

Penjelasan terperinci ChatGPT/InstructGPT

Kata Pengantar
Siri GPT ialah siri artikel pra-latihan dari OpenAI Nama penuh GPT ialah Generative Pre-Trained Transformer Seperti namanya, tujuan GPT adalah untuk menggunakan Transformer sebagai model asas dan menggunakan teknologi pra-latihan untuk mendapatkan model Teks universal. Kertas kerja yang telah diterbitkan setakat ini termasuk teks pra-latihan GPT-1, GPT-2, GPT-3 dan imej pra-latihan iGPT. GPT-4, yang masih belum dikeluarkan, dikhabarkan sebagai model multi-modal. ChatGPT yang sangat popular baru-baru ini dan [1] yang diumumkan pada awal tahun ini ialah sepasang model kakak Mereka adalah model pemanasan awal yang dikeluarkan sebelum GPT-4, kadangkala juga dipanggil GPT3.5. ChatGPT dan InstructGPT adalah benar-benar konsisten dari segi struktur model dan kaedah latihan, iaitu, kedua-duanya menggunakan pembelajaran arahan (Pembelajaran Pengajaran) dan pembelajaran pengukuhan daripada maklum balas manusia (RLHF) untuk membimbing latihan model Terdapat perbezaan dalam cara pengumpulan data. Jadi untuk memahami ChatGPT, kita mesti terlebih dahulu memahami InstructGPT.
1. Pengetahuan latar belakang
Sebelum memperkenalkan ChatGPT/InstructGPT, kami mula-mula memperkenalkan algoritma asas yang mereka harapkan.
Siri 1.1 GPT
Tiga generasi GPT-1[2], GPT-2[3] dan GPT-3[4] berdasarkan teks pra-latihan semua menggunakan Transformer sebagai model Struktur teras (Rajah 1), perbezaannya ialah bilangan lapisan model dan panjang vektor perkataan dan parameter hiper lain, kandungan khusus mereka ditunjukkan dalam Jadual 1.
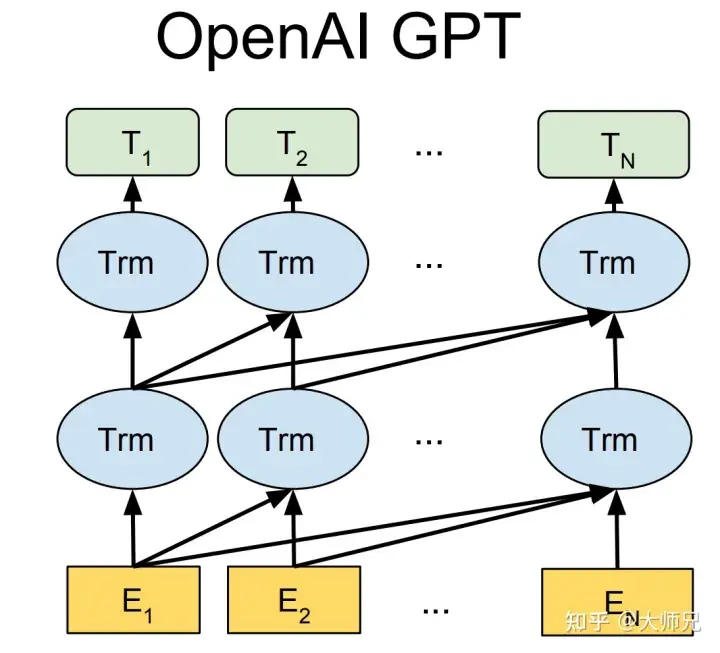
Rajah 1: Struktur model siri GPT (di mana Trm ialah struktur Transformer)
Jadual 1: Masa keluaran, jumlah parameter dan latihan sebelumnya generasi Kuantiti GPT
|
Model |
Masa keluaran |
Bilangan lapisan |
Bilangan kepala | Panjang vektor perkataan |
Jumlah parameter |
Jumlah data pra-latihan |
GPT-1 |
Jun 2018 |
12 |
12 |
768 |
117 juta |
Kira-kira 5GB |
GPT-2 |
Februari 2019 |
48 |
- |
1600 |
1.5 bilion |
40GB |
GPT-3 |
Mei 2020 |
96 |
96 |
12888 |
175 bilion |
45TB |
GPT-1 dilahirkan beberapa bulan lebih awal daripada BERT. Mereka semua menggunakan Transformer sebagai struktur teras Perbezaannya ialah GPT-1 membina tugasan pra-latihan secara generatif dari kiri ke kanan, dan kemudian memperoleh model pra-latihan umum . GPT-1 mencapai keputusan SOTA pada 9 tugasan NLP pada masa itu, tetapi saiz model dan volum data yang digunakan oleh GPT-1 adalah agak kecil, yang mendorong kelahiran GPT-2.
