


Tetamu: Lu Mian
Organisasi: Warna Dakwat
6-7 Ogos 2022, AISummit Global Artificial Intelligence The technical persidangan telah diadakan seperti yang dijadualkan. Pada mesyuarat itu, Lu Mian, arkitek sistem 4Paradigm dan ketua R&D OpenMLDB, memberikan ucaptama bertajuk "Pangkalan Data Pembelajaran Mesin Sumber Terbuka OpenMLDB: Platform Ciri Tahap Pengeluaran Dalam Talian dan Luar Talian yang Konsisten", memfokuskan pada data dan cabaran ciri buatan. pelaksanaan kejuruteraan perisikan , platform pengiraan ciri peringkat pengeluaran OpenMLDB yang konsisten dalam talian dan luar talian, OpenMLDB v0.5: peningkatan prestasi, kos dan kemudahan penggunaan dikongsi dalam tiga aspek.
Kandungan ucapan kini disusun seperti berikut, dengan harapan dapat memberi inspirasi kepada anda.
Hari ini, menurut statistik, 95% masa dalam pelaksanaan kecerdasan buatan dibelanjakan untuk data. Walaupun terdapat pelbagai alat data seperti MySQL di pasaran, mereka masih jauh daripada menyelesaikan masalah pelaksanaan kecerdasan buatan. Jadi, mari kita lihat dahulu isu data.
Jika anda telah mengambil bahagian dalam beberapa pembangunan aplikasi pembelajaran mesin, anda seharusnya amat kagum dengan MLOps, seperti yang ditunjukkan dalam rajah di bawah:
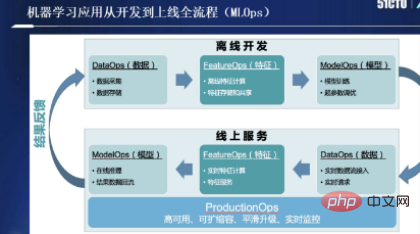
Malah, tiada pemahaman semasa MLOps Tiada definisi akademik yang ketat, dan ia boleh dibahagikan kepada dua proses: pembangunan luar talian dan perkhidmatan dalam talian. Pembawa maklumat dalam setiap proses, daripada data, ciri, kepada model, akan melalui tiga pembawa berbeza, daripada proses pembangunan luar talian kepada proses perkhidmatan dalam talian.
Seterusnya kami menumpukan pada proses ciri perantaraan untuk memahami cara menyelesaikan cabaran yang dihadapi.
