
 pembangunan bahagian belakang
Tutorial Python
Memahami pengelompokan hierarki dalam satu artikel (kod Python)
pembangunan bahagian belakang
Tutorial Python
Memahami pengelompokan hierarki dalam satu artikel (kod Python)
Memahami pengelompokan hierarki dalam satu artikel (kod Python)


Pertama sekali, pengelompokan tergolong dalam pembelajaran mesin tanpa pengawasan dan terdapat banyak kaedah, seperti K-means yang terkenal. Pengelompokan hierarki juga merupakan jenis pengelompokan dan juga sangat biasa digunakan. Seterusnya, saya akan menyemak secara ringkas prinsip asas K-means, dan kemudian perlahan-lahan memperkenalkan definisi dan langkah hierarki pengelompokan hierarki, yang akan lebih membantu untuk difahami oleh semua orang.
Apakah perbezaan antara pengelompokan hierarki dan K-means?
Prinsip kerja K-means boleh diringkaskan secara ringkas sebagai:
- Tentukan bilangan gugusan (k)
- Pilih k titik secara rawak daripada data sebagai centroids
- Berikan semua titik kepada centroid gugusan terdekat
- Kira centroid bagi gugusan yang baru terbentuk
- Ulang langkah 3 dan 4
Ini ialah proses lelaran sehingga pusat gugusan yang baru terbentuk kekal tidak berubah atau bilangan maksimum lelaran dicapai.
Tetapi K-means mempunyai beberapa kelemahan Kita mesti menentukan bilangan kluster K sebelum algoritma bermula . Tetapkan nilai dahulu, yang mungkin membawa kepada beberapa penyelewengan antara pemahaman kita dan situasi sebenar.
Pengelompokan hierarki adalah berbeza sama sekali. Ia tidak memerlukan kita untuk menentukan bilangan gugusan pada permulaan Sebaliknya, ia mula-mula membentuk keseluruhan pengelompokan hierarki, dan kemudian dengan menentukan jarak yang sesuai, nombor gugusan yang sepadan. dan jumlah boleh didapati secara automatik.
Apakah pengelompokan hierarki?
Mari kita perkenalkan apakah pengelompokan hierarki dari cetek ke dalam Mari kita mulakan dengan contoh mudah.
Andaikan kita mempunyai mata berikut dan kita mahu mengumpulkannya:

Kita boleh menetapkan setiap titik ini kepada gugusan berasingan, Hanya 4 gugusan ( 4 warna):

Kemudian berdasarkan persamaan (jarak) gugusan ini, titik yang paling hampir (paling dekat) dikumpulkan bersama dan digabungkan Ulangi proses ini sehingga hanya satu gugusan kekal:
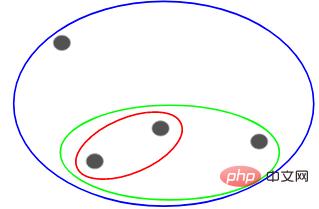
Perkara di atas pada asasnya membina hierarki. Mari kita fahami ini dahulu, dan kami akan memperkenalkan langkah pelapisannya secara terperinci kemudian.
Jenis pengelompokan hierarki
Terdapat dua jenis pengelompokan hierarki utama:
- Pengelompokan hierarki aglomeratif
- Pengelompokan hierarki pisah
Pengelompokan hierarki aglomeratif
Mula-mula biarkan semua titik menjadi gugusan yang berasingan, dan kemudian teruskan menggabungkannya melalui persamaan sehingga hanya terdapat satu gugusan pada akhirnya Ini ialah pengelompokan hierarki aglomeratif Prosesnya adalah konsisten dengan apa yang kami katakan di atas.
Kelompok berhierarki terbahagi
Kelompok berhierarki terbahagi adalah sebaliknya Ia bermula dari satu gugusan dan membahagikannya secara beransur-ansur sehingga ia tidak boleh dipisahkan, iaitu setiap titik adalah gugusan.
