
 Peranti teknologi
AI
Graf-DETR3D: Memikirkan semula kawasan bertindih dalam pengesanan objek 3D berbilang paparan
Peranti teknologi
AI
Graf-DETR3D: Memikirkan semula kawasan bertindih dalam pengesanan objek 3D berbilang paparan
Graf-DETR3D: Memikirkan semula kawasan bertindih dalam pengesanan objek 3D berbilang paparan

kertas arXiv "Graph-DETR3D: Memikirkan Semula Kawasan Bertindih untuk Pengesanan Objek 3D Berbilang Paparan", 22 Jun, hasil kerja Universiti Sains dan Teknologi China, Institut Teknologi Harbin dan SenseTime.

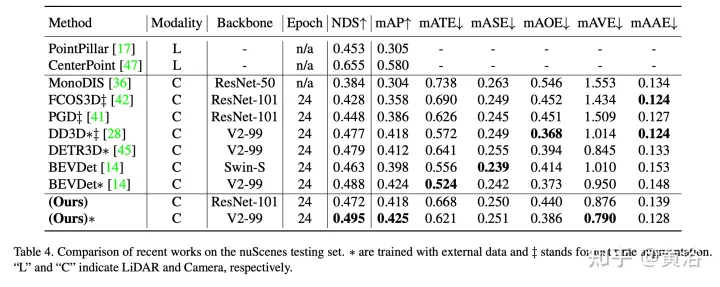
Mengesan objek 3-D daripada berbilang paparan imej ialah tugas asas namun mencabar dalam pemahaman pemandangan visual. Oleh kerana kosnya yang rendah dan kecekapan tinggi, pengesanan objek 3-D berbilang paparan menunjukkan prospek aplikasi yang luas. Walau bagaimanapun, disebabkan kekurangan maklumat mendalam, adalah amat sukar untuk mengesan objek dengan tepat melalui perspektif dalam ruang 3-D. Baru-baru ini, DETR3D memperkenalkan paradigma pertanyaan 3D-2D baharu untuk mengagregatkan imej berbilang paparan untuk pengesanan objek 3D dan mencapai prestasi terkini.
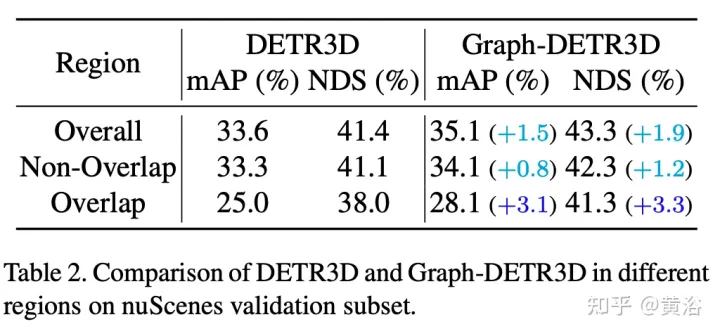
Melalui eksperimen berpandu intensif, kertas kerja ini mengukur sasaran yang terletak di kawasan berbeza dan mendapati bahawa "kejadian terpenggal" (iaitu, kawasan sempadan setiap imej) adalah halangan utama yang menghalang prestasi DETR3D. Walaupun menggabungkan berbilang ciri daripada dua paparan bersebelahan dalam kawasan bertindih, DETR3D masih mengalami pengagregatan ciri yang tidak mencukupi dan oleh itu terlepas peluang untuk meningkatkan prestasi pengesanan sepenuhnya.
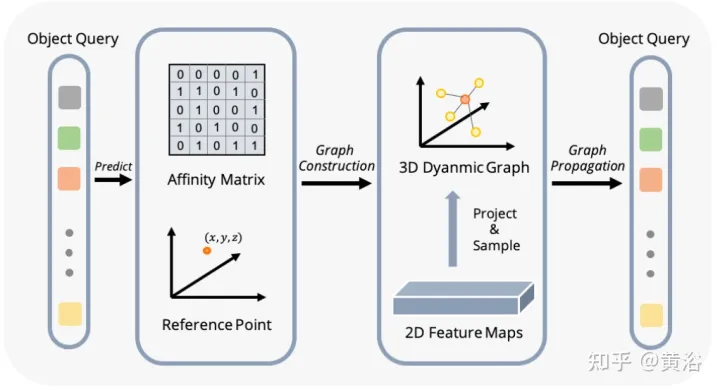
Untuk menyelesaikan masalah ini, Graph-DETR3D dicadangkan untuk mengagregatkan maklumat imej berbilang paparan secara automatik melalui pembelajaran struktur graf (GSL). Peta 3D dinamik dibina antara setiap pertanyaan sasaran dan peta ciri 2-D untuk meningkatkan perwakilan sasaran, terutamanya di kawasan sempadan. Selain itu, Graph-DETR3D mendapat manfaat daripada strategi latihan pelbagai skala invarian kedalaman baharu, yang mengekalkan konsistensi kedalaman visual dengan menskalakan saiz imej dan kedalaman sasaran secara serentak.
