
 Peranti teknologi
AI
Butiran seni bina superkomputer Tesla Dojo didedahkan buat kali pertama! 'Fucked to pieces' untuk pemanduan autonomi
Peranti teknologi
AI
Butiran seni bina superkomputer Tesla Dojo didedahkan buat kali pertama! 'Fucked to pieces' untuk pemanduan autonomi
Butiran seni bina superkomputer Tesla Dojo didedahkan buat kali pertama! 'Fucked to pieces' untuk pemanduan autonomi

Untuk memenuhi permintaan yang semakin meningkat untuk model kecerdasan buatan dan pembelajaran mesin, Tesla telah mencipta teknologi kecerdasan buatannya sendiri untuk mengajar kereta Tesla memandu secara automatik.
Baru-baru ini, Tesla mendedahkan banyak butiran tentang seni bina pengkomputeran super Dojo pada persidangan Hot Chips 34.
Pada asasnya, Dojo ialah superkomputer boleh gubah gergasi yang dibina daripada seni bina tersuai sepenuhnya meliputi pengiraan, rangkaian, cip input/output (I/O) kepada seni bina set arahan (ISA), penghantaran kuasa, pembungkusan dan penyejukan. Semua ini dilakukan untuk menjalankan algoritma latihan pembelajaran mesin tersuai dan khusus pada skala.
Ganesh Venkataramanan ialah pengarah kanan perkakasan pemanduan autonomi Tesla dan bertanggungjawab untuk projek Dojo dan pasukan reka bentuk CPU AMD. Pada persidangan Hot Chips 34, beliau dan sekumpulan jurutera cip, sistem dan perisian mendedahkan banyak ciri seni bina mesin itu buat kali pertama.
Pusat Data "Sandwic"
" Secara umumnya, proses pembuatan cip kami adalah meletakkannya pada bungkusan dan meletakkan bungkusan itu pada papan litar bercetak , dan kemudian sistem itu masuk ke dalam rak," kata Venkataramanan.
Tetapi terdapat masalah dengan proses ini: setiap kali data berpindah dari cip ke pakej dan keluar dari pakej, terdapat kependaman dan kehilangan lebar jalur.
Untuk mengatasi batasan ini, Venkataramanan dan pasukannya memutuskan untuk bermula dari awal.

Oleh itu, jubin latihan Dojo dilahirkan.
Ini ialah kluster pengkomputeran serba lengkap yang mengambil masa setengah kaki padu dan berkemampuan 556TFLOPS prestasi FP32 dalam pakej penyejuk cecair 15kW.
Setiap jubin dilengkapi dengan 11GB SRAM dan disambungkan melalui fabrik 9TB/s menggunakan protokol pemindahan tersuai di seluruh tindanan.
Venkataramanan berkata: "Papan latihan ini mewakili tahap penyepaduan yang tiada tandingan daripada komputer ke memori, kepada penghantaran kuasa, kepada komunikasi, tanpa memerlukan sebarang suis tambahan." 🎜>
Inti jubin latihan ialah D1 Tesla, cip transistor 50 bilion berdasarkan proses 7nm TSMC. Tesla berkata setiap D1 mampu mencapai 22TFLOPS prestasi FP32 pada TDP 400W.

Walau bagaimanapun, reka bentuk sistem dan seni bina susun menegak pada cip membawa cabaran kepada penghantaran kuasa.
Menurut Venkataramanan, kebanyakan pemecut semasa meletakkan bekalan kuasa terus di sebelah wafer silikon. Beliau menjelaskan bahawa pendekatan ini, walaupun berkesan, bermakna sebahagian besar pemecut perlu dikhaskan untuk komponen ini, yang tidak praktikal untuk Dojo. Oleh itu, Tesla memilih untuk memberikan kuasa secara terus melalui bahagian bawah cip.
Selain itu, Tesla telah membangunkan Pemproses Antara Muka Dojo (DIP), yang merupakan jambatan antara CPU hos dan pemproses latihan.
