
 pembangunan bahagian belakang
Tutorial Python
Python memperoleh maklumat dan ulasan tarikan pelancong serta mencipta awan perkataan dan visualisasi data
pembangunan bahagian belakang
Tutorial Python
Python memperoleh maklumat dan ulasan tarikan pelancong serta mencipta awan perkataan dan visualisasi data
Python memperoleh maklumat dan ulasan tarikan pelancong serta mencipta awan perkataan dan visualisasi data


Helo semua, saya Encik Chewshu!
Bak kata pepatah: Bukankah seronok mempunyai kawan dari jauh? Ia adalah perkara yang sangat menggembirakan untuk mempunyai rakan-rakan datang bermain dengan kami, jadi kami harus melakukan yang terbaik untuk menjadi tuan tanah dan membawa rakan-rakan kami bermain! Jadi persoalannya ialah, bilakah masa terbaik dan ke mana hendak pergi, dan di manakah tempat yang paling menyeronokkan?
Hari ini saya akan mengajar anda langkah demi langkah cara menggunakan kumpulan benang untuk merangkak maklumat tarikan dan menyemak data perjalanan yang sama serta membuat awan perkataan dan visualisasi data! ! ! Beritahu anda maklumat tentang tarikan pelancong di pelbagai bandar.
Sebelum kita mula merangkak data, mari kita fahami urutan dahulu.
Thread
Proses: Proses ialah aktiviti berjalan kod pada pengumpulan data dan merupakan unit asas peruntukan sumber dan penjadualan dalam sistem.
Thread: Ia ialah proses yang ringan, unit terkecil pelaksanaan program dan laluan pelaksanaan proses tersebut.
Terdapat sekurang-kurangnya satu urutan dalam satu proses dan berbilang rangkaian dalam proses berkongsi sumber proses tersebut.
Kitaran hayat benang
Sebelum mencipta berbilang utas, mari kita pelajari terlebih dahulu tentang kitaran hayat benang, seperti yang ditunjukkan dalam rajah di bawah:
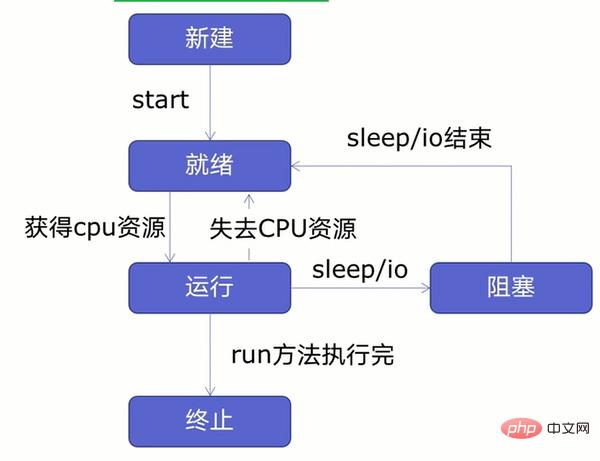
Seperti yang dapat dilihat dari rajah, benang boleh dibahagikan kepada lima keadaan - baru, sedia, berjalan, disekat, dan ditamatkan.
Mula-mula buat utas baharu dan mulakan utas Selepas itu, utas dalam keadaan sedia tidak akan berjalan serta-merta selepas memperoleh sumber CPU memasuki keadaan berjalan, utas mungkin kehilangan CPU Benang memasuki keadaan sedia atau keadaan disekat apabila sumber menghadapi operasi tidur atau IO (membaca, menulis, dll. Ia akan memasuki keadaan berjalan hanya selepas tidur atau IO). operasi tamat atau sumber CPU diperoleh semula Ia akan memasuki keadaan ditamatkan selepas operasi selesai.
Nota: Mencipta sistem utas baharu memerlukan peruntukan sumber, dan menamatkan sistem utas memerlukan sumber kitar semula Jadi bagaimana untuk mengurangkan overhed sistem mencipta/menamatkan utas pada masa ini? guna semula benang Ini boleh mengurangkan overhed sistem.
Sebelum mencipta kumpulan benang, mari kita pelajari dahulu cara membuat berbilang rangkaian.