Terdapat dua kategori aplikasi utama dalam pembangunan kecerdasan buatan Satu ialah jenis persepsi, seperti wajah biasa pengiktirafan, dsb. Semuanya adalah aplikasi AI berasaskan persepsi, yang pada asasnya berdasarkan algoritma DNN. Jenis lain ialah senario AI membuat keputusan, seperti pengesyoran diperibadikan untuk membeli-belah Taobao. Selain itu, terdapat beberapa senario seperti senario kawalan risiko dan senario anti-penipuan di mana AI digunakan secara meluas dalam membuat keputusan.
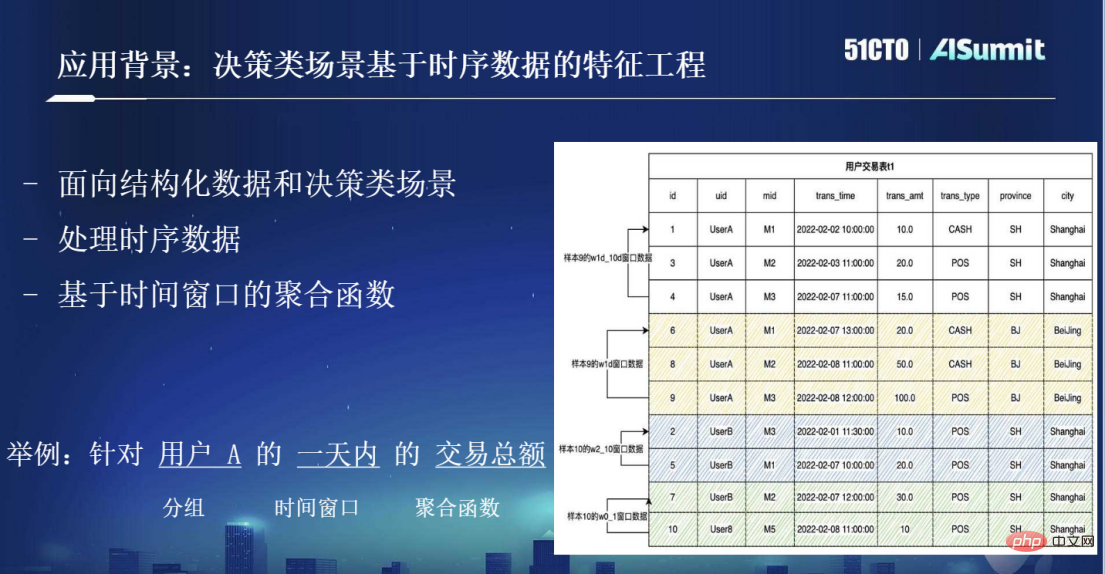
Oleh itu, latar belakang aplikasi yang kita bicarakan sekarang adalah untuk senario membuat keputusan jenis ini Salah satu ciri terbesar ialah datanya adalah data berstruktur dalam jadual dua dimensi, dan ia juga begitu data siri masa. Seperti yang ditunjukkan dalam rajah di bawah, terdapat "masa trans" pada jadual transaksi pengguna, yang mewakili titik masa di mana setiap rekod berlaku Apabila disambungkan, ia adalah data siri masa. Salah satu kaedah pemprosesan yang paling biasa untuk kejuruteraan ciri berdasarkan data siri masa ialah fungsi pengagregatan berdasarkan tetingkap masa. Contohnya, menyasarkan jumlah urus niaga pengguna dalam sehari, dsb. Ini ialah operasi biasa kejuruteraan ciri dalam senario membuat keputusan.
Mengapa kita perlu menggunakan OpenMLDB sekarang? Latar belakang yang sangat besar ialah menggunakan pengkomputeran masa nyata yang keras untuk memenuhi keperluan AI.
Apakah pengkomputeran masa nyata yang sukar? Ia mempunyai dua makna Satu merujuk kepada menggunakan data masa nyata yang paling segar untuk mencapai kesan perniagaan membuat keputusan yang paling hebat. Sebagai contoh, anda perlu menggunakan gelagat klik pengguna dalam 10 saat atau 1 minit yang lalu untuk membuat keputusan perniagaan, bukannya data dari tahun lalu atau tahun sebelumnya.
