

Algoritma pembelajaran ensemble mendalam untuk pengelasan imej retina

Penterjemah |. Zhu Xianzhong
Sun Shujuan

Gambar 1 : Muka depan projek Iluminado yang direka oleh pengarang asal sendiri
Pada tahun 2019, Pertubuhan Kesihatan Sedunia menganggarkan terdapat kira-kira 2.2 bilion orang cacat penglihatan di dunia, yang mana sekurang-kurangnya 1 bilion boleh dicegah atau masih mengalami masalah penglihatan. Apabila bercakap tentang penjagaan mata, dunia menghadapi banyak cabaran, termasuk ketidaksamaan dalam liputan dan kualiti perkhidmatan pencegahan, terapeutik dan pemulihan. Terdapat kekurangan kakitangan penjagaan mata terlatih dan perkhidmatan penjagaan mata kurang disepadukan ke dalam sistem kesihatan utama. Matlamat saya adalah untuk memberi inspirasi kepada tindakan untuk menangani cabaran ini bersama-sama. Projek yang dibentangkan dalam artikel ini adalah sebahagian daripada Iluminado, projek batu penjuru sains data semasa saya.
Matlamat Reka Bentuk Projek Capstone
Tujuan mencipta projek ini adalah untuk melatih model ensemble pembelajaran mendalam, dan akhirnya menjadikannya sangat mudah untuk keluarga berpendapatan rendah untuk melaksanakan model ini tersedia, dan diagnosis risiko penyakit awal boleh dilakukan dengan kos yang rendah. Dengan menggunakan prosedur model saya, pakar oftalmologi boleh menentukan sama ada campur tangan segera diperlukan berdasarkan fotografi fundus retina.
Sumber set data projek
OphthAI menyediakan set data imej pelbagai penyakit fundus (Retinal Fundus Multi-Disease Image Dataset, dirujuk sebagai "RFMiD") tersedia secara umum set data imej, set data ini mengandungi 3200 imej fundus yang ditangkap oleh tiga kamera fundus berbeza dan dijelaskan oleh dua pakar retina kanan berdasarkan konsensus yang diputuskan.
Imej ini diekstrak daripada beribu-ribu pemeriksaan yang dilakukan sepanjang 2009-2010, dengan pilihan kedua-dua imej berkualiti tinggi dan agak sedikit kualiti rendah, menjadikan Set Data lebih mencabar.
Set data dibahagikan kepada tiga bahagian, termasuk set latihan (60% atau 1920 imej), set penilaian (20% atau 640 imej) dan set ujian (20% dan 640 foto ). Secara purata, perkadaran orang yang mempunyai penyakit dalam set latihan, set penilaian dan set ujian masing-masing adalah 60±7%, 20±7% dan 20±5%. Tujuan asas set data ini adalah untuk menangani pelbagai penyakit mata yang timbul dalam amalan klinikal harian, dengan sejumlah 45 kategori penyakit/patologi dikenal pasti. Label ini boleh didapati dalam tiga fail CSV, iaitu RFMiD_Training_Labels.CSV, RFMiD_Validation_Labels.SSV dan RFMiD_Testing_Labels.CSV.
Sumber imej
Imej di bawah diambil menggunakan alat yang dipanggil kamera fundus. Kamera fundus ialah mikroskop berkuasa rendah khusus yang dipasang pada kamera denyar yang digunakan untuk mengambil gambar fundus, lapisan retina di bahagian belakang mata.
Kini, kebanyakan kamera fundus adalah pegang tangan, jadi pesakit hanya perlu melihat terus ke dalam kanta. Antaranya, bahagian kilat yang terang menunjukkan bahawa imej fundus telah diambil.
Kamera pegang tangan mempunyai kelebihannya kerana ia boleh dibawa ke lokasi yang berbeza dan boleh menempatkan pesakit berkeperluan khas, seperti pengguna kerusi roda. Selain itu, mana-mana pekerja yang mempunyai latihan yang diperlukan boleh mengendalikan kamera, membolehkan pesakit diabetes yang kurang mendapat perkhidmatan membuat pemeriksaan tahunan mereka dengan cepat, selamat dan cekap.
