
 Peranti teknologi
AI
Penyelidikan operasi dipacu AI mengoptimumkan 'mesin litografi'! Universiti Sains dan Teknologi China dan lain-lain mencadangkan model jujukan hierarki untuk meningkatkan kecekapan penyelesaian pengaturcaraan matematik.
Peranti teknologi
AI
Penyelidikan operasi dipacu AI mengoptimumkan 'mesin litografi'! Universiti Sains dan Teknologi China dan lain-lain mencadangkan model jujukan hierarki untuk meningkatkan kecekapan penyelesaian pengaturcaraan matematik.
Penyelidikan operasi dipacu AI mengoptimumkan 'mesin litografi'! Universiti Sains dan Teknologi China dan lain-lain mencadangkan model jujukan hierarki untuk meningkatkan kecekapan penyelesaian pengaturcaraan matematik.

Penyelesai pengaturcaraan matematik dikenali sebagai "mesin litografi" dalam bidang penyelidikan operasi dan pengoptimuman kerana kepentingan dan serba bolehnya.
Antaranya, Mixed-Integer Linear Programming (MILP) ialah komponen utama penyelesai pengaturcaraan matematik dan boleh memodelkan sejumlah besar aplikasi praktikal, seperti penjadualan pengeluaran industri, penjadualan logistik, reka bentuk cip dan perancangan laluan ., pelaburan kewangan dan bidang utama lain.
Baru-baru ini, pasukan Profesor Wang Jie di Makmal MIRA Universiti Sains dan Teknologi China dan Makmal Bahtera Nuh Huawei telah bersama-sama mencadangkan Model Jujukan Hierarki (HEM), yang meningkatkan kecekapan penyelesaian integer campuran. penyelesai pengaturcaraan linear, dan hasil yang berkaitan telah diterbitkan pada ICLR 2023.
Pada masa ini, algoritma telah disepadukan ke dalam perpustakaan model MindSpore ModelZoo Huawei, dan teknologi serta keupayaan yang berkaitan akan disepadukan ke dalam penyelesai AI OptVerse Huawei tahun ini. Penyelesai ini bertujuan untuk menggabungkan penyelidikan operasi dan AI untuk menembusi had pengoptimuman penyelidikan operasi industri, membantu perusahaan dalam membuat keputusan kuantitatif dan operasi yang diperhalusi, dan mencapai pengurangan kos dan peningkatan kecekapan!

Senarai pengarang: Wang Zhihai*, Li Xijun*, Wang Jie**, Kuang Yufei, Yuan Mingxuan, Zeng Jia, Zhang Yongdong, Wu Feng
Pautan kertas: https://openreview.net/forum?id=Zob4P9bRNcK
Set data sumber terbuka: https://drive.google.com/drive/folders/1LXLZ8vq3L7v00XH- Tx3U6hiTJ79sCzxY?usp=sharing
Kod sumber terbuka versi PyTorch: https://github.com/MIRALab-USTC/L2O-HEM-Torch
Kod sumber terbuka versi MindSpore: https:// gitee.com/mindspore/models/ tree/master/research/l2o/hem-learning-to-cut
Penyelesai AI Tianchou (OptVerse): https://www.huaweicloud.com/product/modelarts/ optverse.html

