

Pembelajaran mesin layan diri berdasarkan pangkalan data pintar


Penterjemah |. Zhang Yi
Penilai |. organisasi yang dipacu wawasan) merujuk kepada organisasi yang dipacu wawasan (berorientasikan maklumat). Untuk menjadi IDO, anda terlebih dahulu memerlukan data dan alat untuk mengendalikan dan menganalisis data kedua, penganalisis data atau saintis data dengan pengalaman yang sesuai dan akhirnya, anda perlu mencari teknologi atau kaedah untuk melaksanakan pembuatan keputusan berasaskan wawasan proses di seluruh syarikat.
Pembelajaran mesin ialah teknologi yang boleh memaksimumkan kelebihan data. Proses ML mula-mula menggunakan data untuk melatih model ramalan, dan kemudian menyelesaikan masalah berkaitan data selepas latihan berjaya. Daripada jumlah ini, rangkaian saraf tiruan adalah teknologi yang paling berkesan, dan reka bentuknya berpunca daripada pemahaman semasa kami tentang cara otak manusia berfungsi. Memandangkan sumber pengkomputeran yang luas yang dimiliki oleh orang ramai pada masa ini, ia boleh menghasilkan model yang luar biasa yang dilatih pada jumlah data yang besar.
Perniagaan boleh menggunakan pelbagai perisian dan skrip layan diri untuk menyelesaikan tugasan yang berbeza untuk mengelakkan kesilapan manusia. Begitu juga, anda boleh membuat keputusan berdasarkan data untuk mengelakkan kesilapan manusia.
2. Mengapakah syarikat lambat menggunakan kecerdasan buatan
Hanya minoriti syarikat menggunakan kecerdasan buatan atau pembelajaran mesin untuk memproses data. Biro Banci AS berkata sehingga 2020, kurang daripada 10% perniagaan AS telah menggunakan pembelajaran mesin (kebanyakannya syarikat besar).
Halangan kepada penggunaan ML termasuk:
AI mempunyai banyak kerja yang perlu dilakukan sebelum ia boleh menggantikan manusia. Yang pertama ialah banyak syarikat kekurangan dan tidak mampu membayar profesional. Saintis data sangat dihormati dalam bidang ini, tetapi mereka juga yang paling mahal untuk diupah. Kekurangan data yang tersedia, keselamatan data dan pelaksanaan algoritma ML yang memakan masa.- Sukar untuk syarikat mewujudkan persekitaran di mana data dan kelebihannya boleh direalisasikan. Persekitaran ini memerlukan alat, proses dan strategi yang relevan.
- 3. Alat ML (AutoML) automatik tidak mencukupi untuk promosi pembelajaran mesin
- Walaupun platform ML automatik mempunyai masa depan yang cerah, liputannya pada masa ini agak terhad turut memperdebatkan sama ada ML automatik akan menggantikan saintis data tidak lama lagi.
Jika anda ingin berjaya menggunakan pembelajaran mesin layan diri dalam syarikat anda, alatan AutoML sememangnya penting, tetapi proses, kaedah dan strategi juga mesti diberi perhatian. Platform AutoML hanyalah alat, dan kebanyakan pakar ML percaya ini tidak mencukupi.
4. Pecahkan proses pembelajaran mesin
Sebarang proses ML bermula dengan data. Adalah diterima umum bahawa penyediaan data ialah bahagian terpenting dalam proses ML, dan bahagian pemodelan hanyalah satu bahagian daripada saluran paip data keseluruhan, sambil dipermudahkan melalui alatan AutoML. Aliran kerja yang lengkap masih memerlukan banyak kerja untuk mengubah data dan menyuapkannya kepada model. Penyediaan data dan transformasi data boleh menjadi sebahagian daripada bahagian kerja yang paling memakan masa dan tidak menyenangkan. Selain itu, data perniagaan yang digunakan untuk melatih model ML akan dikemas kini dengan kerap. Oleh itu, ia memerlukan perusahaan membina saluran paip ETL yang kompleks yang boleh menguasai alatan dan proses yang kompleks, jadi memastikan kesinambungan dan sifat masa nyata proses ML juga merupakan tugas yang mencabar.
