
 Peranti teknologi
AI
2022 Top10 model pembelajaran seliaan sendiri dikeluarkan! Lapan pencapaian Amerika Syarikat dan China mendominasi senarai itu
Peranti teknologi
AI
2022 Top10 model pembelajaran seliaan sendiri dikeluarkan! Lapan pencapaian Amerika Syarikat dan China mendominasi senarai itu
2022 Top10 model pembelajaran seliaan sendiri dikeluarkan! Lapan pencapaian Amerika Syarikat dan China mendominasi senarai itu

Pembelajaran penyeliaan kendiri membolehkan komputer memerhati dunia dan memahaminya dengan mempelajari struktur imej, pertuturan atau teks. Ini telah mendorong banyak kemajuan besar baru-baru ini dalam kecerdasan buatan.
Walaupun penyelidik di seluruh dunia melaburkan banyak usaha dalam bidang ini, pada masa ini terdapat perbezaan besar dalam cara algoritma pembelajaran penyeliaan sendiri belajar daripada imej, pertuturan, teks dan modaliti lain. Oleh itu, forum kecerdasan buatan Analytics India Magazine melancarkan sepuluh model pembelajaran penyeliaan sendiri teratas pada tahun 2022 untuk pembaca.
Data2vec

Pautan kertas: https://arxiv.org/pdf/2202.03555.pdf
Kod sumber terbuka: https://t.co/3x8VCwGI2x pic.twitter.com/Q9TNDg1paj
Meta AI mengeluarkan algoritma data2vec pada bulan Januari untuk penglihatan komputer berkaitan pertuturan, imej dan teks model. Menurut pasukan AI, model ini sangat kompetitif dalam tugas NLP.
Ia tidak menggunakan pembelajaran kontrastif atau pembinaan semula yang bergantung pada contoh input. Pasukan Meta AI menyatakan bahawa kaedah latihan data2vec adalah untuk mewakili model ramalan dengan memberikan pandangan separa data input.
Pasukan berkata: "Kami mula-mula mengekod sampel latihan bertopeng dalam model pelajar. Selepas itu, dalam model yang sama, kami mengekod sampel input yang tidak bertopeng untuk membina sasaran latihan. Model ini (model guru) dan model pelajar hanya berbeza dalam parameter 》

Model ini meramalkan perwakilan model sampel latihan tidak bertopeng berdasarkan sampel latihan bertopeng. Ini menghapuskan pergantungan pada objektif khusus modaliti dalam tugas pembelajaran.
ConvNext

Pautan kertas: https://arxiv.org/pdf/2201.03545.pdf
Kod sumber terbuka: https://t.co/nWx2KFtl7X
ConvNext, juga dipanggil model ConvNet untuk tahun 2020-an, ialah model yang dikeluarkan oleh pasukan Meta AI dalam Model Mac. Ia berdasarkan sepenuhnya pada modul ConvNet dan oleh itu tepat, mudah dalam reka bentuk dan berskala.

VICReg

Pautan kertas: https:// t.co/H7crDPHCHV
Kod sumber terbuka: https://t.co/oadSBT61P3
Penyaturan kovarian invarian varians (VICReg) menggabungkan istilah varians dan Decorrelation mekanisme berdasarkan pengurangan redundansi dan regularisasi kovarians untuk mengelakkan keruntuhan pengekod yang menghasilkan vektor malar atau tidak bermaklumat.

VICReg tidak memerlukan teknik seperti perkongsian berat antara cawangan, penormalan kelompok, penormalan ciri, pengkuantitian keluaran, kecerunan berhenti, bank memori, dll., dan berfungsi dengan baik pada beberapa tugas hiliran Hasil yang dicapai adalah setanding dengan keadaan seni. Tambahan pula, telah ditunjukkan secara eksperimen bahawa istilah penyesuaian varians boleh menstabilkan latihan kaedah lain dan menggalakkan peningkatan prestasi.
STEGO

Pautan kertas: https://arxiv.org/abs/2203.08414
Makmal Sains Komputer dan Kecerdasan Buatan MIT bekerjasama dengan Microsoft dan Cornell University untuk membangunkan Transformer Penyeliaan Sendiri untuk Pengoptimuman Graf Berasaskan Tenaga (STEGO) untuk menyelesaikan salah satu tugas paling sukar dalam penglihatan komputer : Berikan label kepada setiap piksel imej tanpa pengawasan manusia.