Rajah 1. Perbandingan kecekapan penyelesaian antara HEM dan strategi lalai penyelesai (Lalai kecekapan penyelesaian HEM boleh dipertingkatkan sehingga 47.28%
1 Pengenalan
Pemotongan satah (potongan) adalah penting untuk menyelesaikan masalah pengaturcaraan linear integer campuran dengan cekap.
Antaranya, pemilihan potong (cut selection) bertujuan untuk memilih subset yang sesuai bagi satah potong untuk dipilih bagi meningkatkan kecekapan menyelesaikan MILP. Pemilihan satah pemotongan banyak bergantung pada dua sub-masalah: (P1) satah pemotongan yang manakah harus diutamakan, dan (P2) berapa satah pemotongan harus dipilih.
Walaupun banyak penyelesai MILP moden mengendalikan (P1) dan (P2) dengan heuristik yang direka secara manual, kaedah pembelajaran mesin mempunyai potensi untuk mempelajari heuristik yang lebih cekap.
Walau bagaimanapun, banyak kaedah pembelajaran sedia ada memfokuskan pada pembelajaran satah pemotongan yang harus diutamakan, tetapi abaikan mempelajari bilangan satah pemotongan yang perlu dipilih. Di samping itu, kami telah memerhati daripada sebilangan besar keputusan eksperimen bahawa satu lagi masalah kecil, iaitu (P3), yang memotong susunan satah harus diutamakan, juga mempunyai kesan yang signifikan terhadap kecekapan menyelesaikan MILP.
Untuk menangani cabaran ini, kami mencadangkan Model Jujukan Hierarki (HEM) novel dan mempelajari strategi pemilihan satah pemotongan melalui rangka kerja pembelajaran pengukuhan.
Setahu kita HEM merupakan kaedah pembelajaran pertama yang boleh mengendalikan (P1), (P2) dan (P3) secara serentak. Eksperimen menunjukkan bahawa HEM meningkatkan kecekapan menyelesaikan MILP dengan ketara berbanding garis dasar yang direka dan dipelajari secara manual pada set data MILP dunia sebenar yang dijana secara buatan dan berskala besar.
2 Latar belakang dan pengenalan masalah
2.1 Pengenalan kepada satah pemotongan (potongan)
Mixed-Integer Linear Programming (MILP) ialah model pengoptimuman umum yang digunakan secara meluas dalam pelbagai bidang aplikasi praktikal, seperti pengurusan rantaian bekalan [1], perancangan pengeluaran [2], perancangan dan penghantaran [3], pemilihan lokasi kilang [4], masalah pembungkusan [5], dsb.
MILP standard mempunyai bentuk berikut:

(1)
Masalah yang diberikan ( 1), kami membuang semua kekangan integernya dan mendapatkan masalah kelonggaran pengaturcaraan linear (LPR), yang dalam bentuk:

(2)
Memandangkan masalah (2) memanjangkan set masalah yang boleh dilaksanakan (1), kita boleh mempunyai bahawa nilai optimum masalah LPR adalah sempadan bawah masalah MILP asal.
Memandangkan masalah LPR dalam (2), satah pemotongan (potongan) ialah kelas ketaksamaan linear undang-undang yang, apabila ditambah kepada masalah kelonggaran pengaturcaraan linear, mengecilkan kemungkinan ruang domain masalah LPR tanpa mengalih keluar sebarang penyelesaian boleh dilaksanakan integer bagi masalah MILP asal.
2.2 Pengenalan kepada pemilihan potong
Penyelesai MILP boleh menjana sejumlah besar satah pemotong dalam proses menyelesaikan masalah MILP, dan akan terus menambah satah pemotongan kepada masalah asal dalam pusingan berturut-turut.
Secara khusus, setiap pusingan merangkumi lima langkah:
(1) Selesaikan masalah LPR semasa
(2) Hasilkan satu siri satah pemotongan untuk dipilih ;
(3) Pilih subset yang sesuai daripada satah pemotongan untuk dipilih;
(4) Tambahkan subset yang dipilih kepada masalah LPR dalam (1) untuk mendapatkan masalah LPR Baharu;
(5) Kitaran diulang, berdasarkan masalah LPR baharu, dan memasuki pusingan seterusnya. Menambah semua satah pemotongan yang dijana kepada masalah LPR mengecilkan ruang domain yang boleh dilaksanakan bagi masalah tersebut ke tahap maksimum yang mungkin untuk memaksimumkan sempadan bawah. Walau bagaimanapun, menambah terlalu banyak satah pemotongan boleh menyebabkan masalah mempunyai terlalu banyak kekangan, meningkatkan overhed pengiraan penyelesaian masalah dan menyebabkan masalah ketidakstabilan berangka [6,7]. Oleh itu, penyelidik telah mencadangkan pemilihan satah pemotongan (cut selection), yang bertujuan untuk memilih subset satah pemotongan calon yang sesuai untuk meningkatkan kecekapan penyelesaian masalah MILP sebanyak mungkin. Pemilihan satah pemotongan adalah penting untuk meningkatkan kecekapan menyelesaikan masalah pengaturcaraan linear integer bercampur [8, 9, 10]. 2.3 Percubaan heuristik - tertib penambahan satah pemotonganKami mereka bentuk dua algoritma heuristik untuk pemilihan satah memotong, iaitu RandomAll dan RandomNV (lihat Bab 3 kertas asal untuk butiran). Mereka semua menambah potongan yang dipilih pada masalah MILP dalam susunan rawak selepas memilih kumpulan potongan. Seperti yang ditunjukkan dalam keputusan dalam Rajah 2, apabila satah pemotongan yang sama dipilih, menambah satah pemotongan terpilih ini dalam susunan yang berbeza mempunyai kesan yang besar terhadap kecekapan penyelesaian penyelesai (lihat Bab 3 kertas asal untuk analisis keputusan terperinci).