Berbanding dengan GPT-1, GPT-2 tidak membuat kekecohan besar tentang struktur model, tetapi hanya menggunakan model dengan lebih banyak parameter dan lebih banyak data latihan (Jadual 1). Idea GPT-2 yang paling penting ialah idea bahawa "semua pembelajaran yang diselia adalah subset model bahasa yang tidak diselia." Idea ini juga merupakan pendahulu pembelajaran segera. GPT-2 juga menimbulkan banyak sensasi ketika ia pertama kali dilahirkan Berita yang dijananya sudah cukup untuk menipu kebanyakan manusia dan mencapai kesan mengelirukan berita palsu dengan berita sebenar. Ia juga dipanggil "senjata paling berbahaya di dunia AI" pada masa itu, dan banyak portal mengarahkan untuk mengharamkan penggunaan berita yang dihasilkan oleh GPT-2.
Apabila GPT-3 dicadangkan, di samping kesannya jauh melebihi GPT-2, perkara yang menyebabkan lebih banyak perbincangan ialah 175 bilion parameternya. Selain GPT-3 dapat menyelesaikan tugasan NLP biasa, penyelidik tanpa diduga mendapati bahawa GPT-3 juga mempunyai prestasi yang baik dalam menulis kod dalam bahasa seperti SQL dan JavaScript, dan melaksanakan operasi matematik yang mudah. Latihan GPT-3 menggunakan pembelajaran dalam konteks, iaitu sejenis meta-pembelajaran Idea teras meta-pembelajaran adalah untuk mencari julat permulaan yang sesuai melalui sejumlah kecil data, supaya model boleh Pantas. sesuai pada set data yang terhad dan hasil yang baik.
Melalui analisis di atas, kita dapat melihat bahawa dari perspektif prestasi, GPT mempunyai dua matlamat:
- Meningkatkan prestasi model pada tugasan NLP biasa
- Tingkatkan keupayaan generalisasi model pada tugas NLP bukan tipikal lain (seperti penulisan kod, operasi matematik).
Selain itu, sejak lahirnya model pra-latihan, masalah yang dikritik ialah berat sebelah model pra-latihan. Oleh kerana model pra-latihan dilatih pada model dengan tahap parameter yang sangat besar melalui data besar-besaran, berbanding sistem pakar yang dikawal sepenuhnya oleh peraturan buatan, model pra-latihan adalah seperti kotak hitam. Tiada siapa yang boleh menjamin bahawa model pra-latihan itu tidak akan menghasilkan beberapa kandungan berbahaya yang mengandungi diskriminasi kaum, seksisme, dsb., kerana berpuluh-puluh gigabait atau bahkan berpuluh-puluh terabait data latihannya hampir pasti mengandungi sampel latihan yang serupa. Ini adalah motivasi untuk InstructGPT dan ChatGPT Kertas ini menggunakan 3H untuk meringkaskan matlamat pengoptimuman mereka:
- Berguna (Bermanfaat
- Jujur);
- Tidak berbahaya.
Model siri GPT OpenAI bukan sumber terbuka, tetapi ia menyediakan tapak web percubaan untuk model tersebut dan pelajar yang berkelayakan boleh mencubanya sendiri.
1.2 Pembelajaran Arahan (Pembelajaran Arahan) dan Pembelajaran Pantas (Pembelajaran Pantas)
Pembelajaran terbimbing ialah artikel bertajuk "Model Bahasa yang Diperbaiki" oleh pasukan Quoc V.Le Google Deepmind pada tahun 2021 The idea yang dicadangkan dalam artikel "Pelajar Sifar Pukulan" [5]. Tujuan pembelajaran arahan dan pembelajaran segera adalah untuk memanfaatkan pengetahuan model bahasa itu sendiri. Perbezaannya ialah Prompt merangsang keupayaan pelengkapan model bahasa, seperti menghasilkan separuh kedua ayat berdasarkan separuh pertama ayat, atau pengisian kloz, dsb. Arahan merangsang keupayaan pemahaman model bahasa Ia membolehkan model mengambil tindakan yang betul dengan memberi arahan yang lebih jelas. Kita boleh memahami dua kaedah pembelajaran yang berbeza ini melalui contoh berikut:
- Petua untuk belajar: Saya membeli kalung ini untuk teman wanita saya. Kalung ini sangat ____.