Situasi fotografi sistem pengimejan retina fundus:
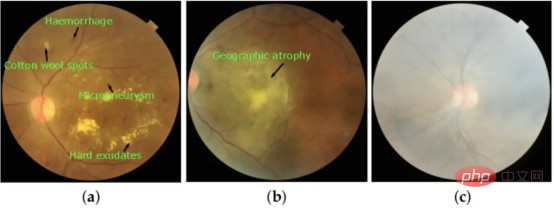
Rajah 2: Imej yang diambil berdasarkan ciri visual masing-masing : (a) retinopati diabetik (DR), (b) degenerasi makula berkaitan usia (ARMD) dan (c) jerebu sederhana (MH).
Di manakah diagnosis akhir dilakukan?
Proses saringan awal boleh dibantu dengan pembelajaran mendalam, tetapi diagnosis akhir dibuat oleh pakar oftalmologi menggunakan pemeriksaan slit lamp.
Proses ini juga dikenali sebagai diagnosis biomikroskopik, dan ia melibatkan pemeriksaan sel hidup. Doktor boleh melakukan pemeriksaan mikroskopik untuk menentukan sama ada terdapat sebarang kelainan pada mata pesakit.
Rajah 3: Ilustrasi pemeriksaan lampu celah
Aplikasi pembelajaran mendalam dalam pengelasan imej retina
Berbeza daripada algoritma pembelajaran mesin tradisional, neural Konvolusi yang mendalam rangkaian (CNN) boleh menggunakan model berbilang lapisan untuk mengekstrak dan mengelaskan ciri secara automatik daripada data mentah.
Baru-baru ini, komuniti akademik telah menerbitkan sejumlah besar artikel mengenai penggunaan rangkaian neural convolutional (CNN) untuk mengenal pasti pelbagai penyakit mata, seperti retinopati diabetik dan hasil yang tidak normal (AUROC) >0.9) glaukoma, dsb.
Metrik Data
Skor AUROC meringkaskan keluk ROC kepada nombor yang menerangkan prestasi model apabila mengendalikan berbilang ambang serentak. Perlu diingat bahawa skor AUROC 1 mewakili skor sempurna, manakala skor AUROC 0.5 sepadan dengan tekaan rawak.
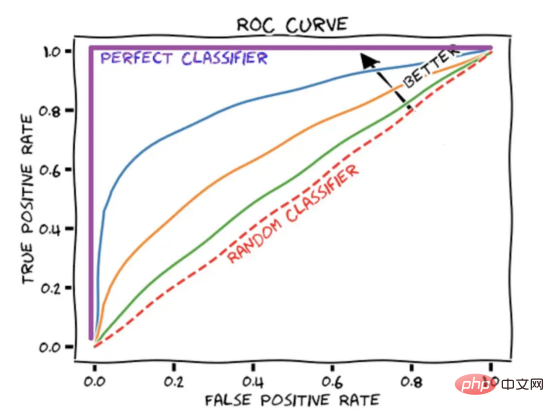
Rajah 4: Perwakilan skematik keluk ROC
Kaedah yang digunakan - fungsi kehilangan entropi silang
Entropi silang sering digunakan sebagai fungsi kehilangan dalam pembelajaran mesin. Entropi silang ialah metrik dalam bidang teori maklumat yang membina definisi entropi dan biasanya digunakan untuk mengira perbezaan antara dua taburan kebarangkalian, manakala entropi silang boleh dianggap sebagai mengira jumlah entropi antara dua taburan.
Entropi silang juga berkaitan dengan kehilangan logistik, yang dipanggil kerugian logaritma. Walaupun kedua-dua ukuran ini datang daripada sumber yang berbeza, apabila digunakan sebagai fungsi kerugian untuk model klasifikasi, kedua-dua kaedah mengira kuantiti yang sama dan boleh digunakan secara bergantian.
