
 pembangunan bahagian belakang
Tutorial Python
Sistem pengecaman muka Python dengan kadar pengecaman luar talian sehingga 99%, sumber terbuka~
pembangunan bahagian belakang
Tutorial Python
Sistem pengecaman muka Python dengan kadar pengecaman luar talian sehingga 99%, sumber terbuka~
Sistem pengecaman muka Python dengan kadar pengecaman luar talian sehingga 99%, sumber terbuka~


Pada masa lalu, pengecaman muka terutamanya merangkumi teknologi dan sistem seperti pengumpulan imej muka, pra-pemprosesan pengecaman muka, pengesahan identiti dan carian identiti. Kini pengecaman muka telah diperluaskan secara perlahan kepada pengesanan pemandu, penjejakan pejalan kaki dan juga penjejakan objek dinamik dalam ADAS.
Dapat dilihat bahawa sistem pengecaman muka telah dibangunkan daripada pemprosesan imej mudah kepada pemprosesan video masa nyata. Selain itu, algoritma telah berubah daripada kaedah statistik tradisional seperti Adaboots dan PCA kepada kaedah pembelajaran mendalam seperti CNN dan RCNN dan pengubahsuaiannya. Kini sebilangan besar orang telah mula mengkaji pengecaman muka 3D, dan projek jenis ini kini disokong oleh ahli akademik, industri dan negara.
Pertama, mari kita lihat status penyelidikan semasa. Seperti yang dapat dilihat daripada trend pembangunan di atas, hala tuju penyelidikan utama semasa ialah menggunakan kaedah pembelajaran mendalam untuk menyelesaikan pengecaman muka video.
Penyelidik utama:
Seperti berikut: Profesor Shan Shiguang dari Institut Teknologi Pengkomputeran, Akademi Sains China, Profesor Li Ziqing dari Institut Biometrik, Akademi Sains China, Profesor Su Guangda dari Universiti Tsinghua, dan Profesor Tang Xiaoou dari Universiti Cina Hong Kong, Ross B. Girshick, dsb.
Projek sumber terbuka utama:
Enjin pengecaman muka SeeetaFace. Enjin itu dibangunkan oleh kumpulan penyelidik pengecaman muka yang diketuai oleh penyelidik Shan Shiguang dari Institut Teknologi Pengkomputeran, Akademi Sains China. Kod ini dilaksanakan berdasarkan C++ dan tidak bergantung pada mana-mana fungsi perpustakaan pihak ketiga Lesen sumber terbuka ialah BSD-2 dan boleh digunakan secara percuma oleh ahli akademik dan industri.
API/SDK perisian utama:
- muka++. Face++.com ialah platform perkhidmatan awan yang menyediakan pengesanan muka percuma, pengecaman muka, analisis atribut muka dan perkhidmatan lain. Face++ ialah platform awan teknologi muka baharu yang dimiliki oleh Beijing Megvii Technology Co., Ltd. Dalam pertandingan kuda hitam, Face++ memenangi kejohanan tahunan dan telah menerima pelaburan Lenovo Star.
- skybiometri. Ia terutamanya termasuk pengesanan muka, pengecaman muka dan pengumpulan wajah.
Pangkalan data imej pengecaman muka utama:
Pangkalan data imej muka yang lebih baik pada masa ini didedahkan termasuk LFW (Wajah Berlabel di Alam Liar) dan YFW (Muka YouTube di Alam Liar) ). Set data percubaan semasa pada asasnya diperoleh daripada LFW, dan ketepatan pengecaman muka imej semasa telah mencapai 99%. Berikut ialah ringkasan pangkalan data imej wajah sedia ada:

Terdapat lebih banyak syarikat yang melakukan pengecaman muka di China, dan aplikasinya juga sangat meluas. Antaranya, Hanwang Technology mempunyai bahagian pasaran tertinggi. Arah penyelidikan dan status semasa syarikat utama adalah seperti berikut:
- Teknologi Hanwang: Teknologi Hanwang terutamanya melakukan pengesahan pengecaman muka, yang digunakan terutamanya dalam sistem kawalan akses, sistem kehadiran, dsb.
- iFlytek: Dengan sokongan pasukan Profesor Tang Xiaoou di Universiti China Hong Kong, iFlytek telah membangunkan teknologi pengecaman muka berdasarkan proses Gaussian – muka Gussian Kadar pengecaman teknologi ini pada LFW ialah 98.52%. . , kadar pengiktirafan semasa DEEPID2 syarikat pada LFW telah mencapai 99.4%.
- Sichuan University Zhisheng: Sorotan penyelidikan semasa syarikat ialah pengecaman muka 3D, dan ia telah berkembang kepada perindustrian kamera muka penuh 3D dan sebagainya.
- SenseTime: Ia terutamanya sebuah syarikat yang berdedikasi untuk menerajui kejayaan dalam teknologi teras "pembelajaran mendalam" kecerdasan buatan dan penyelesaian industri untuk kecerdasan buatan dan analisis data besar. Ia kini terlibat dalam pengecaman muka, pengecaman teks , dan pengecaman badan manusia, pengecaman kenderaan, pengecaman objek, pemprosesan imej dan arah lain mempunyai daya saing yang kuat. Dalam pengecaman muka, terdapat 106 mata utama muka untuk pengecaman.
