
 Peranti teknologi
AI
Penyebaran + pengesanan sasaran = penjanaan imej yang boleh dikawal! Pasukan China mencadangkan GLIGEN untuk mengawal kedudukan spatial objek dengan sempurna
Peranti teknologi
AI
Penyebaran + pengesanan sasaran = penjanaan imej yang boleh dikawal! Pasukan China mencadangkan GLIGEN untuk mengawal kedudukan spatial objek dengan sempurna
Penyebaran + pengesanan sasaran = penjanaan imej yang boleh dikawal! Pasukan China mencadangkan GLIGEN untuk mengawal kedudukan spatial objek dengan sempurna

Dengan sumber terbuka Stable Diffusion, penggunaan bahasa semula jadi untuk penjanaan imej secara beransur-ansur menjadi popular Banyak masalah AIGC juga telah terdedah, seperti AI tidak boleh menarik tangan, tidak dapat memahami hubungan tindakan dan sukar untuk mengawal kedudukan objek menunggu.
Sebab utama ialah "antara muka input" hanya mempunyai bahasa semula jadi, tidak dapat mencapai kawalan skrin yang baik.
Baru-baru ini, kawasan tumpuan penyelidikan dari University of Wisconsin-Madison, Columbia University dan Microsoft telah mencadangkan kaedah baharu GLIGEN, yang menggunakan input pembumian sebagai syarat untuk menambah baik "pra- teks terlatih kepada imej" Kefungsian Model Resapan telah diperluaskan.

Pautan kertas: https://arxiv.org/pdf/2301.07093.pdf
Laman utama projek: https://gligen.github.io/
Pautan pengalaman: https: //huggingface.co/spaces/gligen/demo
Untuk mengekalkan sejumlah besar pengetahuan konseptual model pra-latihan, para penyelidik tidak memilih untuk mendenda -tala model, tetapi melalui gating Mekanisme menyuntik keadaan pembumian input yang berbeza ke dalam lapisan baharu yang boleh dilatih untuk mencapai kawalan ke atas penjanaan imej dunia terbuka.
Pada masa ini GLIGEN menyokong empat input.

(kiri atas) teks entiti+kotak (kanan atas) imej entiti+kotak
(kiri bawah) gaya imej + teks + kotak (kanan bawah) entiti teks + titik utama
Percubaan keputusan juga menunjukkan, prestasi tangkapan sifar GLIGEN pada COCO dan LVIS adalah jauh lebih baik daripada garis dasar reka letak-ke-imej yang diselia semasa.
Penjanaan imej yang boleh dikawal
Sebelum model penyebaran, rangkaian musuh generatif (GAN) sentiasa menjadi peneraju dalam bidang penjanaan imej, dan ruang terpendam dan bersyaratnya input berada dalam " Aspek "operasi terkawal" dan "penjanaan" telah dikaji sepenuhnya.
Model autoregresif dan resapan bersyarat teks menunjukkan kualiti imej dan liputan konsep yang menakjubkan, terima kasih kepada objektif pembelajaran yang lebih stabil dan data berpasangan imej-teks berskala besar Berlatih dan cepat keluar dari bulatan, menjadi alat untuk membantu reka bentuk dan penciptaan seni.
Walau bagaimanapun, model penjanaan imej teks berskala besar sedia ada tidak boleh dikondisikan pada mod input lain "selain teks" dan tidak mempunyai konsep kedudukan yang tepat atau penggunaan imej rujukan untuk mengawal proses penjanaan Kebolehan menghadkan penyampaian maklumat.
Sebagai contoh, sukar untuk menerangkan lokasi tepat objek menggunakan teks dan kotak sempadan (kotak sempadan
) atau titik kekunci (titik utama) ) boleh dilaksanakan dengan mudah.

Sesetengah alatan sedia ada seperti inpainting, layout2img generation, dsb. boleh menggunakan input modal selain daripada teks, tetapi mereka Ini input jarang digabungkan untuk penjanaan text2img terkawal.
Di samping itu, model generatif sebelumnya biasanya dilatih secara bebas pada set data khusus tugas, manakala dalam bidang pengecaman imej, paradigma yang telah lama wujud adalah untuk belajar daripada "imej berskala besar data" Atau model asas pra-latihan pada "pasangan teks imej" untuk mula membina model untuk tugasan tertentu.
