
 pembangunan bahagian belakang
Tutorial Python
Saya menggunakan Python untuk merangkak rakan WeChat saya, mereka begini...
pembangunan bahagian belakang
Tutorial Python
Saya menggunakan Python untuk merangkak rakan WeChat saya, mereka begini...
Saya menggunakan Python untuk merangkak rakan WeChat saya, mereka begini...


Dengan populariti WeChat, semakin ramai orang mula menggunakan WeChat. WeChat telah berubah secara beransur-ansur daripada perisian sosial yang ringkas kepada cara hidup Orang ramai memerlukan WeChat untuk komunikasi harian, dan WeChat juga diperlukan untuk komunikasi kerja. Setiap rakan dalam WeChat mewakili peranan berbeza yang dimainkan oleh orang ramai dalam masyarakat.

Artikel hari ini akan menjalankan analisis data pada rakan WeChat berdasarkan Python Dimensi utama yang dipilih di sini ialah: jantina, avatar, tandatangan, lokasi, terutamanya menggunakan carta dan awan perkataan keputusan dibentangkan dalam dua bentuk Antaranya, analisis kekerapan perkataan dan analisis sentimen digunakan untuk maklumat teks. Bak kata pepatah: Jika seorang pekerja ingin menjalankan tugasnya dengan baik, dia mesti mengasah peralatannya dahulu. Sebelum memulakan artikel ini secara rasmi, izinkan saya memperkenalkan secara ringkas modul pihak ketiga yang digunakan dalam artikel ini:
itchat: Antara muka web WeChat merangkum versi Python, yang digunakan dalam artikel ini untuk mendapatkan maklumat rakan WeChat.
jieba: Versi Python bagi pembahagian perkataan yang gagap, digunakan dalam artikel ini untuk membahagikan maklumat teks.
matplotlib: modul lukisan carta dalam Python, digunakan dalam artikel ini untuk melukis carta lajur dan carta pai
snownlp: modul pembahagian perkataan bahasa Cina dalam Python, digunakan dalam artikel ini untuk menganalisis maklumat teks Buat pertimbangan emosi.
PIL: Modul pemprosesan imej dalam Python, digunakan dalam artikel ini untuk memproses imej.
numpy: modul pengiraan berangka dalam Python, digunakan bersama dengan modul wordcloud dalam artikel ini.
wordcloud: Modul awan perkataan dalam Python, digunakan dalam artikel ini untuk melukis gambar awan perkataan.
TencentYoutuyun: SDK versi Python yang disediakan oleh Tencent Youtuyun digunakan dalam artikel ini untuk mengecam wajah dan mengekstrak maklumat tag imej.
Modul di atas boleh dipasang melalui pip Untuk mendapatkan arahan terperinci tentang penggunaan setiap modul, sila rujuk dokumentasi masing-masing.
1. Analisis data
Prasyarat untuk menganalisis data rakan WeChat adalah untuk mendapatkan maklumat rakan Dengan menggunakan modul itchat, semua ini akan menjadi sangat mudah melalui dua perkara berikut baris kod :
itchat.auto_login(hotReload = True) friends = itchat.get_friends(update = True)
