
 Peranti teknologi
AI
Laporan mendalam: AI dipacu model besar mempercepatkan seluruh papan! Dekad emas bermula
Peranti teknologi
AI
Laporan mendalam: AI dipacu model besar mempercepatkan seluruh papan! Dekad emas bermula
Laporan mendalam: AI dipacu model besar mempercepatkan seluruh papan! Dekad emas bermula

Selepas mengalami "tiga naik dan dua turun" dalam tempoh 70 tahun yang lalu, dengan peningkatan & kemajuan cip asas, kuasa pengkomputeran, data dan infrastruktur lain, industri AI global secara beransur-ansur beralih daripada kecerdasan pengiraan kepada kecerdasan persepsi dan kognitif kecerdasan, dan sedang membentuk dengan sewajarnya Bahagian industri buruh dan sistem kerjasama "cip, kemudahan pengkomputeran, rangka kerja AI & model algoritma, dan senario aplikasi". Sejak 2019, model besar AI telah meningkatkan keupayaan untuk membuat generalisasi penyelesaian masalah dengan ketara, dan "model besar + model kecil" secara beransur-ansur menjadi laluan teknologi arus perdana dalam industri, memacu pecutan keseluruhan pembangunan industri AI global dan membentuk "cip + infrastruktur kuasa pengkomputeran + AI Struktur rantaian nilai industri yang stabil bagi "rangka kerja & perpustakaan algoritma + senario aplikasi".
Untuk rujukan dalaman yang bijak dalam keluaran ini, kami mengesyorkan laporan CITIC Securities "Model Besar Memacu AI untuk Mempercepat Secara Komprehensif, dan Kitaran Pelaburan Sepuluh Tahun Keemasan Industri Bermula" untuk mentafsir status semasa kecerdasan buatan industri dan isu teras dalam pembangunan industri. Sumber: CITIC Securities
1. "Tiga Naik dan Tiga Turun" Kecerdasan Buatan
Memandangkan konsep & teori "kecerdasan buatan" mula dicadangkan pada tahun 1956, pembangunan industri AI & teknologi telah mengalami tiga peringkat pembangunan utama.
1 ) 20 Abad 50 Era ~20 Abad 70 Era: Terhad oleh prestasi pengkomputeran, volum data, dsb., ia kekal lebih pada tahap teori . Persidangan Dartmouth pada tahun 1956 mempromosikan kemunculan gelombang pertama kecerdasan buatan di dunia Pada masa itu, suasana optimis meresap ke seluruh dunia akademik, dan banyak ciptaan bertaraf dunia muncul dari segi algoritma, termasuk kaedah yang dipanggil pengukuhan. pembelajaran Dalam bentuk prototaipnya, pembelajaran pengukuhan adalah idea teras algoritma AlphaGo Google. Pada awal tahun 1970-an, AI mengalami kesesakan: orang ramai mendapati bahawa pemisah logik, perceptron, pembelajaran pengukuhan, dll. hanya boleh melakukan tugasan yang sangat mudah dan bertujuan sempit, dan tidak dapat mengendalikan tugas yang berada di luar skop mereka. Memori terhad dan kelajuan pemprosesan komputer pada masa itu tidak mencukupi untuk menyelesaikan sebarang masalah AI praktikal. Kerumitan pengiraan ini meningkat secara eksponen, menjadikannya tugas pengiraan yang mustahil.
2 ) 20 Abad 80 Era ~20 Abad 90 Era: Sistem pakar ialah percubaan pengkomersilan pertama kecerdasan buatan, dengan kos perkakasan yang tinggi, Senario terpakai terhad menyekat pembangunan selanjutnya pasaran. Pada tahun 1980-an, program AI sistem pakar mula diterima pakai oleh syarikat di seluruh dunia, dan "pemprosesan pengetahuan" menjadi tumpuan penyelidikan AI arus perdana. Keupayaan sistem pakar datang daripada pengetahuan profesional yang mereka simpan, dan sistem asas pengetahuan dan kejuruteraan pengetahuan menjadi hala tuju utama penyelidikan AI pada 1980-an. Walau bagaimanapun, kepraktisan sistem pakar terhad kepada situasi tertentu, dan keghairahan orang ramai terhadap sistem pakar tidak lama kemudian bertukar kepada kekecewaan yang besar. Sebaliknya, kemunculan PC moden dari 1987 hingga 1993 jauh lebih murah daripada mesin seperti Symbolics dan Lisp yang digunakan oleh sistem pakar. Berbanding dengan PC moden, sistem pakar dianggap kuno dan sangat sukar untuk diselenggara. Akibatnya, pembiayaan kerajaan mula merosot, dan musim sejuk datang lagi.
3) 2015 Tahun hingga kini: Secara beransur-ansur membentuk satu rantaian perindustrian bahagian buruh dan sistem kerjasama. Peristiwa penting kecerdasan buatan ketiga berlaku pada Mac 2016. AlphaGo yang dibangunkan oleh Google DeepMind mengalahkan pemain sembilan dan profesional Korea Lee Sedol dalam pertempuran manusia-mesin Go. Selepas itu, orang ramai menjadi biasa dengan kecerdasan buatan, dan semangat digerakkan dalam pelbagai bidang. Insiden ini mewujudkan model pembelajaran mendalam klasifikasi statistik berdasarkan algoritma rangkaian saraf DNN Model jenis ini lebih umum berbanding sebelum ini dan boleh digunakan pada senario aplikasi yang berbeza melalui pengekstrakan nilai ciri yang berbeza. Pada masa yang sama, populariti Internet mudah alih dari 2010 hingga 2015 turut membawa khasiat data yang belum pernah berlaku sebelum ini kepada algoritma pembelajaran mendalam. Terima kasih kepada peningkatan dalam volum data, peningkatan dalam kuasa pengkomputeran dan kemunculan algoritma pembelajaran mesin baharu, kecerdasan buatan telah mula menjalani pelarasan besar. Bidang penyelidikan kecerdasan buatan juga berkembang, termasuk sistem pakar, pembelajaran mesin, pengkomputeran evolusi, logik kabur, penglihatan komputer, pemprosesan bahasa semula jadi, sistem pengesyoran, dsb. Perkembangan pembelajaran mendalam telah membawa kecerdasan buatan ke dalam klimaks pembangunan baharu.
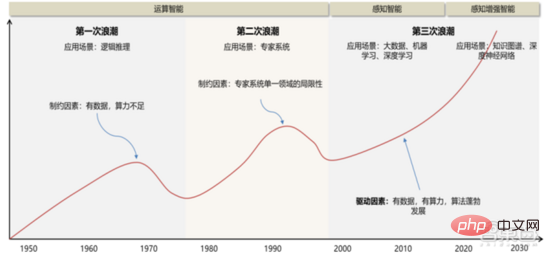 ▲ Gelombang ketiga pembangunan kecerdasan buatan
▲ Gelombang ketiga pembangunan kecerdasan buatan
Gelombang ketiga kecerdasan buatan membawa kepada kita beberapa senario yang boleh dikomersialkan, seperti DNN algoritma Prestasi cemerlang membolehkan pengecaman pertuturan dan pengecaman imej menyumbang kumpulan pertama kes perniagaan yang berjaya dalam bidang keselamatan dan pendidikan. Dalam beberapa tahun kebelakangan ini, pembangunan algoritma seperti Transformer berdasarkan algoritma rangkaian saraf telah meletakkan pengkomersilan NLP (pemprosesan bahasa semula jadi) dalam agenda, dan ia dijangka melihat senario pengkomersilan matang dalam 3-5 tahun akan datang.
