
 Peranti teknologi
AI
Mengapa ChatGPT begitu berkuasa: penjelasan terperinci tentang artikel sepanjang 10,000 perkataan oleh bapa WolframAlpha
Peranti teknologi
AI
Mengapa ChatGPT begitu berkuasa: penjelasan terperinci tentang artikel sepanjang 10,000 perkataan oleh bapa WolframAlpha
Mengapa ChatGPT begitu berkuasa: penjelasan terperinci tentang artikel sepanjang 10,000 perkataan oleh bapa WolframAlpha

Stephen Wolfram, bapa kepada Bahasa Wolfram, telah datang untuk menyokong ChatGPT sekali lagi.
Bulan lepas, dia juga menulis artikel secara khusus mengesyorkan enjin carian pengetahuan pengkomputerannya sendiri WolframAlpha, berharap untuk mempunyai gabungan sempurna dengan ChatGPT.
Ini mungkin bermaksud, "Jika kuasa pengkomputeran anda tidak mencapai standard, maka anda boleh menyuntik 'kuasa besar' saya ke dalamnya."

Selepas lebih sebulan, Stephen Wolfram menerbitkan semula dua soalan: "Apakah itu ChatGPT" dan "Mengapa ia begitu berkesan?" artikel panjang 10,000 patah perkataan memberikan penjelasan terperinci dalam istilah yang mudah dan mudah difahami.

(Untuk memastikan pengalaman membaca, kandungan berikut akan diceritakan oleh Stephen Wolfram dalam orang pertama; terdapat telur easter di akhir artikel itu!)
Tambah satu perkataan pada satu masa
Keupayaan ChatGPT untuk menjana teks secara automatik yang menyerupai teks tulisan manusia adalah luar biasa dan tidak dijangka. Jadi, bagaimana ia dicapai? Mengapakah ia berfungsi dengan baik dalam menghasilkan teks yang bermakna?
Dalam artikel ini, saya akan memberikan anda gambaran keseluruhan kerja dalaman ChatGPT dan meneroka sebab ia berjaya menghasilkan teks yang memuaskan.
Perlu diingatkan bahawa saya akan memberi tumpuan kepada mekanisme keseluruhan ChatGPT Walaupun saya akan menyebut beberapa butiran teknikal, saya tidak akan membincangkan secara mendalam. Pada masa yang sama, perlu ditekankan bahawa apa yang saya katakan juga terpakai kepada "model bahasa besar" (LLM) semasa yang lain, bukan hanya ChatGPT.
Perkara pertama yang perlu dijelaskan ialah tugas teras ChatGPT adalah sentiasa menjana "kesinambungan yang munasabah", iaitu, berdasarkan teks sedia ada, menjana kandungan munasabah seterusnya yang sesuai dengan tulisan manusia tabiat. Apa yang dipanggil "munasabah" merujuk kepada membuat kesimpulan kandungan yang mungkin muncul seterusnya berdasarkan corak statistik berbilion halaman web, buku digital dan kandungan tulisan manusia yang lain.
Sebagai contoh, jika kita memasukkan teks "Perkara terbaik tentang AI ialah kuasanya", ChatGPT akan mencari teks yang serupa dalam berbilion halaman teks manusia, dan kemudian mengira kebarangkalian perkataan seterusnya muncul. Perlu diingat bahawa ChatGPT tidak membandingkan secara langsung teks itu sendiri, tetapi berdasarkan pengertian tertentu "padanan makna". Akhirnya, ChatGPT akan menjana senarai perkataan yang mungkin dan memberikan setiap perkataan kedudukan kebarangkalian:

Perlu diperhatikan bahawa apabila ChatGPT selesai Dengan tugasan seperti menulis artikel, ia benar-benar hanya bertanya berulang kali: "Memandangkan teks yang sudah ada, apakah perkataan seterusnya - dan menambah perkataan (lebih tepat) setiap kali , seperti yang saya jelaskan, ia menambah "?" token", yang mungkin hanya sebahagian daripada perkataan, itulah sebabnya ia kadang-kadang "mencipta perkataan baharu").
Pada setiap langkah ia mendapat senarai perkataan dengan kebarangkalian. Tetapi perkataan manakah yang harus dipilih untuk ditambahkan pada artikel (atau apa-apa lagi) yang ditulisnya?
Seseorang mungkin berpendapat bahawa perkataan "peringkat tertinggi" (iaitu perkataan yang diberikan "kebarangkalian" tertinggi) harus dipilih. Tetapi di sinilah sesuatu yang misteri mula menjalar masuk. Kerana atas sebab tertentu - dan mungkin suatu hari nanti kita akan mempunyai kefahaman saintifik - jika kita sentiasa memilih perkataan peringkat tertinggi, kita biasanya berakhir dengan artikel yang sangat "hambar" yang tidak pernah menunjukkan sebarang kreativiti ( Kadang-kadang berulang-ulang verbatim). Jika kadangkala (secara rawak) kita memilih perkataan yang berperingkat rendah, kita mungkin mendapat artikel yang "lebih menarik".
Kehadiran rawak di sini bermakna jika kami menggunakan gesaan yang sama beberapa kali, kemungkinan besar kami akan mendapat artikel yang berbeza setiap kali. Selaras dengan konsep voodoo, terdapat parameter khusus yang dipanggil "suhu" dalam proses, yang menentukan kekerapan perkataan yang lebih rendah akan digunakan Untuk penjanaan artikel, "suhu" ini paling baik ditetapkan kepada 0.8. Perlu ditekankan bahawa "teori" tidak digunakan di sini, ia hanya fakta yang telah terbukti berkesan dalam amalan. Sebagai contoh, konsep "suhu" wujud kerana taburan eksponen (taburan biasa dari fizik statistik) kebetulan digunakan, tetapi tidak ada hubungan "fizikal" antara mereka, sekurang-kurangnya setakat yang kita tahu.
Sebelum saya meneruskan, saya harus menjelaskan bahawa demi pembentangan, saya tidak menggunakan sistem penuh dalam ChatGPT pada kebanyakan masa, sebaliknya, saya biasanya menggunakan sistem GPT-2 yang lebih mudah, yang mempunyai Ciri yang hebat, iaitu; ia cukup kecil untuk dijalankan pada komputer meja standard. Oleh itu, hampir semua yang saya tunjukkan akan mengandungi kod Bahasa Wolfram yang jelas yang boleh anda jalankan pada komputer anda dengan segera.
Sebagai contoh, gambar di bawah menunjukkan cara untuk mendapatkan jadual kebarangkalian di atas. Mula-mula, kita mesti mendapatkan semula rangkaian neural "Model Bahasa" yang mendasari:

Kemudian, kita akan menyelami rangkaian saraf ini dan membincangkan apakah itu Bagaimana ia berfungsi. Tetapi buat masa ini, kami boleh menggunakan "model rangkaian" ini pada teks kami sebagai kotak hitam dan meminta 5 perkataan teratas berdasarkan kebarangkalian model fikir ia patut mengikuti:

Setelah keputusan diperoleh, ia ditukar kepada "set data" yang diformatkan secara eksplisit:

di bawah ialah kes berulang kali "menggunakan model" - menambah pada setiap langkah perkataan dengan kebarangkalian tertinggi (dinyatakan dalam kod ini sebagai "keputusan" dalam model):

Apa yang akan berlaku jika kita teruskan? Dalam situasi ("sifar darjah") ini, situasi yang agak mengelirukan dan berulang boleh berkembang dengan cepat.

Tetapi jika bukannya sentiasa memilih perkataan "atas", anda kadangkala secara rawak memilih perkataan "bukan atas" ("rawak" sepadan dengan "suhu" "adalah 0.8)? Kita boleh terus menulis teks sekali lagi:

Setiap kali kita melakukan ini, akan ada pilihan rawak yang berbeza dan teks yang sepadan akan berbeza. Sebagai contoh, 5 contoh berikut:

Perlu dinyatakan bahawa walaupun dalam langkah pertama, terdapat banyak kemungkinan "Perkataan seterusnya" adalah tersedia untuk pemilihan (pada suhu 0.8), walaupun kebarangkaliannya berkurangan dengan cepat (ya, garis lurus pada plot logaritma ini sepadan dengan pereputan "undang kuasa" n–1 , yang merupakan ciri statistik umum bahasa):

Jadi apa yang akan berlaku jika kita terus menulis? Berikut ialah contoh rawak. Ia lebih baik sedikit daripada menggunakan perkataan berperingkat tertinggi (darjah sifar), tetapi masih agak pelik:

Ini ialah GPT paling mudah untuk digunakan - 2 model (dari 2019) selesai. Hasilnya lebih baik menggunakan model GPT-3 yang lebih besar yang lebih baru. Berikut ialah teks menggunakan perkataan kedudukan tertinggi (sifar darjah) yang dijana menggunakan "petunjuk" yang sama tetapi menggunakan model GPT-3 terbesar:

