
 Peranti teknologi
AI
Reka bentuk dan pelaksanaan sistem pemantauan anomali pangkalan data berdasarkan algoritma AI
Peranti teknologi
AI
Reka bentuk dan pelaksanaan sistem pemantauan anomali pangkalan data berdasarkan algoritma AI
Reka bentuk dan pelaksanaan sistem pemantauan anomali pangkalan data berdasarkan algoritma AI

Pengarang: Cao Zhenweiyuan
Pasukan R&D platform pangkalan data Meituan menghadapi keperluan yang semakin mendesak untuk menemui anomali pangkalan data Untuk menemui, mencari dan menghentikan kerugian dengan lebih cepat dan bijak, kami telah membangunkan pangkalan data pada perkhidmatan pengesanan Anomali.
1. Latar Belakang
Pangkalan data digunakan secara meluas dalam senario perniagaan teras Meituan, dengan keperluan kestabilan yang tinggi dan toleransi yang sangat rendah untuk pengecualian. Oleh itu, penemuan anomali pangkalan data yang cepat, lokasi dan stop loss menjadi semakin penting. Sebagai tindak balas kepada masalah pemantauan yang tidak normal, kaedah penggera ambang tetap tradisional memerlukan pengalaman pakar untuk mengkonfigurasi peraturan, dan tidak boleh melaraskan ambang secara fleksibel dan dinamik mengikut senario perniagaan yang berbeza, yang boleh mengubah masalah kecil menjadi kegagalan besar dengan mudah.
Keupayaan penemuan anomali pangkalan data berasaskan AI boleh menjalankan 7*24 jam pemeriksaan penunjuk utama berdasarkan prestasi sejarah pangkalan data, dan boleh mengesan risiko dalam tunas anomali, Ia mendedahkan keabnormalan dan membantu kakitangan R&D dalam mengesan dan menghentikan kehilangan sebelum masalah menjadi lebih teruk. Berdasarkan pertimbangan faktor di atas, pasukan R&D platform pangkalan data Meituan memutuskan untuk membangunkan sistem perkhidmatan pengesanan anomali pangkalan data. Seterusnya, artikel ini akan menghuraikan beberapa pemikiran dan amalan kami dari beberapa dimensi seperti analisis ciri, pemilihan algoritma, latihan model dan pengesanan masa nyata.
2. Analisis ciri
2.1 Ketahui corak perubahan data
Sebelum meneruskan pembangunan dan pengekodan khusus, terdapat tugas yang sangat penting , iaitu Daripada penunjuk pemantauan sejarah sedia ada, kita boleh menemui corak perubahan data siri masa, dan kemudian memilih algoritma yang sesuai berdasarkan ciri pengedaran data. Berikut ialah beberapa carta pengedaran penunjuk wakil yang kami pilih daripada data sejarah: 
Rajah 1 Borang penunjuk pangkalan data
Daripada rajah di atas , kita dapat melihat bahawa corak data terutamanya membentangkan tiga keadaan: kitaran, hanyut dan pegun [1]. Oleh itu, kita boleh memodelkan sampel dengan ciri biasa ini pada peringkat awal, yang boleh merangkumi kebanyakan senario. Seterusnya, kami menganalisisnya dari tiga perspektif: berkala, drift dan pegun, dan membincangkan proses reka bentuk algoritma.
2.1.1 Perubahan kitaran
Dalam banyak senario perniagaan, penunjuk akan turun naik dengan kerap disebabkan oleh puncak pagi dan petang atau beberapa tugas yang dijadualkan. Kami percaya bahawa ini adalah turun naik tetap yang wujud bagi data, dan model harus mempunyai keupayaan untuk mengenal pasti komponen berkala dan mengesan anomali kontekstual. Untuk penunjuk siri masa yang tidak mempunyai komponen arah aliran jangka panjang, apabila penunjuk mempunyai komponen kitaran, 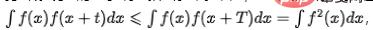 , dengan T mewakili rentang tempoh siri masa. Gambar rajah autokorelasi boleh dikira, iaitu, nilai
, dengan T mewakili rentang tempoh siri masa. Gambar rajah autokorelasi boleh dikira, iaitu, nilai 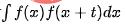 apabila t mengambil nilai yang berbeza, dan kemudian periodicity boleh ditentukan dengan menganalisis selang puncak autokorelasi Proses utama termasuk langkah berikut:
apabila t mengambil nilai yang berbeza, dan kemudian periodicity boleh ditentukan dengan menganalisis selang puncak autokorelasi Proses utama termasuk langkah berikut:
- Ekstrak komponen arah aliran dan asingkan jujukan baki. Gunakan kaedah purata bergerak untuk mengekstrak jangka arah aliran jangka panjang, dan buat perbezaan dengan jujukan asal untuk mendapatkan jujukan baki (Di sini analisis berkala tiada kaitan dengan aliran. Jika komponen trend tidak dipisahkan, autokorelasi akan terjejas dengan ketara , sukar untuk mengenal pasti tempoh ).
- Kira autokorelasi bergolek (Korelasi Bergolek) jujukan baki. Jujukan autokorelasi dikira dengan melakukan operasi pendaraban titik vektor dengan jujukan baki selepas menganjak jujukan baki secara bulat (autokorelasi kitaran boleh mengelakkan pereputan tertunda).
- Tempoh T ditentukan berdasarkan koordinat puncak jujukan autokorelasi. Ekstrak satu siri puncak tertinggi tempatan bagi jujukan autokorelasi, dan ambil selang absis sebagai tempoh (Jika nilai autokorelasi sepadan dengan titik tempoh adalah kurang daripada ambang yang diberikan, ia dianggap tidak mempunyai periodicity yang ketara. ).
Proses khusus adalah seperti berikut:

Rajah 2 Skema proses pengekstrakan kitaran
2.1.2 Perubahan drift
Untuk model dimodelkan Jujukan biasanya diperlukan untuk tidak mempunyai arah aliran jangka panjang atau hanyut global yang jelas, jika tidak model yang dijana biasanya tidak dapat menyesuaikan diri dengan baik kepada arah aliran terkini penunjuk [2]. Kami merujuk kepada situasi di mana nilai min siri masa berubah dengan ketara dari semasa ke semasa atau terdapat titik mutasi global, secara kolektif dirujuk sebagai senario hanyut. Untuk menangkap trend terkini siri masa dengan tepat, kita perlu menentukan sama ada terdapat hanyut dalam data sejarah pada peringkat awal pemodelan. Siri hanyut global dan berkala bermakna hanyut, seperti yang ditunjukkan dalam contoh berikut:

Rajah 3 Gambar rajah hanyut data
Penunjuk pangkalan data dipengaruhi oleh faktor kompleks seperti aktiviti perniagaan Banyak data akan mempunyai perubahan tidak berkala dan pemodelan perlu bertolak ansur dengan perubahan ini. Oleh itu, berbeza daripada masalah pengesanan titik perubahan klasik, dalam senario pengesanan anomali, kita hanya perlu mengesan keadaan di mana data stabil dalam sejarah dan kemudian hanyut. Berdasarkan prestasi algoritma dan prestasi sebenar, kami menggunakan kaedah pengesanan drift berdasarkan penapisan median Proses utama termasuk pautan berikut:
1
a. Mengikut saiz tetingkap yang diberikan, ekstrak median dalam tetingkap untuk mendapatkan komponen trend siri masa.
b. Tetingkap perlu cukup besar untuk mengelakkan pengaruh faktor berkala dan melakukan pembetulan kelewatan penapis.
c. Sebab penggunaan median berbanding pelicinan min adalah untuk mengelakkan pengaruh sampel yang tidak normal.
2 Tentukan sama ada jujukan terlicin meningkat atau berkurang
a setiap titik lebih besar daripada ( kurang daripada ) titik sebelumnya, jujukan ialah jujukan meningkat ( ) menurun.
b. Jika jujukan meningkat atau menurun dengan ketara, maka penunjuk itu jelas mempunyai arah aliran jangka panjang, dan ia boleh ditamatkan lebih awal.
3 Lintas urutan lancar dan gunakan dua peraturan berikut untuk menentukan sama ada terdapat hanyut
a. Jika nilai maksimum jujukan di sebelah kiri titik sampel semasa adalah kurang daripada nilai minimum jujukan di sebelah kanan titik sampel semasa, terdapat hanyut mengejut (aliran menaik).
b Jika nilai minimum jujukan di sebelah kiri titik sampel semasa adalah lebih besar daripada nilai maksimum jujukan di sebelah kanan titik sampel semasa, terdapat satu. hanyut jatuh secara tiba-tiba (Arus bawah).
2.1.3 Perubahan pegunUntuk penunjuk siri masa, jika sifatnya tidak berubah dengan perubahan masa cerapan pada bila-bila masa, kami percaya bahawa ini siri masa adalah stabil. Oleh itu, untuk siri masa dengan komponen arah aliran jangka panjang atau komponen kitaran, semuanya tidak pegun. Contoh khusus ditunjukkan dalam rajah di bawah:

Rajah 4 Petunjuk kepegunan data
Dalam pandangan daripada situasi ini, Kita boleh menentukan sama ada siri masa tertentu adalah pegun melalui ujian punca unit (Ujian Dickey-Fuller Augmented)[3]. Khususnya, untuk sekeping data sejarah penunjuk julat masa tertentu, kami percaya bahawa siri masa adalah stabil apabila syarat berikut dipenuhi pada masa yang sama:
- Nilai p yang diperolehi oleh ujian adfuller untuk data siri masa 1 hari terakhir adalah kurang daripada 0.05.
- Nilai-p yang diperolehi oleh ujian adfuller untuk data siri masa 7 hari lepas adalah kurang daripada 0.05.
3. Pemilihan algoritma
3.1 Peraturan pengedaran dan pemilihan algoritma
Dengan memahami pengesanan anomali data siri masa beberapa yang terkenal syarikat dalam industri Menurut pengenalan produk yang diterbitkan di laman web, ditambah dengan pengalaman sejarah terkumpul kami dan analisis pensampelan beberapa penunjuk sebenar dalam talian, fungsi ketumpatan kebarangkalian mereka mematuhi pengedaran berikut:

Rajah 5 Perwakilan skematik pencongan pengedaran
Untuk pengedaran di atas, kami menyiasat beberapa algoritma biasa dan menentukan plot kotak, perbezaan median mutlak dan Extreme teori nilai sebagai algoritma pengesanan anomali muktamad. Berikut ialah jadual perbandingan algoritma untuk pengesanan data siri masa biasa:

Sebab utama kami tidak memilih 3Sigma ialah ia mempunyai toleransi yang rendah untuk anomali, manakala Perbezaan median mutlak secara teorinya mempunyai toleransi yang lebih baik untuk anomali, jadi apabila data menunjukkan taburan yang sangat simetri, perbezaan median mutlak (MAD) digunakan dan bukannya 3Sigma untuk pengesanan. Kami menggunakan algoritma pengesanan yang berbeza untuk pengedaran data yang berbeza (Untuk prinsip algoritma yang berbeza, sila rujuk lampiran di penghujung artikel dan saya tidak akan menghuraikan terlalu banyak di sini):
- Skewness rendah dan taburan simetri tinggi: perbezaan mutlak median (MAD)
- Taburan pencongan sederhana: Boxplot (Boxplot) >)
- Dengan analisis di atas, kita boleh mendapatkan proses khusus untuk mengeluarkan model berdasarkan pada sampel:
Rajah 6 Proses pemodelan algoritma
Proses pemodelan keseluruhan algoritma ialah ditunjukkan dalam rajah di atas, yang merangkumi terutamanya cabang berikut: pengesanan drift masa, kestabilan masa Analisis seksualiti, analisis berkala siri masa dan pengiraan kecondongan. Yang berikut diperkenalkan masing-masing: 
- Pengesanan drift masa. Jika adegan di mana hanyut wujud dikesan, siri masa input perlu dipotong mengikut titik hanyut t yang diperolehi oleh pengesanan, dan sampel siri masa selepas titik hanyut digunakan sebagai input proses pemodelan berikutnya, direkodkan sebagai S={Si}, di mana i>t.
- Analisis pegun siri masa. Jika siri masa input S memenuhi ujian pegun, ia akan dimodelkan terus melalui plot kotak (lalai ) atau perbezaan median mutlak.
- Analisis berkala siri masa. Dalam kes berkala, rentang tempoh direkodkan sebagai T, siri masa input S dipotong mengikut rentang T, dan proses pemodelan dijalankan untuk baldi data yang terdiri daripada setiap indeks masa j∈{0,1, ⋯,T−1} . Dalam ketiadaan periodicity, proses pemodelan dilakukan untuk semua siri masa input S sebagai baldi data.
Kes : Diberi siri masa ts={t0,t1,⋯ , tn}, dengan mengandaikan bahawa terdapat berkala dan jangka masa ialah T, untuk indeks masa j, di mana j∈{0,1,⋯,T−1}, adalah perlu untuk memodelkannya. titik sampel terdiri daripada selang [tj−kT−m, tj−kT+m], dengan m ialah parameter, mewakili saiz tetingkap, dan k ialah integer, memuaskan j− kT−m≥0, j−kT+m≤n. Sebagai contoh, dengan mengandaikan bahawa siri masa yang diberikan bermula dari 2022/03/01 00:00:00 hingga 2022/03/08 00:00:00, saiz tetingkap yang diberikan ialah 5, dan jangka masa adalah satu hari, kemudian untuk indeks masa 30 Dalam erti kata lain, titik sampel yang diperlukan untuk memodelkannya akan datang daripada tempoh masa berikut: [03/01 00:25:00, 03/01 00:35:00]
[03/02 00 :25:00, 03/02 00:35:00]
...
[03/07 00:25:00, 03/07 00:35:00]
- Pengiraan kecondongan. Penunjuk siri masa ditukar kepada gambar rajah taburan kebarangkalian, dan pencongan taburan dikira Jika nilai mutlak pencongan melebihi ambang, teori nilai ekstrem digunakan untuk memodelkan ambang keluaran. Jika nilai mutlak kecondongan kurang daripada ambang, ambang dimodelkan dan dikeluarkan mengikut plot kotak atau perbezaan median mutlak.
3.2 Pemodelan Contoh Kes
Satu kes dipilih di sini untuk menunjukkan analisis data dan proses pemodelan untuk memudahkan pemahaman yang lebih jelas tentang proses di atas. Rajah (a) ialah jujukan asal, Rajah (b) ialah jujukan yang dilipat mengikut rentang hari, Rajah (c) ialah prestasi arah aliran yang dikuatkan bagi sampel dalam selang indeks masa tertentu dalam Rajah (b), Rajah ( d) ) ialah ambang bawah yang sepadan dengan indeks masa dalam rajah (c). Berikut ialah kes pemodelan sampel sejarah bagi siri masa tertentu:

Rajah 7 Pemodelan kes
Histogram taburan sampel dan ambang dalam kawasan (c) rajah di atas (Beberapa sampel tidak normal telah dihapuskan Dapat dilihat bahawa dalam senario pengedaran yang sangat condong ini, ambang dikira oleh algoritma EVT adalah lebih Untuk menjadi munasabah.