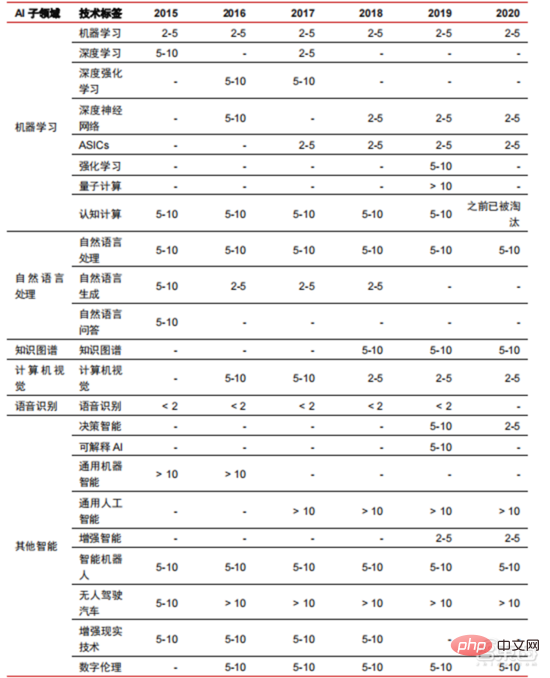
▲ Bilangan tahun yang diperlukan untuk perindustrian teknologi kecerdasan buatan
2 Pembahagian kerja secara beransur-ansur selesai, dan senario pelaksanaan sentiasa berkembang
.Selepas 5 hingga 6 tahun yang lalu Dengan perkembangan itu, industri AI global secara beransur-ansur membentuk pembahagian kerja dan kerjasama serta struktur rantaian industri yang lengkap, dan mula membentuk senario aplikasi biasa dalam beberapa bidang.
1. Cip AI: daripada GPU kepada FPGA, ASIC, dsb., prestasi terus meningkat
Chip ialah ketinggian yang menguasai AI industri . Kemakmuran pusingan industri kecerdasan buatan ini adalah disebabkan oleh kuasa pengkomputeran AI yang dipertingkatkan, yang membolehkan pembelajaran mendalam dan algoritma rangkaian saraf berbilang lapisan. Kecerdasan Buatan Kecerdasan buatan meresap dengan pantas ke dalam pelbagai industri, dan data berkembang secara besar-besaran Ini menghasilkan model algoritma yang sangat kompleks, objek pemprosesan heterogen dan keperluan prestasi pengkomputeran yang tinggi. Oleh itu, pembelajaran mendalam kecerdasan buatan memerlukan keupayaan pemprosesan selari yang sangat berkuasa Berbanding dengan CPU, cip AI mempunyai lebih banyak unit operasi logik (ALU) untuk pemprosesan data dan sesuai untuk pemprosesan selari data intensif. tatasusunan get boleh atur cara medan (FPGA), litar bersepadu khusus aplikasi (ASIC), dsb.
Dari perspektif senario penggunaan, perkakasan yang berkaitan termasuk: cip inferens sisi awan, cip ujian sisi awan, cip pemprosesan terminal, teras IP, dsb. Dalam bahagian "latihan" atau "pembelajaran" awan, NVIDIA GPU mempunyai kelebihan daya saing yang kuat, dan Google TPU juga sedang giat mengembangkan pasaran dan aplikasinya. FPGA dan ASIC mungkin mempunyai kelebihan dalam aplikasi "inferens" penggunaan akhir. Amerika Syarikat mempunyai kelebihan yang kukuh dalam bidang GPU dan FPGA, dengan syarikat berfaedah seperti NVIDIA, Xilinx, dan Google dan Amazon juga sedang giat membangunkan cip AI.
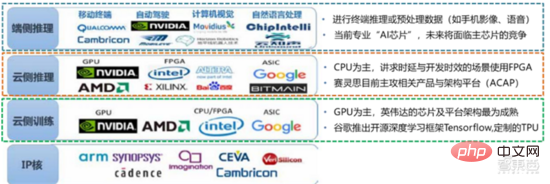
▲ Aplikasi cip dalam pautan AI yang berbeza
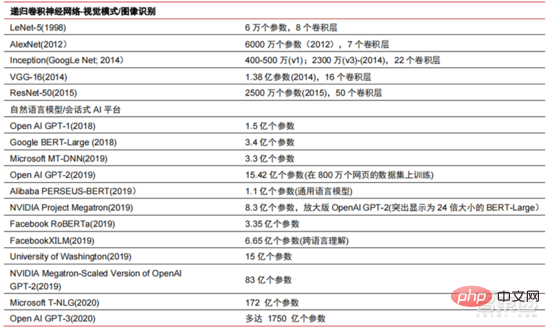
▲ Kerumitan model algoritma rangkaian neural kecerdasan buatan
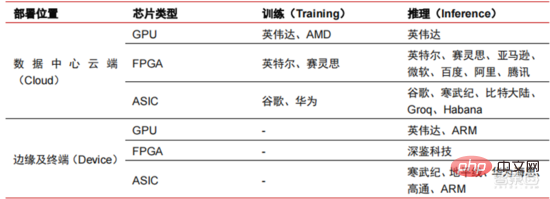
▲ Susun atur pengeluar cip
Dalam pasaran pengkomputeran berprestasi tinggi, menyelesaikan masalah kompleks dengan bantuan keupayaan pengkomputeran selari cip AI kini merupakan penyelesaian arus perdana. Menurut data Tractica, saiz pasaran AI HPC global adalah kira-kira AS$1.36 bilion pada 2019, dan saiz pasaran dijangka mencecah AS$11.19 bilion menjelang 2025, dengan CAGR tujuh tahun sebanyak 35.1%. Bahagian pasaran AI HPC akan meningkat daripada 13.2% pada 2019 kepada 35.5% pada 2025. Pada masa yang sama, data Tractica menunjukkan bahawa saiz pasaran cip AI global ialah AS$6.4 bilion pada 2019, dan saiz pasaran dijangka mencecah AS$51 bilion menjelang 2023, dengan ruang pasaran berkembang hampir 10 kali ganda.
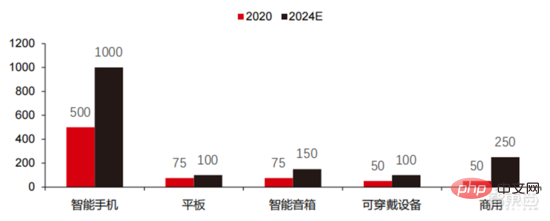
▲ Penghantaran cip pengkomputeran tepi (berjuta-juta, mengikut peranti terminal)
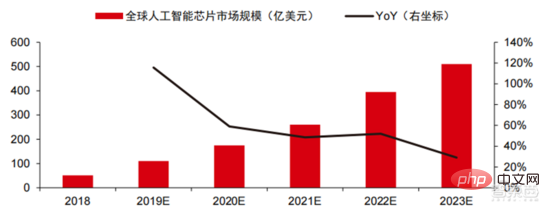
▲ Cip kecerdasan buatan global Saiz pasaran ( USD 100 juta)
Dalam tempoh dua tahun yang lalu, sejumlah besar syarikat cip yang dibangunkan sendiri telah muncul di China, diwakili oleh Moore Thread, yang membangunkan GPU yang dibangunkan sendiri, dan Cambrian, yang membangunkan yang dibangunkan sendiri. cip pemanduan autonomi. Moore Thread mengeluarkan seni bina sistem bersatu MUSA dan cip generasi pertama "Sudi" pada Mac 2022. Seni bina baharu Moore Thread menyokong seni bina CUDA NVIDIA. Menurut data IDC, antara cip kecerdasan buatan China pada separuh pertama tahun 2021, GPU telah menjadi pilihan pertama dalam pasaran, menyumbang lebih daripada 90% bahagian pasaran Walau bagaimanapun, dengan pembangunan stabil cip lain, ia adalah menjangkakan bahawa bahagian GPU akan berkurangan secara beransur-ansur kepada 80% menjelang 2025. .