Selain itu, data perniagaan yang digunakan untuk melatih model ML akan dikemas kini dengan kerap. Oleh itu, ia memerlukan perusahaan membina saluran paip ETL yang kompleks yang boleh menguasai alatan dan proses yang kompleks, jadi memastikan kesinambungan dan sifat masa nyata proses ML juga merupakan tugas yang mencabar.
5. Sepadukan ML dengan Aplikasi
Andaikan sekarang kita telah membina model ML dan kemudiannya perlu menggunakannya. Pendekatan penggunaan klasik menganggapnya sebagai komponen lapisan aplikasi, seperti yang ditunjukkan di bawah:
Inputnya ialah data dan output ialah ramalan yang kami dapat. Gunakan output model ML dengan menyepadukan API aplikasi ini. Ini semua kelihatan mudah hanya dari perspektif pembangun, tetapi tidak apabila anda memikirkan prosesnya. Dalam organisasi yang besar, sebarang penyepaduan dan penyelenggaraan dengan aplikasi perniagaan boleh menjadi agak rumit. Walaupun syarikat itu celik teknologi, sebarang permintaan untuk perubahan kod mesti melalui proses semakan dan ujian khusus merentas pelbagai peringkat jabatan. Ini menjejaskan fleksibiliti secara negatif dan meningkatkan kerumitan aliran kerja keseluruhan.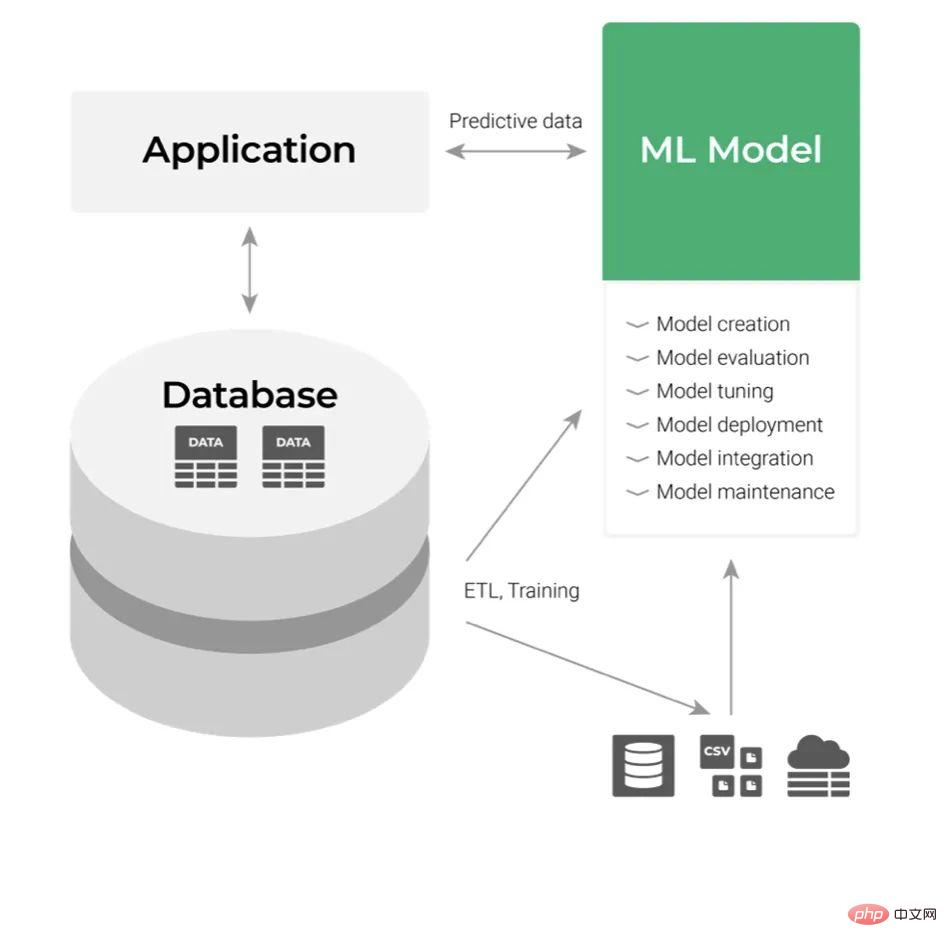 Jika terdapat fleksibiliti yang mencukupi dalam menguji pelbagai konsep dan idea, pembuatan keputusan berasaskan ML akan menjadi lebih mudah, jadi orang ramai akan lebih suka produk dengan keupayaan layan diri.
