
 Peranti teknologi
AI
Pembelajaran pengukuhan mendalam menangani pemanduan autonomi dunia sebenar
Peranti teknologi
AI
Pembelajaran pengukuhan mendalam menangani pemanduan autonomi dunia sebenar
Pembelajaran pengukuhan mendalam menangani pemanduan autonomi dunia sebenar

Kertas arXiv "Tackling Real-World Autonomous Driving using Deep Reinforcement Learning" telah dimuat naik pada 5 Julai 2022. Pengarangnya adalah dari Vislab dari Universiti Parma di Itali dan Ambarella (pemerolehan Vislab).

Dalam barisan pemasangan pemanduan autonomi biasa, sistem kawalan mewakili dua komponen paling kritikal, di mana data yang diambil oleh penderia dan data yang diproses oleh algoritma persepsi digunakan untuk mencapai keselamatan Tingkah laku memandu sendiri yang selesa. Khususnya, modul perancangan meramalkan laluan yang perlu diikuti oleh kereta pandu sendiri untuk melakukan tindakan peringkat tinggi yang betul, manakala sistem kawalan melakukan satu siri tindakan peringkat rendah, mengawal stereng, pendikit dan brek.
Kerja ini mencadangkan perancang Pembelajaran Pengukuhan Dalam (DRL) tanpa model untuk melatih rangkaian saraf untuk meramalkan pecutan dan sudut stereng, dengan itu memperoleh data autonomi yang didorong oleh kedudukan kereta dan algoritma persepsi mengeluarkan data yang didorong oleh modul individu kenderaan. Khususnya, sistem yang telah disimulasikan dan dilatih sepenuhnya boleh memandu dengan lancar dan selamat dalam persekitaran bebas halangan simulasi dan sebenar (kawasan bandar Palma), membuktikan bahawa sistem itu mempunyai keupayaan generalisasi yang baik dan juga boleh memandu dalam persekitaran selain daripada senario latihan. Di samping itu, untuk menggunakan sistem pada kenderaan autonomi sebenar dan mengurangkan jurang antara prestasi simulasi dan prestasi sebenar, penulis juga membangunkan modul yang diwakili oleh rangkaian neural kecil yang mampu menghasilkan semula tingkah laku persekitaran sebenar semasa latihan simulasi Tingkah laku dinamik kereta.
Sejak beberapa dekad yang lalu, kemajuan besar telah dicapai dalam meningkatkan tahap automasi kenderaan, daripada pendekatan mudah berasaskan peraturan kepada melaksanakan sistem pintar berasaskan AI. Khususnya, sistem ini bertujuan untuk menangani batasan utama pendekatan berasaskan peraturan, iaitu kekurangan rundingan dan interaksi dengan pengguna jalan raya lain dan pemahaman yang lemah tentang dinamika adegan.
Pembelajaran Pengukuhan (RL) digunakan secara meluas untuk menyelesaikan tugasan yang menggunakan output ruang kawalan diskret, seperti Go, permainan Atari atau catur, serta pemanduan autonomi dalam ruang kawalan berterusan. Khususnya, algoritma RL digunakan secara meluas dalam bidang pemanduan autonomi untuk membangunkan sistem perlaksanaan membuat keputusan dan manuver, seperti pertukaran lorong aktif, menjaga lorong, manuver memotong, persimpangan dan pemprosesan bulatan, dsb.
Artikel ini menggunakan versi tertunda D-A3C, yang tergolong dalam keluarga algoritma Actor-Critics yang dipanggil. Khususnya terdiri daripada dua entiti berbeza: Pelakon dan Pengkritik. Tujuan Pelakon adalah untuk memilih tindakan yang perlu dilakukan oleh ejen, manakala Pengkritik menganggarkan fungsi nilai keadaan, iaitu, sejauh mana keadaan khusus ejen itu. Dalam erti kata lain, Pelakon ialah taburan kebarangkalian π(a|s; θπ) ke atas tindakan (di mana θ ialah parameter rangkaian), dan pengkritik adalah anggaran fungsi nilai keadaan v(st; θv) = E(Rt|st), di mana R ialah Pulangan yang dijangkakan.