- Arahan untuk pembelajaran: Nilaikan emosi ayat ini: Saya membeli rantai ini untuk teman wanita saya dan dia sangat menyukainya. Pilihan: A = baik; B = sederhana;
Kelebihan pembelajaran arahan ialah selepas penalaan halus untuk pelbagai tugasan, ia juga boleh melakukan pukulan sifar pada tugasan lain, manakala pembelajaran arahan semuanya ditujukan kepada satu tugasan. Keupayaan generalisasi tidak sebaik pembelajaran yang diarahkan. Kita boleh memahami penalaan halus, pembelajaran kiu dan pembelajaran arahan melalui Rajah 2.
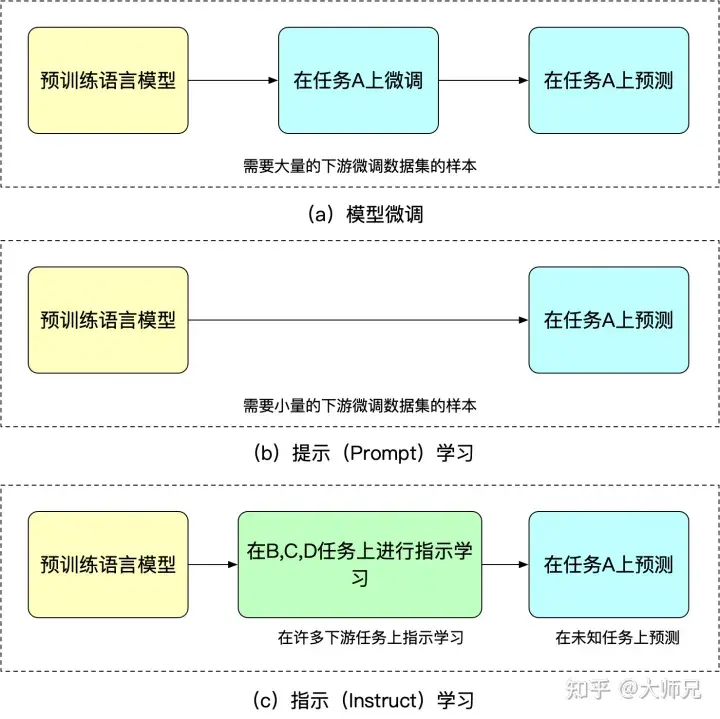
Rajah 2: Persamaan dan perbezaan antara penalaan halus model, pembelajaran segera dan pembelajaran terbimbing
1.3 Pembelajaran pengukuhan dengan maklum balas tiruan
Oleh kerana model terlatih tidak begitu terkawal, model boleh dianggap sebagai pemasangan pengedaran set latihan. Kemudian apabila dimasukkan semula ke dalam model generatif, pengedaran data latihan adalah faktor paling penting yang mempengaruhi kualiti kandungan yang dihasilkan. Kadangkala kami berharap model itu bukan sahaja dipengaruhi oleh data latihan, tetapi juga boleh dikawal secara buatan, untuk memastikan kegunaan, ketulenan dan tidak berbahaya bagi data yang dihasilkan. Isu penjajaran disebut berkali-kali dalam kertas itu. Kita boleh memahaminya sebagai penjajaran kandungan keluaran model dan kandungan keluaran yang disukai manusia bukan sahaja merangkumi kelancaran dan ketepatan tatabahasa bagi kandungan yang dihasilkan. tetapi juga kualiti kandungan yang dihasilkan Kebergunaan, keaslian dan tidak berbahaya.
Kami tahu bahawa pembelajaran pengukuhan membimbing latihan model melalui mekanisme ganjaran (Ganjaran) Mekanisme ganjaran boleh dianggap sebagai fungsi kehilangan mekanisme latihan model tradisional. Pengiraan ganjaran adalah lebih fleksibel dan pelbagai daripada fungsi kerugian (ganjaran AlphaGO adalah hasil daripada permainan). Idea pembelajaran pengukuhan adalah untuk menyesuaikan fungsi kehilangan melalui sejumlah besar sampel ganjaran untuk mencapai latihan model. Begitu juga, maklum balas manusia juga tidak boleh diterbitkan, jadi kami juga boleh menggunakan maklum balas buatan sebagai ganjaran untuk pembelajaran pengukuhan, dan pembelajaran pengukuhan berdasarkan maklum balas buatan muncul mengikut keperluan masa.
RLHF boleh dikesan kembali kepada "Pembelajaran Peneguhan Dalam daripada Keutamaan Manusia" [6] yang diterbitkan oleh Google pada tahun 2017. Ia menggunakan anotasi manual sebagai maklum balas untuk meningkatkan aplikasi pembelajaran pengukuhan dalam robot simulasi dan prestasi permainan Atari kesan.