Model resapan telah dilatih pada berbilion pasangan teks imej, dan persoalan biasa ialah: bolehkah kita membina model resapan sedia ada, memberi mereka mod input bersyarat baharu? ?
Disebabkan oleh jumlah besar pengetahuan konsep yang dimiliki oleh model pra-latihan, adalah mungkin untuk mencapai prestasi yang lebih baik pada tugas penjanaan lain sambil memperoleh lebih banyak data daripada penjanaan imej teks sedia ada model.
GLIGEN
Berdasarkan tujuan dan idea di atas, model GLIGEN yang dicadangkan oleh penyelidik masih mengekalkan tajuk teks sebagai input, tetapi juga membolehkan modaliti input lain, seperti sebagai konsep pembumian Kotak pembatas, imej rujukan pembumian dan titik utama bahagian pembumian.
Masalah utama di sini adalah untuk mengekalkan sejumlah besar pengetahuan konseptual asal dalam model pra-latihan sambil belajar menyuntik maklumat asas baharu.
Untuk mengelakkan lupa pengetahuan, para penyelidik mencadangkan pembekuan model asal dan menambah lapisan Transformer berpagar baharu untuk menyerap input pengikatan baharu Yang berikut menggunakan kotak sempadan sebagai contoh.
Input arahan

Setiap entiti teks penggredan diwakili sebagai kotak sempadan yang mengandungi nilai koordinat penjuru kiri atas dan kanan bawah.
Perlu diambil perhatian bahawa kerja berkaitan susun atur2img sedia ada biasanya memerlukan kamus konsep dan hanya boleh mengendalikan entiti set rapat (seperti kategori COCO) semasa fasa penilaian pengekod pengekodan perihalan imej boleh menyamaratakan maklumat lokasi dalam set latihan kepada konsep lain.
Data latihan
digunakan untuk menjana pembumian imej Data latihan memerlukan teks c dan entiti asas e sebagai syarat Dalam amalan, keperluan data boleh dilonggarkan dengan mempertimbangkan input yang lebih fleksibel.

Terdapat terutamanya tiga jenis data
1 . Data pembumian
Setiap imej dikaitkan dengan kapsyen yang menerangkan keseluruhan imej entiti kata nama diekstrak daripada kapsyen dan dilabelkan dengan kotak sempadan.
Memandangkan entiti kata nama diambil terus daripada tajuk bahasa semula jadi, ia boleh merangkumi perbendaharaan kata yang lebih kaya, yang bermanfaat kepada generasi asas perbendaharaan kata dunia terbuka.
2. Data pengesanan 80 kategori objek), pilih untuk menggunakan token tajuk kosong dalam panduan bebas pengelas sebagai tajuk.
Jumlah data pengesanan (berjuta-juta tahap) adalah lebih besar daripada data asas (ribuan tahap), jadi keseluruhan data latihan boleh ditingkatkan dengan banyak.
3. Data Pengesanan dan Kapsyen
Entiti kata nama adalah sama dengan entiti kata nama dalam data pengesanan , dan imej diterangkan dengan tajuk teks sahaja, mungkin terdapat kes di mana entiti kata nama tidak konsisten sepenuhnya dengan entiti dalam tajuk.
Sebagai contoh, tajuk hanya memberikan penerangan aras tinggi tentang ruang tamu dan tidak menyebut objek di tempat kejadian, manakala anotasi pengesanan memberikan butiran peringkat objek yang lebih halus.
Mekanisme perhatian berpagar
Penyelidik Matlamatnya ialah untuk memberikan model penjanaan imej bahasa berskala besar yang sedia ada keupayaan berasaskan ruang baharu
Model penyebaran berskala besar telah dilatih terlebih dahulu pada teks imej berskala rangkaian untuk mendapatkan pengetahuan yang diperlukan. untuk mensintesis imej realistik berdasarkan arahan bahasa yang pelbagai dan kompleks Memandangkan pra-latihan adalah mahal dan berprestasi baik, adalah penting untuk mengekalkan pengetahuan ini dalam pemberat model sambil mengembangkan keupayaan baharu Ini boleh dicapai dengan menyesuaikan modul baharu untuk menampung keupayaan baharu lama kelamaan.