(Untuk butiran khusus, sila rujuk: https://machinelearningmastery.com/logistic-regression-with-maximum-likelihood-estimation/)
Apakah itu cross-entropy ?
Entropi silang ialah ukuran perbezaan antara dua taburan kebarangkalian untuk set pembolehubah rawak atau peristiwa tertentu. Anda mungkin ingat bahawa maklumat mengukur bilangan bit yang diperlukan untuk mengekod dan menghantar peristiwa. Peristiwa berkemungkinan rendah cenderung mengandungi lebih banyak maklumat, manakala peristiwa berkemungkinan tinggi mengandungi kurang maklumat.
Dalam teori maklumat, kami suka menerangkan "kejutan" sesuatu peristiwa. Semakin kecil kemungkinan sesuatu peristiwa itu berlaku, semakin mengejutkannya, yang bermaksud ia mengandungi lebih banyak maklumat.
- Peristiwa kebarangkalian rendah (mengejutkan): maklumat lanjut.
- Peristiwa kebarangkalian tinggi (tidak mengejutkan): kurang maklumat.
Memandangkan kebarangkalian kejadian P(x), maklumat h(x) boleh dikira untuk peristiwa x, seperti berikut:
h(x) = -log(P(x))
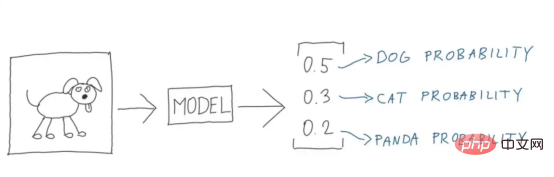
Rajah 4: Ilustrasi sempurna (Sumber imej: Vlastimil Martinek)
Entropi diperoleh daripada taburan kebarangkalian Bilangan bit diperlukan untuk menghantar acara yang dipilih secara rawak. Taburan condong mempunyai entropi yang lebih rendah, manakala taburan dengan kebarangkalian kejadian yang sama umumnya mempunyai entropi yang lebih tinggi.
Rajah 5: Ilustrasi sempurna nisbah sasaran kepada kebarangkalian yang diramalkan (Sumber imej: Vlastimil Martinek)
Taburan kebarangkalian yang condong mempunyai "kejutan" yang lebih sedikit dan seterusnya mempunyai entropi yang lebih rendah kerana kemungkinan peristiwa mendominasi. Secara relatifnya, taburan keseimbangan adalah lebih mengejutkan dan mempunyai entropi yang lebih tinggi kerana peristiwa itu berkemungkinan sama berlaku.
- Taburan kebarangkalian serong (tidak mengejutkan): entropi rendah.
- Taburan kebarangkalian keseimbangan (mengejutkan): entropi tinggi.
Entropi H(x) boleh dikira untuk pembolehubah rawak dengan set x keadaan diskret x dan kebarangkaliannya P(x), seperti yang ditunjukkan dalam rajah di bawah:
Rajah 6: Formula rentas entropi pelbagai peringkat (Sumber imej: Vlastimil Martinek)
Pengkelasan berbilang kategori - kami gunakan Entropi silang kategori ialah kes aplikasi khusus bagi entropi silang di mana sasaran menggunakan skema vektor pengekodan satu panas. (Pembaca yang berminat boleh merujuk artikel Vlastimil Martinek)

Rajah 7: Gambar rajah penguraian sempurna pengiraan kehilangan panda dan kucing (Sumber imej: Vlastimil Martinek)
Rajah 8: Penguraian sempurna bagi nilai kerugian 1 (Sumber imej: Vlastimil Martinek)
Rajah 9: Penguraian sempurna bagi nilai kehilangan Rajah 2 (Sumber imej: Vlastimil Martinek)
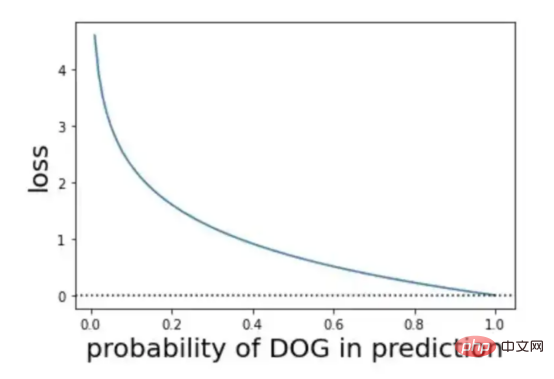
Rajah 9: Visual perwakilan tentang kebarangkalian dan kerugian (Sumber imej: Vlastimil Martinek)
Bagaimana pula dengan entropi silang binari?