Mencipta berbilang benang
Mencipta berbilang benang boleh dibahagikan kepada empat langkah:
- Mencipta fungsi;
- Mencipta benang; > Mulakan utas;
- Tunggu hingga tamat
Buat fungsi
Untuk kemudahan demonstrasi, kami menggunakan halaman web taman blog sebagai fungsi perangkak Kod khusus adalah seperti berikut:import requests
urls=[
f'https://www.cnblogs.com/#p{page}'
for page in range(1,50)
]
def get_parse(url):
response=requests.get(url)
print(url,len(response.text))Buat utas
Dalam langkah sebelumnya kami mencipta fungsi perangkak, dan seterusnya kami akan mencipta utas Kod khusus adalah seperti berikut:import threading #多线程 def multi_thread(): threads=[] for url in urls: threads.append( threading.Thread(target=get_parse,args=(url,)) )
- sasaran ialah fungsi berjalan; args ialah parameter yang diperlukan untuk menjalankan fungsi.
Mulakan utas
Benang telah dibuat Seterusnya, utas akan dimulakan adalah sangat mudah 🎜>Mula-mula, kami memperoleh tugasan utas dalam senarai utas melalui gelung for dan mulakan utas melalui .start().
for thread in threads: thread.start()
Selepas memulakan utas, anda akan menunggu sehingga utas itu tamat Kod khusus adalah seperti berikut:
Sama seperti memulakan utas , mula-mula dapatkan tugasan utas dalam senarai utas melalui gelung for, dan kemudian gunakan kaedah .join() untuk menunggu sehingga utas itu tamat.for thread in threads: thread.join()
Multi-threading telah dibuat Seterusnya, kami akan menguji kelajuan multi-threading Kod khusus adalah seperti berikut:
Hasil berjalan adalah seperti yang ditunjukkan di bawah: <. 🎜>if __name__ == '__main__': t1=time.time() multi_thread() t2=time.time() print(t2-t1)
Ia hanya mengambil masa lebih daripada 1 saat untuk merangkak 50 halaman web taman blog dengan berbilang urutan dan URL permintaan rangkaian berbilang benang adalah rawak. 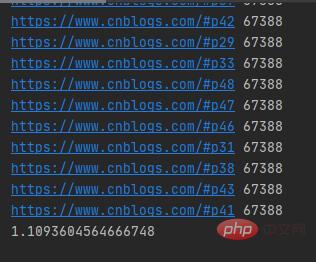
Hasil larian adalah seperti yang ditunjukkan di bawah:
if __name__ == '__main__': t1=time.time() for i in urls: get_parse(i) t2=time.time() print(t2-t1)
<. 🎜>
Memerlukan lebih daripada 9 saat untuk satu utas untuk merangkak 50 halaman web park blog.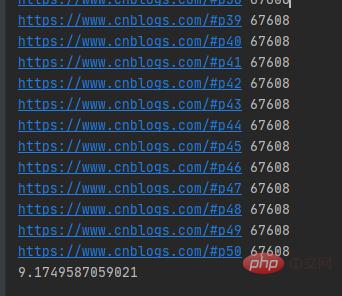 Seperti yang kami katakan di atas, mencipta sistem benang baharu memerlukan peruntukan sumber, dan menamatkan sistem benang memerlukan sumber kitar semula Untuk mengurangkan overhed sistem, kami boleh mencipta kumpulan benang.
Seperti yang kami katakan di atas, mencipta sistem benang baharu memerlukan peruntukan sumber, dan menamatkan sistem benang memerlukan sumber kitar semula Untuk mengurangkan overhed sistem, kami boleh mencipta kumpulan benang.