Rajah 8 Perbandingan ambang pengedaran serong
4 > 4.1 Proses aliran data
Untuk mengesan data peringkat kedua berskala besar dalam masa nyata, kami mereka bentuk penyelesaian teknikal berikut berdasarkan pemprosesan strim masa nyata berdasarkan Flink:Berikut ialah latihan luar talian khusus dan reka bentuk teknologi pengesanan dalam talian: Rajah 9 Latihan luar talian dan reka bentuk teknologi pengesanan dalam talian Algoritma pengesanan anomali mengguna pakai idea bahagi-dan-takluk secara keseluruhan dalam latihan model peringkat, ciri diekstrak berdasarkan pengenalan data sejarah Pilih algoritma pengesanan yang sesuai. Ini dibahagikan kepada dua bahagian: latihan luar talian dan pengesanan dalam talian terutamanya melaksanakan prapemprosesan data, pengelasan siri masa dan pemodelan siri masa berdasarkan keadaan sejarah. Dalam talian terutamanya memuatkan dan menggunakan model terlatih luar talian untuk pengesanan anomali masa nyata dalam talian. Reka bentuk khusus ditunjukkan dalam rajah di bawah: Rajah 10 Proses pengesanan anomali Untuk meningkatkan kecekapan algoritma lelaran pengoptimuman dan meneruskan operasi untuk meningkatkan ketepatan dan mengingat semula, kami menggunakan Horae ( data siri masa berskala dalaman Meituan keupayaan semakan kes sistem pengesanan anomali ) membolehkan gelung tertutup pengesanan dalam talian, pemeliharaan kes, analisis dan pengoptimuman, penilaian keputusan dan keluaran dalam talian. Rajah 11 Proses operasi Pada masa ini, penunjuk algoritma pengesanan anomali adalah seperti berikut : Pada masa ini, keupayaan pemantauan anomali pangkalan data Meituan pada dasarnya telah selesai, dan kami akan meneruskan mengusahakan produk pada masa hadapan. Optimumkan dan kembangkan, arahan khusus termasuk: Perbezaan median mutlak, iaitu, Sisihan Mutlak Median(MAD), ialah ukuran teguh bagi bias sampel data berangka univariate [6], biasanya dikira dengan formula berikut: Apabila prior adalah normal pengedaran, secara amnya C memilih 1.4826 dan k memilih 3. MAD mengandaikan bahawa 50% tengah sampel adalah sampel biasa, manakala sampel abnormal berada dalam 50% kawasan di kedua-dua belah. Apabila sampel mematuhi taburan normal, penunjuk MAD lebih mampu menyesuaikan diri dengan outlier dalam set data daripada sisihan piawai. Untuk sisihan piawai, kuasa dua jarak dari data ke min digunakan Sisihan yang lebih besar mempunyai berat yang lebih besar daripada eksperimen. Algoritma MAD mempunyai kesan yang lebih besar pada data Terdapat keperluan yang lebih tinggi untuk kenormalan. Plot kotak terutamanya menerangkan diskret dan simetri taburan sampel melalui beberapa statistik, termasuk: Rajah 12 Plot kotak Bandingkan Q1 dengan Q3 Jarak antara dipanggil IQR. Apabila sampel menyimpang daripada IQR sebanyak 1.5 kali kuartil atas ( atau menyimpang daripada IQR sebanyak 1.5 kali kuartil bawah ) , menganggap sampel sebagai outlier. Tidak seperti tiga sisihan piawai berdasarkan andaian kenormalan, plot kotak secara amnya tidak membuat sebarang andaian tentang pengagihan data asas sampel, boleh menerangkan situasi diskret sampel, dan mempunyai keyakinan yang lebih tinggi terhadap kemungkinan sampel abnormal yang terkandung dalam sampel. Toleransi. Untuk data berat sebelah, pemodelan ditentukur Boxplot lebih konsisten dengan pengedaran data [7]. Data dunia sebenar sukar untuk digeneralisasikan dengan pengedaran yang diketahui, contohnya, untuk beberapa peristiwa melampau (Anomali ), model kebarangkalian ( seperti taburan Gaussian ) cenderung memberikan kebarangkalian 0. Teori nilai melampau[8] adalah untuk membuat kesimpulan taburan peristiwa melampau yang mungkin kita perhatikan tanpa sebarang andaian taburan berdasarkan data asal Ini ialah taburan nilai melampau (EVD ). Ungkapan matematiknya adalah seperti berikut (Formula fungsi taburan kumulatif pelengkap): di mana t mewakili ambang empirikal bagi sampel Nilai yang berbeza boleh ditetapkan untuk senario yang berbeza, yang merupakan parameter bentuk dan parameter skala dalam taburan Pareto umum Apabila sampel yang diberikan melebihi empirikal yang ditetapkan ambang Dalam kes t, pembolehubah rawak X-t mematuhi taburan Pareto umum. Melalui kaedah anggaran kemungkinan maksimum, kita boleh mengira anggaran parameter dan , dan mendapatkan ambang model melalui formula berikut: Dalam formula di atas q mewakili parameter risiko, n ialah bilangan semua sampel, dan Nt ialah bilangan sampel yang memenuhi x-t>0. Oleh kerana biasanya tiada maklumat apriori untuk menganggar ambang empirikal t, kuantiti empirikal sampel boleh digunakan untuk menggantikan nilai berangka t Nilai kuantil empirik di sini boleh dipilih mengikut situasi sebenar. [1] Ren, H., Xu, B., Wang, Y., Yi, C., Huang, C., Kou , X., ... & Zhang, Q. (2019, Julai perkhidmatan pengesanan anomali siri masa di microsoft Dalam Prosiding persidangan antarabangsa ACM SIGKDD ke-25 mengenai penemuan pengetahuan & perlombongan data (ms. 3009-3017). [2] Lu, J., Liu, A., Dong, F., Gu, F., Gama, J., & Zhang, G. (2018). : Kajian semula. IEEE Transactions on Knowledge and Data Engineering, 31(12), 2346-2363. [3] Mushtaq, R. (2011 Augmented dickey fuller test. [4] Ma, M., Yin, Z., Zhang, S., Wang, S., Zheng, C., Jiang, X., ... & Pei, D. (2020) . Mendiagnosis punca pertanyaan lambat terputus-putus dalam pangkalan data awan Prosiding Endowmen VLDB, 1176-1189. [5] Holzinger, A. (2016). informatika kesihatan: bilakah kita memerlukan Informatik Otak manusia, 3(2), 119-131. [6] Leys, C., Ley, C . , Klein, O., Bernard, P., & Licata, L. (2013 Mengesan penyimpangan: Jangan gunakan sisihan piawai di sekitar min, gunakan sisihan mutlak di sekitar median Journal of experimental social psychology, 49(4). 764-766. [7] Hubert, M., & Vandervieren, E. (2008). 5201. [8] Siffer, A., Fouque, P. A., Termier, A., & Largouet, C. (2017, Ogos pengesanan dalam aliran dengan teori nilai melampau daripada Persidangan Antarabangsa ACM SIGKDD ke-23 mengenai Penemuan Pengetahuan dan Perlombongan Data (ms. 1067-1075).

