Penterjemah |. Zhu Xianzhong
Pengulas |. New York Times, 90% tenaga di pusat data dibazirkan kerana kebanyakan data yang dikumpul oleh syarikat tidak pernah dianalisis atau digunakan dalam sebarang bentuk. Lebih khusus lagi, ini dipanggil "Data Gelap."
"Data gelap" merujuk kepada data yang diperoleh melalui pelbagai operasi rangkaian komputer tetapi tidak digunakan dalam sebarang cara untuk memperoleh cerapan atau membuat keputusan. Keupayaan organisasi untuk mengumpul data mungkin melebihi daya pemprosesannya untuk menganalisisnya. Dalam sesetengah kes, organisasi mungkin tidak mengetahui bahawa data sedang dikumpul. IBM menganggarkan bahawa kira-kira 90% daripada data yang dijana oleh penderia dan penukaran analog-ke-digital tidak pernah digunakan. — Takrifan “Data Gelap” daripada Wikipedia 
Dari perspektif pembelajaran mesin, salah satu sebab utama data ini tidak berguna untuk melukis sebarang cerapan ialah kekurangan label. Ini menjadikan algoritma pembelajaran tanpa pengawasan sangat menarik untuk mengeksploitasi potensi data ini.
Rangkaian Adversarial Generatif
Pada 2014, Ian Goodfello et al mencadangkan kaedah baharu untuk menganggar model generatif melalui proses lawan. Ia melibatkan latihan dua model bebas secara serentak: model penjana yang cuba memodelkan pengedaran data, dan diskriminator yang cuba mengklasifikasikan input sebagai data latihan atau data palsu melalui penjana.
Kertas kerja ini menetapkan pencapaian yang sangat penting dalam bidang pembelajaran mesin moden dan membuka cara baharu untuk pembelajaran tanpa pengawasan. Pada tahun 2015, makalah GAN konvolusi yang mendalam yang diterbitkan oleh Radford et al berjaya menghasilkan imej 2D dengan menggunakan prinsip rangkaian konvolusi, dengan itu terus membina idea ini dalam kertas itu.
Melalui artikel ini, saya cuba menerangkan komponen utama yang dibincangkan dalam kertas di atas dan melaksanakannya menggunakan rangka kerja PyTorch.
Apakah aspek GAN yang menarik?
Untuk memahami kepentingan GAN atau DCGAN (Deep Convolutional Generative Adversarial Networks), mari kita fahami dahulu perkara yang menjadikannya begitu popular.
1. Memandangkan kebanyakan data sebenar tidak dilabelkan, sifat pembelajaran GAN yang tidak diselia menjadikannya sesuai untuk kes penggunaan sedemikian.
2. Penjana dan diskriminasi bertindak sebagai pengekstrak ciri yang sangat baik untuk kes penggunaan dengan data berlabel terhad, atau menjana data tambahan untuk meningkatkan latihan model kuadratik, kerana mereka boleh menjana sampel palsu sebaliknya Gunakan teknik penambahan.
3. GAN menyediakan alternatif kepada teknik kemungkinan maksimum. Proses pembelajaran lawan mereka dan fungsi kos bukan heuristik menjadikan mereka sangat menarik untuk pembelajaran pengukuhan.
4. Penyelidikan tentang GAN sangat menarik, dan hasilnya telah menyebabkan perdebatan meluas tentang kesan ML/DL. Sebagai contoh, Deepfake ialah aplikasi GAN yang menindih muka seseorang pada orang sasaran, yang sangat kontroversial kerana ia berpotensi digunakan untuk tujuan jahat.
5. Akhir sekali, bekerja dengan rangkaian seperti ini adalah hebat dan semua penyelidikan baharu dalam bidang ini sangat menarik.
Seni Bina Keseluruhan
Senibina Deep Convolutional GAN
Seperti yang kita bincangkan sebelum ini, kami akan berusaha melalui DCGAN, DCGAN Cuba untuk melaksanakan idea teras GAN, rangkaian konvolusi untuk menjana imej realistik.