Seterusnya ialah contoh rawak "suhu ialah 0.8":

Dari manakah datangnya kebarangkalian ini?
ChatGPT sentiasa memilih perkataan seterusnya berdasarkan kebarangkalian. Tetapi dari mana datangnya kebarangkalian ini?
Mari kita mulakan dengan soalan yang lebih mudah. Apabila kita mempertimbangkan untuk menjana teks bahasa Inggeris huruf demi huruf (bukan perkataan demi perkataan), bagaimanakah kita menentukan kebarangkalian setiap huruf?
Cara paling mudah ialah mengambil sampel teks bahasa Inggeris dan mengira kekerapan huruf yang berbeza di dalamnya. Contohnya, berikut ialah cara huruf untuk "kucing" muncul dalam rencana Wikipedia (kiraan ditiadakan di sini):

Ini ialah "anjing" ” kes:

Hasilnya adalah serupa, tetapi tidak betul-betul sama (lagipun, “o” lebih biasa dalam artikel “anjing” kerana ia sendiri muncul dalam perkataan "anjing"). Walau bagaimanapun, jika kita mengambil sampel teks bahasa Inggeris yang cukup besar, akhirnya kita boleh mengharapkan untuk mendapat sekurang-kurangnya hasil yang agak konsisten:

Di sini kami hanya menggunakan kebarangkalian ini Contoh menjana urutan huruf:

Kita boleh memecahkannya kepada "perkataan" dengan, katakan, merawat ruang sebagai huruf dengan huruf tertentu kebarangkalian :

boleh membahagikan "perkataan" dengan lebih baik dengan memaksa pengedaran "panjang perkataan" selaras dengan bahasa Inggeris:

Di sini kami tidak menghasilkan sebarang "perkataan sebenar", tetapi hasilnya kelihatan lebih baik sedikit. Walau bagaimanapun, untuk pergi lebih jauh, kita memerlukan lebih banyak kerja daripada hanya memilih setiap huruf secara rawak. Sebagai contoh, kita tahu bahawa jika "q" muncul, huruf seterusnya pada asasnya mestilah "u".
Ini ialah peta kebarangkalian bagi huruf itu sendiri:

Ini ialah sepasang huruf biasa dalam teks bahasa Inggeris ("2 -gram") plot kebarangkalian. Paksi mendatar ialah huruf pertama yang mungkin, paksi menegak ialah huruf kedua (plot kebarangkalian ditiadakan di sini):

Di sini, Kita boleh lihat lajur "q" kosong di mana-mana kecuali pada baris "u" (kebarangkalian sifar). Nah, sekarang daripada menjana "perkataan" huruf demi huruf, kami menjananya menggunakan kebarangkalian "2 gram" ini, dua huruf pada satu masa. Berikut ialah contoh keputusan - yang kebetulan termasuk beberapa "perkataan sebenar":

Dengan teks bahasa Inggeris yang mencukupi, kita bukan sahaja boleh mendapatkan yang bagus Anggarkan kebarangkalian satu huruf atau pasangan huruf (2-gram), dan juga kombinasi huruf yang lebih panjang. Jika kita menggunakan kebarangkalian n-gram yang lebih panjang secara progresif untuk menjana "perkataan rawak", kita akan mendapati bahawa ia beransur-ansur menjadi "lebih realistik".

Tetapi sekarang mari kita anggap bahawa – seperti ChatGPT – kita berurusan dengan keseluruhan perkataan, bukan huruf. Terdapat kira-kira 40,000 perkataan biasa dalam bahasa Inggeris. Dengan melihat sejumlah besar teks bahasa Inggeris (cth. berjuta-juta buku dengan berpuluh-puluh bilion perkataan), kita boleh menganggarkan kekerapan setiap perkataan. Menggunakan anggaran ini, kita boleh mula menjana "ayat" di mana setiap perkataan dipilih secara bebas secara rawak dengan kebarangkalian yang sama bahawa ia muncul dalam korpus. Berikut ialah contoh perkara yang kami dapat:

Tidak menghairankan, ini mengarut. Jadi apa yang boleh kita lakukan untuk menghasilkan ayat yang lebih baik? Sama seperti dengan huruf, kita boleh mula memikirkan kebarangkalian bukan sahaja perkataan, tetapi juga pasangan perkataan atau n-gram yang lebih panjang. Untuk pasangan perkataan, berikut ialah 5 contoh, semuanya bermula dengan perkataan "kucing":

nampak sedikit "lebih bermakna" sedikit. Jika kita boleh menggunakan n-gram yang cukup panjang, kita mungkin membayangkan pada dasarnya "mendapatkan ChatGPT" - iaitu, kita akan mendapat sesuatu yang menjana urutan teks panjang dengan "kebarangkalian artikel keseluruhan yang betul". Tetapi inilah perkaranya: tidak cukup teks bahasa Inggeris yang sebenarnya telah ditulis untuk dapat menyimpulkan kebarangkalian ini.
Mungkin terdapat berpuluh bilion perkataan dalam perangkak web; mungkin terdapat berpuluh bilion lagi perkataan dalam buku digital. Tetapi walaupun dengan 40,000 perkataan biasa, bilangan kemungkinan 2-tuple sudah 1.6 bilion, dan bilangan kemungkinan 3-tuple adalah 60 trilion. Oleh itu, kita tidak boleh menganggarkan kebarangkalian kemungkinan ini daripada teks sedia ada. Pada masa kita perlu menjana "coretan esei" 20 perkataan, bilangan kemungkinan sudah melebihi bilangan zarah di alam semesta, jadi dalam satu erti kata ia tidak boleh ditulis semuanya.
Jadi, apa yang perlu kita lakukan? Idea utama ialah membina model yang membolehkan kita menganggarkan kebarangkalian jujukan harus berlaku, walaupun kita tidak pernah melihat jujukan ini secara eksplisit dalam korpus teks yang sedang kita lihat. Pada teras ChatGPT ialah apa yang dipanggil "model bahasa besar" (LLM), yang dibina untuk menganggarkan kebarangkalian ini dengan baik.
(Atas sebab ruang, "Apakah itu model", "Rangkaian Neural", "Pembelajaran Mesin dan Latihan Rangkaian Neural", "Amalan dan Pengetahuan Latihan Rangkaian Neural", "Konsep Pembenaman", dsb. ditiadakan di sini Penyusunan bab, pembaca yang berminat boleh membaca teks asal sendiri)
Struktur dalaman ChatGPT
Tidak syak lagi bahawa ia akhirnya merupakan rangkaian saraf yang besar, dan semasa versi adalah satu dengan rangkaian GPT-3 175 bilion berat. Dalam banyak cara, rangkaian saraf ini sangat serupa dengan rangkaian saraf lain yang telah kami bincangkan, tetapi ia adalah rangkaian saraf yang direka khusus untuk memproses bahasa. Ciri yang paling ketara ialah seni bina rangkaian saraf yang dipanggil "Transformer."
Dalam jenis rangkaian saraf pertama yang kita bincangkan di atas, setiap neuron dalam mana-mana lapisan tertentu pada asasnya disambungkan (dengan sekurang-kurangnya sedikit berat) kepada setiap neuron dalam lapisan sebelumnya. Walau bagaimanapun, rangkaian bersambung sepenuhnya sedemikian (mungkin) berlebihan jika anda ingin memproses data dengan struktur tertentu yang diketahui. Oleh itu, pada peringkat awal pemprosesan imej, adalah perkara biasa untuk menggunakan rangkaian saraf konvolusional ("convnets"), di mana neuron sebenarnya disusun pada grid yang serupa dengan piksel imej, dan hanya berinteraksi dengan neuron berhampiran grid disambungkan.
Idea Transformer adalah untuk melakukan sekurang-kurangnya sesuatu yang serupa dengan urutan token yang membentuk teks. Walau bagaimanapun, Transformer bukan sahaja mentakrifkan kawasan tetap di mana sambungan boleh dibuat, ia juga memperkenalkan konsep "perhatian" - konsep "perhatian" lebih memfokuskan pada bahagian tertentu urutan daripada yang lain. Mungkin suatu hari nanti masuk akal untuk melancarkan rangkaian saraf am dengan semua penyesuaian melalui latihan. Tetapi dalam amalan sekurang-kurangnya buat masa ini, memodulasi perkara adalah penting, sama seperti Transformers, dan mungkin perkara yang dilakukan oleh otak kita juga.
Jadi, apakah sebenarnya yang dilakukan oleh ChatGPT (atau, lebih tepat lagi, rangkaian GPT-3 yang berasaskannya)? Ingat, matlamat keseluruhannya ialah untuk terus menulis teks secara "munasabah" berdasarkan apa yang dilihat daripada latihan (yang termasuk melihat teks daripada berbilion-bilion halaman di seluruh web dan seterusnya). Jadi, pada bila-bila masa, ia mempunyai jumlah teks tertentu, dan matlamatnya adalah untuk memilih pilihan yang sesuai untuk token seterusnya.
Pengendalian ChatGPT adalah berdasarkan tiga peringkat asas. Pertama, ia memperoleh urutan token yang sepadan dengan teks semasa dan mencari pembenaman (iaitu, tatasusunan nombor) yang mewakilinya. Ia kemudiannya beroperasi pada pembenaman ini dalam "cara rangkaian neural standard", menyebabkan nilai "berubah-ubah" melalui lapisan berturut-turut dalam rangkaian untuk menghasilkan pembenaman baharu (iaitu tatasusunan nombor baharu). Seterusnya, ia mengambil bahagian terakhir tatasusunan itu dan menjana tatasusunan yang mengandungi kira-kira 50,000 nilai yang diterjemahkan kepada kebarangkalian token seterusnya yang berbeza dan berkemungkinan (ya, terdapat bilangan token yang sama seperti perkataan Inggeris biasa, walaupun Hanya kira-kira 3000 token ialah perkataan yang lengkap, selebihnya adalah serpihan)
Intinya ialah setiap bahagian saluran paip ini dilaksanakan oleh rangkaian saraf, dan beratnya ditentukan oleh latihan hujung ke hujung rangkaian . Dalam erti kata lain, tiada apa yang sebenarnya "reka bentuk secara eksplisit" kecuali seni bina keseluruhannya "dipelajari" daripada data latihan.
Walau bagaimanapun, terdapat banyak butiran dalam cara seni bina dibina - mencerminkan pelbagai pengalaman dan pengetahuan tentang rangkaian saraf. Walaupun ini adalah perkara yang terperinci, saya fikir adalah berguna untuk membincangkan beberapa butiran ini untuk sekurang-kurangnya memahami perkara yang diperlukan untuk membina ChatGPT.
Yang pertama ialah modul benam. Ini ialah gambarajah skematik GPT-2, dinyatakan dalam Bahasa Wolfram:

Teks ini memperkenalkan modul yang dipanggil "modul terbenam", Ia mempunyai tiga langkah utama. Dalam langkah pertama, teks ditukar kepada jujukan token, dan setiap token ditukar menjadi vektor benam dengan panjang 768 (untuk GPT-2) atau 12288 (untuk GPT-3 ChatGPT) menggunakan rangkaian neural satu lapisan . Pada masa yang sama, terdapat juga "laluan sekunder" dalam modul, yang digunakan untuk menukar kedudukan integer token kepada vektor pembenaman. Akhir sekali, nilai token dan vektor benam kedudukan token ditambah bersama untuk menjana jujukan vektor benam terakhir.
Mengapa kita menambah nilai token dan vektor pembenaman kedudukan token? Nampaknya tidak ada penjelasan yang saintifik. Baru sahaja mencuba banyak perkara yang berbeza dan yang ini nampaknya berkesan. Dan tradisi rangkaian saraf juga berpendapat bahawa selagi tetapan awal adalah "kira-kira betul," dengan latihan yang mencukupi, butiran biasanya boleh diselaraskan secara automatik tanpa benar-benar "memahami bagaimana rangkaian saraf direkayasa."
Fungsi modul "membenamkan modul" ini adalah untuk menukar teks kepada jujukan vektor benam. Mengambil rentetan "hello hello hello hello hello hello hello hello hello bye bye bye bye bye bye bye bye bye bye bye" sebagai contoh, ia boleh ditukar menjadi satu siri vektor benam dengan panjang 768, termasuk dari setiap token Maklumat diekstrak daripada nilai dan lokasi.

Elemen setiap vektor pembenaman token ditunjukkan di sini Satu siri benam "hello" dipaparkan secara mendatar, diikuti dengan siri "bye". membenamkan. Tatasusunan kedua di atas ialah pembenaman kedudukan, yang strukturnya nampak rawak kebetulan dipelajari (dalam kes ini dalam GPT-2).
Baiklah, selepas modul benam datang "bahagian utama" Transformer: satu siri yang dipanggil "blok perhatian" (12 untuk GPT-2, 96 untuk GPT-3 ChatGPT). Ini adalah kompleks dan mengingatkan sistem kejuruteraan besar atau sistem biologi yang biasanya tidak dapat difahami. Walau bagaimanapun, berikut ialah gambar rajah "blok perhatian" tunggal GPT-2:

Dalam setiap blok perhatian, terdapat satu set " kepala perhatian" (GPT-2 mempunyai 12, GPT-3 ChatGPT mempunyai 96), setiap kepala perhatian bertindak secara bebas pada blok nilai yang berbeza dalam vektor benam. (Ya, kami tidak tahu faedah membahagikan vektor benam menjadi bahagian, mahupun maksud bahagian berbezanya; ini hanyalah salah satu teknik yang didapati berkesan.)
Jadi, apakah fungsi kepala perhatian? Pada asasnya, ia adalah cara untuk "menoleh ke belakang" pada urutan token (iaitu teks yang telah dijana) dan "membungkus" maklumat sejarah dalam bentuk yang berguna untuk mencari token seterusnya dengan mudah. Di atas, kami menyebut menggunakan kebarangkalian binari untuk memilih perkataan berdasarkan token sebelumnya. Mekanisme "perhatian" dalam Transformer membenarkan "perhatian" kepada perkataan awal, yang berpotensi menangkap, contohnya, cara kata kerja merujuk kepada kata nama yang muncul berbilang perkataan di hadapan mereka dalam ayat.
Secara khusus, peranan ketua perhatian adalah untuk menggabungkan semula blok pembenaman vektor yang berkaitan dengan token yang berbeza dan memberi mereka berat tertentu. Jadi, sebagai contoh, 12 kepala perhatian dalam blok perhatian pertama dalam GPT-2 mempunyai yang berikut ("lihat kembali urutan token ke permulaan") corak "kumpul semula berat" untuk rentetan "hello, bye" di atas: 🎜>






Ini berbeza sama sekali daripada sistem pengkomputeran biasa seperti mesin Turing, yang berulang kali "memproses semula" keputusan melalui elemen pengiraan yang sama. Di sini - sekurang-kurangnya dari segi menjana token output yang diberikan - setiap elemen pengiraan (iaitu neuron) digunakan sekali sahaja.
Tetapi masih terdapat rasa "gelung luar" dalam ChatGPT, yang digunakan semula walaupun dalam elemen yang dikira. Kerana apabila ChatGPT ingin menjana token baharu, ia sentiasa "membaca" (iaitu menggunakannya sebagai input) keseluruhan jujukan token yang muncul sebelum itu, termasuk token yang sebelum ini "ditulis" oleh ChatGPT sendiri. Kita boleh menganggap persediaan ini sebagai bermakna bahawa ChatGPT melibatkan sekurang-kurangnya "gelung maklum balas" pada tahap paling luarnya, walaupun setiap lelaran boleh dilihat secara eksplisit sebagai token yang muncul dalam teks yang dihasilkannya.
Mari kita kembali ke teras ChatGPT: rangkaian saraf yang digunakan untuk menjana setiap token. Pada satu peringkat, ia sangat mudah: koleksi neuron buatan yang serupa. Sesetengah bahagian rangkaian hanya terdiri daripada ("bersambung sepenuhnya") lapisan neuron, di mana setiap neuron pada lapisan itu disambungkan (dengan sedikit berat) kepada setiap neuron pada lapisan sebelumnya. Tetapi terutamanya dalam seni bina Transformernya, ChatGPT mempunyai bahagian yang lebih berstruktur di mana hanya neuron tertentu pada lapisan tertentu disambungkan. (Sudah tentu, seseorang masih boleh mengatakan "semua neuron disambungkan" - tetapi sesetengah neuron mempunyai berat sifar).
Selain itu, beberapa aspek rangkaian saraf dalam ChatGPT bukanlah lapisan "homogen" yang paling semula jadi. Sebagai contoh, dalam blok perhatian, terdapat tempat di mana "berbilang salinan" data masuk dibuat, setiap satunya melalui "laluan pemprosesan" yang berbeza, mungkin melibatkan bilangan lapisan yang berbeza, sebelum dipasang semula kemudian. Walaupun ini mungkin cara notasi yang mudah, sekurang-kurangnya pada dasarnya adalah mungkin untuk mempertimbangkan "mengisi padat" lapisan dan hanya mempunyai beberapa pemberat menjadi sifar.
Jika anda melihat laluan terpanjang dalam ChatGPT, terdapat kira-kira 400 lapisan (lapisan teras) - bukan jumlah yang besar dalam beberapa cara. Tetapi terdapat berjuta-juta neuron, sejumlah 175 bilion sambungan, dan oleh itu 175 bilion berat. Satu perkara yang perlu disedari ialah setiap kali ChatGPT menjana token baharu, ia perlu melakukan pengiraan yang melibatkan setiap pemberat. Dari segi pelaksanaan, pengiraan ini boleh disusun ke dalam operasi tatasusunan yang sangat selari, yang boleh diselesaikan dengan mudah pada GPU. Tetapi masih terdapat 175 bilion pengiraan yang diperlukan untuk setiap token yang dihasilkan (dan lebih sedikit lagi pada akhirnya) - jadi ya, tidak menghairankan bahawa menghasilkan sekeping teks yang panjang dengan ChatGPT mengambil sedikit masa.
Tetapi akhirnya kita juga perlu ambil perhatian bahawa semua operasi ini entah bagaimana berfungsi bersama-sama untuk mencapai kerja "seperti manusia" untuk menjana teks. Perlu ditekankan sekali lagi bahawa (sekurang-kurangnya setakat yang kita tahu) tidak ada "sebab teori muktamad" mengapa perkara seperti ini harus berfungsi. Sebenarnya, seperti yang akan kita bincangkan, saya fikir kita harus menganggap ini sebagai - yang berpotensi mengejutkan - penemuan saintifik: Dalam rangkaian saraf seperti ChatGPT, adalah mungkin untuk menangkap apa yang dilakukan oleh otak manusia dalam menjana bahasa mampu melakukannya.
(Disebabkan kepanjangan artikel asal, rakan-rakan yang berminat boleh klik pada pautan di hujung artikel untuk membaca teks penuh)
One More Thing
Mungkin semasa membuka artikel ini, terdapat beberapa Rakan telah melihat beberapa perubahan halus:

Ya, editor kandungan teras artikel ini tiada selain daripada ChatGPT!
Selain itu, ia membincangkan pandangannya tentang artikel Stephen Wolfram:

Pautan rujukan:
[1 ] https://www.php.cn/link/e3670ce0c315396e4836d7024abcf3dd
[2] https://www.php.cn /link/b02fbaedab1394d
[3]https://www.php.cn/link/76e9a17937b75b73a8a430acf210feaf
Atas ialah kandungan terperinci Mengapa ChatGPT begitu berkuasa: penjelasan terperinci tentang artikel sepanjang 10,000 perkataan oleh bapa WolframAlpha. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1384
1384
 52
52

 ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
DALL-E 3 telah diperkenalkan secara rasmi pada September 2023 sebagai model yang jauh lebih baik daripada pendahulunya. Ia dianggap sebagai salah satu penjana imej AI terbaik setakat ini, mampu mencipta imej dengan perincian yang rumit. Walau bagaimanapun, semasa pelancaran, ia adalah tidak termasuk
 3 Cara Menukar Bahasa pada iPhone
Feb 02, 2024 pm 04:12 PM
3 Cara Menukar Bahasa pada iPhone
Feb 02, 2024 pm 04:12 PM
Bukan rahsia lagi bahawa iPhone adalah salah satu alat elektronik yang paling mesra pengguna, dan salah satu sebabnya ialah ia boleh diperibadikan dengan mudah mengikut keinginan anda. Dalam Pemperibadian, anda boleh menukar bahasa kepada bahasa yang berbeza daripada bahasa yang anda pilih semasa menyediakan iPhone anda. Jika anda biasa dengan berbilang bahasa, atau tetapan bahasa iPhone anda salah, anda boleh menukarnya seperti yang kami terangkan di bawah. Cara Menukar Bahasa iPhone [3 Kaedah] iOS membenarkan pengguna menukar bahasa pilihan pada iPhone secara bebas untuk menyesuaikan diri dengan keperluan yang berbeza. Anda boleh menukar bahasa interaksi dengan Siri untuk memudahkan komunikasi dengan pembantu suara. Pada masa yang sama, apabila menggunakan papan kekunci tempatan, anda boleh bertukar antara berbilang bahasa dengan mudah untuk meningkatkan kecekapan input.
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Langkah pemasangan: 1. Muat turun perisian ChatGTP dari laman web rasmi ChatGTP atau kedai mudah alih 2. Selepas membukanya, dalam antara muka tetapan, pilih bahasa sebagai bahasa Cina 3. Dalam antara muka permainan, pilih permainan mesin manusia dan tetapkan Spektrum bahasa Cina; 4 Selepas memulakan, masukkan arahan dalam tetingkap sembang untuk berinteraksi dengan perisian.
 Bagaimana untuk menetapkan bahasa komputer Win10 kepada bahasa Cina?
Jan 05, 2024 pm 06:51 PM
Bagaimana untuk menetapkan bahasa komputer Win10 kepada bahasa Cina?
Jan 05, 2024 pm 06:51 PM
Kadang-kadang kita hanya memasang sistem komputer dan mendapati bahawa sistem itu dalam bahasa Inggeris Dalam kes ini, kita perlu menukar bahasa komputer kepada bahasa Cina Jadi bagaimana untuk menukar bahasa komputer ke bahasa Cina dalam sistem win10 . Cara menukar bahasa komputer dalam win10 kepada bahasa Cina 1. Hidupkan komputer dan klik butang mula di sudut kiri bawah. 2. Klik pilihan tetapan di sebelah kiri. 3. Pilih "Masa dan Bahasa" pada halaman yang terbuka 4. Selepas membuka, klik "Bahasa" di sebelah kiri 5. Di sini anda boleh menetapkan bahasa komputer yang anda mahu.