Satu lagi perkara yang sangat penting ialah untuk pengiraan masa nyata, sebaik sahaja pengguna mengeluarkan permintaan tingkah laku, pengiraan ciri perlu dilakukan dalam masa yang singkat atau bahkan pada tahap milisaat.
Terdapat banyak produk di pasaran untuk pengkomputeran kelompok/penstriman, tetapi produk tersebut masih belum mencapai keperluan pengkomputeran masa nyata keras peringkat milisaat.
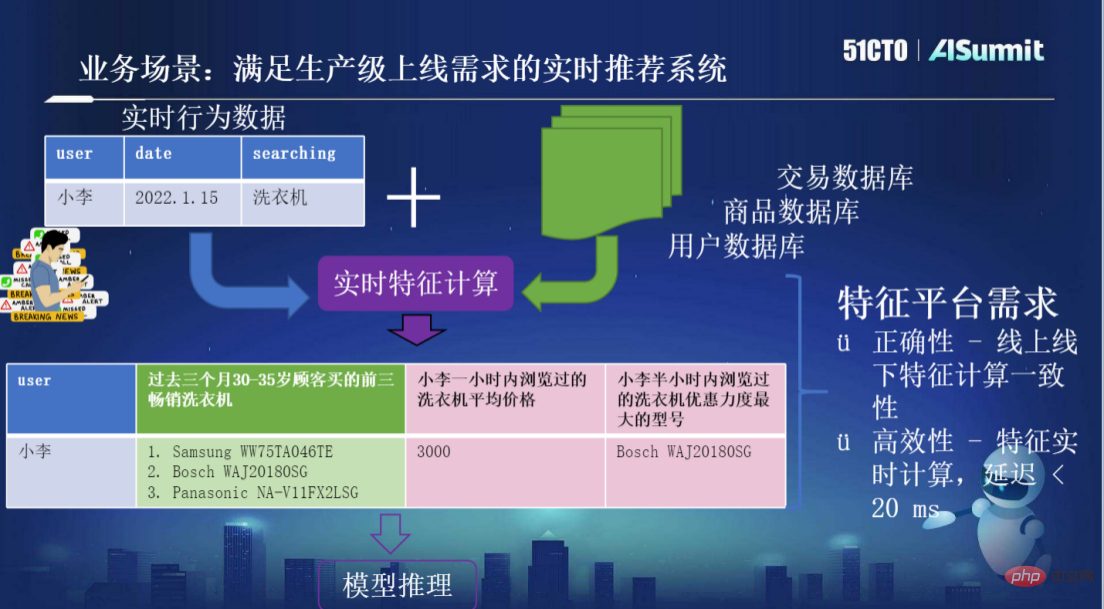
Sebagai contoh, seperti yang ditunjukkan dalam rajah di bawah untuk membina sistem pengesyoran masa nyata yang memenuhi keperluan dalam talian peringkat pengeluaran, pengguna Xiao Li melakukan carian dengan kata kunci "mesin basuh." Dia perlu meletakkan permintaan asal data serta pengguna, produk dan urus niaga dalam sistem Data maklumat digabungkan untuk pengiraan ciri masa nyata, dan kemudian beberapa ciri yang lebih bermakna dijana, iaitu kejuruteraan ciri yang dipanggil, proses penjanaan ciri. Sebagai contoh, sistem akan menjana "tiga mesin basuh terlaris yang dibeli oleh pelanggan kumpulan umur tertentu dalam tempoh tiga bulan lalu Ciri jenis ini tidak memerlukan ketepatan masa yang kukuh dan dikira berdasarkan data sejarah yang lebih panjang." Walau bagaimanapun, sistem juga mungkin memerlukan beberapa data yang sangat sensitif masa, seperti "rekod menyemak imbas dalam masa sejam/setengah jam lalu", dsb. Selepas sistem memperoleh ciri yang baru dikira, ia akan menyediakan model untuk inferens. Terdapat dua keperluan utama untuk platform ciri sistem sedemikian Satu ialah ketepatan, iaitu, ketekalan pengiraan ciri dalam talian dan luar talian adalah kecekapan, iaitu, pengiraan ciri masa nyata, kelewatan
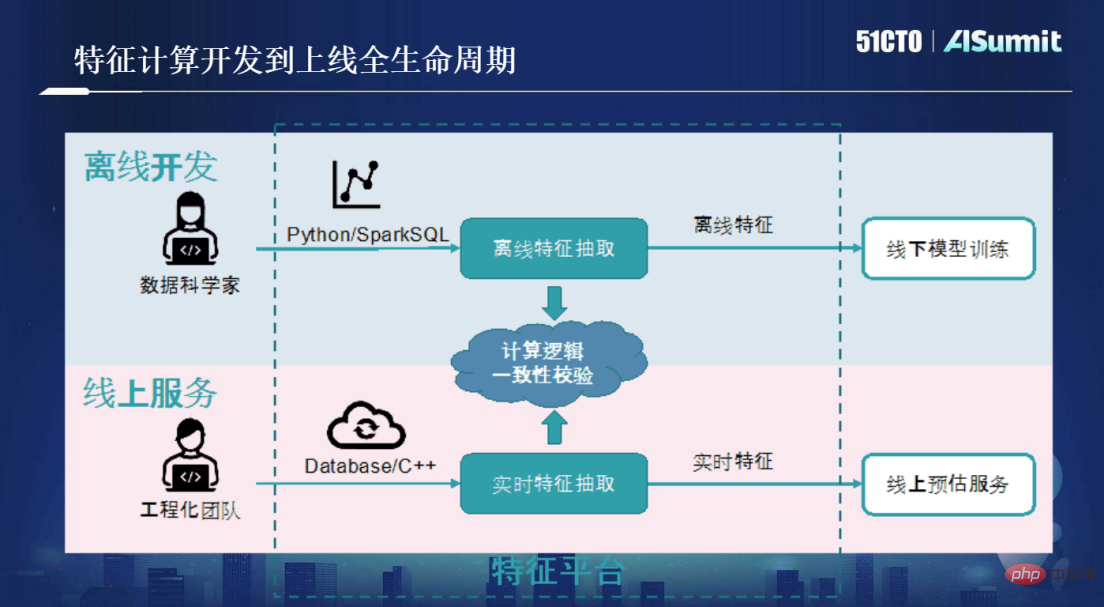
Sebelum terdapat metodologi OpenMLDB, semua orang menggunakan proses yang ditunjukkan dalam rajah di bawah untuk pembangunan pengiraan ciri.