Proses pengecaman muka
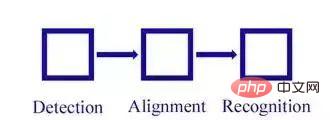
Pengecaman muka terbahagi kepada empat bahagian: pengesanan muka (pengesanan muka), penentukuran muka (penjajaran muka), pengesahan muka (pengesahan muka), pengenalan muka (face identification).
Pengesanan muka:
Kesan muka dalam imej dan bingkaikan hasilnya dengan bingkai segi empat tepat. Dalam openCV, terdapat pengelas Harr yang boleh digunakan secara langsung.
Penjajaran muka:
Betulkan postur wajah yang dikesan untuk menjadikan wajah sebagai "positif" yang mungkin, ketepatan pengecaman muka dapat dipertingkatkan. Kaedah pembetulan termasuk pembetulan 2D dan pembetulan 3D Kaedah pembetulan 3D boleh membolehkan pengecaman muka sisi yang lebih baik.
Apabila melakukan pembetulan muka, terdapat satu langkah untuk mengesan lokasi titik ciri Lokasi titik ciri ini adalah terutamanya lokasi seperti bahagian kiri hidung, bahagian bawah lubang hidung, kedudukan anak mata. bahagian bawah bibir atas, dsb. Selepas mengetahui kedudukan titik ciri ini, lakukan ubah bentuk dipacu kedudukan, dan muka boleh "diperbetulkan". Seperti yang ditunjukkan dalam rajah di bawah:
Berikut ialah teknologi yang dibangunkan oleh MSRA pada 2014: Pengesanan dan Penjajaran Muka Lata Bersama (ECCV14). Artikel ini secara langsung melakukan pengesanan dan penjajaran dalam 30ms.
Pengesahan muka:
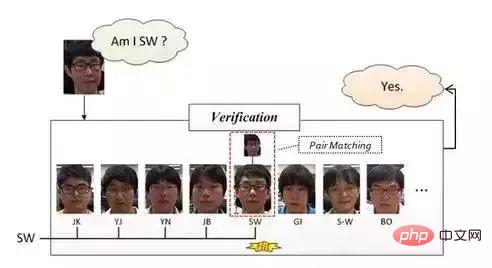
Pengesahan muka, pengesahan muka adalah berdasarkan padanan pasangan, jadi jawapan yang diterima ialah "ya" atau "tidak". Dalam operasi khusus, imej ujian diberikan, dan kemudian padanan pasangan dilakukan satu demi satu Jika padanan berjaya, ia bermakna imej ujian dan muka yang dipadankan adalah wajah orang yang sama.
Kaedah ini (sepatutnya) secara amnya digunakan dalam sistem tebuk masuk pengimbasan muka di pejabat kecil Kaedah operasi khusus adalah kira-kira proses berikut: masukkan foto muka pekerja satu demi satu di luar talian (orang yang masuk oleh pekerja Biasanya terdapat lebih daripada satu muka). Selepas kamera menangkap imej apabila pekerja meleret muka untuk mendaftar masuk, ia mula-mula melakukan pengesanan muka melalui kaedah yang dinyatakan di atas, kemudian melakukan pembetulan muka, dan kemudian melakukan pengesahan muka. . Sebaik sahaja keputusan perlawanan adalah "Ya" ”, menunjukkan bahawa orang yang mengimbas muka adalah milik pejabat ini dan pengesahan wajah selesai pada langkah ini.
Apabila memasuki wajah pekerja secara offline, kita boleh memadankan wajah dengan nama orang tersebut, supaya setelah pengesahan wajah berjaya, kita boleh tahu siapa orang tersebut.
Kelebihan sistem yang disebutkan di atas adalah kos yang rendah untuk dibangunkan dan sesuai untuk pejabat kecil, ia tidak boleh disekat semasa tangkapan, dan ia juga memerlukan postur muka yang agak lurus (kami memiliki sistem ini, tetapi belum mengalaminya). Rajah berikut memberikan penjelasan skematik:
Pengenalan/pengecaman muka:
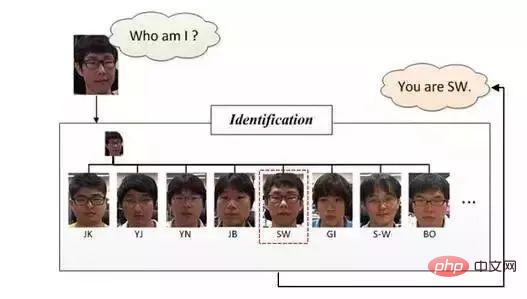
Pengenalan muka atau Pengecaman muka, pengecaman muka adalah seperti berikut Seperti yang ditunjukkan dalam rajah , apa yang ingin dijawab ialah "Siapa saya?" Berbanding dengan padanan pasangan yang digunakan dalam pengesahan muka, ia menggunakan lebih banyak kaedah pengelasan dalam peringkat pengecaman. Ia sebenarnya mengklasifikasikan imej (muka) selepas melakukan dua langkah sebelum ini iaitu pengesanan muka dan pembetulan muka.
