

Penerokaan dan amalan pengoptimuman kedudukan kasar carian Meituan

Pengarang: Xiaojiang Suogui Li Xiang et al
Kedudukan kasar ialah pencarian dan promosi dalam industri modul penting sistem. Dalam penerokaan dan amalan mengoptimumkan kesan kedudukan kasar, pasukan kedudukan carian Meituan mengoptimumkan kedudukan kasar daripada dua aspek: pautan kedudukan halus dan pengoptimuman bersama kesan dan prestasi berdasarkan senario perniagaan sebenar, meningkatkan kesan kedudukan kasar.
1. Pengenalan
Seperti yang kita semua tahu, dalam carian, pengesyoran, pengiklanan dan bidang aplikasi industri berskala besar lain, untuk mengimbangi prestasi dan kesan, sistem kedudukan biasanya digunakan seni bina Cascade [1,2], seperti yang ditunjukkan dalam Rajah 1 di bawah. Mengambil sistem kedudukan carian Meituan sebagai contoh, keseluruhan kedudukan dibahagikan kepada peringkat pengisihan kasar, pengisihan halus, penyusunan semula dan peringkat pengisihan bercampur terletak di antara pengisihan semula dan pengisihan halus, dan ia perlu menapis item seratus peringkat; set daripada set item calon peringkat seribu Berikannya kepada lapisan mendayung yang halus.

Rajah 1 Corong Isih
Melihat modul kedudukan kasar dari perspektif pautan penuh Meituan kedudukan carian , pada masa ini terdapat beberapa cabaran dalam pengoptimuman lapisan pengisihan kasar:
- Pincang pemilihan sampel: Di bawah sistem pengisihan lata , Pengisihan kasar adalah jauh daripada pautan paparan hasil akhir, menghasilkan perbezaan yang besar antara ruang sampel latihan luar talian model pengisihan kasar dan ruang sampel yang akan diramalkan, dan terdapat kecenderungan pemilihan sampel yang serius.
- Gandingan pengisihan kasar dan halus: Pengisihan kasar adalah antara ingat dan pengisihan halus memerlukan lebih banyak pemerolehan dan penggunaan rantaian berikutnya .
- Kekangan prestasi: Calon yang ditetapkan untuk ramalan kedudukan kasar dalam talian jauh lebih tinggi daripada model penarafan halus Walau bagaimanapun, keseluruhan sistem carian sebenar mempunyai keperluan yang ketat pada prestasi, menyebabkan pengisihan Kasar perlu menumpukan pada prestasi ramalan.
Artikel ini akan menumpukan pada cabaran di atas untuk berkongsi penerokaan dan amalan yang berkaitan pengoptimuman lapisan ranking kasar carian Meituan Antaranya, kami meletakkan masalah bias pemilihan sampel bersama-sama dalam masalah hubungan kedudukan halus. Artikel ini terbahagi terutamanya kepada tiga bahagian: bahagian pertama akan memperkenalkan secara ringkas laluan evolusi lapisan kedudukan kasar kedudukan carian Meituan bahagian kedua memperkenalkan penerokaan dan amalan pengoptimuman kedudukan kasar yang berkaitan, yang pertama adalah menggunakan pengetahuan penyulingan dan pembelajaran perbandingan untuk membuat perkaitan yang baik antara pengisihan kasar dan pengisihan kasar untuk mengoptimumkan kesan pengisihan kasar Tugas kedua ialah mempertimbangkan prestasi pengisihan kasar dan pengoptimuman pengoptimuman pengisihan kasar Semua kerja berkaitan telah dalam talian sepenuhnya kesannya adalah penting; bahagian terakhir ialah ringkasan dan pandangan Saya harap kandungan ini berguna dan memberi inspirasi kepada semua orang.
2 Laluan evolusi ranking kasar
Evolusi teknologi ranking kasar Meituan Search dibahagikan kepada peringkat berikut:
- 2016: Pemberat linear berdasarkan maklumat seperti korelasi, kualiti, kadar penukaran, dll. Kaedah ini mudah tetapi mempunyai keupayaan ekspresi yang lemah bagi ciri. Lemah, pemberat ditentukan secara manual, dan terdapat banyak ruang untuk penambahbaikan dalam kesan pengisihan.
- 2017: Kedudukan ramalan mengikut arah menggunakan model LR ringkas berdasarkan pembelajaran mesin.