Sama seperti melog masuk ke versi web WeChat, kami boleh log masuk dengan mengimbas kod QR dengan telefon bimbit kami Objek rakan yang dikembalikan di sini adalah koleksi, dan yang pertama elemen ialah pengguna semasa. Oleh itu, dalam proses analisis data berikut, kami sentiasa mengambil rakan[1:] sebagai data input asal Setiap elemen dalam koleksi adalah struktur kamus Mengambil diri saya sebagai contoh, anda dapat melihat bahawa terdapat Sex, City, Province , HeadImgUrl dan Tandatangan ialah empat medan Analisis berikut kami akan bermula daripada empat medan ini:

2. Jantina rakan
Analisis jantina rakan , kami terlebih dahulu. perlu mendapatkan maklumat jantina semua rakan Di sini kami mengekstrak medan Seks bagi setiap maklumat rakan, dan kemudian mengira nombor Lelaki, Perempuan dan Unkonw masing-masing Kami mengumpulkan tiga nilai ini ke dalam senarai modul untuk melukis carta pai. Kod ini dilaksanakan seperti berikut:
def analyseSex(firends): sexs = list(map(lambda x:x['Sex'],friends[1:])) counts = list(map(lambda x:x[1],Counter(sexs).items())) labels = ['Unknow','Male','Female'] colors = ['red','yellowgreen','lightskyblue'] plt.figure(figsize=(8,5), dpi=80) plt.axes(aspect=1) plt.pie(counts, #性别统计结果 labels=labels, #性别展示标签 colors=colors, #饼图区域配色 labeldistance = 1.1, #标签距离圆点距离 autopct = '%3.1f%%', #饼图区域文本格式 shadow = False, #饼图是否显示阴影 startangle = 90, #饼图起始角度 pctdistance = 0.6 #饼图区域文本距离圆点距离 ) plt.legend(loc='upper right',) plt.title(u'%s的微信好友性别组成' % friends[0]['NickName']) plt.show()
Berikut ialah penjelasan ringkas tentang kod ini Nilai medan jantina dalam WeChat termasuk Unkonw, Lelaki dan Perempuan, dan yang sepadan Nilainya ialah 0, 1, dan 2 masing-masing. Tiga nilai berbeza ini dikira melalui Counter() dalam modul Koleksi, dan kaedah item()nya mengembalikan koleksi tupel.
Elemen dimensi pertama tuple mewakili kunci, iaitu, 0, 1, 2, dan elemen dimensi kedua tuple mewakili nombor, dan set tupel itu diisih, itu ialah, kuncinya adalah mengikut 0, 1, 2 disusun mengikut urutan, jadi bilangan tiga nilai yang berbeza ini boleh diperolehi melalui kaedah map() Kita boleh menghantarnya ke matplotlib untuk melukis tiga nilai berbeza ini ditentukan oleh matplotlib yang dikira. Gambar berikut ialah peta taburan jantina rakan yang dilukis oleh matplotlib:
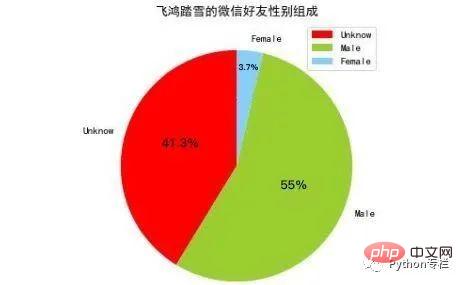
3 Avatar Rakan
Analisis avatar rakan dari dua aspek avatar rakan, berapakah nisbah rakan yang menggunakan avatar wajah manusia Kedua, apakah kata kunci berharga yang boleh diekstrak daripada avatar rakan ini.
Di sini anda perlu memuat turun avatar secara setempat berdasarkan medan HeadImgUrl, dan kemudian gunakan antara muka API berkaitan pengecaman muka yang disediakan oleh Tencent Youtu untuk mengesan sama ada terdapat wajah dalam imej avatar dan mengekstrak tag dalam imej. Antaranya, yang pertama ialah klasifikasi dan ringkasan, dan kami menggunakan carta pai untuk membentangkan keputusan; Kod kunci adalah seperti berikut:
def analyseHeadImage(frineds):
# Init Path
basePath = os.path.abspath('.')
