
 Peranti teknologi
AI
Seni bina dalam terkini untuk pengesanan sasaran mempunyai separuh parameter dan 3 kali lebih pantas +
Peranti teknologi
AI
Seni bina dalam terkini untuk pengesanan sasaran mempunyai separuh parameter dan 3 kali lebih pantas +
Seni bina dalam terkini untuk pengesanan sasaran mempunyai separuh parameter dan 3 kali lebih pantas +

Pengenalan ringkas
Pengarang penyelidikan mencadangkan Matrix Net (xNet), seni bina dalam baharu untuk pengesanan objek. xNets memetakan objek dengan dimensi saiz dan nisbah bidang yang berbeza ke dalam lapisan rangkaian, di mana objek hampir seragam dalam saiz dan nisbah bidang dalam lapisan. Oleh itu, xNets menyediakan seni bina sedar saiz dan nisbah aspek. Penyelidik menggunakan xNets untuk meningkatkan pengesanan sasaran berasaskan titik kunci. Seni bina baharu mencapai kecekapan masa yang lebih tinggi daripada pengesan satu tangkapan lain, dengan 47.8 mAP pada set data MS COCO, sambil menggunakan separuh parameter dan menjadi 3 kali lebih pantas untuk melatih daripada rangka kerja terbaik seterusnya.
Paparan hasil mudah

Seperti yang ditunjukkan dalam rajah di atas, parameter dan kecekapan xNet jauh melebihi model lain. Antaranya, FSAF mempunyai kesan terbaik dalam kalangan pengesan berasaskan sauh, mengatasi RetinaNet klasik. Model yang dicadangkan oleh penyelidik mengatasi semua seni bina satu pukulan lain dengan bilangan parameter yang sama.
Latar belakang dan situasi semasa
Pengesanan objek ialah salah satu tugas yang paling banyak dikaji dalam penglihatan komputer, dengan banyak aplikasi untuk tugas penglihatan lain, seperti penjejakan objek, contohnya pembahagian dan kapsyen imej. Struktur pengesanan objek boleh dibahagikan kepada dua kategori: pengesan pukulan tunggal dan pengesan dua peringkat. Pengesan dua peringkat menggunakan rangkaian cadangan rantau untuk mencari bilangan calon objek yang tetap, dan kemudian menggunakan rangkaian kedua untuk meramalkan markah setiap calon dan menambah baik kotak sempadannya.
Algoritma Dua peringkat Biasa

Pengesan tangkapan tunggal juga boleh dibahagikan kepada dua kategori: pengesan berasaskan sauh dan titik kunci pengesan berasaskan. Pengesan berasaskan anchor mengandungi banyak kotak pembatas anchor dan kemudian meramalkan offset dan kelas setiap templat. Seni bina berasaskan anchor yang paling terkenal ialah RetinaNet, yang mencadangkan fungsi kehilangan fokus untuk membantu membetulkan ketidakseimbangan kelas kotak pembatas anchor. Pengesan berasaskan sauh berprestasi terbaik ialah FSAF. FSAF menyepadukan output berasaskan sauh dengan kepala output tanpa sauh untuk meningkatkan lagi prestasi.
Sebaliknya, pengesan berasaskan titik kekunci meramalkan peta haba untuk penjuru kiri atas dan bawah kanan dan memadankannya menggunakan pembenaman ciri. Pengesan berasaskan titik kekunci asal ialah CornerNet, yang menggunakan lapisan pengumpulan koener khas untuk mengesan objek dengan saiz yang berbeza dengan tepat. Sejak itu, Centerne telah menambah baik seni bina CornerNet dengan meramalkan pusat dan sudut objek.
