

Penterjemah |. Zhu Xianzhong
Penilai |. Sun Shujuan
Dalam artikel ini, saya ingin berkongsi dengan anda kaedah saya untuk mengoptimumkan data input model pembelajaran mendalam. Sebagai seorang saintis data dan jurutera data, saya telah berjaya menggunakan teknik ini untuk kerja saya sendiri. Anda akan belajar cara menggunakan maklumat kontekstual untuk memperkayakan data input model melalui beberapa kes pembangunan dunia sebenar yang konkrit. Ini akan membantu anda mereka bentuk model pembelajaran mendalam yang lebih mantap dan tepat.

Model pembelajaran mendalam sangat berkuasa kerana ia sangat baik dalam mengintegrasikan maklumat kontekstual. Kami boleh meningkatkan prestasi rangkaian saraf dengan menambahkan beberapa konteks pada dimensi data asal. Kita boleh mencapai ini melalui beberapa kejuruteraan data yang bijak.
Apabila anda membangunkan algoritma pembelajaran mendalam ramalan baharu, anda boleh memilih seni bina model yang sangat sesuai untuk kes penggunaan khusus anda. Bergantung pada data input dan tugas ramalan sebenar, anda mungkin telah memikirkan banyak kaedah: jika anda bercadang untuk mengklasifikasikan imej, maka anda mungkin memilih rangkaian saraf konvolusi jika anda meramalkan siri masa atau menganalisis teks, kemudian rangkaian LSTM; Boleh menjadi pilihan yang menjanjikan. Selalunya, keputusan tentang seni bina model yang betul sebahagian besarnya didorong oleh jenis data yang mengalir ke dalam model.
Hasilnya, mencari struktur data input yang betul (iaitu mentakrifkan lapisan input model) telah menjadi salah satu langkah paling kritikal dalam reka bentuk model. Saya biasanya menumpukan lebih banyak masa pembangunan untuk membentuk data input daripada apa-apa lagi. Untuk menjadi jelas, kita tidak perlu berurusan dengan struktur data mentah yang diberikan, cuma cari model yang sesuai. Keupayaan rangkaian saraf untuk mengendalikan kejuruteraan ciri dan pemilihan ciri secara dalaman ("pemodelan hujung ke hujung") tidak mengecualikan kami daripada mengoptimumkan struktur data input. Kita harus menyampaikan data sedemikian rupa sehingga model dapat memahaminya dengan baik dan membuat keputusan yang paling termaklum (iaitu, ramalan yang paling tepat). Faktor "rahsia" di sini ialah maklumat konteks. Iaitu, kita harus memperkayakan data mentah dengan konteks sebanyak mungkin.
Jadi, apakah yang saya maksudkan secara khusus dengan "konteks" di atas? Mari kita berikan satu contoh. Mary ialah seorang saintis data yang memulakan pekerjaan baharu membangunkan sistem ramalan jualan untuk sebuah syarikat runcit minuman. Ringkasnya, tugasnya ialah: memandangkan kedai tertentu dan produk tertentu (lemonade, jus oren, bir...), modelnya sepatutnya dapat meramalkan jualan masa depan produk ini di kedai tertentu. Ramalan akan digunakan untuk beribu-ribu produk berbeza yang ditawarkan oleh ratusan kedai berbeza. Setakat ini, sistem telah berfungsi dengan baik. Hari pertama Mary dihabiskan di bahagian jualan, di mana kerja-kerja ramalan telah pun dilakukan, walaupun secara manual oleh Peters, seorang akauntan jualan yang berpengalaman. Matlamatnya adalah untuk memahami atas dasar apa pakar domain menentukan permintaan masa depan untuk produk tertentu. Sebagai seorang saintis data yang baik, Mary menjangkakan bahawa pengalaman Peters selama bertahun-tahun akan sangat membantu dalam menentukan data yang mungkin lebih berharga kepada model itu. Untuk mengetahui, Mary bertanya kepada Peters dua soalan.