Semasa proses latihan, mekanisme gating digunakan untuk menyepadukan maklumat asas baharu secara beransur-ansur ke dalam model pra-latihan. Reka bentuk ini membolehkan fleksibiliti dalam proses pensampelan semasa penjanaan untuk meningkatkan kualiti dan kebolehkawalan. 
Ia juga telah dibuktikan dalam eksperimen bahawa menggunakan model lengkap (semua lapisan) pada separuh pertama langkah pensampelan dan hanya lapisan asal (tiada lapisan Transformer berpagar) dalam separuh masa kedua, menjana Hasilnya boleh mencerminkan keadaan pembumian dengan lebih tepat dan mempunyai kualiti imej yang lebih tinggi.
Bahagian percubaan
Dalam set terbuka teks asas kepada tugas penjanaan imej, mula-mula gunakan hanya anotasi asas COCO (COCO2014CD) untuk latihan dan menilai sama ada GLIGEN boleh menjana entiti asas selain daripada kategori COCO.

Seperti yang anda lihat, GLIGEN boleh mempelajari konsep baharu seperti "blue jay", "croissant", atau baharu Atribut objek seperti "meja kayu coklat", dan maklumat ini tidak muncul dalam kategori latihan.
Penyelidik percaya ini adalah kerana perhatian diri berpagar GLIGEN belajar untuk meletakkan semula ciri visual yang sepadan dengan entiti asas dalam tajuk untuk lapisan perhatian silang berikut, dan keupayaan Generalisasi diperoleh kerana ruang teks kongsi dalam dua lapisan ini.
Percubaan juga menilai secara kuantitatif prestasi penjanaan sifar tangkapan model ini pada LVIS, yang mengandungi 1203 kategori objek ekor panjang. Gunakan GLIP untuk meramalkan kotak sempadan daripada imej yang dijana dan mengira AP, dinamakan skor GLIP; bandingkan dengan model terkini yang direka untuk tugasan susun atur2img,

 Secara keseluruhannya, kertas ini:
Secara keseluruhannya, kertas ini:
Cadangan kaedah penjanaan text2img baharu
, memberikan model penyebaran text2img yang sedia ada kebolehkawalan pembumian baharu, model itu menyedari. penjanaan text2img berasaskan dunia terbuka dan input kotak sempadan, iaitu, ia menyepadukan konsep kedudukan baharu yang tidak diperhatikan dalam latihan3. Prestasi sifar tangkapan model ini pada tugasan susun atur2img; adalah jauh lebih baik daripada tahap tercanggih sebelum ini, membuktikan bahawa model generatif pra-latihan berskala besar boleh meningkatkan prestasi tugasan hiliran
Atas ialah kandungan terperinci Penyebaran + pengesanan sasaran = penjanaan imej yang boleh dikawal! Pasukan China mencadangkan GLIGEN untuk mengawal kedudukan spatial objek dengan sempurna. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bagaimana untuk mengosongkan latar belakang desktop sejarah imej terkini dalam Windows 11
Apr 14, 2023 pm 01:37 PM
Bagaimana untuk mengosongkan latar belakang desktop sejarah imej terkini dalam Windows 11
Apr 14, 2023 pm 01:37 PM
<p>Windows 11 menambah baik pemperibadian dalam sistem, membenarkan pengguna melihat sejarah terkini perubahan latar belakang desktop yang dibuat sebelum ini. Apabila anda memasuki bahagian pemperibadian dalam aplikasi Tetapan Sistem Windows, anda boleh melihat pelbagai pilihan, menukar kertas dinding latar belakang adalah salah satu daripadanya. Tetapi kini anda boleh melihat sejarah terkini kertas dinding latar belakang yang ditetapkan pada sistem anda. Jika anda tidak suka melihat ini dan ingin mengosongkan atau memadamkan sejarah terbaharu ini, teruskan membaca artikel ini, yang akan membantu anda mengetahui lebih lanjut tentang cara melakukannya menggunakan Editor Pendaftaran. </p><h2>Cara menggunakan penyuntingan pendaftaran