- 2018: Menggunakan model dua menara berdasarkan produk dalaman vektor, istilah pertanyaan, pengguna, ciri kontekstual dan pedagang dimasukkan ke Kedua-dua bahagian, selepas pengiraan rangkaian dalam, vektor perkataan pengguna & pertanyaan dan vektor pedagang masing-masing dijana, dan kemudian skor anggaran diperoleh melalui pengiraan produk dalaman untuk pengisihan. Kaedah ini boleh mengira dan menyimpan vektor pedagang terlebih dahulu, jadi ramalan dalam talian adalah pantas, tetapi keupayaan untuk menyeberang maklumat pada kedua-dua belah pihak adalah terhad.
- 2019: Untuk menyelesaikan masalah model menara berkembar tidak dapat memodelkan ciri silang dengan baik, keluaran kembar -model menara digunakan sebagai Ciri digabungkan dengan ciri silang lain melalui model pokok GBDT.
- 2020 hingga sekarang: Disebabkan peningkatan kuasa pengkomputeran, saya mula meneroka model kasar hujung ke hujung NN dan terus mengulang model NN .
Pada peringkat ini, model dua menara yang biasa digunakan dalam model susun atur kasar dalam industri, seperti Tencent [3] dan model NN interaktif, seperti Alibaba Baba[1,2]. Perkara berikut terutamanya memperkenalkan kerja pengoptimuman berkaitan Carian Meituan dalam proses menaik taraf kedudukan kasar kepada model NN, yang terutamanya merangkumi dua bahagian: pengoptimuman kesan kedudukan kasar dan pengoptimuman gabungan kesan & prestasi.
3. Amalan pengoptimuman kedudukan kasar
Dengan banyak kerja pengoptimuman kesan [5,6] yang dilaksanakan dalam model NN Kedudukan Halus Carian Meituan, kami juga mula meneroka pengoptimuman NN kedudukan kasar model . Memandangkan pengisihan kasar mempunyai kekangan prestasi yang ketat, ia tidak boleh digunakan untuk menggunakan semula secara langsung kerja pengoptimuman pengisihan halus kepada pengisihan kasar. Berikut akan memperkenalkan pengoptimuman kesan kaitan pengisihan halus dengan memindahkan keupayaan pengisihan pengisihan halus kepada pengisihan kasar, serta pengoptimuman tukar ganti bagi kesan dan prestasi carian automatik berdasarkan struktur rangkaian saraf.
3.1 Pengoptimuman kesan pautan pengisihan halus
Model pengisihan kasar dihadkan oleh kekangan prestasi pemarkahan, yang akan membawa kepada struktur model yang lebih mudah dan bilangan ciri yang lebih kecil daripada model pengisihan halus jauh lebih rendah daripada pengisihan halus, jadi kesan pengisihan adalah lebih buruk daripada pengisihan halus. Untuk mengimbangi kehilangan kesan yang disebabkan oleh struktur ringkas dan ciri yang lebih sedikit bagi model penarafan kasar, kami mencuba kaedah penyulingan pengetahuan [7] untuk memautkan kedudukan halus untuk mengoptimumkan kedudukan kasar.
Penyulingan pengetahuan ialah kaedah biasa dalam industri untuk memudahkan struktur model dan meminimumkan kehilangan kesan Ia mengamalkan paradigma Guru-Pelajar: model dengan struktur yang kompleks dan keupayaan pembelajaran yang kukuh digunakan sebagai model Guru Model dengan struktur yang agak mudah digunakan sebagai model Pelajar, dan model Guru digunakan untuk membantu latihan model Pelajar, seterusnya memindahkan "pengetahuan" model Guru kepada model Pelajar untuk menambah baik. kesan model Pelajar. Gambarajah skema penyulingan baris halus dan penyulingan baris kasar ditunjukkan dalam Rajah 2 di bawah Skim penyulingan dibahagikan kepada tiga jenis berikut: penyulingan hasil baris halus, penyulingan skor ramalan baris halus, dan penyulingan perwakilan ciri. Pengalaman praktikal skim penyulingan ini dalam kedudukan kasar carian Meituan akan diperkenalkan di bawah.

Rajah 2 Gambarajah skema penyulingan baris halus dan baris kasar
3.1.1 Senarai hasil penyulingan baris halus
Penyisihan kasar adalah pra-modul untuk penyortiran yang baik. tingkah laku ( klik , membuat pesanan, membayar ) sebagai sampel positif, dan mendedahkan item yang tidak berlaku sebagai sampel negatif, anda juga boleh memperkenalkan beberapa sampel positif dan negatif yang dibina melalui hasil pengisihan model pengisihan halus, yang boleh mengurangkan pengisihan kasar pada tahap tertentu Kecondongan pemilihan sampel model juga boleh memindahkan keupayaan pengisihan halus kepada pengisihan kasar. Berikut akan memperkenalkan pengalaman praktikal menggunakan hasil pengisihan halus untuk menyaring model pengisihan kasar dalam senario carian Meituan.