线程池原理
一个线程池由两部分组成,如下图所示:
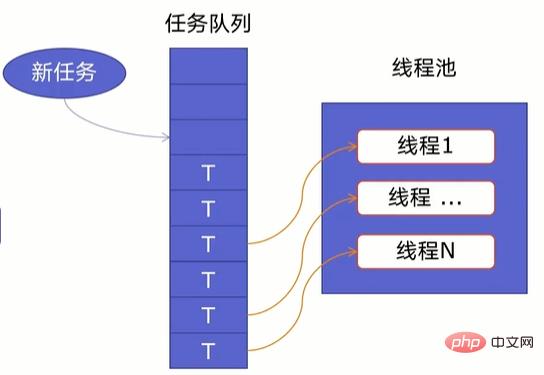
- 线程池:里面提前建好N个线程,这些都会被重复利用;
- 任务队列:当有新任务的时候,会把任务放在任务队列中。
当任务队列里有任务时,线程池的线程会从任务队列中取出任务并执行,执行完任务后,线程会执行下一个任务,直到没有任务执行后,线程会回到线程池中等待任务。
使用线程池可以处理突发性大量请求或需要大量线程完成任务(处理时间较短的任务)。
好了,了解了线程池原理后,我们开始创建线程池。
线程池创建
Python提供了ThreadPoolExecutor类来创建线程池,其语法如下所示:
ThreadPoolExecutor(max_workers=None, thread_name_prefix='', initializer=None, initargs=())
其中:
- max_workers:最大线程数;
- thread_name_prefix:允许用户控制由线程池创建的threading.Thread工作线程名称以方便调试;
- initializer:是在每个工作者线程开始处调用的一个可选可调用对象;
- initargs:传递给初始化器的元组参数。
注意:在启动 max_workers 个工作线程之前也会重用空闲的工作线程。
在ThreadPoolExecutor类中提供了map()和submit()函数来插入任务队列。其中:
map()函数
map()语法格式为:
map(调用方法,参数队列)
具体示例如下所示:
import requestsimport concurrent.futuresimport timeurls=[f'https://www.cnblogs.com/#p{page}'for page in range(1,50)]def get_parse(url):response=requests.get(url)return response.textdef map_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20) as pool:htmls=pool.map(get_parse,urls)htmls=list(zip(urls,htmls))for url,html in htmls:print(url,len(html))if __name__ == '__main__':t1=time.time()map_pool()t2=time.time()print(t2-t1)首先我们导入requests网络请求库、concurrent.futures模块,把所有的URL放在urls列表中,然后自定义get_parse()方法来返回网络请求返回的数据,再自定义map_pool()方法来创建代理池,其中代理池的最大max_workers为20,调用map()方法把网络请求任务放在任务队列中,在把返回的数据和URL合并为元组,并放在htmls列表中。
运行结果如下图所示:
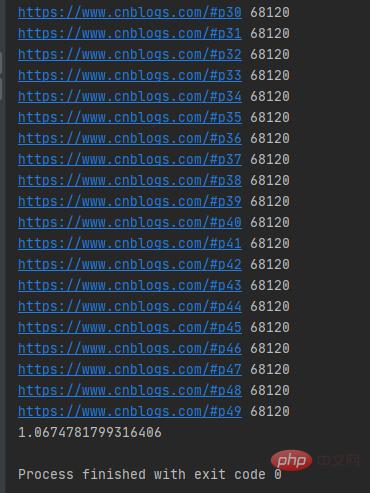
可以发现map()函数返回的结果和传入的参数顺序是对应的。
注意:当我们直接在自定义方法get_parse()中打印结果时,打印结果是乱序的。
submit()函数
submit()函数语法格式如下:
submit(调用方法,参数)
具体示例如下:
def submit_pool():with concurrent.futures.ThreadPoolExecutor(max_workers=20)as pool:futuress=[pool.submit(get_parse,url)for url in urls]futures=zip(urls,futuress)for url,future in futures:print(url,len(future.result()))
运行结果如下图所示:
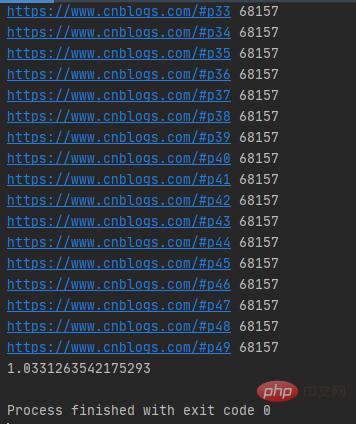
注意:submit()函数输出结果需需要调用result()方法。
好了,线程知识就学到这里了,接下来开始我们的爬虫。
爬前分析
