
 Peranti teknologi
AI
Bolehkah BERT juga digunakan di CNN? Hasil penyelidikan ByteDance dipilih untuk Spotlight ICLR 2023
Peranti teknologi
AI
Bolehkah BERT juga digunakan di CNN? Hasil penyelidikan ByteDance dipilih untuk Spotlight ICLR 2023
Bolehkah BERT juga digunakan di CNN? Hasil penyelidikan ByteDance dipilih untuk Spotlight ICLR 2023

Bagaimana untuk menjalankan BERT pada rangkaian saraf konvolusi?
Anda boleh terus menggunakan SparK - Merekabentuk BERT untuk Rangkaian Konvolusi: Pemodelan Bertopeng Jarang dan Hierarki yang dicadangkan oleh pasukan teknikal ByteDance Baru-baru ini, ia telah disertakan sebagai kertas fokus Spotlight oleh Persidangan Kepintaran Buatan :

Pautan kertas:
https://www. php.cn/link/e38e37a99f7de1f45d169efcdb288dd1
Kod sumber terbuka: :
https://www.php.cn/link/9dfcf16f0adbc5e2a55ef02db36bac7f >Ini juga merupakan kejayaan pertama BERT pada Convolutional Neural Network (CNN)
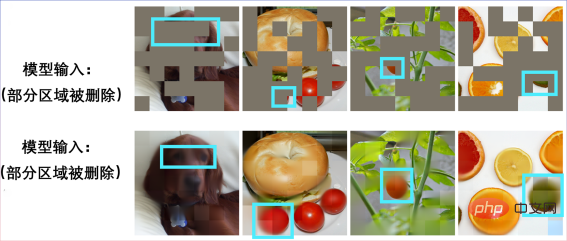
. Mari kita rasai sendiri prestasi SparK dalam pra-latihan. Masukkan gambar yang tidak lengkap:
 Pulihkan anak anjing:
Pulihkan anak anjing:
 Satu lagi Gambar yang rosak:
Satu lagi Gambar yang rosak:
 Ternyata ia adalah sandwic bagel:
Ternyata ia adalah sandwic bagel:
 Pemulihan gambar juga boleh dicapai dalam senario lain:
Pemulihan gambar juga boleh dicapai dalam senario lain:

“
Sebarang tindakan dan pemikiran yang hebat , Semuanya mempunyai permulaan yang sederhana. BERT menggunakan "cloze": padam secara rawak beberapa perkataan dalam ayat dan biarkan model belajar untuk pulih. BERT sangat bergantung pada
Model teras dalam medan NLP - Transformer.
Transformer secara semula jadi sesuai untuk memproses data jujukan panjang boleh ubah (seperti ayat bahasa Inggeris), jadi ia boleh mengatasi "pemadaman rawak" dengan mudah BERT cloze". CNN dalam bidang visual juga mahu menikmati BERT: Apakah dua cabaran itu?
Mengimbas kembali sejarah pembangunan penglihatan komputer, Model rangkaian saraf konvolusi memekatkan intipati banyak model klasik seperti kesetaraan translasi , struktur pelbagai skala, dan lain-lain, boleh dikatakan sebagai tunjang utama dunia CV. Tetapi apa yang sangat berbeza daripada Transformer ialah CNN sememangnya tidak dapat menyesuaikan diri dengan data yang "dilubangi" oleh cloze dan penuh dengan "lubang rawak", jadi ia tidak dapat menikmati dividen pra-latihan BERT pada pandangan pertama. cabaran yang menghalang kejayaan penerapan BERT di CNN. Selain itu, pasukan penulis juga menegaskan bahawa algoritma BERT yang berasal dari bidang NLP secara semula jadi tidak mempunyai ciri-ciri "multi-scale" , dan struktur piramid berskala Ia boleh dipanggil "standard emas" dalam sejarah panjang penglihatan komputer. Konflik antara BERT skala tunggal dan CNN berskala semula jadi ialah Cabaran 2. Penyelesaian SparK: Pemodelan Topeng Jarang dan Hierarki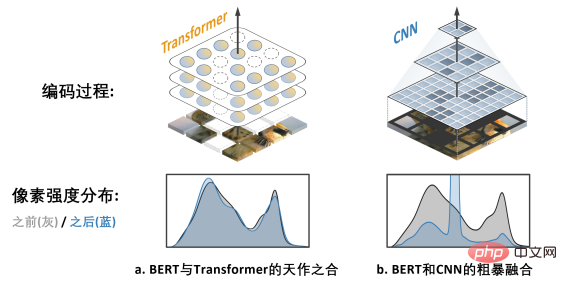
Pertama, diilhamkan oleh pemprosesan data awan titik tiga dimensi, pasukan pengarang mencadangkan untuk merawat imej berpecah-belah selepas operasi penyamaran (operasi berongga) sebagai titik Jarang awan dikodkan menggunakan Submanifold Sparse Convolution. Ini membolehkan rangkaian konvolusi mengendalikan imej yang dipadam secara rawak dengan mudah.