Strategi 1: Berdasarkan sampel positif dan negatif yang dilaporkan oleh pengguna, pilih secara rawak sebilangan kecil sampel yang tidak terdedah di bahagian bawah pengisihan halus untuk menambah pengisihan kasar sampel negatif, seperti yang ditunjukkan dalam Rajah 3. Perubahan ini mempunyai Recall@150 luar talian ( sila rujuk lampiran untuk penjelasan penunjuk) +5PP, dan CTR dalam talian +0.1%.

Rajah 3 Contoh negatif hasil pengisihan tambahan
Strategi 2 : Secara langsung melakukan pensampelan rawak dalam set yang disusun halus untuk mendapatkan sampel latihan Kedudukan yang disusun dengan halus digunakan sebagai label untuk membina pasangan untuk latihan, seperti yang ditunjukkan dalam Rajah 4 di bawah. Berbanding dengan strategi 1, kesan luar talian ialah Recall@150 +2PP, dan CTR dalam talian ialah +0.06%.

Rajah 4 Isih depan dan belakang untuk membentuk sampel pasangan
Strategi 3: Berdasarkan pemilihan set sampel strategi 2, label dibina dengan mengklasifikasikan kedudukan isihan halus, dan kemudian pasangan dibina mengikut label terperingkat untuk latihan. Berbanding dengan strategi 2, kesan luar talian ialah Recall@150 +3PP, dan CTR dalam talian ialah +0.1%.
3.1.2 Penyulingan Skor Ramalan Kedudukan Halus
Penyulingan sebelumnya menggunakan hasil pengisihan ialah cara kasar untuk menggunakan maklumat kedudukan yang baik Kami seterusnya menambah berdasarkan skor Ramalan ini penyulingan [8], adalah diharapkan bahawa output skor oleh model ranking kasar dan output taburan skor oleh model ranking halus akan sejajar yang mungkin, seperti yang ditunjukkan dalam Rajah 5 di bawah:

Rajah 5 Pembinaan skor ramalan kedudukan halus kerugian tambahan
Dari segi pelaksanaan khusus, kami menggunakan paradigma penyulingan dua peringkat untuk menyaring model klasifikasi kasar berdasarkan model pengelasan halus yang telah dilatih Kehilangan penyulingan menggunakan ralat kuasa dua minimum keluaran kasar model pengelasan dan keluaran model pengelasan halus , dan tambahkan parameter Lambda untuk mengawal kesan Kehilangan penyulingan pada Kehilangan akhir, seperti yang ditunjukkan dalam formula (1). Menggunakan kaedah penyulingan pecahan yang tepat, kesan luar talian ialah Recall@150 +5PP, dan kesan dalam talian ialah CTR +0.05%.
3.1.3 Penyulingan Perwakilan Ciri
Industri menggunakan penyulingan pengetahuan untuk membimbing pemodelan perwakilan kedudukan halus dan kasar, yang telah disahkan sebagai cara yang berkesan untuk meningkatkan prestasi model [7], walau bagaimanapun, secara langsung menggunakan kaedah tradisional untuk menyaring perwakilan mempunyai kelemahan berikut: Pertama, adalah mustahil untuk menyaring hubungan pengisihan antara pengisihan kasar dan pengisihan halus Seperti yang dinyatakan di atas, penyulingan hasil pengisihan dalam senario kami adalah di luar talian dan dalam talian. Kesannya ditambah baik ke atas semua perkara di atas; yang kedua ialah skim penyulingan pengetahuan tradisional yang menggunakan perbezaan KL sebagai ukuran perwakilan, yang merawat setiap dimensi perwakilan secara bebas dan tidak dapat menyaring maklumat yang sangat relevan dan berstruktur [9]. Walau bagaimanapun, di Amerika Syarikat, Dalam senario carian kumpulan, data adalah sangat berstruktur, jadi menggunakan strategi penyulingan pengetahuan tradisional untuk penyulingan perwakilan mungkin tidak dapat menangkap pengetahuan berstruktur ini dengan baik.