Jika terdapat fleksibiliti yang mencukupi dalam menguji pelbagai konsep dan idea, pembuatan keputusan berasaskan ML akan menjadi lebih mudah, jadi orang ramai akan lebih suka produk dengan keupayaan layan diri.
6. Pembelajaran mesin layan diri/pangkalan data pintar?
Seperti yang kita lihat di atas, data ialah teras proses ML, alatan ML sedia ada mengambil data dan ramalan pengembalian, dan ramalan ini Ia juga merupakan bentuk data.
Kini persoalan timbul:
Mengapa kami menganggap ML sebagai aplikasi kendiri dan melaksanakan penyepaduan kompleks antara model, aplikasi dan pangkalan data ML?Mengapa tidak membuat ML ciri teras pangkalan data?- Mengapa tidak menjadikan model ML tersedia melalui sintaks pangkalan data standard seperti SQL?
- Mari Kita Analisa masalah di atas dan cabarannya untuk mencari penyelesaian ML.
-
Cabaran #1: Penyepaduan data yang kompleks dan saluran paip ETL
Mengekalkan penyepaduan data yang kompleks dan saluran paip ETL antara model dan pangkalan data ML merupakan salah satu cabaran terbesar yang dihadapi oleh proses ML.
SQL ialah alat manipulasi data yang sangat baik, jadi kami boleh menyelesaikan masalah ini dengan memperkenalkan model ML ke dalam lapisan data. Dalam erti kata lain, model ML akan belajar dalam pangkalan data dan ramalan pulangan.
Cabaran #2: Penyepaduan model ML dengan aplikasi
Menyepadukan model ML dengan aplikasi perniagaan melalui API merupakan satu lagi cabaran yang dihadapi.
Aplikasi perniagaan dan alatan BI digandingkan rapat dengan pangkalan data. Oleh itu, jika alat AutoML menjadi sebahagian daripada pangkalan data, kita boleh menggunakan sintaks SQL standard untuk membuat ramalan. Seterusnya, penyepaduan API antara model ML dan aplikasi perniagaan tidak lagi diperlukan kerana model tersebut berada dalam pangkalan data.
Penyelesaian: Benamkan AutoML dalam pangkalan data
Benamkan alatan AutoML dalam pangkalan data akan membawa banyak faedah, seperti:
- Sesiapa sahaja yang bekerja dengan data dan memahami SQL Sesiapa sahaja (penganalisis data atau saintis data) boleh memanfaatkan kuasa pembelajaran mesin.
- Pembangun perisian boleh membenamkan ML ke dalam alatan dan aplikasi perniagaan dengan lebih cekap.
- Tiada penyepaduan kompleks diperlukan antara data dan model serta antara model dan aplikasi perniagaan.