Rajah 10: Ilustrasi formula rentas entropi kategori (Sumber imej: Vlastimil Martinek)
Dalam kami projek Kami memilih untuk menggunakan klasifikasi binari - skema silang entropi binari, iaitu, skema silang entropi dengan sasaran 0 atau 1. Jika kita menukar sasaran kepada vektor pengekodan panas masing-masing [0,1] atau [1,0] dan meramalkan, maka kita boleh menggunakan formula entropi silang untuk mengira.

Rajah 11: Ilustrasi formula pengiraan entropi silang binari (Sumber imej: Vlastimil Martinek)
Gunakan Kehilangan asimetri algoritma mengendalikan data tidak seimbang
Dalam persekitaran model berbilang label biasa, ciri set data mungkin mempunyai bilangan label positif dan negatif yang tidak seimbang. Pada ketika ini, kecenderungan set data untuk memihak kepada label negatif mempunyai pengaruh yang dominan pada proses pengoptimuman dan akhirnya membawa kepada kurang penekanan kecerunan label positif, sekali gus mengurangkan ketepatan keputusan ramalan.
Ini betul-betul situasi yang dihadapi oleh set data yang saya gunakan sekarang.
Algoritma kehilangan asimetri yang dibangunkan oleh BenBaruch et al (rujuk Rajah 12) digunakan dalam projek ini. Ini adalah kaedah untuk menyelesaikan klasifikasi berbilang label, tetapi terdapat juga yang serius masalah dalam kategori situasi pengagihan tidak seimbang.
Cara yang saya fikirkan ialah mengurangkan berat bahagian label negatif dengan mengubah suai komponen positif dan negatif entropi silang secara tidak simetri, dan akhirnya menyerlahkan positif yang dinyatakan di atas label yang lebih sukar diproses.
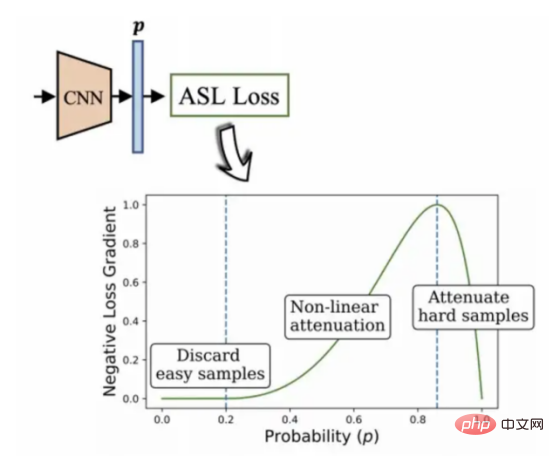
Rajah 12: Algoritma pengelasan berbilang label asimetri (2020, pengarang: Ben-Baruch et al.)
