


Sesetengah bahan pembelajaran pdf yang dimuat turun dalam talian akan mempunyai tera air, yang sangat mempengaruhi pembacaan. Sebagai contoh, gambar di bawah telah dipotong daripada fail pdf Hari ini kita akan menggunakan Python untuk menyelesaikan masalah ini.

PIL: Perpustakaan Pengimejan Python ialah perpustakaan standard pemprosesan imej yang sangat berkuasa dalam python, tetapi ia hanya boleh menyokong python 2.7, jadi saya mempunyai sukarelawan. Penulis mencipta bantal yang menyokong python 3 berdasarkan PIL dan menambah beberapa ciri baharu.
pip install pillow
pymupdf boleh menggunakan python untuk mengakses fail dengan sambungan *.pdf, .xps, .oxps, .epub, .cbz atau *.fb2. Banyak format imej popular turut disokong, termasuk imej TIFF berbilang halaman.
pip install PyMuPDF
Import modul yang diperlukan
from PIL import Image from itertools import product import fitz import os
pdf Prinsip penyingkiran tera air adalah serupa dengan penyingkiran tera air imej editor dahulu Mulakan dengan mengalih keluar tera air daripada imej di atas.
Semua orang yang telah mempelajari komputer tahu bahawa RGB digunakan untuk mewakili merah, hijau dan biru dalam komputer, (255, 0, 0) digunakan untuk mewakili merah, (0, 255, 0) digunakan untuk mewakili hijau, (0, 0, 255) mewakili biru, (255, 255, 255) mewakili putih, (0, 0, 0) mewakili hitam Prinsip penyingkiran tera air adalah untuk menukar warna tera air kepada putih (255,. 255, 255).
Mula-mula dapatkan lebar dan tinggi imej, dan gunakan modul itertools untuk mendapatkan produk Cartesian lebar dan tinggi sebagai piksel. Warna setiap piksel terdiri daripada tiga bit pertama RGB dan bit keempat saluran Alpha. Saluran alfa tidak diperlukan, hanya data RGB.
def remove_img():
image_file = input("请输入图片地址:")
img = Image.open(image_file)
width, height = img.size
for pos in product(range(width), range(height)):
rgb = img.getpixel(pos)[:3]
print(rgb)
Gunakan tangkapan skrin WeChat untuk menyemak RGB piksel tera air.
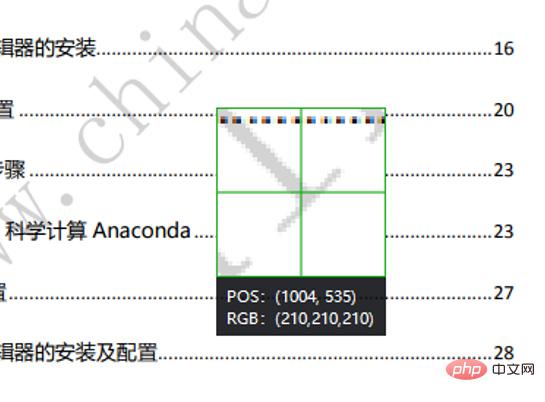
Anda boleh melihat bahawa RGB bagi tera air ialah (210, 210, 210 Di sini, jika jumlah RGB melebihi 620, ia ditentukan sebagai tera air). titik pada masa ini, gantikan warna piksel dengan Putih. Akhirnya simpan gambar.
rgb = img.getpixel(pos)[:3]
if(sum(rgb) >= 620):
img.putpixel(pos, (255, 255, 255))
img.save('d:/qsy.png')
Contoh hasil:

Prinsip penyingkiran tera air PDF adalah lebih kurang sama dengan imej penyingkiran tera air Selepas membuka fail pdf dengan PyMuPDF, tukar setiap halaman pdf menjadi imej pixmap mempunyai RGB sendiri. Anda hanya perlu menukar RGB dalam tera air pdf kepada (255, 255, 255) ia sebagai imej.
def remove_pdf():
page_num = 0
pdf_file = input("请输入 pdf 地址:")
pdf = fitz.open(pdf_file);
for page in pdf:
pixmap = page.get_pixmap()
for pos in product(range(pixmap.width), range(pixmap.height)):
rgb = pixmap.pixel(pos[0], pos[1])
if(sum(rgb) >= 620):
pixmap.set_pixel(pos[0], pos[1], (255, 255, 255))
pixmap.pil_save(f"d:/pdf_images/{page_num}.png")
print(f"第{page_num}水印去除完成")
page_num = page_num + 1
Contoh hasil:
Tukar imej kepada pdf Apa yang perlu diberi perhatian ialah susunan imej, fail digital Nama mesti ditukar kepada jenis int sebelum mengisih. Selepas membuka imej dengan modul PyMuPDF, gunakan fungsi convertToPDF() untuk menukar imej kepada pdf satu halaman. Masukkan ke dalam fail pdf baharu.
def pic2pdf():
pic_dir = input("请输入图片文件夹路径:")
pdf = fitz.open()
img_files = sorted(os.listdir(pic_dir),key=lambda x:int(str(x).split('.')[0]))
for img in img_files:
print(img)
imgdoc = fitz.open(pic_dir + '/' + img)
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
pdf.insertPDF(imgpdf)
pdf.save("d:/demo.pdf")
pdf.close()
Tanda air yang menjengkelkan pada PDF dan gambar akhirnya boleh hilang di hadapan ular sawa yang berkuasa. Adakah anda sudah cukup belajar?
Atas ialah kandungan terperinci Sangat mudah! Alih keluar tera air daripada imej dan PDF dengan Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



