
 Peranti teknologi
AI
Kerja baru oleh Jeff Dean dan lain-lain: Lihat model bahasa dari sudut lain, ia tidak boleh ditemui jika skala tidak mencukupi
Peranti teknologi
AI
Kerja baru oleh Jeff Dean dan lain-lain: Lihat model bahasa dari sudut lain, ia tidak boleh ditemui jika skala tidak mencukupi
Kerja baru oleh Jeff Dean dan lain-lain: Lihat model bahasa dari sudut lain, ia tidak boleh ditemui jika skala tidak mencukupi

Model bahasa telah memberi kesan revolusioner pada pemprosesan bahasa semula jadi (NLP) dalam beberapa tahun kebelakangan ini. Adalah diketahui bahawa memanjangkan model bahasa, seperti parameter, boleh membawa kepada prestasi yang lebih baik dan kecekapan sampel pada pelbagai tugasan NLP hiliran. Dalam kebanyakan kes, kesan penskalaan pada prestasi selalunya boleh diramalkan oleh undang-undang penskalaan, dan kebanyakan penyelidik telah mengkaji fenomena yang boleh diramal.
Sebaliknya, 16 penyelidik termasuk Jeff Dean, Percy Liang, dsb. bekerjasama dalam kertas kerja "Keupayaan Muncul Model Bahasa Besar" Mereka membincangkan fenomena model besar yang tidak dapat diramalkan dan Ini dipanggil kebolehan muncul model bahasa besar. Apa yang dipanggil kemunculan bermaksud bahawa beberapa fenomena tidak wujud dalam model yang lebih kecil tetapi wujud dalam model yang lebih besar. Mereka percaya bahawa keupayaan model ini muncul.
Kemunculan sebagai idea telah lama dibincangkan dalam bidang seperti fizik, biologi dan sains komputer, dan kertas kerja ini bermula dengan definisi umum kemunculan yang diadaptasi daripada penyelidikan Steinhardt, dan berakar umbi dalam artikel yang dipanggil More Is Different oleh pemenang Hadiah Nobel dan ahli fizik Philip Anderson pada tahun 1972.
Artikel ini meneroka kemunculan saiz model, seperti yang diukur oleh pengiraan latihan dan parameter model. Secara khusus, kertas ini mentakrifkan keupayaan muncul model bahasa besar sebagai keupayaan yang tidak terdapat dalam model berskala kecil tetapi terdapat dalam model berskala besar oleh itu, model berskala besar tidak boleh diramalkan dengan hanya mengekstrapolasi peningkatan prestasi kecil; model skala. Kajian ini menyiasat keupayaan kemunculan model yang diperhatikan dalam julat kerja terdahulu dan mengklasifikasikannya ke dalam tetapan seperti kiu pukulan kecil dan kiu dirangsang.
Keupayaan model yang muncul ini memberi inspirasi kepada penyelidikan masa depan tentang sebab keupayaan ini diperoleh dan sama ada skala yang lebih besar memperoleh lebih banyak keupayaan yang muncul dan menyerlahkan ini Kepentingan penyelidikan.

Alamat kertas: https://arxiv.org/pdf/2206.07682.pdf
Tugas menggesa sampel kecil
Artikel ini mula-mula membincangkan keupayaan yang muncul dalam paradigma menggesa. Contohnya, dalam gesaan GPT-3, diberikan gesaan tugas model bahasa yang telah dilatih, model boleh melengkapkan respons tanpa latihan lanjut atau kemas kini kecerunan parameter. Di samping itu, Brown et al mencadangkan gesaan sampel kecil, di mana mereka menggunakan beberapa contoh input-output dalam konteks model (input) sebagai gesaan (mukadimah), dan kemudian meminta model untuk melaksanakan tugas inferens yang tidak kelihatan. Rajah 1 menunjukkan contoh gesaan.
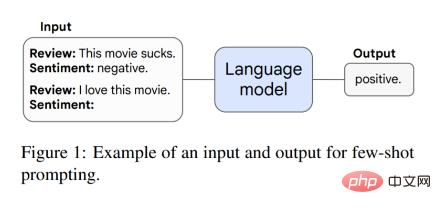

Apabila model mempunyai prestasi stokastik dan mempunyai skala tertentu, tugas boleh dilakukan dengan sampel kecil gesaan, Pada masa ini, keupayaan muncul akan muncul, dan kemudian prestasi model akan jauh lebih tinggi daripada prestasi rawak. Rajah di bawah menunjukkan 8 keupayaan muncul bagi 5 siri model bahasa (LaMDA, GPT-3, Gopher, Chinchilla dan PaLM).