baseFolder = basePath + '\HeadImages\'
if(os.path.exists(baseFolder) == False):
os.makedirs(baseFolder)
# Analyse Images
faceApi = FaceAPI()
use_face = 0
not_use_face = 0
image_tags = ''
for index in range(1,len(friends)):
friend = friends[index]
# Save HeadImages
imgFile = baseFolder + '\Image%s.jpg' % str(index)
imgData = itchat.get_head_img(userName = friend['UserName'])
if(os.path.exists(imgFile) == False):
with open(imgFile,'wb') as file:
file.write(imgData)
# Detect Faces
time.sleep(1)
result = faceApi.detectFace(imgFile)
if result == True:
use_face += 1
else:
not_use_face += 1
# Extract Tags
result = faceApi.extractTags(imgFile)
image_tags += ','.join(list(map(lambda x:x['tag_name'],result)))
labels = [u'使用人脸头像',u'不使用人脸头像']
counts = [use_face,not_use_face]
colors = ['red','yellowgreen','lightskyblue']
plt.figure(figsize=(8,5), dpi=80)
plt.axes(aspect=1)
plt.pie(counts, #性别统计结果
labels=labels, #性别展示标签
colors=colors, #饼图区域配色
labeldistance = 1.1, #标签距离圆点距离
autopct = '%3.1f%%', #饼图区域文本格式
shadow = False, #饼图是否显示阴影
startangle = 90, #饼图起始角度
pctdistance = 0.6 #饼图区域文本距离圆点距离
)
plt.legend(loc='upper right',)
plt.title(u'%s的微信好友使用人脸头像情况' % friends[0]['NickName'])
plt.show()
image_tags = image_tags.encode('iso8859-1').decode('utf-8')
back_coloring = np.array(Image.open('face.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=800,
height=480,
margin=15
)
wordcloud.generate(image_tags)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()这里我们会在当前目录新建一个HeadImages目录,用于存储所有好友的头像,然后我们这里会用到一个名为FaceApi类,这个类由腾讯优图的SDK封装而来,这里分别调用了人脸检测和图像标签识别两个API接口,前者会统计”使用人脸头像”和”不使用人脸头像”的好友各自的数目,后者会累加每个头像中提取出来的标签。其分析结果如下图所示:
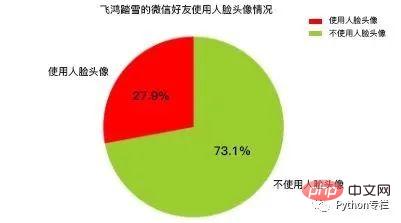
可以注意到,在所有微信好友中,约有接近1/4的微信好友使用了人脸头像, 而有接近3/4的微信好友没有人脸头像,这说明在所有微信好友中对”颜值 “有自信的人,仅仅占到好友总数的25%,或者说75%的微信好友行事风格偏低调为主,不喜欢用人脸头像做微信头像。
其次,考虑到腾讯优图并不能真正的识别”人脸”,我们这里对好友头像中的标签再次进行提取,来帮助我们了解微信好友的头像中有哪些关键词,其分析结果如图所示:

通过词云,我们可以发现:在微信好友中的签名词云中,出现频率相对较高的关键字有:女孩、树木、房屋、文本、截图、卡通、合影、天空、大海。这说明在我的微信好友中,好友选择的微信头像主要有日常、旅游、风景、截图四个来源。
好友选择的微信头像中风格以卡通为主,好友选择的微信头像中常见的要素有天空、大海、房屋、树木。通过观察所有好友头像,我发现在我的微信好友中,使用个人照片作为微信头像的有15人,使用网络图片作为微信头像的有53人,使用动漫图片作为微信头像的有25人,使用合照图片作为微信头像的有3人,使用孩童照片作为微信头像的有5人,使用风景图片作为微信头像的有13人,使用女孩照片作为微信头像的有18人,基本符合图像标签提取的分析结果。
4. 好友签名
分析好友签名,签名是好友信息中最为丰富的文本信息,按照人类惯用的”贴标签”的方法论,签名可以分析出某一个人在某一段时间里状态,就像人开心了会笑、哀伤了会哭,哭和笑两种标签,分别表明了人开心和哀伤的状态。
这里我们对签名做两种处理,第一种是使用结巴分词进行分词后生成词云,目的是了解好友签名中的关键字有哪些,哪一个关键字出现的频率相对较高;第二种是使用SnowNLP分析好友签名中的感情倾向,即好友签名整体上是表现为正面的、负面的还是中立的,各自的比重是多少。这里提取Signature字段即可,其核心代码如下:
def analyseSignature(friends):
signatures = ''
emotions = []
pattern = re.compile("1fd.+")
for friend in friends:
signature = friend['Signature']
if(signature != None):
signature = signature.strip().replace('span', '').replace('class', '').replace('emoji', '')
signature = re.sub(r'1f(d.+)','',signature)
if(len(signature)>0):
