
 Peranti teknologi
AI
Ringkasan enam kaedah biasa pembelajaran berterusan: menyesuaikan model ML kepada data baharu sambil mengekalkan prestasi data lama
Peranti teknologi
AI
Ringkasan enam kaedah biasa pembelajaran berterusan: menyesuaikan model ML kepada data baharu sambil mengekalkan prestasi data lama
Ringkasan enam kaedah biasa pembelajaran berterusan: menyesuaikan model ML kepada data baharu sambil mengekalkan prestasi data lama

Pembelajaran berterusan merujuk kepada model yang mempelajari sejumlah besar tugasan secara berurutan tanpa melupakan pengetahuan yang diperoleh daripada tugasan sebelumnya. Ini merupakan konsep penting kerana, di bawah pembelajaran diselia, model pembelajaran mesin dilatih untuk menjadi fungsi terbaik untuk set data atau pengedaran data tertentu. Dalam persekitaran kehidupan sebenar, data jarang statik dan mungkin berubah. Model ML biasa boleh mengalami kemerosotan prestasi apabila berhadapan dengan data yang tidak kelihatan. Fenomena ini dipanggil pelupaan bencana.

Cara biasa untuk menyelesaikan jenis masalah ini ialah melatih semula keseluruhan model pada set data baharu yang lebih besar yang mengandungi data lama dan baharu. Tetapi pendekatan ini selalunya mahal. Oleh itu, terdapat bidang penyelidikan ML yang mengkaji masalah ini Berdasarkan penyelidikan dalam bidang ini, artikel ini akan membincangkan 6 kaedah supaya model dapat menyesuaikan diri dengan data baru sambil mengekalkan prestasi lama dan mengelakkan keperluan untuk melaksanakan. keseluruhan set data (lama + baharu) untuk dilatih semula.
Prompt
Prompt Idea berpunca daripada idea bahawa pembayang (urutan perkataan pendek) untuk GPT 3 boleh membantu mendorong model untuk menaakul dan menjawab dengan lebih baik. Jadi Prompt diterjemahkan sebagai prompt dalam artikel ini. Penalaan petunjuk merujuk kepada menggunakan pembayang kecil yang boleh dipelajari dan memberinya sebagai input kepada model bersama dengan input sebenar. Ini membolehkan kami hanya melatih model kecil yang memberikan petunjuk tentang data baharu tanpa perlu melatih semula berat model.
Secara khusus, saya memilih contoh penggunaan gesaan untuk mendapatkan semula intensif berasaskan teks, yang diadaptasi daripada artikel Wang "Belajar untuk Mendorong Pembelajaran berterusan".
Pengarang makalah menerangkan idea mereka menggunakan rajah berikut:
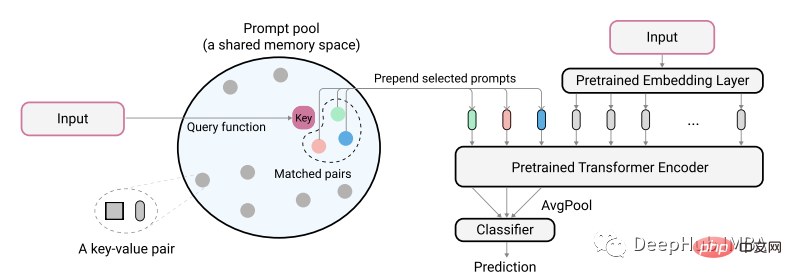
Input teks yang dikodkan sebenar digunakan untuk mengenal pasti pasangan padanan minimum daripada gesaan kunci kolam. Isyarat yang dikenal pasti ini terlebih dahulu ditambahkan pada benam teks yang tidak dikodkan sebelum ia dimasukkan ke dalam model. Tujuannya adalah untuk melatih gesaan ini untuk mewakili tugasan baharu sambil mengekalkan model lama tidak berubah Gesaan di sini adalah sangat kecil, mungkin hanya 20 token setiap gesaan.