Jaring Matriks
Rajah di bawah menunjukkan jaring Matriks (xNets), yang menggunakan matriks hierarki untuk memodelkan sasaran dengan saiz yang berbeza dan nisbah melintang plexus, di mana dalam matriks Setiap entri i, j daripada mewakili lapisan li,j Lebar di sudut kiri atas matriks l1,1 diturunkan sampel oleh 2^(i-1), dan ketinggian dikurangkan oleh 2^(j-1). Lapisan pepenjuru ialah lapisan segi empat sama dengan saiz yang berbeza, bersamaan dengan FPN, manakala lapisan luar pepenjuru ialah lapisan segi empat tepat (ini unik untuk xNets). Lapisan l1,1 ialah lapisan terbesar Lebar lapisan dibelah dua untuk setiap langkah ke kanan, dan ketinggian dibelah dua untuk setiap langkah ke kanan.

Contohnya, lapisan l3,4 ialah separuh lebar lapisan l3,3. Lapisan pepenjuru memodelkan objek yang nisbah bidangnya hampir dengan segi empat sama, manakala lapisan bukan pepenjuru memodelkan objek yang nisbah bidangnya tidak hampir dengan segi empat sama. Lapisan berhampiran sudut atas kanan atau kiri bawah objek model matriks dengan nisbah bidang yang sangat tinggi atau rendah. Sasaran sedemikian sangat jarang berlaku, jadi ia boleh dipangkas untuk meningkatkan kecekapan.
1. Penjanaan Lapisan
Menjana lapisan matriks ialah langkah kritikal kerana ia mempengaruhi bilangan parameter model. Lebih banyak parameter, lebih kuat ekspresi model dan lebih sukar masalah pengoptimuman, jadi penyelidik memilih untuk memperkenalkan seberapa sedikit parameter baharu yang mungkin. Lapisan pepenjuru boleh diperolehi daripada peringkat tulang belakang yang berbeza atau menggunakan rangka kerja piramid ciri. Lapisan segi tiga atas diperoleh dengan menggunakan satu siri lilitan 3x3 bersama dengan langkah 1x2 pada lapisan pepenjuru. Begitu juga, lapisan kiri bawah diperoleh menggunakan lilitan 3x3 bersama dengan langkah 2x1. Parameter dikongsi antara semua konvolusi pensampelan bawah untuk meminimumkan bilangan parameter baharu.
2. Julat lapisan
Setiap lapisan dalam matriks memodelkan sasaran dengan lebar dan ketinggian tertentu, jadi kita perlu menentukan lebar yang diberikan kepada sasaran untuk setiap lapisan dalam matriks dan ketinggian julat. Julat perlu mencerminkan medan penerimaan vektor ciri lapisan matriks. Setiap langkah ke kanan dalam matriks secara berkesan menggandakan medan penerimaan dalam dimensi mendatar, dan setiap langkah menggandakan medan penerimaan dalam dimensi menegak. Oleh itu, semasa kita bergerak ke kanan atau ke bawah dalam matriks, julat lebar atau tinggi perlu dua kali ganda. Setelah julat untuk lapisan pertama l1,1 ditakrifkan, kita boleh menggunakan peraturan di atas untuk menjana julat bagi lapisan matriks yang lain.
3. Kelebihan Jaring Matriks
Kelebihan utama Jaring Matriks ialah ia membenarkan isirong lilitan segi empat tepat mengumpul maklumat tentang nisbah aspek yang berbeza. Dalam model pengesanan objek tradisional, seperti RetinaNet, kernel lilitan segi empat sama diperlukan untuk mengeluarkan nisbah aspek dan skala yang berbeza. Ini adalah kontra-intuitif kerana aspek berbeza kotak sempadan memerlukan latar belakang yang berbeza. Dalam Matrix Nets, memandangkan konteks setiap lapisan matriks berubah, kernel lilitan persegi yang sama boleh digunakan untuk kotak sempadan skala dan nisbah bidang yang berbeza.
Oleh kerana saiz sasaran hampir seragam dalam lapisan yang ditetapkan, julat dinamik lebar dan ketinggian adalah lebih kecil berbanding dengan seni bina lain (seperti FPN). Oleh itu, mengundur ketinggian dan lebar sasaran akan menjadi masalah pengoptimuman yang lebih mudah. Akhir sekali, Matrix Nets boleh digunakan sebagai sebarang seni bina pengesanan objek, berasaskan anchor atau keypoint, pengesan satu pukulan atau dua pukulan.