nlp = SnowNLP(signature)
emotions.append(nlp.sentiments)
signatures += ' '.join(jieba.analyse.extract_tags(signature,5))
with open('signatures.txt','wt',encoding='utf-8') as file:
file.write(signatures)
# Sinature WordCloud
back_coloring = np.array(Image.open('flower.jpg'))
wordcloud = WordCloud(
font_path='simfang.ttf',
background_color="white",
max_words=1200,
mask=back_coloring,
max_font_size=75,
random_state=45,
width=960,
height=720,
margin=15
)
wordcloud.generate(signatures)
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
wordcloud.to_file('signatures.jpg')
# Signature Emotional Judgment
count_good = len(list(filter(lambda x:x>0.66,emotions)))
count_normal = len(list(filter(lambda x:x>=0.33 and x<=0.66,emotions)))
count_bad = len(list(filter(lambda x:x<0.33,emotions)))
labels = [u'负面消极',u'中性',u'正面积极']
values = (count_bad,count_normal,count_good)
plt.rcParams['font.sans-serif'] = ['simHei']
plt.rcParams['axes.unicode_minus'] = False
plt.xlabel(u'情感判断')
plt.ylabel(u'频数')
plt.xticks(range(3),labels)
plt.legend(loc='upper right',)
plt.bar(range(3), values, color = 'rgb')
plt.title(u'%s的微信好友签名信息情感分析' % friends[0]['NickName'])
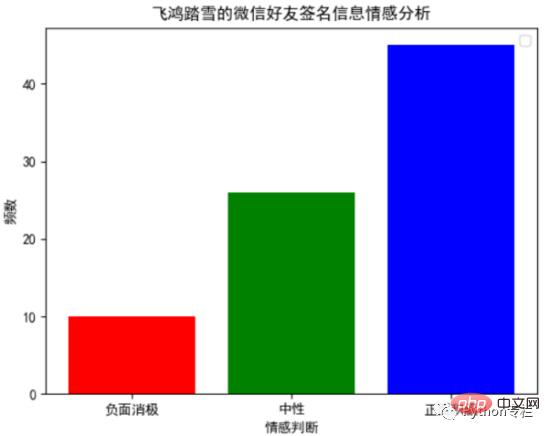
plt.show()通过词云,我们可以发现:在微信好友的签名信息中,出现频率相对较高的关键词有:努力、长大、美好、快乐、生活、幸福、人生、远方、时光、散步。

通过以下柱状图,我们可以发现:在微信好友的签名信息中,正面积极的情感判断约占到55.56%,中立的情感判断约占到32.10%,负面消极的情感判断约占到12.35%。这个结果和我们通过词云展示的结果基本吻合,这说明在微信好友的签名信息中,约有87.66%的签名信息,传达出来都是一种积极向上的态度。
5. 好友位置
分析好友位置,主要通过提取Province和City这两个字段。Python中的地图可视化主要通过Basemap模块,这个模块需要从国外网站下载地图信息,使用起来非常的不便。
百度的ECharts在前端使用的比较多,虽然社区里提供了pyecharts项目,可我注意到因为政策的改变,目前Echarts不再支持导出地图的功能,所以地图的定制方面目前依然是一个问题,主流的技术方案是配置全国各省市的JSON数据。
这里我使用的是BDP个人版,这是一个零编程的方案,我们通过Python导出一个CSV文件,然后将其上传到BDP中,通过简单拖拽就可以制作可视化地图,简直不能再简单,这里我们仅仅展示生成CSV部分的代码:
def analyseLocation(friends):
headers = ['NickName','Province','City']
with open('location.csv','w',encoding='utf-8',newline='',) as csvFile:
writer = csv.DictWriter(csvFile, headers)
writer.writeheader()
for friend in friends[1:]:
row = {}
row['NickName'] = friend['NickName']
row['Province'] = friend['Province']
row['City'] = friend['City']
writer.writerow(row)下图是BDP中生成的微信好友地理分布图,可以发现:我的微信好友主要集中在宁夏和陕西两个省份。
6. 总结
这篇文章是我对数据分析的又一次尝试,主要从性别、头像、签名、位置四个维度,对微信好友进行了一次简单的数据分析,主要采用图表和词云两种形式来呈现结果。总而言之一句话,”数据可视化是手段而并非目的”,重要的不是我们在这里做了这些图出来,而是从这些图里反映出来的现象,我们能够得到什么本质上的启示,希望这篇文章能让大家有所启发。
Atas ialah kandungan terperinci Saya menggunakan Python untuk merangkak rakan WeChat saya, mereka begini.... Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python: Contoh dan perbandingan kod
Apr 15, 2025 am 12:07 AM
PHP dan Python mempunyai kelebihan dan kekurangan mereka sendiri, dan pilihannya bergantung kepada keperluan projek dan keutamaan peribadi. 1.PHP sesuai untuk pembangunan pesat dan penyelenggaraan aplikasi web berskala besar. 2. Python menguasai bidang sains data dan pembelajaran mesin.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python vs JavaScript: Komuniti, Perpustakaan, dan Sumber