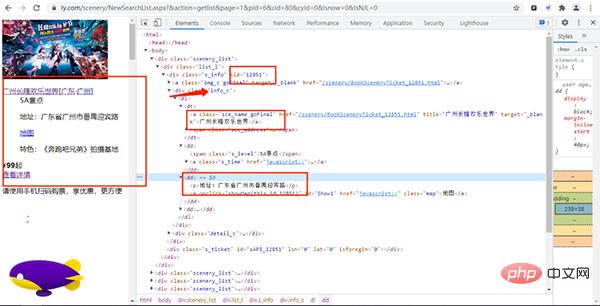
首先我们进入同程旅行的景点网页并打开开发者工具,如下图所示:
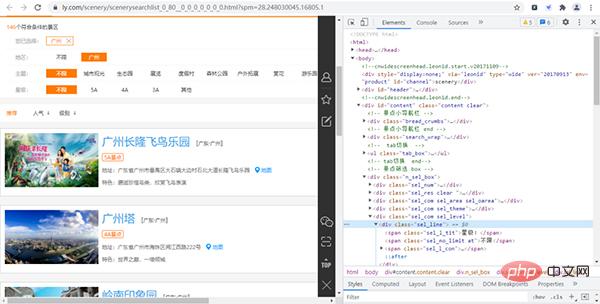
经过寻找,我们发现各个景点的基础信息(详情页URL、景点id等)都存放在下图的URL链接中,
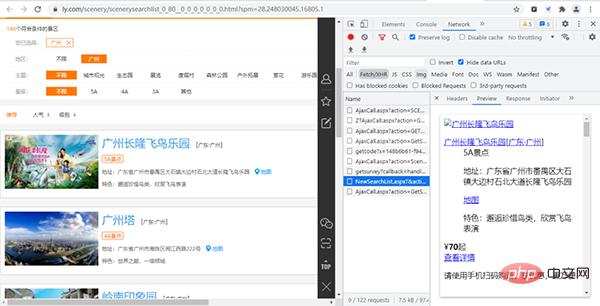
其URL链接为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=2&kw=&pid=6&cid=80&cyid=0&sort=&isnow=0&spType=&lbtypes=&IsNJL=0&classify=0&grade=&dctrack=1%CB%871629537670551030%CB%8720%CB%873%CB%872557287248299209%CB%870&iid=0.6901326566387387
经过增删改查操作,我们可以把该URL简化为:
https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page=1&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0
其中page为我们翻页的重要参数。
打开该URL链接,如下图所示:
通过上面的URL链接,我们可以获取到很多景点的基础信息,随机打开一个景点的详情网页并打开开发者模式,经过查找,评论数据存放在如下图的URL链接中,
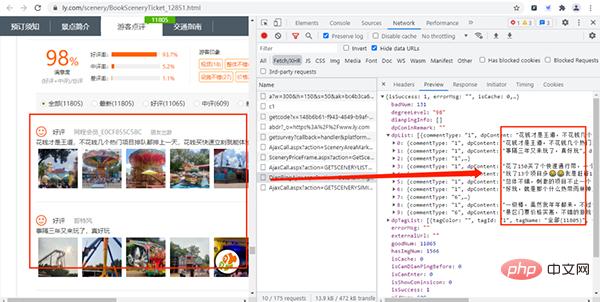
其URL链接如下所示:
https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid=12851&page=1&pageSize=10&labId=1&sort=0&iid=0.48901069375088
其中:action、labId、iid、sort为常量,sid是景点的id,page控制翻页,pageSize是每页获取的数据量。
在上上步中,我们知道景点id的存放位置,那么构造评论数据的URL就很简单了。
实战演练
这次我们爬虫步骤是:
- 获取景点基本信息
- 获取评论数据
- 创建MySQL数据库
- 保存数据
- 创建线程池
- 数据分析
获取景点基本信息
首先我们先获取景点的名字、id、价格、特色、地点和等级,主要代码如下所示:
def get_parse(url):response=requests.get(url,headers=headers)Xpath=parsel.Selector(response.text)data=Xpath.xpath('/html/body/div')for i in data:Scenery_data={'title':i.xpath('./div/div[1]/div[1]/dl/dt/a/text()').extract_first(),'sid':i.xpath('//div[@]/div/@sid').extract_first(),'Grade':i.xpath('./div/div[1]/div[1]/dl/dd[1]/span/text()').extract_first(), 'Detailed_address':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:',''),'characteristic':i.xpath('./div/div[1]/div[1]/dl/dd[3]/p/text()').extract_first(),'price':i.xpath('./div/div[1]/div[2]/div[1]/span/b/text()').extract_first(),'place':i.xpath('./div/div[1]/div[1]/dl/dd[2]/p/text()').extract_first().replace('地址:','')[6:8]}首先自定义方法get_parse()来发送网络请求后使用parsel.Selector()方法来解析响应的文本数据,然后通过xpath来获取数据。