Peta definisi tinggi yang dibangunkan secara dalaman melaksanakan simulator simulasi; contoh adegan ditunjukkan dalam Rajah a, yang merupakan sebahagian daripada kawasan peta sistem ujian kereta pandu sendiri, manakala Rajah B menunjukkan pandangan sekeliling yang dilihat oleh ejen, Sesuai dengan kawasan seluas 50 × 50 meter, ia dibahagikan kepada empat saluran: halangan (Rajah c), ruang boleh dipandu (Rajah d), laluan yang harus diikuti oleh ejen ( Rajah e) dan garisan berhenti (Rajah f). Peta definisi tinggi dalam simulator membolehkan mendapatkan beberapa maklumat tentang persekitaran luaran, seperti lokasi atau bilangan lorong, had laju jalan raya, dsb.
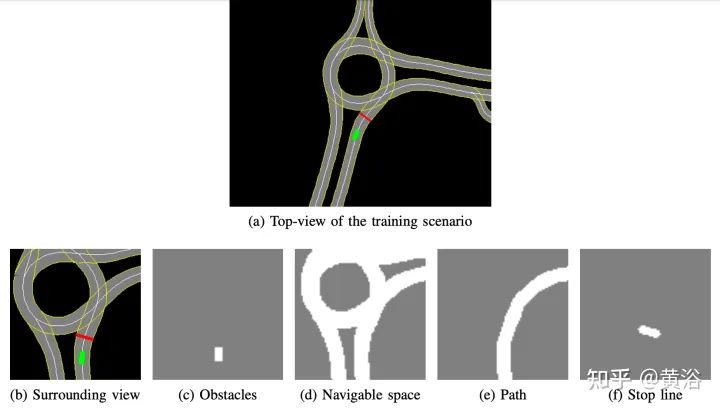
Memfokuskan pada mencapai gaya pemanduan yang lancar dan selamat, jadi ejen dilatih dalam adegan statik, tidak termasuk halangan atau pengguna jalan raya lain, belajar mengikut laluan dan mematuhi had laju .
Gunakan rangkaian saraf seperti yang ditunjukkan dalam rajah untuk melatih ejen dan meramalkan sudut stereng dan pecutan setiap 100 milisaat. Ia dibahagikan kepada dua sub-modul: sub-modul pertama boleh menentukan sudut stereng sa, dan sub-modul kedua digunakan untuk menentukan acc pecutan. Input kepada dua submodul ini diwakili oleh 4 saluran (ruang pandu, laluan, halangan dan garisan henti), sepadan dengan pandangan sekeliling ejen. Setiap saluran input visual mengandungi empat imej 84×84 piksel untuk memberikan ejen sejarah keadaan lalu. Bersama-sama dengan input visual ini, rangkaian menerima 5 parameter skalar, termasuk kelajuan sasaran (had kelajuan jalan raya), kelajuan semasa ejen, nisbah kelajuan sasaran kelajuan semasa dan tindakan terakhir yang berkaitan dengan sudut stereng dan pecutan.
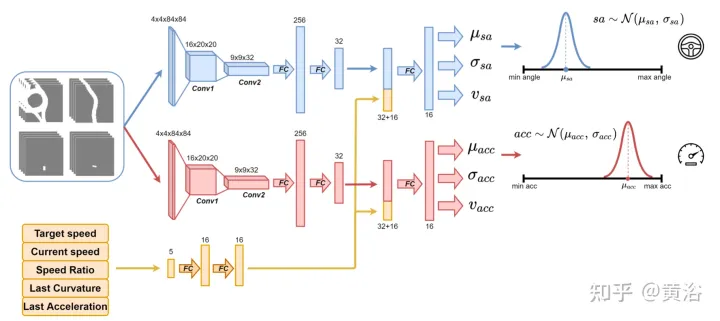
Untuk memastikan penerokaan, dua taburan Gaussian digunakan untuk sampel keluaran dua sub-modul untuk mendapatkan pecutan relatif (acc=N (μacc, σacc) ) dan Sudut stereng (sa=N(μsa,σsa)). Sisihan piawai σacc dan σsa diramalkan dan dimodulasi oleh rangkaian saraf semasa fasa latihan untuk menganggarkan ketidakpastian model. Di samping itu, rangkaian menggunakan dua fungsi ganjaran berbeza R-acc-t dan R-sa-t, masing-masing berkaitan dengan pecutan dan sudut stereng, untuk menjana anggaran nilai keadaan yang sepadan (vacc dan vsa).