Jadi, tidak kira sama ada 10, 100, 1000 titik data, semua titik ini tergolong dalam kelompok yang sama pada mulanya:
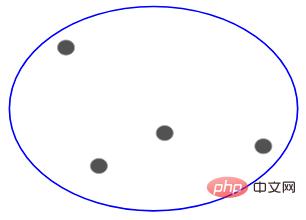
Sekarang , Pisahkan dua titik paling jauh dalam gugusan dalam setiap lelaran, dan ulangi proses ini sehingga setiap gugusan mengandungi hanya satu titik:

Proses di atas adalah membelah Kelompok Hierarki.
Langkah-langkah untuk melaksanakan pengelompokan hierarki
Proses umum pengelompokan hierarki telah diterangkan di atas Sekarang datang perkara utama.
Ini adalah salah satu isu terpenting dalam pengelompokan Kaedah umum pengiraan persamaan ialah mengira jarak antara pusat gugusan ini. Titik dengan jarak minimum dipanggil titik serupa dan kita boleh menggabungkannya atau kita boleh memanggilnya algoritma berasaskan jarak.
Juga dalam pengelompokan hierarki, terdapat konsep yang dipanggil matriks kedekatan, yang menyimpan jarak antara setiap titik. Di bawah kami menggunakan contoh untuk memahami cara mengira persamaan, matriks kedekatan dan langkah khusus pengelompokan hierarki.
Pengenalan Kes
Andaikan seorang guru ingin membahagikan pelajar kepada kumpulan yang berbeza. Sekarang saya mempunyai markah setiap pelajar pada tugasan, dan saya ingin membahagikan mereka kepada kumpulan berdasarkan markah ini. Tiada matlamat yang ditetapkan di sini tentang berapa banyak kumpulan yang perlu ada. Memandangkan guru tidak tahu jenis pelajar mana yang patut ditugaskan kepada kumpulan mana, ia tidak boleh diselesaikan sebagai masalah pembelajaran yang diselia. Di bawah, kami akan cuba menggunakan pengelompokan hierarki untuk memisahkan pelajar kepada kumpulan yang berbeza.
Berikut adalah keputusan 5 pelajar:
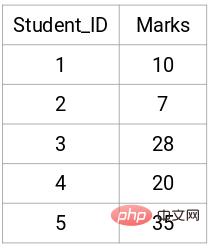
Buat matriks kedekatan
Mula-mula, kita perlu mencipta matriks kedekatan, yang menyimpan jarak antara setiap titik, supaya kita boleh mendapatkan bentuk matriks n Square daripada X n.
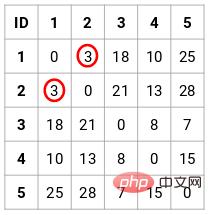
Dalam kes ini, matriks kedekatan 5 x 5 berikut boleh diperolehi:
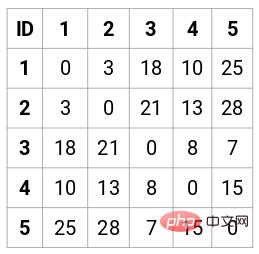
Terdapat dua perkara yang perlu diperhatikan dalam matriks:
- Unsur pepenjuru matriks sentiasa 0 kerana jarak titik dari dirinya sentiasa 0
- Gunakan formula jarak Euclidean untuk mengira jarak unsur luar pepenjuru
Sebagai contoh, jika kita ingin mengira jarak antara titik 1 dan 2, formula pengiraan ialah:
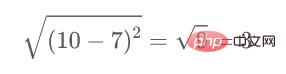
Begitu juga, isikan elemen kedekatan yang tinggal. matriks selepas melengkapkan kaedah pengiraan ini.
Lakukan pengelompokan hierarki
Ini dicapai menggunakan pengelompokan hierarki aglomeratif.
Langkah 1: Mula-mula, kami menetapkan semua titik ke dalam satu kelompok:

Di sini warna yang berbeza mewakili kelompok yang berbeza, 5 daripadanya dalam titik data kami, iaitu terdapat 5 kluster yang berbeza.