STEGO mempelajari "segmentasi semantik" - secara ringkas, memberikan label kepada setiap piksel dalam imej.
Segmentasi semantik ialah kemahiran penting untuk sistem penglihatan komputer hari ini kerana imej mungkin diganggu oleh objek. Untuk menyukarkan lagi perkara, objek ini tidak selalunya muat dalam kotak teks. Algoritma selalunya lebih sesuai untuk "benda" diskret seperti orang dan kereta daripada perkara yang sukar diukur seperti tumbuh-tumbuhan, langit dan kentang tumbuk.
Ambil adegan anjing bermain di taman sebagai contoh Sistem sebelumnya mungkin hanya dapat mengenal pasti anjing, tetapi dengan memberikan label pada setiap piksel imej, STEGO boleh menguraikan imej kepada beberapa komponen utama. : Anjing , langit, rumput dan pemiliknya.

Mesin yang boleh "melihat dunia" adalah penting kepada pelbagai teknologi baru muncul, seperti kereta pandu sendiri dan model ramalan untuk diagnosis perubatan. Memandangkan STEGO boleh belajar tanpa label, ia boleh mengesan objek dalam domain yang berbeza, malah objek yang manusia belum faham sepenuhnya.
CoBERT

Pautan kertas: https://arxiv.org/pdf/2210.04062.pdf
Untuk pembelajaran perwakilan pertuturan yang diselia sendiri, penyelidik dari Universiti China Hong Kong (Shenzhen) mencadangkan Kod BERT (CoBERT). Tidak seperti kaedah penyulingan diri yang lain, model mereka meramalkan perwakilan daripada modaliti yang berbeza. Model ini menukar pertuturan kepada urutan kod diskret untuk pembelajaran perwakilan.

Pertama, pasukan penyelidik menggunakan model kod pra-latihan HuBERT untuk melatih dalam ruang diskret. Mereka kemudiannya memperhalusi model kod menjadi model pertuturan, bertujuan untuk melaksanakan pembelajaran yang lebih baik merentas modaliti. Peningkatan ketara pada tugas ST menunjukkan bahawa perwakilan CoBERT mungkin membawa lebih banyak maklumat linguistik daripada kerja sebelumnya.
CoBERT mengatasi prestasi algoritma semasa terbaik pada tugas ASR dan membawa peningkatan ketara dalam tugas SUPERB Speech Translation (ST).
FedX

Pautan kertas: https://arxiv.org/abs/2207.09158
FedX ialah rangka kerja pembelajaran bersekutu tanpa pengawasan yang dilancarkan oleh Microsoft dengan kerjasama Universiti Tsinghua dan Institut Sains dan Teknologi Termaju Korea. Melalui pengekstrakan pengetahuan tempatan dan global serta pembelajaran perbandingan, algoritma mempelajari perwakilan tidak berat sebelah daripada data tempatan yang diskret dan heterogen. Tambahan pula, ia adalah algoritma yang boleh disesuaikan yang boleh digunakan sebagai modul tambahan kepada pelbagai algoritma penyeliaan kendiri sedia ada dalam senario pembelajaran bersekutu.
TriBYOL

Pautan kertas: https://arxiv.org/pdf/2206.03012.pdf
Universiti Hokkaido di Jepun mencadangkan TriBYOL untuk pembelajaran perwakilan penyeliaan kendiri kumpulan kecil. Di bawah model ini, penyelidik tidak memerlukan sejumlah besar sumber pengkomputeran untuk mempelajari perwakilan yang baik. Model ini mempunyai struktur rangkaian tiga kali ganda dan menggabungkan kehilangan tiga paparan, dengan itu meningkatkan kecekapan dan mengatasi beberapa algoritma penyeliaan sendiri pada berbilang set data.