class PromptPool(nn.Module):
def __init__(self, M = 100, hidden_size = 768, length = 20, N=5):
super().__init__()
self.pool = nn.Parameter(torch.rand(M, length, hidden_size), requires_grad=True).float()
self.keys = nn.Parameter(torch.rand(M, hidden_size), requires_grad=True).float()
self.length = length
self.hidden = hidden_size
self.n = N
nn.init.xavier_normal_(self.pool)
nn.init.xavier_normal_(self.keys)
def init_weights(self, embedding):
pass
# function to select from pool based on index
def concat(self, indices, input_embeds):
subset = self.pool[indices, :] # 2, 2, 20, 768
subset = subset.to("cuda:0").reshape(indices.size(0),
self.n*self.length,
self.hidden) # 2, 40, 768
return torch.cat((subset, input_embeds), 1)
# x is cls output
def query_fn(self, x):
# encode input x to same dim as key using cosine
x = x / x.norm(dim=1)[:, None]
k = self.keys / self.keys.norm(dim=1)[:, None]
scores = torch.mm(x, k.transpose(0,1).to("cuda:0"))
# get argmin
subsets = torch.topk(scores, self.n, 1, False).indices # k smallest
return subsets
pool = PromptPool()Kemudian kami menggunakan model data lama yang terlatih untuk melatih data baharu Di sini kami hanya melatih berat bahagian gesaan.
def train():
count = 0
print("*********** Started Training *************")
start = time.time()
for epoch in range(40):
model.eval()
pool.train()
optimizer.zero_grad(set_to_none=True)
lap = time.time()
for batch in iter(train_dataloader):
count += 1
q, p, train_labels = batch
queries_emb = model(input_ids=q['input_ids'].to("cuda:0"),
attention_mask=q['attention_mask'].to("cuda:0"))
passage_emb = model(input_ids=p['input_ids'].to("cuda:0"),
attention_mask=p['attention_mask'].to("cuda:0"))
# pool
q_idx = pool.query_fn(queries_emb)
raw_qembedding = model.model.embeddings(input_ids=q['input_ids'].to("cuda:0"))
q = pool.concat(indices=q_idx, input_embeds=raw_qembedding)
p_idx = pool.query_fn(passage_emb)
raw_pembedding = model.model.embeddings(input_ids=p['input_ids'].to("cuda:0"))
p = pool.concat(indices=p_idx, input_embeds=raw_pembedding)
qattention_mask = torch.ones(batch_size, q.size(1))
pattention_mask = torch.ones(batch_size, p.size(1))
queries_emb = model.model(inputs_embeds=q,
attention_mask=qattention_mask.to("cuda:0")).last_hidden_state
passage_emb = model.model(inputs_embeds=p,
attention_mask=pattention_mask.to("cuda:0")).last_hidden_state
q_cls = queries_emb[:, pool.n*pool.length+1, :]
p_cls = passage_emb[:, pool.n*pool.length+1, :]
loss, ql, pl = calc_loss(q_cls, p_cls)
loss.backward()
optimizer.step()
optimizer.zero_grad(set_to_none=True)
if count % 10 == 0:
print("Model Loss:", round(loss.item(),4),
"| QL:", round(ql.item(),4), "| PL:", round(pl.item(),4),
"| Took:", round(time.time() - lap), "secondsn")
lap = time.time()
if count % 40 == 0 and count > 0:
print("model saved")
torch.save(model.state_dict(), model_PATH)
torch.save(pool.state_dict(), pool_PATH)
if count == 4600: return
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")Selepas latihan selesai, proses inferens seterusnya perlu menggabungkan input dengan pembayang yang diambil. Contohnya, contoh ini mendapat prestasi -93% untuk kumpulan petunjuk data baharu dan -94% untuk latihan penuh (lama + baharu). Ini serupa dengan prestasi yang dinyatakan dalam kertas asal. Tetapi kaveatnya ialah keputusan mungkin berbeza-beza bergantung pada tugasan, dan anda harus mencuba eksperimen untuk mengetahui perkara yang paling berkesan.