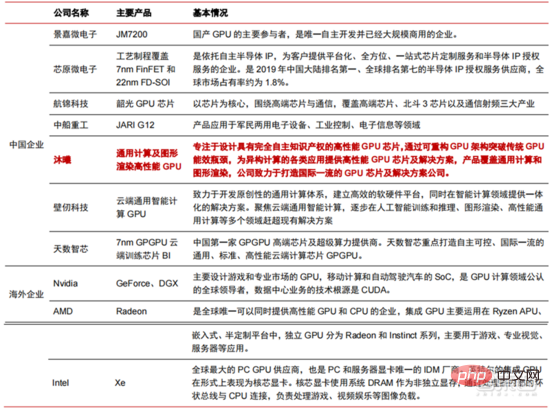
▲ pemain utama cip GPU dan peta jalan teknikal
2. Kemudahan kuasa pengkomputeran: Dengan bantuan pengkomputeran awan, pembinaan sendiri dan kaedah lain, penunjuk seperti skala kuasa pengkomputeran dan kos unit telah dipertingkatkan secara berterusan
Pada masa lalu, pembangunan kuasa pengkomputeran telah berkesan mengurangkan kesesakan pembangunan kecerdasan buatan. Sebagai konsep purba, kecerdasan buatan telah dihadkan dalam pembangunan masa lalunya oleh kuasa pengkomputeran yang tidak mencukupi keperluan kuasa pengkomputerannya terutamanya datang dari dua aspek: 1) Salah satu cabaran terbesar kecerdasan buatan ialah ketidakkonsistenan antara pengecaman dan ketepatan. Tinggi, dan untuk meningkatkan ketepatan, adalah perlu untuk meningkatkan skala dan ketepatan model, yang memerlukan sokongan kuasa pengkomputeran yang lebih kuat. 2) Memandangkan senario aplikasi kecerdasan buatan dilaksanakan secara beransur-ansur, data dalam bidang imej, suara, penglihatan mesin dan permainan telah menunjukkan pertumbuhan yang meletup, yang juga telah mengemukakan keperluan yang lebih tinggi untuk kuasa pengkomputeran, menjadikan teknologi pengkomputeran memasuki pusingan baharu tempoh inovasi berkelajuan tinggi. Perkembangan kuasa pengkomputeran dalam dekad yang lalu atau lebih telah mengurangkan kesesakan pembangunan kecerdasan buatan pada masa hadapan, pengkomputeran pintar akan menunjukkan ciri-ciri permintaan yang lebih besar, keperluan prestasi yang lebih tinggi, dan keperluan yang pelbagai pada bila-bila masa, di mana-mana sahaja.
Memandangkan ia menghampiri had fizikal, Undang-undang Moore untuk pertumbuhan kuasa pengkomputeran akan tamat tempoh secara beransur-ansur, dan industri kuasa pengkomputeran berada dalam peringkat inovasi komprehensif pelbagai faktor . Pada masa lalu, bekalan kuasa pengkomputeran telah dipertingkatkan terutamanya melalui pengecutan proses, iaitu, menambah bilangan tindanan transistor dalam cip yang sama untuk meningkatkan prestasi pengkomputeran. Walau bagaimanapun, apabila proses terus menghampiri had fizikal dan kos terus meningkat, Undang-undang Moore secara beransur-ansur menjadi tidak berkesan Industri kuasa pengkomputeran memasuki era pasca-Moore, dan bekalan kuasa pengkomputeran perlu dipertingkatkan melalui inovasi komprehensif pelbagai faktor. Pada masa ini terdapat empat tahap bekalan kuasa pengkomputeran: kuasa pengkomputeran cip tunggal, kuasa pengkomputeran mesin lengkap, kuasa pengkomputeran pusat data dan kuasa pengkomputeran rangkaian, yang terus berkembang dan menaik taraf melalui teknologi yang berbeza untuk memenuhi keperluan bekalan kuasa pengkomputeran yang pelbagai dalam zaman pintar. Selain itu, meningkatkan prestasi keseluruhan sistem pengkomputeran melalui penyepaduan mendalam sistem perisian dan perkakasan serta pengoptimuman algoritma juga merupakan hala tuju penting untuk evolusi industri kuasa pengkomputeran.
Skala kuasa pengkomputeran: Menurut "Kertas Putih Indeks Pembangunan Kuasa Pengkomputeran China" yang dikeluarkan oleh Akademi Teknologi Maklumat dan Komunikasi China pada 2021, jumlah skala kuasa pengkomputeran global masih akan mengekalkan trend pertumbuhan pada tahun 2020, dengan jumlah skala mencapai 429EFlops Peningkatan tahun ke tahun sebanyak 39%, yang mana skala kuasa pengkomputeran asas ialah 313EFlops, skala kuasa pengkomputeran pintar ialah 107EFlops, dan skala kuasa pengkomputeran super ialah 9EFlops. . Perkadaran kuasa pengkomputeran pintar telah meningkat. Kadar pembangunan kuasa pengkomputeran negara saya adalah serupa dengan dunia Pada tahun 2020, jumlah skala kuasa pengkomputeran negara saya mencapai 135EFlops, menyumbang 39% daripada skala kuasa pengkomputeran global, mencapai pertumbuhan tinggi sebanyak 55%, dan. mencapai kadar pertumbuhan lebih daripada 40% selama tiga tahun berturut-turut.
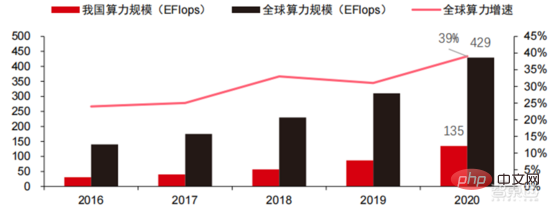
▲ Perubahan dalam skala kuasa pengkomputeran global
Struktur kuasa pengkomputeran: situasi pembangunan negara saya serupa dengan keadaan dunia, dan kuasa pengkomputeran pintar berkembang pesat Perkadaran itu meningkat daripada 3% pada 2016 kepada 41% pada 2020. Perkadaran kuasa pengkomputeran asas menurun daripada 95% pada 2016 kepada 57% pada 2020. Didorong oleh permintaan hiliran, infrastruktur kuasa pengkomputeran kecerdasan buatan yang diwakili oleh pusat pengkomputeran pintar telah berkembang pesat. Pada masa yang sama, dari segi permintaan masa hadapan, menurut laporan "Ubiquitous Computing Power: Cornerstone of an Intelligent Society" yang dikeluarkan oleh Huawei pada 2020, dengan mempopularkan kecerdasan buatan, dijangka menjelang 2030, permintaan untuk tiruan kuasa pengkomputeran perisikan akan bersamaan dengan 160 bilion cip Qualcomm Snapdragon 855 mempunyai cip AI terbina dalam, yang bersamaan dengan kira-kira 390 kali ganda pada 2018 dan kira-kira 120 kali ganda pada 2020.
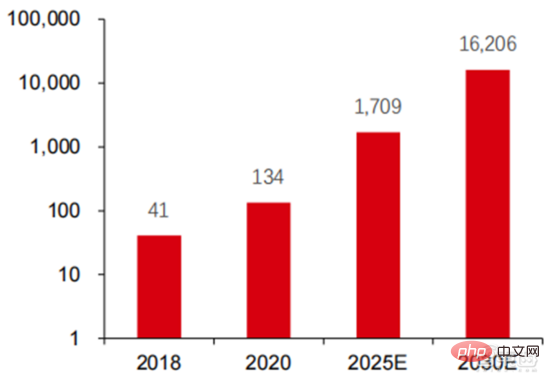
▲ Anggaran permintaan kuasa pengkomputeran kecerdasan buatan (EFlops) pada tahun 2030
Storan data: pangkalan data bukan perhubungan dan digunakan untuk menyimpan serta mengurus bukan -pangkalan data hubungan Tasik data untuk data berstruktur sedang mengalami ledakan permintaan. Jumlah data global telah menunjukkan pertumbuhan yang pesat dalam beberapa tahun kebelakangan ini, menurut statistik IDC, jumlah data yang dijana secara global pada tahun 2019 ialah 41ZB dalam tempoh sepuluh tahun yang lalu adalah hampir 50%. jumlah data global mungkin setinggi 175ZB menjelang 2025, 2019-2025 Ia masih akan mengekalkan kadar pertumbuhan kompaun hampir 30% setiap tahun, dan lebih daripada 80% data akan menjadi data tidak berstruktur seperti teks, imej, audio dan video, yang sukar diproses. Lonjakan dalam jumlah data (terutamanya data tidak berstruktur) telah menjadikan kelemahan pangkalan data hubungan semakin ketara Dalam menghadapi pertumbuhan eksponen geometri dalam data, model sambungan data susun menegak pangkalan data hubungan tradisional yang direka untuk data berstruktur sukar untuk dipenuhi. .
