
 Peranti teknologi
AI
Menggunakan visualisasi perisian dan pemindahan pembelajaran dalam ramalan kecacatan perisian
Peranti teknologi
AI
Menggunakan visualisasi perisian dan pemindahan pembelajaran dalam ramalan kecacatan perisian
Menggunakan visualisasi perisian dan pemindahan pembelajaran dalam ramalan kecacatan perisian

Motivasi artikel adalah untuk mengelakkan perwakilan perantaraan kod sumber, mewakili kod sumber sebagai imej dan terus mengekstrak maklumat semantik kod untuk meningkatkan prestasi ramalan kecacatan.
Pertama, lihat contoh motivasi seperti yang ditunjukkan di bawah. Walaupun kedua-dua contoh File1.java dan File2.java mengandungi 1 pernyataan if, 2 untuk pernyataan dan 4 panggilan fungsi, ciri semantik dan struktur kod adalah berbeza. Untuk mengesahkan sama ada menukar kod sumber kepada imej boleh membantu membezakan kod yang berbeza, pengarang menjalankan eksperimen: memetakan kod sumber kepada piksel mengikut nombor perpuluhan ASCII aksara, menyusunnya ke dalam matriks piksel dan mendapatkan imej kod sumber. Penulis menunjukkan bahawa terdapat perbezaan antara imej kod sumber yang berbeza.

Gamb. 1 Contoh Motivasi
Sumbangan utama artikel adalah seperti berikut:
Tukar kod kepada imej dan ekstrak maklumat semantik dan struktur daripadanya ;
Cadangkan rangka kerja hujung ke hujung yang menggabungkan mekanisme perhatian kendiri dan pemindahan pembelajaran untuk mencapai ramalan kecacatan.
Rangka kerja model yang dicadangkan dalam artikel ditunjukkan dalam Rajah 2, yang dibahagikan kepada dua peringkat: visualisasi kod sumber dan pemodelan pembelajaran pemindahan mendalam.
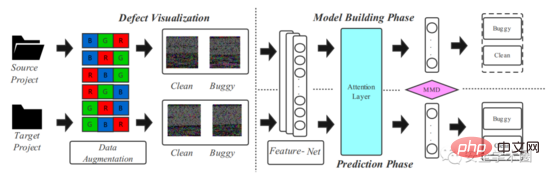
Gamb. 2 Rangka Kerja
1. Visualisasi kod sumber
Artikel menukar kod sumber kepada 6 imej, prosesnya ditunjukkan dalam Rajah 3 ditunjukkan. Tukar kod ASCII perpuluhan bagi aksara kod sumber kepada vektor integer tidak bertanda 8-bit, susun vektor ini mengikut baris dan lajur dan jana matriks imej. Integer 8-bit secara langsung sepadan dengan tahap kelabu. Untuk menyelesaikan masalah set data asal yang kecil, penulis mencadangkan kaedah pengembangan set data berdasarkan peningkatan warna dalam artikel: nilai tiga saluran warna R, G, dan B disusun dan digabungkan untuk menghasilkan 6 imej berwarna. Ia kelihatan agak mengelirukan di sini Selepas menukar nilai saluran, maklumat semantik dan struktur harus berubah, bukan? Tetapi penulis menerangkannya dalam nota kaki, seperti yang ditunjukkan dalam Rajah 4.
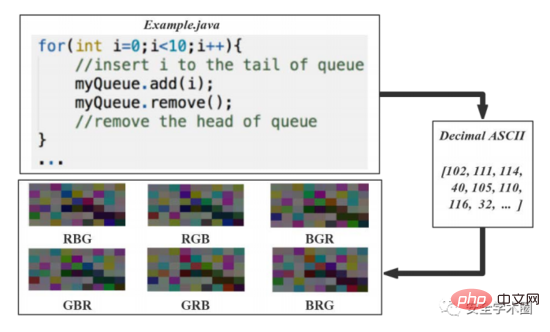
Gamb. 3 Proses visualisasi kod sumber

Gamb. 4 Nota kaki artikel 2
2 .Pemodelan Pembelajaran Pemindahan Dalam
Artikel menggunakan rangkaian DAN untuk menangkap maklumat semantik dan struktur kod sumber. Untuk meningkatkan keupayaan model untuk menyatakan maklumat penting, penulis menambah lapisan Perhatian pada struktur DAN asal. Proses latihan dan ujian ditunjukkan dalam Rajah 5, di mana conv1-conv5 datang daripada AlexNet, dan empat lapisan bersambung sepenuhnya fc6-fc9 digunakan sebagai pengelas. Penulis menyebut bahawa untuk projek baharu, melatih model pembelajaran mendalam memerlukan sejumlah besar data berlabel, yang sukar. Oleh itu, pengarang mula-mula melatih model pra-latihan pada ImageNet 2012, dan menggunakan parameter model pra-latihan sebagai parameter awal untuk memperhalusi semua lapisan konvolusi, dengan itu mengurangkan perbezaan antara imej kod dan imej dalam ImageNet 2012.