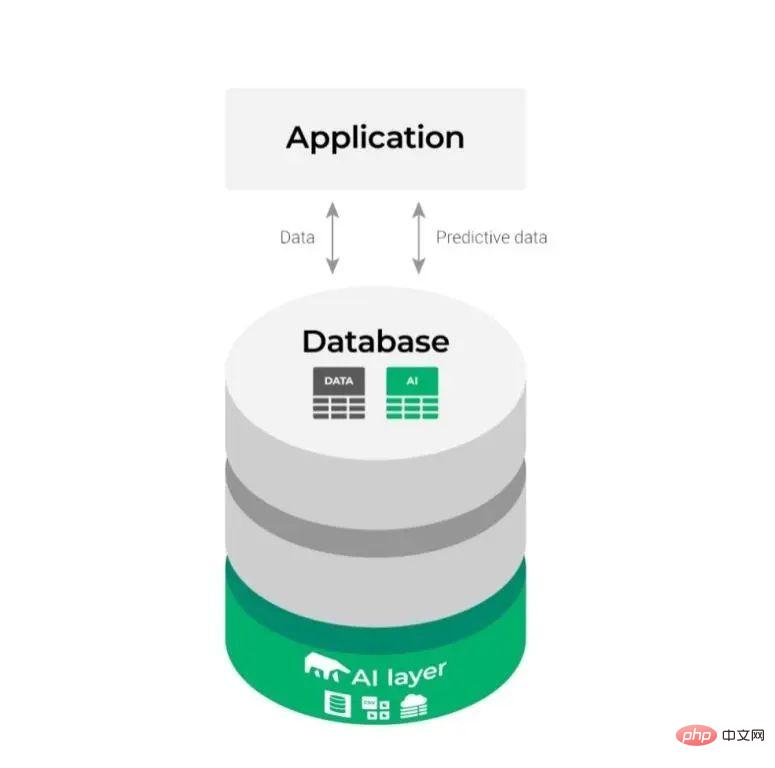
Dengan cara ini, gambar rajah penyepaduan yang agak kompleks di atas berubah seperti berikut:

Ia kelihatan lebih mudah dan menjadikan proses ML lebih lancar dan cekap .
7. Cara melaksanakan ML layan diri menggunakan model sebagai jadual pangkalan data maya
Langkah seterusnya dalam mencari penyelesaian ialah melaksanakannya.
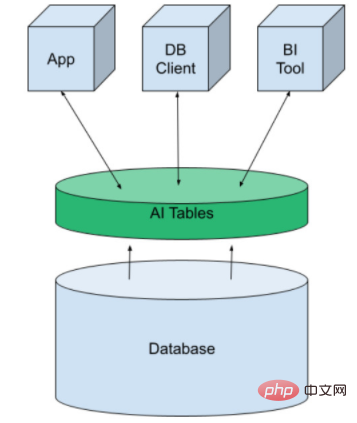
Untuk ini, kami menggunakan struktur yang dipanggil AI Tables. Ia membawa pembelajaran mesin ke platform data dalam bentuk jadual maya. Ia boleh dibuat seperti jadual pangkalan data lain dan kemudian didedahkan kepada aplikasi, alat BI dan pelanggan DB. Kami membuat ramalan dengan hanya menanyakan data.
Jadual AI pada asalnya dibangunkan oleh MindsDB dan tersedia sebagai sumber terbuka atau perkhidmatan awan terurus. Mereka menyepadukan pangkalan data SQL dan NoSQL tradisional seperti Kafka dan Redis.
8. Menggunakan Jadual AI
Konsep Jadual AI membolehkan kami melaksanakan proses ML dalam pangkalan data supaya semua langkah proses ML (iaitu penyediaan data, latihan model dan ramalan) boleh jadi pangkalan data.
- Melatih Jadual AI
Pertama, pengguna perlu mencipta Jadual AI mengikut keperluan mereka sendiri, yang serupa dengan model pembelajaran mesin, termasuk lajur daripada sumber jadual, dsb. ciri valens; dan kemudian selesaikan tugas pemodelan yang tinggal dengan sendirinya melalui enjin AutoML. Contoh akan diberikan kemudian.
- Buat ramalan
Setelah Jadual AI dibuat, ia sedia untuk digunakan tanpa sebarang penggunaan selanjutnya. Untuk membuat ramalan, hanya jalankan pertanyaan SQL standard pada Jadual AI.
Anda boleh membuat ramalan satu demi satu atau secara berkelompok. Jadual AI boleh mengendalikan banyak tugas pembelajaran mesin yang kompleks, seperti siri masa berbilang variasi, pengesanan anomali, dsb.
