
 pembangunan bahagian belakang
Tutorial Python
Gunakan Python untuk membuat alat ramalan harga rumah!
pembangunan bahagian belakang
Tutorial Python
Gunakan Python untuk membuat alat ramalan harga rumah!
Gunakan Python untuk membuat alat ramalan harga rumah!


Helo semua.
Ini ialah kes ramalan harga rumah, yang datang daripada tapak web Kaggle Ia merupakan soalan persaingan pertama untuk ramai pemula algoritma.
Kes ini mempunyai proses lengkap untuk menyelesaikan masalah pembelajaran mesin, termasuk EDA, kejuruteraan ciri, latihan model, gabungan model, dsb.
Proses ramalan harga rumah
Ikuti saya dan ketahui tentang kes ini.
Tiada perkataan panjang, tiada kod berlebihan, hanya penerangan ringkas.
1. EDA
Tujuan Analisis Data Penerokaan (EDA) adalah untuk memberi kita pemahaman penuh tentang set data. Pada langkah ini, kandungan yang kami terokai adalah seperti berikut:

Kandungan EDA
1.1 Set data input
train = pd.read_csv('./data/train.csv')
test = pd.read_csv('./data/test.csv')

Sampel latihan
latihan dan ujian ialah set latihan dan set ujian masing-masing, dengan 1460 sampel dan 80 ciri masing-masing.
Lajur Harga Jualan mewakili harga perumahan, yang ingin kami ramalkan.
1.2 Pengagihan harga rumah
Oleh kerana tugas kami adalah untuk meramal harga rumah, perkara teras yang perlu difokuskan dalam set data ialah pengagihan nilai lajur harga rumah (SalePrice).
sns.distplot(train['SalePrice']);
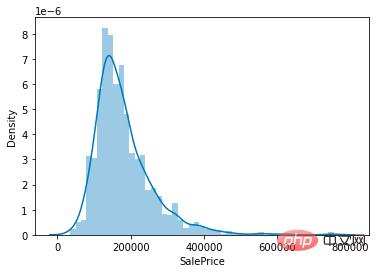
Taburan nilai harga rumah
Seperti yang dapat dilihat dari rajah, nilai puncak lajur SalePrice agak curam, dan puncak nilainya condong ke kiri.
Anda juga boleh memanggil terus fungsi skew() dan kurt() untuk mengira nilai condong dan kurtosis tertentu bagi SalePrice.
Untuk situasi di mana kecondongan dan kurtosis agak besar, adalah disyorkan untuk melicinkan lajur SalePrice menggunakan log().
1.3 Ciri yang berkaitan dengan harga rumah
Setelah memahami pengagihan SalePrice, kita boleh mengira korelasi antara 80 ciri dan SalePrice.
Fokus pada 10 ciri yang paling berkaitan dengan SalePrice.
# 计算列之间相关性
corrmat = train.corr()
# 取 top10
k = 10
cols = corrmat.nlargest(k, 'SalePrice')['SalePrice'].index
# 绘图
cm = np.corrcoef(train[cols].values.T)
sns.set(font_scale=1.25)
hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10}, yticklabels=cols.values, xticklabels=cols.values)
plt.show()
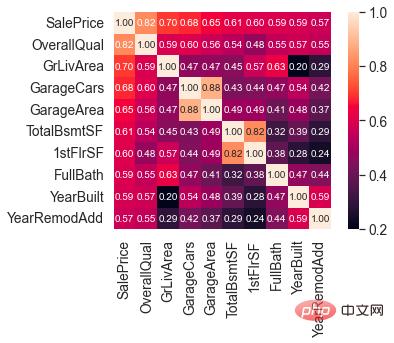
Ciri yang sangat berkorelasi dengan SalePrice
Kualiti Keseluruhan (bahan rumah dan hiasan), GrLivArea (ruang tamu di atas tanah), GarageCars (kapasiti garaj) Terdapat korelasi yang kukuh antara TotalBsmtSF (kawasan bawah tanah) dan SalePrice.
Ciri-ciri ini juga akan ditumpukan semasa melakukan kejuruteraan ciri nanti.
1.4 Hapuskan sampel terpencil
Memandangkan saiz sampel set data adalah sangat kecil, outlier tidak kondusif untuk latihan model kami yang seterusnya.
Jadi adalah perlu untuk mengira outlier bagi setiap ciri berangka dan menghapuskan sampel dengan outlier terbanyak.