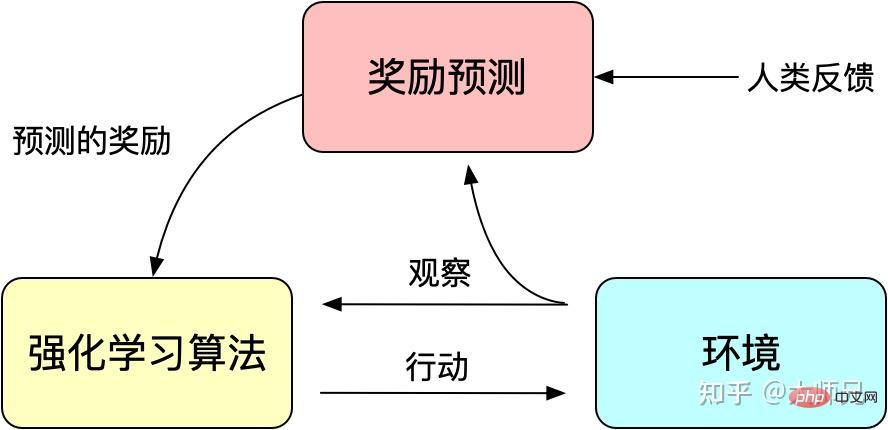
Rajah 3: Prinsip asas pembelajaran pengukuhan dengan maklum balas buatan
InstructGPT/ChatGPT juga menggunakan algoritma klasik dalam pembelajaran pengukuhan: yang dicadangkan oleh OpenAI Proximal Pengoptimuman Dasar (PPO) [7]. Algoritma PPO ialah jenis algoritma Kecerunan Dasar yang baharu terlalu besar, ia akan memudaratkan pembelajaran. PPO mencadangkan fungsi objektif baharu yang boleh mencapai kemas kini kelompok kecil dalam berbilang langkah latihan, menyelesaikan masalah sukar untuk menentukan saiz langkah dalam algoritma Gradien Dasar. Malah, TRPO juga direka untuk menyelesaikan idea ini, tetapi berbanding dengan algoritma TRPO, algoritma PPO lebih mudah untuk diselesaikan.
2. Tafsiran prinsip InstructGPT/ChatGPT
Dengan pengetahuan asas di atas, lebih mudah untuk kita memahami InstructGPT dan ChatGPT. Secara ringkasnya, InstructGPT/ChatGPT kedua-duanya mengguna pakai struktur rangkaian GPT-3, dan membina sampel latihan melalui pembelajaran arahan untuk melatih model ganjaran (RM) yang mencerminkan kesan kandungan yang diramalkan Akhirnya, skor model ganjaran ini adalah digunakan untuk membimbing model pembelajaran pengukuhan. Proses latihan InstructGPT/ChatGPT ditunjukkan dalam Rajah 4.
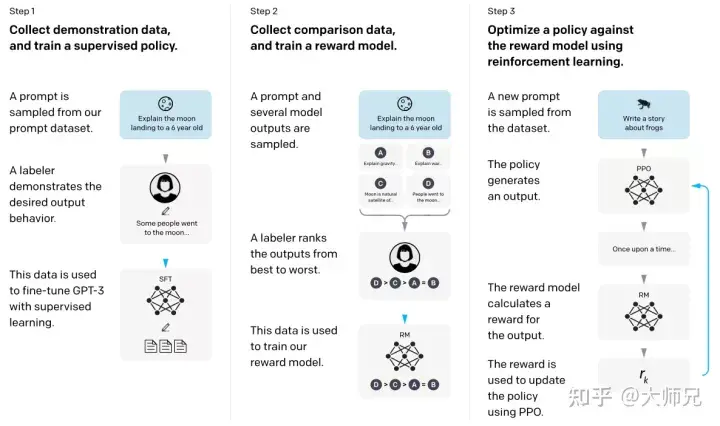
Rajah 4: Proses pengiraan ArahanGPT: (1) Penyeliaan penalaan halus (SFT); (2) Latihan model ganjaran (3) Ganjaran berdasarkan PPO Model melaksanakan pembelajaran pengukuhan.
Daripada Rajah 4 kita dapat melihat bahawa latihan InstructGPT/ChatGPT boleh dibahagikan kepada 3 langkah, di mana langkah 2 dan 3 ialah model ganjaran dan model SFT pembelajaran pengukuhan yang boleh dioptimumkan secara berulang.
- Lakukan penalaan halus diselia (Supervised FineTune, SFT) GPT-3 berdasarkan set data SFT yang dikumpul
- Kumpulkan data perbandingan berlabel secara manual dan latih model ganjaran (Reword Model , RM);
- Gunakan RM sebagai matlamat pengoptimuman pembelajaran pengukuhan dan gunakan algoritma PPO untuk memperhalusi model SFT.