DCGAN terdiri daripada dua model bebas: penjana (G) yang cuba memodelkan vektor hingar rawak sebagai input dan cuba mempelajari pengedaran data untuk menjana sampel palsu dan satu lagi diskriminator (D) yang mendapat data latihan (sampel sebenar) dan data yang dihasilkan (sampel palsu) dan cuba mengklasifikasikannya. Pertempuran antara dua model ini adalah apa yang kita panggil proses latihan permusuhan, di mana kerugian satu pihak adalah keuntungan pihak lain.
Penjana
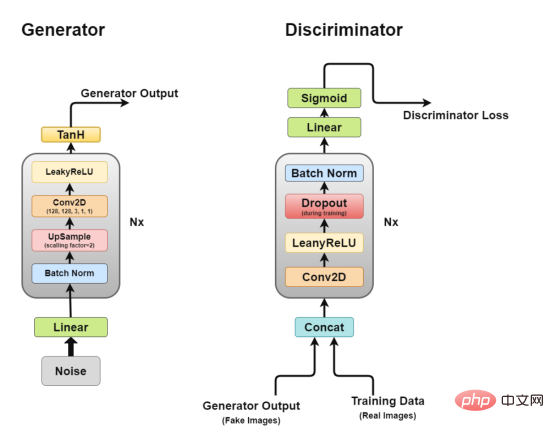
Rajah seni bina penjana
Penjana adalah bahagian yang paling kami minati kerana ia adalah yang menghasilkan imej palsu untuk cuba memperbodohkan si diskriminasi.
Sekarang, mari kita lihat seni bina penjana dengan lebih terperinci.
- Lapisan linear: Vektor hingar dimasukkan ke dalam lapisan bersambung sepenuhnya dan outputnya diubah menjadi tensor 4D.
- Lapisan normalisasi kelompok: Menstabilkan pembelajaran dengan menormalkan input kepada min sifar dan varians unit Ini mengelakkan masalah latihan seperti kecerunan yang hilang atau meletup dan membenarkan kecerunan mengalir melalui rangkaian.
- Lapisan upsampling: Menurut tafsiran saya tentang kertas itu, ia menyebut menggunakan upsampling dan kemudian menggunakan lapisan convolutional mudah di atasnya, dan bukannya menggunakan lapisan transpose convolutional untuk upsampling. Tetapi saya telah melihat sesetengah orang menggunakan transpose konvolusi, jadi strategi aplikasi khusus terpulang kepada anda.
- Lapisan Konvolusi 2D: Apabila kita meniup sampel matriks, kita melepasinya melalui lapisan konvolusi dengan langkah 1 dan menggunakan pelapik yang sama, membolehkan ia belajar daripada data sampel naik.
- Lapisan ReLU: Artikel ini menyebut penggunaan ReLU dan bukannya LeakyReLU sebagai penjana kerana ia membolehkan model tepu dengan cepat dan menutup ruang warna pengedaran latihan.
- Lapisan pengaktifan TanH: Artikel ini mencadangkan kami menggunakan fungsi pengaktifan TanH untuk mengira output penjana, tetapi tidak menghuraikan sebabnya. Jika kita terpaksa membuat tekaan, ini kerana sifat TanH membolehkan model menumpu lebih cepat.
Antaranya, lapisan 2 hingga lapisan 5 membentuk blok penjana teras, yang boleh diulang N kali untuk mendapatkan bentuk imej output yang dikehendaki.
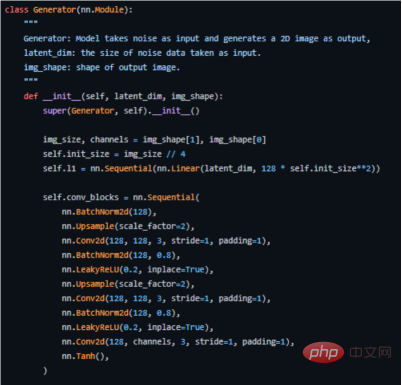
Berikut ialah kod utama cara kami melaksanakannya dalam PyTorch (untuk kod sumber lengkap, lihat alamat https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan .py).