9. Contoh Kerja Jadual AI
Bagi peruncit, memastikan produk berada dalam stok pada masa yang tepat adalah tugas yang rumit. Apabila permintaan meningkat, penawaran meningkat. Berdasarkan data dan pembelajaran mesin ini, kami boleh meramalkan jumlah stok produk tertentu pada hari tertentu, menghasilkan lebih banyak hasil untuk peruncit.
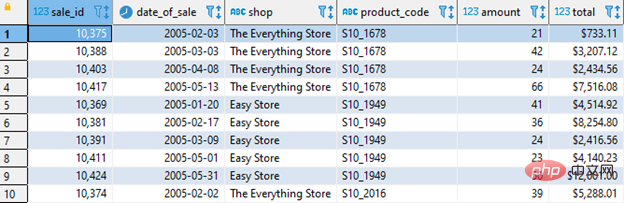
Mula-mula anda perlu menjejaki maklumat berikut dan membina Jadual AI:
- Tarikh dijual produk (tarikh_jualan)
- Produk dijual ke kedai (kedai)
- Produk khusus yang dijual (kod_produk)
- Kuantiti produk yang dijual (jumlah)
Seperti yang ditunjukkan di bawah:
(1) Melatih Jadual AI
Untuk mencipta dan melatih Jadual AI, anda mesti membenarkan MindsDB mengakses data terlebih dahulu. Untuk arahan terperinci, sila rujuk dokumentasi MindsDB.
Jadual AI adalah seperti model ML dan memerlukan data sejarah untuk melatihnya.
Yang berikut menggunakan perintah SQL mudah untuk melatih AITable:
Mari kita menganalisis pertanyaan ini:
- Menggunakan MindsDB CIPTA penyata PREDICTOR dalam .
- Tentukan pangkalan data sumber berdasarkan data sejarah.
- Latih Jadual AI berdasarkan jadual data sejarah (jadual_sejarah), dan lajur yang dipilih (lajur_1 dan lajur_2) ialah ciri yang digunakan untuk ramalan.
- AutoML melengkapkan tugas pemodelan yang tinggal secara automatik.
- MindsDB akan mengenal pasti jenis data setiap lajur, menormalkan dan mengekodnya serta membina dan melatih model ML.
Pada masa yang sama, anda boleh melihat ketepatan dan keyakinan keseluruhan setiap ramalan dan menganggarkan lajur (ciri) yang lebih penting untuk keputusan.
Dalam pangkalan data, kami selalunya perlu mengendalikan tugas yang melibatkan data siri masa berbilang variasi dengan kardinaliti tinggi. Menggunakan kaedah tradisional, usaha yang besar diperlukan untuk mencipta model ML tersebut. Kita perlu mengumpulkan data dan mengisihnya berdasarkan masa, tarikh atau medan data cap masa tertentu.
Sebagai contoh, kami meramalkan bilangan tukul yang dijual di kedai perkakasan. Nah, data dikumpulkan mengikut kedai dan produk, dan ramalan dibuat untuk setiap gabungan kedai dan produk yang berbeza. Ini membawa kita kepada masalah mencipta model siri masa untuk setiap kumpulan.
Ini kelihatan seperti projek yang besar, tetapi MindsDB menyediakan kaedah untuk mencipta model ML tunggal menggunakan pernyataan GROUP BY untuk melatih data siri masa berbilang variasi sekaligus. Mari lihat cara ia dilakukan menggunakan hanya satu arahan SQL:
Peramal stock_forecaster dicipta untuk meramalkan jumlah item yang akan dijual oleh kedai tertentu pada masa hadapan. Data diisih mengikut tarikh jualan dan dikumpulkan mengikut kedai. Jadi kita boleh meramalkan jumlah jualan untuk setiap kedai.
(2) Ramalan kelompok
Dengan menggunakan pertanyaan di bawah untuk menyambungkan jadual data jualan dengan peramal, operasi JOIN menambah kuantiti yang diramalkan pada rekod, supaya kita boleh mendapatkan banyak sekali gus Ramalan kelompok yang direkodkan.
