

Pada 6-7 Ogos 2022, Persidangan Teknologi Kecerdasan Buatan Global AIsummit akan diadakan seperti yang dijadualkan. Di sub-forum "Penjelajahan Sempadan Kecerdasan Buatan" yang diadakan pada petang ke-7, Huang Hongbo, pakar teknikal AI dari Xishanju, berkongsi tema "Kombinasi Praktikal Pembelajaran Pengukuhan dan Pokok Tingkah Laku dalam Permainan" dan berkongsi secara terperinci impak pembelajaran pengukuhan dalam bidang permainan.
Huang Hongbo berkata bahawa pelaksanaan teknologi pembelajaran tetulang tidak terletak pada penambahbaikan algoritma, tetapi pada menggabungkan teknologi pembelajaran tetulang dengan pembelajaran mendalam dan perancangan permainan untuk membentuk penyelesaian yang lengkap dan Mencapainya.
Pembelajaran peneguhan menjadikan permainan lebih pintar
Pelaksanaan pembelajaran peneguhan dalam permainan boleh menjadikan permainan lebih pintar dan lebih mudah dimainkan. Ini adalah Tujuan utama penggunaan pembelajaran peneguhan dalam permainan.
"Pembelajaran pengukuhan ialah paradigma pembelajaran mesin yang melatih strategi ejen supaya satu siri keputusan boleh dibuat." Huang Hongbo berkata bahawa tujuan ejen adalah untuk mengeluarkan tindakan berdasarkan pemerhatian terhadap persekitaran. Tindakan ini akan membawa kepada lebih banyak pemerhatian dan ganjaran. Latihan melibatkan banyak percubaan dan kesilapan kerana ejen berinteraksi dengan persekitaran, dan dasar boleh dipertingkatkan dengan setiap lelaran.
Dalam permainan, ejen yang mengambil tindakan atau melakukan tingkah laku ialah ejen permainan. Pertimbangkan watak atau robot dalam permainan, ia perlu memahami keadaan permainan, di mana pemain berada, dan kemudian berdasarkan pemerhatian ini, ia harus membuat keputusan berdasarkan situasi permainan. Dalam pembelajaran pengukuhan, keputusan didorong oleh ganjaran, yang boleh disediakan dalam permainan sebagai skor tinggi atau untuk mencapai tahap baharu untuk mencapai matlamat tertentu.
Huang Hongbo berkata bahawa perkara paling menarik tentang situasi permainan ialah strategi ejen dilatih di bawah tekanan permainan. Contohnya, ia boleh belajar cara mengendalikan serangan, atau cara berkelakuan untuk mencapai matlamat tertentu.
Peranan pokok tingkah laku dalam permainan
Pokok tingkah laku ialah struktur pokok yang mengandungi nod logik dan nod tingkah laku. Biasanya, anda boleh mengabstrak setiap situasi ke dalam jenis nod, menulis nod mengikut spesifikasi, dan kemudian menyambungkan nod ini ke dalam pokok. Setiap kali pengguna mencari gelagat, dia akan bermula dari nod akar pokok dan mencari gelagat yang konsisten dengan data semasa daripada setiap nod.
Ringkasnya, apabila tahap gandingan setiap modul AI adalah tinggi dan butirannya besar, perubahan selalunya melibatkan sejumlah besar pengubahsuaian, dan mudah untuk sejumlah besar kod pendua muncul . Kemunculan pokok tingkah laku telah menyediakan "buku nota persegi" untuk pembangun permainan, membolehkan pembangun AI membina satu set rangka kerja AI dengan lebih mudah yang boleh diguna semula, mudah dikembangkan dan diselenggara. Boleh dikatakan bahawa pembelajaran peneguhan diperoleh melalui latihan, dan pokok tingkah laku adalah gabungan beberapa pernyataan lain dan jika.