Menurut Rajah 4, kami akan memperkenalkan dua aspek pengumpulan set data dan latihan model InstructGPT/ChatGPT masing-masing.
2.1 Pengumpulan set data
Seperti yang ditunjukkan dalam Rajah 4, latihan InstructGPT/ChatGPT dibahagikan kepada 3 langkah, dan data yang diperlukan untuk setiap langkah adalah berbeza sedikit di bawah.
2.1.1 Set data SFT
Set data SFT digunakan untuk melatih model diselia dalam langkah pertama, iaitu menggunakan data baharu yang dikumpul, GPT-3 dilatih mengikut kaedah latihan GPT-3 3 Buat pelarasan halus. Oleh kerana GPT-3 ialah model generatif berdasarkan pembelajaran segera, set data SFT juga merupakan sampel yang terdiri daripada pasangan balasan segera. Sebahagian daripada data SFT datang daripada pengguna OpenAI's PlayGround, dan sebahagian lagi datang daripada 40 pelabel yang digunakan oleh OpenAI. Dan mereka melatih pelabel itu. Dalam set data ini, tugas annotator ialah menulis arahan berdasarkan kandungan dan arahan tersebut diperlukan untuk memenuhi tiga perkara berikut:
- Tugas mudah: pelabel memberikan apa-apa tugasan mudah, sambil memastikan kepelbagaian tugasan; 🎜> Berkaitan dengan pengguna: Dapatkan kes penggunaan daripada antara muka, dan kemudian biarkan pelabel menulis arahan berdasarkan kes penggunaan ini.
- 2.1.2 Set Data RM
Jadual 2: Taburan data InstructGPT 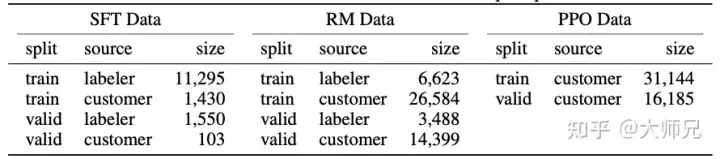
Lebih daripada 96% data adalah dalam bahasa Inggeris, dan 20 bahasa lain seperti Cina, Perancis, Sepanyol, dsb. menambah sehingga kurang daripada 4% , yang mungkin menyebabkan InstructGPT/ChatGPT gagal Menjana bahasa lain, tetapi kesannya harus jauh lebih rendah daripada bahasa Inggeris
- Terdapat 9 jenis gesaan, dan kebanyakannya adalah tugas penjanaan, yang mungkin membawa kepada tugasan. jenis yang tidak dilindungi oleh model;
- 40 pekerja penyumberan luar berasal dari Amerika Syarikat dan Asia Tenggara Mereka agak tertumpu dan mempunyai bilangan yang kecil model dengan nilai yang betul adalah gabungan nilai 40 pekerja penyumberan luar ini. Dan pengedaran yang agak sempit ini mungkin menjana beberapa isu diskriminasi dan prejudis yang lebih dibimbangkan oleh wilayah lain.
- Selain itu, blog ChatGPT menyebut bahawa kaedah latihan ChatGPT dan InstructGPT adalah sama . Memandangkan ChatGPT hanya digunakan dalam bidang dialog, di sini saya rasa ChatGPT mempunyai dua perbezaan dalam pengumpulan data: 1. Ia meningkatkan perkadaran tugas dialog 2. Ia menukar kaedah segera kepada kaedah Soal Jawab. Sudah tentu, ini hanya spekulasi Penerangan yang lebih tepat tidak akan diketahui sehingga maklumat yang lebih terperinci seperti kertas dan kod sumber ChatGPT dikeluarkan.
di mana rθ(x,y) ialah nilai ganjaran bagi x gesaan dan respons y di bawah model ganjaran dengan parameter θ, yw ialah hasil tindak balas yang disukai oleh pelabel, dan yl ialah hasil tindak balas yang tidak disukai oleh pelabel. . D ialah keseluruhan set data latihan.
2.2.3 Model Pembelajaran Pengukuhan (PPO)
Model pembelajaran pengukuhan dan pra-latihan ialah dua arah AI yang paling hangat dalam tempoh dua tahun lalu Ramai penyelidik saintifik sebelum ini mengatakan bahawa pembelajaran pengukuhan is not One sangat sesuai digunakan untuk model pra-latihan kerana sukar untuk membina mekanisme ganjaran daripada kandungan output model. InstructGPT/ChatGPT mencapai ini secara balas intuitif Ia memperkenalkan pembelajaran pengukuhan ke dalam model bahasa pra-latihan dengan menggabungkan anotasi manual, yang merupakan inovasi terbesar algoritma ini.