Perbezaan Graph-DETR3D terletak pada dua perkara, seperti yang ditunjukkan dalam rajah: (1) modul pengagregatan ciri graf dinamik; (2) strategi latihan pelbagai skala invarian dalam. Ia mengikut struktur asas DETR3D dan terdiri daripada tiga komponen: pengekod imej, penyahkod pengubah dan kepala ramalan sasaran. Memandangkan set imej I = {I1, I2,…,IK} (dirakam oleh N kamera peri-lihat), Graph-DETR3D bertujuan untuk meramalkan lokasi dan kategori kotak sempadan yang menarik. Mula-mula, gunakan pengekod imej (termasuk ResNet dan FPN) untuk menukar imej ini menjadi satu set ciri peringkat peta ciri yang agak L F. Kemudian, graf 3-D dinamik dibina untuk mengagregatkan maklumat 2-D secara meluas melalui modul pengagregatan ciri graf dinamik (DGFA) untuk mengoptimumkan perwakilan pertanyaan sasaran. Akhir sekali, pertanyaan sasaran yang dipertingkatkan digunakan untuk mengeluarkan ramalan akhir.
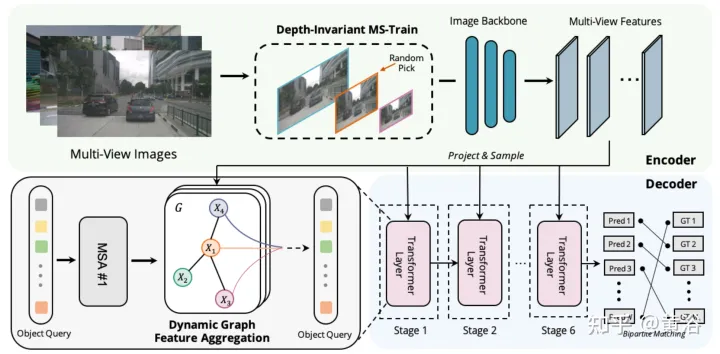
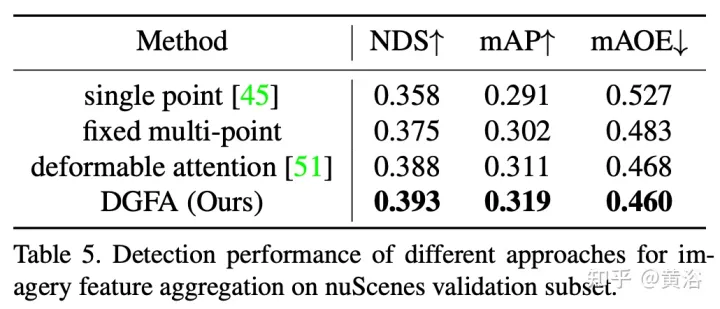
Rajah menunjukkan proses pengagregatan ciri graf dinamik (DFGA): mula-mula bina graf 3-D yang boleh dipelajari untuk setiap pertanyaan sasaran, dan kemudian bina graf 3-D yang boleh dipelajari daripada satah imej 2-D Ciri-ciri Persampelan. Akhir sekali, perwakilan pertanyaan sasaran dipertingkatkan melalui sambungan graf. Skim penyebaran mesej yang saling berkaitan ini menyokong penghalusan berulang pembinaan struktur graf dan peningkatan ciri.
Latihan berbilang skala ialah strategi penambahan data yang biasa digunakan dalam tugas pengesanan objek 2D dan 3D, yang terbukti berkesan dan rendah dalam kos inferens. Walau bagaimanapun, ia jarang muncul dalam kaedah pemeriksaan 3-D berasaskan penglihatan. Mengambil kira saiz imej input yang berbeza boleh meningkatkan keteguhan model, sambil melaraskan saiz imej dan mengubah suai parameter dalaman kamera untuk melaksanakan strategi latihan berbilang skala biasa.
Fenomena menarik ialah prestasi akhir menurun dengan mendadak. Dengan menganalisis data input dengan teliti, kami mendapati bahawa hanya menskala semula imej membawa kepada masalah kekaburan perspektif: apabila sasaran diubah saiz kepada skala yang lebih besar/lebih kecil, sifat mutlaknya (iaitu saiz sasaran, jarak ke ego titik) jangan Berubah.