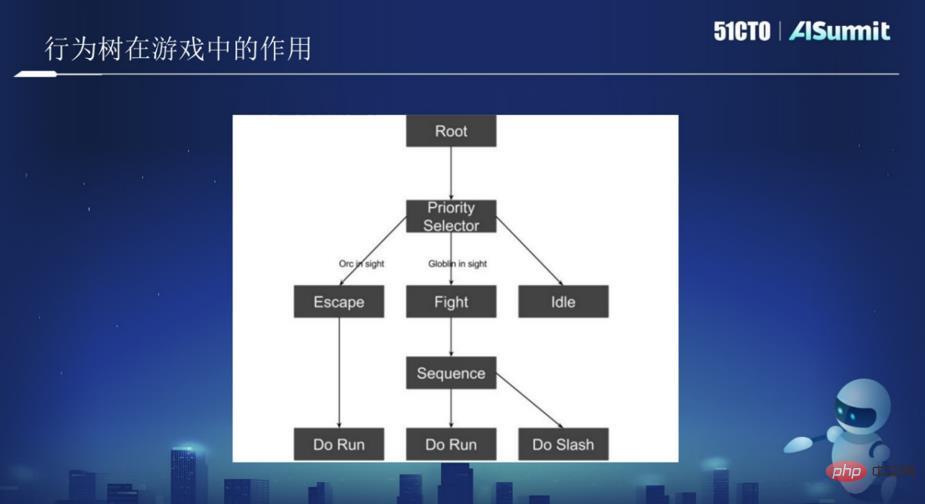
Seperti yang ditunjukkan dalam gambar di atas, terdapat nod akar, dan di bawahnya adalah nod pokok Nod pokok termasuk melarikan diri, menyerang, mengembara, dsb. Fikirkan gambar di atas sebagai AI atau robot dan biarkan ia meronda di dalam hutan. Apabila AI melihat ORC ORC dan menentukan bahawa ia tidak dapat mengalahkan ORC, apabila keadaan ini dicetuskan, AI akan melarikan diri dan melaksanakan tindakan Run apabila melarikan diri. Apabila dinilai lebih mudah untuk melawan, operasi Fight akan dilakukan.
Dalam rajah di atas, terdapat dua nod, satu ialah Root, iaitu nod punca; satu ialah nod Pemilih, iaitu nod logik. Semua nod dilaksanakan dalam susunan tertentu dari kiri ke kanan Ini adalah pokok tingkah laku. Oleh itu, anda hanya perlu menulis logik yang sepadan dalam setiap nod untuk membolehkan AI melakukan beberapa tindakan yang berkaitan. Beberapa pokok tingkah laku akhirnya membentuk permainan.
Gabungan pembelajaran peneguhan dan pokok tingkah laku menjadikan permainan lebih kaya
Bagaimana untuk menggunakan gabungan pembelajaran peneguhan dan pokok tingkah laku untuk menjadikan permainan lebih kaya? Ini adalah aplikasi sukar yang perlu dibincangkan dalam banyak permainan.
Sebelum itu, mari kita bincangkan bila lebih baik menggunakan pembelajaran peneguhan dan dalam keadaan apakah lebih baik menggunakan pokok tingkah laku. Huang Hongbo berkata bahawa jika tidak ada cara untuk mencapai matlamat menggunakan pokok tingkah laku, pembelajaran pengukuhan boleh digunakan Contohnya, dalam FPS (penembak orang pertama), berapa banyak kuasa tembakan yang harus digunakan, siapa yang harus ditembak, jenis apa. senjata harus digunakan, dsb. Lebih sukar untuk membuat keputusan melalui pokok tingkah laku Secara umumnya, lebih baik menggunakan pembelajaran pengukuhan.
Bila hendak menggunakan pokok tingkah laku? Contohnya, jika anda menghadapi halangan dalam permainan dan perlu melepasinya, anda boleh memilih untuk menggunakan pembelajaran pengukuhan untuk melakukannya, atau anda boleh memilih untuk menggunakan pepohon tingkah laku untuk melakukannya. Tetapi jika kita menggunakan pembelajaran pengukuhan untuk melakukannya, latihan akan menjadi sangat menyusahkan. Memandangkan hanya ada satu pilihan dalam situasi ini, iaitu melangkau, adalah lebih mudah untuk menggunakan pokok tingkah laku.
Tidak sukar untuk mencari bahawa jika pokok pembelajaran dan tingkah laku peneguhan digabungkan dan digunakan dalam permainan, ia adalah penyelesaian yang lebih baik. Huang Hongbo berkata terdapat dua kaedah pelaksanaan yang agak besar untuk menggabungkan pembelajaran peneguhan dengan pokok tingkah laku: satu berdasarkan pembelajaran peneguhan dan ditambah dengan pokok tingkah laku dan ditambah dengan pembelajaran peneguhan;
Sebelah pokok gelagat: Dengan pepohon gelagat sebagai kaedah pergerakan AI utama, pepohon gelagat menerima input obs daripada klien permainan, dan menulis gelagat pepohon gelagat yang sepadan untuk obs mengikut situasi sasarannya sendiri setiap tingkah laku pokok tingkah laku, beberapa nod yang memerlukan pembelajaran peneguhan untuk membuat keputusan diserahkan kepada pembelajaran pengukuhan Kemudian di sini, pembelajaran peneguhan diperlukan untuk melaksanakan latihan yang sepadan untuk beberapa senario tertentu.