Rangkaian saraf dilatih pada empat adegan di bandar Palma. Untuk setiap senario, berbilang kejadian dibuat dan ejen adalah bebas antara satu sama lain pada kejadian ini. Setiap ejen mengikut model basikal kinematik, dengan sudut stereng [-0.2, +0.2] dan pecutan [-2.0 m, +2.0 m]. Pada permulaan segmen, setiap ejen mula memandu pada kelajuan rawak ([0.0, 8.0]) dan mengikut laluan yang dimaksudkan, mematuhi had laju jalan. Had laju jalan raya di kawasan bandar ini berjulat dari 4 ms hingga 8.3 ms.
Akhir sekali, memandangkan tiada halangan dalam adegan latihan, klip boleh berakhir di salah satu keadaan terminal berikut:
- Matlamat dicapai : Ejen mencapai lokasi sasaran akhir.
- Memandu di luar jalan: Ejen melangkaui laluan yang dimaksudkan dan tersilap meramal sudut stereng.
- Masa Sudah Tamat: Masa untuk melengkapkan serpihan tamat; ini terutamanya disebabkan oleh ramalan berhati-hati terhadap keluaran pecutan semasa memandu di bawah had laju jalan.
Untuk mendapatkan strategi yang boleh memandu kereta dengan jayanya dalam persekitaran simulasi dan sebenar, pembentukan ganjaran adalah penting untuk mencapai tingkah laku yang diingini. Khususnya, dua fungsi ganjaran berbeza ditakrifkan untuk menilai kedua-dua tindakan masing-masing: R-acc-t dan R-sa-t masing-masing berkaitan dengan pecutan dan sudut stereng, ditakrifkan seperti berikut:
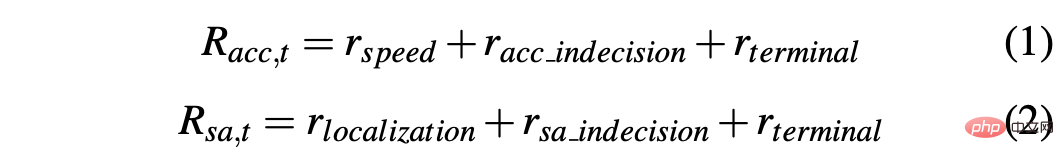
di mana
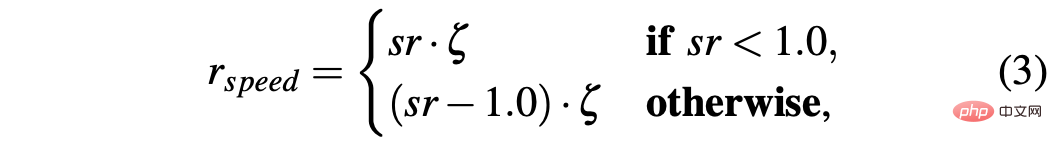
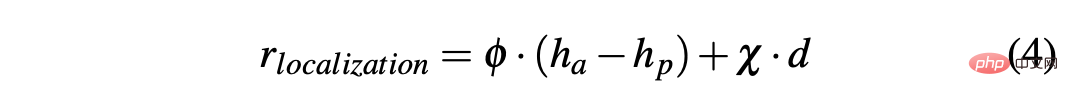
R-sa-t dan R-acc-t kedua-duanya mempunyai unsur dalam formula Penalize dua tindakan berturut-turut yang perbezaan dalam pecutan dan sudut stereng adalah lebih besar daripada ambang tertentu δacc dan δsa masing-masing. Khususnya, perbezaan antara dua pecutan berturut-turut dikira seperti berikut: Δacc=| acc (t) − acc (t− 1) | , manakala rac_indecision ditakrifkan seperti berikut:
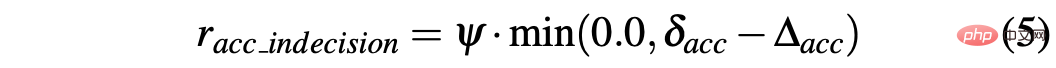
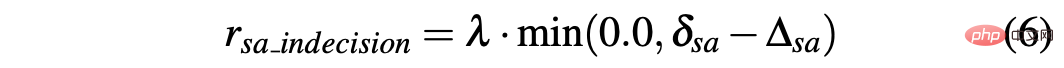
- Matlamat dicapai: Ejen mencapai kedudukan matlamat, jadi kedua-duanya memberi ganjaran rterminal ditetapkan kepada +1.0;
- Memandu di luar jalan: Ejen menyimpang dari laluannya, terutamanya disebabkan oleh ramalan sudut stereng yang tidak tepat. Oleh itu, tetapkan isyarat negatif -1.0 kepada Rsa,t dan isyarat negatif 0.0 kepada R-acc-t; ramalan pecutan terlalu berhati-hati; oleh itu, rterminal menganggap −1.0 untuk R-acc-t dan 0.0 untuk R-sa-t.