获取评论数据
获取景点基本信息后,接下来通过景点基本信息中的sid来构造评论信息的URL链接,主要代码如下所示:
def get_data(Scenery_data):for i in range(1,3):link = f'https://www.ly.com/scenery/AjaxHelper/DianPingAjax.aspx?action=GetDianPingList&sid={Scenery_data["sid"]}&page={i}&pageSize=100&labId=1&sort=0&iid=0.20105777381446832'response=requests.get(link,headers=headers)Json=response.json()commtent_detailed=Json.get('dpList')# 有评论数据if commtent_detailed!=None:for i in commtent_detailed:Comment_information={'dptitle':Scenery_data['title'],'dpContent':i.get('dpContent'),'dpDate':i.get('dpDate')[5:7],'lineAccess':i.get('lineAccess')}#没有评论数据elif commtent_detailed==None:Comment_information={'dptitle':Scenery_data['title'],'dpContent':'没有评论','dpDate':'没有评论','lineAccess':'没有评论'}首先自定义方法get_data()并传入刚才获取的景点基础信息数据,然后通过景点基础信息的sid来构造评论数据的URL链接,当在构造评论数据的URL时,需要设置pageSize和page这两个变量来获取多条评论和进行翻页,构造URL链接后就发送网络请求。
这里需要注意的是:有些景点是没有评论,所以我们需要通过if语句来进行设置。
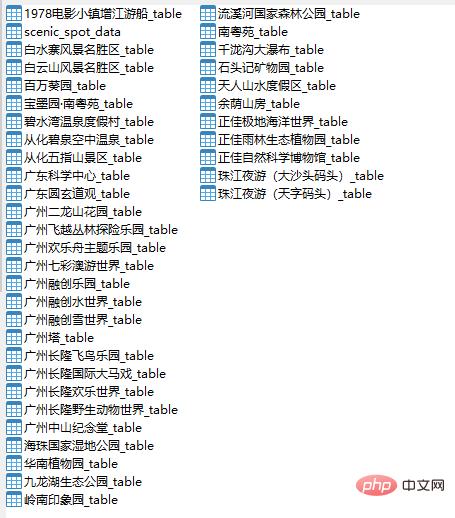
创建MySQL数据库
这次我们把数据存放在MySQL数据库中,由于数据比较多,所以我们把数据分为两种数据表,一种是景点基础信息表,一种是景点评论数据表,主要代码如下所示:
#创建数据库def create_db():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port)cursor=db.cursor()sql='create database if not exists commtent default character set utf8'cursor.execute(sql)db.close()create_table()#创建景点信息数据表def create_table():db=pymysql.connect(host=host,user=user,passwd=passwd,port=port,db='commtent')cursor=db.cursor()sql = 'create table if not exists Scenic_spot_data (title varchar(255) not null, link varchar(255) not null,Grade varchar(255) not null, Detailed_address varchar(255) not null, characteristic varchar(255)not null, price int not null, place varchar(255) not null)'cursor.execute(sql)db.close()
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,然后关闭数据库连接,最后调用自定义方法create_table()来创建景点信息数据表。