Gunakan penjana rangka kerja PyTorch untuk melaksanakan kod utama
Diskriminator
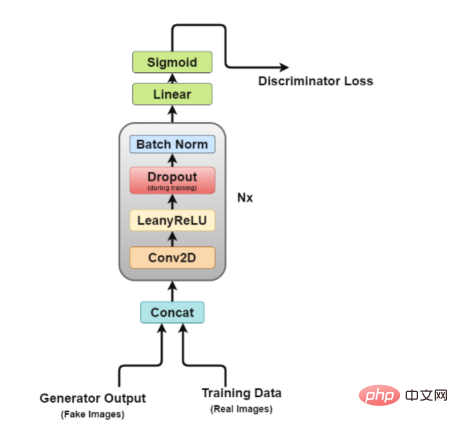
Rajah seni bina Diskriminator
Sekarang, mari kita lihat dengan lebih dekat seni bina diskriminasi.
Lapisan Concat: Lapisan ini menggabungkan imej palsu dan sebenar dalam satu kelompok untuk memberi suapan kepada diskriminator, tetapi ini juga boleh dilakukan secara berasingan, hanya untuk mendapatkan kehilangan penjana.
- Lapisan konvolusi: Kami menggunakan konvolusi langkah di sini, yang membolehkan kami menurunkan sampel imej dan mempelajari penapis dalam satu sesi latihan.
- Lapisan LeakyReLU: Seperti yang disebut dalam kertas kerja, didapati bahawa Leakyrelus sangat berguna untuk diskriminator kerana ia membolehkan latihan lebih mudah berbanding dengan fungsi output maksimum kertas GAN asal.
- Lapisan tercicir: digunakan untuk latihan sahaja, membantu mengelakkan pemasangan berlebihan. Model ini mempunyai kecenderungan untuk menghafal data imej sebenar, pada ketika itu latihan mungkin rosak kerana diskriminator tidak lagi boleh "diperdayakan" oleh penjana.
- Lapisan Normalisasi Kelompok: Kertas tersebut menyebut bahawa ia menggunakan normalisasi kelompok pada penghujung setiap blok diskriminator (kecuali yang pertama). Alasan yang dinyatakan dalam makalah ini ialah penggunaan normalisasi kelompok pada setiap lapisan boleh menyebabkan ayunan sampel dan ketidakstabilan model.
- Lapisan Linear: Lapisan bersambung sepenuhnya yang mengambil vektor bentuk semula daripada lapisan normalisasi kelompok 2D yang digunakan.
- Lapisan Pengaktifan Sigmoid: Memandangkan kita berurusan dengan klasifikasi binari keluaran diskriminator, pilihan logik lapisan Sigmoidd dibuat.
- Dalam seni bina ini, lapisan 2 hingga lapisan 5 membentuk blok teras diskriminator, dan pengiraan boleh diulang N kali untuk menjadikan model lebih kompleks bagi setiap data latihan.
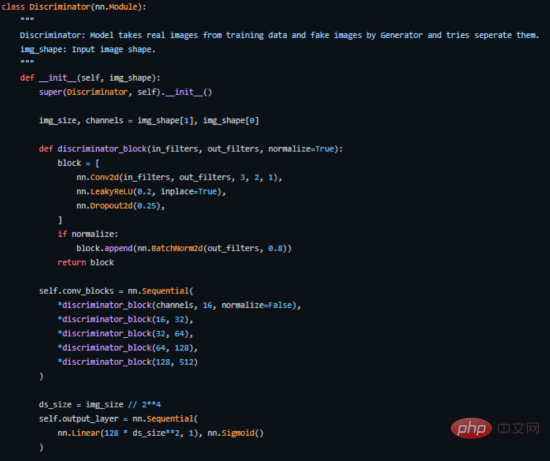
Berikut ialah cara kami melaksanakannya dalam PyTorch (kod sumber lengkap boleh didapati di https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py).
