

Algoritma penyebaran label ialah algoritma pembelajaran mesin separa diselia yang memberikan label kepada titik data yang tidak dilabel sebelum ini. Untuk menggunakan algoritma ini dalam pembelajaran mesin, hanya sebahagian kecil daripada contoh yang mempunyai label atau klasifikasi. Label ini disebarkan kepada titik data tidak berlabel semasa proses pemodelan, pemasangan dan ramalan algoritma.

LabelPropagation ialah algoritma pantas untuk mencari komuniti dalam graf. Ia hanya menggunakan struktur rangkaian sebagai panduan untuk mengesan sambungan ini dan tidak memerlukan fungsi objektif yang telah ditetapkan atau maklumat priori tentang populasi. Penyebaran teg dicapai dengan menyebarkan teg dalam rangkaian dan membentuk sambungan berdasarkan proses penyebaran teg.
Teg tertutup biasanya diberikan teg yang sama. Satu label boleh mendominasi dalam kumpulan nod yang bersambung padat, tetapi akan menghadapi masalah di kawasan yang jarang bersambung. Label akan dihadkan kepada kumpulan nod yang bersambung rapat, dan apabila algoritma selesai, nod yang berakhir dengan label yang sama boleh dianggap sebagai sebahagian daripada sambungan yang sama. Algoritma menggunakan teori graf seperti berikut:-
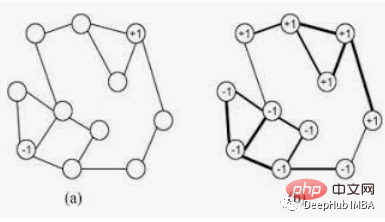
Algoritma LabelPropagation berfungsi dengan cara berikut:-
Untuk menunjukkan cara algoritma LabelPropagation berfungsi, kami menggunakan set data Pima Indians Semasa mencipta program, saya mengimport perpustakaan yang diperlukan untuk menjalankannya



Kadar ketepatan mencarinya ialah 76.9%. 
Mari kita lihat algoritma lain, LabelSpreading. 
 LabelSpreading telah dicadangkan oleh Dengyong Zhou et al dalam kertas kerja 2003 mereka bertajuk "Belajar dengan Konsistensi Tempatan dan Global". Kunci kepada pembelajaran separa penyeliaan ialah andaian a priori ketekalan, yang bermaksud: titik berdekatan berkemungkinan mempunyai label yang sama, dan titik pada struktur yang sama (sering dipanggil manifold kelompok) berkemungkinan besar mempunyai label yang sama.
LabelSpreading telah dicadangkan oleh Dengyong Zhou et al dalam kertas kerja 2003 mereka bertajuk "Belajar dengan Konsistensi Tempatan dan Global". Kunci kepada pembelajaran separa penyeliaan ialah andaian a priori ketekalan, yang bermaksud: titik berdekatan berkemungkinan mempunyai label yang sama, dan titik pada struktur yang sama (sering dipanggil manifold kelompok) berkemungkinan besar mempunyai label yang sama.
LabelSpreading boleh dianggap sebagai bentuk biasa LabelPropagation. Dalam teori graf, matriks Laplacian ialah perwakilan matriks graf Formula matriks Laplacian ialah:
L ialah matriks Laplacian, D ialah matriks darjah, dan A ialah matriks bersebelahan.
Berikut ialah contoh mudah pelabelan graf tidak terarah dan hasil matriks Laplaciannya

Artikel ini akan menggunakan set data sonar untuk menunjukkan cara untuk gunakan fungsi LabelSpreading sklearn.
Terdapat lebih banyak perpustakaan di sini daripada di atas, jadi penerangan ringkas:
Selepas import selesai, gunakan panda untuk membaca set data:

Saya mencipta peta haba menggunakan seaborn:-

Mula-mula lakukan prapemprosesan yang mudah, padamkan lajur yang sangat berkorelasi, sekali gus mengurangkan bilangan lajur daripada 61 kepada 58:

Kemudian kocok data dan baris semula, supaya ramalan secara amnya lebih tepat dalam set data yang dikocok, buat salinan set data dan tentukan y_orig sebagai sasaran latihan:

Gunakan matplotlib untuk memplot titik data 2D Scatter Plot :-

Rawak 60% daripada label dalam set data menggunakan penjana nombor rawak. Kemudian label rawak diberikan -1:-

Selepas pramemproses data, tentukan pembolehubah bersandar dan bebas, iaitu y dan X masing-masing. Pembolehubah y ialah lajur terakhir dan
Menggunakan kaedah ini, kita boleh mencapai ketepatan 87.98%:-
Perbandingan mudah
1 , alpha dipanggil pekali pengapit, yang merujuk kepada jumlah relatif penggunaan maklumat jirannya dan bukannya label awalnya Jika 0, ia bermakna mengekalkan maklumat label awal maklumat awal; set alpha=0.2 , bermakna 80% daripada maklumat label asal sentiasa dikekalkan 
Atas ialah kandungan terperinci Dua algoritma penyebaran label separa diselia dalam sklearn: LabelPropagation dan LabelSpreading. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