Mula-mula kita perlu melakukan senario di mana saintis data akan menggunakan alat Python/SparkSQL untuk pengekstrakan ciri luar talian. KPI saintis data adalah untuk membina model keperluan perniagaan yang memenuhi ketepatan Apabila kualiti model mencapai standard, tugas itu selesai. Cabaran kejuruteraan yang dihadapi oleh skrip ciri selepas mereka pergi ke dalam talian, seperti kependaman rendah, keselarasan tinggi dan ketersediaan tinggi, bukan dalam bidang kuasa saintis.
Untuk meletakkan skrip Python yang ditulis oleh saintis data dalam talian, pasukan kejuruteraan perlu masuk. Semua yang perlu mereka lakukan ialah menukar data Skrip luar talian yang dicipta oleh saintis telah dibina semula dan dioptimumkan, dan C++/Pangkalan Data digunakan untuk perkhidmatan pengekstrakan ciri masa nyata. Ini memenuhi satu siri keperluan kejuruteraan untuk kependaman rendah, konkurensi tinggi dan ketersediaan tinggi, membolehkan skrip ciri benar-benar pergi ke dalam talian untuk perkhidmatan dalam talian.
Proses ini sangat mahal dan memerlukan campur tangan dua set pasukan kemahiran, dan mereka menggunakan alatan yang berbeza. Selepas dua set proses selesai, ketekalan logik pengiraan perlu diperiksa Iaitu, logik pengiraan skrip ciri yang dibangunkan oleh saintis data mestilah konsisten sepenuhnya dengan logik pengekstrakan ciri masa nyata akhir. . Keperluan ini kelihatan jelas dan mudah, tetapi ia akan memperkenalkan banyak kos komunikasi, kos ujian dan kos pembangunan berulang semasa proses pengesahan konsisten. Mengikut pengalaman lepas, lebih besar projek, lebih lama pengesahan konsisten akan mengambil masa dan kos akan menjadi sangat tinggi.
Secara umumnya, sebab utama ketidakkonsistenan antara dalam talian dan luar talian semasa proses pengesahan konsisten ialah alatan pembangunan tidak konsisten. Contohnya, saintis menggunakan Python , dan pasukan kejuruteraan Pangkalan data digunakan, dan perbezaan dalam keupayaan alat boleh membawa kepada kompromi dan ketidakkonsistenan fungsian juga terdapat jurang dalam definisi data, algoritma dan kognisi.
Ringkasnya, kos pembangunan berdasarkan dua set proses tradisional adalah sangat tinggi, memerlukan dua set pembangun dari stesen kemahiran yang berbeza dan pembangunan dan operasi daripada dua set sistem Ia juga perlu untuk menambah pengesahan bertindan, pengesahan, dsb.
Dan OpenMLDB menyediakan penyelesaian sumber terbuka kos rendah.
Pada bulan Jun tahun lalu, OpenMLDB secara rasminya adalah sumber terbuka dan ialah pemain muda dalam projek sumber terbuka, tetapi telah dilaksanakan dalam lebih daripada 100 senario, meliputi lebih daripada 300 nod.
OpenMLDB ialah pangkalan data pembelajaran mesin sumber terbuka Fungsi utamanya adalah untuk menyediakan platform ciri dalam talian dan luar talian yang konsisten. Jadi bagaimanakah OpenMLDB memenuhi keperluan prestasi tinggi dan ketepatan?