# 获取数值型特征 numeric_features = train.dtypes[train.dtypes != 'object'].index # 计算每个特征的离群样本 for feature in numeric_features: outs = detect_outliers(train[feature], train['SalePrice'],top=5, plot=False) all_outliers.extend(outs) # 输出离群次数最多的样本 print(Counter(all_outliers).most_common()) # 剔除离群样本 train = train.drop(train.index[outliers])
detect_outliers() ialah fungsi tersuai yang menggunakan algoritma LocalOutlierFactor pustaka sklearn untuk mengira outlier.
Pada ketika ini, EDA sudah lengkap. Akhir sekali, set latihan dan set ujian digabungkan untuk melaksanakan kejuruteraan ciri berikut.
y = train.SalePrice.reset_index(drop=True) train_features = train.drop(['SalePrice'], axis=1) test_features = test features = pd.concat([train_features, test_features]).reset_index(drop=True)
Ciri menggabungkan ciri set latihan dan set ujian, dan merupakan data yang akan kami proses di bawah.
2. Kejuruteraan Ciri
Kejuruteraan Ciri
2.1 Jenis ciri pembetulan
MSSubClass (jenis rumah), YrSold (Tahun jualan) dan MoSold (Bulan jualan) ialah ciri kategori, tetapi ia diwakili oleh nombor dan ia perlu ditukar kepada ciri teks.
features['MSSubClass'] = features['MSSubClass'].apply(str) features['YrSold'] = features['YrSold'].astype(str) features['MoSold'] = features['MoSold'].astype(str)
2.2 Mengisi nilai yang hilang dalam ciri
Tiada piawaian bersatu untuk mengisi nilai yang hilang Adalah perlu untuk memutuskan cara mengisi berdasarkan ciri yang berbeza.
# Functional:文档提供了典型值 Typ
features['Functional'] = features['Functional'].fillna('Typ') #Typ 是典型值
# 分组填充需要按照相似的特征分组,取众数或中位数
# MSZoning(房屋区域)按照 MSSubClass(房屋)类型分组填充众数
features['MSZoning'] = features.groupby('MSSubClass')['MSZoning'].transform(lambda x: x.fillna(x.mode()[0]))
#LotFrontage(到接到举例)按Neighborhood分组填充中位数
features['LotFrontage'] = features.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.median()))
# 车库相关的数值型特征,空代表无,使用0填充空值。
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
features[col] = features[col].fillna(0)
2.3 Pembetulan Skewness
Sama seperti meneroka lajur SalePrice, ciri dengan kecondongan tinggi dilicinkan.
# skew()方法,计算特征的偏度(skewness)。 skew_features = features[numeric_features].apply(lambda x: skew(x)).sort_values(ascending=False) # 取偏度大于 0.15 的特征 high_skew = skew_features[skew_features > 0.15] skew_index = high_skew.index # 处理高偏度特征,将其转化为正态分布,也可以使用简单的log变换 for i in skew_index: features[i] = boxcox1p(features[i], boxcox_normmax(features[i] + 1))
2.4 Pemadaman dan penambahan ciri
Ciri yang hampir kesemua nilai tiada atau mempunyai nisbah nilai tunggal yang tinggi (99.94%) boleh dipadamkan terus.
features = features.drop(['Utilities', 'Street', 'PoolQC',], axis=1)
Pada masa yang sama, berbilang ciri boleh digabungkan untuk menjana ciri baharu.
Kadangkala model sukar untuk mempelajari hubungan antara ciri-ciri gabungan manual boleh mengurangkan kesukaran pembelajaran model dan meningkatkan kesannya.
# 将原施工日期和改造日期融合 features['YrBltAndRemod']=features['YearBuilt']+features['YearRemodAdd'] # 将地下室面积、1楼、2楼面积融合 features['TotalSF']=features['TotalBsmtSF'] + features['1stFlrSF'] + features['2ndFlrSF']
Dapat didapati bahawa ciri yang kami gabungkan adalah semua ciri yang sangat berkaitan dengan SalePrice.