Seperti yang ditunjukkan dalam modul Ejen dalam Rajah 3, HEM terdiri daripada model dasar atas dan bawah. Model lapisan atas dan bawah masing-masing mempelajari dasar lapisan atas (dasar) dan dasar lapisan bawah.
Pertama, dasar peringkat atas mempelajari bilangan pemotongan yang harus dipilih dengan meramalkan perkadaran yang sesuai. Dengan mengandaikan bahawa panjang keadaan ialah dan nisbah ramalan ialah , maka bilangan potongan yang harus dipilih untuk ramalan ialah 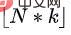
, dengan 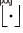 mewakili fungsi pembundaran ke bawah. Kami mentakrifkan
mewakili fungsi pembundaran ke bawah. Kami mentakrifkan  .
.
Kedua, dasar peringkat rendah belajar memilih subset tertib bagi saiz tertentu. Dasar peringkat bawah boleh mentakrifkan 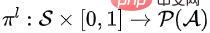 , dengan
, dengan 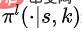 mewakili taburan kebarangkalian pada ruang tindakan yang diberi keadaan S dan perkadaran K. Secara khusus, kami memodelkan dasar asas sebagai urutan kepada model jujukan (model jujukan).
mewakili taburan kebarangkalian pada ruang tindakan yang diberi keadaan S dan perkadaran K. Secara khusus, kami memodelkan dasar asas sebagai urutan kepada model jujukan (model jujukan).
Akhir sekali, strategi pemilihan potong diperolehi melalui hukum jumlah kebarangkalian, iaitu