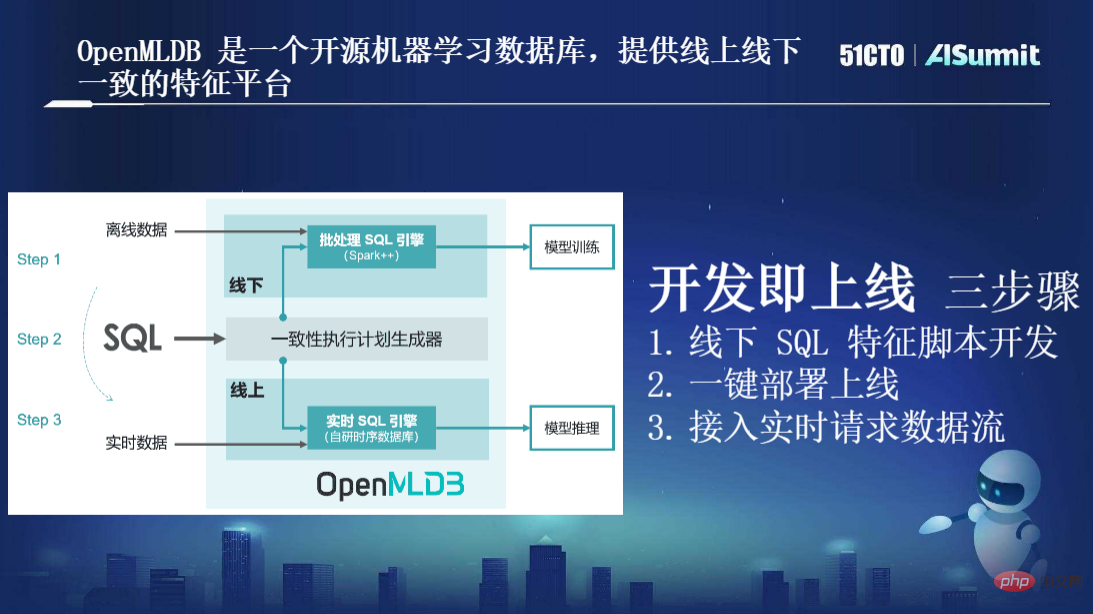
Seperti yang ditunjukkan dalam gambar di atas, pertama sekali, satu-satunya bahasa pengaturcaraan yang digunakan oleh OpenMLDB ialah SQL tiada lagi dua set rantai alat Kedua-dua saintis data dan pembangun menggunakan SQL untuk menyatakan ciri.
Kedua, dua set enjin dipisahkan dalam OpenMLDB Satu ialah "enjin SQL kelompok", yang dioptimumkan pada tahap kod sumber berdasarkan Spark++, menyediakan kaedah pengkomputeran berprestasi tinggi dan membuat pengembangan sintaks. . Set lain ialah "enjin SQL masa nyata", yang merupakan pangkalan data siri masa sumber yang dibangunkan sendiri oleh pasukan kami. Berdasarkan "enjin SQL masa nyata", kami boleh mencapai pengiraan masa nyata peringkat milisaat yang cekap dalam talian, sambil memastikan ketersediaan tinggi, kependaman rendah dan serentak tinggi.
Terdapat juga "penjana pelan pelaksanaan konsisten" yang penting antara kedua-dua enjin ini, yang direka untuk memastikan ketekalan logik pelan pelaksanaan dalam talian dan luar talian. Dengan itu, konsistensi dalam talian dan luar talian boleh dijamin secara semula jadi tanpa memerlukan pembacaan pruf manual.
Ringkasnya, berdasarkan seni bina ini, matlamat utama kami adalah untuk mencapai matlamat pengoptimuman "pembangunan dan dalam talian", yang terutamanya merangkumi tiga langkah: pembangunan skrip ciri SQL luar talian satu-; klik penempatan dan dalam talian ; Akses aliran data permintaan masa nyata.
Dapat dilihat bahawa berbanding dengan dua set proses sebelumnya, dua set rantai alat dan dua set pelaburan pemaju, kelebihan terbesar set enjin ini ialah ia menjimatkan banyak kos kejuruteraan, iaitu, selagi saintis data menggunakan SQL untuk membangunkan skrip ciri, mereka tidak lagi memerlukan pasukan kejuruteraan untuk melakukan pengoptimuman pusingan kedua, dan mereka boleh pergi dalam talian secara langsung operasi manual pengesahan konsisten dalam talian dan luar talian, yang menjimatkan banyak masa dan kos.