Untuk mengetahui lebih lanjut tentang menganalisis dan menggambarkan ramalan dalam alatan BI, lihat artikel ini.
(3) Aplikasi Praktikal
Pendekatan tradisional menganggap model ML sebagai aplikasi bebas, memerlukan penyelenggaraan saluran paip ETL ke pangkalan data dan penyepaduan API kepada aplikasi perniagaan. Walaupun alatan AutoML menjadikan bahagian pemodelan mudah dan mudah, aliran kerja ML yang lengkap masih memerlukan pakar yang berpengalaman untuk mengurusnya. Malah, pangkalan data sudah pun menjadi alat pilihan untuk penyediaan data, jadi lebih masuk akal untuk memperkenalkan ML ke dalam pangkalan data daripada memperkenalkan data ke dalam ML. Oleh kerana alatan AutoML berada dalam pangkalan data, binaan AI Tables daripada MindsDB menyediakan pengamal data AutoML layan diri dan memperkemas aliran kerja pembelajaran mesin.
Pautan asal: https://dzone.com/articles/self-service-machine-learning-with-intelligent-dat
Pengenalan penterjemah
Zhang Yi, editor komuniti 51CTO, jurutera peringkat pertengahan. Terutamanya menyelidik pelaksanaan algoritma kecerdasan buatan dan aplikasi senario, mempunyai pemahaman dan penguasaan algoritma pembelajaran mesin dan algoritma kawalan automatik, dan akan terus memberi perhatian kepada trend pembangunan teknologi kecerdasan buatan di dalam dan luar negara, terutamanya aplikasi buatan. teknologi perisikan dalam kereta bersambung pintar dan rumah pintar Pelaksanaan dan aplikasi khusus dalam bidang lain.




Atas ialah kandungan terperinci Pembelajaran mesin layan diri berdasarkan pangkalan data pintar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1392
1392
 52
52

 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 AI yang boleh dijelaskan: Menerangkan model AI/ML yang kompleks
Jun 03, 2024 pm 10:08 PM
AI yang boleh dijelaskan: Menerangkan model AI/ML yang kompleks
Jun 03, 2024 pm 10:08 PM
Penterjemah |. Disemak oleh Li Rui |. Chonglou Model kecerdasan buatan (AI) dan pembelajaran mesin (ML) semakin kompleks hari ini, dan output yang dihasilkan oleh model ini adalah kotak hitam – tidak dapat dijelaskan kepada pihak berkepentingan. AI Boleh Dijelaskan (XAI) bertujuan untuk menyelesaikan masalah ini dengan membolehkan pihak berkepentingan memahami cara model ini berfungsi, memastikan mereka memahami cara model ini sebenarnya membuat keputusan, dan memastikan ketelusan dalam sistem AI, Amanah dan akauntabiliti untuk menyelesaikan masalah ini. Artikel ini meneroka pelbagai teknik kecerdasan buatan (XAI) yang boleh dijelaskan untuk menggambarkan prinsip asasnya. Beberapa sebab mengapa AI boleh dijelaskan adalah penting Kepercayaan dan ketelusan: Untuk sistem AI diterima secara meluas dan dipercayai, pengguna perlu memahami cara keputusan dibuat
 Pembelajaran Mesin dalam C++: Panduan untuk Melaksanakan Algoritma Pembelajaran Mesin Biasa dalam C++
Jun 03, 2024 pm 07:33 PM
Pembelajaran Mesin dalam C++: Panduan untuk Melaksanakan Algoritma Pembelajaran Mesin Biasa dalam C++
Jun 03, 2024 pm 07:33 PM
Dalam C++, pelaksanaan algoritma pembelajaran mesin termasuk: Regresi linear: digunakan untuk meramalkan pembolehubah berterusan Langkah-langkah termasuk memuatkan data, mengira berat dan berat sebelah, mengemas kini parameter dan ramalan. Regresi logistik: digunakan untuk meramalkan pembolehubah diskret Proses ini serupa dengan regresi linear, tetapi menggunakan fungsi sigmoid untuk ramalan. Mesin Vektor Sokongan: Algoritma klasifikasi dan regresi yang berkuasa yang melibatkan pengkomputeran vektor sokongan dan label ramalan.