Untuk kaedah ini berbaloi untuk dipertimbangkan, ia mesti dapat mengekalkan >80% prestasi model lama pada data lama, manakala pembayang juga harus membantu model mencapai prestasi yang baik pada data baharu.
Kelemahan kaedah ini ialah ia memerlukan penggunaan kolam pembayang, yang menambah masa tambahan. Ini bukan penyelesaian kekal, tetapi ia boleh dilaksanakan buat masa ini, dan mungkin kaedah baharu akan muncul pada masa hadapan.
Penyulingan Data
Anda mungkin pernah mendengar istilah penyulingan pengetahuan, iaitu teknik yang menggunakan pemberat daripada model guru untuk membimbing dan melatih model berskala lebih kecil. Penyulingan Data berfungsi sama, menggunakan pemberat daripada data sebenar untuk melatih subset data yang lebih kecil. Oleh kerana isyarat utama set data diperhalusi dan dipadatkan kepada set data yang lebih kecil, latihan kami tentang data baharu hanya perlu disediakan dengan beberapa data yang diperhalusi untuk mengekalkan prestasi lama.
Dalam contoh ini, saya menggunakan penyulingan data pada tugas mendapatkan semula (teks) padat. Tiada orang lain yang menggunakan kaedah ini dalam bidang ini pada masa ini, jadi hasilnya mungkin bukan yang terbaik, tetapi jika anda menggunakan kaedah ini pada pengelasan teks, anda sepatutnya mendapat hasil yang baik.
Pada asasnya, idea penyulingan data teks berasal daripada kertas oleh Li bertajuk Penyulingan Data untuk Pengelasan Teks, yang diilhamkan oleh Penyulingan Set Data Wang, di mana beliau menyuling data imej. Li menerangkan tugas penyulingan data teks dengan gambar rajah berikut:
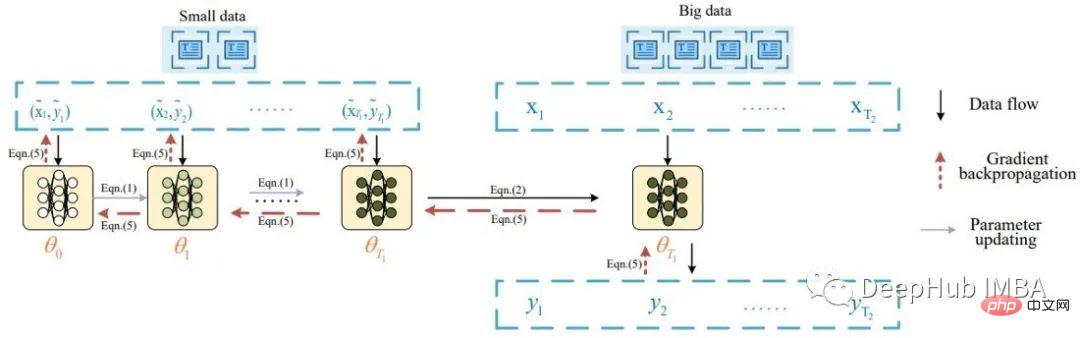
Menurut kertas kerja, sekumpulan data suling dimasukkan dahulu ke dalam model untuk mengemas kini beratnya. Model yang dikemas kini kemudian dinilai menggunakan data sebenar dan isyarat disebarkan semula ke set data suling. Makalah ini melaporkan hasil pengelasan yang baik (>80% ketepatan) pada 8 set data penanda aras awam.