Rajah berikut menunjukkan proses lengkap OpenMLDB daripada pembangunan luar talian kepada perkhidmatan dalam talian:
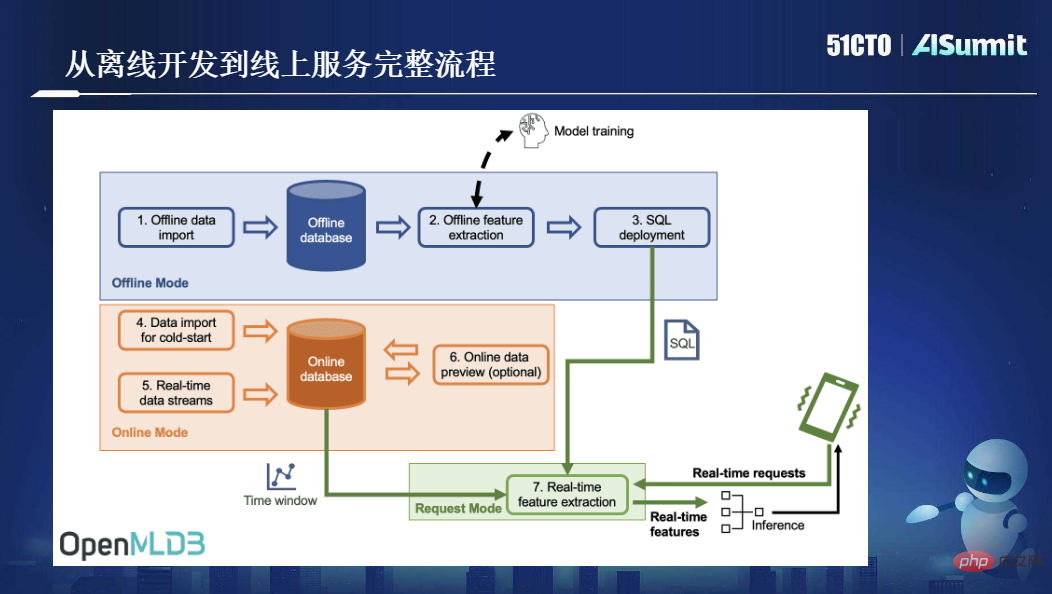
Secara keseluruhan, OpenMLDB menyelesaikan masalah teras - konsistensi pembelajaran mesin dalam talian dan luar talian dan menyediakan ciri teras - pengiraan ciri masa nyata peringkat milisaat. Kedua-dua mata ini adalah nilai teras yang disediakan oleh OpenMLDB.
Oleh kerana OpenMLDB mempunyai dua set enjin, dalam talian dan luar talian, kaedah aplikasi juga berbeza. Rajah berikut menunjukkan kaedah kami yang disyorkan untuk rujukan:

Seterusnya, kami akan memperkenalkan beberapa komponen teras dalam ciri OpenMLDB Or:
Ciri 1, enjin pelaksanaan konsisten dalam talian dan luar talian, berdasarkan fungsi pengkomputeran asas yang bersatu, pelarasan adaptif mod pelaksanaan dalam talian dan luar talian daripada pelan logik kepada pelan fizikal, sekali gus menjadikan Dalam talian dan luar talian konsistensi dijamin secara semula jadi.
Ciri dua, enjin pengiraan ciri dalam talian berprestasi tinggi, termasuk struktur data indeks memori jadual lompat dua lapisan berprestasi tinggi bagi pengiraan masa nyata + teknologi pra-pengagregatan; ; menyediakan kedua-dua memori/cakera Pelbagai enjin storan untuk memenuhi keperluan prestasi dan kos yang berbeza.
Ciri tiga, enjin pengkomputeran luar talian yang dioptimumkan untuk pengiraan ciri, termasuk pengoptimuman pengiraan condong data berbilang tetingkap; Ini semua menghasilkan peningkatan yang ketara dalam prestasi berbanding versi komuniti.
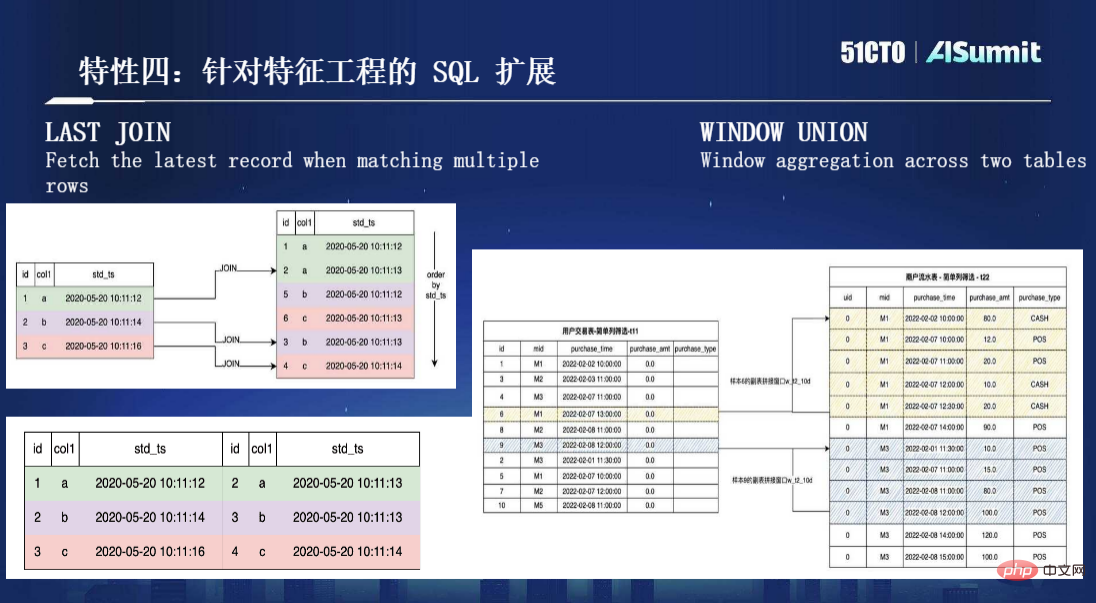