4.2 Proses pengesanan anomali

5. Operasi Produk

6 Tinjauan Masa Depan
7. Lampiran
7.1 Perbezaan median mutlak
7.2 Plot kotak

7.3 Teori Nilai Terlampau
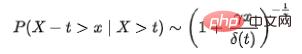
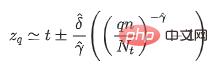
8. Rujukan
Atas ialah kandungan terperinci Reka bentuk dan pelaksanaan sistem pemantauan anomali pangkalan data berdasarkan algoritma AI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Kaedah apa yang digunakan untuk menukar rentetan ke dalam objek dalam vue.js?
Apr 07, 2025 pm 09:39 PM
Apabila menukar rentetan ke objek dalam vue.js, json.parse () lebih disukai untuk rentetan json standard. Untuk rentetan JSON yang tidak standard, rentetan boleh diproses dengan menggunakan ungkapan biasa dan mengurangkan kaedah mengikut format atau url yang dikodkan. Pilih kaedah yang sesuai mengikut format rentetan dan perhatikan isu keselamatan dan pengekodan untuk mengelakkan pepijat.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Cara menetapkan masa tamat vue axios
Apr 07, 2025 pm 10:03 PM
Untuk menetapkan masa untuk Vue Axios, kita boleh membuat contoh Axios dan menentukan pilihan masa tamat: dalam tetapan global: vue.prototype. $ Axios = axios.create ({timeout: 5000}); Dalam satu permintaan: ini. $ axios.get ('/api/pengguna', {timeout: 10000}).
 Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Vue.js Bagaimana untuk menukar pelbagai jenis rentetan ke dalam pelbagai objek?
Apr 07, 2025 pm 09:36 PM
Ringkasan: Terdapat kaedah berikut untuk menukar array rentetan vue.js ke dalam tatasusunan objek: Kaedah asas: Gunakan fungsi peta yang sesuai dengan data yang diformat biasa. Permainan lanjutan: Menggunakan ungkapan biasa boleh mengendalikan format yang kompleks, tetapi mereka perlu ditulis dengan teliti dan dipertimbangkan. Pengoptimuman Prestasi: Memandangkan banyak data, operasi tak segerak atau perpustakaan pemprosesan data yang cekap boleh digunakan. Amalan Terbaik: Gaya Kod Jelas, Gunakan nama dan komen pembolehubah yang bermakna untuk memastikan kod ringkas.
 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