Menurut pengenalan empat konsep di atas, kita dapat memahami bahawa pengecaman muka terutamanya merangkumi tiga modul bebas yang besar:
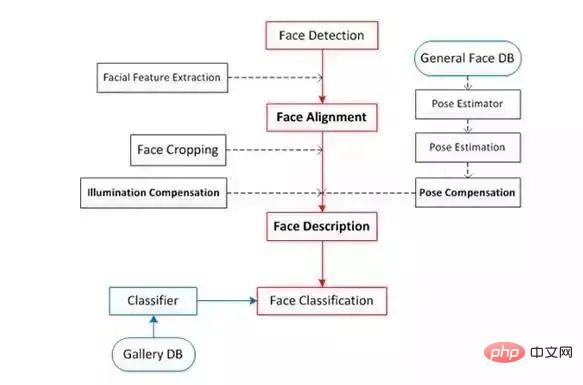
Kami membahagikan langkah di atas secara terperinci dan mendapatkan rajah proses berikut:
Klasifikasi pengecaman muka
Kini, dengan perkembangan pengecaman muka teknologi, teknologi pengecaman muka terbahagi terutamanya kepada tiga kategori: pertama, kaedah pengecaman berasaskan imej, kedua, kaedah pengecaman berasaskan video, dan kaedah pengecaman muka tiga dimensi ketiga.
Kaedah pengecaman berasaskan imej:
Proses ini ialah proses pengecaman imej statik, terutamanya menggunakan pemprosesan imej. Algoritma utama termasuk PCA, EP, kaedah kernel, Bayesian Framwork, SVM, HMM, Adaboot dan algoritma lain. Tetapi pada tahun 2014, pengecaman muka mencapai kejayaan besar menggunakan teknologi pembelajaran Dalam, yang diwakili oleh 97.25% muka dalam dan 97.27% muka dalam. Walau bagaimanapun, set latihan muka dalam ialah 4 juta set Pada masa yang sama, Gussian oleh Tang Xiaoou Universiti Cina Hong Kong Set latihan muka ialah 2w.
Kaedah pengecaman masa nyata berdasarkan video:
Proses ini boleh dilihat dalam proses pengesanan pengecaman muka, yang bukan sahaja memerlukan mencari kedudukan dan saiz muka dalam video, tetapi juga perlu menentukan Korespondensi antara bingkai antara muka yang berbeza.
DeepFace
Kertas rujukan (maklumat):
1. DeepFace: Menutup Jurang kepada Prestasi Peringkat Manusia dalam Pengesahan Muka
2. http://blog.csdn.net/zouxy09/article/details/8781543
3. Blog terbitan rangkaian saraf konvolusi. http://blog.csdn.net/zouxy09/article/details/9993371/
4. Nota mengenai Rangkaian Neural Konvolusi
5
6. Catatan blog DeepFace: http://blog.csdn.net/Hao_Zhang_Vision/article/details/52831399?locationNum=2&fps=1DeepFace telah dicadangkan oleh FaceBook, diikuti oleh DeepID dan FaceNet. . Selain itu, DeepFace boleh dilihat dalam DeepID dan FaceNet, jadi DeepFace boleh dikatakan sebagai asas kepada CNN dalam pengecaman muka Pada masa ini, pembelajaran mendalam juga telah mencapai keputusan yang sangat baik dalam pengecaman muka. Jadi di sini kita mula belajar daripada DeepFace. Dalam proses pembelajaran DeepFace, bukan sahaja kaedah yang digunakan oleh DeepFace akan diperkenalkan, malah algoritma utama lain yang sedang digunakan dalam langkah ini akan diperkenalkan untuk memberikan penerangan ringkas dan menyeluruh tentang pengecaman muka imej sedia ada. teknologi. Rangka kerja asas DeepFace1 Proses asas pengecaman mukapengesanan muka -> penjajaran muka -> pengesahan muka -> pengenalan muka 2. . Pengesanan muka 2.1 Teknologi sedia ada:pengelas haar:
Pengesanan muka telah pun mempunyai pengelas haar yang boleh digunakan terus dalam opencv, berdasarkan algoritma Viola-Jones.
Algoritma Adaboost (pengelas lata):
1. Kertas rujukan: Pengesanan muka Masa Nyata Teguh.
2. Rujukan blog Cina: http://blog.csdn.net/cyh_24/article/details/39755661
3 /s/blog_7769660f01019ep0.html
2.2 Kaedah yang digunakan dalam artikel
Artikel ini menggunakan kaedah pengesanan muka berdasarkan titik pengesanan (Fiducial Point Detector).
- Mula-mula pilih 6 titik rujukan, 2 pusat mata, 1 titik hidung dan 3 titik pada mulut.
- Gunakan SVR untuk mempelajari mata penanda aras melalui ciri LBP.