- Salah satu masalah utama yang dikaitkan dengan simulator ialah perbezaan antara data simulasi dan sebenar, yang disebabkan oleh kesukaran untuk menghasilkan semula situasi dunia sebenar dalam simulator secara realistik. Untuk mengatasi masalah ini, simulator sintetik digunakan untuk memudahkan input kepada rangkaian saraf dan mengurangkan jurang antara data simulasi dan sebenar. Malah, maklumat yang terkandung dalam 4 saluran (halangan, ruang memandu, laluan dan garisan henti) sebagai input kepada rangkaian saraf boleh dihasilkan semula dengan mudah oleh algoritma persepsi dan penyetempatan dan peta definisi tinggi yang dibenamkan pada kenderaan autonomi sebenar.
Malah, titik pecutan dan sudut stereng yang dipratetap oleh rangkaian saraf bukanlah arahan yang boleh dilaksanakan, dan tidak mengambil kira beberapa faktor, seperti inersia sistem, kelewatan penggerak dan faktor bukan ideal yang lain. Oleh itu, untuk menghasilkan semula dinamik kenderaan sebenar secara realistik yang mungkin, model yang terdiri daripada rangkaian saraf kecil yang terdiri daripada 3 lapisan bersambung sepenuhnya (tindak balas mendalam) telah dibangunkan. Graf kelakuan tindak balas kedalaman ditunjukkan sebagai garis putus-putus merah dalam rajah di atas Ia boleh diperhatikan bahawa ia sangat serupa dengan lengkung oren yang mewakili kereta autonomi sebenar. Memandangkan adegan latihan tidak mempunyai halangan dan kenderaan lalu lintas, masalah yang diterangkan adalah lebih ketara untuk aktiviti sudut stereng, tetapi idea yang sama telah digunakan untuk output pecutan.
Latih model tindak balas mendalam menggunakan set data yang dikumpulkan pada kereta pandu sendiri, di mana input sepadan dengan arahan yang diberikan kepada kenderaan oleh pemandu manusia (tekanan pemecut dan pusingan stereng) dan output sepadan dengan pendikit, brek dan lentur kenderaan, boleh diukur menggunakan GPS, odometer atau teknologi lain. Dengan cara ini, membenamkan model sedemikian dalam simulator menghasilkan sistem yang lebih berskala yang menghasilkan semula gelagat kenderaan autonomi. Oleh itu modul tindak balas kedalaman adalah penting untuk pembetulan sudut stereng, tetapi walaupun dalam cara yang kurang jelas, ia adalah perlu untuk pecutan, dan ini akan menjadi jelas kelihatan dengan pengenalan halangan.
Dua strategi berbeza telah diuji pada data sebenar untuk mengesahkan kesan model tindak balas mendalam pada sistem. Selepas itu, sahkan bahawa kenderaan mengikut laluan dengan betul dan mematuhi had laju yang diperoleh daripada peta HD. Akhir sekali, terbukti bahawa pra-latihan rangkaian saraf melalui Pembelajaran Peniruan boleh mengurangkan jumlah masa latihan dengan ketara.