Akhirnya permudahkan ciri dan lakukan pemprosesan 01 pada ciri dengan pengedaran membosankan (contohnya: 99 daripada 100 data mempunyai nilai 0.9, dan satu lagi mempunyai nilai 0.1).
features['haspool'] = features['PoolArea'].apply(lambda x: 1 if x > 0 else 0) features['has2ndfloor'] = features['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
2.6 生成最终训练数据
到这里特征工程就做完了, 我们需要从features中将训练集和测试集重新分离出来,构造最终的训练数据。
X = features.iloc[:len(y), :] X_sub = features.iloc[len(y):, :] X = np.array(X.copy()) y = np.array(y) X_sub = np.array(X_sub.copy())
三. 模型训练
因为SalePrice是数值型且是连续的,所以需要训练一个回归模型。
3.1 单一模型
首先以岭回归(Ridge) 为例,构造一个k折交叉验证模型。
from sklearn.linear_model import RidgeCV from sklearn.pipeline import make_pipeline from sklearn.model_selection import KFold kfolds = KFold(n_splits=10, shuffle=True, random_state=42) alphas_alt = [14.5, 14.6, 14.7, 14.8, 14.9, 15, 15.1, 15.2, 15.3, 15.4, 15.5] ridge = make_pipeline(RobustScaler(), RidgeCV(alphas=alphas_alt, cv=kfolds))
岭回归模型有一个超参数alpha,而RidgeCV的参数名是alphas,代表输入一个超参数alpha数组。在拟合模型时,会从alpha数组中选择表现较好某个取值。
由于现在只有一个模型,无法确定岭回归是不是最佳模型。所以我们可以找一些出场率高的模型多试试。
# lasso lasso = make_pipeline( RobustScaler(), LassoCV(max_iter=1e7, alphas=alphas2, random_state=42, cv=kfolds)) #elastic net elasticnet = make_pipeline( RobustScaler(), ElasticNetCV(max_iter=1e7, alphas=e_alphas, cv=kfolds, l1_ratio=e_l1ratio)) #svm svr = make_pipeline(RobustScaler(), SVR( C=20, epsilon=0.008, gamma=0.0003, )) #GradientBoosting(展开到一阶导数) gbr = GradientBoostingRegressor(...) #lightgbm lightgbm = LGBMRegressor(...) #xgboost(展开到二阶导数) xgboost = XGBRegressor(...)
有了多个模型,我们可以再定义一个得分函数,对模型评分。
#模型评分函数 def cv_rmse(model, X=X): rmse = np.sqrt(-cross_val_score(model, X, y, scoring="neg_mean_squared_error", cv=kfolds)) return (rmse)
以岭回归为例,计算模型得分。
score = cv_rmse(ridge)
print("Ridge score: {:.4f} ({:.4f})n".format(score.mean(), score.std()), datetime.now(), ) #0.1024
运行其他模型发现得分都差不多。
这时候我们可以任选一个模型,拟合,预测,提交训练结果。还是以岭回归为例
# 训练模型
ridge.fit(X, y)
# 模型预测
submission.iloc[:,1] = np.floor(np.expm1(ridge.predict(X_sub)))
# 输出测试结果
submission = pd.read_csv("./data/sample_submission.csv")
submission.to_csv("submission_single.csv", index=False)
submission_single.csv是岭回归预测的房价,我们可以把这个结果上传到 Kaggle 网站查看结果的得分和排名。
3.2 模型融合-stacking
有时候为了发挥多个模型的作用,我们会将多个模型融合,这种方式又被称为集成学习。
stacking 是一种常见的集成学习方法。简单来说,它会定义个元模型,其他模型的输出作为元模型的输入特征,元模型的输出将作为最终的预测结果。
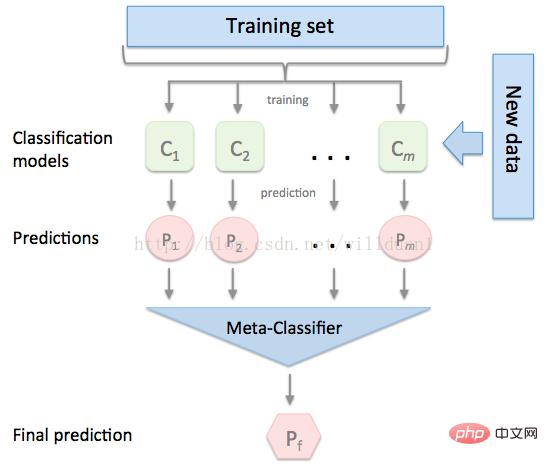
stacking
这里,我们用mlextend库中的StackingCVRegressor模块,对模型做stacking。
stack_gen = StackingCVRegressor( regressors=(ridge, lasso, elasticnet, gbr, xgboost, lightgbm), meta_regressor=xgboost, use_features_in_secondary=True)
训练、预测的过程与上面一样,这里不再赘述。
3.3 模型融合-线性融合
多模型线性融合的思想很简单,给每个模型分配一个权重(权重加和=1),最终的预测结果取各模型的加权平均值。
# 训练单个模型 ridge_model_full_data = ridge.fit(X, y) lasso_model_full_data = lasso.fit(X, y) elastic_model_full_data = elasticnet.fit(X, y) gbr_model_full_data = gbr.fit(X, y) xgb_model_full_data = xgboost.fit(X, y) lgb_model_full_data = lightgbm.fit(X, y) svr_model_full_data = svr.fit(X, y) models = [ ridge_model_full_data, lasso_model_full_data, elastic_model_full_data, gbr_model_full_data, xgb_model_full_data, lgb_model_full_data, svr_model_full_data, stack_gen_model ] # 分配模型权重 public_coefs = [0.1, 0.1, 0.1, 0.1, 0.15, 0.1, 0.1, 0.25] # 线性融合,取加权平均 def linear_blend_models_predict(data_x,models,coefs, bias): tmp=[model.predict(data_x) for model in models] tmp = [c*d for c,d in zip(coefs,tmp)] pres=np.array(tmp).swapaxes(0,1) pres=np.sum(pres,axis=1) return pres
到这里,房价预测的案例我们就讲解完了,大家可以自己运行一下,看看不同方式训练出来的模型效果。