Pangkalan data bukan perhubungan dan tasik data yang digunakan untuk menyimpan dan mengurus data tidak berstruktur secara beransur-ansur menduduki bahagian pasaran yang semakin meningkat disebabkan fleksibiliti dan kebolehskalaan yang mudah. Menurut IDC, saiz pasaran pangkalan data Nosql global ialah AS$5.6 bilion pada 2020 dan dijangka meningkat kepada AS$19 bilion pada 2025, dengan kadar pertumbuhan kompaun sebanyak 27.6% dari 2020 hingga 2025. Pada masa yang sama, menurut IDC, saiz pasaran tasik data global ialah AS$6.2 bilion pada 2020, dan kadar pertumbuhan saiz pasaran pada 2020 ialah 34.4%.
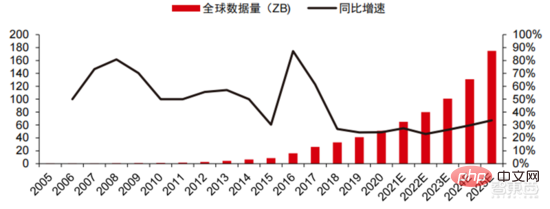
▲ Jumlah data global dan kadar pertumbuhan tahun ke tahun (ZB, %)
3 Rangka kerja AI: agak matang, dikuasai oleh beberapa gergasi
Tensorflow<.> (Industri), PyTorch (Academia) secara beransur-ansur mencapai penguasaan. Tensorflow yang dilancarkan oleh Google ialah arus perdana, dan bersama-sama modul sumber terbuka lain seperti Keras (Tensorflow2 menyepadukan modul Keras), sumber terbuka Facebook PyTorch, dll., ia membentuk rangka kerja arus perdana semasa untuk pembelajaran AI. Sejak penubuhannya pada 2011, Google Brain telah menjalankan penyelidikan aplikasi pembelajaran mendalam berskala besar untuk penyelidikan saintifik dan pembangunan produk Google. Kerja awalnya ialah DistBelief, pendahulu TensorFlow. DistBelief diperhalusi dan digunakan secara meluas dalam pembangunan produk di Google dan syarikat milik Alphabet yang lain. Pada November 2015, berdasarkan DistBelief, Google Brain menyelesaikan pembangunan TensorFlow, "sistem pembelajaran mesin generasi kedua" dan menjadikan kod sumber terbuka. Berbanding dengan pendahulunya, TensorFlow mempunyai peningkatan yang ketara dalam prestasi, fleksibiliti seni bina dan mudah alih.
Walaupun Tensorflow dan Pytorch adalah modul sumber terbuka itu sendiri, disebabkan model besar dan kerumitan rangka kerja pembelajaran mendalam, pengubahsuaian dan kemas kininya pada asasnya diselesaikan oleh Google. Hasilnya, Google dan Facebook juga telah mengemas kini Tensorflow dan PyTorch secara langsung mendominasi model pembangunan industri kecerdasan buatan.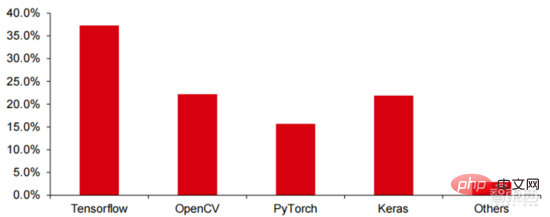
Pembelajaran mendalam sedang beralih kepada rangkaian saraf dalam. Pembelajaran mesin ialah algoritma komputer yang meramalkan data seperti imej dan bunyi melalui pembelajaran ciri tak linear berbilang lapisan dan pengekstrakan ciri hierarki. Pembelajaran mendalam ialah pembelajaran mesin lanjutan, juga dikenali sebagai rangkaian saraf dalam (DNN: Rangkaian Neural Dalam). Rangkaian saraf dan kaedah latihan yang berbeza diwujudkan untuk latihan dan inferens dalam senario (maklumat) yang berbeza, dan latihan ialah proses mengoptimumkan berat dan arah penghantaran setiap neuron melalui potongan data yang besar. Rangkaian saraf konvolusi boleh mempertimbangkan piksel tunggal dan pembolehubah persekitaran sekeliling, dan memudahkan jumlah pengekstrakan data, meningkatkan lagi kecekapan algoritma rangkaian saraf.
Algoritma rangkaian saraf telah menjadi teras pemprosesan data besar. AI menjalankan pembelajaran mendalam melalui data berlabel besar-besaran, mengoptimumkan rangkaian dan model saraf, dan memperkenalkan pautan aplikasi penaakulan dan membuat keputusan. Tahun 1990-an adalah tempoh peningkatan pesat dalam pembelajaran mesin dan algoritma rangkaian saraf, dan algoritma digunakan secara komersil dengan sokongan kuasa pengkomputeran. Selepas 1990-an, bidang aplikasi praktikal teknologi AI termasuk perlombongan data, robot industri, logistik, pengecaman pertuturan, perisian perbankan, diagnosis perubatan dan enjin carian, dsb. Rangka kerja algoritma berkaitan telah menjadi tumpuan susun atur gergasi teknologi.
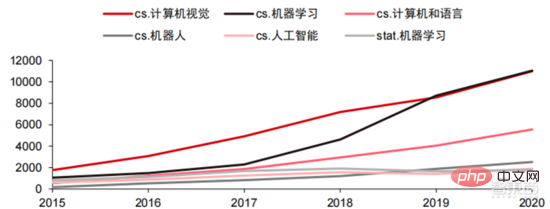
Dari segi hala tuju teknikal, visi komputer dan pembelajaran mesin adalah penyelidikan dan pembangunan teknologi utama arah. Menurut data ARXIV, dari perspektif penyelidikan teori, dua bidang penglihatan komputer dan pembelajaran mesin berkembang pesat dari 2015 hingga 2020, diikuti oleh bidang robotik. Pada tahun 2020, antara penerbitan berkaitan AI tentang ARXIV, bilangan penerbitan dalam bidang penglihatan komputer melebihi 11,000, menduduki tempat pertama dalam bilangan penerbitan berkaitan AI.
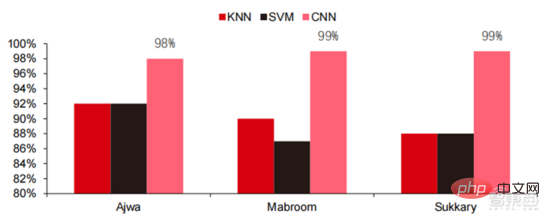
Dalam lima tahun yang lalu, kami telah memerhatikan bahawa algoritma rangkaian saraf, terutamanya CNN dan DNN, adalah algoritma pembelajaran mesin yang paling pesat berkembang dalam beberapa tahun kebelakangan ini Disebabkan prestasi cemerlangnya dalam penglihatan komputer, pemprosesan bahasa semula jadi dan bidang lain. prestasi mereka telah mempercepatkan dengan ketara Ia telah mempercepatkan pelaksanaan aplikasi kecerdasan buatan dan merupakan faktor utama dalam kematangan pesat penglihatan komputer dan kecerdasan membuat keputusan. Seperti yang dapat dilihat dari pandangan sisi, kaedah DNN standard mempunyai kelebihan yang jelas berbanding kaedah tradisional KNN, SVM, dan hutan rawak dalam tugasan pengecaman pertuturan.