Kesannya adalah seperti berikut:

3. Penjajaran muka (penjajaran muka)
Penjajaran 2D:
- Pangkas imej Dikesan dalam dua dimensi, skala, putar dan terjemahkan imej ke dalam enam lokasi utama. Potong bahagian muka.
Penjajaran 3D:
- Cari model 3D dan gunakan model 3D ini untuk memangkas muka 2D menjadi muka 3D. 67 titik asas, kemudian triangulasi Delaunay, menambah segi tiga pada kontur untuk mengelakkan ketakselanjaran.
- Tukar muka segi tiga kepada bentuk 3D
- Muka segi tiga menjadi jala segi tiga 3D dengan kedalaman
- Membelokkan jala segi tiga supaya Bahagian hadapan muka menghadap ke hadapan
- Muka yang terakhir diluruskan
Kesannya adalah seperti berikut:
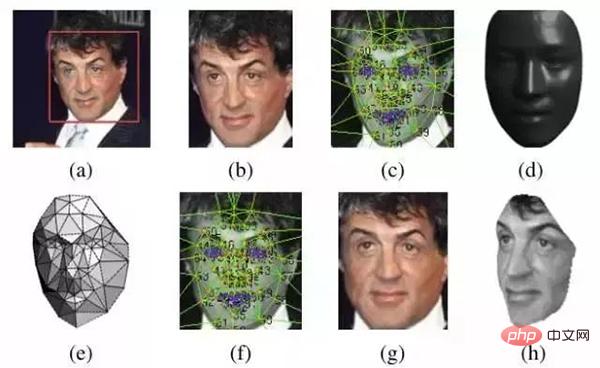
Penjajaran 2D di atas sepadan dengan (b) Gambar, Penjajaran 3D sepadan dengan (c) ~ (h).
4 Pengesahan muka
4.1 Teknologi sedia ada
LBP && Bayesian bersama:
Melalui dua kaedah gabungan LBP berdimensi tinggi dan Bayesian Bersama.
- Kertas: Wajah Bayesian Disemak Semula: Formulasi Bersama
Siri DeepID:
Gabungan tujuh model Bayesian bersama menggunakan SVM, ketepatan Mencapai 99.15%
- Kertas: Pembelajaran Mendalam Perwakilan Wajah oleh Pengenalpastian Bersama-Pengesahan
4.2 Kaedah dalam artikel
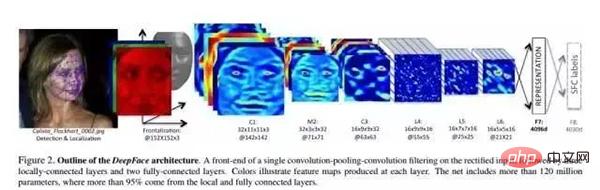
Dalam kertas, rangkaian saraf dalam (DNN) dilatih melalui tugas pengecaman muka berbilang kelas. Struktur rangkaian ditunjukkan dalam rajah di atas.
Parameter struktur:
Selepas penjajaran 3D, imej yang terbentuk adalah semua imej 152×152, yang dimasukkan ke dalam struktur rangkaian di atas Parameter struktur adalah seperti berikut:
- Penukaran: 32 11×11×3 biji lilitan
- pengumpulan maks: 3×3, langkah=2
- Penukaran: 16 biji lilitan 9×9
- Local-Conv: 16 9×9 convolution kernel Local bermakna parameter kernel convolution tidak dikongsi
- Local-Conv: 16 7×7 convolution kernel , parameter tidak dikongsi
- Local-Conv: 16 5×5 konvolusi kernel, parameter tidak dikongsi
- Tersambung sepenuhnya: 4096 dimensi
- Softmax: 4030 dimensi
Ekstrak ciri peringkat rendah:
Prosesnya adalah seperti berikut:
- Peringkat pra-pemprosesan: masukkan muka 3 saluran, dan lakukan pembetulan 3D, dan kemudian Dinormalkan kepada 152*152 piksel saiz - 152*152*3.
- Melalui lapisan lilitan C1: C1 mengandungi 32 penapis 11*11*3 (iaitu kernel lilitan), menghasilkan 32 Peta ciri - 32*142*142*3.
- Melalui lapisan undian maksimum M2: saiz tetingkap gelongsor M2 ialah 3*3, saiz langkah gelongsor ialah 2, dan tiga saluran ditinjau secara bebas.
- Melalui lapisan lilitan lain C3: C3 mengandungi 16 biji lilitan 3 dimensi 9*9*16.
Rangkaian 3 lapisan di atas adalah untuk mengekstrak ciri peringkat rendah, seperti ciri tepi ringkas dan ciri tekstur. Lapisan undian Maks menjadikan rangkaian konvolusi lebih teguh kepada transformasi tempatan. Jika input ialah muka yang diperbetulkan, ia menjadikan rangkaian lebih mantap kepada ralat pelabelan kecil.