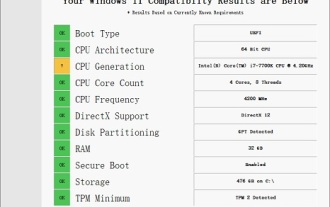 Penyelesaian kepada i7-7700 tidak dapat menaik taraf kepada Windows 11
Dec 26, 2023 pm 06:52 PM
Penyelesaian kepada i7-7700 tidak dapat menaik taraf kepada Windows 11
Dec 26, 2023 pm 06:52 PM
Prestasi i77700 adalah mencukupi untuk menjalankan win11, tetapi pengguna mendapati bahawa i77700 mereka tidak boleh dinaik taraf kepada win11 Ini terutamanya disebabkan oleh sekatan yang dikenakan oleh Microsoft, jadi mereka boleh memasangnya selagi mereka melangkau sekatan ini. i77700 tidak boleh dinaik taraf kepada win11: 1. Kerana Microsoft mengehadkan versi CPU. 2. Hanya Intel generasi kelapan dan versi ke atas boleh terus menaik taraf kepada win11 3. Sebagai generasi ke-7, i77700 tidak dapat memenuhi keperluan naik taraf win11. 4. Walau bagaimanapun, i77700 benar-benar mampu menggunakan win11 dengan lancar dari segi prestasi. 5. Jadi anda boleh menggunakan sistem pemasangan langsung win11 laman web ini. 6. Selepas muat turun selesai, klik kanan fail dan "muat"nya. 7. Klik dua kali untuk menjalankan "Satu klik
 Pengesanan jatuh, berdasarkan pengecaman tindakan manusia titik rangka, sebahagian daripada kod dilengkapkan dengan Chatgpt
Apr 12, 2023 am 08:19 AM
Pengesanan jatuh, berdasarkan pengecaman tindakan manusia titik rangka, sebahagian daripada kod dilengkapkan dengan Chatgpt
Apr 12, 2023 am 08:19 AM
Salam semua. Hari ini saya ingin berkongsi dengan anda projek pengesanan jatuh, tepatnya, ia adalah pengecaman pergerakan manusia berdasarkan titik rangka. Ia secara kasarnya dibahagikan kepada tiga langkah: pengecaman badan manusia, kod sumber projek pengelasan titik rangka manusia telah dibungkus, lihat penghujung artikel untuk cara mendapatkannya. 0. chatgpt Pertama, kita perlu mendapatkan aliran video yang dipantau. Kod ini agak tetap. Kita boleh terus chatgpt melengkapkan kod yang ditulis oleh chatgpt Tiada masalah dan boleh digunakan terus. Tetapi apabila ia datang kepada tugas perniagaan kemudian, seperti menggunakan mediapipe untuk mengenal pasti titik rangka manusia, kod yang diberikan oleh chatgpt adalah tidak betul. Saya rasa chatgpt boleh digunakan sebagai kotak alat yang bebas daripada logik perniagaan Anda boleh cuba menyerahkannya kepada c
 Bagaimana untuk Muat Turun Imej Kertas Dinding Spotlight Windows pada PC
Aug 23, 2023 pm 02:06 PM
Bagaimana untuk Muat Turun Imej Kertas Dinding Spotlight Windows pada PC
Aug 23, 2023 pm 02:06 PM
Windows tidak pernah mengabaikan estetika. Daripada bidang hijau bucolic XP kepada reka bentuk berputar biru Windows 11, kertas dinding desktop lalai telah menjadi sumber kegembiraan pengguna selama bertahun-tahun. Dengan Windows Spotlight, anda kini mempunyai akses terus kepada imej yang cantik dan mengagumkan untuk skrin kunci dan kertas dinding desktop anda setiap hari. Malangnya, imej ini tidak melepak. Jika anda telah jatuh cinta dengan salah satu imej sorotan Windows, maka anda pasti ingin tahu cara memuat turunnya supaya anda boleh mengekalkannya sebagai latar belakang anda buat seketika. Ini semua yang anda perlu tahu. Apakah WindowsSpotlight? Sorotan Tetingkap ialah pengemas kini kertas dinding automatik yang tersedia daripada Pemperibadian > dalam apl Tetapan
 Bagaimana untuk menggunakan teknologi segmentasi semantik imej dalam Python?
Jun 06, 2023 am 08:03 AM
Bagaimana untuk menggunakan teknologi segmentasi semantik imej dalam Python?
