

Saya percaya bahawa apabila anda menangkap data, anda akan menemui banyak parameter yang disulitkan, seperti "token", "tanda", dll. Hari ini saya akan membawa anda ke sana Ambil inventori ini algoritma penyulitan arus perdana dalam proses penangkapan data, apakah ciri-cirinya, apakah kaedah penyulitan, dsb. Mengetahui ini akan banyak membantu kami untuk memecahkan parameter yang disulitkan ini secara terbalik!
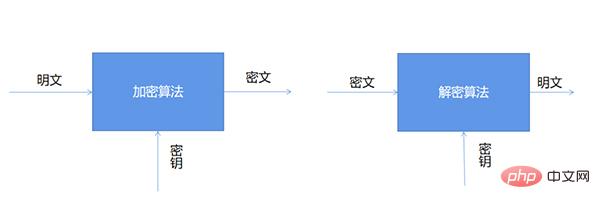
Pertama sekali, kita perlu faham, apakah penyulitan dan penyahsulitan? Seperti namanya
Operasi algoritma penyulitan dan penyahsulitan biasanya dilakukan di bawah kawalan satu set kunci, yang masing-masing merupakan kunci penyulitan (Kunci Penyulitan) dan kunci penyahsulitan (Kunci Penyahsulitan), seperti ditunjukkan di bawah Ditunjukkan:
Algoritma penyulitan dibahagikan kepada penyulitan simetri, penyulitan asimetri dan algoritma cincang, antaranya
Base64 bukanlah algoritma penyulitan dalam erti kata yang ketat. . Ia hanya kaedah pengekodan Ia menggunakan 64 aksara, iaitu A-Z, a-z, 0-9, +, /, untuk mengekod data. Pengekodan Base64 tidak boleh dibaca dan perlu dinyahkod sebelum boleh dibaca. Kami menggunakan Python untuk melakukan pengekodan Base64 pada mana-mana URL Kodnya adalah seperti berikut:
import base64
# 想将字符串转编码成base64,要先将字符串转换成二进制数据
url = "www.baidu.com"
bytes_url = url.encode("utf-8")
str_url = base64.b64encode(bytes_url)# 被编码的参数必须是二进制数据
print(str_url)Output:
b'd3d3LmJhaWR1LmNvbQ=='
Kemudian begitu juga, kita juga boleh menyahkodnya, Kodnya adalah seperti berikut:
url = "d3d3LmJhaWR1LmNvbQ=="
str_url = base64.b64decode(url).decode("utf-8")
print(str_url)Output:
www.baidu.com
MD5 ialah algoritma cincang linear yang digunakan secara meluas, dan dijana selepas penyulitan tetap-. data panjang (32-bit atau 16-bit), terdiri daripada huruf dan nombor, dengan huruf besar dan huruf kecil yang seragam. Data yang dijana oleh penyulitan akhir tidak boleh diterbalikkan, yang bermaksud bahawa ia tidak boleh dipulihkan dengan mudah kepada rentetan asal melalui data yang disulitkan, melainkan melalui perengkahan kekerasan.
Mari kita laksanakan penyulitan MD5 dalam Python:
import hashlib
str = 'this is a md5 demo.'
hl = hashlib.md5()
hl.update(str.encode(encoding='utf-8'))
print('MD5加密前为 :' + str)
print('MD5加密后为 :' + hl.hexdigest())Output:
MD5加密前为 :this is a md5 demo. MD5加密后为 :b2caf2a298a9254b38a2e33b75cfbe75
Seperti yang dinyatakan di atas, penyulitan MD5 boleh dilakukan melalui kaedah brute force cracking untuk mengurangkannya keselamatan, jadi dalam proses operasi sebenar, kami akan menambah nilai garam (Salt) atau penyulitan MD5 berganda untuk meningkatkan kebolehpercayaannya adalah seperti berikut:
# post传入的参数
params = "123456"
# 加密后需拼接的盐值(Salt)
salt = "asdfkjalksdncxvm"
def md5_encrypt():
m = md5()
m.update(params.encode('utf8'))
sign1 = m.hexdigest()
return sign1
def md5_encrypt_with_salt():
m = md5()
m.update((md5_encrypt() + salt).encode('utf8'))
sign2 = m.hexdigest()
return sign2而至于填充这一概念,AES的分组加密的特性我们需要了解,具体如下图所示:
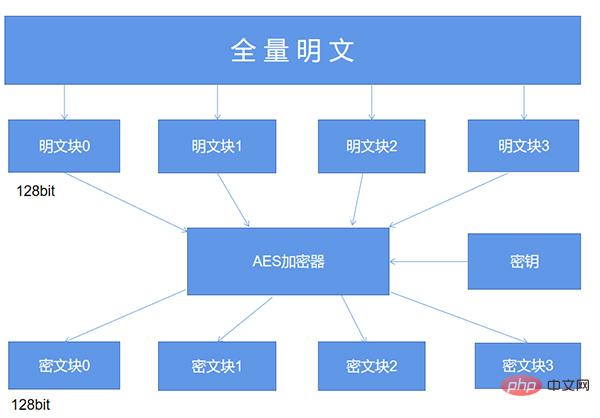
简单来说,AES算法在对明文加密的时候,并不是把整个明文一股脑儿地加密成一整段密文,而是把明文拆分成一个个独立的明文块,每一个明文块的长度为128比特。
这些明文块经过AES加密器的复杂处理之后,生成一个个独立的密文块,将这些密文块拼接到一起就是最终的AES加密的结果了。
那么这里就有一个问题了,要是有一段明文的长度是196比特,如果按照每128比特一个明文块来拆分的话,第二个明文块只有64比特了,不足128比特该怎么办呢?这个时候就轮到填充来发挥作用了,默认的填充方式是PKCS5Padding以及ISO10126Padding。
不过在AES加密的时候使用了某一种填充方式,解密的时候也必须采用同样的填充方式。
AES的工作模式,体现在了把明文块加密成密文块的处理过程中,主要有五种不同的工作模式,分别是CBC、ECB、CTR、CFB以及OFB模式,同样地,如果在AES加密过程当中使用了某一种工作模式,解密的时候也必须采用同样地工作模式。最后我们用Python来实现一下AES加密。
import base64
from Crypto.Cipher import AES
def AES_encrypt(text, key):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
text = text.encode("utf-8")
encryptor = AES.new(key.encode('utf-8'), AES.MODE_ECB)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text.decode('utf-8')或者大家也可以看一下网上其他的AES加密算法的实现过程,基本上也都是大同小异的,由于篇幅有限,今天暂时就先介绍到这里,后面要是大家感兴趣的话,会去分享一下其他加密算法的实现原理与特征。
Atas ialah kandungan terperinci Inventori algoritma penyulitan biasa yang digunakan dalam 90% perangkak Python. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