BIG-Bench: Rajah 2A-D menggambarkan empat contoh kecil tugasan segera yang muncul daripada BIG-Bench, BIG-Bench ialah satu set lebih daripada 200 penanda aras penilaian model bahasa. Rajah 2A menunjukkan penanda aras aritmetik yang menguji penambahan dan penolakan nombor 3 digit, dan pendaraban nombor 2 digit. Jadual 1 memberikan lebih banyak keupayaan muncul BIG-Bench.

Strategi segera yang dipertingkatkan
Pada masa ini, walaupun pembayang sampel kecil ialah cara paling biasa untuk berinteraksi dengan model bahasa yang besar, kerja baru-baru ini telah mencadangkan beberapa pembayang lain dan strategi penalaan halus untuk meningkatkan lagi keupayaan model bahasa. Artikel ini juga menganggap teknologi sebagai keupayaan yang muncul jika ia tidak menunjukkan peningkatan atau berbahaya sebelum digunakan pada model yang cukup besar.
Penaakulan berbilang langkah: Untuk model bahasa dan model NLP, tugas penaakulan, terutamanya yang melibatkan penaakulan berbilang langkah, sentiasa menjadi cabaran besar . Strategi dorongan baru-baru ini yang dipanggil rantaian pemikiran membolehkan model bahasa menyelesaikan jenis masalah ini dengan membimbing mereka menjana satu siri langkah perantaraan sebelum memberikan jawapan akhir. Seperti yang ditunjukkan dalam Rajah 3A, apabila menskalakan kepada 1023 latihan FLOP (~100B parameter), gesaan rantaian pemikiran hanya mengatasi gesaan standard tanpa langkah perantaraan.
Arahan berikut: Seperti yang ditunjukkan dalam Rajah 3B, Wei et al mendapati bahawa apabila FLOP latihan adalah 7·10^21 (parameter 8B) atau lebih kecil, arahan penalaan halus (. arahan mengikut) -finetuning) teknik menjejaskan prestasi model dan hanya meningkatkan prestasi apabila melanjutkan FLOP latihan kepada 10^23 (~100B parameter).
Pelaksanaan program: Seperti yang ditunjukkan dalam Rajah 3C, dalam penilaian dalam domain penambahan 8-bit, menggunakan pad awal hanya membantu ∼9 · 10^19 latihan FLOP (parameter 40M) atau model yang lebih besar. Rajah 3D menunjukkan bahawa model ini juga boleh digeneralisasikan kepada penambahan 9-bit di luar domain, yang berlaku dalam ∼1.3 · 10^20 latihan FLOP (parameter 100M).