Walau bagaimanapun, lapisan undian sedemikian akan menyebabkan rangkaian kehilangan beberapa maklumat mengenai struktur terperinci muka dan lokasi tepat tekstur kecil. Oleh itu, kertas itu hanya menambah lapisan undian Maks selepas lapisan konvolusi pertama. Lapisan sebelumnya ini dipanggil tahap prapemprosesan adaptif hadapan. Walau bagaimanapun, untuk banyak pengiraan, di mana ini perlu, lapisan ini mempunyai parameter yang sangat sedikit. Mereka hanya mengembangkan imej input ke dalam set ciri tempatan yang mudah.
Lapisan seterusnya:
L4, L5 dan L6 semuanya adalah lapisan yang disambungkan secara setempat Sama seperti lapisan konvolusi menggunakan penapis, set lapisan yang berbeza dilatih dan dipelajari pada setiap kedudukan ciri imej. Memandangkan kawasan yang berbeza mempunyai sifat statistik yang berbeza selepas pembetulan, andaian kestabilan spatial rangkaian konvolusi tidak dapat diwujudkan.
Sebagai contoh, kawasan antara mata dan kening mempamerkan penampilan yang sangat berbeza dan sangat berbeza berbanding dengan kawasan antara hidung dan mulut. Dalam erti kata lain, dengan menggunakan imej yang diperbetulkan input, struktur DNN disesuaikan.
Penggunaan lapisan sambungan tempatan tidak menjejaskan beban pengiraan semasa pengekstrakan ciri, tetapi ia menjejaskan bilangan parameter latihan. Hanya kerana terdapat perpustakaan muka berlabel yang begitu besar, kami mampu membeli tiga lapisan besar yang disambungkan secara tempatan. Unit keluaran lapisan sambungan tempatan dipengaruhi oleh tampung input yang besar, dan penggunaan (parameter) lapisan sambungan tempatan boleh dilaraskan sewajarnya (tiada pemberat dikongsi)
Sebagai contoh, output bagi Lapisan L6 dipengaruhi oleh 74* Kesan tampalan input 74*3, pada muka yang diperbetulkan, adalah sukar untuk mempunyai sebarang perkongsian parameter statistik antara tampalan besar tersebut.
Lapisan atas:
Akhir sekali, dua lapisan teratas rangkaian (F7, F8) disambungkan sepenuhnya: setiap unit output disambungkan kepada semua input. Kedua-dua lapisan ini boleh menangkap korelasi antara ciri di kawasan yang jauh dalam imej muka. Sebagai contoh, korelasi antara kedudukan dan bentuk mata serta kedudukan dan bentuk mulut (bahagian ini juga mengandungi maklumat) boleh diperolehi daripada kedua-dua lapisan ini. Output lapisan pertama F7 yang disambungkan sepenuhnya ialah vektor ekspresi ciri muka asal kami.
Dari segi ekspresi ciri, vektor ciri ini sangat berbeza daripada perihalan ciri berasaskan LBP tradisional. Kaedah tradisional biasanya menggunakan perihalan ciri tempatan (histogram pengiraan) dan berfungsi sebagai input kepada pengelas.
Output lapisan terakhir F8 yang disambungkan sepenuhnya memasuki K-way softmax (K ialah bilangan kategori), yang menjana taburan kebarangkalian label kategori. Biarkan Ok mewakili keluaran ke-k bagi imej input selepas melalui rangkaian, iaitu, kebarangkalian label kelas keluaran k boleh dinyatakan dengan formula berikut:
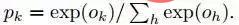
Matlamat latihan adalah untuk memaksimumkan keluaran yang betul Kebarangkalian kelas (id muka). Ini dicapai dengan meminimumkan kehilangan entropi silang bagi setiap sampel latihan. Biarkan k mewakili label kategori yang betul bagi input yang diberikan, maka kehilangan entropi silang ialah:
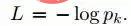
Dengan mengira kecerunan kehilangan entropi silang L pada parameter dan menggunakan kaedah pengurangan kecerunan stokastik untuk meminimumkan kehilangan entropi silang.
Kecerunan dikira dengan perambatan balik standard ralat. Menariknya, ciri yang dihasilkan oleh rangkaian ini sangat jarang. Lebih daripada 75% elemen ciri peringkat atas ialah 0. Ini disebabkan terutamanya oleh penggunaan fungsi pengaktifan ReLU. Fungsi tak linear ambang lembut ini digunakan dalam semua lapisan konvolusi, lapisan bersambung setempat dan lapisan bersambung sepenuhnya (kecuali lapisan terakhir F8), menghasilkan ciri yang sangat tidak linear dan jarang selepas lata keseluruhan.
Sparsity juga berkaitan dengan penggunaan regularization dropout, yang menetapkan elemen ciri rawak kepada 0 semasa latihan. Kami hanya menggunakan keciciran dalam lapisan F7 yang bersambung sepenuhnya Disebabkan set latihan yang besar, kami tidak menemui overfitting yang ketara semasa proses latihan.
Memandangkan imej I, ekspresi cirinya G(I) dikira melalui rangkaian suapan hadapan bagi setiap lapisan L boleh dianggap sebagai satu siri fungsi:

Penormalan:
Pada peringkat terakhir, kami menormalkan elemen ciri kepada 0 hingga 1 untuk mengurangkan sensitiviti ciri kepada perubahan pencahayaan. Setiap elemen dalam vektor ciri dibahagikan dengan nilai maksimum yang sepadan dalam set latihan. Kemudian lakukan normalisasi L2. Memandangkan kami menggunakan fungsi pengaktifan ReLU, sistem kami kurang invarian dengan skala imej.