回顾整个案例会发现,我们在数据预处理和特征工程上花费了很大心思,虽然机器学习问题模型原理比较难学,但实际过程中往往特征工程花费的心思最多。
Atas ialah kandungan terperinci Gunakan Python untuk membuat alat ramalan harga rumah!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Meme Coin Exchange Ranking Meme Coin Exchange Utama Top 10 tempat
Apr 22, 2025 am 09:57 AM
Meme Coin Exchange Ranking Meme Coin Exchange Utama Top 10 tempat
Apr 22, 2025 am 09:57 AM
Platform yang paling sesuai untuk duit syiling meme perdagangan termasuk: 1. Binance, yang terbesar di dunia, dengan kecairan yang tinggi dan yuran pengendalian yang rendah; 2. Okx, enjin perdagangan yang cekap, menyokong pelbagai syiling meme; 3. 4. Redim (Solana dex), kos rendah, digabungkan dengan buku pesanan serum; 5. Pancakeswap (BSC DEX), yuran transaksi yang rendah dan kelajuan cepat; 6. Orca (Solana dex), Pengoptimuman Pengalaman Pengguna; 7. Coinbase, keselamatan tinggi, sesuai untuk pemula; 8. Huobi, terkenal di Asia, pasangan perdagangan yang kaya; 9. Dexrabbit, pintar
 Apakah laman web perisian tontonan pasaran percuma? Kedudukan sepuluh perisian tontonan pasaran bebas teratas dalam bulatan mata wang
Apr 22, 2025 am 10:57 AM
Apakah laman web perisian tontonan pasaran percuma? Kedudukan sepuluh perisian tontonan pasaran bebas teratas dalam bulatan mata wang
Apr 22, 2025 am 10:57 AM
Tiga teratas sepuluh perisian tontonan pasaran bebas teratas dalam bulatan mata wang adalah OKX, Binance dan Gate.io. 1. OKX menyediakan antara muka mudah dan data masa nyata, menyokong pelbagai carta dan analisis pasaran. 2. Binance mempunyai fungsi yang kuat, data yang tepat, dan sesuai untuk semua jenis peniaga. 3. Gate.io terkenal dengan kestabilan dan komprehensifnya, dan sesuai untuk pelabur jangka panjang dan jangka pendek.
 Sepuluh cadangan platform percuma untuk data masa nyata mengenai pasaran bulatan mata wang dikeluarkan
Apr 22, 2025 am 08:12 AM
Sepuluh cadangan platform percuma untuk data masa nyata mengenai pasaran bulatan mata wang dikeluarkan
Apr 22, 2025 am 08:12 AM
Platform data cryptocurrency yang sesuai untuk pemula termasuk coinmarketcap dan sangkakala bukan kecil. 1. CoinMarketCap menyediakan harga masa nyata global, nilai pasaran, dan kedudukan volum perdagangan untuk keperluan analisis pemula dan asas. 2. Petikan bukan kecil menyediakan antara muka yang mesra Cina, sesuai untuk pengguna Cina untuk cepat menyaring projek berpotensi berisiko rendah.
 10 Teratas Aplikasi Mata Wang Maya Digital: Pertukaran mata wang digital teratas dalam Perdagangan Bulatan Mata Wang
Apr 22, 2025 pm 03:00 PM
10 Teratas Aplikasi Mata Wang Maya Digital: Pertukaran mata wang digital teratas dalam Perdagangan Bulatan Mata Wang
Apr 22, 2025 pm 03:00 PM
Sepuluh aplikasi mata wang maya digital teratas ialah: 1. Okx, 2. Binance, 3. Gate.io, 4. Coinbase, 5 Kraken, 6. Huobi, 7. Kucoin, 8. Pertukaran ini dipilih berdasarkan faktor -faktor seperti jumlah urus niaga, pengalaman pengguna dan keselamatan, dan semuanya menyediakan pelbagai perkhidmatan perdagangan mata wang digital dan pengalaman perdagangan yang cekap.