Jun 06, 2023 am 08:03 AM
Dengan pembangunan berterusan teknologi kecerdasan buatan, teknologi segmentasi semantik imej telah menjadi hala tuju penyelidikan yang popular dalam bidang analisis imej. Dalam segmentasi semantik imej, kami membahagikan kawasan yang berbeza dalam imej dan mengelaskan setiap kawasan untuk mencapai pemahaman yang menyeluruh tentang imej. Python ialah bahasa pengaturcaraan yang terkenal dengan keupayaan analisis data dan visualisasi datanya yang hebat menjadikannya pilihan pertama dalam bidang penyelidikan teknologi kecerdasan buatan. Artikel ini akan memperkenalkan cara menggunakan teknologi segmentasi semantik imej dalam Python. 1. Pengetahuan prasyarat semakin mendalam
 Karya terbaharu MIT: menggunakan GPT-3.5 untuk menyelesaikan masalah pengesanan anomali siri masa
Jun 08, 2024 pm 06:09 PM
Karya terbaharu MIT: menggunakan GPT-3.5 untuk menyelesaikan masalah pengesanan anomali siri masa
Jun 08, 2024 pm 06:09 PM
Hari ini saya ingin memperkenalkan kepada anda artikel yang diterbitkan oleh MIT minggu lepas, menggunakan GPT-3.5-turbo untuk menyelesaikan masalah pengesanan anomali siri masa, dan pada mulanya mengesahkan keberkesanan LLM dalam pengesanan anomali siri masa. Tiada penalaan dalam keseluruhan proses, dan GPT-3.5-turbo digunakan secara langsung untuk pengesanan anomali Inti artikel ini ialah cara menukar siri masa kepada input yang boleh dikenali oleh GPT-3.5-turbo, dan cara mereka bentuk. gesaan atau saluran paip untuk membenarkan LLM menyelesaikan tugas pengesanan anomali. Izinkan saya memperkenalkan karya ini kepada anda secara terperinci. Tajuk kertas imej: Largelanguagemodelscanbezero-shotanomalydete
 iOS 17: Cara menggunakan pemangkasan satu klik dalam foto
Sep 20, 2023 pm 08:45 PM
iOS 17: Cara menggunakan pemangkasan satu klik dalam foto
Sep 20, 2023 pm 08:45 PM
Dengan apl iOS 17 Photos, Apple memudahkan untuk memangkas foto mengikut spesifikasi anda. Baca terus untuk mengetahui caranya. Sebelum ini dalam iOS 16, memangkas imej dalam apl Foto melibatkan beberapa langkah: Ketik antara muka pengeditan, pilih alat pangkas dan kemudian laraskan pemangkasan menggunakan gerak isyarat picit untuk zum atau seret penjuru alat pangkas. Dalam iOS 17, Apple bersyukur telah memudahkan proses ini supaya apabila anda mengezum masuk pada mana-mana foto yang dipilih dalam pustaka Foto anda, butang Pangkas baharu muncul secara automatik di penjuru kanan sebelah atas skrin. Mengklik padanya akan memaparkan antara muka pemangkasan penuh dengan tahap zum pilihan anda, jadi anda boleh memangkas ke bahagian imej yang anda suka, memutar imej, menyongsangkan imej atau menggunakan nisbah skrin atau menggunakan penanda
 Bagaimana untuk mengubah saiz kumpulan imej menggunakan PowerToys pada Windows
Aug 23, 2023 pm 07:49 PM
Bagaimana untuk mengubah saiz kumpulan imej menggunakan PowerToys pada Windows
Aug 23, 2023 pm 07:49 PM
Mereka yang perlu bekerja dengan fail imej setiap hari selalunya perlu mengubah saiznya agar sesuai dengan keperluan projek dan pekerjaan mereka. Walau bagaimanapun, jika anda mempunyai terlalu banyak imej untuk diproses, saiz semula imej secara individu boleh mengambil banyak masa dan usaha. Dalam kes ini, alat seperti PowerToys boleh berguna untuk, antara lain, mengubah saiz fail kumpulan menggunakan utiliti pengubah semula imejnya. Begini cara untuk menyediakan tetapan Image Resizer anda dan mulakan saiz semula kumpulan imej dengan PowerToys. Cara Mengubah Saiz Imej Secara Berkelompok dengan PowerToys PowerToys ialah program semua-dalam-satu dengan pelbagai utiliti dan ciri untuk membantu anda mempercepatkan tugas harian anda. Salah satu utilitinya ialah imej