Jaring Matriks digunakan untuk pengesanan berasaskan titik utama
Apabila CornerNet dicadangkan, ia adalah untuk Daripada pengesanan berasaskan sauh, ia menggunakan sepasang sudut (kiri atas dan kanan bawah) untuk meramalkan kotak sempadan. Untuk setiap sudut, CornerNet meramalkan peta haba, offset dan benam. 
Gambar di atas ialah rangka kerja pengesanan sasaran berdasarkan perkara utama - KP-xNet, yang mengandungi 4 langkah.
- (a-b): Tulang belakang xNet digunakan; , dan untuk setiap lapisan matriks, peta haba dan mengimbangi sudut kiri atas dan sudut kanan bawah diramalkan, dan titik tengah diramalkan untuk mereka dalam lapisan sasaran; ): Menggunakan ramalan Titik tengah sepadan dengan sudut dalam lapisan yang sama, dan kemudian output semua lapisan digabungkan dengan penindasan lembut bukan maksimum untuk mendapatkan output akhir.
- Hasil eksperimen
- Jadual berikut menunjukkan keputusan pada set data MS COCO:
Para penyelidik juga membandingkan model yang baru dicadangkan dengan model lain berdasarkan bilangan parameter pada tulang belakang yang berbeza. Dalam rajah pertama, kami mendapati bahawa KP-xNet mengatasi semua struktur lain pada semua peringkat parameter. Para penyelidik percaya ini kerana KP-xNet menggunakan seni bina sedar skala dan nisbah aspek.
 Alamat kertas:
Alamat kertas:
https://arxiv.org/pdf/1908.04646.pdf
Atas ialah kandungan terperinci Seni bina dalam terkini untuk pengesanan sasaran mempunyai separuh parameter dan 3 kali lebih pantas +. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1371
1371
 52
52

![Cara Menggunakan Kesan Kedalaman pada iPhone [2023]](https://img.php.cn/upload/article/000/465/014/169410031113297.png?x-oss-process=image/resize,m_fill,h_207,w_330) Cara Menggunakan Kesan Kedalaman pada iPhone [2023]
Sep 07, 2023 pm 11:25 PM
Cara Menggunakan Kesan Kedalaman pada iPhone [2023]
Sep 07, 2023 pm 11:25 PM
Jika terdapat satu perkara yang boleh anda pilih sebagai berbeza pada iPhone, itu ialah bilangan pilihan penyesuaian yang anda ada semasa berurusan dengan skrin kunci iPhone anda. Antara pilihan, terdapat ciri kesan kedalaman, yang menjadikan kertas dinding anda kelihatan seperti ia berinteraksi dengan widget jam skrin kunci. Kami akan menerangkan kesan kedalaman, bila dan di mana anda boleh menggunakannya dan cara menggunakannya pada iPhone anda. Apakah kesan kedalaman pada iPhone? Apabila anda menambah kertas dinding dengan elemen berbeza, iPhone akan membahagikannya kepada beberapa lapisan kedalaman. Untuk melakukan ini, iOS menggunakan enjin saraf terbina dalam untuk mengesan maklumat kedalaman dalam kertas dinding, memisahkan subjek yang anda mahu muncul dalam fokus daripada elemen lain latar belakang yang dipilih. Ini akan mencipta kesan kelihatan sejuk di mana watak utama dalam kertas dinding
 Analisis perbandingan seni bina pembelajaran mendalam
May 17, 2023 pm 04:34 PM
Analisis perbandingan seni bina pembelajaran mendalam
May 17, 2023 pm 04:34 PM
Konsep pembelajaran mendalam berasal daripada penyelidikan rangkaian saraf tiruan Perceptron berbilang lapisan yang mengandungi berbilang lapisan tersembunyi ialah struktur pembelajaran mendalam. Pembelajaran mendalam menggabungkan ciri peringkat rendah untuk membentuk perwakilan peringkat tinggi yang lebih abstrak untuk mewakili kategori atau ciri data. Ia dapat menemui perwakilan ciri teragih bagi data. Pembelajaran mendalam ialah sejenis pembelajaran mesin, dan pembelajaran mesin ialah satu-satunya cara untuk mencapai kecerdasan buatan. Jadi, apakah perbezaan antara pelbagai seni bina sistem pembelajaran mendalam? 1. Rangkaian Bersambung Sepenuhnya (FCN) Rangkaian bersambung sepenuhnya (FCN) terdiri daripada satu siri lapisan bersambung sepenuhnya, dengan setiap neuron dalam setiap lapisan disambungkan kepada setiap neuron dalam lapisan lain. Kelebihan utamanya ialah ia adalah "struktur agnostik", iaitu tiada andaian khas tentang input diperlukan. Walaupun agnostik struktur ini membuat lengkap
 Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Jun 01, 2024 pm 09:46 PM
Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Jun 01, 2024 pm 09:46 PM
1. Pengenalan Pada masa ini, pengesan objek utama ialah rangkaian dua peringkat atau satu peringkat berdasarkan rangkaian pengelas tulang belakang yang digunakan semula CNN dalam. YOLOv3 ialah salah satu pengesan satu peringkat tercanggih yang menerima imej input dan membahagikannya kepada matriks grid bersaiz sama. Sel grid dengan pusat sasaran bertanggungjawab untuk mengesan sasaran tertentu. Apa yang saya kongsikan hari ini ialah kaedah matematik baharu yang memperuntukkan berbilang grid kepada setiap sasaran untuk mencapai ramalan kotak sempadan ketat muat yang tepat. Para penyelidik juga mencadangkan peningkatan data salin-tampal luar talian yang berkesan untuk pengesanan sasaran. Kaedah yang baru dicadangkan dengan ketara mengatasi beberapa pengesan objek terkini dan menjanjikan prestasi yang lebih baik. 2. Rangkaian pengesanan sasaran latar belakang direka bentuk untuk digunakan
 SOTA baharu untuk pengesanan sasaran: YOLOv9 keluar, dan seni bina baharu menghidupkan semula konvolusi tradisional
Feb 23, 2024 pm 12:49 PM
SOTA baharu untuk pengesanan sasaran: YOLOv9 keluar, dan seni bina baharu menghidupkan semula konvolusi tradisional
Feb 23, 2024 pm 12:49 PM
Dalam bidang pengesanan sasaran, YOLOv9 terus membuat kemajuan dalam proses pelaksanaan Dengan mengguna pakai seni bina dan kaedah baharu, ia secara berkesan meningkatkan penggunaan parameter konvolusi tradisional, yang menjadikan prestasinya jauh lebih unggul daripada produk generasi sebelumnya. Lebih setahun selepas YOLOv8 dikeluarkan secara rasmi pada Januari 2023, YOLOv9 akhirnya hadir! Sejak Joseph Redmon, Ali Farhadi dan yang lain mencadangkan model YOLO generasi pertama pada 2015, penyelidik dalam bidang pengesanan sasaran telah mengemas kini dan mengulanginya berkali-kali. YOLO ialah sistem ramalan berdasarkan maklumat global imej, dan prestasi modelnya terus dipertingkatkan. Dengan menambah baik algoritma dan teknologi secara berterusan, penyelidik telah mencapai hasil yang luar biasa, menjadikan YOLO semakin berkuasa dalam tugas pengesanan sasaran.
 'Kesilapan' ini sebenarnya bukan satu kesilapan: mulakan dengan empat kertas klasik untuk memahami apa yang 'salah' dengan gambar rajah seni bina Transformer
Jun 14, 2023 pm 01:43 PM
'Kesilapan' ini sebenarnya bukan satu kesilapan: mulakan dengan empat kertas klasik untuk memahami apa yang 'salah' dengan gambar rajah seni bina Transformer
Jun 14, 2023 pm 01:43 PM
Beberapa ketika dahulu, tweet yang menunjukkan ketidakkonsistenan antara gambar rajah seni bina Transformer dan kod dalam kertas kerja pasukan Google Brain "AttentionIsAllYouNeed" mencetuskan banyak perbincangan. Sesetengah orang berpendapat bahawa penemuan Sebastian adalah kesilapan yang tidak disengajakan, tetapi ia juga mengejutkan. Lagipun, memandangkan populariti kertas Transformer, ketidakkonsistenan ini sepatutnya disebut seribu kali. Sebastian Raschka berkata sebagai tindak balas kepada komen netizen bahawa kod "paling asli" sememangnya konsisten dengan gambar rajah seni bina, tetapi versi kod yang diserahkan pada 2017 telah diubah suai, tetapi gambar rajah seni bina tidak dikemas kini pada masa yang sama. Ini juga punca perbincangan "tidak konsisten".