Seperti yang ditunjukkan dalam Jadual 2, set latihan PPO datang sepenuhnya daripada API. Ia membimbing latihan berterusan model SFT melalui model ganjaran yang diperoleh dalam langkah 2. Banyak kali pembelajaran pengukuhan adalah sangat sukar untuk dilatih InstructGPT/ChatGPT menghadapi dua masalah semasa proses latihan:
- Masalah 1: Apabila model dikemas kini, data dan latihan yang dihasilkan oleh model pembelajaran pengukuhan. perbezaan dalam data untuk model ganjaran akan menjadi lebih besar dan lebih besar. Penyelesaian penulis ialah menambah istilah penalti KL βlog(πϕRL(y∣x)/πSFT(y∣x)) kepada fungsi kehilangan untuk memastikan bahawa output model PPO dan output SFT tidak begitu berbeza.
- Masalah 2: Hanya menggunakan model PPO untuk latihan akan membawa kepada penurunan yang ketara dalam prestasi model pada tugasan umum NLP Penyelesaian penulis ialah menambah sasaran model bahasa umum γEx∼Dpretrain kepada sasaran latihan [. log(πϕRL(x))], pembolehubah ini dipanggil PPO-ptx dalam kertas.
Ringkasnya, matlamat latihan PPO ialah formula (2). (2) objektif (ϕ)=E(x,y)∼DπϕRL[rθ(x,y)−βlog(πϕRL(y∣x)/πSFT(y∣x))]+γEx∼Dpralatihan [log( πϕRL(x))]
3. Analisis prestasi InstructGPT/ChatGPT
Tidak dapat dinafikan bahawa kesan InstructGPT/ChatGPT adalah sangat baik, terutamanya selepas pengenalan anotasi manual, biarkan The "nilai" dan ketepatan model dan "keaslian" pola tingkah laku manusia telah banyak dipertingkatkan. Jadi, hanya berdasarkan penyelesaian teknikal dan kaedah latihan InstructGPT/ChatGPT, kita boleh menganalisis apakah kesan peningkatan yang boleh dibawa?
3.1 Kelebihan
- Kesan InstructGPT/ChatGPT adalah lebih realistik daripada GPT-3: Ini mudah difahami, kerana GPT-3 sendiri mempunyai keupayaan generalisasi dan penjanaan yang sangat kuat, serta On InstructGPT /ChatGPT, pelabel berbeza diperkenalkan untuk menulis segera dan menjana pengisihan hasil, dan ia juga diperhalusi di atas GPT-3, yang membolehkan kami memperoleh ganjaran yang lebih tinggi untuk data yang lebih realistik apabila melatih model ganjaran. Penulis juga membandingkan prestasi mereka dengan GPT-3 pada set data TruthfulQA Keputusan eksperimen menunjukkan bahawa walaupun 1.3 bilion PPO-ptx bersaiz kecil berprestasi lebih baik daripada GPT-3.
- InstructGPT/ChatGPT adalah lebih tidak berbahaya sedikit daripada GPT-3 dari segi model tidak berbahaya: prinsipnya adalah sama seperti di atas. Walau bagaimanapun, penulis mendapati bahawa InstructGPT tidak bertambah baik dengan ketara pada diskriminasi, prejudis dan set data lain. Ini kerana GPT-3 sendiri adalah model yang sangat berkesan, dan kebarangkalian untuk menghasilkan sampel bermasalah dengan keadaan berbahaya, diskriminasi, berat sebelah, dan lain-lain adalah sangat rendah. Hanya mengumpul dan melabelkan data melalui 40 pelabel mungkin tidak dapat mengoptimumkan sepenuhnya model dalam aspek ini, jadi peningkatan dalam prestasi model akan menjadi sedikit atau tidak dapat dilihat.
- InstructGPT/ChatGPT mempunyai keupayaan pengekodan yang kukuh: Pertama sekali, GPT-3 mempunyai keupayaan pengekodan yang kukuh dan API berdasarkan GPT-3 juga telah mengumpul sejumlah besar kod pengekodan. Dan beberapa pekerja dalaman OpenAI turut mengambil bahagian dalam kerja pengumpulan data. Melalui sejumlah besar data yang berkaitan dengan pengekodan dan anotasi manual, tidak menghairankan bahawa InstructGPT/ChatGPT yang terlatih mempunyai keupayaan pengekodan yang sangat kuat.
3.2 Kelemahan
- InstructGPT/ChatGPT akan mengurangkan keberkesanan model pada tugasan umum NLP: Kami membincangkan perkara ini semasa latihan PPO, walaupun fungsi kehilangan diubah suai Ia boleh dikurangkan, tetapi masalahnya tidak diselesaikan sepenuhnya.