Berikutan idea yang dicadangkan, saya membuat beberapa perubahan kecil dan menggunakan sekumpulan data suling dan berbilang data sebenar. Berikut ialah kod untuk mencipta data suling untuk latihan mendapatkan semula intensif:
class DistilledData(nn.Module):
def __init__(self, num_labels, M, q_len=64, hidden_size=768):
super().__init__()
self.num_samples = M
self.q_len = q_len
self.num_labels = num_labels
self.data = nn.Parameter(torch.rand(num_labels, M, q_len, hidden_size), requires_grad=True) # i.e. shape: 1000, 4, 64, 768
# init using model embedding, xavier, or load from state dict
def init_weights(self, model, path=None):
if model:
self.data.requires_grad = False
print("Init weights using model embedding")
raw_embedding = model.model.get_input_embeddings()
soft_embeds = raw_embedding.weight[:, :].clone().detach()
nums = soft_embeds.size(0)
for i1 in range(self.num_labels):
for i2 in range(self.num_samples):
for i3 in range(self.q_len):
random_idx = random.randint(0, nums-1)
self.data[i1, i2, i3, :] = soft_embeds[random_idx, :]
print(self.data.shape)
self.data.requires_grad = True
if not path:
nn.init.xavier_normal_(self.data)
else:
distilled_data.load_state_dict(torch.load(path), strict=False)
# function to sample a passage and positive sample as in the article, i am doing dense retrieval
def get_sample(self, label):
q_idx = random.randint(0, self.num_samples-1)
sampled_dist_q = self.data[label, q_idx, :, :]
p_idx = random.randint(0, self.num_samples-1)
while q_idx == p_idx:
p_idx = random.randint(0, self.num_samples-1)
sampled_dist_p = self.data[label, p_idx, :, :]
return sampled_dist_q, sampled_dist_p, q_idx, p_idxIni ialah kod untuk mengekstrak isyarat ke data suling
def distll_train(chunk_size=32):
count, times = 0, 0
print("*********** Started Training *************")
start = time.time()
lap = time.time()
for epoch in range(40):
distilled_data.train()
for batch in iter(train_dataloader):
count += 1
# get real query, pos, label, distilled data query, distilled data pos, ... from batch
q, p, train_labels, dq, dp, q_indexes, p_indexes = batch
for idx in range(0, dq['input_ids'].size(0), chunk_size):
model.train()
with torch.enable_grad():
# train on distiled data first
x1 = dq['input_ids'][idx:idx+chunk_size].clone().detach().requires_grad_(True)
x2 = dp['input_ids'][idx:idx+chunk_size].clone().detach().requires_grad_(True)
q_emb = model(inputs_embeds=x1.to("cuda:0"),
attention_mask=dq['attention_mask'][idx:idx+chunk_size].to("cuda:0")).cpu()
p_emb = model(inputs_embeds=x2.to("cuda:0"),
attention_mask=dp['attention_mask'][idx:idx+chunk_size].to("cuda:0"))
loss = default_loss(q_emb.to("cuda:0"), p_emb)
del q_emb, p_emb
loss.backward(retain_graph=True, create_graph=False)
state_dict = model.state_dict()
# update model weights
with torch.no_grad():
for idx, param in enumerate(model.parameters()):
if param.requires_grad and not param.grad is None:
param.data -= (param.grad*3e-5)
# real data
model.eval()
q_embs = []
p_embs = []
for k in range(0, len(q['input_ids']), chunk_size):
with torch.no_grad():
q_emb = model(input_ids=q['input_ids'][k:k+chunk_size].to("cuda:0"),).cpu()
p_emb = model(input_ids=p['input_ids'][k:k+chunk_size].to("cuda:0"),).cpu()
q_embs.append(q_emb)
p_embs.append(p_emb)
q_embs = torch.cat(q_embs, 0)
p_embs = torch.cat(p_embs, 0)
r_loss = default_loss(q_embs.to("cuda:0"), p_embs.to("cuda:0"))
del q_embs, p_embs