Kami menggunakan teknologi pembelajaran kontrastif untuk model ranking kasar, supaya model ranking kasar juga boleh menyaring hubungan tertib semasa menyuling perwakilan model ranking halus. Kami menggunakan 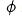 untuk mewakili model kasar dan
untuk mewakili model kasar dan 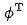 untuk mewakili model yang baik. Katakan q ialah permintaan dalam set data
untuk mewakili model yang baik. Katakan q ialah permintaan dalam set data 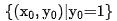 ialah contoh positif di bawah permintaan dan
ialah contoh positif di bawah permintaan dan 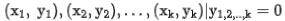 ialah contoh k negatif yang sepadan di bawah permintaan itu.
ialah contoh k negatif yang sepadan di bawah permintaan itu.
Kami memasukkan 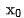 masing-masing ke dalam rangkaian kedudukan kasar dan halus, dan mendapatkan perwakilan sepadannya
masing-masing ke dalam rangkaian kedudukan kasar dan halus, dan mendapatkan perwakilan sepadannya  , dan Pada pada masa yang sama, kami memasukkan
, dan Pada pada masa yang sama, kami memasukkan 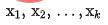 ke dalam rangkaian ranking kasar untuk mendapatkan perwakilan
ke dalam rangkaian ranking kasar untuk mendapatkan perwakilan 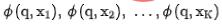 yang dikodkan oleh model ranking kasar. Untuk pemilihan pasangan contoh negatif untuk pembelajaran perbandingan, kami menggunakan penyelesaian dalam Strategi 3 untuk membahagikan susunan pengisihan halus ke dalam tong. dan pengisihan halus antara tong berbeza dianggap sebagai contoh positif. Pasangan perwakilan dianggap sebagai contoh negatif, dan kemudian InfoNCE Loss digunakan untuk mengoptimumkan matlamat ini:
yang dikodkan oleh model ranking kasar. Untuk pemilihan pasangan contoh negatif untuk pembelajaran perbandingan, kami menggunakan penyelesaian dalam Strategi 3 untuk membahagikan susunan pengisihan halus ke dalam tong. dan pengisihan halus antara tong berbeza dianggap sebagai contoh positif. Pasangan perwakilan dianggap sebagai contoh negatif, dan kemudian InfoNCE Loss digunakan untuk mengoptimumkan matlamat ini:
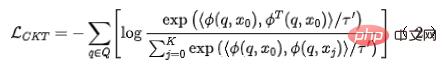
di mana mewakili hasil darab titik dua vektor, dan ialah pekali suhu. Dengan menganalisis sifat kehilangan InfoNCE, tidak sukar untuk mendapati bahawa formula di atas pada asasnya bersamaan dengan sempadan bawah yang memaksimumkan maklumat bersama antara perwakilan kasar dan perwakilan halus. Oleh itu, kaedah ini pada asasnya memaksimumkan ketekalan antara perwakilan halus dan perwakilan kasar pada tahap maklumat bersama, dan boleh menyaring pengetahuan berstruktur dengan lebih berkesan.

Rajah 6 Pemindahan maklumat peringkat halus pembelajaran kontrastif
Berdasarkan formula di atas (1) Pada selain itu, kehilangan penyulingan perwakilan pembelajaran kontrastif tambahan, kesan luar talian Recall@150 +14PP, CTR dalam talian +0.15%. Untuk butiran kerja berkaitan, sila rujuk kertas kami [10] (di bawah penyerahan).
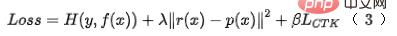
3.2 Pengoptimuman Bersama Kesan dan Prestasi
Seperti yang dinyatakan sebelum ini, calon kedudukan kasar yang ditetapkan untuk ramalan dalam talian adalah agak besar Memandangkan kekangan prestasi pautan penuh sistem, kedudukan kasar perlu dipertimbangkan kecekapan ramalan. Kerja yang dinyatakan di atas semuanya dioptimumkan berdasarkan paradigma DNN + penyulingan mudah, tetapi terdapat dua masalah:
- Pada masa ini, ia terhad oleh prestasi dalam talian dan hanya menggunakan Mudah ciri dihapuskan dan ciri silang yang lebih kaya tidak diperkenalkan, menyebabkan ruang untuk penambahbaikan lagi kesan model.
- Penyulingan dengan struktur model kasar tetap akan kehilangan kesan penyulingan, menghasilkan penyelesaian suboptimum [11].