Untuk vektor keluaran 4096-d:
- Mula-mula normalkan setiap dimensi, iaitu, bagi setiap dimensi dalam vektor hasil, bahagikan dimensi dengan keseluruhan Nilai maksimum pada set latihan.
- Setiap vektor adalah L2 dinormalkan.
2. Pengesahan
2.1 Jarak Chi-square
Dalam sistem ini, vektor ciri DeepFace yang dinormalkan adalah konsisten dengan ciri berasaskan histogram tradisional (seperti LBP ) mempunyai persamaan berikut:
- Semua nilai adalah negatif
- Sangat jarang
- Nilai unsur ciri semuanya berada di antara selang [0, 1]
Formula pengiraan jarak khi kuasa dua adalah seperti berikut:
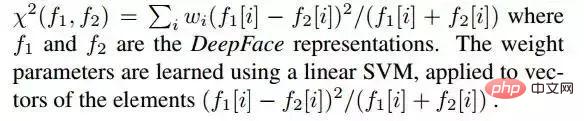
2.2 Rangkaian Siam
Akhir-ke- pembelajaran metrik akhir juga disebut dalam artikel Kaedah, setelah pembelajaran (latihan) selesai, rangkaian pengecaman muka (sehingga F7) digunakan semula pada dua gambar input, dan kedua-dua vektor ciri yang diperoleh digunakan secara langsung untuk meramalkan sama ada kedua-duanya gambar input adalah milik orang yang sama. Ini dibahagikan kepada langkah-langkah berikut:
a Kira perbezaan mutlak antara dua ciri;
3. Penilaian Eksperimen
3.1 Set Data
- Set Data Klasifikasi Wajah Sosial(SFC): 4.4M muka/4030 orang
- LFW: 13323 muka/5749 orang
- terhad: hanya ya/tidak Teg
- tidak terhad: pasangan latihan lain juga boleh diperolehi
- tanpa diawasi: tidak dilatih di LFW
- Youtube Face(YTF): 3425video/1595 orang
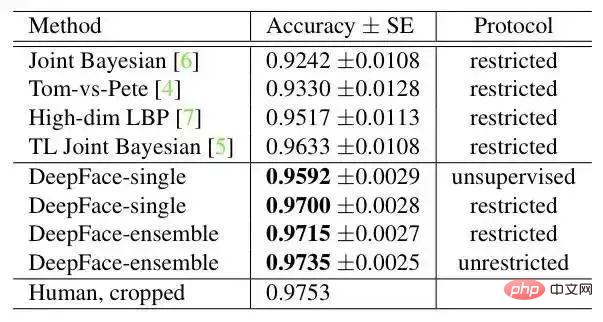
hasil pada LFW:
hasil pada YTF:
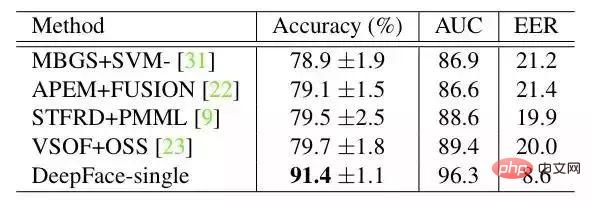
Kaedah DeepFace yang terbesar dan kaedah seterusnya Perbezaannya ialah DeepFace menggunakan kaedah penjajaran sebelum melatih rangkaian saraf. Makalah ini percaya bahawa sebab rangkaian saraf boleh berfungsi ialah apabila muka dijajarkan, ciri kawasan muka ditetapkan pada piksel tertentu Pada masa ini, rangkaian saraf konvolusi boleh digunakan untuk mempelajari ciri tersebut.
Model dalam artikel ini menggunakan kaedah pengecaman muka terkini berdasarkan pembelajaran mendalam dalam dlib kotak alat C++ Berdasarkan tahap penanda aras perpustakaan ujian data muka luar Labeled Faces in the Wild, ia telah mencapai ketepatan. sebanyak 99.38%.
Lagi algoritma
http://www.gycc.com/trends/face%20recognition/overview/
dlib : http://dlib.net/Pustaka ujian data Wajah Berlabel di Alam Liar: http://vis-www.cs.umass.edu/lfw/
Model ini menyediakan alat baris perintah pengenalan_muka yang ringkas Membolehkan pengguna untuk terus menggunakan folder gambar untuk operasi pengecaman muka melalui arahan.
Tangkap ciri wajah dalam gambar
Tangkap semua wajah dalam satu gambar
Cari dan proses ciri wajah dalam gambar
Cari kedudukan dan garisan setiap mata, hidung, mulut dan dagu seseorang.