3.3 Kaedah latihan: hierarki kecerunan dasar
Fungsi objektif pengoptimuman yang diberikan

Rajah 4. Kecerunan dasar hierarki. Kami mengoptimumkan model HEM dalam cara penurunan kecerunan stokastik ini.
4 Pengenalan Eksperimen
Eksperimen kami mempunyai lima bahagian utama:
Eksperimen 1. Pada 3 masalah MILP yang dijana secara buatan dan 6 masalah dengan Kaedah kami dinilai pada masalah MILP yang mencabar penanda aras.
Eksperimen 2. Jalankan eksperimen ablasi yang direka dengan teliti untuk memberikan cerapan yang mendalam tentang HEM.
Eksperimen 3. Uji prestasi generalisasi HEM untuk saiz masalah.
Percubaan 4. Visualisasikan ciri-ciri satah pemotongan yang dipilih mengikut kaedah dan garis dasar kami.
Percubaan 5. Gunakan kaedah kami kepada masalah penjadualan pengeluaran sebenar Huawei untuk mengesahkan keunggulan HEM.
Kami hanya memperkenalkan Eksperimen 1 dalam artikel ini Untuk lebih banyak hasil percubaan, sila lihat Bab 5 kertas asal. Sila ambil perhatian bahawa semua keputusan percubaan yang dilaporkan dalam kertas kami adalah keputusan yang diperoleh berdasarkan latihan dengan kod versi PyTorch.
Keputusan Eksperimen 1 ditunjukkan dalam Jadual 1. Kami membandingkan keputusan HEM dan 6 garis dasar pada 9 set data sumber terbuka. Keputusan eksperimen menunjukkan bahawa HEM boleh meningkatkan kecekapan penyelesaian kira-kira 20% secara purata.

Rajah 5. Penilaian strategi pada set data mudah, sederhana dan keras. Prestasi optimum ditandakan dalam huruf tebal. Biarkan m mewakili purata bilangan kekangan, dan n mewakili purata bilangan pembolehubah. Kami menunjukkan min aritmetik (sisihan piawai) masa penyelesaian dan kamiran jurang primal-dwi.
Atas ialah kandungan terperinci Penyelidikan operasi dipacu AI mengoptimumkan 'mesin litografi'! Universiti Sains dan Teknologi China dan lain-lain mencadangkan model jujukan hierarki untuk meningkatkan kecekapan penyelesaian pengaturcaraan matematik.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Untuk menetapkan masa untuk Vue Axios, kita boleh membuat contoh Axios dan menentukan pilihan masa tamat: dalam tetapan global: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dalam satu permintaan: ini. $ axios.get ('/api/pengguna', {timeout: 10000}).
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
 Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
MySQL boleh mengembalikan data JSON. Fungsi JSON_EXTRACT mengekstrak nilai medan. Untuk pertanyaan yang kompleks, pertimbangkan untuk menggunakan klausa WHERE untuk menapis data JSON, tetapi perhatikan kesan prestasinya. Sokongan MySQL untuk JSON sentiasa meningkat, dan disyorkan untuk memberi perhatian kepada versi dan ciri terkini.
 Kunci utama MySQL boleh menjadi batal
Apr 08, 2025 pm 03:03 PM
Kunci utama MySQL boleh menjadi batal
Apr 08, 2025 pm 03:03 PM
Kunci utama MySQL tidak boleh kosong kerana kunci utama adalah atribut utama yang secara unik mengenal pasti setiap baris dalam pangkalan data. Jika kunci utama boleh kosong, rekod tidak dapat dikenal pasti secara unik, yang akan membawa kepada kekeliruan data. Apabila menggunakan lajur integer sendiri atau UUIDs sebagai kunci utama, anda harus mempertimbangkan faktor-faktor seperti kecekapan dan penghunian ruang dan memilih penyelesaian yang sesuai.
 Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Penjelasan terperinci mengenai atribut asid asid pangkalan data adalah satu set peraturan untuk memastikan kebolehpercayaan dan konsistensi urus niaga pangkalan data. Mereka menentukan bagaimana sistem pangkalan data mengendalikan urus niaga, dan memastikan integriti dan ketepatan data walaupun dalam hal kemalangan sistem, gangguan kuasa, atau pelbagai pengguna akses serentak. Gambaran keseluruhan atribut asid Atomicity: Transaksi dianggap sebagai unit yang tidak dapat dipisahkan. Mana -mana bahagian gagal, keseluruhan transaksi dilancarkan kembali, dan pangkalan data tidak mengekalkan sebarang perubahan. Sebagai contoh, jika pemindahan bank ditolak dari satu akaun tetapi tidak meningkat kepada yang lain, keseluruhan operasi dibatalkan. Begintransaction; UpdateAcCountSsetBalance = Balance-100Wh