 Cadangan aplikasi pertukaran mata wang maya yang boleh dipercayai dan mudah digunakan Ranking terbaru sepuluh pertukaran dalam bulatan mata wang
Apr 22, 2025 pm 01:21 PM
Cadangan aplikasi pertukaran mata wang maya yang boleh dipercayai dan mudah digunakan Ranking terbaru sepuluh pertukaran dalam bulatan mata wang
Apr 22, 2025 pm 01:21 PM
Aplikasi pertukaran mata wang maya yang boleh dipercayai dan mudah digunakan ialah: 1. Binance, 2 Okx, 3. Gate.io, 4 Coinbase, 5. Kraken, 6. Huobi Global, 7 Bitfinex, 8. Kucoin, 9. Bittrex, 10. Platform ini dipilih sebagai yang terbaik untuk jumlah transaksi, pengalaman pengguna dan keselamatan mereka, dan semua tawaran pendaftaran, pengesahan, deposit, pengeluaran dan operasi transaksi.
 Apakah aplikasi perdagangan mata wang digital sesuai untuk pemula? Ketahui mengenai bulatan duit syiling dalam satu artikel
Apr 22, 2025 am 08:45 AM
Apakah aplikasi perdagangan mata wang digital sesuai untuk pemula? Ketahui mengenai bulatan duit syiling dalam satu artikel
Apr 22, 2025 am 08:45 AM
Apabila memilih platform perdagangan mata wang digital yang sesuai untuk pemula, anda perlu mempertimbangkan keselamatan, kemudahan penggunaan, sumber pendidikan dan ketelusan kos: 1. Keutamaan diberikan kepada platform yang menyediakan penyimpanan sejuk, pengesahan dua faktor dan insurans aset; 2. Aplikasi dengan antara muka yang mudah dan operasi yang jelas lebih sesuai untuk pemula; 3. Platform harus menyediakan alat pembelajaran seperti tutorial dan analisis pasaran; 4. Perhatikan kos tersembunyi seperti yuran transaksi dan yuran pengeluaran tunai.
 Disyorkan Top 10 untuk akses mudah ke aplikasi dagangan mata wang digital (kedudukan terkini dalam 25)
Apr 22, 2025 am 07:45 AM
Disyorkan Top 10 untuk akses mudah ke aplikasi dagangan mata wang digital (kedudukan terkini dalam 25)
Apr 22, 2025 am 07:45 AM
GATE.IO (Versi Global) Kelebihan teras adalah bahawa antara muka adalah minimalis, menyokong Cina, dan proses transaksi mata wang fiat adalah intuitif; Binance (versi mudah) kelebihan teras adalah bahawa jumlah dagangan dunia adalah yang pertama di dunia, dan model versi mudah hanya mengekalkan perdagangan tempat; OKX (Versi Hong Kong) Kelebihan teras adalah bahawa antara muka mudah, menyokong Kanton/Mandarin, dan mempunyai ambang yang rendah untuk perdagangan derivatif; Kelebihan teras Stesen Huobi Global (Hong Kong) adalah bahawa ia adalah pertukaran lama, melancarkan terminal perdagangan meta-universiti; Kucoin (Edisi Komuniti Cina) Kelebihan teras adalah bahawa ia menyokong 800 mata wang, dan antara muka mengamalkan interaksi WeChat; Kelebihan teras Kraken (Hong Kong) adalah bahawa ia adalah pertukaran lama Amerika, memegang lesen SVF Hong Kong, dan mempunyai antara muka yang mudah; Kelebihan teras Hashkey Exchange (Hong Kong) adalah pertukaran yang terkenal di Hong Kong, menyokong undang-undang
 Apakah platform perdagangan mata wang digital pada tahun 2025? Kedudukan terbaru dari sepuluh aplikasi mata wang digital teratas
Apr 22, 2025 pm 03:09 PM
Apakah platform perdagangan mata wang digital pada tahun 2025? Kedudukan terbaru dari sepuluh aplikasi mata wang digital teratas
Apr 22, 2025 pm 03:09 PM
Aplikasi yang disyorkan untuk platform tontonan mata wang maya yang teratas: 1. Okx, 2.