这里我们只给出了创建景点信息数据表的代码,因为创建数据表只是sql这条语句稍微有点不同,其他都一样,大家可以参考这代码来创建各个景点评论数据表。
保存数据
创建好数据库和数据表后,接下来就要保存数据了,主要代码如下所示:
首先我们调用pymysql.connect()方法来连接数据库,通过.cursor()获取游标,再通过.execute()方法执行单条的sql语句,执行成功后返回受影响的行数,使用了try-except语句,当保存的数据不成功,就调用rollback()方法,撤消当前事务中所做的所有更改,并释放此连接对象当前使用的任何数据库锁。
#保存景点数据到景点数据表中def saving_scenery_data(srr):db = pymysql.connect(host=host, user=user, password=passwd, port=port, db='commtent')cursor = db.cursor()sql = 'insert into Scenic_spot_data(title, link, Grade, Detailed_address, characteristic,price,place) values(%s,%s,%s,%s,%s,%s,%s)'try:cursor.execute(sql, srr)db.commit()except:db.rollback()db.close()
注意:srr是传入的景点信息数据。
创建线程池
好了,单线程爬虫已经写好了,接下来将创建一个函数来创建我们的线程池,使单线程爬虫变为多线程,主要代码如下所示:
urls = [f'https://www.ly.com/scenery/NewSearchList.aspx?&action=getlist&page={i}&pid=6&cid=80&cyid=0&isnow=0&IsNJL=0'for i in range(1, 6)]def multi_thread():with concurrent.futures.ThreadPoolExecutor(max_workers=8)as pool:h=pool.map(get_parse,urls)if __name__ == '__main__':create_db()multi_thread()创建线程池的代码很简单就一个with语句和调用map()方法
运行结果如下图所示:
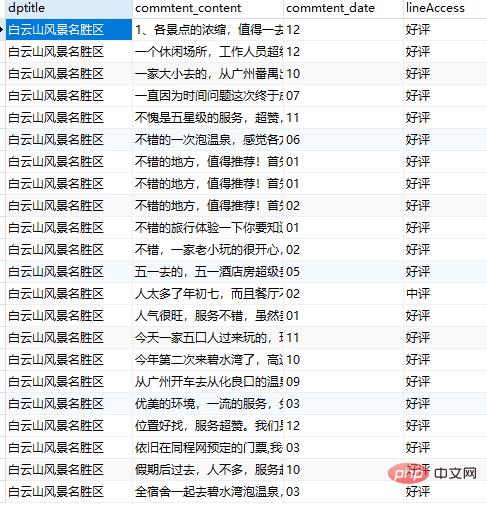
好了,数据已经获取到了,接下来将进行数据分析。
数据可视化
首先我们来分析一下各个景点那个月份游玩的人数最多,这样我们就不用担心去游玩的时机不对了。
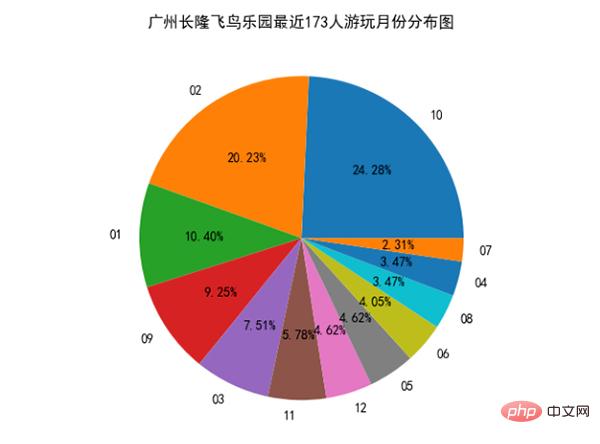
我们发现10月、2月、1月去广州长隆飞鸟乐园游玩的人数占总体比例最多。分析完月份后,我们来看看评论情况如何:
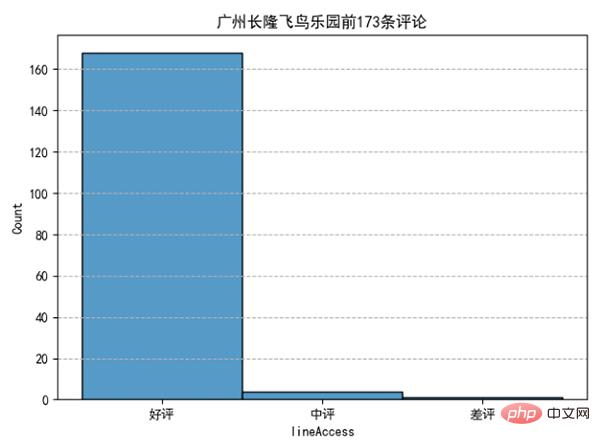
可以发现去好评占了绝大部分,可以说:去长隆飞鸟乐园玩耍,去了都说好。看了评论情况,评论内容有什么:

好了,获取旅游景点信息及评论并做词云、数据可视化就讲到这里了。
Atas ialah kandungan terperinci Python memperoleh maklumat dan ulasan tarikan pelancong serta mencipta awan perkataan dan visualisasi data. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Rancangan Python 2 jam: Pendekatan yang realistik
Apr 11, 2025 am 12:04 AM
Rancangan Python 2 jam: Pendekatan yang realistik
Apr 11, 2025 am 12:04 AM
Anda boleh mempelajari konsep pengaturcaraan asas dan kemahiran Python dalam masa 2 jam. 1. Belajar Pembolehubah dan Jenis Data, 2.