Sebagai contoh konkrit, rajah menunjukkan masalah samar-samar ini: walaupun kedudukan 3D mutlak kawasan yang dipilih dalam (a) dan (b) adalah sama, bilangan piksel imej adalah berbeza. Rangkaian ramalan kedalaman cenderung untuk menganggarkan kedalaman berdasarkan kawasan yang diduduki oleh imej. Oleh itu, corak latihan dalam rajah ini mungkin mengelirukan model ramalan kedalaman dan merosot lagi prestasi akhir.

Kira semula kedalaman dari perspektif piksel untuk tujuan ini. Pseudokod algoritma adalah seperti berikut:

Berikut ialah operasi penyahkodan:

Saiz piksel yang dikira semula ialah:
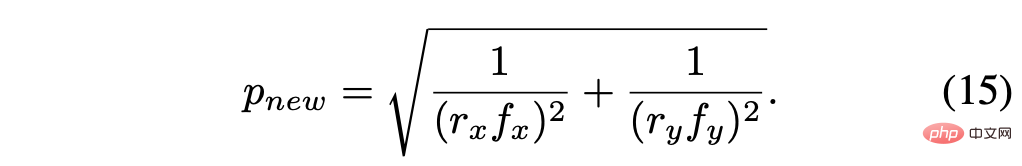
Anggap faktor skala r = rx = ry, kemudian mudahkan untuk mendapatkan:
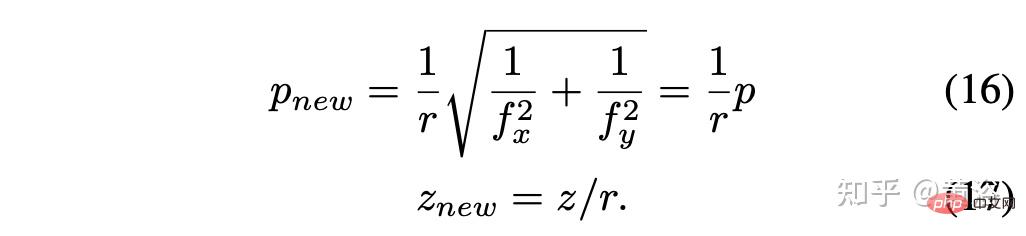
Keputusan percubaan adalah seperti berikut:
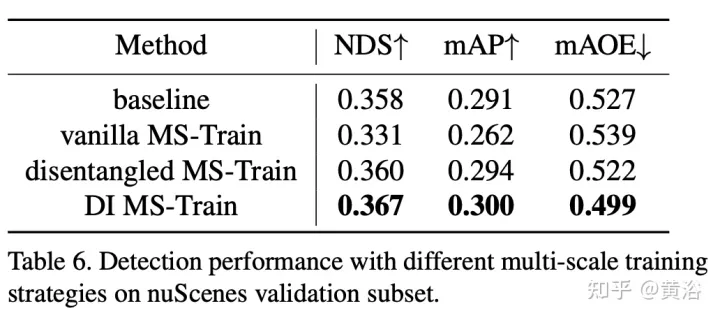
Nota: DI = Kedalaman-Invarian
Atas ialah kandungan terperinci Graf-DETR3D: Memikirkan semula kawasan bertindih dalam pengesanan objek 3D berbilang paparan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?
Mar 06, 2024 pm 05:34 PM
Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?