- Kadangkala InstructGPT/ChatGPT akan memberikan beberapa output yang tidak masuk akal: Walaupun InstructGPT/ChatGPT menggunakan maklum balas manusia, ia dihadkan oleh sumber manusia yang terhad. Perkara yang paling mempengaruhi model ialah tugas model bahasa yang diselia, di mana manusia hanya memainkan peranan pembetulan. Oleh itu, berkemungkinan besar ia dihadkan oleh data pembetulan yang terhad, atau mengelirukan tugas yang diselia (hanya mengambil kira output model, bukan apa yang manusia inginkan), mengakibatkan kandungan tidak realistik yang dihasilkannya. Sama seperti seorang pelajar, walaupun ada guru yang membimbingnya, belum tentu pelajar itu dapat mempelajari semua titik ilmu.
- Model ini sangat sensitif kepada arahan: Ini juga boleh dikaitkan dengan jumlah data yang tidak mencukupi yang dijelaskan oleh pelabel, kerana arahan adalah satu-satunya petunjuk untuk model menghasilkan output Jika bilangan dan jenis arahan tidak dilatih dengan secukupnya, ia boleh menyebabkan Model mempunyai masalah ini.
- Model terlalu mentafsir konsep mudah: Ini mungkin kerana pelabel cenderung memberikan ganjaran yang lebih tinggi kepada kandungan output yang lebih panjang apabila membandingkan kandungan yang dijana.
- Arahan yang berbahaya mungkin mengeluarkan balasan yang berbahaya: contohnya, InstructGPT/ChatGPT juga akan memberikan pelan tindakan untuk "Pelan Pemusnahan AI Kemanusiaan" yang dicadangkan oleh pengguna (Rajah 5). Ini kerana InstructGPT/ChatGPT menganggap bahawa arahan yang ditulis oleh pelabel adalah munasabah dan mempunyai nilai yang betul, dan tidak membuat pertimbangan yang lebih terperinci mengenai arahan yang diberikan oleh pengguna, yang akan menyebabkan model memberikan balasan kepada sebarang input. Walaupun model ganjaran terkemudian mungkin memberikan nilai ganjaran yang lebih rendah kepada jenis output ini, apabila model menjana teks, model itu bukan sahaja perlu mempertimbangkan nilai model, tetapi juga mempertimbangkan padanan kandungan dan arahan yang dijana. Kadangkala terdapat masalah dengan menjana beberapa nilai Output juga mungkin.

Rajah 5: Rancangan untuk kemusnahan manusia yang ditulis oleh ChatGPT.
3.3 Kerja masa hadapan
Kami telah menganalisis penyelesaian teknikal InstrcutGPT/ChatGPT dan masalahnya, kemudian kami juga boleh melihat sudut pengoptimuman InstrcutGPT/ChatGPT.
- Pengurangan kos dan peningkatan kecekapan anotasi manual: InstrcutGPT/ChatGPT menggunakan pasukan anotasi 40 orang, tetapi berdasarkan prestasi model, pasukan 40 orang ini tidak mencukupi. Bagaimana untuk membolehkan manusia menyediakan kaedah maklum balas yang lebih berkesan dan secara organik dan mahir menggabungkan prestasi manusia dan prestasi model adalah sangat penting.
- Keupayaan model untuk menyamaratakan/menyimpan arahan yang betul: Arahan adalah satu-satunya petunjuk untuk model menghasilkan output, dan model sangat bergantung padanya Cara meningkatkan keupayaan generalisasi model bagi arahan dan arahan ralat keupayaan pembetulan yang ditunjukkan adalah tugas yang sangat penting untuk meningkatkan pengalaman model. Ini bukan sahaja membolehkan model mempunyai rangkaian senario aplikasi yang lebih luas, tetapi juga menjadikan model lebih "pintar".
- Elakkan kemerosotan prestasi pada tugas umum: Mungkin perlu untuk mereka bentuk cara yang lebih munasabah untuk menggunakan maklum balas manusia, atau struktur model yang lebih canggih. Kerana kami membincangkan bahawa banyak masalah InstrcutGPT/ChatGPT boleh diselesaikan dengan menyediakan lebih banyak data berlabel pelabel, tetapi ini akan membawa kepada kemerosotan prestasi yang lebih serius bagi tugasan umum NLP, jadi penyelesaian diperlukan untuk meningkatkan prestasi 3H dan tugasan umum NLP yang menjana hasil mencapai keseimbangan.