Apr 15, 2025 am 12:16 AM
Python dan JavaScript mempunyai kelebihan dan kekurangan mereka sendiri dari segi komuniti, perpustakaan dan sumber. 1) Komuniti Python mesra dan sesuai untuk pemula, tetapi sumber pembangunan depan tidak kaya dengan JavaScript. 2) Python berkuasa dalam bidang sains data dan perpustakaan pembelajaran mesin, sementara JavaScript lebih baik dalam perpustakaan pembangunan dan kerangka pembangunan depan. 3) Kedua -duanya mempunyai sumber pembelajaran yang kaya, tetapi Python sesuai untuk memulakan dengan dokumen rasmi, sementara JavaScript lebih baik dengan MDNWebDocs. Pilihan harus berdasarkan keperluan projek dan kepentingan peribadi.
 Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Cara Memilih Versi PyTorch Di Bawah Centos
Apr 14, 2025 pm 02:51 PM
Apabila memilih versi pytorch di bawah CentOS, faktor utama berikut perlu dipertimbangkan: 1. Keserasian versi CUDA Sokongan GPU: Jika anda mempunyai NVIDIA GPU dan ingin menggunakan pecutan GPU, anda perlu memilih pytorch yang menyokong versi CUDA yang sepadan. Anda boleh melihat versi CUDA yang disokong dengan menjalankan arahan NVIDIA-SMI. Versi CPU: Jika anda tidak mempunyai GPU atau tidak mahu menggunakan GPU, anda boleh memilih versi CPU PyTorch. 2. Pytorch versi python
 Cara melakukan pra -proses data dengan pytorch di centOs
Apr 14, 2025 pm 02:15 PM
Cara melakukan pra -proses data dengan pytorch di centOs
Apr 14, 2025 pm 02:15 PM
Dengan cekap memproses data pitorch pada sistem CentOS, langkah-langkah berikut diperlukan: Pemasangan Ketergantungan: Kemas kini pertama sistem dan pasang Python3 dan PIP: Sudoyumupdate-iSudoyumStallpython3-Isudoyumstallpython3-y Konfigurasi Persekitaran Maya (disyorkan): Gunakan Conda untuk membuat dan mengaktifkan persekitaran maya baru, contohnya: condacreate-n
 Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
Cara Memasang Nginx di CentOs
Apr 14, 2025 pm 08:06 PM
CentOS Memasang Nginx memerlukan mengikuti langkah-langkah berikut: memasang kebergantungan seperti alat pembangunan, pcre-devel, dan openssl-devel. Muat turun Pakej Kod Sumber Nginx, unzip dan menyusun dan memasangnya, dan tentukan laluan pemasangan sebagai/usr/local/nginx. Buat pengguna Nginx dan kumpulan pengguna dan tetapkan kebenaran. Ubah suai fail konfigurasi nginx.conf, dan konfigurasikan port pendengaran dan nama domain/alamat IP. Mulakan perkhidmatan Nginx. Kesalahan biasa perlu diberi perhatian, seperti isu ketergantungan, konflik pelabuhan, dan kesilapan fail konfigurasi. Pengoptimuman prestasi perlu diselaraskan mengikut keadaan tertentu, seperti menghidupkan cache dan menyesuaikan bilangan proses pekerja.