▲ Algoritma lilitan menembusi kesesakan ketepatan pemprosesan imej tradisional dan tersedia secara industri buat kali pertama
Dari segi kos latihan , algoritma rangkaian saraf Kos latihan kecerdasan buatan telah menurun dengan ketara. ImageNet ialah set data yang mengandungi lebih 14 juta imej yang digunakan untuk melatih algoritma kecerdasan buatan. Menurut ujian oleh pasukan Stanford DAWNBench, latihan sistem pengecaman imej moden pada tahun 2020 hanya berharga kira-kira AS$7.5, penurunan lebih daripada 99% daripada AS$1,100 pada tahun 2017. Ini terutamanya disebabkan oleh pengoptimuman reka bentuk algoritma, pengurangan kos kuasa pengkomputeran, dan Kemajuan dalam infrastruktur latihan AI berskala besar. Lebih pantas sistem boleh dilatih, lebih pantas ia boleh dinilai dan dikemas kini dengan data baharu, yang akan mempercepatkan lagi latihan sistem ImageNet dan meningkatkan produktiviti membangunkan dan menggunakan sistem kecerdasan buatan.
Melihat pada pengagihan masa latihan, masa yang diperlukan untuk latihan algoritma rangkaian saraf telah dikurangkan secara menyeluruh. Dengan menganalisis pengagihan masa latihan dalam setiap tempoh, didapati bahawa dalam beberapa tahun kebelakangan ini, masa latihan telah sangat dipendekkan dan pengagihan masa latihan menjadi lebih tertumpu, yang terutamanya mendapat manfaat daripada penggunaan meluas cip pemecut.
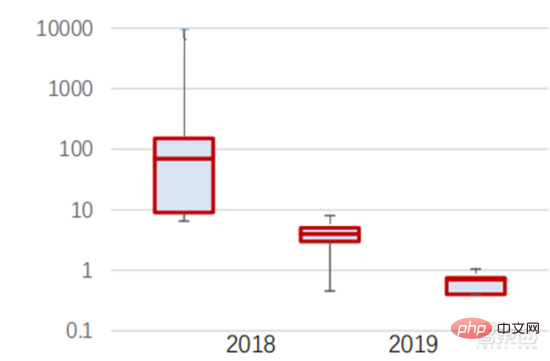
▲ Pengagihan masa latihan ImageNet (minit)
Didorong oleh rangkaian saraf konvolusi, markah ujian ketepatan penglihatan komputer telah meningkat dengan ketara peringkat perindustrian. Ketepatan penglihatan komputer telah mencapai kemajuan yang luar biasa dalam dekad yang lalu, terutamanya disebabkan oleh penerapan teknologi pembelajaran mesin. Ujian Ketepatan Top-1 Lebih baik sistem AI menetapkan label yang betul pada imej, lebih serupa ramalannya (antara semua label yang mungkin) adalah dengan label sasaran. Dengan data latihan tambahan (seperti foto daripada media sosial), terdapat 1 ralat setiap 10 percubaan pada ujian ketepatan Top-1 pada Januari 2021, berbanding 1 ralat setiap 10 percubaan pada Disember 2012 4 ralat akan berlaku. Satu lagi ujian ketepatan, Top-5, meminta komputer menjawab sama ada label sasaran adalah antara lima ramalan pengelas teratas itu meningkat daripada 85% pada 2013 kepada 99% pada 2021, melebihi Markah 94.9%.
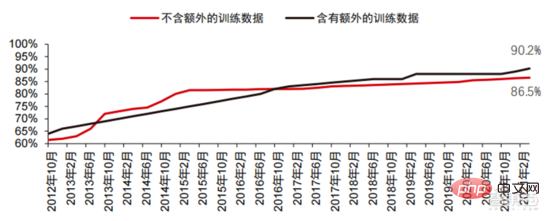
▲ TOP-1 perubahan ketepatan
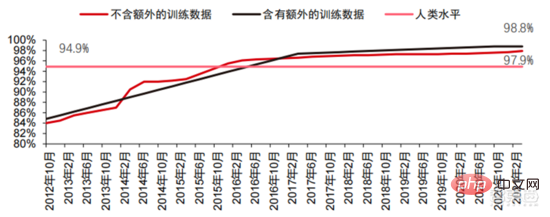
▲ TOP-5 perubahan ketepatan
Dalam proses pembangunan algoritma rangkaian saraf, model Transformer telah menjadi arus perdana dalam tempoh lima tahun yang lalu, menyepadukan pelbagai model kecil bertaburan pada masa lalu . Model Transformer ialah model NLP klasik yang dilancarkan oleh Google pada 2017 (Bert menggunakan Transformer). Bahagian teras model biasanya terdiri daripada dua bahagian, iaitu pengekod dan penyahkod. Pengekod/penyahkod terutamanya terdiri daripada dua modul: rangkaian saraf suapan (bahagian biru dalam gambar) dan mekanisme perhatian (bahagian merah mawar dalam gambar Penyahkod biasanya mempunyai perhatian tambahan (silang). mekanisme. Pengekod dan penyahkod mengelas dan memfokus semula data dengan meniru rangkaian saraf Prestasi model melebihi RNN dan CNN dalam tugas penterjemahan mesin Hanya pengekod/penyahkod diperlukan untuk mencapai hasil yang baik dan boleh diselaraskan dengan cekap.
AI Pemodelan besar ialah trend baharu yang muncul dalam tempoh dua tahun yang lalu + Model pra-latihan yang baik. -penyelesaian penalaan dan penyesuaian secara beransur-ansur 🎜> menjadi arus perdana, dan menjadi mungkin untuk model AI digeneralisasikan dengan sokongan data besar. Model kecil tradisional dilatih dengan data berlabel dalam medan tertentu dan mempunyai fleksibiliti yang lemah selalunya tidak boleh digunakan pada senario aplikasi lain dan perlu dilatih semula. Model AI besar biasanya dilatih pada data tidak berlabel berskala besar, dan model besar boleh diperhalusi untuk memenuhi keperluan pelbagai tugas aplikasi. Diwakili oleh OpenAI, Google, Microsoft, Facebook, NVIDIA dan institusi lain, penggunaan model pintar berskala besar telah menjadi trend global terkemuka, dan telah membentuk model asas dengan kuantiti parameter yang besar seperti GPT-3 dan Switch Transformer.
Megatron-LM yang dibangunkan bersama oleh NVIDIA dan Microsoft pada penghujung 2021 mempunyai 8.3 bilion parameter, manakala Megatron yang dibangunkan oleh Facebook mempunyai 11 bilion parameter. Kebanyakan parameter ini datang daripada reddit, wikipedia, laman web berita, dll. Alat seperti tasik data yang diperlukan untuk penyimpanan dan analisis sejumlah besar data akan menjadi salah satu fokus penyelidikan dan pembangunan masa hadapan.
5. Senario aplikasi: Dilaksanakan secara beransur-ansur dalam bidang keselamatan, Internet, runcit dan lain-lain
Pada masa ini, teknologi yang paling matang di bahagian aplikasi ialah pengecaman pertuturan, pengecaman imej, dsb. ., memberi tumpuan kepada bidang ini, terdapat sejumlah besar syarikat yang disenaraikan di China dan Amerika Syarikat, dan kelompok industri tertentu telah dibentuk. Dalam bidang pengecaman pertuturan, syarikat tersenarai yang agak matang termasuk iFlytek dan Nuance, yang sebelum ini telah diambil alih oleh Microsoft untuk AS$29 bilion.