# distill backward
if count % 2 == 0:
d_grad = torch.autograd.grad(inputs=[x1.to("cuda:0")],#, x2.to("cuda:0")],
outputs=loss,
grad_outputs=r_loss)
indexes = q_indexes
else:
d_grad = torch.autograd.grad(inputs=[x2.to("cuda:0")],
outputs=loss,
grad_outputs=r_loss)
indexes = p_indexes
loss.detach()
r_loss.detach()
grads = torch.zeros(distilled_data.data.shape) # lbl, 10, 100, 768
for i, k in enumerate(indexes):
grads[train_labels[i], k, :, :] = grads[train_labels[i], k, :, :].to("cuda:0")
+ d_grad[0][i, :, :]
distilled_data.data.grad = grads
data_optimizer.step()
data_optimizer.zero_grad(set_to_none=True)
model.load_state_dict(state_dict)
model_optimizer.step()
model_optimizer.zero_grad(set_to_none=True)
if count % 10 == 0:
print("Count:", count ,"| Data:", round(loss.item(), 4), "| Model:",
round(r_loss.item(),4), "| Time:", round(time.time() - lap, 4))
# print()
lap = time.time()
if count % 100 == 0:
torch.save(model.state_dict(), model_PATH)
torch.save(distilled_data.state_dict(), distill_PATH)
if loss < 0.1 and r_loss < 1:
times += 1
if times > 100:
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")
return
del loss, r_loss, grads, q, p, train_labels, dq, dp, x1, x2, state_dict
print("Training Took:", round(time.time() - start), "seconds")
print("n*********** Training Complete *************")Kod seperti pemuatan data, latihan dikecualikan di sini Setelah kami menyaring data, kami boleh menggunakannya dengan melatih model baharu padanya, contohnya dengan menggabungkannya dengan data baharu.
Menurut eksperimen saya, model yang dilatih pada data suling (hanya mengandungi 4 sampel setiap label) mencapai prestasi terbaik sebanyak 66%, manakala model yang dilatih sepenuhnya pada data mentah juga mencapai 66% prestasi terbaik. Model biasa yang tidak terlatih mencapai prestasi 45%. Seperti yang dinyatakan di atas nombor ini mungkin tidak baik untuk tugas mendapatkan semula intensif, tetapi akan menjadi lebih baik pada data kategori.
Untuk kaedah ini berguna apabila melaraskan model kepada data baharu, seseorang itu perlu dapat mengekstrak set data yang jauh lebih kecil daripada data asal (iaitu ~1%). Data yang diperhalusi juga boleh memberikan anda prestasi yang lebih rendah sedikit daripada atau sama dengan kaedah pembelajaran aktif.
Kelebihan kaedah ini ialah ia boleh mencipta data suling untuk kegunaan kekal. Kelemahannya ialah data yang diekstrak tidak boleh ditafsir dan memerlukan masa latihan tambahan.
Kurikulum/Latihan aktif
Latihan kurikulum ialah kaedah yang secara beransur-ansur menjadi lebih sukar untuk menyediakan sampel latihan kepada model semasa latihan. Apabila melatih data baharu, kaedah ini memerlukan pelabelan manual tugas, mengklasifikasikan tugas kepada mudah, sederhana atau sukar, dan kemudian mengambil sampel data. Untuk memahami maksud model menjadi mudah, sederhana atau sukar, saya mengambil imej ini sebagai contoh:
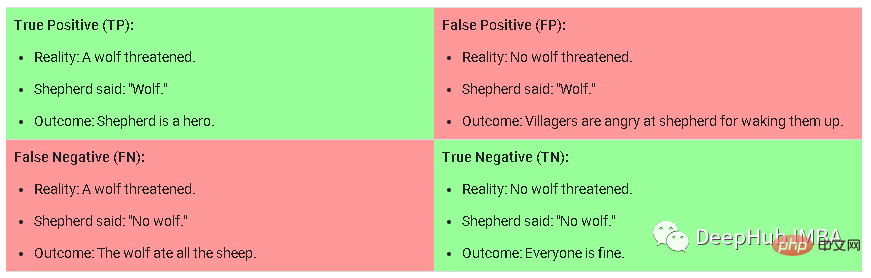
Ini ialah matriks kekeliruan dalam tugas pengelasan, sampel keras adalah palsu Positif (Positif Palsu) merujuk kepada sampel yang model meramalkan kemungkinan besar adalah Benar, tetapi sebenarnya tidak Benar. Sampel sederhana ialah sampel yang mempunyai kebarangkalian sederhana hingga tinggi untuk betul tetapi Negatif Benar di bawah ambang ramalan. Sampel mudah ialah sampel yang mempunyai kemungkinan lebih rendah untuk Benar Positif/Negatif.