Bahagian kod utama diskriminator yang dilaksanakan dengan PyTorch
Latihan lawan
Kami melatih diskriminator (D) untuk memaksimumkan yang betul kebarangkalian bahawa label diberikan kepada sampel latihan dan sampel daripada penjana (G), yang boleh dilakukan dengan meminimumkan log(D(x)). Kami secara serentak melatih G untuk meminimumkan log(1 − D(G(z))), di mana z mewakili vektor hingar. Dalam erti kata lain, kedua-dua D dan G menggunakan fungsi nilai V (G, D) untuk memainkan permainan minimax dua pemain berikut:
Formula pengiraan fungsi kos lawan
Dalam persekitaran aplikasi praktikal, persamaan di atas mungkin tidak memberikan kecerunan yang mencukupi untuk G belajar dengan baik. Pada peringkat awal pembelajaran, apabila G lemah, D boleh menolak sampel dengan keyakinan yang tinggi kerana ia berbeza dengan ketara daripada data latihan. Dalam kes ini, fungsi log(1 − D(G(z))) mencapai ketepuan. Daripada melatih G untuk meminimumkan log(1 − D(G(z))), kami melatih G untuk memaksimumkan logD(G(z)). Fungsi objektif ini menjana mata tetap yang sama untuk G dan D dinamik, tetapi memberikan pengiraan kecerunan yang lebih kukuh pada awal pembelajaran. ——kertas arxiv
Ini boleh menjadi rumit kerana kami melatih dua model pada masa yang sama, dan GAN terkenal sukar untuk dilatih, seperti yang akan kita bincangkan kemudian. isu yang diketahui dipanggil mod runtuh.
Makalah mengesyorkan menggunakan pengoptimum Adam dengan kadar pembelajaran 0.0002 kadar pembelajaran yang rendah menunjukkan bahawa GAN cenderung untuk menyimpang dengan sangat cepat. Ia juga menggunakan momentum tertib pertama dan kedua dengan nilai 0.5 dan 0.999 untuk mempercepatkan lagi latihan. Model ini dimulakan kepada taburan wajaran biasa dengan min sifar dan sisihan piawai 0.02.
Berikut menunjukkan cara kami melaksanakan gelung latihan untuk ini (lihat https://github.com/akash-agni/ReadThePaper/blob/main/DCGAN/dcgan.py untuk kod sumber yang lengkap).
Gelung latihan DCGAN
Mod Runtuh
Sebaik-baiknya, kami mahu penjana menghasilkan pelbagai output. Sebagai contoh, jika ia menjana muka, ia harus menjana wajah baharu untuk setiap input rawak. Walau bagaimanapun, jika penjana menghasilkan output munasabah yang cukup baik untuk memperdayakan diskriminator, ia mungkin menghasilkan output yang sama berulang kali.
Akhirnya, penjana akan mengoptimumkan diskriminator tunggal secara berlebihan dan berputar di antara satu set kecil output, situasi yang dipanggil "mod runtuh".
Kaedah berikut boleh digunakan untuk membetulkan keadaan.
- Kehilangan Wasserstein: Fungsi kehilangan Wasserstein mengurangkan keruntuhan mod dengan membenarkan anda melatih diskriminator ke tahap optimum tanpa perlu risau tentang kecerunan yang hilang. Jika diskriminator tidak tersekat dalam minimum tempatan, ia akan belajar untuk menolak output stabil penjana. Oleh itu, penjana perlu mencuba perkara baru.
- GAN Terbuka: GAN Terbuka menggunakan fungsi kehilangan penjana yang mengandungi bukan sahaja klasifikasi diskriminator semasa, tetapi juga keluaran versi diskriminator masa hadapan. Oleh itu, penjana tidak boleh dioptimumkan secara berlebihan untuk satu diskriminator.
Apl
- Penukar Gaya: Apl Retouching Wajah sedang hangat digemari sekarang. Antaranya, penuaan wajah, muka menangis dan ubah bentuk wajah selebriti hanyalah beberapa aplikasi yang menjadi popular di media sosial.