Penjagaan perubatan pintar:AI+ Penjagaan perubatan kebanyakannya digunakan dalam senario bantuan perubatan. Produk AI dalam bidang perubatan dan kesihatan melibatkan pelbagai senario aplikasi seperti perundingan pintar, pengumpulan sejarah perubatan, rekod perubatan elektronik suara, kemasukan suara perubatan, diagnosis pengimejan perubatan, susulan pintar dan platform awan perubatan. Dari perspektif proses rawatan perubatan hospital, produk pra-diagnosis kebanyakannya adalah produk pembantu suara, seperti panduan perubatan, koleksi sejarah perubatan, dan lain-lain produk terutamanya adalah produk pengesanan susulan. Dengan mengambil kira produk yang berbeza dalam keseluruhan proses rawatan perubatan, bidang aplikasi utama semasa penjagaan perubatan AI+ masih merupakan senario tambahan, menggantikan kerja fizikal dan berulang doktor. Syarikat luar negara terkemuka dalam penjagaan perubatan AI+ ialah Nuance 50% daripada perniagaan syarikat itu berasal daripada penyelesaian perubatan pintar, dan penyelesaian transkripsi dokumen perubatan klinikal seperti rekod perubatan merupakan sumber pendapatan utama bagi perniagaan perubatan.
Bandar pintar: Penyakit bandar besar dan perbandaran baharu membawa cabaran baharu kepada tadbir urus bandar, merangsangAI+ permintaan untuk tadbir urus bandar. Apabila populasi dan bilangan kenderaan bermotor bertambah di bandar besar dan sederhana, masalah seperti kesesakan bandar semakin ketara. Dengan kemajuan urbanisasi baharu, bandar pintar akan menjadi model pembangunan utama bandar raya China. Pengurusan trafik AI+security dan AI+ yang terlibat dalam bandar pintar akan menjadi penyelesaian pelaksanaan utama di sisi G. Pada 2016, Hangzhou menjalankan transformasi otak data bandar pertamanya, dan indeks kesesakan puncak menurun kepada di bawah 1.7. Pada masa ini, otak data bandar yang diwakili oleh Alibaba telah melabur lebih daripada 1.5 bilion yuan, terutamanya dalam bidang seperti keselamatan pintar dan pengangkutan pintar. Skala industri bandar pintar negara saya terus berkembang Institut Penyelidikan Industri yang Berpandangan ke Hadapan meramalkan bahawa ia akan mencapai 25 trilion yuan pada tahun 2022, dengan purata kadar pertumbuhan kompaun tahunan sebanyak 55.27% dari 2014 hingga 2022.
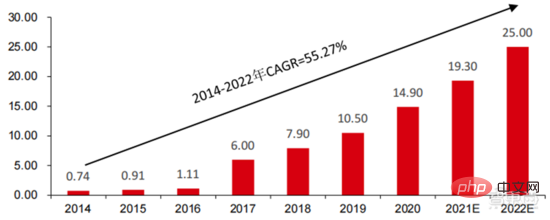 ▲ Saiz dan ramalan pasaran bandar pintar dari 2014 hingga 2022 (unit: trilion yuan)
▲ Saiz dan ramalan pasaran bandar pintar dari 2014 hingga 2022 (unit: trilion yuan)
Dalam 2020 saiz pasaran tahunan mencapai 5710 bilion, dan pergudangan pintar membawa masuk pasaran bernilai ratusan bilion. Dalam konteks kos tinggi dan transformasi digital dalam industri logistik, logistik pergudangan dan pembuatan produk menghadapi keperluan mendesak untuk automasi, pendigitalan dan transformasi pintar untuk meningkatkan kecekapan pembuatan dan peredaran. Menurut data dari Persekutuan Logistik dan Pembelian China, pasaran logistik pintar China akan mencapai 571 bilion yuan pada 2020, dengan purata kadar pertumbuhan kompaun tahunan sebanyak 21.61% dari 2013 hingga 2020. Teknologi maklumat generasi baharu seperti Internet Perkara, data besar, pengkomputeran awan dan kecerdasan buatan bukan sahaja menggalakkan pembangunan industri logistik pintar, tetapi juga mengemukakan keperluan perkhidmatan yang lebih tinggi untuk industri logistik pintar pasaran logistik dijangka terus berkembang. Menurut anggaran GGII, saiz pasaran pergudangan pintar China adalah hampir 90 bilion yuan pada tahun 2019, dan Institut Penyelidikan Hadapan meramalkan bahawa jumlah ini akan mencapai lebih daripada 150 bilion yuan pada tahun 2025.
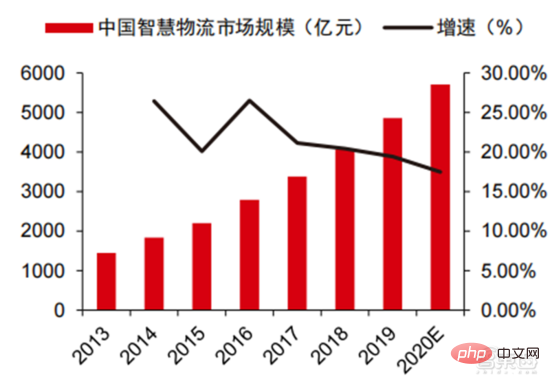 ▲ Saiz pasaran logistik pintar China dan kadar pertumbuhan dari 2013 hingga 2020
▲ Saiz pasaran logistik pintar China dan kadar pertumbuhan dari 2013 hingga 2020
Runcit baharu: Kepintaran buatan akan mengurangkan kos buruh dan meningkatkan kecekapan operasi. Amazon Go ialah konsep kedai tanpa pemandu yang dicadangkan oleh Amazon Kedai tanpa pemandu itu dilancarkan secara rasmi di Seattle, Amerika Syarikat pada 22 Januari 2018. AmazonGo menggabungkan pengkomputeran awan dan pembelajaran mesin, menggunakan Teknologi Just Walk Out dan Amazon Recognition. Kamera dalam kedai, pemantau penderia dan algoritma mesin di belakangnya akan mengenal pasti item yang dibawa oleh pengguna dan menyemak secara automatik apabila pelanggan meninggalkan kedai Ini merupakan revolusi baharu dalam bidang perniagaan runcit.
Komponen modul kecerdasan buatan berasaskan awan merupakan hala tuju utama gergasi Internet utama dalam pengkomersilan kecerdasan buatan Sepadukan teknologi kecerdasan buatan ke dalam penjualan perkhidmatan awan. Teknologi AI Google Cloud Platform sentiasa berada di barisan hadapan dalam industri dan komited untuk menyepadukan teknologi AI termaju ke dalam pusat perkhidmatan pengkomputeran awan. Dalam beberapa tahun kebelakangan ini, Google telah memperoleh beberapa syarikat AI dan melancarkan produk seperti TPU cip khusus AI dan perkhidmatan awan Cloud AutoML untuk melengkapkan reka letaknya. Pada masa ini, keupayaan AI Google telah meliputi perkhidmatan kognitif, pembelajaran mesin, robotik, analisis data & kerjasama dan bidang lain. Berbeza daripada produk yang agak bertaburan beberapa vendor awan dalam bidang AI, Google lebih lengkap dan sistematik dalam pengendalian produk AI, Ia menyepadukan aplikasi menegak ke dalam komponen AI asas, dan menyepadukan pengkomputeran Tensorflow dan TPU ke dalam infrastruktur, membentuk satu. perkhidmatan platform AI yang lengkap.
Baidu ialah AI vendor awan awam China dengan keupayaan terkuat, strategi teras Baidu AI Ia pemerkasaan terbuka. Baidu telah membina platform AI yang diwakili oleh DuerOS dan Apollo untuk membuka ekosistem dan membentuk lelaran data dan senario yang positif. Berdasarkan asas data carian Internet Baidu, pemprosesan bahasa semula jadi, graf pengetahuan dan teknologi potret pengguna telah beransur-ansur matang. Di peringkat platform dan ekologi, Baidu Cloud ialah platform pengkomputeran besar yang terbuka kepada semua rakan kongsi dan menjadi platform sokongan asas dengan pelbagai keupayaan Baidu Brain. Terdapat juga beberapa penyelesaian menegak, seperti sistem pengendalian generasi baharu berdasarkan interaksi manusia-komputer berasaskan bahasa semula jadi, dan Apollo yang berkaitan dengan pemanduan pintar. Pengeluar kenderaan boleh memanggil keupayaan yang mereka perlukan, dan pengeluar elektronik automotif juga boleh menggunakan keupayaan sepadan yang mereka perlukan untuk membina keseluruhan platform dan ekosistem secara bersama.