Maximally Interfered Retrieval
Ini adalah kaedah yang diperkenalkan oleh Rahaf dalam makalah (1908.04742) bertajuk "Online Continual Learning with Maximally Interfered Retrieval". Idea utama ialah untuk setiap kumpulan data baharu yang dilatih, jika anda mengemas kini berat model untuk data yang lebih baharu, anda perlu mengenal pasti sampel lama yang paling terjejas dari segi nilai kehilangan. Memori saiz terhad yang terdiri daripada data lama dikekalkan dan sampel yang paling mengganggu diambil bersama dengan setiap kumpulan data baharu untuk dilatih bersama.
Kertas ini ialah kertas kerja yang mantap dalam bidang pembelajaran berterusan dan mempunyai banyak petikan, jadi ia boleh digunakan untuk kes anda.
Akmentasi Retrieval
Agmentasi Retrieval merujuk kepada teknik menambah input, sampel, dsb. dengan mendapatkan semula item daripada koleksi. Ini adalah konsep umum dan bukannya teknologi khusus. Kebanyakan kaedah yang telah kami bincangkan setakat ini adalah operasi berkaitan perolehan sedikit sebanyak. Kertas kerja Izacard bertajuk Few-shot Learning with Retrieval Augmented Language Models menggunakan model yang lebih kecil untuk mencapai prestasi cemerlang dalam pembelajaran beberapa pukulan. Peningkatan perolehan juga digunakan dalam banyak situasi lain, seperti penjanaan perkataan atau menjawab soalan fakta.
Melanjutkan model untuk menggunakan lapisan tambahan semasa latihan ialah kaedah yang paling biasa dan paling mudah, tetapi ia tidak semestinya berkesan, jadi ia tidak akan dibincangkan secara terperinci di sini. Contoh di sini ialah Pembelajaran Sedikit Tangkapan Cekap Lewis tanpa Gesaan. Menggunakan lapisan tambahan selalunya merupakan cara yang paling mudah tetapi dicuba dan diuji untuk mendapatkan prestasi yang baik pada data lama dan baharu. Idea utama adalah untuk memastikan berat model tetap dan melatih satu atau beberapa lapisan pada data baharu dengan kehilangan klasifikasi.
Ringkasan Dalam artikel ini, saya memperkenalkan 6 kaedah yang boleh anda gunakan semasa melatih model tentang data baharu. Seperti biasa seseorang itu harus bereksperimen dan memutuskan kaedah mana yang paling berkesan, tetapi penting untuk diperhatikan bahawa terdapat banyak kaedah selain kaedah yang saya ada di atas, contohnya penyulingan data adalah kawasan aktif dalam penglihatan komputer dan anda boleh menemui banyak tentangnya kertas . Nota terakhir: agar kaedah ini bernilai, kaedah ini harus mencapai prestasi yang baik pada kedua-dua data lama dan baharu.