ColloSSL

Pautan kertas: https://arxiv.org/pdf/ 2202.00758.pdf
Penyelidik di Nokia Bell Labs, dengan kerjasama Georgia Institute of Technology dan University of Cambridge, telah membangunkan ColloSSL, algoritma penyeliaan kendiri kolaboratif untuk pengecaman aktiviti manusia.

Set data sensor tidak berlabel yang ditangkap serentak oleh berbilang peranti boleh dilihat sebagai transformasi semula jadi antara satu sama lain, yang kemudian menjana isyarat untuk pembelajaran perwakilan. Kertas kerja ini mencadangkan tiga kaedah - pemilihan peranti, pensampelan kontras dan kehilangan kontrastif berbilang paparan.
LoRot

Pautan kertas: https://arxiv.org/pdf/2207.10023.pdf
Sungkyunkwan A universiti pasukan penyelidik mencadangkan tugas tambahan mudah diselia sendiri yang meramalkan putaran setempat (LoRot) dengan tiga atribut untuk membantu dalam menyelia sasaran.

Model ini mempunyai tiga ciri utama. Pertama, pasukan penyelidik membimbing model untuk mempelajari ciri yang kaya. Kedua, latihan yang diedarkan tidak berubah dengan ketara semasa peralihan penyeliaan kendiri berlaku. Ketiga, model ini ringan dan serba boleh serta mempunyai kebolehsuaian yang tinggi kepada teknologi terdahulu.

TS2Vec

Pautan kertas: https:// arxiv.org/pdf/2106.10466.pdf
Microsoft dan Universiti Peking mencadangkan rangka kerja pembelajaran am TS2Vec untuk pembelajaran perwakilan siri masa pada mana-mana peringkat semantik. Model ini melaksanakan pembelajaran kontrastif dalam teknik hierarki dalam paparan konteks yang dipertingkatkan, memberikan perwakilan konteks yang kukuh untuk cap masa individu.

Keputusan menunjukkan bahawa model TS2Vec mencapai peningkatan yang ketara dalam prestasi berbanding pembelajaran perwakilan siri masa tanpa pengawasan yang canggih.
Pada tahun 2022, akan terdapat inovasi besar dalam dua bidang pembelajaran penyeliaan kendiri dan pembelajaran pengukuhan. Walaupun penyelidik telah membahaskan mana yang lebih penting, seperti yang dikatakan oleh guru pembelajaran penyeliaan sendiri Yann LeCun: "Pembelajaran pengukuhan adalah seperti ceri pada kek, pembelajaran yang diselia adalah aising pada kek, dan pembelajaran penyeliaan sendiri adalah kek itu sendiri. 》
Rujukan:
https://analyticsindiamag.com/top-10-self-supervised-learning-models-in-2022/
Atas ialah kandungan terperinci 2022 Top10 model pembelajaran seliaan sendiri dikeluarkan! Lapan pencapaian Amerika Syarikat dan China mendominasi senarai itu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