Kedua, diilhamkan oleh reka bentuk elegan UNet, pasukan pengarang secara semula jadi mereka bentuk model penyahkod pengekod dengan sambungan sisi, membolehkan ciri-ciri berbilang skala mengalir antara berbilang peringkat model, membolehkan BERT menerima sepenuhnya standard emas berskala emas penglihatan komputer.
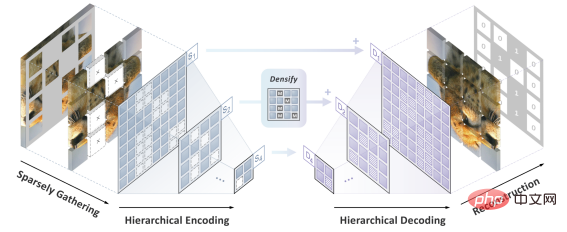
Pada ketika ini, SparK, algoritma pemodelan topeng berbilang skala yang jarang disesuaikan untuk rangkaian konvolusi (CNN), telah dilahirkan.
SparK ialah
generik:
Ia boleh boleh digunakan secara langsung pada mana-mana rangkaian konvolusi tanpa sebarang pengubahsuaian pada strukturnya atau pengenalan sebarang komponen tambahan - sama ada ResNet klasik yang biasa atau model lanjutan ConvNeXt terkini, anda boleh mendapat manfaat secara langsung daripada SparK .
Dari ResNet ke ConvNeXt: Tiga peningkatan prestasi tugas visual utama
Pasukan pengarang memilih dua keluarga model konvolusi wakil, ResNet dan ConvNeXt, dan menjalankan ujian prestasi pada pengelasan imej, pengesanan sasaran dan tugasan pembahagian contoh. Pada model ResNet-50 klasik, SparK berfungsi sebagai satu-satunya pra-latihan generatif, dicapai Tahap terkini:
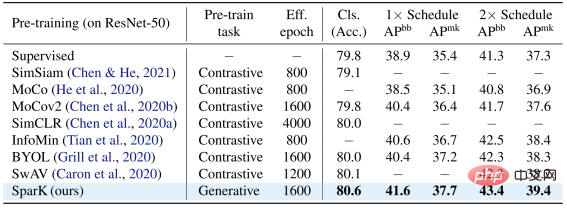
Pada model ConvNeXt, SparK masih di hadapan . Sebelum pra-latihan, ConvNeXt dan Swin-Transformer dipadankan secara sama rata; selepas pra-latihan, ConvNeXt mengatasi Swin-Transformer dalam tiga tugasan:
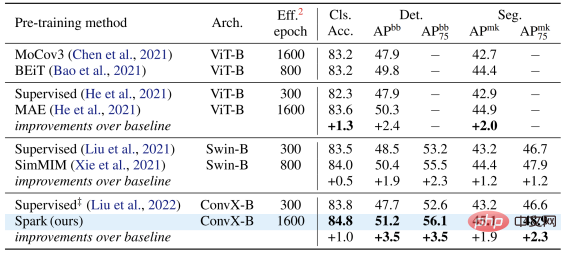
Apabila mengesahkan SparK pada keluarga model lengkap dari kecil hingga besar, ia boleh diperhatikan:
Tidak kira Model besar atau kecil , baharu atau lama, semuanya boleh mendapat manfaat daripada SparK, dan apabila saiz model/overhed latihan meningkat, peningkatan lebih tinggi lagi, mencerminkan keupayaan penskalaan algoritma SparK:
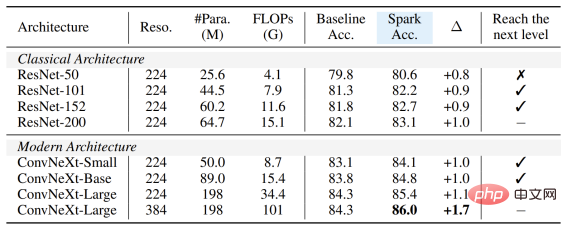 dan
dan
Struktur hierarki baris 3 dan 4 Baris) adalah reka bentuk yang sangat kritikal akan menyebabkan kemerosotan prestasi yang serius:
Atas ialah kandungan terperinci Bolehkah BERT juga digunakan di CNN? Hasil penyelidikan ByteDance dipilih untuk Spotlight ICLR 2023. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Perbelanjaan pengguna global aplikasi penyuntingan video ByteDance CapCut melebihi AS$100 juta
Sep 14, 2023 pm 09:41 PM
Perbelanjaan pengguna global aplikasi penyuntingan video ByteDance CapCut melebihi AS$100 juta
Sep 14, 2023 pm 09:41 PM