Bahagian pembelajaran pengukuhan: Strategi keseluruhan adalah untuk melatih beberapa model, setiap model melaksanakan strategi, dan kemudian membenamkannya ke dalam pepohon tingkah laku.
Huang Hongbo berkata antara dua kaedah pelaksanaan berbeza ini, yang mana satu lebih baik memerlukan pertimbangan berbeza berdasarkan situasi berbeza, aplikasi berbeza dan permainan berbeza, jadi ia tidak boleh digeneralisasikan.
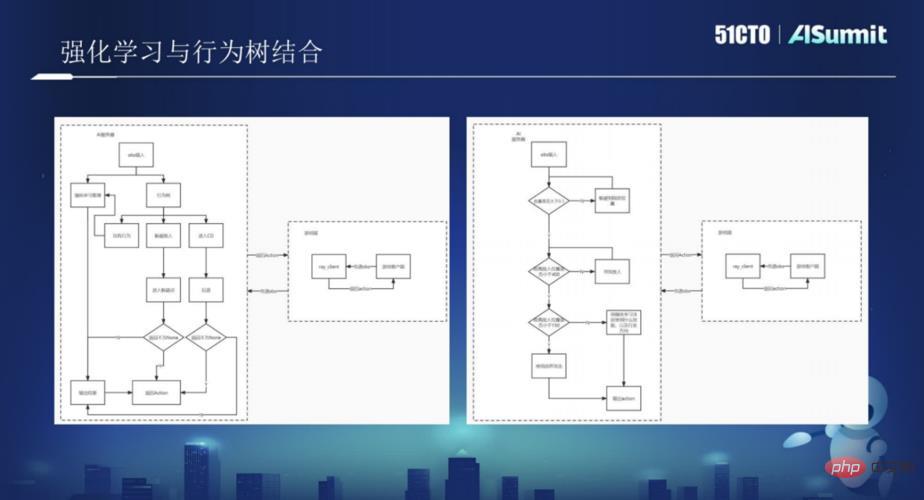
Pada masa berikutnya, Huang Hongbo memperkenalkan secara terperinci rangka kerja teknikal yang digunakan oleh Xishanju dalam pembelajaran pengukuhan dan pokok tingkah laku, dan digabungkan dengan sejumlah besar kes permainan, yang diperkenalkan dalam perincian Bagaimana pokok tingkah laku dan pembelajaran peneguhan digabungkan dalam permainan untuk menjadikan permainan lebih kaya. Pengguna yang berminat dengan latihan kes mungkin ingin memberi perhatian kepada video perkongsian menarik Persidangan Teknologi Kepintaran Buatan Global AISummit. (https://www.php.cn/link/53253027fef2ab5162a602f2acfed431)
Atas ialah kandungan terperinci Pakar teknikal AI Xishanju Huang Hongbo: Penyepaduan praktikal pembelajaran pengukuhan dan pokok tingkah laku dalam permainan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah perisian pejabat
Apakah perisian pejabat
 Pengenalan kepada maksud tetingkap muat turun awan
Pengenalan kepada maksud tetingkap muat turun awan
 Perkara yang perlu dilakukan jika penamaan semula fail sementara gagal
Perkara yang perlu dilakukan jika penamaan semula fail sementara gagal
 Perkara yang perlu dilakukan jika avast melaporkan positif palsu
Perkara yang perlu dilakukan jika avast melaporkan positif palsu
 Perbezaan antara dapatkan dan pos
Perbezaan antara dapatkan dan pos
 Telekom cdma
Telekom cdma
 Apakah yang perlu saya lakukan jika imej CAD tidak boleh dialihkan?
Apakah yang perlu saya lakukan jika imej CAD tidak boleh dialihkan?
 penyelesaian laluan fakepath
penyelesaian laluan fakepath
 Semak sama ada port dibuka dalam linux
Semak sama ada port dibuka dalam linux








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