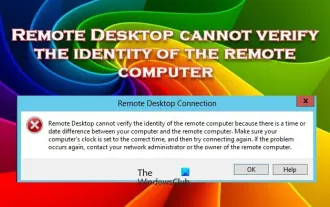 Desktop Jauh tidak boleh mengesahkan identiti komputer jauh
Feb 29, 2024 pm 12:30 PM
Desktop Jauh tidak boleh mengesahkan identiti komputer jauh
Feb 29, 2024 pm 12:30 PM
Perkhidmatan Desktop Jauh Windows membolehkan pengguna mengakses komputer dari jauh, yang sangat mudah untuk orang yang perlu bekerja dari jauh. Walau bagaimanapun, masalah boleh dihadapi apabila pengguna tidak dapat menyambung ke komputer jauh atau apabila Desktop Jauh tidak dapat mengesahkan identiti komputer. Ini mungkin disebabkan oleh isu sambungan rangkaian atau kegagalan pengesahan sijil. Dalam kes ini, pengguna mungkin perlu menyemak sambungan rangkaian, memastikan komputer jauh berada dalam talian dan cuba menyambung semula. Selain itu, memastikan bahawa pilihan pengesahan komputer jauh dikonfigurasikan dengan betul adalah kunci untuk menyelesaikan isu tersebut. Masalah sedemikian dengan Perkhidmatan Desktop Jauh Windows biasanya boleh diselesaikan dengan menyemak dan melaraskan tetapan dengan teliti. Desktop Jauh tidak boleh mengesahkan identiti komputer jauh kerana perbezaan masa atau tarikh. Sila pastikan pengiraan anda
 Kedudukan Sains Komputer Kebangsaan 2024 CSRankings Dikeluarkan! CMU mendominasi senarai, MIT terkeluar daripada 5 teratas
Mar 25, 2024 pm 06:01 PM
Kedudukan Sains Komputer Kebangsaan 2024 CSRankings Dikeluarkan! CMU mendominasi senarai, MIT terkeluar daripada 5 teratas
Mar 25, 2024 pm 06:01 PM
Kedudukan Utama Sains Komputer Kebangsaan 2024CSRankings baru sahaja dikeluarkan! Tahun ini, dalam ranking universiti CS terbaik di Amerika Syarikat, Carnegie Mellon University (CMU) berada di antara yang terbaik di negara ini dan dalam bidang CS, manakala University of Illinois di Urbana-Champaign (UIUC) telah menduduki tempat kedua selama enam tahun berturut-turut. Georgia Tech menduduki tempat ketiga. Kemudian, Universiti Stanford, Universiti California di San Diego, Universiti Michigan, dan Universiti Washington terikat di tempat keempat di dunia. Perlu diingat bahawa kedudukan MIT jatuh dan jatuh daripada lima teratas. CSRankings ialah projek ranking universiti global dalam bidang sains komputer yang dimulakan oleh Profesor Emery Berger dari Pusat Pengajian Sains Komputer dan Maklumat di Universiti Massachusetts Amherst. Kedudukan adalah berdasarkan objektif
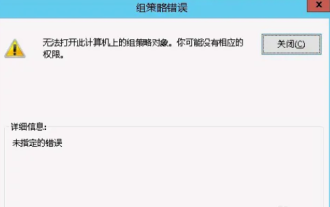 Tidak dapat membuka objek Dasar Kumpulan pada komputer ini
Feb 07, 2024 pm 02:00 PM
Tidak dapat membuka objek Dasar Kumpulan pada komputer ini
Feb 07, 2024 pm 02:00 PM
Kadangkala, sistem pengendalian mungkin tidak berfungsi apabila menggunakan komputer. Masalah yang saya hadapi hari ini ialah apabila mengakses gpedit.msc, sistem menggesa objek Dasar Kumpulan tidak boleh dibuka kerana kebenaran yang betul mungkin tiada. Objek Dasar Kumpulan pada komputer ini tidak dapat dibuka Penyelesaian: 1. Apabila mengakses gpedit.msc, sistem menggesa bahawa objek Dasar Kumpulan pada komputer ini tidak boleh dibuka kerana kekurangan kebenaran. Butiran: Sistem tidak dapat mengesan laluan yang ditentukan. 2. Selepas pengguna mengklik butang tutup, tetingkap ralat berikut muncul. 3. Semak rekod log dengan segera dan gabungkan maklumat yang direkodkan untuk mendapati bahawa masalahnya terletak pada fail C:\Windows\System32\GroupPolicy\Machine\registry.pol
 CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
CLIP-BEVFormer: Selia secara eksplisit struktur BEVFormer untuk meningkatkan prestasi pengesanan ekor panjang
Mar 26, 2024 pm 12:41 PM