Setiap DIP mempunyai 32GB HBM, dan sehingga lima daripada kad ini boleh disambungkan ke jubin latihan pada 900GB/s untuk jumlah 4.5TB/s, setiap jubin mempunyai sejumlah 160GB HBM.

 Perisian
Perisian
“Apabila kami mereka bentuk sistem ini, kemudahan pengaturcaraan oleh rakan perisian adalah yang paling penting Penyelidik tidak menunggu orang perisian anda menulis kernel berkod tangan untuk menampung algoritma baharu yang ingin kami jalankan. Untuk melakukan ini, Tesla melepaskan idea menggunakan kernel dan mereka bentuk seni bina Dojo di sekeliling pengkompil. "Apa yang kami lakukan ialah kami menggunakan PiTorch. Kami mencipta lapisan tengah yang membantu kami selari untuk menskalakan perkakasan di bawahnya. Di bawahnya semuanya tersusun kod. "Untuk mencipta perisian timbunan yang boleh menyesuaikan diri dengan sebarang beban kerja masa hadapan, ini adalah satu-satunya cara. Walaupun menekankan fleksibiliti perisian, Venkataramanan menegaskan bahawa platform yang sedang berjalan di makmal mereka terhad kepada Tesla buat masa ini. Selepas membaca perkara di atas, mari kita lihat dengan lebih mendalam seni bina Dojo. Tesla mempunyai sistem kecerdasan buatan yang besar untuk pembelajaran mesin. Tesla mempunyai modal yang mencukupi untuk mengupah pekerja dan membina cip serta sistem khusus untuk aplikasinya, sama seperti sistem dalam kereta Tesla. Tesla bukan sahaja membina cip AInya sendiri, tetapi juga superkomputer. Analisis sistem teragih Setiap nod Dojo mempunyai CPU Sendiri, antara muka ingatan dan komunikasi. Nod Dojo Ini ialah saluran pemprosesan pemproses Dojo . Memproses saluran paip Setiap nod mempunyai 1.25MB SRAM. Dalam latihan AI dan cip inferens, teknik biasa adalah untuk mencari bersama memori dengan pengiraan untuk meminimumkan pemindahan data, yang sangat mahal dari perspektif kuasa dan prestasi. Memori Nod Kemudian setiap nod disambungkan ke Grid 2D . Antara Muka Rangkaian Ini ialah gambaran keseluruhan laluan data. Laluan Data Berikut ialah contoh perkara yang boleh cip lakukan penghuraian senarai. List Parsing Berikut adalah lebih lanjut mengenai set arahan, ialah asal Tesla, bukannya set arahan Intel, Arm, NVIDIA atau AMD CPU/GPU biasa. Set arahan Dalam kecerdasan buatan, format aritmetik adalah penting, terutamanya perkara yang disokong oleh cip Format . Menggunakan DOJO, Tesla boleh mengkaji format biasa seperti FP32, FP16 dan BFP16. Ini adalah format industri biasa. Format aritmetik Tesla juga sedang mengusahakan FP8 atau CFP8 yang boleh dikonfigurasikan . Ia datang dalam pilihan julat 4/3 dan 5/2. Ini serupa dengan konfigurasi NVIDIA H100 Hopper FP8. Kami juga melihat pemecut AI teras Untether.AI Boqueria 1458 RISC-V memfokus pada jenis FP8 yang berbeza. Dojo juga mempunyai format CFP16 yang berbeza, untuk mencapai ketepatan yang lebih tinggi dan menyokong FP32, BFP16, CFP8 dan CFP16. Format Aritmetik 3 Teras ini kemudiannya disepadukan ke dalam rekaan dalam acuan. Cip D1 Tesla dihasilkan oleh TSMC menggunakan proses 7nm. Setiap cip mempunyai 354 nod pemprosesan Dojo dan 440MB SRAM. Acuan D1 Kotak