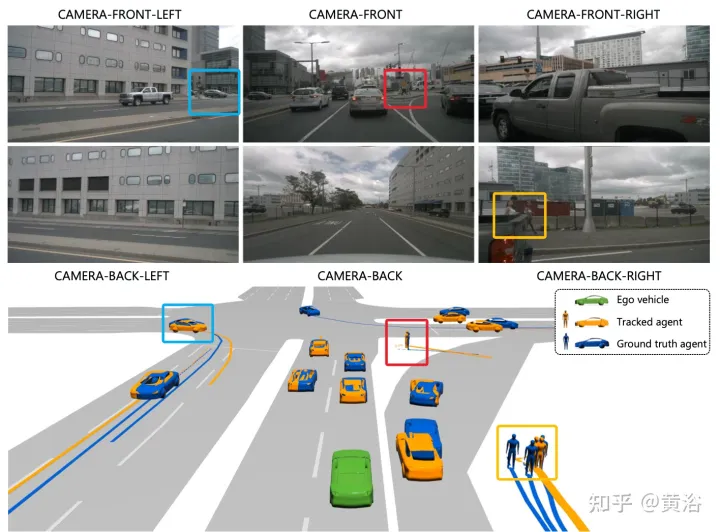
Nota: Ini pemaparan sasaran tidak buruk.
Atas ialah kandungan terperinci ViP3D: Ramalan trajektori visual hujung ke hujung melalui pertanyaan ejen 3D. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Ditulis di atas & pemahaman peribadi pengarang Gaussiansplatting tiga dimensi (3DGS) ialah teknologi transformatif yang telah muncul dalam bidang medan sinaran eksplisit dan grafik komputer dalam beberapa tahun kebelakangan ini. Kaedah inovatif ini dicirikan oleh penggunaan berjuta-juta Gaussians 3D, yang sangat berbeza daripada kaedah medan sinaran saraf (NeRF), yang terutamanya menggunakan model berasaskan koordinat tersirat untuk memetakan koordinat spatial kepada nilai piksel. Dengan perwakilan adegan yang eksplisit dan algoritma pemaparan yang boleh dibezakan, 3DGS bukan sahaja menjamin keupayaan pemaparan masa nyata, tetapi juga memperkenalkan tahap kawalan dan pengeditan adegan yang tidak pernah berlaku sebelum ini. Ini meletakkan 3DGS sebagai penukar permainan yang berpotensi untuk pembinaan semula dan perwakilan 3D generasi akan datang. Untuk tujuan ini, kami menyediakan gambaran keseluruhan sistematik tentang perkembangan dan kebimbangan terkini dalam bidang 3DGS buat kali pertama.
 Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
0. Ditulis di hadapan&& Pemahaman peribadi bahawa sistem pemanduan autonomi bergantung pada persepsi lanjutan, membuat keputusan dan teknologi kawalan, dengan menggunakan pelbagai penderia (seperti kamera, lidar, radar, dll.) untuk melihat persekitaran sekeliling dan menggunakan algoritma dan model untuk analisis masa nyata dan membuat keputusan. Ini membolehkan kenderaan mengenali papan tanda jalan, mengesan dan menjejaki kenderaan lain, meramalkan tingkah laku pejalan kaki, dsb., dengan itu selamat beroperasi dan menyesuaikan diri dengan persekitaran trafik yang kompleks. Teknologi ini kini menarik perhatian meluas dan dianggap sebagai kawasan pembangunan penting dalam pengangkutan masa depan satu. Tetapi apa yang menyukarkan pemanduan autonomi ialah memikirkan cara membuat kereta itu memahami perkara yang berlaku di sekelilingnya. Ini memerlukan algoritma pengesanan objek tiga dimensi dalam sistem pemanduan autonomi boleh melihat dan menerangkan dengan tepat objek dalam persekitaran sekeliling, termasuk lokasinya,
 Ciri-ciri wajah berterbangan, mulut terbuka, mata terbuka, dan kening terangkat AI boleh menirunya dengan sempurna Penipuan video adalah mustahil untuk dicegah.
Dec 14, 2023 pm 11:30 PM
Ciri-ciri wajah berterbangan, mulut terbuka, mata terbuka, dan kening terangkat AI boleh menirunya dengan sempurna Penipuan video adalah mustahil untuk dicegah.