Mar 06, 2024 pm 05:34 PM
Kertas StableDiffusion3 akhirnya di sini! Model ini dikeluarkan dua minggu lalu dan menggunakan seni bina DiT (DiffusionTransformer) yang sama seperti Sora. Ia menimbulkan kekecohan apabila ia dikeluarkan. Berbanding dengan versi sebelumnya, kualiti imej yang dijana oleh StableDiffusion3 telah dipertingkatkan dengan ketara Ia kini menyokong gesaan berbilang tema, dan kesan penulisan teks juga telah dipertingkatkan, dan aksara bercelaru tidak lagi muncul. StabilityAI menegaskan bahawa StableDiffusion3 ialah satu siri model dengan saiz parameter antara 800M hingga 8B. Julat parameter ini bermakna model boleh dijalankan terus pada banyak peranti mudah alih, dengan ketara mengurangkan penggunaan AI
 Adakah anda benar-benar menguasai penukaran sistem koordinat? Isu berbilang sensor yang tidak dapat dipisahkan daripada pemanduan autonomi
Oct 12, 2023 am 11:21 AM
Adakah anda benar-benar menguasai penukaran sistem koordinat? Isu berbilang sensor yang tidak dapat dipisahkan daripada pemanduan autonomi
Oct 12, 2023 am 11:21 AM
Artikel perintis dan utama pertama terutamanya memperkenalkan beberapa sistem koordinat yang biasa digunakan dalam teknologi pemanduan autonomi, dan cara melengkapkan korelasi dan penukaran antara mereka, dan akhirnya membina model persekitaran bersatu. Fokus di sini adalah untuk memahami penukaran daripada kenderaan kepada badan tegar kamera (parameter luaran), penukaran kamera kepada imej (parameter dalaman) dan penukaran unit imej kepada piksel. Penukaran daripada 3D kepada 2D akan mempunyai herotan, terjemahan, dsb. Perkara utama: Sistem koordinat kenderaan dan sistem koordinat badan kamera perlu ditulis semula: sistem koordinat satah dan sistem koordinat piksel Kesukaran: herotan imej mesti dipertimbangkan Kedua-dua penyahherotan dan penambahan herotan diberi pampasan pada satah imej. 2. Pengenalan Terdapat empat sistem penglihatan secara keseluruhannya: sistem koordinat satah piksel (u, v), sistem koordinat imej (x, y), sistem koordinat kamera () dan sistem koordinat dunia (). Terdapat hubungan antara setiap sistem koordinat,
 Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Artikel ini sudah cukup untuk anda membaca tentang pemanduan autonomi dan ramalan trajektori!
Feb 28, 2024 pm 07:20 PM
Ramalan trajektori memainkan peranan penting dalam pemanduan autonomi Ramalan trajektori pemanduan autonomi merujuk kepada meramalkan trajektori pemanduan masa hadapan kenderaan dengan menganalisis pelbagai data semasa proses pemanduan kenderaan. Sebagai modul teras pemanduan autonomi, kualiti ramalan trajektori adalah penting untuk kawalan perancangan hiliran. Tugas ramalan trajektori mempunyai timbunan teknologi yang kaya dan memerlukan kebiasaan dengan persepsi dinamik/statik pemanduan autonomi, peta ketepatan tinggi, garisan lorong, kemahiran seni bina rangkaian saraf (CNN&GNN&Transformer), dll. Sangat sukar untuk bermula! Ramai peminat berharap untuk memulakan ramalan trajektori secepat mungkin dan mengelakkan perangkap Hari ini saya akan mengambil kira beberapa masalah biasa dan kaedah pembelajaran pengenalan untuk ramalan trajektori! Pengetahuan berkaitan pengenalan 1. Adakah kertas pratonton teratur? A: Tengok survey dulu, hlm
 Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Jun 01, 2024 pm 09:46 PM
Anotasi kotak sempadan berlebihan berbilang grid untuk pengesanan objek yang tepat
Jun 01, 2024 pm 09:46 PM
1. Pengenalan Pada masa ini, pengesan objek utama ialah rangkaian dua peringkat atau satu peringkat berdasarkan rangkaian pengelas tulang belakang yang digunakan semula CNN dalam. YOLOv3 ialah salah satu pengesan satu peringkat tercanggih yang menerima imej input dan membahagikannya kepada matriks grid bersaiz sama. Sel grid dengan pusat sasaran bertanggungjawab untuk mengesan sasaran tertentu. Apa yang saya kongsikan hari ini ialah kaedah matematik baharu yang memperuntukkan berbilang grid kepada setiap sasaran untuk mencapai ramalan kotak sempadan ketat muat yang tepat. Para penyelidik juga mencadangkan peningkatan data salin-tampal luar talian yang berkesan untuk pengesanan sasaran. Kaedah yang baru dicadangkan dengan ketara mengatasi beberapa pengesan objek terkini dan menjanjikan prestasi yang lebih baik. 2. Rangkaian pengesanan sasaran latar belakang direka bentuk untuk digunakan
 SOTA baharu untuk pengesanan sasaran: YOLOv9 keluar, dan seni bina baharu menghidupkan semula konvolusi tradisional
Feb 23, 2024 pm 12:49 PM
SOTA baharu untuk pengesanan sasaran: YOLOv9 keluar, dan seni bina baharu menghidupkan semula konvolusi tradisional
Feb 23, 2024 pm 12:49 PM
Dalam bidang pengesanan sasaran, YOLOv9 terus membuat kemajuan dalam proses pelaksanaan Dengan mengguna pakai seni bina dan kaedah baharu, ia secara berkesan meningkatkan penggunaan parameter konvolusi tradisional, yang menjadikan prestasinya jauh lebih unggul daripada produk generasi sebelumnya. Lebih setahun selepas YOLOv8 dikeluarkan secara rasmi pada Januari 2023, YOLOv9 akhirnya hadir! Sejak Joseph Redmon, Ali Farhadi dan yang lain mencadangkan model YOLO generasi pertama pada 2015, penyelidik dalam bidang pengesanan sasaran telah mengemas kini dan mengulanginya berkali-kali. YOLO ialah sistem ramalan berdasarkan maklumat global imej, dan prestasi modelnya terus dipertingkatkan. Dengan menambah baik algoritma dan teknologi secara berterusan, penyelidik telah mencapai hasil yang luar biasa, menjadikan YOLO semakin berkuasa dalam tugas pengesanan sasaran.