Integrasi Pertama Cip D1 ini dibungkus dalam Pada jubin latihan dojo. Cip D1 diuji dan kemudian dipasang ke dalam jubin 5×5. Jubin ini mempunyai lebar jalur 4.5TB/s setiap tepi. Mereka juga mempunyai sampul penghantaran kuasa sebanyak 15kW setiap modul, atau kira-kira 600W setiap cip D1 selepas menolak kuasa yang digunakan oleh 40 dies I/O. Perbandingan menunjukkan mengapa sesuatu seperti Lightmatter Passage akan menjadi lebih menarik jika syarikat tidak mahu mereka bentuk perkara sedemikian. Jubin latihan Dojo kotak integrasi kedua Antara muka Dojo Pemproses ialah terletak di tepi grid 2D. Setiap blok latihan mempunyai 11GB SRAM dan 160GB DRAM kongsi. Topologi sistem Dojo Berikut ialah pemprosesan penyambungan rangkaian 2D nod Data lebar jalur grid. Dojo sistem komunikasi logik 2D grid Setiap DIP Menyediakan 32GB /s pautan ke sistem hos. Dojo sistem komunikasi PCIe pautan DIP dan hos Tesla juga mempunyai pautan Z-plane untuk laluan yang lebih panjang. Dalam ucapan yang lain, Tesla bercakap tentang inovasi peringkat sistem. Mekanisme komunikasi Berikut ialah sempadan kelewatan antara die dan jubin , Itulah sebabnya mereka dikendalikan secara berbeza dalam Dojo. Sebab pautan Z-plane diperlukan kerana laluan yang panjang adalah mahal. Mekanisme komunikasi sistem Dojo Mana-mana nod pemprosesan boleh melintasi sistem Akses data. Setiap nod boleh menolak atau menarik data ke SRAM atau DRAM. Komunikasi kelompok sistem Dojo Dojo menggunakan komunikasi skema pengalamatan rata . Rangkaian Sistem 1 Cip ini boleh dipintas dalam perisian Salah nod pemprosesan. System Network 2 Ini bermakna perisian mesti memahami sistem topologi . Rangkaian Sistem 3 Dojo tidak menjamin hujung-ke- tamatkan pesanan trafik , jadi paket perlu dikira di destinasi. Rangkaian Sistem 4 Berikut ialah cara paket dikira ke dalam bahagian sistem penyegerakan. Penyegerakan sistem Pengkompil perlu mentakrifkan nod dengan Tree . System Sync 2 Tesla berkata bahawa satu exa-pod mempunyai lebih daripada 1 juta CPU ( atau nod pengiraan). Ini adalah sistem yang besar. Tesla membina Dojo khusus untuk bekerja pada skala. Biasanya, syarikat pemula ingin membina satu atau beberapa cip AI bagi setiap sistem. Jelas sekali, Tesla memberi tumpuan kepada skala yang lebih besar. Dalam banyak cara, masuk akal untuk Tesla mempunyai tempat latihan AI yang besar. Apa yang lebih menarik ialah ia bukan sahaja menggunakan sistem yang tersedia secara komersial, tetapi ia juga membina cip dan sistemnya sendiri. Sesetengah ISA pada bahagian skalar dipinjam daripada RISC-V, tetapi bahagian vektor dan banyak seni bina Tesla telah disesuaikan, jadi ini memerlukan banyak kerja. Gambaran Keseluruhan Seni Bina Dojo


























Ringkasan
Atas ialah kandungan terperinci Butiran seni bina superkomputer Tesla Dojo didedahkan buat kali pertama! 'Fucked to pieces' untuk pemanduan autonomi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1389
1389
 52
52

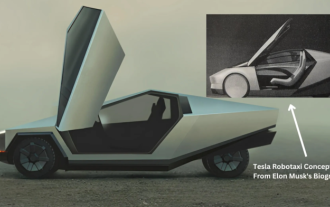 Tesla akhirnya mengambil tindakan! Adakah teksi pandu sendiri akan didedahkan tidak lama lagi? !