3.4 InstrcutGPT/ChatGPT jawapan topik hangat
- Adakah kemunculan ChatGPT menyebabkan pengaturcara peringkat rendah kehilangan pekerjaan mereka? Berdasarkan prinsip ChatGPT dan kandungan yang dijana bocor di Internet, banyak kod yang dijana oleh ChatGPT boleh berjalan dengan betul. Tetapi tugas seorang pengaturcara bukan sahaja untuk menulis kod, tetapi yang lebih penting untuk mencari penyelesaian kepada masalah. Oleh itu, ChatGPT tidak akan menggantikan pengaturcara, terutamanya pengaturcara peringkat tinggi. Sebaliknya, ia akan menjadi alat yang sangat berguna untuk pengaturcara untuk menulis kod, seperti banyak alat penjanaan kod hari ini.
- Stack Overflow mengumumkan peraturan sementara: Larang ChatGPT. ChatGPT pada asasnya ialah model penjanaan teks Berbanding dengan penjanaan kod, ia lebih baik dalam menjana teks palsu. Selain itu, kod atau penyelesaian yang dijana oleh model penjanaan teks tidak dijamin boleh dijalankan dan boleh menyelesaikan masalah, tetapi ia akan mengelirukan ramai orang yang menanyakan masalah ini dengan berpura-pura sebagai teks sebenar. Untuk mengekalkan kualiti forum, Stack Overflow telah mengharamkan ChatGPT dan juga sedang membersihkan.
- Chatbot ChatGPT telah didorong untuk menulis "rancangan untuk memusnahkan manusia" dan memberikan kod apakah isu yang perlu diberi perhatian dalam pembangunan AI? "Rancang untuk Memusnahkan Kemanusiaan" ChatGPT ialah kandungan terjana yang dipasang secara paksa berdasarkan data besar-besaran di bawah arahan yang tidak dijangka. Walaupun kandungannya kelihatan sangat nyata dan ungkapannya sangat fasih, ia hanya menunjukkan bahawa ChatGPT mempunyai kesan generatif yang sangat kuat, tetapi ini tidak bermakna ChatGPT mempunyai idea untuk memusnahkan manusia. Kerana ia hanya model penjanaan teks, bukan model membuat keputusan.
4. Ringkasan
Sama seperti kebanyakan orang semasa algoritma pertama kali dilahirkan, ChatGPT telah menarik perhatian meluas dalam industri dan manusia dengan kegunaan, keaslian dan kesannya yang tidak berbahaya pada AI. Tetapi selepas kami melihat prinsip algoritmanya, kami mendapati ia tidak semenakutkan seperti yang diiklankan dalam industri. Sebaliknya, kita boleh belajar banyak perkara berharga daripada penyelesaian teknikalnya. Sumbangan paling penting InstrcutGPT/ChatGPT dalam industri AI ialah gabungan pintar model pembelajaran pengukuhan dan pra-latihan. Selain itu, maklum balas tiruan meningkatkan kegunaan, ketulenan dan tidak berbahaya model. ChatGPT juga telah meningkatkan lagi kos model besar Sebelum ini, ia hanya persaingan antara volum data dan skala model Kini ia malah memperkenalkan perbelanjaan pengambilan sumber luar, menjadikan pekerja individu lebih mahal.
Rujukan
- ^Ouyang, Long, et al. "Melatih model bahasa untuk mengikuti arahan dengan maklum balas manusia." // /arxiv.org/pdf/2203.02155.pdf
- ^Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Meningkatkan pemahaman bahasa melalui pra-latihan generatif. https: //www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
- ^Radford, A., Wu, J., Child, R., Luan, D., Amodei , D . dan Sutskever, I., 2019. Model bahasa ialah pelajar berbilang tugas tanpa pengawasan *Blog OpenAI*, *1*(8), h.9. 27/ GPT%E6%8A%80%E6%9C%AF%E5%88%9D%E6%8E%A2/language-models.pdf
- ^Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al "Model bahasa adalah pelajar yang jarang dicetak". /file /1457c0d6bfcb4967418bfb8ac142f64a-Paper.pdf
- ^Wei, Jason, et al. org/ pdf/2109.01652.pdf
- ^Christiano, Paul F., et al. "Pembelajaran peneguhan mendalam daripada pilihan manusia." *Kemajuan dalam sistem pemprosesan maklumat saraf* 30 (2017). .org /pdf/1706.03741.pdf
- ^Schulman, John, et al "Algoritma pengoptimuman dasar proksimal arXiv:1707.06347* (2017 https://arxiv.org/pdf/). 1707.06347. pdf
Atas ialah kandungan terperinci Penjelasan terperinci ChatGPT/InstructGPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
DALL-E 3 telah diperkenalkan secara rasmi pada September 2023 sebagai model yang jauh lebih baik daripada pendahulunya. Ia dianggap sebagai salah satu penjana imej AI terbaik setakat ini, mampu mencipta imej dengan perincian yang rumit. Walau bagaimanapun, semasa pelancaran, ia adalah tidak termasuk
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