Menurut pengalaman praktikal kami, memperkenalkan secara langsung ciri silang ke dalam lapisan kasar tidak dapat memenuhi keperluan kependaman dalam talian. Oleh itu, untuk menyelesaikan masalah di atas, kami telah meneroka dan melaksanakan penyelesaian pemodelan ranking kasar berdasarkan carian seni bina rangkaian saraf Penyelesaian ini secara serentak mengoptimumkan kesan dan prestasi model ranking kasar dan memilih gabungan ciri dan model terbaik yang memenuhi. keperluan kelewatan kedudukan kasar, rajah seni bina keseluruhan ditunjukkan dalam Rajah 7 di bawah:

Rajah 7 Ciri dan struktur model berdasarkan NAS
Pilih Di bawah kami akan memperkenalkan secara ringkas dua perkara teknikal utama pencarian seni bina rangkaian saraf (NAS) dan pengenalan pemodelan kecekapan:
- Carian seni bina rangkaian saraf: Seperti yang ditunjukkan dalam Rajah 7 di atas, kami menggunakan kaedah pemodelan berdasarkan ProxylessNAS [12]. Selain parameter rangkaian, keseluruhan latihan model menambah ciri Parameter topeng dan parameter seni bina rangkaian Parameter ini Ia boleh dibezakan dan dipelajari bersama dengan sasaran model. Dalam bahagian pemilihan ciri, kami memperkenalkan parameter Mask berdasarkan taburan Bernoulli kepada setiap ciri, lihat formula (4), di mana parameter θ taburan Bernoulli dikemas kini melalui perambatan belakang, dan akhirnya kepentingan setiap ciri diperoleh . Dalam bahagian pemilihan struktur, perwakilan Mixop lapisan L digunakan Setiap kumpulan Mixop termasuk N unit struktur rangkaian pilihan Dalam percubaan, kami menggunakan perceptron berbilang lapisan dengan bilangan unit saraf lapisan tersembunyi yang berbeza, di mana N= {1024 , 512, 256, 128, 64}, dan kami juga menambah unit struktur dengan nombor unit tersembunyi 0 untuk memilih rangkaian saraf dengan bilangan lapisan yang berbeza.

- Pemodelan Kecekapan: Untuk memodelkan metrik kecekapan dalam objektif model, kita perlu menggunakan objektif pembelajaran yang boleh dibezakan Untuk mewakili model memakan masa, memakan masa model kasar terutamanya dibahagikan kepada ciri memakan masa dan struktur model memakan masa.
Untuk penggunaan masa ciri, jangkaan kelewatan setiap ciri fi boleh dimodelkan seperti yang ditunjukkan dalam formula (5), di mana 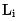 ialah kelewatan setiap ciri yang direkodkan oleh pelayan.
ialah kelewatan setiap ciri yang direkodkan oleh pelayan.
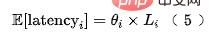
Dalam situasi sebenar, ciri boleh dibahagikan kepada dua kategori Satu bahagian ialah ciri penghantaran telus hulu, dan kelewatannya terutamanya datang dari huluan masa kelewatan penghantaran; jenis ciri lain datang daripada pemerolehan tempatan (membaca KV atau pengiraan), maka kelewatan setiap gabungan ciri boleh dimodelkan sebagai:
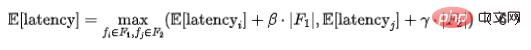
di mana 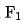 dan
dan 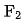 mewakili bilangan set ciri yang sepadan,
mewakili bilangan set ciri yang sepadan, 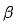 dan
dan 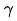 Memodelkan ciri sistem tarik serentak.
Memodelkan ciri sistem tarik serentak.
Untuk pemodelan kelewatan struktur model, sila rujuk bahagian kanan Rajah 7 di atas Memandangkan pelaksanaan Mixops ini dilakukan secara berurutan, kita boleh mengira kelewatan struktur model secara rekursif. . Apabila , penggunaan masa keseluruhan bahagian model boleh dinyatakan oleh lapisan terakhir Mixop Gambarajah skematik ditunjukkan dalam Rajah 8 di bawah:

Rajah 8 Sambungan model Gambarajah pengiraan masa
Sebelah kiri Rajah 8 ialah rangkaian kasar yang dilengkapi dengan pemilihan seni bina rangkaian, yang mewakili berat unit neural ke lapisan. Di sebelah kanan ialah gambarajah skema pengiraan kelewatan rangkaian. Oleh itu, penggunaan masa bagi keseluruhan bahagian ramalan model boleh dinyatakan oleh lapisan terakhir model, seperti yang ditunjukkan dalam formula (7):
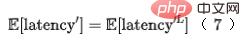
Akhir sekali, kami memperkenalkan indeks kecekapan ke dalam model, Kehilangan akhir latihan model ditunjukkan dalam formula berikut (8), di mana f mewakili rangkaian kedudukan halus, 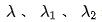 mewakili faktor keseimbangan, dan
mewakili faktor keseimbangan, dan 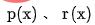 mewakili output pemarkahan bagi ranking kasar dan ranking halus masing-masing.
mewakili output pemarkahan bagi ranking kasar dan ranking halus masing-masing.