Untuk Diuji seni bina
Untuk meringkaskan, projek ini menggunakan seni bina yang ditunjukkan dalam rajah:
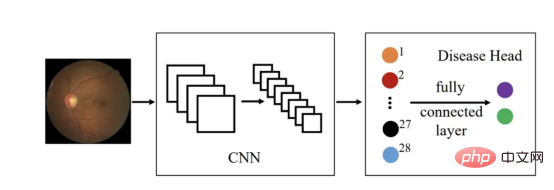
Rajah 13 (Sumber gambar: Sixu)
Algoritma utama yang digunakan dalam seni bina di atas terutamanya termasuk:
- DenseNet-121
- InceptionV3
- >Selain itu, kandungan berkaitan algoritma yang dinyatakan di atas pasti akan dikemas kini selepas saya menyiapkan projek Capstone artikel ini! Pembaca yang berminat sila nantikan!
- Pengenalan penterjemah Zhu Xianzhong, editor komuniti 51CTO, blogger pakar 51CTO, pensyarah, guru komputer di sebuah universiti di Weifang dan seorang veteran dalam industri pengaturcaraan bebas.
Pembelajaran Ensemble Mendalam untuk Klasifikasi Imej Retina (CNN)
, oleh Cathy KamAtas ialah kandungan terperinci Algoritma pembelajaran ensemble mendalam untuk pengelasan imej retina. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Kaedah dan langkah untuk menggunakan BERT untuk analisis sentimen dalam Python
Jan 22, 2024 pm 04:24 PM
Kaedah dan langkah untuk menggunakan BERT untuk analisis sentimen dalam Python
Jan 22, 2024 pm 04:24 PM
BERT ialah model bahasa pembelajaran mendalam pra-latihan yang dicadangkan oleh Google pada 2018. Nama penuh ialah BidirectionalEncoderRepresentationsfromTransformers, yang berdasarkan seni bina Transformer dan mempunyai ciri pengekodan dwiarah. Berbanding dengan model pengekodan sehala tradisional, BERT boleh mempertimbangkan maklumat kontekstual pada masa yang sama semasa memproses teks, jadi ia berfungsi dengan baik dalam tugas pemprosesan bahasa semula jadi. Dwiarahnya membolehkan BERT memahami dengan lebih baik hubungan semantik dalam ayat, dengan itu meningkatkan keupayaan ekspresif model. Melalui kaedah pra-latihan dan penalaan halus, BERT boleh digunakan untuk pelbagai tugas pemprosesan bahasa semula jadi, seperti analisis sentimen, penamaan.
 Analisis fungsi pengaktifan AI yang biasa digunakan: amalan pembelajaran mendalam Sigmoid, Tanh, ReLU dan Softmax
Dec 28, 2023 pm 11:35 PM
Analisis fungsi pengaktifan AI yang biasa digunakan: amalan pembelajaran mendalam Sigmoid, Tanh, ReLU dan Softmax
Dec 28, 2023 pm 11:35 PM
Fungsi pengaktifan memainkan peranan penting dalam pembelajaran mendalam Ia boleh memperkenalkan ciri tak linear ke dalam rangkaian saraf, membolehkan rangkaian belajar dengan lebih baik dan mensimulasikan hubungan input-output yang kompleks. Pemilihan dan penggunaan fungsi pengaktifan yang betul mempunyai kesan penting terhadap prestasi dan hasil latihan rangkaian saraf Artikel ini akan memperkenalkan empat fungsi pengaktifan yang biasa digunakan: Sigmoid, Tanh, ReLU dan Softmax, bermula dari pengenalan, senario penggunaan, kelebihan, kelemahan dan penyelesaian pengoptimuman Dimensi dibincangkan untuk memberi anda pemahaman yang menyeluruh tentang fungsi pengaktifan. 1. Fungsi Sigmoid Pengenalan kepada formula fungsi SIgmoid: Fungsi Sigmoid ialah fungsi tak linear yang biasa digunakan yang boleh memetakan sebarang nombor nyata antara 0 dan 1. Ia biasanya digunakan untuk menyatukan
 Di luar ORB-SLAM3! SL-SLAM: Adegan bertekstur lemah ringan, kegelisahan teruk dan lemah semuanya dikendalikan
May 30, 2024 am 09:35 AM