Atas ialah kandungan terperinci Ringkasan enam kaedah biasa pembelajaran berterusan: menyesuaikan model ML kepada data baharu sambil mengekalkan prestasi data lama. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 15 alat anotasi imej percuma sumber terbuka disyorkan
Mar 28, 2024 pm 01:21 PM
15 alat anotasi imej percuma sumber terbuka disyorkan
Mar 28, 2024 pm 01:21 PM
Anotasi imej ialah proses mengaitkan label atau maklumat deskriptif dengan imej untuk memberi makna dan penjelasan yang lebih mendalam kepada kandungan imej. Proses ini penting untuk pembelajaran mesin, yang membantu melatih model penglihatan untuk mengenal pasti elemen individu dalam imej dengan lebih tepat. Dengan menambahkan anotasi pada imej, komputer boleh memahami semantik dan konteks di sebalik imej, dengan itu meningkatkan keupayaan untuk memahami dan menganalisis kandungan imej. Anotasi imej mempunyai pelbagai aplikasi, meliputi banyak bidang, seperti penglihatan komputer, pemprosesan bahasa semula jadi dan model penglihatan graf Ia mempunyai pelbagai aplikasi, seperti membantu kenderaan dalam mengenal pasti halangan di jalan raya, dan membantu dalam proses. pengesanan dan diagnosis penyakit melalui pengecaman imej perubatan. Artikel ini terutamanya mengesyorkan beberapa alat anotasi imej sumber terbuka dan percuma yang lebih baik. 1.Makesen
 Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Dalam bidang pembelajaran mesin dan sains data, kebolehtafsiran model sentiasa menjadi tumpuan penyelidik dan pengamal. Dengan aplikasi meluas model yang kompleks seperti kaedah pembelajaran mendalam dan ensemble, memahami proses membuat keputusan model menjadi sangat penting. AI|XAI yang boleh dijelaskan membantu membina kepercayaan dan keyakinan dalam model pembelajaran mesin dengan meningkatkan ketelusan model. Meningkatkan ketelusan model boleh dicapai melalui kaedah seperti penggunaan meluas pelbagai model yang kompleks, serta proses membuat keputusan yang digunakan untuk menerangkan model. Kaedah ini termasuk analisis kepentingan ciri, anggaran selang ramalan model, algoritma kebolehtafsiran tempatan, dsb. Analisis kepentingan ciri boleh menerangkan proses membuat keputusan model dengan menilai tahap pengaruh model ke atas ciri input. Anggaran selang ramalan model
 Kenal pasti overfitting dan underfitting melalui lengkung pembelajaran
Apr 29, 2024 pm 06:50 PM
Kenal pasti overfitting dan underfitting melalui lengkung pembelajaran
Apr 29, 2024 pm 06:50 PM
Artikel ini akan memperkenalkan cara mengenal pasti pemasangan lampau dan kekurangan dalam model pembelajaran mesin secara berkesan melalui keluk pembelajaran. Underfitting dan overfitting 1. Overfitting Jika model terlampau latihan pada data sehingga ia mempelajari bunyi daripadanya, maka model tersebut dikatakan overfitting. Model yang dipasang terlebih dahulu mempelajari setiap contoh dengan sempurna sehingga ia akan salah mengklasifikasikan contoh yang tidak kelihatan/baharu. Untuk model terlampau, kami akan mendapat skor set latihan yang sempurna/hampir sempurna dan set pengesahan/skor ujian yang teruk. Diubah suai sedikit: "Punca overfitting: Gunakan model yang kompleks untuk menyelesaikan masalah mudah dan mengekstrak bunyi daripada data. Kerana set data kecil sebagai set latihan mungkin tidak mewakili perwakilan yang betul bagi semua data. 2. Underfitting Heru
 Telus! Analisis mendalam tentang prinsip model pembelajaran mesin utama!
Apr 12, 2024 pm 05:55 PM
Telus! Analisis mendalam tentang prinsip model pembelajaran mesin utama!