 iOS 18 menambah fungsi album 'Dipulihkan' baharu untuk mendapatkan semula foto yang hilang atau rosak
Jul 18, 2024 am 05:48 AM
iOS 18 menambah fungsi album 'Dipulihkan' baharu untuk mendapatkan semula foto yang hilang atau rosak
Jul 18, 2024 am 05:48 AM
Keluaran terbaharu Apple bagi sistem iOS18, iPadOS18 dan macOS Sequoia telah menambah ciri penting pada aplikasi Photos, yang direka untuk membantu pengguna memulihkan foto dan video yang hilang atau rosak dengan mudah disebabkan pelbagai sebab. Ciri baharu ini memperkenalkan album yang dipanggil "Dipulihkan" dalam bahagian Alat pada apl Foto yang akan muncul secara automatik apabila pengguna mempunyai gambar atau video pada peranti mereka yang bukan sebahagian daripada pustaka foto mereka. Kemunculan album "Dipulihkan" menyediakan penyelesaian untuk foto dan video yang hilang akibat kerosakan pangkalan data, aplikasi kamera tidak disimpan ke pustaka foto dengan betul, atau aplikasi pihak ketiga yang menguruskan pustaka foto. Pengguna hanya memerlukan beberapa langkah mudah
 Tutorial terperinci tentang mewujudkan sambungan pangkalan data menggunakan MySQLi dalam PHP
Jun 04, 2024 pm 01:42 PM
Tutorial terperinci tentang mewujudkan sambungan pangkalan data menggunakan MySQLi dalam PHP
Jun 04, 2024 pm 01:42 PM
Cara menggunakan MySQLi untuk mewujudkan sambungan pangkalan data dalam PHP: Sertakan sambungan MySQLi (require_once) Cipta fungsi sambungan (functionconnect_to_db) Fungsi sambungan panggilan ($conn=connect_to_db()) Laksanakan pertanyaan ($result=$conn->query()) Tutup sambungan ( $conn->close())
 Bagaimana untuk mengendalikan ralat sambungan pangkalan data dalam PHP
Jun 05, 2024 pm 02:16 PM
Bagaimana untuk mengendalikan ralat sambungan pangkalan data dalam PHP
Jun 05, 2024 pm 02:16 PM
Untuk mengendalikan ralat sambungan pangkalan data dalam PHP, anda boleh menggunakan langkah berikut: Gunakan mysqli_connect_errno() untuk mendapatkan kod ralat. Gunakan mysqli_connect_error() untuk mendapatkan mesej ralat. Dengan menangkap dan mengelog mesej ralat ini, isu sambungan pangkalan data boleh dikenal pasti dan diselesaikan dengan mudah, memastikan kelancaran aplikasi anda.
 Aplikasi Pembelajaran Mesin Golang: Membina Algoritma Pintar dan Penyelesaian Dipacu Data
Jun 02, 2024 pm 06:46 PM
Aplikasi Pembelajaran Mesin Golang: Membina Algoritma Pintar dan Penyelesaian Dipacu Data
Jun 02, 2024 pm 06:46 PM
Gunakan pembelajaran mesin di Golang untuk membangunkan algoritma pintar dan penyelesaian terdorong data: Pasang pustaka Gonum untuk algoritma dan utiliti pembelajaran mesin. Regresi linear menggunakan model LinearRegression Gonum, algoritma pembelajaran yang diselia. Latih model menggunakan data latihan, yang mengandungi pembolehubah input dan pembolehubah sasaran. Ramalkan harga rumah berdasarkan ciri baharu, yang daripadanya model akan mengeluarkan perhubungan linear.