Soalan pertama: "Apakah data yang anda analisis untuk mengira berapa banyak botol air limau jenama tertentu yang akan kami jual di kedai kami di Berlin bulan depan? Bagaimanakah anda mentafsir data itu?" > Peters menjawab: "Lama kelamaan kami mengambil langkah pertama dalam menjual air limau di Berlin". Dia kemudian melukis graf berikut untuk menggambarkan strateginya:
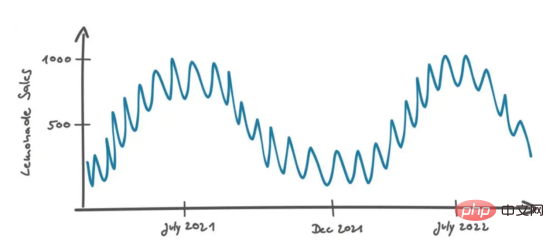
Peters meneruskan: “Apabila saya melihat corak peningkatan jualan yang berulang pada musim panas dan penurunan jualan pada musim sejuk, saya fikir kemungkinan besar perkara ini akan berlaku juga pada masa hadapan, jadi saya mendasarkan anggaran saya pada kemungkinan itu. "Kedengarannya munasabah.
Peters mentafsir data jualan dalam konteks temporal, di mana jarak dua titik data ditentukan oleh perbezaan masanya. Jika data tidak mengikut urutan kronologi, sukar untuk ditafsirkan. Contohnya, jika kita hanya melihat taburan jualan dalam histogram, konteks temporal akan hilang dan anggaran terbaik jualan masa hadapan kita ialah beberapa nilai agregat, seperti median semua nilai.
Konteks muncul apabila data diisih mengikut cara tertentu.
Sudah tentu anda harus menyuap model ramalan jualan anda dengan data jualan sejarah dalam susunan kronologi yang betul untuk mengekalkan konteks "percuma" daripada pangkalan data. Model pembelajaran mendalam adalah sangat berkuasa kerana ia sangat baik dalam mengintegrasikan maklumat kontekstual, serupa dengan otak kita (dalam kes ini, sudah tentu, otak Peters).
Pernahkah anda terfikir: mengapa pembelajaran mendalam sangat berkesan untuk pengelasan imej dan pengesanan objek imej? Kerana sudah terdapat banyak konteks "semula jadi" dalam imej biasa: imej pada asasnya adalah titik data keamatan cahaya, disusun mengikut dua dimensi latar belakang, iaitu jarak ruang dalam arah x dan jarak ruang dalam arah y. Dan filem sebagai bentuk animasi (jujukan masa imej) menambah masa sebagai dimensi kontekstual ketiga.
Oleh kerana konteks sangat berfaedah untuk ramalan, kami boleh meningkatkan prestasi model dengan menambahkan lebih banyak dimensi konteks - walaupun dimensi ini sudah disertakan dalam data asal. Kami mencapai ini melalui beberapa kaedah kejuruteraan data yang bijak, seperti yang diterangkan seterusnya.
Kita harus menyampaikan data dengan cara yang model dapat memahaminya dengan baik dan membuat keputusan yang paling termaklum. Saya biasanya menumpukan lebih banyak masa pembangunan untuk membentuk data input daripada apa-apa lagi.