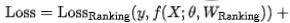

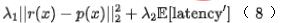
Secara bersama mengoptimumkan kesan dan prestasi ramalan model kedudukan kasar melalui pemodelan carian seni bina rangkaian saraf, Recall@150 +11PP luar talian, akhirnya dalam talian Apabila kelewatan atas tidak meningkat, penunjuk dalam talian CTR +0.12% untuk kerja terperinci, sila rujuk [13], yang telah diterima oleh KDD 2022;
4. Ringkasan
Bermula dari 2020, kami telah melaksanakan model MLP berlapis kasar melalui sejumlah besar pengoptimuman prestasi kejuruteraan akan diteruskan ke Berdasarkan model MLP, model penarafan kasar diulang secara berterusan untuk meningkatkan kesan penarafan kasar.
Pertama sekali, kami menggunakan skim penyulingan yang biasa digunakan dalam industri untuk menghubungkan kedudukan baik untuk mengoptimumkan kedudukan kasar, dan menjalankan tiga peringkat penyulingan hasil kedudukan halus, skor ramalan kedudukan halus penyulingan, dan penyulingan perwakilan ciri Sebilangan besar eksperimen telah dijalankan untuk menambah baik kesan model reka letak kasar tanpa meningkatkan kelewatan dalam talian. Kedua, memandangkan kaedah penyulingan tradisional tidak dapat mengendalikan maklumat berstruktur ciri dengan baik dalam senario pengisihan, kami membangunkan skema yang dibangunkan sendiri untuk memindahkan maklumat pengisihan halus kepada pengisihan kasar berdasarkan pembelajaran kontrastif.
Akhirnya, kami seterusnya mempertimbangkan bahawa pengoptimuman kasar pada asasnya adalah pertukaran antara kesan dan prestasi Kami menerima pakai idea pemodelan berbilang objektif untuk mengoptimumkan kesan dan prestasi secara serentak, dan melaksanakan seni bina rangkaian saraf secara automatik Teknologi carian digunakan untuk menyelesaikan masalah, membolehkan model memilih set ciri dan struktur model secara automatik dengan kecekapan dan kesan terbaik. Pada masa hadapan, kami akan terus mengulangi teknologi lapisan kasar dari aspek berikut:
- Pemodelan berbilang objektif baris kasar: Baris kasar semasa pada asasnya ialah model objektif tunggal Kami sedang cuba menggunakan pemodelan berbilang objektif lapisan baris halus ke barisan kasar.
- Peruntukan kuasa pengkomputeran dinamik seluruh sistem yang dipautkan dengan pengisihan kasar: Pengisihan kasar boleh mengawal kuasa pengkomputeran ingatan semula dan kuasa pengkomputeran pengisihan halus , keperluan model Kuasa pengkomputeran adalah berbeza, jadi peruntukan kuasa pengkomputeran dinamik boleh mengurangkan penggunaan kuasa pengkomputeran sistem tanpa mengurangkan kesan dalam talian Pada masa ini, kami telah mencapai kesan dalam talian tertentu dalam aspek ini.
5. Lampiran
Penunjuk luar talian pengisihan tradisional kebanyakannya berdasarkan penunjuk NDCG, MAP dan AUC Untuk pengisihan kasar, intipatinya adalah berat sebelah terhadap tugas mengingat semula yang menyasarkan pemilihan set, jadi penunjuk kedudukan tradisional tidak kondusif untuk mengukur kesan lelaran model kedudukan kasar. Kami merujuk kepada penunjuk Recall dalam [6] sebagai ukuran kesan luar talian pengisihan kasar, iaitu, menggunakan hasil pengisihan halus sebagai kebenaran asas untuk mengukur tahap penjajaran keputusan TopK bagi pengisihan kasar dan pengisihan halus. Takrifan khusus penunjuk Recall adalah seperti berikut:
Maksud fizikal formula ini adalah untuk mengukur pertindihan antara K atas isihan kasar dan K atas isihan halus ini penunjuk lebih konsisten dengan pemilihan set pengisihan kasar intipati.