Dec 14, 2023 pm 11:30 PM
Dengan kebolehan tiruan AI yang begitu kuat, ia benar-benar mustahil untuk menghalangnya, sama sekali mustahil untuk menghalangnya. Adakah pembangunan AI mencapai tahap ini sekarang? Kaki hadapan anda membuat ciri-ciri wajah anda terbang, dan pada kaki belakang anda, ekspresi yang sama direproduksi Menatap, mengangkat kening, mencebik, tidak kira betapa berlebihan ekspresi itu, semuanya ditiru dengan sempurna. Tingkatkan kesukaran, angkat kening lebih tinggi, buka mata lebih luas, malah bentuk mulutnya bengkok, dan avatar watak maya dapat menghasilkan semula ekspresi dengan sempurna. Apabila anda melaraskan parameter di sebelah kiri, avatar maya di sebelah kanan juga akan menukar pergerakannya dengan sewajarnya untuk memberikan gambaran dekat mulut dan mata Tiruan itu tidak boleh dikatakan sama, tetapi ungkapan itu betul-betul sama (paling kanan). Penyelidikan ini datang dari institusi seperti Universiti Teknikal Munich, yang mencadangkan GaussianAvatars, yang
 CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
Ditulis di atas & pemahaman peribadi penulis: Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Hanya selepas kenderaan pemanduan autonomi yang memandu di jalan raya memperoleh keputusan persepsi yang tepat melalui modul persepsi boleh Peraturan hiliran dan. modul kawalan dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat. Algoritma persepsi BEV berdasarkan penglihatan tulen digemari oleh industri kerana kos perkakasannya yang rendah dan penggunaan mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran.
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
 MotionLM: Teknologi pemodelan bahasa untuk ramalan gerakan berbilang ejen
Oct 13, 2023 pm 12:09 PM
MotionLM: Teknologi pemodelan bahasa untuk ramalan gerakan berbilang ejen
Oct 13, 2023 pm 12:09 PM
Artikel ini dicetak semula dengan kebenaran daripada akaun awam Autonomous Driving Heart. Sila hubungi sumber untuk mencetak semula. Tajuk asal: MotionLM: Multi-Agent Motion Forecasting as Language Modelling Paper pautan: https://arxiv.org/pdf/2309.16534.pdf Gabungan pengarang: Waymo Conference: ICCV2023 Idea kertas: Untuk perancangan keselamatan kenderaan autonomi, ramalkan tingkah laku masa hadapan dengan pasti ejen jalan raya adalah penting. Kajian ini mewakili trajektori berterusan sebagai jujukan token gerakan diskret dan menganggap ramalan gerakan berbilang agen sebagai tugas pemodelan bahasa. Model yang kami cadangkan, MotionLM, mempunyai kelebihan berikut: Pertama
 LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
May 09, 2024 pm 04:55 PM
Ditulis di atas & pemahaman peribadi pengarang: Kertas kerja ini didedikasikan untuk menyelesaikan cabaran utama model bahasa besar multimodal semasa (MLLM) dalam aplikasi pemanduan autonomi, iaitu masalah melanjutkan MLLM daripada pemahaman 2D kepada ruang 3D. Peluasan ini amat penting kerana kenderaan autonomi (AV) perlu membuat keputusan yang tepat tentang persekitaran 3D. Pemahaman spatial 3D adalah penting untuk AV kerana ia memberi kesan langsung kepada keupayaan kenderaan untuk membuat keputusan termaklum, meramalkan keadaan masa depan dan berinteraksi dengan selamat dengan alam sekitar. Model bahasa besar berbilang mod semasa (seperti LLaVA-1.5) selalunya hanya boleh mengendalikan input imej resolusi rendah (cth.) disebabkan oleh had resolusi pengekod visual, had panjang jujukan LLM. Walau bagaimanapun, aplikasi pemanduan autonomi memerlukan
 Mempelajari pengetahuan penghunian rentas mod: RadOcc menggunakan teknologi penyulingan berbantukan pemaparan
Jan 25, 2024 am 11:36 AM
Mempelajari pengetahuan penghunian rentas mod: RadOcc menggunakan teknologi penyulingan berbantukan pemaparan
Jan 25, 2024 am 11:36 AM
Tajuk asal: Radocc: LearningCross-ModalityOccupancyKnowledge throughRenderingAssistedDistillation Paper pautan: https://arxiv.org/pdf/2312.11829.pdf Unit pengarang: FNii, CUHK-ShenzhenSSE, CUHK-Shenzhen Huawei Noah's Arkiv Paper 20 ialah Persidangan Precision AAAI2cy Paper 302:D tugas baru muncul yang bertujuan untuk menganggarkan keadaan penghunian dan semantik adegan 3D menggunakan imej berbilang paparan. Walau bagaimanapun, disebabkan kekurangan prior geometri, senario berasaskan imej