Mari kita kembali kepada perbincangan Mary dan Peters. Mary tahu bahawa dalam kebanyakan kes, data sebenar tidak kelihatan sebaik carta di atas, jadi dia mengubah suai carta sedikit supaya kelihatan seperti ini:
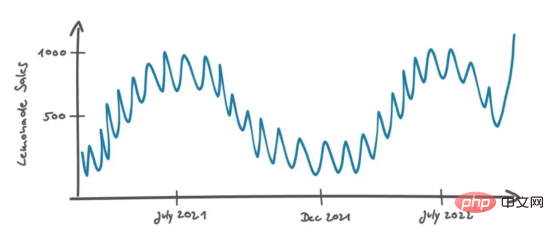
Soalan kedua yang diajukan oleh Mary ialah: “Bagaimana jika titik data jualan terakhir melebihi paras kebisingan biasa Ini mungkin senario sebenar Mungkin produk sedang menjalankan kempen pemasaran yang berjaya Lebih baik sekarang. Dalam kes ini, kesannya adalah tahan lama dan jualan pada masa hadapan akan kekal pada tahap tinggi yang sama atau mungkin ia hanya satu anomali kerana lawatan ke Berlin kanak-kanak membeli sebotol jenama limau ini Dalam kes ini, pertumbuhan jualan tidak stabil dan hanya boleh dianggap sebagai data bunyi Dalam kes ini, bagaimana anda melakukannya ?"
Anda boleh melihat Peters menggaru kepalanya sebelum menjawab: "Dalam kes ini, saya melihat jualan di kedai yang serupa di Berlin, contohnya kedai kami di Hamburg dan Munich ia juga terletak di bandar-bandar utama di Jerman. Saya tidak akan mempertimbangkan kedai di kawasan luar bandar kerana saya menjangkakan pelanggan yang berbeza dengan citarasa dan pilihan yang berbeza ”
Dia menambah keluk jualan kedai lain kepada dua senario yang mungkin. "Jika saya melihat jualan meningkat di Berlin, saya rasa ia adalah bunyi bising. Tetapi jika saya melihat jualan limau meningkat di Hamburg dan Munich juga, saya menjangkakan ia akan menjadi kesan penstabilan."
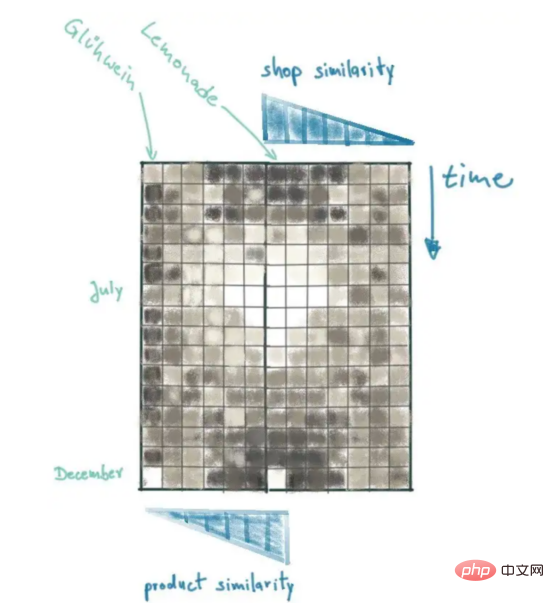
Jadi, dalam beberapa situasi yang agak sukar, Peters mempertimbangkan lebih banyak data untuk membuat keputusan yang lebih termaklum. Dia menambah dimensi data baharu dalam konteks kedai yang berbeza. Seperti yang dinyatakan di atas, konteks berlaku apabila data disusun mengikut cara tertentu. Untuk membuat konteks kedai, kita perlu menentukan ukuran jarak terlebih dahulu untuk memesan data dari kedai yang berbeza dengan sewajarnya. Sebagai contoh, Peters membezakan kedai berdasarkan saiz bandar di mana ia berada. 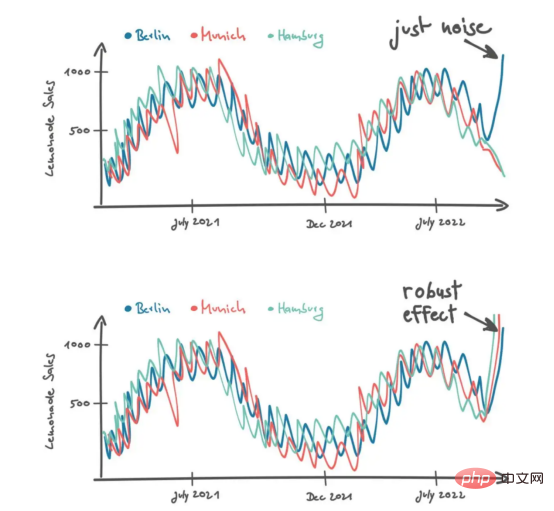