Di luar ORB-SLAM3! SL-SLAM: Adegan bertekstur lemah ringan, kegelisahan teruk dan lemah semuanya dikendalikan
May 30, 2024 am 09:35 AM
Ditulis sebelum ini, hari ini kita membincangkan bagaimana teknologi pembelajaran mendalam boleh meningkatkan prestasi SLAM berasaskan penglihatan (penyetempatan dan pemetaan serentak) dalam persekitaran yang kompleks. Dengan menggabungkan kaedah pengekstrakan ciri dalam dan pemadanan kedalaman, di sini kami memperkenalkan sistem SLAM visual hibrid serba boleh yang direka untuk meningkatkan penyesuaian dalam senario yang mencabar seperti keadaan cahaya malap, pencahayaan dinamik, kawasan bertekstur lemah dan seks yang teruk. Sistem kami menyokong berbilang mod, termasuk konfigurasi monokular, stereo, monokular-inersia dan stereo-inersia lanjutan. Selain itu, ia juga menganalisis cara menggabungkan SLAM visual dengan kaedah pembelajaran mendalam untuk memberi inspirasi kepada penyelidikan lain. Melalui percubaan yang meluas pada set data awam dan data sampel sendiri, kami menunjukkan keunggulan SL-SLAM dari segi ketepatan kedudukan dan keteguhan penjejakan.
 Pembenaman ruang terpendam: penjelasan dan demonstrasi
Jan 22, 2024 pm 05:30 PM
Pembenaman ruang terpendam: penjelasan dan demonstrasi
Jan 22, 2024 pm 05:30 PM
Pembenaman Ruang Terpendam (LatentSpaceEmbedding) ialah proses memetakan data berdimensi tinggi kepada ruang berdimensi rendah. Dalam bidang pembelajaran mesin dan pembelajaran mendalam, pembenaman ruang terpendam biasanya merupakan model rangkaian saraf yang memetakan data input berdimensi tinggi ke dalam set perwakilan vektor berdimensi rendah ini sering dipanggil "vektor terpendam" atau "terpendam pengekodan". Tujuan pembenaman ruang terpendam adalah untuk menangkap ciri penting dalam data dan mewakilinya ke dalam bentuk yang lebih ringkas dan mudah difahami. Melalui pembenaman ruang terpendam, kami boleh melakukan operasi seperti memvisualisasikan, mengelaskan dan mengelompokkan data dalam ruang dimensi rendah untuk memahami dan menggunakan data dengan lebih baik. Pembenaman ruang terpendam mempunyai aplikasi yang luas dalam banyak bidang, seperti penjanaan imej, pengekstrakan ciri, pengurangan dimensi, dsb. Pembenaman ruang terpendam adalah yang utama
 Fahami dalam satu artikel: kaitan dan perbezaan antara AI, pembelajaran mesin dan pembelajaran mendalam
Mar 02, 2024 am 11:19 AM
Fahami dalam satu artikel: kaitan dan perbezaan antara AI, pembelajaran mesin dan pembelajaran mendalam
Mar 02, 2024 am 11:19 AM
Dalam gelombang perubahan teknologi yang pesat hari ini, Kecerdasan Buatan (AI), Pembelajaran Mesin (ML) dan Pembelajaran Dalam (DL) adalah seperti bintang terang, menerajui gelombang baharu teknologi maklumat. Ketiga-tiga perkataan ini sering muncul dalam pelbagai perbincangan dan aplikasi praktikal yang canggih, tetapi bagi kebanyakan peneroka yang baru dalam bidang ini, makna khusus dan hubungan dalaman mereka mungkin masih diselubungi misteri. Jadi mari kita lihat gambar ini dahulu. Dapat dilihat bahawa terdapat korelasi rapat dan hubungan progresif antara pembelajaran mendalam, pembelajaran mesin dan kecerdasan buatan. Pembelajaran mendalam ialah bidang khusus pembelajaran mesin dan pembelajaran mesin
 Super kuat! 10 algoritma pembelajaran mendalam teratas!