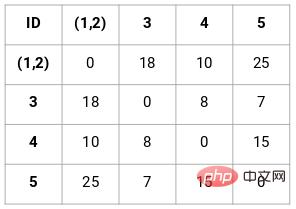
Langkah 2: Seterusnya, kita perlu mencari jarak minimum dalam matriks kedekatan dan menggabungkan titik dengan jarak terkecil. Kemudian kami mengemas kini matriks jarak:
Jarak minimum ialah 3, jadi kami akan menggabungkan mata 1 dan 2:
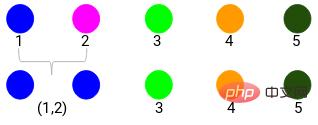
Mari lihat kelompok yang dikemas kini dan kemas kini matriks kedekatan dengan sewajarnya:
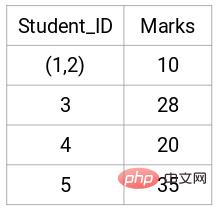
Selepas kemas kini, kami mengambil nilai terbesar (7, 10) antara dua titik 1 dan 2 untuk menggantikan nilai kluster ini. Sudah tentu, sebagai tambahan kepada nilai maksimum, kita juga boleh mengambil nilai minimum atau purata. Kami kemudian akan mengira matriks kehampiran gugusan ini sekali lagi:
Langkah 3: Ulang langkah 2 sehingga hanya tinggal satu gugusan.
Selepas mengulangi semua langkah, kami akan mendapat gugusan yang digabungkan seperti yang ditunjukkan di bawah:
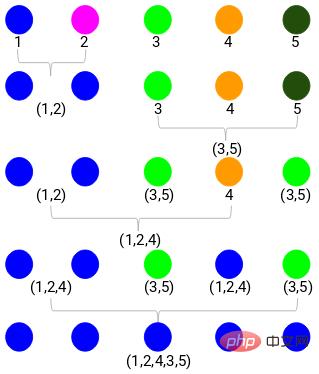
Beginilah cara pengelompokan hierarki aglomeratif berfungsi. Tetapi masalahnya kita masih tidak tahu berapa banyak kumpulan yang perlu dipecahkan? Adakah kumpulan 2, 3, atau 4?
Mari mulakan dengan cara memilih bilangan gugusan.
Bagaimana untuk memilih bilangan kelompok?
Untuk mendapatkan bilangan kelompok bagi pengelompokan hierarki, kami menggunakan konsep yang dipanggil dendrogram.
Melalui dendrogram, kita boleh memilih bilangan kluster dengan lebih mudah.
Berbalik kepada contoh di atas. Apabila kita menggabungkan dua gugusan, dendrogram dengan sewajarnya merekodkan jarak antara gugusan ini dan mewakilinya secara grafik. Berikut ialah keadaan asal dendrogram. Abscissa merekodkan tanda setiap titik, dan paksi menegak merekodkan jarak antara titik:
Apabila menggabungkan dua Apabila terdapat kelompok, mereka akan disambungkan dalam dendrogram, dan ketinggian sambungan adalah jarak antara titik. Berikut ialah proses pengelompokan hierarki yang baru kami lakukan.
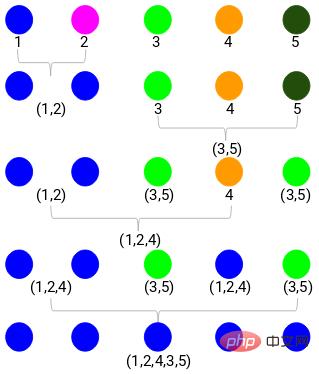
Kemudian mula melukis gambar rajah pokok proses di atas. Bermula daripada mencantumkan sampel 1 dan 2, jarak antara dua sampel ini ialah 3.