 Python: meneroka aplikasi utamanya
Apr 10, 2025 am 09:41 AM
Python: meneroka aplikasi utamanya
Apr 10, 2025 am 09:41 AM
Python digunakan secara meluas dalam bidang pembangunan web, sains data, pembelajaran mesin, automasi dan skrip. 1) Dalam pembangunan web, kerangka Django dan Flask memudahkan proses pembangunan. 2) Dalam bidang sains data dan pembelajaran mesin, numpy, panda, scikit-learn dan perpustakaan tensorflow memberikan sokongan yang kuat. 3) Dari segi automasi dan skrip, Python sesuai untuk tugas -tugas seperti ujian automatik dan pengurusan sistem.
 Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Tidak mustahil untuk melihat kata laluan MongoDB secara langsung melalui Navicat kerana ia disimpan sebagai nilai hash. Cara mendapatkan kata laluan yang hilang: 1. Tetapkan semula kata laluan; 2. Periksa fail konfigurasi (mungkin mengandungi nilai hash); 3. Semak Kod (boleh kata laluan Hardcode).
 Cara Menggunakan AWS Glue Crawler dengan Amazon Athena
Apr 09, 2025 pm 03:09 PM
Cara Menggunakan AWS Glue Crawler dengan Amazon Athena
Apr 09, 2025 pm 03:09 PM
Sebagai profesional data, anda perlu memproses sejumlah besar data dari pelbagai sumber. Ini boleh menimbulkan cabaran kepada pengurusan data dan analisis. Nasib baik, dua perkhidmatan AWS dapat membantu: AWS Glue dan Amazon Athena.
 Cara memulakan pelayan dengan redis
Apr 10, 2025 pm 08:12 PM
Cara memulakan pelayan dengan redis
Apr 10, 2025 pm 08:12 PM
Langkah -langkah untuk memulakan pelayan Redis termasuk: Pasang Redis mengikut sistem operasi. Mulakan perkhidmatan Redis melalui Redis-server (Linux/macOS) atau redis-server.exe (Windows). Gunakan redis-cli ping (linux/macOS) atau redis-cli.exe ping (windows) perintah untuk memeriksa status perkhidmatan. Gunakan klien Redis, seperti redis-cli, python, atau node.js untuk mengakses pelayan.
 Cara Membaca Gilir Redis
Apr 10, 2025 pm 10:12 PM
Cara Membaca Gilir Redis
Apr 10, 2025 pm 10:12 PM
Untuk membaca giliran dari Redis, anda perlu mendapatkan nama giliran, membaca unsur -unsur menggunakan arahan LPOP, dan memproses barisan kosong. Langkah-langkah khusus adalah seperti berikut: Dapatkan nama giliran: Namakannya dengan awalan "giliran:" seperti "giliran: my-queue". Gunakan arahan LPOP: Keluarkan elemen dari kepala barisan dan kembalikan nilainya, seperti LPOP Queue: My-Queue. Memproses Baris kosong: Jika barisan kosong, LPOP mengembalikan nihil, dan anda boleh menyemak sama ada barisan wujud sebelum membaca elemen.
 Cara melihat versi pelayan Redis
Apr 10, 2025 pm 01:27 PM
Cara melihat versi pelayan Redis
Apr 10, 2025 pm 01:27 PM
Soalan: Bagaimana untuk melihat versi pelayan Redis? Gunakan alat perintah Redis-cli -version untuk melihat versi pelayan yang disambungkan. Gunakan arahan pelayan INFO untuk melihat versi dalaman pelayan dan perlu menghuraikan dan mengembalikan maklumat. Dalam persekitaran kluster, periksa konsistensi versi setiap nod dan boleh diperiksa secara automatik menggunakan skrip. Gunakan skrip untuk mengautomasikan versi tontonan, seperti menyambung dengan skrip Python dan maklumat versi percetakan.
 Betapa selamatnya kata laluan Navicat?
Apr 08, 2025 pm 09:24 PM
Betapa selamatnya kata laluan Navicat?
Apr 08, 2025 pm 09:24 PM
Keselamatan kata laluan Navicat bergantung pada gabungan penyulitan simetri, kekuatan kata laluan dan langkah -langkah keselamatan. Langkah -langkah khusus termasuk: menggunakan sambungan SSL (dengan syarat bahawa pelayan pangkalan data menyokong dan mengkonfigurasi sijil dengan betul), mengemas kini Navicat, menggunakan kaedah yang lebih selamat (seperti terowong SSH), menyekat hak akses, dan yang paling penting, tidak pernah merakam kata laluan.