Ciri 4, sambungan SQL untuk kejuruteraan ciri. Seperti yang dinyatakan sebelum ini, kami menggunakan SQL untuk definisi ciri, tetapi sebenarnya SQL tidak direka untuk pengiraan ciri Oleh itu, selepas mengkaji sejumlah besar kes dan mengumpul pengalaman penggunaan, kami mendapati bahawa adalah perlu untuk membuat beberapa sambungan kepada sintaks SQL. untuk menjadikannya lebih baik mengendalikan pengiraan ciri. Terdapat dua sambungan penting di sini, satu ialah LAST JOIN dan satu lagi ialah WINDOW UNION yang lebih biasa digunakan, seperti yang ditunjukkan dalam rajah di bawah:
Ciri lima, sokongan ciri peringkat perusahaan. Sebagai pangkalan data yang diedarkan, OpenMLDB mempunyai ciri-ciri ketersediaan tinggi, pengembangan dan pengecutan yang lancar, dan peningkatan yang lancar, dan telah dilaksanakan dalam banyak kes perusahaan.
Ciri 6: Pembangunan dan pengurusan dengan SQL sebagai teras OpenMLDB juga merupakan pengurusan pangkalan data Sebagai contoh, jika CLI disediakan, maka OpenMLDB boleh digunakan dalam keseluruhan CLI Keseluruhan proses dilaksanakan di dalamnya, daripada pengiraan ciri luar talian, penyelesaian SQL dalam talian kepada permintaan dalam talian, dsb., yang boleh memberikan pengalaman pembangunan proses penuh berdasarkan SQL dan CLI.
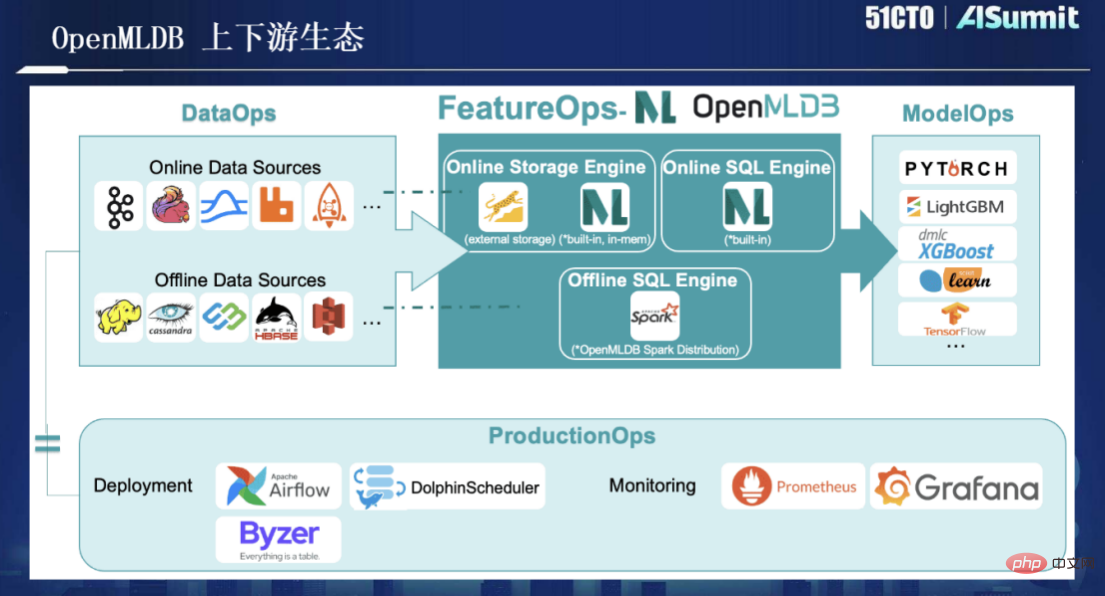
Selain itu, OpenMLDB kini merupakan sumber terbuka, dan pengembangan ekologi huluan dan hilirannya adalah seperti yang ditunjukkan dalam rajah di bawah:
Seterusnya, mari perkenalkan Versi baharu OpenMLDB v0.5, kami telah membuat beberapa peningkatan dalam tiga aspek.