CapCut, alat penyuntingan video kreatif yang dimiliki oleh ByteDance, mempunyai sejumlah besar pengguna di China, Amerika Syarikat dan Asia Tenggara. Alat ini menyokong platform Android, iOS dan PC Laporan terbaru daripada data.ai, sebuah organisasi penyelidikan pasaran, menunjukkan bahawa pada 11 September 2023, jumlah perbelanjaan pengguna CapCut pada iOS dan Google Play telah melebihi AS$100 juta (nota pada laman web ini: pada masa ini kira-kira 7.28 bilion), berjaya mengatasi Splice (kedudukan No. 1 pada separuh kedua 2022) dan menjadi aplikasi penyuntingan video paling menguntungkan di dunia pada separuh pertama 2023, peningkatan sebanyak 180% berbanding separuh kedua tahun 2022. Sehingga Ogos 2023, 490 juta orang di seluruh dunia menggunakan CapCut melalui telefon iPhone dan Android. da
 Xiaomi Byte bergabung tenaga! Model besar akses Xiao Ai ke Doubao: sudah dipasang pada telefon mudah alih dan SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte bergabung tenaga! Model besar akses Xiao Ai ke Doubao: sudah dipasang pada telefon mudah alih dan SU7
Jun 13, 2024 pm 05:11 PM
Menurut berita pada 13 Jun, menurut akaun awam “Volcano Engine” Byte, pembantu kecerdasan buatan Xiaomi “Xiao Ai” telah mencapai kerjasama dengan Volcano Engine Kedua-dua pihak akan mencapai pengalaman interaktif AI yang lebih pintar berdasarkan model besar beanbao . Dilaporkan bahawa model beanbao berskala besar yang dicipta oleh ByteDance boleh memproses sehingga 120 bilion token teks dengan cekap dan menjana 30 juta keping kandungan setiap hari. Xiaomi menggunakan model besar Doubao untuk meningkatkan keupayaan pembelajaran dan penaakulan modelnya sendiri dan mencipta "Xiao Ai Classmate", yang bukan sahaja memahami keperluan pengguna dengan lebih tepat, tetapi juga menyediakan kelajuan tindak balas yang lebih pantas dan perkhidmatan kandungan yang lebih komprehensif. Contohnya, apabila pengguna bertanya tentang konsep saintifik yang kompleks, &ldq
 Pertempuran sebenar penggunaan berskala besar model Bytedance
Apr 12, 2023 pm 08:31 PM
Pertempuran sebenar penggunaan berskala besar model Bytedance
Apr 12, 2023 pm 08:31 PM
1. Pengenalan latar belakang Dalam ByteDance, aplikasi berdasarkan pembelajaran mendalam berkembang di mana-mana Jurutera memberi perhatian kepada kesan model tetapi juga perlu memberi perhatian kepada konsistensi dan prestasi perkhidmatan dalam talian Pada masa awal, ini biasanya memerlukan pakar algoritma dan pakar kejuruteraan untuk bekerjasama dan bekerjasama rapat untuk menyelesaikan Mod ini mempunyai kos yang agak tinggi seperti penyelesaian masalah dan pengesahan perbezaan. Dengan populariti rangka kerja PyTorch/TensorFlow, latihan model pembelajaran mendalam dan penaakulan dalam talian telah disatukan Pembangun hanya perlu memberi perhatian kepada logik algoritma tertentu dan memanggil API Python untuk menyelesaikan proses pengesahan latihan. model boleh disiri dan dieksport dengan mudah, dan kerja penaakulan diselesaikan oleh enjin C++ berprestasi tinggi yang bersatu. Pengalaman pembangun yang dipertingkatkan daripada latihan kepada penggunaan