3. Perubahan industri: Model besar AI telah beransur-ansur menjadi arus perdana, dan pembangunan perindustrian dijangka mempercepatkan secara menyeluruh
Dalam beberapa tahun kebelakangan ini, laluan evolusi teknologi AI industri terutamanya menunjukkan ciri-ciri berikut: Prestasi modul asas terus meningkat Penambahbaikan, memfokuskan pada keupayaan generalisasi model, dengan itu membantu mengoptimumkan kepelbagaian algoritma AI dan menyalurkan semula pengumpulan data. Pembangunan mampan teknologi AI bergantung pada penemuan dalam algoritma asas, yang juga memerlukan pembinaan keupayaan asas dengan kuasa pengkomputeran sebagai teras dan persekitaran yang disokong oleh data besar untuk pembelajaran pengetahuan dan pengalaman. Populariti pesat model besar dalam industri, mod operasi model besar + model kecil, dan peningkatan berterusan keupayaan pautan asas seperti cip dan infrastruktur kuasa pengkomputeran, serta peningkatan berterusan yang terhasil dalam kategori senario aplikasi dan kedalaman senario, dan Akhirnya, ia akan membawa promosi bersama berterusan antara keupayaan asas industri dan senario aplikasi, dan memacu pembangunan industri AI global untuk terus memecut di bawah logik kitaran hadapan.
Model besar membawa keupayaan menyelesaikan masalah am yang kukuh. Pada masa ini, kebanyakan kecerdasan buatan adalah dalam "gaya bengkel manual". Menghadapi aplikasi hiliran dalam pelbagai industri, AI secara beransur-ansur menunjukkan ciri-ciri pemecahan dan kepelbagaian, dan fleksibiliti model tidak tinggi. Untuk meningkatkan keupayaan penyelesaian umum, model besar menyediakan penyelesaian yang boleh dilaksanakan, iaitu "pra-latihan model besar + penalaan halus tugas hiliran". Penyelesaian ini merujuk kepada menangkap pengetahuan daripada sejumlah besar data berlabel dan tidak berlabel, meningkatkan keupayaan generalisasi model dengan menyimpan pengetahuan ke dalam sejumlah besar parameter dan memperhalusi tugas khusus.
Model besar dijangka akan terus menembusi had ketepatan struktur model sedia ada, dan digabungkan dengan latihan model kecil bersarang, meningkatkan lagi kecekapan model dalam senario tertentu. Dalam tempoh sepuluh tahun yang lalu, peningkatan ketepatan model bergantung terutamanya pada perubahan struktur rangkaian Walau bagaimanapun, apabila teknologi reka bentuk struktur rangkaian saraf semakin matang dan cenderung untuk menumpu, peningkatan ketepatan telah mencapai kesesakan. penggunaan model besar dijangka dapat menembusi kesesakan ini. Mengambil model pemindahan visual Google, Big Transfer, BiT, sebagai contoh, dua set data, ILSVRC-2012 (1.28 juta imej, 1000 kategori) dan JFT-300M (300 juta imej, 18291 kategori), digunakan untuk melatih ketepatan ResNet50 Mereka adalah 77% dan 79% masing-masing Penggunaan model besar meningkatkan lagi ketepatan kesesakan. Selain itu, menggunakan JFT-300M untuk melatih ResNet152x4, ketepatan boleh meningkat kepada 87.5%, iaitu 10.5% lebih tinggi daripada struktur ILSVRC-2012+ResNet50.
Model besar + Model kecil: Promosi kecerdasan buatan model besar umum dan digabungkan dengan pengoptimuman data dalam senario tertentu akan menjadi buatan jangka sederhana kunci perwujudan perniagaan industri perisikan. Model asal pengekstrakan semula data untuk senario tertentu telah terbukti sukar untuk mengaut keuntungan Kos untuk melatih semula model adalah terlalu tinggi, dan model yang diperolehi mempunyai serba boleh yang rendah dan sukar untuk digunakan semula. Dalam konteks peningkatan berterusan prestasi pengkomputeran cip, percubaan untuk memasukkan model besar ke dalam model kecil memberikan pengeluar idea lain Dengan menganalisis data besar-besaran, mereka boleh mendapatkan model tujuan umum, dan kemudian menyarangkan model kecil khusus untuk menyediakan penyelesaian bagi. senario yang berbeza. Dioptimumkan dan menjimatkan banyak kos. Vendor awan awam seperti Alibaba Cloud, Huawei Cloud dan Tencent Cloud sedang giat membangunkan platform model besar yang dibangunkan sendiri untuk meningkatkan keluasan model.
AI Cip gergasi yang diwakili oleh NVIDIA, dalam generasi baharu cip, AI biasanya digunakan dalam industri model, direka khas dengan enjin baharu untuk meningkatkan kuasa pengkomputeran dengan sangat baik. Seni bina Hopper NVIDIA memperkenalkan enjin Transformer, yang sangat mempercepatkan latihan AI. Enjin Transformer menggunakan perisian dan teknologi NVIDIA Hopper Tensor Core tersuai, yang direka untuk mempercepatkan latihan model yang dibina pada blok binaan model AI biasa yang dikenali sebagai Transformers. Teras Tensor ini mampu menggunakan ketepatan campuran FP8 dan FP16 untuk mempercepatkan pengiraan AI dengan ketara untuk model Transformer. Operasi Teras Tensor dengan FP8 mempunyai dua kali daya pemprosesan operasi 16-bit. Enjin Transformer menangani cabaran ini dengan heuristik tersuai yang ditala NVIDIA yang memilih secara dinamik antara pengiraan FP8 dan FP16 dan secara automatik mengendalikan unjuran semula dan penskalaan antara ketepatan ini dalam setiap lapisan. Menurut data yang disediakan oleh NVIDIA, seni bina Hopper boleh menjadi 9 kali lebih cekap daripada model Ampere apabila melatih model Transformer.
Di bawah trend teknologi model besar, vendor awan secara beransur-ansur menjadi pemain teras dalam pasaran kuasa pengkomputeran Selepas rangka kerja teknologi kecerdasan buatan berkembang ke arah generalisasi melalui model besar, vendor awan juga boleh menggunakan keupayaan PaaS untuk menyepadukan. keupayaan IaaS asas digabungkan dengan PaaS untuk menyediakan penyelesaian universal untuk pasaran. Kami telah melihat bahawa dengan kemunculan model besar, jumlah data yang perlu diproses dan dianalisis oleh kecerdasan buatan meningkat dari hari ke hari Pada masa yang sama, bahagian data ini telah diubah daripada set data profesional pada masa lalu data besar tujuan umum. Gergasi pengkomputeran awan boleh menggabungkan keupayaan PaaS mereka yang berkuasa dengan asas IaaS untuk menyediakan pemprosesan data sehenti untuk pengeluar kecerdasan buatan Ini juga telah membantu gergasi pengkomputeran awan menjadi salah satu penerima utama gelombang kecerdasan buatan ini.