Matriks jualan dalam rajah memberikan ringkasan yang baik tentang jualan limau baru-baru ini, dan corak yang terhasil boleh dijelaskan secara visual. Lihat titik data di sudut kiri bawah matriks jualan: Ini ialah data jualan terbaharu untuk Berlin. Ambil perhatian bahawa titik terang itu berkemungkinan terkecuali, kerana kedai yang serupa (mis. Burger) tidak akan mengulangi peningkatan mendadak dalam jualan. Sebaliknya, kemuncak jualan pada bulan Julai diterbitkan semula oleh kedai yang serupa. 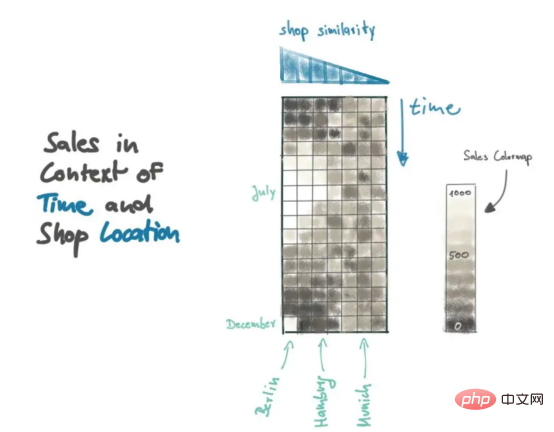
Sekarang, mari menterjemah pernyataan Peters ke dalam istilah matematik yang boleh dimodelkan berdasarkan saiz populasi bandar tempat produk itu berada. Apabila menambah dimensi konteks baharu, kita mesti mempertimbangkan metrik jarak yang betul dengan berhati-hati. Ia bergantung pada faktor yang mempengaruhi entiti yang ingin kita ramalkan. Faktor yang mempengaruhi bergantung sepenuhnya pada produk dan penunjuk jarak mesti diselaraskan dengan sewajarnya. Contohnya, jika anda melihat jualan bir di Jerman, anda akan mendapati bahawa pengguna berkemungkinan membeli produk daripada kilang bir tempatan (anda boleh menemui kira-kira 1,300 kilang bir yang berbeza di seluruh negara).
Orang dari Cologne biasanya minum Kursch, tetapi apabila anda memandu setengah jam ke utara ke wilayah Düsseldorf, orang ramai mengelak Kursch dan memilih bir Stronger Alt yang lebih gelap dan lebih maltier. Oleh itu, dalam kes jualan bir Jerman, memodelkan jarak kedai mengikut jarak geografi mungkin merupakan pilihan yang munasabah. Walau bagaimanapun, ini tidak berlaku untuk kategori produk lain (lemonade, jus oren, minuman sukan…).
Oleh kerana kami menambah dimensi konteks tambahan, kami mencipta set data kaya konteks di mana model ramalan yang berpotensi boleh mendapatkan profil jualan limau pada masa yang berbeza dan di kedai yang berbeza. Ini membolehkan model membuat keputusan termaklum tentang jualan masa depan di gedung Berlin dengan melihat sejarah jualan terkini dan melihat ke kiri dan kanan di kedai yang serupa di lokasi lain.
Dari sini kita boleh menambahkan lagi jenis produk sebagai dimensi kontekstual tambahan. Oleh itu, kami memperkayakan matriks jualan dengan data daripada produk lain, disusun mengikut persamaannya dengan air limau (sasaran ramalan kami). Sekali lagi, kita perlu mencari metrik persamaan yang baik. Adakah Coke lebih seperti limau berbanding jus oren? Pada data apakah kita boleh menentukan kedudukan persamaan?