Apr 08, 2024 pm 05:49 PM
Tesla akhirnya mengambil tindakan! Adakah teksi pandu sendiri akan didedahkan tidak lama lagi? !
Apr 08, 2024 pm 05:49 PM
Menurut berita pada 8 April, Ketua Pegawai Eksekutif Tesla Elon Musk baru-baru ini mendedahkan bahawa Tesla komited untuk membangunkan sepenuhnya teknologi kereta pandu sendiri Robotaxi teksi pandu sendiri tanpa pemandu yang dinanti-nantikan akan dilancarkan pada 8 Ogos. Editor data mengetahui bahawa kenyataan Musk pada Sebelum ini, Reuters melaporkan bahawa rancangan Tesla untuk memandu kereta akan memberi tumpuan kepada pengeluaran Robotaxi. Bagaimanapun, Musk menafikannya, menuduh Reuters telah membatalkan rancangan untuk membangunkan kereta kos rendah dan sekali lagi menerbitkan laporan palsu, sambil menjelaskan bahawa kereta kos rendah Model 2 dan Robotax
 Debut pengkomputeran super Tesla Dojo, Musk: Kuasa pengkomputeran latihan AI menjelang akhir tahun akan lebih kurang sama dengan 8,000 GPU NVIDIA H100
Jul 24, 2024 am 10:38 AM
Debut pengkomputeran super Tesla Dojo, Musk: Kuasa pengkomputeran latihan AI menjelang akhir tahun akan lebih kurang sama dengan 8,000 GPU NVIDIA H100
Jul 24, 2024 am 10:38 AM
Menurut berita dari laman web ini pada 24 Julai, Ketua Pegawai Eksekutif Tesla Elon Musk (Elon Musk) menyatakan dalam panggilan persidangan pendapatan hari ini bahawa syarikat itu akan menyelesaikan kluster latihan kecerdasan buatan terbesar setakat ini, yang akan dilengkapi dengan 2 Ribu NVIDIA H100 GPU. Musk juga memberitahu pelabur mengenai panggilan pendapatan syarikat bahawa Tesla akan berusaha membangunkan superkomputer Dojonya kerana GPU daripada Nvidia mahal. Tapak ini menterjemah sebahagian daripada ucapan Musk seperti berikut: Jalan untuk bersaing dengan NVIDIA melalui Dojo adalah sukar, tetapi saya fikir kami tidak mempunyai pilihan sekarang. Dari perspektif NVIDIA, mereka pasti akan meningkatkan harga GPU ke tahap yang boleh ditanggung oleh pasaran, tetapi
 Tesla Cybertruck melonjak dari tebing untuk mencabar, pertunjukan kuasa melampaui had!
Mar 07, 2024 pm 09:28 PM
Tesla Cybertruck melonjak dari tebing untuk mencabar, pertunjukan kuasa melampaui had!