6. Pengenalan Pengarang
Xiaojiang, Suogui, Li Xiang, Cao Yue, Peihao, Xiao Yao, Dayao, Chen Sheng, Yunsen, Li Qian dsb., semua daripada Platform Meituan/ Jabatan Algoritma Pengesyoran Carian.
Atas ialah kandungan terperinci Penerokaan dan amalan pengoptimuman kedudukan kasar carian Meituan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
1.3ms mengambil masa 1.3ms! Seni bina rangkaian neural mudah alih sumber terbuka terbaru Tsinghua RepViT
Mar 11, 2024 pm 12:07 PM
Alamat kertas: https://arxiv.org/abs/2307.09283 Alamat kod: https://github.com/THU-MIG/RepViTRepViT berprestasi baik dalam seni bina ViT mudah alih dan menunjukkan kelebihan yang ketara. Seterusnya, kami meneroka sumbangan kajian ini. Disebutkan dalam artikel bahawa ViT ringan biasanya berprestasi lebih baik daripada CNN ringan pada tugas visual, terutamanya disebabkan oleh modul perhatian diri berbilang kepala (MSHA) mereka yang membolehkan model mempelajari perwakilan global. Walau bagaimanapun, perbezaan seni bina antara ViT ringan dan CNN ringan belum dikaji sepenuhnya. Dalam kajian ini, penulis menyepadukan ViT ringan ke dalam yang berkesan
 Tafsiran mendalam: Mengapa Laravel lambat seperti siput?
Mar 07, 2024 am 09:54 AM
Tafsiran mendalam: Mengapa Laravel lambat seperti siput?
Mar 07, 2024 am 09:54 AM
Laravel ialah rangka kerja pembangunan PHP yang popular, tetapi kadangkala ia dikritik kerana lambat seperti siput. Apakah sebenarnya yang menyebabkan kelajuan Laravel tidak memuaskan? Artikel ini akan memberikan penjelasan yang mendalam tentang sebab mengapa Laravel lambat seperti siput dari pelbagai aspek, dan menggabungkannya dengan contoh kod khusus untuk membantu pembaca memperoleh pemahaman yang lebih mendalam tentang masalah ini. 1. Isu prestasi pertanyaan ORM Dalam Laravel, ORM (Pemetaan Perhubungan Objek) ialah fungsi yang sangat berkuasa yang membolehkan
 Perbincangan tentang strategi pengoptimuman gc Golang
Mar 06, 2024 pm 02:39 PM
Perbincangan tentang strategi pengoptimuman gc Golang
Mar 06, 2024 pm 02:39 PM
Kutipan sampah (GC) Golang sentiasa menjadi topik hangat di kalangan pemaju. Sebagai bahasa pengaturcaraan yang pantas, pengumpul sampah terbina dalam Golang boleh mengurus memori dengan sangat baik, tetapi apabila saiz program bertambah, beberapa masalah prestasi kadangkala berlaku. Artikel ini akan meneroka strategi pengoptimuman GC Golang dan menyediakan beberapa contoh kod khusus. Pengumpulan sampah dalam pemungut sampah Golang Golang adalah berdasarkan sapuan tanda serentak (concurrentmark-s
 Meneroka rangkaian Siam menggunakan kehilangan kontrastif untuk perbandingan persamaan imej
Apr 02, 2024 am 11:37 AM
Meneroka rangkaian Siam menggunakan kehilangan kontrastif untuk perbandingan persamaan imej
Apr 02, 2024 am 11:37 AM
Pengenalan Dalam bidang penglihatan komputer, mengukur kesamaan imej dengan tepat adalah tugas kritikal dengan pelbagai aplikasi praktikal. Daripada enjin carian imej kepada sistem pengecaman muka dan sistem pengesyoran berasaskan kandungan, keupayaan untuk membandingkan dan mencari imej serupa dengan cekap adalah penting. Rangkaian Siam digabungkan dengan kehilangan kontras menyediakan rangka kerja yang kuat untuk mempelajari persamaan imej dalam cara yang dipacu data. Dalam catatan blog ini, kami akan menyelami butiran rangkaian Siam, meneroka konsep kehilangan kontras dan meneroka cara kedua-dua komponen ini berfungsi bersama untuk mencipta model persamaan imej yang berkesan. Pertama, rangkaian Siam terdiri daripada dua subrangkaian yang sama yang berkongsi berat dan parameter yang sama. Setiap sub-rangkaian mengekod imej input ke dalam vektor ciri, yang
 Pengoptimuman program C++: teknik pengurangan kerumitan masa
Jun 01, 2024 am 11:19 AM
Pengoptimuman program C++: teknik pengurangan kerumitan masa
Jun 01, 2024 am 11:19 AM
Kerumitan masa mengukur masa pelaksanaan algoritma berbanding saiz input. Petua untuk mengurangkan kerumitan masa program C++ termasuk: memilih bekas yang sesuai (seperti vektor, senarai) untuk mengoptimumkan storan dan pengurusan data. Gunakan algoritma yang cekap seperti isihan pantas untuk mengurangkan masa pengiraan. Hapuskan berbilang operasi untuk mengurangkan pengiraan berganda. Gunakan cawangan bersyarat untuk mengelakkan pengiraan yang tidak perlu. Optimumkan carian linear dengan menggunakan algoritma yang lebih pantas seperti carian binari.