Pertama, mari kita lihat sejarah pembangunan OpenMLDB. Pada Jun 2021, OpenMLDB adalah sumber terbuka Malah, ia sudah mempunyai ramai pelanggan sebelum itu, dan ia telah mula membangunkan baris pertama kod pada 2017. Ia telah menjadi empat atau lima tahun pengumpulan teknologi.
Dalam ulang tahun pertama selepas sumber terbuka, kami mengulang kira-kira lima versi. Berbanding dengan versi sebelumnya, v0.5.0 mempunyai ciri penting berikut:
Peningkatan prestasi, teknologi pengagregatan boleh meningkatkan prestasi tetingkap panjang dengan ketara. Pengoptimuman pra-pengagregatan meningkatkan prestasi dengan dua urutan magnitud dari segi kependaman dan pemprosesan di bawah pertanyaan tetingkap panjang.
Pengurangan kos, bermula dari versi v0.5.0, enjin dalam talian menyediakan dua pilihan enjin berdasarkan memori dan memori luaran. Berdasarkan ingatan, kependaman rendah dan konkurensi tinggi; memberikan tindak balas kependaman peringkat milisaat pada kos penggunaan yang lebih tinggi. Berdasarkan memori luaran, ia kurang sensitif terhadap prestasi menggunakan pelaksanaan kos rendah, kos boleh dikurangkan sebanyak 75% di bawah konfigurasi biasa berdasarkan SSD. Kod perniagaan lapisan atas kedua-dua enjin tidak dapat dilihat dan boleh ditukar pada kos sifar.
Kemudahan penggunaan yang dipertingkatkan. Kami memperkenalkan fungsi takrif pengguna (UDF) dalam versi v0.5.0, yang bermaksud bahawa jika SQL tidak dapat memenuhi ungkapan logik pengekstrakan ciri anda, fungsi takrif pengguna, seperti C/C++ UDF, pendaftaran dinamik UDF, dll., disokong untuk memudahkan pengguna.
Akhir sekali, terima kasih kepada semua pembangun OpenMLDB Sejak sumber terbuka, hampir 100 penyumbang telah membuat sumbangan kod dalam komuniti kami Pada masa yang sama, kami juga mengalu-alukan lebih ramai pembangun untuk menyertai. Komuniti, sumbangkan kekuatan anda sendiri dan lakukan perkara yang lebih bermakna bersama-sama.
Tayangan ulang ucapan persidangan dan PPT dalam talian, masukkan Tapak web rasmi Lihat kandungan yang menarik.
Atas ialah kandungan terperinci Ketua R&D OpenMLDB Lu Mian, arkitek sistem Paradigma Keempat: Pangkalan data pembelajaran mesin sumber terbuka OpenMLDB: platform ciri peringkat pengeluaran yang konsisten dalam talian dan luar talian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Aplikasi kecerdasan buatan dalam kehidupan
Aplikasi kecerdasan buatan dalam kehidupan
 Apakah konsep asas kecerdasan buatan
Apakah konsep asas kecerdasan buatan
 Tutorial PHP
Tutorial PHP
 Apakah perpustakaan kecerdasan buatan python?
Apakah perpustakaan kecerdasan buatan python?
 Bagaimana untuk membuat halaman web dalam python
Bagaimana untuk membuat halaman web dalam python
 Semak ruang cakera dalam linux
Semak ruang cakera dalam linux
 Batalkan kempen WeChat
Batalkan kempen WeChat
 Bagaimana untuk mengimport telefon lama ke telefon baru dari telefon bimbit Huawei
Bagaimana untuk mengimport telefon lama ke telefon baru dari telefon bimbit Huawei
 Konsep m2m dalam Internet Perkara
Konsep m2m dalam Internet Perkara








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