Ditulis di atas & pemahaman peribadi penulis: Pada masa ini, dalam keseluruhan sistem pemanduan autonomi, modul persepsi memainkan peranan penting Hanya selepas kenderaan pemanduan autonomi yang memandu di jalan raya memperoleh keputusan persepsi yang tepat melalui modul persepsi boleh Peraturan hiliran dan. modul kawalan dalam sistem pemanduan autonomi membuat pertimbangan dan keputusan tingkah laku yang tepat pada masanya dan betul. Pada masa ini, kereta dengan fungsi pemanduan autonomi biasanya dilengkapi dengan pelbagai penderia maklumat data termasuk penderia kamera pandangan sekeliling, penderia lidar dan penderia radar gelombang milimeter untuk mengumpul maklumat dalam modaliti yang berbeza untuk mencapai tugas persepsi yang tepat. Algoritma persepsi BEV berdasarkan penglihatan tulen digemari oleh industri kerana kos perkakasannya yang rendah dan penggunaan mudah, dan hasil keluarannya boleh digunakan dengan mudah untuk pelbagai tugas hiliran.
 Terokai prinsip asas dan pemilihan algoritma bagi fungsi isihan C++
Apr 02, 2024 pm 05:36 PM
Terokai prinsip asas dan pemilihan algoritma bagi fungsi isihan C++
Apr 02, 2024 pm 05:36 PM
Lapisan bawah fungsi C++ sort menggunakan isihan gabungan, kerumitannya ialah O(nlogn), dan menyediakan pilihan algoritma pengisihan yang berbeza, termasuk isihan pantas, isihan timbunan dan isihan stabil.
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Bolehkah kecerdasan buatan meramalkan jenayah? Terokai keupayaan CrimeGPT
Mar 22, 2024 pm 10:10 PM
Bolehkah kecerdasan buatan meramalkan jenayah? Terokai keupayaan CrimeGPT
Mar 22, 2024 pm 10:10 PM
Konvergensi kecerdasan buatan (AI) dan penguatkuasaan undang-undang membuka kemungkinan baharu untuk pencegahan dan pengesanan jenayah. Keupayaan ramalan kecerdasan buatan digunakan secara meluas dalam sistem seperti CrimeGPT (Teknologi Ramalan Jenayah) untuk meramal aktiviti jenayah. Artikel ini meneroka potensi kecerdasan buatan dalam ramalan jenayah, aplikasi semasanya, cabaran yang dihadapinya dan kemungkinan implikasi etika teknologi tersebut. Kecerdasan Buatan dan Ramalan Jenayah: Asas CrimeGPT menggunakan algoritma pembelajaran mesin untuk menganalisis set data yang besar, mengenal pasti corak yang boleh meramalkan di mana dan bila jenayah mungkin berlaku. Set data ini termasuk statistik jenayah sejarah, maklumat demografi, penunjuk ekonomi, corak cuaca dan banyak lagi. Dengan mengenal pasti trend yang mungkin terlepas oleh penganalisis manusia, kecerdasan buatan boleh memperkasakan agensi penguatkuasaan undang-undang
 Algoritma pengesanan yang dipertingkatkan: untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi
Jun 06, 2024 pm 12:33 PM
Algoritma pengesanan yang dipertingkatkan: untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi
Jun 06, 2024 pm 12:33 PM
01Garis prospek Pada masa ini, sukar untuk mencapai keseimbangan yang sesuai antara kecekapan pengesanan dan hasil pengesanan. Kami telah membangunkan algoritma YOLOv5 yang dipertingkatkan untuk pengesanan sasaran dalam imej penderiaan jauh optik resolusi tinggi, menggunakan piramid ciri berbilang lapisan, strategi kepala pengesanan berbilang dan modul perhatian hibrid untuk meningkatkan kesan rangkaian pengesanan sasaran dalam imej penderiaan jauh optik. Menurut set data SIMD, peta algoritma baharu adalah 2.2% lebih baik daripada YOLOv5 dan 8.48% lebih baik daripada YOLOX, mencapai keseimbangan yang lebih baik antara hasil pengesanan dan kelajuan. 02 Latar Belakang & Motivasi Dengan perkembangan pesat teknologi penderiaan jauh, imej penderiaan jauh optik resolusi tinggi telah digunakan untuk menggambarkan banyak objek di permukaan bumi, termasuk pesawat, kereta, bangunan, dll. Pengesanan objek dalam tafsiran imej penderiaan jauh