- Permainan Video: Penjanaan tekstur objek 3D dan penjanaan pemandangan berasaskan imej hanyalah sebahagian daripada aplikasi yang membantu industri permainan video membangunkan permainan yang lebih besar dengan lebih pantas.
- Industri Filem: CGI (imej janaan komputer) telah menjadi sebahagian besar daripada filem model, dan dengan potensi yang dibawa oleh GAN, pembuat filem kini boleh bermimpi lebih besar daripada sebelumnya.
- Penjanaan Pertuturan: Sesetengah syarikat menggunakan GAN untuk menambah baik aplikasi teks ke pertuturan dengan menggunakannya untuk menjana pertuturan yang lebih realistik.
- Pemulihan Imej: Gunakan GAN untuk mengecilkan dan memulihkan imej yang rosak, mewarnakan imej sejarah dan memperbaik video lama dengan menjana bingkai yang hilang untuk meningkatkan kadar bingkai.
Kesimpulan
Ringkasnya, kertas kerja mengenai GAN dan DCGAN yang dinyatakan di atas dalam artikel ini hanyalah kertas mercu tanda kerana ia mempelopori bidang pembelajaran tanpa pengawasan Cara baharu. Kaedah latihan adversarial yang dicadangkan di dalamnya menyediakan kaedah baharu untuk model latihan yang menyerupai proses pembelajaran dunia sebenar. Jadi ia akan menjadi sangat menarik untuk melihat bagaimana bidang ini berkembang.
Akhir sekali, anda boleh menemui kod sumber pelaksanaan lengkap projek sampel dalam artikel ini pada repositori kod sumber GitHub saya.
Pengenalan penterjemah
Zhu Xianzhong, editor komuniti 51CTO, guru komputer di sebuah universiti di Weifang dan seorang veteran dalam industri pengaturcaraan bebas.
Tajuk asal: Melaksanakan Deep Convolutional GAN, pengarang: Akash Agnihotri
Atas ialah kandungan terperinci Rangkaian musuh generatif konvolusi yang mendalam dalam amalan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



 Bahagian kod utama diskriminator yang dilaksanakan dengan PyTorch
Bahagian kod utama diskriminator yang dilaksanakan dengan PyTorch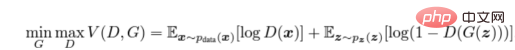 Formula pengiraan fungsi kos lawan
Formula pengiraan fungsi kos lawan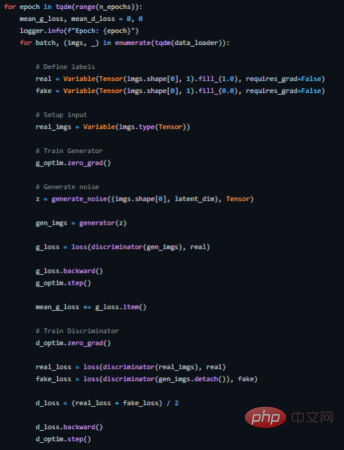
 Bagaimana untuk mengikat data dalam senarai lungsur
Bagaimana untuk mengikat data dalam senarai lungsur
 Bagaimana untuk mencipta folder baharu dalam webstorm
Bagaimana untuk mencipta folder baharu dalam webstorm
 Bagaimana untuk mengkonfigurasi pembolehubah persekitaran JDK
Bagaimana untuk mengkonfigurasi pembolehubah persekitaran JDK
 Bagaimana untuk memasukkan BIOS pada thinkpad
Bagaimana untuk memasukkan BIOS pada thinkpad
 Aplikasi platform dagangan Ouyi
Aplikasi platform dagangan Ouyi
 Apakah perpustakaan kecerdasan buatan python?
Apakah perpustakaan kecerdasan buatan python?
 Penyelesaian kepada kejayaan java dan kegagalan javac
Penyelesaian kepada kejayaan java dan kegagalan javac
 Cara menggunakan fungsi Print() dalam Python
Cara menggunakan fungsi Print() dalam Python
 Kelebihan memuat turun laman web rasmi Yiou Exchange App
Kelebihan memuat turun laman web rasmi Yiou Exchange App








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