Mar 07, 2024 pm 09:28 PM
Menurut berita pada 7 Mac, video Tesla Cybertruck mencabar "Road to Hell's Revenge" di pekan kecil Utah, Amerika Syarikat, baru-baru ini didedahkan di Internet. Cliff terletak di Salt Lake City, Utah, Amerika Syarikat, dan merupakan tempat yang popular untuk penggemar aktiviti luar. Terdapat lebih daripada 30 jalan luar jalan di sini, dan dinding batu yang lasak dan curam menarik ramai peminat luar jalan yang melampau untuk mencabar. Video itu menunjukkan bahawa apabila Tesla Cybertruck mencabar gaung berbentuk V hampir 45 darjah, ia bergantung pada kuasa kuat tiga motornya untuk mendaki dengan mantap dan akhirnya berjaya sampai ke puncak. Semasa pendakian, Cybertruck beraksi dengan baik tanpa sebarang gelincir, walaupun permukaan batu licin. Mengikut pemahaman editor, model Tesla Cybertruck dibahagikan kepada belakang motor tunggal
 Versi baru Tesla Model 3 berprestasi tinggi lulus pensijilan Korea, dan parameter kuasa telah didedahkan dan menarik perhatian
Mar 06, 2024 pm 08:49 PM
Versi baru Tesla Model 3 berprestasi tinggi lulus pensijilan Korea, dan parameter kuasa telah didedahkan dan menarik perhatian
Mar 06, 2024 pm 08:49 PM
Menurut berita pada 6 Mac, media baru-baru ini mendedahkan bahawa model baru Tesla Model 3 berprestasi tinggi telah lulus pensijilan Korea yang berkaitan dan mendedahkan satu siri parameter kuasa yang menarik perhatian. Dilaporkan bahawa kereta baharu ini akan dilengkapi dengan sistem dwi-motor termaju, termasuk motor tak segerak aruhan 3D3 yang dipasang di hadapan dan motor segerak magnet kekal 4D2 yang dipasang di belakang Kedua-duanya berfungsi bersama untuk mengeluarkan kuasa yang menakjubkan. Secara khusus, motor hadapan menyediakan 215 kuasa kuda, manakala motor belakang menyediakan sehingga 412 kuasa kuda, menjadikan jumlah kuasa kenderaan itu kepada 461kW yang menakjubkan. Motor 4D2 belakang sahaja mempunyai kuasa lebih kurang 303kW. Reka bentuk motor kereta baharu ini boleh mencapai kuasa puncak apabila kelajuan mencecah 110km/j, yang menjadikan Model 3 baharu berprestasi lebih baik apabila memandu pada kelajuan tinggi.
 Teknologi FSD Tesla memukau Jerman, dan pemanduan autonomi menjanjikan pada masa hadapan
Apr 29, 2024 pm 01:20 PM
Teknologi FSD Tesla memukau Jerman, dan pemanduan autonomi menjanjikan pada masa hadapan
Apr 29, 2024 pm 01:20 PM
Menurut berita pada 29 April, Tesla baru-baru ini secara terbuka menunjukkan teknologi FSD pemanduan autonomi sepenuhnya yang dinanti-nantikan buat pertama kali di Jerman, menandakan kemasukan rasmi teknologi FSD ke pasaran Eropah. Semasa acara demonstrasi, Rikard Fredriksson, penasihat kanan Kementerian Pengangkutan Sweden, berpeluang merasainya. Dia mengambil Tesla Model Y dan mengalami sendiri kemudahan FSD (pemandu autonomi sepenuhnya). Prestasi di jalan raya Jerman. Fredriksson telah memegang jawatan berkaitan keselamatan produk dalam projek automotif Apple dan mempunyai pemahaman yang mendalam tentang teknologi pemanduan autonomi. Selepas mengalami sistem bantuan pemanduan Fredriksson, pemanduan FSD+12 adalah lancar dan semula jadi. Beliau juga menyebut secara khusus bahawa ketika dalam perjalanan dari pusat bandar Munich ke lapangan terbang
 Laporan kewangan S1 2024 Tesla mengumumkan: penurunan hasil, pengeluaran model berharga rendah dalam agenda
Apr 24, 2024 pm 06:16 PM
Laporan kewangan S1 2024 Tesla mengumumkan: penurunan hasil, pengeluaran model berharga rendah dalam agenda
Apr 24, 2024 pm 06:16 PM