Mar 15, 2024 pm 03:46 PM
Super kuat! 10 algoritma pembelajaran mendalam teratas!
Mar 15, 2024 pm 03:46 PM
Hampir 20 tahun telah berlalu sejak konsep pembelajaran mendalam dicadangkan pada tahun 2006. Pembelajaran mendalam, sebagai revolusi dalam bidang kecerdasan buatan, telah melahirkan banyak algoritma yang berpengaruh. Jadi, pada pendapat anda, apakah 10 algoritma teratas untuk pembelajaran mendalam? Berikut adalah algoritma teratas untuk pembelajaran mendalam pada pendapat saya Mereka semua menduduki kedudukan penting dari segi inovasi, nilai aplikasi dan pengaruh. 1. Latar belakang rangkaian saraf dalam (DNN): Rangkaian saraf dalam (DNN), juga dipanggil perceptron berbilang lapisan, adalah algoritma pembelajaran mendalam yang paling biasa Apabila ia mula-mula dicipta, ia dipersoalkan kerana kesesakan kuasa pengkomputeran tahun, kuasa pengkomputeran, Kejayaan datang dengan letupan data. DNN ialah model rangkaian saraf yang mengandungi berbilang lapisan tersembunyi. Dalam model ini, setiap lapisan menghantar input ke lapisan seterusnya dan
 Daripada asas kepada amalan, semak sejarah pembangunan pengambilan vektor Elasticsearch
Oct 23, 2023 pm 05:17 PM
Daripada asas kepada amalan, semak sejarah pembangunan pengambilan vektor Elasticsearch
Oct 23, 2023 pm 05:17 PM
1. Pengenalan Pengambilan semula vektor telah menjadi komponen teras sistem carian dan pengesyoran moden. Ia membolehkan pemadanan pertanyaan dan pengesyoran yang cekap dengan menukar objek kompleks (seperti teks, imej atau bunyi) kepada vektor berangka dan melakukan carian persamaan dalam ruang berbilang dimensi. Daripada asas kepada amalan, semak semula sejarah pembangunan vektor retrieval_elasticsearch Elasticsearch Sebagai enjin carian sumber terbuka yang popular, pembangunan Elasticsearch dalam pengambilan vektor sentiasa menarik perhatian ramai. Artikel ini akan menyemak sejarah pembangunan pengambilan vektor Elasticsearch, memfokuskan pada ciri dan kemajuan setiap peringkat. Mengambil sejarah sebagai panduan, adalah mudah untuk semua orang mewujudkan rangkaian penuh pengambilan vektor Elasticsearch.
 Cara menggunakan model hibrid CNN dan Transformer untuk meningkatkan prestasi
Jan 24, 2024 am 10:33 AM
Cara menggunakan model hibrid CNN dan Transformer untuk meningkatkan prestasi
Jan 24, 2024 am 10:33 AM
Rangkaian Neural Konvolusi (CNN) dan Transformer ialah dua model pembelajaran mendalam berbeza yang telah menunjukkan prestasi cemerlang pada tugasan yang berbeza. CNN digunakan terutamanya untuk tugas penglihatan komputer seperti klasifikasi imej, pengesanan sasaran dan pembahagian imej. Ia mengekstrak ciri tempatan pada imej melalui operasi lilitan, dan melakukan pengurangan dimensi ciri dan invarian ruang melalui operasi pengumpulan. Sebaliknya, Transformer digunakan terutamanya untuk tugas pemprosesan bahasa semula jadi (NLP) seperti terjemahan mesin, klasifikasi teks dan pengecaman pertuturan. Ia menggunakan mekanisme perhatian kendiri untuk memodelkan kebergantungan dalam jujukan, mengelakkan pengiraan berjujukan dalam rangkaian saraf berulang tradisional. Walaupun kedua-dua model ini digunakan untuk tugasan yang berbeza, ia mempunyai persamaan dalam pemodelan jujukan, jadi