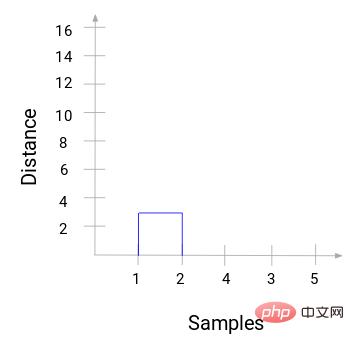
Anda boleh melihat bahawa 1 dan 2 telah digabungkan. Garis menegak mewakili jarak antara 1 dan 2. Dengan cara yang sama, semua langkah penggabungan kelompok dilukis mengikut proses pengelompokan hierarki, dan akhirnya gambar rajah pokok seperti ini diperoleh:
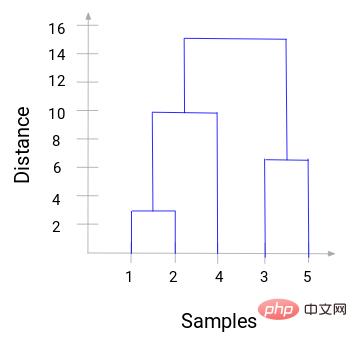
Melalui dendrogram, kita boleh menggambarkan dengan jelas langkah-langkah pengelompokan hierarki. Semakin jauh jarak garis menegak dalam dendrogram, semakin jauh jarak antara kelompok.
Dengan gambar rajah pokok ini, adalah lebih mudah untuk kita menentukan bilangan gugusan.
Kini kita boleh menetapkan jarak ambang dan melukis garisan mendatar. Sebagai contoh, kami menetapkan ambang kepada 12 dan melukis garisan mendatar seperti berikut:
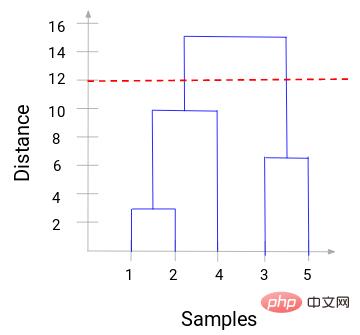
Seperti yang anda boleh lihat dari titik persilangan, bilangan gugusan ialah persilangan bagi garis mendatar ambang dan kuantiti garis menegak (garisan merah bersilang 2 garisan menegak, kita akan mempunyai 2 kelompok). Selaras dengan absis, satu kluster akan mempunyai set sampel (1,2,4), dan kluster lain akan mempunyai set sampel (3,5).
Dengan cara ini, kami menyelesaikan masalah menentukan bilangan gugusan dalam pengelompokan hierarki melalui dendrogram.
Kes praktikal kod Python
Di atas adalah asas teori, dan sesiapa sahaja yang mempunyai sedikit asas matematik boleh memahaminya. Berikut ialah cara untuk melaksanakan proses ini menggunakan kod Python. Berikut ialah data pembahagian pelanggan untuk ditunjukkan.
Dataset dan kod ada dalam repositori GitHub saya:
https://github.com/xiaoyusmd/PythonDataScience
Jika anda rasa ia membantu, sila berikan bintang!
Data ini datang daripada perpustakaan pembelajaran mesin UCI. Matlamat kami adalah untuk membahagikan pelanggan pengedar borong berdasarkan perbelanjaan tahunan mereka untuk kategori produk yang berbeza (cth. susu, barangan runcit, wilayah, dll.).
Pertama, data diseragamkan untuk menjadikan semua data dalam dimensi yang sama mudah dikira, dan kemudian pengelompokan hierarki digunakan pada pelanggan segmen.