 DualBEV: mengatasi BEVFormer dan BEVDet4D dengan ketara, buka buku!
Mar 21, 2024 pm 05:21 PM
DualBEV: mengatasi BEVFormer dan BEVDet4D dengan ketara, buka buku!
Mar 21, 2024 pm 05:21 PM
Kertas kerja ini meneroka masalah mengesan objek dengan tepat dari sudut pandangan yang berbeza (seperti perspektif dan pandangan mata burung) dalam pemanduan autonomi, terutamanya cara mengubah ciri dari perspektif (PV) kepada ruang pandangan mata burung (BEV) dengan berkesan dilaksanakan melalui modul Transformasi Visual (VT). Kaedah sedia ada secara amnya dibahagikan kepada dua strategi: penukaran 2D kepada 3D dan 3D kepada 2D. Kaedah 2D-ke-3D meningkatkan ciri 2D yang padat dengan meramalkan kebarangkalian kedalaman, tetapi ketidakpastian yang wujud dalam ramalan kedalaman, terutamanya di kawasan yang jauh, mungkin menimbulkan ketidaktepatan. Manakala kaedah 3D ke 2D biasanya menggunakan pertanyaan 3D untuk mencuba ciri 2D dan mempelajari berat perhatian bagi kesesuaian antara ciri 3D dan 2D melalui Transformer, yang meningkatkan masa pengiraan dan penggunaan.
 Model dunia penjanaan video adegan pemanduan berbilang paparan autonomi |
Oct 23, 2023 am 11:13 AM
Model dunia penjanaan video adegan pemanduan berbilang paparan autonomi |
Oct 23, 2023 am 11:13 AM
Beberapa pemikiran peribadi pengarang Dalam bidang pemanduan autonomi, dengan pembangunan sub-tugas/penyelesaian hujung-ke-hujung berasaskan BEV, data latihan berbilang paparan berkualiti tinggi dan pembinaan adegan simulasi yang sepadan telah menjadi semakin penting. Sebagai tindak balas kepada titik kesakitan tugas semasa, "kualiti tinggi" boleh dipecahkan kepada tiga aspek: senario ekor panjang dalam dimensi berbeza: seperti kenderaan jarak dekat dalam data halangan dan sudut arah tepat semasa pemotongan kereta, dan data garis lorong. . Ini selalunya bergantung pada sejumlah besar pengumpulan data dan strategi perlombongan data yang kompleks, yang memerlukan kos yang tinggi. Nilai sebenar 3D - imej sangat konsisten: Pemerolehan data BEV semasa sering dipengaruhi oleh ralat dalam pemasangan/penentukuran sensor, peta berketepatan tinggi dan algoritma pembinaan semula itu sendiri. ini membawa saya kepada
 GSLAM |. Seni bina dan penanda aras umum SLAM
Oct 20, 2023 am 11:37 AM
GSLAM |. Seni bina dan penanda aras umum SLAM
Oct 20, 2023 am 11:37 AM
Tiba-tiba menemui kertas 19 tahun GSLAM: Rangka Kerja SLAM Umum dan kod sumber terbuka Penanda Aras: https://github.com/zdzhaoyong/GSLAM Pergi terus ke teks penuh dan rasai kualiti karya ini~1 Teknologi SLAM Abstrak telah mencapai banyak kejayaan baru-baru ini dan menarik ramai yang menarik perhatian syarikat berteknologi tinggi. Walau bagaimanapun, cara untuk antara muka dengan algoritma sedia ada atau yang baru muncul untuk melaksanakan penandaarasan dengan cekap pada kelajuan, kekukuhan dan mudah alih masih menjadi persoalan. Dalam kertas kerja ini, satu platform SLAM baharu yang dipanggil GSLAM dicadangkan, yang bukan sahaja menyediakan keupayaan penilaian tetapi juga menyediakan penyelidik dengan cara yang berguna untuk membangunkan sistem SLAM mereka sendiri dengan pantas.