Apr 12, 2024 pm 05:55 PM
Dalam istilah orang awam, model pembelajaran mesin ialah fungsi matematik yang memetakan data input kepada output yang diramalkan. Secara lebih khusus, model pembelajaran mesin ialah fungsi matematik yang melaraskan parameter model dengan belajar daripada data latihan untuk meminimumkan ralat antara output yang diramalkan dan label sebenar. Terdapat banyak model dalam pembelajaran mesin, seperti model regresi logistik, model pepohon keputusan, model mesin vektor sokongan, dll. Setiap model mempunyai jenis data dan jenis masalah yang berkenaan. Pada masa yang sama, terdapat banyak persamaan antara model yang berbeza, atau terdapat laluan tersembunyi untuk evolusi model. Mengambil perceptron penyambung sebagai contoh, dengan meningkatkan bilangan lapisan tersembunyi perceptron, kita boleh mengubahnya menjadi rangkaian neural yang mendalam. Jika fungsi kernel ditambah pada perceptron, ia boleh ditukar menjadi SVM. yang ini
 Evolusi kecerdasan buatan dalam penerokaan angkasa lepas dan kejuruteraan penempatan manusia
Apr 29, 2024 pm 03:25 PM
Evolusi kecerdasan buatan dalam penerokaan angkasa lepas dan kejuruteraan penempatan manusia
Apr 29, 2024 pm 03:25 PM
Pada tahun 1950-an, kecerdasan buatan (AI) dilahirkan. Ketika itulah penyelidik mendapati bahawa mesin boleh melakukan tugas seperti manusia, seperti berfikir. Kemudian, pada tahun 1960-an, Jabatan Pertahanan A.S. membiayai kecerdasan buatan dan menubuhkan makmal untuk pembangunan selanjutnya. Penyelidik sedang mencari aplikasi untuk kecerdasan buatan dalam banyak bidang, seperti penerokaan angkasa lepas dan kelangsungan hidup dalam persekitaran yang melampau. Penerokaan angkasa lepas ialah kajian tentang alam semesta, yang meliputi seluruh alam semesta di luar bumi. Angkasa lepas diklasifikasikan sebagai persekitaran yang melampau kerana keadaannya berbeza daripada di Bumi. Untuk terus hidup di angkasa, banyak faktor mesti dipertimbangkan dan langkah berjaga-jaga mesti diambil. Para saintis dan penyelidik percaya bahawa meneroka ruang dan memahami keadaan semasa segala-galanya boleh membantu memahami cara alam semesta berfungsi dan bersedia untuk menghadapi kemungkinan krisis alam sekitar
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Adakah Flash Attention stabil? Meta dan Harvard mendapati bahawa sisihan berat model mereka berubah-ubah mengikut urutan magnitud
May 30, 2024 pm 01:24 PM
Adakah Flash Attention stabil? Meta dan Harvard mendapati bahawa sisihan berat model mereka berubah-ubah mengikut urutan magnitud
May 30, 2024 pm 01:24 PM
MetaFAIR bekerjasama dengan Harvard untuk menyediakan rangka kerja penyelidikan baharu untuk mengoptimumkan bias data yang dijana apabila pembelajaran mesin berskala besar dilakukan. Adalah diketahui bahawa latihan model bahasa besar sering mengambil masa berbulan-bulan dan menggunakan ratusan atau bahkan ribuan GPU. Mengambil model LLaMA270B sebagai contoh, latihannya memerlukan sejumlah 1,720,320 jam GPU. Melatih model besar memberikan cabaran sistemik yang unik disebabkan oleh skala dan kerumitan beban kerja ini. Baru-baru ini, banyak institusi telah melaporkan ketidakstabilan dalam proses latihan apabila melatih model AI generatif SOTA Mereka biasanya muncul dalam bentuk lonjakan kerugian Contohnya, model PaLM Google mengalami sehingga 20 lonjakan kerugian semasa proses latihan. Bias berangka adalah punca ketidaktepatan latihan ini,