 Berbilang laluan, berbilang domain, merangkumi semua! Google AI mengeluarkan model am pembelajaran berbilang domain MDL
May 28, 2023 pm 02:12 PM
Berbilang laluan, berbilang domain, merangkumi semua! Google AI mengeluarkan model am pembelajaran berbilang domain MDL
May 28, 2023 pm 02:12 PM
Model pembelajaran mendalam untuk tugas penglihatan (seperti klasifikasi imej) biasanya dilatih hujung ke hujung dengan data daripada domain visual tunggal (seperti imej semula jadi atau imej yang dijana komputer). Secara amnya, aplikasi yang menyelesaikan tugas penglihatan untuk berbilang domain perlu membina berbilang model untuk setiap domain yang berasingan dan melatihnya secara berasingan Data tidak dikongsi antara domain yang berbeza, setiap model akan mengendalikan data input tertentu. Walaupun ia berorientasikan kepada bidang yang berbeza, beberapa ciri lapisan awal antara model ini adalah serupa, jadi latihan bersama model ini adalah lebih cekap. Ini mengurangkan kependaman dan penggunaan kuasa, dan mengurangkan kos memori untuk menyimpan setiap parameter model Pendekatan ini dipanggil pembelajaran berbilang domain (MDL). Selain itu, model MDL juga boleh mengatasi prestasi tunggal
 Apakah seni bina dan prinsip kerja Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
Apakah seni bina dan prinsip kerja Spring Data JPA?
Apr 17, 2024 pm 02:48 PM
SpringDataJPA adalah berdasarkan seni bina JPA dan berinteraksi dengan pangkalan data melalui pemetaan, ORM dan pengurusan transaksi. Repositorinya menyediakan operasi CRUD, dan pertanyaan terbitan memudahkan akses pangkalan data. Selain itu, ia menggunakan pemuatan malas untuk hanya mendapatkan semula data apabila perlu, sekali gus meningkatkan prestasi.
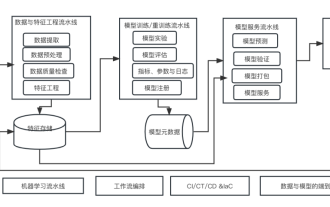 Sepuluh elemen seni bina sistem pembelajaran mesin
Apr 13, 2023 pm 11:37 PM
Sepuluh elemen seni bina sistem pembelajaran mesin
Apr 13, 2023 pm 11:37 PM
Ini ialah era pemerkasaan AI, dan pembelajaran mesin ialah cara teknikal yang penting untuk mencapai AI. Jadi, adakah terdapat seni bina sistem pembelajaran mesin universal? Dalam skop kognitif pengaturcara berpengalaman, Apa-apa sahaja bukanlah apa-apa, terutamanya untuk seni bina sistem. Walau bagaimanapun, adalah mungkin untuk membina seni bina sistem pembelajaran mesin berskala dan boleh dipercayai jika terpakai pada kebanyakan sistem didorong pembelajaran mesin atau kes penggunaan. Daripada perspektif kitaran hayat pembelajaran mesin, seni bina universal yang dipanggil ini merangkumi peringkat pembelajaran mesin utama, daripada membangunkan model pembelajaran mesin, untuk menggunakan sistem latihan dan sistem perkhidmatan kepada persekitaran pengeluaran. Kita boleh cuba menerangkan seni bina sistem pembelajaran mesin sedemikian daripada dimensi 10 elemen. 1.