from sklearn.preprocessing import normalize
data_scaled = normalize(data)
data_scaled = pd.DataFrame(data_scaled, columns=data.columns)
import scipy.cluster.hierarchy as shc
plt.figure(figsize=(10, 7))
plt.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(data_scaled, method='ward'))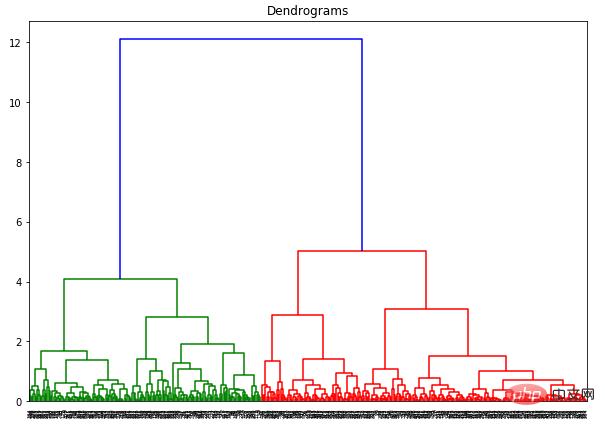
Paksi-x mengandungi semua sampel, dan paksi-y mewakili jarak antara sampel ini. Garis menegak dengan jarak terbesar ialah garis biru Katakan kita memutuskan untuk memotong dendrogram dengan ambang 6:
plt.figure(figsize=(10, 7))
plt.title("Dendrograms")
dend = shc.dendrogram(shc.linkage(data_scaled, method='ward'))
plt.axhline(y=6, color='r', linestyle='--')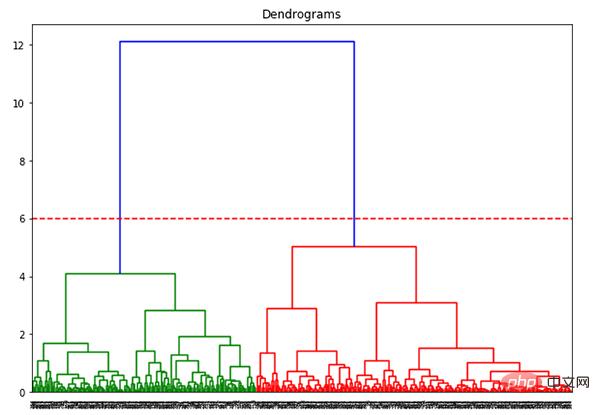
Sekarang kita mempunyai dua kelompok, kita perlu Hierarki pengelompokan digunakan pada 2 kelompok ini:
from sklearn.cluster import AgglomerativeClustering cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward') cluster.fit_predict(data_scaled)

Memandangkan kita telah mentakrifkan 2 kelompok, kita boleh melihat nilai 0 dan 1 dalam keluaran. 0 mewakili mata kepunyaan kelompok pertama, dan 1 mewakili mata kepunyaan kelompok kedua.
plt.figure(figsize=(10, 7)) plt.scatter(data_scaled['Milk'], data_scaled['Grocery'], c=cluster.labels_)
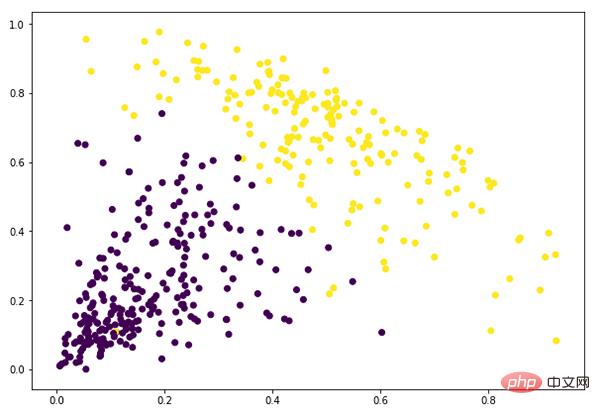
Pada ketika ini kami telah berjaya menyelesaikan pengelompokan.
Atas ialah kandungan terperinci Memahami pengelompokan hierarki dalam satu artikel (kod Python). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1207
24
52
1207
24

 PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP dan Python: Paradigma yang berbeza dijelaskan
Apr 18, 2025 am 12:26 AM
PHP terutamanya pengaturcaraan prosedur, tetapi juga menyokong pengaturcaraan berorientasikan objek (OOP); Python menyokong pelbagai paradigma, termasuk pengaturcaraan OOP, fungsional dan prosedur. PHP sesuai untuk pembangunan web, dan Python sesuai untuk pelbagai aplikasi seperti analisis data dan pembelajaran mesin.
 Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
Memilih antara php dan python: panduan
Apr 18, 2025 am 12:24 AM
PHP sesuai untuk pembangunan web dan prototaip pesat, dan Python sesuai untuk sains data dan pembelajaran mesin. 1.Php digunakan untuk pembangunan web dinamik, dengan sintaks mudah dan sesuai untuk pembangunan pesat. 2. Python mempunyai sintaks ringkas, sesuai untuk pelbagai bidang, dan mempunyai ekosistem perpustakaan yang kuat.
 Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Bolehkah kod studio visual digunakan dalam python
Apr 15, 2025 pm 08:18 PM
Kod VS boleh digunakan untuk menulis Python dan menyediakan banyak ciri yang menjadikannya alat yang ideal untuk membangunkan aplikasi python. Ia membolehkan pengguna untuk: memasang sambungan python untuk mendapatkan fungsi seperti penyempurnaan kod, penonjolan sintaks, dan debugging. Gunakan debugger untuk mengesan kod langkah demi langkah, cari dan selesaikan kesilapan. Mengintegrasikan Git untuk Kawalan Versi. Gunakan alat pemformatan kod untuk mengekalkan konsistensi kod. Gunakan alat linting untuk melihat masalah yang berpotensi lebih awal.
 Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python vs JavaScript: Keluk Pembelajaran dan Kemudahan Penggunaan
Apr 16, 2025 am 12:12 AM
Python lebih sesuai untuk pemula, dengan lengkung pembelajaran yang lancar dan sintaks ringkas; JavaScript sesuai untuk pembangunan front-end, dengan lengkung pembelajaran yang curam dan sintaks yang fleksibel. 1. Sintaks Python adalah intuitif dan sesuai untuk sains data dan pembangunan back-end. 2. JavaScript adalah fleksibel dan digunakan secara meluas dalam pengaturcaraan depan dan pelayan.
 Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Boleh kod vs dijalankan di Windows 8
Apr 15, 2025 pm 07:24 PM
Kod VS boleh dijalankan pada Windows 8, tetapi pengalaman mungkin tidak hebat. Mula -mula pastikan sistem telah dikemas kini ke patch terkini, kemudian muat turun pakej pemasangan kod VS yang sepadan dengan seni bina sistem dan pasangnya seperti yang diminta. Selepas pemasangan, sedar bahawa beberapa sambungan mungkin tidak sesuai dengan Windows 8 dan perlu mencari sambungan alternatif atau menggunakan sistem Windows yang lebih baru dalam mesin maya. Pasang sambungan yang diperlukan untuk memeriksa sama ada ia berfungsi dengan betul. Walaupun kod VS boleh dilaksanakan pada Windows 8, disyorkan untuk menaik taraf ke sistem Windows yang lebih baru untuk pengalaman dan keselamatan pembangunan yang lebih baik.
 PHP dan Python: menyelam mendalam ke dalam sejarah mereka
Apr 18, 2025 am 12:25 AM
PHP dan Python: menyelam mendalam ke dalam sejarah mereka
Apr 18, 2025 am 12:25 AM
PHP berasal pada tahun 1994 dan dibangunkan oleh Rasmuslerdorf. Ia pada asalnya digunakan untuk mengesan pelawat laman web dan secara beransur-ansur berkembang menjadi bahasa skrip sisi pelayan dan digunakan secara meluas dalam pembangunan web. Python telah dibangunkan oleh Guidovan Rossum pada akhir 1980 -an dan pertama kali dikeluarkan pada tahun 1991. Ia menekankan kebolehbacaan dan kesederhanaan kod, dan sesuai untuk pengkomputeran saintifik, analisis data dan bidang lain.
 Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Cara menjalankan program di terminal vscode
Apr 15, 2025 pm 06:42 PM
Dalam kod VS, anda boleh menjalankan program di terminal melalui langkah -langkah berikut: Sediakan kod dan buka terminal bersepadu untuk memastikan bahawa direktori kod selaras dengan direktori kerja terminal. Pilih arahan Run mengikut bahasa pengaturcaraan (seperti python python your_file_name.py) untuk memeriksa sama ada ia berjalan dengan jayanya dan menyelesaikan kesilapan. Gunakan debugger untuk meningkatkan kecekapan debug.
 Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Adakah sambungan vscode berniat jahat?
Apr 15, 2025 pm 07:57 PM
Sambungan kod VS menimbulkan risiko yang berniat jahat, seperti menyembunyikan kod jahat, mengeksploitasi kelemahan, dan melancap sebagai sambungan yang sah. Kaedah untuk mengenal pasti sambungan yang berniat jahat termasuk: memeriksa penerbit, membaca komen, memeriksa kod, dan memasang dengan berhati -hati. Langkah -langkah keselamatan juga termasuk: kesedaran keselamatan, tabiat yang baik, kemas kini tetap dan perisian antivirus.