 Bagaimana untuk membangunkan chatbot pintar menggunakan ChatGPT dan Java
Oct 28, 2023 am 08:54 AM
Bagaimana untuk membangunkan chatbot pintar menggunakan ChatGPT dan Java
Oct 28, 2023 am 08:54 AM
Dalam artikel ini, kami akan memperkenalkan cara membangunkan chatbot pintar menggunakan ChatGPT dan Java, dan menyediakan beberapa contoh kod khusus. ChatGPT ialah versi terkini Generative Pre-training Transformer yang dibangunkan oleh OpenAI, teknologi kecerdasan buatan berasaskan rangkaian saraf yang boleh memahami bahasa semula jadi dan menjana teks seperti manusia. Menggunakan ChatGPT kami boleh membuat sembang adaptif dengan mudah
 Bolehkah chatgpt digunakan di China?
Mar 05, 2024 pm 03:05 PM
Bolehkah chatgpt digunakan di China?
Mar 05, 2024 pm 03:05 PM
chatgpt boleh digunakan di China, tetapi tidak boleh didaftarkan, begitu juga di Hong Kong dan Macao Jika pengguna ingin mendaftar, mereka boleh menggunakan nombor telefon mudah alih asing untuk mendaftar. Perhatikan bahawa semasa proses pendaftaran, persekitaran rangkaian mesti ditukar IP asing.
 Bagaimana untuk membina robot perkhidmatan pelanggan pintar menggunakan PHP ChatGPT
Oct 28, 2023 am 09:34 AM
Bagaimana untuk membina robot perkhidmatan pelanggan pintar menggunakan PHP ChatGPT
Oct 28, 2023 am 09:34 AM
Cara menggunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar Pengenalan: Dengan perkembangan teknologi kecerdasan buatan, robot semakin digunakan dalam bidang perkhidmatan pelanggan. Menggunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar boleh membantu syarikat menyediakan perkhidmatan pelanggan yang lebih cekap dan diperibadikan. Artikel ini akan memperkenalkan cara menggunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar dan menyediakan contoh kod khusus. 1. Pasang ChatGPTPHP dan gunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar.
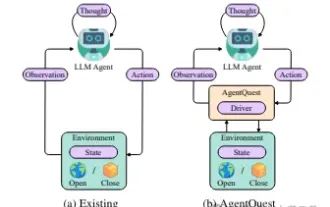 Meneroka sempadan ejen: AgentQuest, rangka kerja penanda aras modular untuk mengukur dan meningkatkan prestasi ejen model bahasa besar secara menyeluruh
Apr 11, 2024 pm 08:52 PM
Meneroka sempadan ejen: AgentQuest, rangka kerja penanda aras modular untuk mengukur dan meningkatkan prestasi ejen model bahasa besar secara menyeluruh
Apr 11, 2024 pm 08:52 PM
Berdasarkan pengoptimuman berterusan model besar, ejen LLM - entiti algoritma yang berkuasa ini telah menunjukkan potensi untuk menyelesaikan tugas penaakulan pelbagai langkah yang kompleks. Daripada pemprosesan bahasa semula jadi kepada pembelajaran mendalam, ejen LLM secara beransur-ansur menjadi tumpuan penyelidikan dan industri Mereka bukan sahaja dapat memahami dan menjana bahasa manusia, tetapi juga merumuskan strategi, melaksanakan tugas dalam persekitaran yang pelbagai, dan juga menggunakan panggilan API dan pengekodan untuk Membina. penyelesaian. Dalam konteks ini, pengenalan rangka kerja AgentQuest merupakan satu peristiwa penting Ia bukan sahaja menyediakan platform penanda aras modular untuk penilaian dan kemajuan ejen LLM, tetapi juga menyediakan penyelidik dengan alat yang Berkuasa untuk menjejak dan meningkatkan prestasi ejen ini pada masa yang tertentu. tahap yang lebih berbutir