Artikel ini membincangkan kuasa kemunculan model bahasa, yang setakat ini hanya diperhatikan pada skala pengiraan tertentu Prestasi bermakna . Keupayaan model yang muncul ini boleh merangkumi pelbagai model bahasa, jenis tugas dan senario percubaan. Kewujudan kemunculan ini bermakna penskalaan tambahan dapat mengembangkan lagi keupayaan model bahasa. Keupayaan ini adalah hasil daripada sambungan model bahasa yang baru ditemui Bagaimana ia muncul dan sama ada lebih banyak sambungan akan membawa lebih banyak keupayaan muncul mungkin merupakan hala tuju penyelidikan masa hadapan yang penting dalam bidang NLP.
Untuk maklumat lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Kerja baru oleh Jeff Dean dan lain-lain: Lihat model bahasa dari sudut lain, ia tidak boleh ditemui jika skala tidak mencukupi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
MySQL boleh mengembalikan data JSON. Fungsi JSON_EXTRACT mengekstrak nilai medan. Untuk pertanyaan yang kompleks, pertimbangkan untuk menggunakan klausa WHERE untuk menapis data JSON, tetapi perhatikan kesan prestasinya. Sokongan MySQL untuk JSON sentiasa meningkat, dan disyorkan untuk memberi perhatian kepada versi dan ciri terkini.
 Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Penjelasan terperinci mengenai atribut asid asid pangkalan data adalah satu set peraturan untuk memastikan kebolehpercayaan dan konsistensi urus niaga pangkalan data. Mereka menentukan bagaimana sistem pangkalan data mengendalikan urus niaga, dan memastikan integriti dan ketepatan data walaupun dalam hal kemalangan sistem, gangguan kuasa, atau pelbagai pengguna akses serentak. Gambaran keseluruhan atribut asid Atomicity: Transaksi dianggap sebagai unit yang tidak dapat dipisahkan. Mana -mana bahagian gagal, keseluruhan transaksi dilancarkan kembali, dan pangkalan data tidak mengekalkan sebarang perubahan. Sebagai contoh, jika pemindahan bank ditolak dari satu akaun tetapi tidak meningkat kepada yang lain, keseluruhan operasi dibatalkan. Begintransaction; UpdateAcCountSsetBalance = Balance-100Wh
 Klausa had SQL Master: Kawal bilangan baris dalam pertanyaan
Apr 08, 2025 pm 07:00 PM
Klausa had SQL Master: Kawal bilangan baris dalam pertanyaan
Apr 08, 2025 pm 07:00 PM
Klausa SQLLIMIT: Kawal bilangan baris dalam hasil pertanyaan. Klausa had dalam SQL digunakan untuk mengehadkan bilangan baris yang dikembalikan oleh pertanyaan. Ini sangat berguna apabila memproses set data yang besar, paparan paginat dan data ujian, dan dapat meningkatkan kecekapan pertanyaan dengan berkesan. Sintaks Asas Sintaks: SelectColumn1, Column2, ... FROMTABLE_NAMELIMITNUMBER_OF_ROWS; Number_of_rows: Tentukan bilangan baris yang dikembalikan. Sintaks dengan Offset: SelectColumn1, Column2, ... Fromtable_namelimitoffset, Number_of_rows; Offset: Langkau
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
 Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Kaedah Navicat untuk melihat kata laluan pangkalan data MongoDB
Apr 08, 2025 pm 09:39 PM
Tidak mustahil untuk melihat kata laluan MongoDB secara langsung melalui Navicat kerana ia disimpan sebagai nilai hash. Cara mendapatkan kata laluan yang hilang: 1. Tetapkan semula kata laluan; 2. Periksa fail konfigurasi (mungkin mengandungi nilai hash); 3. Semak Kod (boleh kata laluan Hardcode).
 Kunci utama MySQL boleh menjadi batal
Apr 08, 2025 pm 03:03 PM
Kunci utama MySQL boleh menjadi batal
Apr 08, 2025 pm 03:03 PM
Kunci utama MySQL tidak boleh kosong kerana kunci utama adalah atribut utama yang secara unik mengenal pasti setiap baris dalam pangkalan data. Jika kunci utama boleh kosong, rekod tidak dapat dikenal pasti secara unik, yang akan membawa kepada kekeliruan data. Apabila menggunakan lajur integer sendiri atau UUIDs sebagai kunci utama, anda harus mempertimbangkan faktor-faktor seperti kecekapan dan penghunian ruang dan memilih penyelesaian yang sesuai.
 Pantau titisan mysql dan Mariadb dengan pengeksport prometheus mysql
Apr 08, 2025 pm 02:42 PM
Pantau titisan mysql dan Mariadb dengan pengeksport prometheus mysql
Apr 08, 2025 pm 02:42 PM
Pemantauan yang berkesan terhadap pangkalan data MySQL dan MariaDB adalah penting untuk mengekalkan prestasi yang optimum, mengenal pasti kemungkinan kesesakan, dan memastikan kebolehpercayaan sistem keseluruhan. Pengeksport Prometheus MySQL adalah alat yang berkuasa yang memberikan pandangan terperinci ke dalam metrik pangkalan data yang penting untuk pengurusan proaktif dan penyelesaian masalah.