Strateginya adalah seperti berikut:
- Strategi 1: Jangan gunakan model tindak balas dalam untuk latihan, tetapi gunakan penapis laluan rendah untuk mensimulasikan tindak balas kenderaan sebenar kepada tindakan sasaran.
- Strategi 2: Pastikan dinamik yang lebih realistik dengan memperkenalkan model tindak balas yang mendalam untuk latihan.
Ujian yang dilakukan dalam simulasi menghasilkan keputusan yang baik untuk kedua-dua strategi. Malah, sama ada dalam adegan terlatih atau kawasan peta yang tidak terlatih, ejen boleh mencapai matlamat dengan tingkah laku yang lancar dan selamat 100% pada setiap masa.
Dengan menguji strategi dalam senario sebenar, keputusan yang berbeza diperolehi. Strategi 1 tidak boleh mengendalikan dinamik kenderaan dan melakukan tindakan yang diramalkan secara berbeza daripada ejen dalam simulasi dengan cara ini, Strategi 1 akan melihat keadaan ramalannya yang tidak dijangka, yang membawa kepada tingkah laku bising pada kenderaan autonomi dan tingkah laku yang tidak selesa.
Tingkah laku ini juga menjejaskan kebolehpercayaan sistem, dan sebenarnya, bantuan manusia kadangkala diperlukan untuk mengelakkan kereta pandu sendiri lari dari jalan.
Sebaliknya, dalam semua ujian dunia sebenar bagi kereta pandu sendiri, Strategi 2 tidak memerlukan manusia untuk mengambil alih, mengetahui dinamik kenderaan dan cara sistem akan berkembang untuk meramalkan tindakan. Satu-satunya situasi yang memerlukan campur tangan manusia adalah untuk mengelakkan pengguna jalan raya yang lain, bagaimanapun, situasi ini tidak dianggap sebagai kegagalan kerana kedua-dua strategi 1 dan 2 dilatih dalam senario bebas halangan.
Untuk lebih memahami perbezaan antara Strategi 1 dan Strategi 2, berikut ialah sudut stereng yang diramalkan oleh rangkaian saraf dan jarak ke lorong tengah dalam tetingkap pendek ujian dunia sebenar. Dapat diperhatikan bahawa kedua-dua strategi berkelakuan berbeza sama sekali .
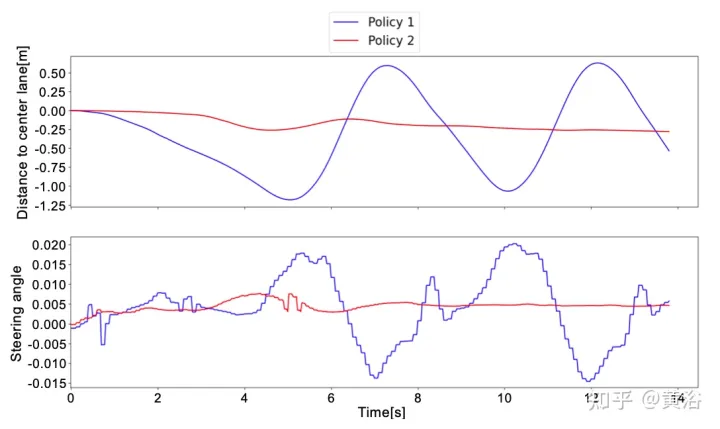
Untuk mengatasi had RL, yang memerlukan berjuta-juta segmen untuk mencapai penyelesaian optimum, pra-latihan dilakukan melalui Pembelajaran Tiruan (IL). Tambahan pula, walaupun trend dalam IL adalah untuk melatih model besar, rangkaian saraf kecil yang sama (~1 juta parameter) digunakan, kerana ideanya adalah untuk meneruskan latihan sistem menggunakan rangka kerja RL untuk memastikan lebih banyak keteguhan dan keupayaan generalisasi. Dengan cara ini, penggunaan sumber perkakasan tidak meningkat, yang penting memandangkan kemungkinan latihan berbilang ejen pada masa hadapan.