Dalam kes kedai, kami mempunyai ukuran berterusan, iaitu populasi bandar. Sekarang kita berurusan dengan kategori produk. Apa yang ingin kami cari adalah produk yang mempunyai tingkah laku jualan yang serupa dengan air limau. Berbeza dengan air limau, kami boleh menjalankan analisis korelasi silang data jualan yang diselesaikan masa untuk semua produk. Dengan cara ini, kami memperoleh pekali korelasi Pearson untuk setiap produk, yang memberitahu kami betapa serupa corak jualan. Minuman ringan seperti Coke mungkin mempunyai corak jualan yang serupa dengan air limau, dengan jualan meningkat semasa musim panas. Produk lain akan berkelakuan berbeza sama sekali. Contohnya, Gühwein, wain hangat dan manis yang disajikan di pasar Krismas, mungkin mempunyai kemuncak jualan yang kukuh pada bulan Disember dan kemudian hampir tiada jualan sepanjang tahun ini.
【Nota Penterjemah】Penyelesaian masa: Nama fizik atau statistik. Perkataan lain yang biasa digunakan berkaitan dengannya ialah diagnosis penyelesaian masa, spektrum penyelesaian masa, dsb.
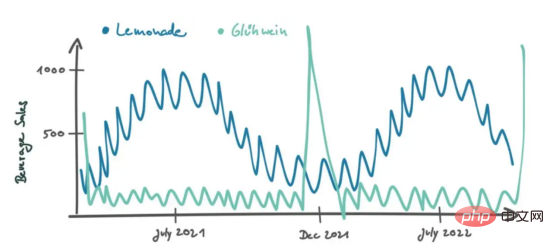
Analisis korelasi silang akan menunjukkan bahawa wain Glühwein mempunyai pekali Pearson yang lebih rendah (sebenarnya negatif), manakala Coke mempunyai pekali Pearson yang lebih tinggi .
Walaupun menambah dimensi ketiga pada matriks jualan, kami boleh memasukkan konteks produk dengan menyertai dimensi kedua dalam arah yang bertentangan. Ini meletakkan data jualan yang paling penting (jualan Lemonade Berlin) di tengah-tengah:
Sementara kami mempunyai struktur data yang sangat bermaklumat, setakat ini kami hanya mempunyai satu ciri: bilangan produk yang dijual untuk produk tertentu di kedai tertentu pada masa tertentu. Ini mungkin sudah cukup untuk membuat ramalan yang mantap dan tepat, tetapi kami juga boleh menambah maklumat berguna tambahan daripada sumber data lain.
Sebagai contoh, gelagat pembelian minuman berkemungkinan besar bergantung pada cuaca. Sebagai contoh, semasa musim panas yang sangat panas, permintaan untuk air limau mungkin meningkat. Kami boleh menyediakan data cuaca (seperti suhu udara) sebagai lapisan kedua matriks. Data cuaca akan dipesan dalam konteks yang sama (lokasi kedai dan produk) seperti data jualan. Untuk produk yang berbeza, kami akan mendapat data suhu udara yang sama. Walau bagaimanapun, untuk masa dan lokasi kedai yang berbeza, kami akan melihat bahawa terdapat perbezaan, yang mungkin memberikan maklumat berguna untuk data tersebut.

Dengan cara ini, kami mempunyai matriks tiga dimensi yang selanjutnya mengandungi data jualan dan suhu. Harap maklum bahawa kami tidak menambah dimensi kontekstual tambahan dengan memasukkan data suhu. Seperti yang saya nyatakan sebelum ini, konteks datang apabila data diisih mengikut cara tertentu. Untuk konteks data yang kami tetapkan, kami mengisih data berdasarkan masa, persamaan produk dan persamaan kedai. Walau bagaimanapun, susunan ciri (dalam kes kami, sepanjang dimensi ketiga matriks) adalah tidak relevan. Malah, struktur data kami adalah bersamaan dengan imej warna RGB. Dalam imej RGB, kita mempunyai dua dimensi konteks (dimensi ruang x dan y) dan tiga lapisan warna (merah, hijau, biru). Untuk tafsiran imej yang betul, susunan saluran warna adalah sewenang-wenangnya. Sebaik sahaja anda mentakrifkannya, anda perlu menyimpannya dengan teratur. Tetapi untuk data yang disusun dalam konteks tertentu, kami tidak mempunyai metrik jarak.