 Penyahkodan kesesakan prestasi Laravel: Teknik pengoptimuman didedahkan sepenuhnya!
Mar 06, 2024 pm 02:33 PM
Penyahkodan kesesakan prestasi Laravel: Teknik pengoptimuman didedahkan sepenuhnya!
Mar 06, 2024 pm 02:33 PM
Penyahkodan kesesakan prestasi Laravel: Teknik pengoptimuman didedahkan sepenuhnya! Laravel, sebagai rangka kerja PHP yang popular, menyediakan pembangun dengan fungsi yang kaya dan pengalaman pembangunan yang mudah. Walau bagaimanapun, apabila saiz projek meningkat dan bilangan lawatan meningkat, kami mungkin menghadapi cabaran kesesakan prestasi. Artikel ini akan menyelidiki teknik pengoptimuman prestasi Laravel untuk membantu pembangun menemui dan menyelesaikan masalah prestasi yang berpotensi. 1. Pengoptimuman pertanyaan pangkalan data menggunakan pemuatan tertunda Eloquent Apabila menggunakan Eloquent untuk menanya pangkalan data, elakkan
 Anda boleh memahami prinsip rangkaian saraf konvolusi walaupun dengan asas sifar! Sangat terperinci!
Jun 04, 2024 pm 08:19 PM
Anda boleh memahami prinsip rangkaian saraf konvolusi walaupun dengan asas sifar! Sangat terperinci!
Jun 04, 2024 pm 08:19 PM
Saya percaya bahawa rakan-rakan yang menyukai teknologi dan mempunyai minat yang kuat dalam AI seperti pengarang mesti biasa dengan rangkaian saraf konvolusional, dan pastinya telah keliru dengan nama "maju" sedemikian untuk masa yang lama. Penulis akan memasuki dunia rangkaian saraf konvolusi dari awal hari ini ~ kongsikannya dengan semua orang! Sebelum kita menyelami rangkaian saraf konvolusi, mari kita lihat cara imej berfungsi. Prinsip Imej Imej diwakili dalam komputer dengan nombor (0-255), dan setiap nombor mewakili kecerahan atau maklumat warna piksel dalam imej. Antaranya: Imej hitam dan putih: Setiap piksel hanya mempunyai satu nilai, dan nilai ini berbeza antara 0 (hitam) dan 255 (putih). Imej berwarna: Setiap piksel mengandungi tiga nilai, yang paling biasa ialah model RGB (Red-Green-Blue), iaitu merah, hijau dan biru
 Kesesakan prestasi Laravel didedahkan: penyelesaian pengoptimuman didedahkan!
Mar 07, 2024 pm 01:30 PM
Kesesakan prestasi Laravel didedahkan: penyelesaian pengoptimuman didedahkan!
Mar 07, 2024 pm 01:30 PM
Kesesakan prestasi Laravel didedahkan: penyelesaian pengoptimuman didedahkan! Dengan perkembangan teknologi Internet, pengoptimuman prestasi laman web dan aplikasi menjadi semakin penting. Sebagai rangka kerja PHP yang popular, Laravel mungkin menghadapi kesesakan prestasi semasa proses pembangunan. Artikel ini akan meneroka masalah prestasi yang mungkin dihadapi oleh aplikasi Laravel dan menyediakan beberapa penyelesaian pengoptimuman dan contoh kod khusus supaya pembangun dapat menyelesaikan masalah ini dengan lebih baik. 1. Pengoptimuman pertanyaan pangkalan data Pertanyaan pangkalan data ialah salah satu kesesakan prestasi biasa dalam aplikasi Web. wujud