 Percepatkan model resapan, jana imej tahap SOTA dalam 1 langkah terpantas, Byte Hyper-SD ialah sumber terbuka
Apr 25, 2024 pm 05:25 PM
Percepatkan model resapan, jana imej tahap SOTA dalam 1 langkah terpantas, Byte Hyper-SD ialah sumber terbuka
Apr 25, 2024 pm 05:25 PM
Baru-baru ini, DiffusionModel telah mencapai kemajuan yang ketara dalam bidang penjanaan imej, membawa peluang pembangunan yang belum pernah berlaku sebelum ini kepada tugas penjanaan imej dan penjanaan video. Walaupun hasil yang mengagumkan, sifat denoising berulang pelbagai langkah yang wujud dalam proses inferens model resapan menghasilkan kos pengiraan yang tinggi. Baru-baru ini, satu siri algoritma penyulingan model resapan telah muncul untuk mempercepatkan proses inferens model resapan. Kaedah-kaedah ini secara kasar boleh dibahagikan kepada dua kategori: i) penyulingan pemuliharaan trajektori; ii) penyulingan pembinaan semula trajektori. Walau bagaimanapun, kedua-dua jenis kaedah ini akan dihadkan oleh siling kesan terhad atau perubahan dalam domain output. Untuk menyelesaikan masalah ini, pasukan teknikal ByteDance mencadangkan kaedah konsisten pembahagian trajektori yang dipanggil Hyper-SD.
 Pusat Shenzhen Bytedance Houhai mempunyai jumlah kawasan pembinaan seluas 77,400 meter persegi dan struktur utama telah ditambah
Jan 24, 2024 pm 05:27 PM
Pusat Shenzhen Bytedance Houhai mempunyai jumlah kawasan pembinaan seluas 77,400 meter persegi dan struktur utama telah ditambah
Jan 24, 2024 pm 05:27 PM
Menurut akaun awam rasmi WeChat Kerajaan Daerah Nanshan "Innovation Nanshan", projek Shenzhen ByteDance Houhai Center telah mencapai kemajuan penting baru-baru ini. Menurut Syarikat Pembinaan dan Pembangunan Biro Kejuruteraan Pembinaan Pertama China, struktur utama projek itu telah dihadkan tiga hari lebih awal daripada jadual. Berita ini bermakna bahawa kawasan teras Nanshan Houhai akan mengantar bangunan mercu tanda baharu. Projek Shenzhen ByteDance Houhai Center terletak di kawasan teras Houhai, Daerah Nanshan Ia merupakan bangunan pejabat ibu pejabat Toutiao Technology Co., Ltd. di Shenzhen. Jumlah kawasan pembinaan adalah 77,400 meter persegi, dengan ketinggian kira-kira 150 meter dan sejumlah 4 tingkat bawah tanah dan 32 di atas tingkat bawah. Dilaporkan bahawa projek Shenzhen ByteDance Houhai Centre akan menjadi bangunan bertingkat tinggi yang inovatif yang menyepadukan pejabat, hiburan, katering dan fungsi lain. Projek ini akan membantu Shenzhen mempromosikan integrasi industri Internet
 NUS dan Byte bekerjasama merentas industri untuk mencapai latihan 72 kali lebih pantas melalui pengoptimuman model, dan memenangi Kertas Cemerlang AAAI2023.