Ringkasnya, struktur data input tidak boleh ditentukan terlebih dahulu. Oleh itu, sudah tiba masanya untuk kita memberikan permainan sepenuhnya kepada kreativiti dan intuisi kita untuk menemui petunjuk kebolehlaksanaan baharu.
Dengan menambahkan dua konteks tambahan dan lapisan ciri tambahan pada data jualan yang diselesaikan masa, kami memperoleh "saluran" 2D dengan dua gambar "saluran" (jualan dan suhu)" . Struktur data ini memberikan pandangan menyeluruh tentang jualan limau terbaharu di kedai tertentu, serta maklumat jualan dan cuaca daripada kedai yang serupa dan produk yang serupa. Struktur data yang kami cipta setakat ini sangat sesuai untuk tafsiran oleh rangkaian saraf dalam - contohnya, mengandungi berbilang lapisan konvolusi dan unit LSTM. Tetapi disebabkan keterbatasan ruang, saya tidak akan membincangkan cara mula mereka bentuk rangkaian saraf yang sesuai berdasarkan ini. Ini mungkin menjadi subjek artikel susulan saya.
Saya mahu anda boleh mempunyai idea anda sendiri, dan walaupun struktur data input anda mungkin tidak ditentukan sebelumnya, anda boleh (harus) menggunakan semua kreativiti dan gerak hati anda untuk memanjangkannya.
Secara amnya, struktur data kaya konteks tidak datang secara percuma. Untuk meramalkan pelbagai produk merentas semua kedai syarikat, kami perlu menjana beribu-ribu maklumat profil jualan yang kaya kontekstual (satu matriks untuk setiap campuran produk kedai). Anda perlu melakukan banyak kerja tambahan untuk mereka bentuk langkah pemprosesan dan penimbalan yang berkesan untuk memasukkan data ke dalam bentuk yang anda perlukan dan menyediakannya untuk latihan pantas rangkaian saraf dan kitaran ramalan seterusnya. Sudah tentu, dengan melakukan ini, anda mendapat model pembelajaran mendalam yang diingini yang boleh membuat ramalan yang tepat dan menjadi sangat teguh walaupun dengan data yang bising kerana ia kelihatan boleh "melanggar peraturan" dan membuat keputusan yang sangat bijak.
Zhu Xianzhong, editor komuniti 51CTO, blogger pakar 51CTO, pensyarah, guru komputer di sebuah universiti di Weifang dan seorang veteran dalam industri pengaturcaraan bebas.
Tajuk asal: Data yang Diperkaya Konteks: Kuasa Besar Rahsia untuk Model Pembelajaran Mendalam Anda, pengarang: Christoph Möhl
Atas ialah kandungan terperinci Senjata rahsia untuk meningkatkan kualiti ramalan model pembelajaran mendalam—data peka konteks. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Algoritma penggantian halaman
Algoritma penggantian halaman
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 apa itu cip isp
apa itu cip isp
 Komponen utama dhtml
Komponen utama dhtml
 Bagaimana untuk mendapatkan panjang tatasusunan dalam js
Bagaimana untuk mendapatkan panjang tatasusunan dalam js
 Bagaimana untuk menyediakan pelayan ftp
Bagaimana untuk menyediakan pelayan ftp
 Mana yang lebih sukar, bahasa c atau python?
Mana yang lebih sukar, bahasa c atau python?
 Bagaimana untuk menyelesaikan peranti usb yang tidak dikenali
Bagaimana untuk menyelesaikan peranti usb yang tidak dikenali








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