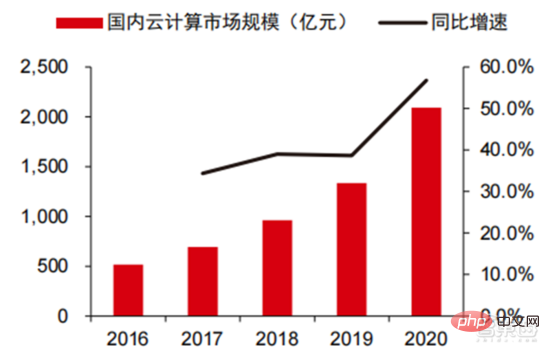
▲ Skala pasaran pengkomputeran awan domestik
Pada masa ini, vendor awan arus perdana antarabangsa seperti AWS dan Azure bersaing dengan awan terkemuka domestik seperti Alibaba Cloud, Tencent Cloud, dan Huawei Cloud Pengeluar telah mula menumpukan pada keupayaan PaaS seperti penyimpanan data dan pemprosesan data. Dari segi keupayaan storan, pangkalan data NoSQL akan mempunyai lebih banyak peluang pada masa hadapan apabila jenis data menjadi semakin kompleks Contohnya, Google Cloud telah menyebarkan reka letaknya dalam kelas objek, pangkalan data hubungan tradisional dan pangkalan data NoSQL. Dari segi pemprosesan data, kepentingan Tasik Data dan Gudang Data telah menjadi semakin menonjol Dengan menambah baik bahagian barisan produk ini, gergasi pengkomputeran awan telah membina model kitaran data yang lengkap dan menggabungkannya dengan keupayaan asas IaaSnya. Barisan produk yang lengkap dan model kitaran data tertutup akan menjadi kelebihan terbesar bagi gergasi pengkomputeran awan pada masa hadapan untuk bersaing dalam lapisan tengah AI.
Dengan penjelasan beransur-ansur struktur rantai industri AI, dan peningkatan ketara dalam kecekapan operasi industri dan kedalaman teknikal yang dibawa oleh model besar, dalam jangka sederhana, dengan mengandaikan bahawa teknologi AI tidak mengalami lonjakan- peralihan ke hadapan, kami menilai bahawa industri AI Nilai rantai dijangka beransur-ansur bergerak lebih dekat ke kedua-dua hujung, dan nilai pautan perantaraan dijangka terus lemah, dan secara beransur-ansur membentuk struktur rantaian perindustrian tipikal "cip + infrastruktur kuasa pengkomputeran + rangka kerja AI & perpustakaan algoritma + senario aplikasi". Pada masa yang sama, di bawah susunan struktur perindustrian sedemikian, kami menjangkakan bahawa syarikat cip huluan, pengeluar infrastruktur awan dan pengeluar aplikasi hiliran dijangka secara beransur-ansur menjadi penerima manfaat teras perkembangan pesat industri AI.
Model besar membawa penyatuan seni bina teknikal asas AI dan permintaan besar untuk kuasa pengkomputeran, yang secara semula jadi membantu syarikat pengkomputeran awan memainkan peranan asas dalam proses ini: pengkomputeran awan mempunyai pengedaran global terluas , kemudahan pengkomputeran perkakasan yang paling berkuasa, manakala rangka kerja AI dan algoritma umum ialah keupayaan PaaS yang paling tipikal dan cenderung untuk disepadukan ke dalam keupayaan platform vendor awan. Oleh itu, dari perspektif fleksibiliti teknikal, keperluan perniagaan sebenar dan dimensi lain, didorong oleh model besar, gergasi pengkomputeran awan dijangka secara beransur-ansur menjadi pembekal utama kemudahan kuasa pengkomputeran + keupayaan rangka kerja algoritma asas, dan terus menghakis algoritma AI sedia ada. penyedia platform. Ia boleh didapati daripada petikan pelbagai produk vendor awan pada masa lalu. Mengambil produk AWS dan Google sebagai contoh, harga penggunaan atas permintaan Linus di Amerika Syarikat Timur semakin menurun.
Seperti yang anda lihat daripada rajah, harga produk m1.large dengan 2 vCPU, 2 ECU dan 7.5GiB telah terus jatuh daripada kira-kira $0.4/jam pada tahun 2008 kepada kira-kira $0.18/jam pada tahun 2022. Harga penggunaan atas permintaan bagi produk n1-standard-8 Google Cloud dengan 8 vCPU dan memori 30GB juga telah menurun daripada AS$0.5/jam pada tahun 2014 kepada AS$0.38/jam pada tahun 2022. Ia boleh dilihat bahawa harga pengkomputeran awan dihidupkan aliran menurun secara keseluruhan. Dalam tempoh 3-5 tahun akan datang, kami akan melihat lebih banyak tawaran AI-sebagai-perkhidmatan (AIaaS). Trend model besar yang disebutkan sebelum ini, terutamanya kelahiran GPT-3, mencetuskan aliran ini Disebabkan bilangan parameter GPT-3 yang besar, ia mesti dijalankan pada kuasa pengkomputeran awan awam yang besar seperti kemudahan pengkomputeran berskala Azure. jadi Microsoft Menjadikannya perkhidmatan yang boleh diperolehi melalui API web juga akan menggalakkan kemunculan model yang lebih besar.
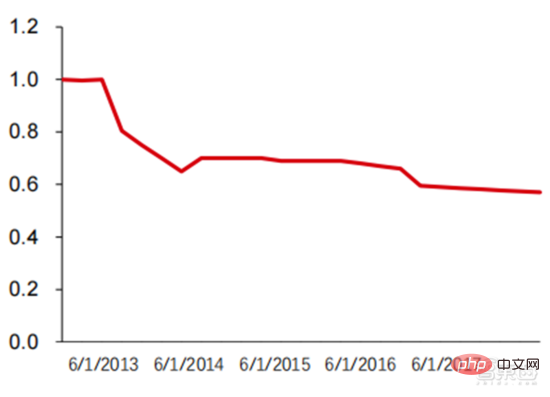
▲ Harga piawai sejarah AWS EC2 (USD/jam)
Dengan sokongan keadaan kuasa pengkomputeran semasa dan keupayaan teknikal yang boleh dijangka, penamatan aplikasi akan Diteruskan untuk merealisasikan lelaran dan pengoptimuman algoritma melalui pemerolehan data, memperbaiki kelemahan yang masih wujud dalam kecerdasan kognitif semasa (arah pengecaman imej), dan cuba berkembang ke arah kecerdasan membuat keputusan. Mengikut keupayaan teknikal semasa dan sokongan kuasa pengkomputeran perkakasan, ia masih akan mengambil masa yang lama untuk mencapai kecerdasan membuat keputusan yang lengkap menjadikan perisikan tempatan berdasarkan pendalaman berterusan senario sedia ada akan menjadi hala tuju utama dalam 3-5 tahun; Tahap aplikasi AI semasa masih terlalu tajam, dan melengkapkan sambungan tempatan akan menjadi langkah pertama untuk mencapai kecerdasan membuat keputusan. Aplikasi perisian kecerdasan buatan akan termasuk dari pemacu bawah ke aplikasi atas dan rangka kerja algoritma, daripada berorientasikan perniagaan (pembuatan, kewangan, logistik, runcit, hartanah, dll.) kepada orang (metaverse, perubatan, robot humanoid, dll.) ), pemanduan autonomi dan bidang lain.
Zhixixi percaya bahawa dengan penambahbaikan berterusan elemen asas seperti cip AI, kemudahan kuasa pengkomputeran dan data, serta peningkatan yang ketara dalam keupayaan untuk menyamaratakan penyelesaian masalah yang dibawa oleh model besar, AI industri membentuk "kuasa cip + pengkomputeran" Dengan struktur rantaian nilai industri yang stabil "Infrastruktur + Rangka Kerja AI & Perpustakaan Algoritma + Senario Aplikasi", pengeluar cip AI, pengeluar pengkomputeran awan (kemudahan kuasa pengkomputeran + rangka kerja algoritma), aplikasi AI + pengeluar senario, pengeluar rangka kerja algoritma platform, dsb. dijangka akan terus menjadi penerima manfaat teras industri.
Atas ialah kandungan terperinci Laporan mendalam: AI dipacu model besar mempercepatkan seluruh papan! Dekad emas bermula. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
Perintah untuk memulakan semula perkhidmatan SSH ialah: Sistem Restart SSHD. Langkah -langkah terperinci: 1. Akses terminal dan sambungkan ke pelayan; 2. Masukkan arahan: SistemCtl Restart SSHD; 3. Sahkan Status Perkhidmatan: Status Sistem SSHD.
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