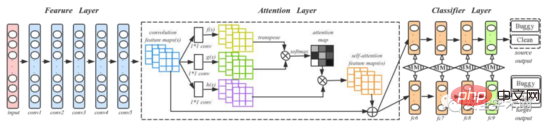
Gamb. 5 Proses latihan dan ujian
3 Latihan dan ramalan model
Kod dan Sasaran yang diberi tag dalam projek Sumber yang tidak berlabel. kod dalam projek menjana imej kod dan memasukkannya ke dalam model pada masa yang sama; kedua-duanya berkongsi lapisan konvolusi dan lapisan Perhatian untuk mengekstrak ciri masing-masing. Kira MK-MDD (Perbezaan Min Maksimum Varian Berbilang Kernel) antara Sumber dan Sasaran dalam lapisan bersambung sepenuhnya. Memandangkan Sasaran tidak mempunyai label, entropi silang hanya dikira untuk Sumber. Model ini dilatih sepanjang fungsi kehilangan menggunakan turunan kecerunan stokastik kumpulan mini. Untuk setiap
Dalam bahagian percubaan, pengarang memilih semua projek Java sumber terbuka dalam gudang data PROMISE dan mengumpul nombor versi, nama kelas dan sama ada terdapat teg pepijat. Muat turun kod sumber daripada github berdasarkan nombor versi dan nama kelas. Akhirnya, data daripada 10 projek Java telah dikumpulkan. Struktur set data ditunjukkan dalam Rajah 6.
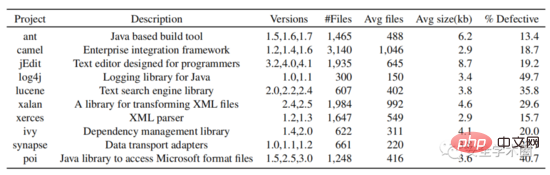
Gamb. 6 Struktur set data
Untuk ramalan kecacatan dalam projek, artikel memilih model garis dasar berikut untuk perbandingan:

Untuk ramalan kecacatan merentas projek, artikel memilih model garis dasar berikut untuk perbandingan:

Untuk meringkaskan, walaupun kertas itu ditulis dua tahun lalu, ideanya ialah masih agak baru , mengelakkan satu siri perwakilan perantaraan kod seperti AST, dan secara langsung menukar kod kepada ciri pengekstrakan imej. Tetapi saya masih keliru Adakah imej yang ditukar daripada kod benar-benar mengandungi maklumat semantik dan struktur kod sumber? Rasanya tak boleh dijelaskan sangat, haha. Kita perlu melakukan beberapa analisis eksperimen kemudian.
Atas ialah kandungan terperinci Menggunakan visualisasi perisian dan pemindahan pembelajaran dalam ramalan kecacatan perisian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Apakah perisian bonjour dan bolehkah ia dinyahpasang?
Feb 20, 2024 am 09:33 AM
Apakah perisian bonjour dan bolehkah ia dinyahpasang?