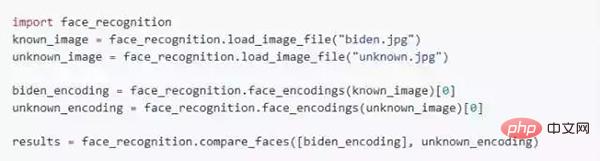
import pengecaman_muka
imej = pengecaman_muka.load_image_file("fail_anda.jpg")
lokasi_muka = pengecaman_muka.lokasi_muka(imej)
Ia menangkap ciri muka mempunyai kegunaan yang sangat penting Sudah tentu, ia juga boleh digunakan untuk solekan digital gambar (seperti Meitu Xiu Xiu)
solekan digital: https://github.com/ageitgey/face_recognition / blob/master/examples/digital_makeup.py
Kenali wajah dalam gambar
Kenali siapa yang muncul dalam foto
Langkah Pasang
Kaedah ini menyokong Python3/python2 Kami hanya mengujinya pada macOS dan Linux Kami tidak tahu sama ada ia boleh digunakan untuk Windows.
Pasang modul ini menggunakan pip3 pypi (atau pip2 Python 2)
Nota penting: Mungkin terdapat masalah semasa menyusun dlib, anda boleh memasangnya dari sumber (bukan pip) dlib ke betulkan ralat, sila lihat manual pemasangan Cara memasang dlib dari sumber
https://gist.github.com/ageitgey/629d75c1baac34dfa5ca2a1928a7aeaf
Lengkapkan pemasangan dengan memasang dlib secara manual dan menjalankan pip3 install face_recognition.
Menggunakan Antara Muka Baris Perintah
Apabila anda memasang face_recognition, anda boleh mendapatkan program baris arahan ringkas yang dipanggil face_recognition, yang boleh membantu anda mengecam foto atau folder foto semua wajah.
Pertama, anda perlu menyediakan folder yang mengandungi foto, dan anda sudah tahu siapa orang dalam foto itu Setiap orang mesti mempunyai fail foto, dan nama fail itu perlu dinamakan sempena nama orang itu . ;
Kemudian anda perlu menyediakan folder lain yang mengandungi foto wajah yang anda ingin kenali
Seterusnya, anda hanya perlu menjalankan perintah pengenalan_muka, dan program boleh menghantar fail bagi wajah yang dikenali Folder mengenal pasti siapa orang dalam foto wajah yang tidak dikenali itu; orang, dipisahkan dengan koma.
Jika anda hanya ingin mengetahui nama orang dalam setiap foto tetapi bukan nama fail, anda boleh melakukan perkara berikut: 
Modul Python
Anda boleh melengkapkan operasi pengecaman muka dengan memperkenalkan pengecaman_muka: 
Kenali wajah dalam gambar dan beritahu nama
Sila rujuk contoh ini: https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.py
Python contoh kod
Semua contoh ada di sini.
https://github.com/ageitgey/face_recognition/tree/master/examples
·Cari wajah dalam gambar
https://github.com/ageitgey/face_recognition/blob/master/examples/find_faces_in_picture.py · 识别照片中的面部特征Identify specific facial features in a photograph https://github.com/ageitgey/face_recognition/blob/master/examples/find_facial_features_in_picture.py · 使用数字美颜Apply (horribly ugly) digital make-up https://github.com/ageitgey/face_recognition/blob/master/examples/digital_makeup.py ·基于已知人名找到并识别出照片中的未知人脸Find and recognize unknown faces in a photograph based on photographs of known people https://github.com/ageitgey/face_recognition/blob/master/examples/recognize_faces_in_pictures.pypython人脸
Baiklah, itu sahaja perkongsian hari ini~
Atas ialah kandungan terperinci Sistem pengecaman muka Python dengan kadar pengecaman luar talian sehingga 99%, sumber terbuka~. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
MySQL mempunyai versi komuniti percuma dan versi perusahaan berbayar. Versi komuniti boleh digunakan dan diubahsuai secara percuma, tetapi sokongannya terhad dan sesuai untuk aplikasi dengan keperluan kestabilan yang rendah dan keupayaan teknikal yang kuat. Edisi Enterprise menyediakan sokongan komersil yang komprehensif untuk aplikasi yang memerlukan pangkalan data yang stabil, boleh dipercayai, berprestasi tinggi dan bersedia membayar sokongan. Faktor yang dipertimbangkan apabila memilih versi termasuk kritikal aplikasi, belanjawan, dan kemahiran teknikal. Tidak ada pilihan yang sempurna, hanya pilihan yang paling sesuai, dan anda perlu memilih dengan teliti mengikut keadaan tertentu.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Fail muat turun MySQL rosak dan tidak boleh dipasang. Penyelesaian pembaikan
Apr 08, 2025 am 11:21 AM
Fail muat turun MySQL rosak dan tidak boleh dipasang. Penyelesaian pembaikan
Apr 08, 2025 am 11:21 AM