Menurut berita pada 24 April, Tesla mendedahkan laporan kewangannya untuk suku pertama 2024 hari ini. Laporan menunjukkan bahawa Tesla mencapai hasil sebanyak AS$21.301 bilion pada suku tersebut, penurunan 9% berbanding tempoh yang sama tahun lepas. Angka itu lebih rendah sedikit daripada ramalan $22.3 bilion oleh penganalisis pasaran. Pada masa yang sama, keuntungan bersih syarikat ialah AS$1.129 bilion, penurunan mendadak sebanyak 55% tahun ke tahun. Tesla telah mencapai kejayaan besar dalam penjualan kenderaan. Pada suku pertama, 386,800 kenderaan telah dihantar secara global, jauh lebih rendah daripada jangkaan pasaran sebelumnya iaitu kira-kira 430,000 kenderaan. Berbanding dengan tempoh yang sama tahun lepas, jumlah penghantaran jatuh sebanyak 8.3%, dan berbanding dengan suku sebelumnya, ia jatuh mendadak sebanyak 20.1%. Ini adalah penurunan pertama tahun ke tahun Tesla dalam penghantaran sejak 2020. untuk memperlahankan
 Shanghai Energy Storage Gigafactory Tesla akan dimasukkan ke dalam pengeluaran percubaan tahun ini, dengan anggaran skala penyimpanan tenaga hampir 40GWj
Mar 22, 2024 pm 12:32 PM
Shanghai Energy Storage Gigafactory Tesla akan dimasukkan ke dalam pengeluaran percubaan tahun ini, dengan anggaran skala penyimpanan tenaga hampir 40GWj
Mar 22, 2024 pm 12:32 PM
Pembinaan Zon Perintis Industri Masa Depan Shanghai sedang meraikan ulang tahun pertamanya Pada taklimat akhbar yang dihoskan oleh Lu Yu, pengarah Bahagian Teknologi Tinggi Jawatankuasa Pengurusan Kawasan Baharu Lingang, maklumat penting mengenai projek penyimpanan tenaga Tesla yang dinanti-nantikan itu. didedahkan. Lu Yu berkata bahawa projek itu merancang untuk menyelesaikan pengeluaran percubaan dalam tahun ini, dan skala pengeluaran dijangka hampir 40GWj. Berita ini telah menarik perhatian meluas projek penyimpanan tenaga Tesla adalah sangat penting untuk pembangunan industri tempatan dan penggunaan tenaga boleh diperbaharui. Sebagai pengeluar kenderaan elektrik yang terkenal di dunia, penyertaan Tesla dalam bidang penyimpanan tenaga telah menarik banyak perhatian. Dengan bekerjasama dengan Shanghai, pembinaan projek penyimpanan tenaga Tesla di Kawasan Baharu Lingang akan membantu meningkatkan tahap perindustrian tempatan dan keupayaan inovasi teknologi. Lu Yu juga memperkenalkan lagi kemajuan Lingang yang lain dalam bidang tenaga baharu. beliau menyebut
 Pengeluaran besar-besaran Tesla Cybertruck menunjukkan tanda-tanda positif, fotografi udara kilang Texas mendedahkan situasi pengeluaran besar
Mar 15, 2024 pm 12:04 PM
Pengeluaran besar-besaran Tesla Cybertruck menunjukkan tanda-tanda positif, fotografi udara kilang Texas mendedahkan situasi pengeluaran besar
Mar 15, 2024 pm 12:04 PM
Kemajuan pengeluaran trak pikap elektrik tulen terbaharu Tesla, Cybertruck, telah menarik perhatian ramai. Walaupun Tesla telah mengekalkan profil rendah, video udara terbaru Texas Gigafactory yang diambil oleh pemerhati Tesla bernama Jeff Roberts nampaknya mendedahkan tanda-tanda positif pengeluaran Cybertruck kepada dunia luar. Menurut video itu, sudah ada lebih daripada 300 Cybertruck di Tesla Gigafactory di Texas, tersebar di pelbagai kawasan. Bilangan besar kali ini merupakan bilangan Cybertrucks terbesar yang pernah ditemui di kilang itu, menunjukkan bahawa pengeluaran besar-besaran model itu berkembang pesat. Ini menunjukkan bahawa Tesla telah mencapai kemajuan yang ketara dalam pengeluaran Cybertruck. Walaupun Tesla sebelum ini telah menyatakan kebimbangan mengenai Cybertr