Feb 20, 2024 am 09:33 AM
Tajuk: Terokai perisian Bonjour dan cara menyahpasangnya Abstrak: Artikel ini akan memperkenalkan fungsi, skop penggunaan dan cara menyahpasang perisian Bonjour. Pada masa yang sama, ia juga akan diterangkan cara menggunakan alatan lain bagi menggantikan Bonjour bagi memenuhi keperluan pengguna. Pengenalan: Bonjour ialah perisian biasa dalam bidang teknologi komputer dan rangkaian. Walaupun ini mungkin tidak biasa bagi sesetengah pengguna, ia boleh menjadi sangat berguna dalam beberapa situasi tertentu. Jika anda telah memasang perisian Bonjour tetapi kini ingin menyahpasangnya, maka
 Apa yang perlu dilakukan jika WPS Office tidak boleh membuka fail PPT - Apa yang perlu dilakukan jika WPS Office tidak boleh membuka fail PPT
Mar 04, 2024 am 11:40 AM
Apa yang perlu dilakukan jika WPS Office tidak boleh membuka fail PPT - Apa yang perlu dilakukan jika WPS Office tidak boleh membuka fail PPT
Mar 04, 2024 am 11:40 AM
Baru-baru ini, ramai rakan bertanya kepada saya apa yang perlu dilakukan sekiranya WPSOffice tidak dapat membuka fail PPT Seterusnya, mari kita belajar bagaimana untuk menyelesaikan masalah WPSOffice tidak dapat membuka fail PPT. 1. Mula-mula buka WPSOffice dan masukkan halaman utama, seperti yang ditunjukkan dalam rajah di bawah. 2. Kemudian masukkan kata kunci "pembaikan dokumen" dalam bar carian di atas, dan kemudian klik untuk membuka alat pembaikan dokumen, seperti yang ditunjukkan dalam rajah di bawah. 3. Kemudian import fail PPT untuk pembaikan, seperti yang ditunjukkan dalam rajah di bawah.
 Apakah perisian crystaldiskmark? -Bagaimana menggunakan crystaldiskmark?
Mar 18, 2024 pm 02:58 PM
Apakah perisian crystaldiskmark? -Bagaimana menggunakan crystaldiskmark?
Mar 18, 2024 pm 02:58 PM
CrystalDiskMark ialah alat penanda aras HDD kecil untuk pemacu keras yang cepat mengukur kelajuan baca/tulis berurutan dan rawak. Seterusnya, biarkan editor memperkenalkan CrystalDiskMark kepada anda dan cara menggunakan crystaldiskmark~ 1. Pengenalan kepada CrystalDiskMark CrystalDiskMark ialah alat ujian prestasi cakera yang digunakan secara meluas yang digunakan untuk menilai kelajuan baca dan tulis serta prestasi pemacu keras mekanikal dan pemacu keadaan pepejal (SSD Prestasi I/O rawak. Ia adalah aplikasi Windows percuma dan menyediakan antara muka mesra pengguna dan pelbagai mod ujian untuk menilai aspek prestasi cakera keras yang berbeza dan digunakan secara meluas dalam ulasan perkakasan
![Perisian Corsair iCUE tidak mengesan RAM [Tetap]](https://img.php.cn/upload/article/000/465/014/170831448976874.png?x-oss-process=image/resize,m_fill,h_207,w_330) Perisian Corsair iCUE tidak mengesan RAM [Tetap]
Feb 19, 2024 am 11:48 AM
Perisian Corsair iCUE tidak mengesan RAM [Tetap]
Feb 19, 2024 am 11:48 AM
Artikel ini akan meneroka perkara yang boleh dilakukan oleh pengguna apabila perisian CorsairiCUE tidak mengenali RAM dalam sistem Windows. Walaupun perisian CorsairiCUE direka untuk membenarkan pengguna mengawal pencahayaan RGB komputer mereka, sesetengah pengguna mendapati bahawa perisian itu tidak berfungsi dengan betul, mengakibatkan ketidakupayaan untuk mengesan modul RAM. Mengapa ICUE tidak mengambil ingatan saya? Sebab utama mengapa ICUE tidak dapat mengenal pasti RAM dengan betul biasanya berkaitan dengan konflik perisian latar belakang Selain itu, tetapan tulis SPD yang salah juga boleh menyebabkan masalah ini. Isu dengan perisian CorsairIcue tidak mengesan RAM telah diperbaiki Jika perisian CorsairIcue tidak mengesan RAM pada komputer Windows anda, sila gunakan cadangan berikut.
 Tutorial penggunaan CrystalDiskinfo-Apakah perisian CrystalDiskinfo?
Mar 18, 2024 pm 04:50 PM
Tutorial penggunaan CrystalDiskinfo-Apakah perisian CrystalDiskinfo?