Data data yang digunakan dalam fasa latihan IL dijana oleh ejen simulasi yang mengikut pendekatan berasaskan peraturan untuk pergerakan. Khususnya, untuk lenturan, algoritma penjejakan pengejaran tulen digunakan, di mana ejen bertujuan untuk bergerak di sepanjang titik laluan tertentu. Sebaliknya, gunakan model IDM untuk mengawal pecutan membujur ejen.
Untuk mencipta set data, ejen berasaskan peraturan telah dialihkan ke atas empat senario latihan, menyimpan parameter skalar dan empat input visual setiap 100 milisaat. Sebaliknya, output diberikan oleh algoritma pengejaran tulen dan model IDM.
Dua kawalan mendatar dan menegak yang sepadan dengan output hanya mewakili tupel (μacc, μsa). Oleh itu, semasa fasa latihan IL, nilai sisihan piawai (σacc, σsa) tidak dianggarkan, begitu juga fungsi nilai (vacc, vsa) dianggarkan. Ciri-ciri ini dan modul tindak balas mendalam dipelajari dalam fasa latihan IL+RL.
Seperti yang ditunjukkan dalam rajah, ia menunjukkan latihan rangkaian saraf yang sama bermula dari peringkat pra-latihan (lengkung biru, IL+RL), dan membandingkannya dengan RL (lengkung merah, RL tulen) mengakibatkan empat kes. Walaupun latihan IL+RL memerlukan lebih sedikit masa daripada RL tulen dan arah alirannya lebih stabil, kedua-dua kaedah mencapai kadar kejayaan yang baik (Rajah a).
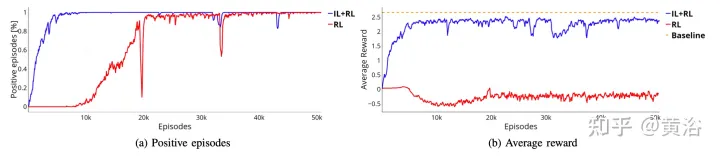
Tambahan pula, keluk ganjaran yang ditunjukkan dalam Rajah b membuktikan bahawa polisi yang diperoleh menggunakan pendekatan RL tulen (lengkung merah) tidak mencapai penyelesaian yang boleh diterima untuk lebih banyak masa latihan, manakala IL+ The Strategi RL mencapai penyelesaian optimum dalam beberapa segmen (lengkung biru dalam panel b). Dalam kes ini, penyelesaian optimum diwakili oleh garis putus-putus oren. Garis dasar ini mewakili purata ganjaran yang diperoleh oleh ejen simulasi yang melaksanakan 50,000 segmen merentas 4 senario. Ejen simulasi mengikut peraturan deterministik, yang sama seperti yang digunakan untuk mengumpul set data pra-latihan IL, iaitu, peraturan mengejar tulen digunakan untuk lenturan dan peraturan IDM digunakan untuk pecutan membujur. Jurang antara kedua-dua pendekatan mungkin lebih ketara, sistem latihan untuk melakukan manuver yang lebih kompleks di mana interaksi kecerdasan-badan mungkin diperlukan.
Atas ialah kandungan terperinci Pembelajaran pengukuhan mendalam menangani pemanduan autonomi dunia sebenar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Mengapakah Gaussian Splatting begitu popular dalam pemanduan autonomi sehingga NeRF mula ditinggalkan?
Jan 17, 2024 pm 02:57 PM
Ditulis di atas & pemahaman peribadi pengarang Gaussiansplatting tiga dimensi (3DGS) ialah teknologi transformatif yang telah muncul dalam bidang medan sinaran eksplisit dan grafik komputer dalam beberapa tahun kebelakangan ini. Kaedah inovatif ini dicirikan oleh penggunaan berjuta-juta Gaussians 3D, yang sangat berbeza daripada kaedah medan sinaran saraf (NeRF), yang terutamanya menggunakan model berasaskan koordinat tersirat untuk memetakan koordinat spatial kepada nilai piksel. Dengan perwakilan adegan yang eksplisit dan algoritma pemaparan yang boleh dibezakan, 3DGS bukan sahaja menjamin keupayaan pemaparan masa nyata, tetapi juga memperkenalkan tahap kawalan dan pengeditan adegan yang tidak pernah berlaku sebelum ini. Ini meletakkan 3DGS sebagai penukar permainan yang berpotensi untuk pembinaan semula dan perwakilan 3D generasi akan datang. Untuk tujuan ini, kami menyediakan gambaran keseluruhan sistematik tentang perkembangan dan kebimbangan terkini dalam bidang 3DGS buat kali pertama.
 Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Semalam semasa temu bual, saya telah ditanya sama ada saya telah membuat sebarang soalan berkaitan ekor panjang, jadi saya fikir saya akan memberikan ringkasan ringkas. Masalah ekor panjang pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi, iaitu, kemungkinan senario dengan kebarangkalian yang rendah untuk berlaku. Masalah ekor panjang yang dirasakan adalah salah satu sebab utama yang kini mengehadkan domain reka bentuk pengendalian kenderaan autonomi pintar satu kenderaan. Seni bina asas dan kebanyakan isu teknikal pemanduan autonomi telah diselesaikan, dan baki 5% masalah ekor panjang secara beransur-ansur menjadi kunci untuk menyekat pembangunan pemanduan autonomi. Masalah ini termasuk pelbagai senario yang berpecah-belah, situasi yang melampau dan tingkah laku manusia yang tidak dapat diramalkan. "Ekor panjang" senario tepi dalam pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi (AVs) kes Edge adalah senario yang mungkin dengan kebarangkalian yang rendah untuk berlaku. kejadian yang jarang berlaku ini
 Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
Pilih kamera atau lidar? Kajian terbaru tentang mencapai pengesanan objek 3D yang mantap
Jan 26, 2024 am 11:18 AM
0. Ditulis di hadapan&& Pemahaman peribadi bahawa sistem pemanduan autonomi bergantung pada persepsi lanjutan, membuat keputusan dan teknologi kawalan, dengan menggunakan pelbagai penderia (seperti kamera, lidar, radar, dll.) untuk melihat persekitaran sekeliling dan menggunakan algoritma dan model untuk analisis masa nyata dan membuat keputusan. Ini membolehkan kenderaan mengenali papan tanda jalan, mengesan dan menjejaki kenderaan lain, meramalkan tingkah laku pejalan kaki, dsb., dengan itu selamat beroperasi dan menyesuaikan diri dengan persekitaran trafik yang kompleks. Teknologi ini kini menarik perhatian meluas dan dianggap sebagai kawasan pembangunan penting dalam pengangkutan masa depan satu. Tetapi apa yang menyukarkan pemanduan autonomi ialah memikirkan cara membuat kereta itu memahami perkara yang berlaku di sekelilingnya. Ini memerlukan algoritma pengesanan objek tiga dimensi dalam sistem pemanduan autonomi boleh melihat dan menerangkan dengan tepat objek dalam persekitaran sekeliling, termasuk lokasinya,
 Adakah anda benar-benar menguasai penukaran sistem koordinat? Isu berbilang sensor yang tidak dapat dipisahkan daripada pemanduan autonomi
Oct 12, 2023 am 11:21 AM
Adakah anda benar-benar menguasai penukaran sistem koordinat? Isu berbilang sensor yang tidak dapat dipisahkan daripada pemanduan autonomi
Oct 12, 2023 am 11:21 AM
Artikel perintis dan utama pertama terutamanya memperkenalkan beberapa sistem koordinat yang biasa digunakan dalam teknologi pemanduan autonomi, dan cara melengkapkan korelasi dan penukaran antara mereka, dan akhirnya membina model persekitaran bersatu. Fokus di sini adalah untuk memahami penukaran daripada kenderaan kepada badan tegar kamera (parameter luaran), penukaran kamera kepada imej (parameter dalaman) dan penukaran unit imej kepada piksel. Penukaran daripada 3D kepada 2D akan mempunyai herotan, terjemahan, dsb. Perkara utama: Sistem koordinat kenderaan dan sistem koordinat badan kamera perlu ditulis semula: sistem koordinat satah dan sistem koordinat piksel Kesukaran: herotan imej mesti dipertimbangkan Kedua-dua penyahherotan dan penambahan herotan diberi pampasan pada satah imej. 2. Pengenalan Terdapat empat sistem penglihatan secara keseluruhannya: sistem koordinat satah piksel (u, v), sistem koordinat imej (x, y), sistem koordinat kamera () dan sistem koordinat dunia (). Terdapat hubungan antara setiap sistem koordinat,
 Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Ramalan trajektori memainkan peranan penting dalam pemanduan autonomi Ramalan trajektori pemanduan autonomi merujuk kepada meramalkan trajektori pemanduan masa hadapan kenderaan dengan menganalisis pelbagai data semasa proses pemanduan kenderaan. Sebagai modul teras pemanduan autonomi, kualiti ramalan trajektori adalah penting untuk kawalan perancangan hiliran. Tugas ramalan trajektori mempunyai timbunan teknologi yang kaya dan memerlukan kebiasaan dengan persepsi dinamik/statik pemanduan autonomi, peta ketepatan tinggi, garisan lorong, kemahiran seni bina rangkaian saraf (CNN&GNN&Transformer), dll. Sangat sukar untuk bermula! Ramai peminat berharap untuk memulakan ramalan trajektori secepat mungkin dan mengelakkan perangkap Hari ini saya akan mengambil kira beberapa masalah biasa dan kaedah pembelajaran pengenalan untuk ramalan trajektori! Pengetahuan berkaitan pengenalan 1. Adakah kertas pratonton teratur? A: Tengok survey dulu, hlm
 Isu reka bentuk fungsi ganjaran dalam pembelajaran pengukuhan
Oct 09, 2023 am 11:58 AM
Isu reka bentuk fungsi ganjaran dalam pembelajaran pengukuhan
Oct 09, 2023 am 11:58 AM
Isu reka bentuk fungsi ganjaran dalam pembelajaran peneguhan Pengenalan Pembelajaran peneguhan ialah kaedah yang mempelajari strategi optimum melalui interaksi antara ejen dan persekitaran. Dalam pembelajaran pengukuhan, reka bentuk fungsi ganjaran adalah penting untuk kesan pembelajaran ejen. Artikel ini akan meneroka isu reka bentuk fungsi ganjaran dalam pembelajaran pengukuhan dan memberikan contoh kod khusus. Peranan fungsi ganjaran dan fungsi ganjaran sasaran merupakan bahagian penting dalam pembelajaran peneguhan dan digunakan untuk menilai nilai ganjaran yang diperolehi oleh ejen dalam keadaan tertentu. Reka bentuknya membantu membimbing ejen untuk memaksimumkan keletihan jangka panjang dengan memilih tindakan yang optimum.
 SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
Tajuk asal: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper pautan: https://arxiv.org/pdf/2402.02519.pdf Pautan kod: https://github.com/HKUST-Aerial-Robotics/SIMPL Unit pengarang: Universiti Sains Hong Kong dan Teknologi Idea Kertas DJI: Kertas kerja ini mencadangkan garis dasar ramalan pergerakan (SIMPL) yang mudah dan cekap untuk kenderaan autonomi. Berbanding dengan agen-sen tradisional
 Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Pada bulan lalu, atas sebab-sebab yang diketahui umum, saya telah mengadakan pertukaran yang sangat intensif dengan pelbagai guru dan rakan sekelas dalam industri. Topik yang tidak dapat dielakkan dalam pertukaran secara semula jadi adalah hujung ke hujung dan Tesla FSDV12 yang popular. Saya ingin mengambil kesempatan ini untuk menyelesaikan beberapa buah fikiran dan pendapat saya pada masa ini untuk rujukan dan perbincangan anda. Bagaimana untuk mentakrifkan sistem pemanduan autonomi hujung ke hujung, dan apakah masalah yang sepatutnya dijangka diselesaikan hujung ke hujung? Menurut definisi yang paling tradisional, sistem hujung ke hujung merujuk kepada sistem yang memasukkan maklumat mentah daripada penderia dan secara langsung mengeluarkan pembolehubah yang membimbangkan tugas. Sebagai contoh, dalam pengecaman imej, CNN boleh dipanggil hujung-ke-hujung berbanding kaedah pengekstrak ciri + pengelas tradisional. Dalam tugas pemanduan autonomi, masukkan data daripada pelbagai penderia (kamera/LiDAR