May 06, 2023 pm 10:46 PM
NUS dan Byte bekerjasama merentas industri untuk mencapai latihan 72 kali lebih pantas melalui pengoptimuman model, dan memenangi Kertas Cemerlang AAAI2023.
May 06, 2023 pm 10:46 PM
Baru-baru ini, persidangan kecerdasan buatan antarabangsa teratas AAAI2023 mengumumkan keputusan pemilihan. Kertas teknikal CowClip yang bekerjasama oleh Universiti Nasional Singapura (NUS) dan Pasukan Pembelajaran Mesin ByteDance (AML) telah disenarai pendek untuk Distinguished Papers (Distinguished Papers). CowClip ialah strategi pengoptimuman latihan model yang boleh meningkatkan kelajuan latihan model sebanyak 72 kali pada satu GPU sambil memastikan ketepatan model Kod yang berkaitan kini adalah sumber terbuka. Alamat kertas: https://arxiv.org/abs/2204.06240Alamat sumber terbuka: https://github.com/bytedance/LargeBatchCTRAAA
 ByteDance mengembangkan pusat R&D global dan menghantar jurutera ke Kanada, Australia dan tempat lain
Jan 18, 2024 pm 04:00 PM
ByteDance mengembangkan pusat R&D global dan menghantar jurutera ke Kanada, Australia dan tempat lain
Jan 18, 2024 pm 04:00 PM
Menurut berita IT House pada 18 Januari, sebagai tindak balas kepada khabar angin baru-baru ini bahawa pekerja domestik TikTok telah berpindah ke luar negara, orang yang rapat dengan ByteDance mendedahkan bahawa syarikat itu sedang bersedia untuk membina pusat R&D di Kanada, Australia dan tempat lain. Pada masa ini, beberapa pusat R&D telah menjalankan operasi percubaan selama kira-kira setengah tahun, dan akan menyokong R&D beberapa perniagaan luar negara seperti TikTok, CapCut dan Lemon8 pada masa hadapan. ByteDance merancang untuk memberi tumpuan kepada pengambilan tempatan dan membantu dalam penubuhan pusat R&D yang berkaitan melalui sebilangan kecil ekspatriat. Difahamkan, sejak enam bulan lalu, syarikat itu telah memilih sebilangan kecil jurutera dari Amerika Syarikat, China, Singapura dan tempat-tempat lain untuk menyertai persiapan itu. Antaranya, seramai 120 orang telah dihantar dari China ke pusat R&D di dua tempat itu, termasuk kedudukan produk, R&D dan operasi. Orang yang berkaitan berkata bahawa langkah ini adalah untuk menghadapi perkembangan perniagaan luar negara dan lebih baik
 Jualan PICO 4 jauh di bawah jangkaan dan berita melaporkan bahawa ByteDance akan membatalkan set kepala VR generasi akan datang PICO 5
Dec 15, 2023 am 09:34 AM
Jualan PICO 4 jauh di bawah jangkaan dan berita melaporkan bahawa ByteDance akan membatalkan set kepala VR generasi akan datang PICO 5
Dec 15, 2023 am 09:34 AM
Menurut berita dari laman web ini pada 13 Disember, menurut The Information, ByteDance sedang bersiap sedia untuk menghentikan set kepala VR generasi baharu PICO PICO5 kerana jualan PICO4 semasa jauh lebih rendah daripada yang dijangkakan. Menurut artikel oleh EqualOcean pada Oktober tahun ini, ByteDance dikatakan akan menutup PICO secara beransur-ansur dan meninggalkan medan Metaverse. Artikel itu menunjukkan bahawa ByteDance percaya bahawa bidang perkakasan di mana PICO terletak bukan kepakarannya, prestasinya dalam beberapa tahun yang lalu tidak memenuhi jangkaan, dan ia tidak mempunyai harapan untuk masa depan, orang yang bertanggungjawab daripada ByteDance menjawab khabar angin tentang "meninggalkan perniagaan PICO secara beransur-ansur, mengatakan berita itu tidak benar." Mereka menyatakan bahawa perniagaan PICO masih beroperasi seperti biasa dan syarikat itu akan melabur dalam realiti lanjutan untuk jangka panjang.