Fail muat turun mysql adalah korup, apa yang perlu saya lakukan? Malangnya, jika anda memuat turun MySQL, anda boleh menghadapi rasuah fail. Ia benar -benar tidak mudah hari ini! Artikel ini akan bercakap tentang cara menyelesaikan masalah ini supaya semua orang dapat mengelakkan lencongan. Selepas membacanya, anda bukan sahaja boleh membaiki pakej pemasangan MySQL yang rosak, tetapi juga mempunyai pemahaman yang lebih mendalam tentang proses muat turun dan pemasangan untuk mengelakkan terjebak pada masa akan datang. Mari kita bercakap tentang mengapa memuat turun fail rosak. Terdapat banyak sebab untuk ini. Masalah rangkaian adalah pelakunya. Gangguan dalam proses muat turun dan ketidakstabilan dalam rangkaian boleh menyebabkan rasuah fail. Terdapat juga masalah dengan sumber muat turun itu sendiri. Fail pelayan itu sendiri rosak, dan sudah tentu ia juga dipecahkan jika anda memuat turunnya. Di samping itu, pengimbasan "ghairah" yang berlebihan beberapa perisian antivirus juga boleh menyebabkan rasuah fail. Masalah Diagnostik: Tentukan sama ada fail itu benar -benar korup
 Mysql tidak dapat dipasang setelah memuat turun
Apr 08, 2025 am 11:24 AM
Mysql tidak dapat dipasang setelah memuat turun
Apr 08, 2025 am 11:24 AM
Sebab utama kegagalan pemasangan MySQL adalah: 1. Isu kebenaran, anda perlu menjalankan sebagai pentadbir atau menggunakan perintah sudo; 2. Ketergantungan hilang, dan anda perlu memasang pakej pembangunan yang relevan; 3. Konflik pelabuhan, anda perlu menutup program yang menduduki port 3306 atau mengubah suai fail konfigurasi; 4. Pakej pemasangan adalah korup, anda perlu memuat turun dan mengesahkan integriti; 5. Pembolehubah persekitaran dikonfigurasikan dengan salah, dan pembolehubah persekitaran mesti dikonfigurasi dengan betul mengikut sistem operasi. Selesaikan masalah ini dan periksa dengan teliti setiap langkah untuk berjaya memasang MySQL.
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
 Penyelesaian kepada perkhidmatan yang tidak dapat dimulakan selepas pemasangan MySQL
Apr 08, 2025 am 11:18 AM
Penyelesaian kepada perkhidmatan yang tidak dapat dimulakan selepas pemasangan MySQL
Apr 08, 2025 am 11:18 AM
MySQL enggan memulakan? Jangan panik, mari kita periksa! Ramai kawan mendapati bahawa perkhidmatan itu tidak dapat dimulakan selepas memasang MySQL, dan mereka sangat cemas! Jangan risau, artikel ini akan membawa anda untuk menangani dengan tenang dan mengetahui dalang di belakangnya! Selepas membacanya, anda bukan sahaja dapat menyelesaikan masalah ini, tetapi juga meningkatkan pemahaman anda tentang perkhidmatan MySQL dan idea anda untuk masalah penyelesaian masalah, dan menjadi pentadbir pangkalan data yang lebih kuat! Perkhidmatan MySQL gagal bermula, dan terdapat banyak sebab, mulai dari kesilapan konfigurasi mudah kepada masalah sistem yang kompleks. Mari kita mulakan dengan aspek yang paling biasa. Pengetahuan asas: Penerangan ringkas mengenai proses permulaan perkhidmatan MySQL Startup. Ringkasnya, sistem operasi memuatkan fail yang berkaitan dengan MySQL dan kemudian memulakan daemon MySQL. Ini melibatkan konfigurasi
 Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Cara mengoptimumkan prestasi pangkalan data selepas pemasangan MySQL
Apr 08, 2025 am 11:36 AM
Pengoptimuman prestasi MySQL perlu bermula dari tiga aspek: konfigurasi pemasangan, pengindeksan dan pengoptimuman pertanyaan, pemantauan dan penalaan. 1. Selepas pemasangan, anda perlu menyesuaikan fail my.cnf mengikut konfigurasi pelayan, seperti parameter innodb_buffer_pool_size, dan tutup query_cache_size; 2. Buat indeks yang sesuai untuk mengelakkan indeks yang berlebihan, dan mengoptimumkan pernyataan pertanyaan, seperti menggunakan perintah menjelaskan untuk menganalisis pelan pelaksanaan; 3. Gunakan alat pemantauan MySQL sendiri (ShowProcessList, ShowStatus) untuk memantau kesihatan pangkalan data, dan kerap membuat semula dan mengatur pangkalan data. Hanya dengan terus mengoptimumkan langkah -langkah ini, prestasi pangkalan data MySQL diperbaiki.
 Adakah mysql memerlukan internet
Apr 08, 2025 pm 02:18 PM
Adakah mysql memerlukan internet
Apr 08, 2025 pm 02:18 PM
MySQL boleh berjalan tanpa sambungan rangkaian untuk penyimpanan dan pengurusan data asas. Walau bagaimanapun, sambungan rangkaian diperlukan untuk interaksi dengan sistem lain, akses jauh, atau menggunakan ciri -ciri canggih seperti replikasi dan clustering. Di samping itu, langkah -langkah keselamatan (seperti firewall), pengoptimuman prestasi (pilih sambungan rangkaian yang betul), dan sandaran data adalah penting untuk menyambung ke Internet.