Mar 18, 2024 pm 04:50 PM
CrystalDiskInfo ialah perisian yang digunakan untuk menyemak peranti perkakasan komputer Dalam perisian ini, kita boleh menyemak perkakasan komputer kita sendiri, seperti kelajuan membaca, mod penghantaran, antara muka, dll.! Jadi sebagai tambahan kepada fungsi ini, bagaimana untuk menggunakan CrystalDiskInfo dan apakah sebenarnya CrystalDiskInfo Izinkan saya menyelesaikannya untuk anda! 1. Asal Usul CrystalDiskInfo Sebagai salah satu daripada tiga komponen utama hos komputer, pemacu keadaan pepejal ialah medium storan komputer dan bertanggungjawab untuk penyimpanan data komputer Pemacu keadaan pepejal yang baik boleh mempercepatkan pembacaan fail dan mempengaruhi pengalaman pengguna. Apabila pengguna menerima peranti baharu, mereka boleh menggunakan perisian pihak ketiga atau SSD lain untuk
 Bagaimana untuk menetapkan kenaikan papan kekunci dalam Adobe Illustrator CS6 - Bagaimana untuk menetapkan kenaikan papan kekunci dalam Adobe Illustrator CS6
Mar 04, 2024 pm 06:04 PM
Bagaimana untuk menetapkan kenaikan papan kekunci dalam Adobe Illustrator CS6 - Bagaimana untuk menetapkan kenaikan papan kekunci dalam Adobe Illustrator CS6
Mar 04, 2024 pm 06:04 PM
Ramai pengguna menggunakan perisian Adobe Illustrator CS6 di pejabat mereka, jadi adakah anda tahu bagaimana untuk menetapkan kenaikan papan kekunci dalam Adobe Illustrator CS6 Kemudian, editor akan membawakan kepada anda kaedah menetapkan kenaikan papan kekunci dalam Adobe Illustrator CS6 Pengguna yang berminat boleh lihat di bawah. Langkah 1: Mulakan perisian Adobe Illustrator CS6, seperti yang ditunjukkan dalam rajah di bawah. Langkah 2: Dalam bar menu, klik perintah [Edit] → [Keutamaan] → [Umum] dalam urutan. Langkah 3: Kotak dialog [Keyboard Increment] muncul, masukkan nombor yang diperlukan dalam kotak teks [Keyboard Increment], dan akhirnya klik butang [OK]. Langkah 4: Gunakan kekunci pintasan [Ctrl]
 Apakah jenis perisian bonjour Adakah ia berguna?
Feb 22, 2024 pm 08:39 PM
Apakah jenis perisian bonjour Adakah ia berguna?
Feb 22, 2024 pm 08:39 PM
Bonjour ialah protokol rangkaian dan perisian yang dilancarkan oleh Apple untuk menemui dan mengkonfigurasi perkhidmatan rangkaian dalam rangkaian kawasan setempat. Peranan utamanya ialah untuk menemui dan berkomunikasi secara automatik antara peranti yang disambungkan dalam rangkaian yang sama. Bonjour pertama kali diperkenalkan dalam versi MacOSX10.2 pada tahun 2002, dan kini dipasang dan didayakan secara lalai dalam sistem pengendalian Apple. Sejak itu, Apple telah membuka teknologi Bonjour kepada pengeluar lain, jadi banyak sistem pengendalian dan peranti lain juga boleh menyokong Bonjour.
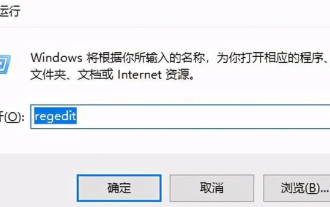 Bagaimana untuk menyelesaikan percubaan perisian yang tidak serasi untuk dimuatkan dengan Edge?
Mar 15, 2024 pm 01:34 PM
Bagaimana untuk menyelesaikan percubaan perisian yang tidak serasi untuk dimuatkan dengan Edge?
Mar 15, 2024 pm 01:34 PM
Apabila kami menggunakan penyemak imbas Edge, kadangkala perisian yang tidak serasi cuba dimuatkan bersama, jadi apa yang sedang berlaku? Biarkan tapak ini dengan teliti memperkenalkan kepada pengguna cara menyelesaikan masalah cuba memuatkan perisian yang tidak serasi dengan Edge. Cara menyelesaikan perisian yang tidak serasi yang cuba dimuatkan dengan Edge Solution 1: Cari IE dalam menu mula dan akses terus dengan IE. Penyelesaian 2: Nota: Mengubah suai pendaftaran boleh menyebabkan kegagalan sistem, jadi kendalikan dengan berhati-hati. Ubah suai parameter pendaftaran. 1. Masukkan regedit semasa operasi. 2. Cari laluan\HKEY_LOCAL_MACHINE\SOFTWARE\Policies\Micros
