
 Peranti teknologi
AI
Microsoft menang! Berbilion latihan pasangan imej teks, Florence berbilang modal memulakan percubaan percuma, tersedia di Azure
Peranti teknologi
AI
Microsoft menang! Berbilion latihan pasangan imej teks, Florence berbilang modal memulakan percubaan percuma, tersedia di Azure
Microsoft menang! Berbilion latihan pasangan imej teks, Florence berbilang modal memulakan percubaan percuma, tersedia di Azure

Pada November 2021, Microsoft mengeluarkan model asas penglihatan pelbagai mod Florence (Florence), yang menyapu lebih daripada 40 tugas penanda aras dan mudah digunakan untuk pengelasan, pengesanan sasaran, VQA, bercakap melalui gambar, pengambilan video dan pengecaman tindakan Tunggu. untuk pelbagai tugas.
Selepas setahun setengah, Florence telah melancarkan penggunaan komersialnya secara rasmi!
Apa yang boleh dilakukan oleh Florence?
Baru-baru ini, Ketua Pegawai Teknologi Kecerdasan Buatan Global Microsoft Huang Xuedong secara rasmi mengumumkan versi pratonton awam model asas Florence Microsoft.
Model Florence telah dilatih dengan berbilion pasangan imej teks dan telah disepadukan ke dalam perkhidmatan penglihatan kognitif Azure Ia telah mencapai keperluan "persekitaran pengeluaran" dari segi "harga" dan "prestasi ". Pada masa ini dalam fasa percubaan percuma.

Perkhidmatan penglihatan yang dipertingkatkan membolehkan pembangun mencipta aplikasi penglihatan komputer yang canggih, sedia pasaran dan bertanggungjawab merentas pelbagai industri. Pelanggan boleh mendigitalkan, menganalisis dan menyambungkan data mereka dengan lancar ke dalam interaksi bahasa semula jadi untuk memperoleh maklumat yang lebih tepat daripada kandungan imej dan video, melindungi pengguna daripada kandungan berbahaya, meningkatkan keselamatan dan mempercepatkan tindak balas insiden.
Keupayaan sebenar Florence juga sangat berkuasa, dan pengguna boleh mengalaminya "di luar kotak" dalam Vision Studio.

URL Pengalaman: https://portal.vision.cognitive.azure.com/gallery/featured
Termasuk khusus:
Kapsyen Padat: Secara automatik memberikan penerangan yang kaya, cadangan reka bentuk, teks alternatif yang boleh diakses, pengoptimuman enjin carian, pengurusan foto pintar dan banyak lagi untuk menyokong kandungan digital.
Pendapatan Imej: Gunakan pertanyaan bahasa semula jadi untuk mengukur persamaan antara imej dan teks dengan lancar untuk memperbaik pengesyoran carian dan iklan.
Penyingkiran Latar Belakang: Orang dan objek boleh diasingkan dengan mudah daripada latar belakang asal dan digantikan dengan pemandangan latar belakang yang lain, sekali gus mengubah rupa dan rasa imej.
Penyesuaian Model: Kurangkan kos dan masa untuk menghantar model tersuai untuk memadankan keperluan perniagaan yang unik dengan lebih ketepatan, walaupun dengan sejumlah kecil imej yang tersedia.
Ringkasan Video: Cari dan berinteraksi dengan kandungan video, pemikiran dan penulisan dengan cara intuitif yang sama seperti yang dilakukan oleh manusia. Boleh membantu mencari kandungan yang berkaitan dan tidak memerlukan metadata tambahan.
Tiffany Ong, pengurus produk produk pengguna Reddit, berkata melalui teknologi Vision Microsoft, ia boleh memudahkan pengguna menemui dan memahami kandungan di Reddit.
Penerangan imej yang baru dicipta menjadikan Reddit lebih mudah untuk diakses, menggunakan perihalan imej untuk membantu memperbaik hasil carian untuk artikel, memberi pengguna Reddit lebih banyak peluang untuk meneroka imej di tapak, mengambil bahagian dalam perbualan dan akhirnya membina hubungan dan rasa masyarakat.
Florence mampu menjana sehingga 10,000 teg bagi setiap imej, memberikan Reddit lebih kawalan ke atas bilangan objek dalam imej dan membantu menjana penerangan imej yang lebih baik.
Microsoft 365
Selain pusat data Microsoft, Microsoft juga menambah baik aplikasi Microsoft 365 (termasuk Teams, PowerPoint, Outlook, Word, Designer, OneDrive) perkhidmatan Vision keupayaan.
Dengan bantuan keupayaan pembahagian imej, Teams memacu inovasi dalam ruang digital dan membawa pengalaman mesyuarat maya ke tahap yang lebih tinggi.
PowerPoint, Outlook dan Word meningkatkan kebolehaksesan dengan penerangan imej yang menggantikan teks secara automatik.
Microsoft Designer dan OneDrive sedang memudahkan kebolehtemuan dan pengeditan imej dengan perihalan imej yang dipertingkat, carian imej dan penjanaan latar belakang.
Pusat data Microsoft memanfaatkan Perkhidmatan Visi untuk meningkatkan keselamatan dan kebolehpercayaan infrastruktur.
Jennison Asuncon, ketua kejuruteraan kebolehcapaian LinkedIn, berkata bahawa lebih daripada 40% siaran di LinkedIn mengandungi sekurang-kurangnya satu imej, yang amat berguna untuk orang buta atau orang berpendapatan rendah Bagi pengguna yang rabun, perkhidmatan penglihatan memberikan semua pengguna akses yang sama kepada membaca dan membolehkan mereka mengambil bahagian dalam perbualan dalam talian.

Dengan Perkhidmatan Kognisi Visual Azure, LinkedIn boleh menyediakan penerangan imej automatik untuk mengedit dan menyokong teks alternatif, yang merupakan pengalaman baharu.
Bukan sahaja saya teruja tentang perkara ini, rakan sekerja saya baru sahaja berkongsi foto mereka menghadiri acara itu, dan Ketua Pegawai Eksekutif LinkedIn Ryan Roslansky berada dalam foto itu.
Berinovasi secara bertanggungjawab
Menyemak Prinsip Kecerdasan Buatan Bertanggungjawab, anda boleh mempelajari cara Microsoft komited untuk membangunkan sistem kecerdasan buatan untuk meningkatkan kebolehcapaian dunia .

Microsoft komited untuk membantu organisasi memanfaatkan sepenuhnya kecerdasan buatan dan melabur banyak dalam projek yang menyediakan teknologi, sumber dan kepakaran untuk memperkasakan mereka yang berusaha mewujudkan dunia yang lebih mampan dan lebih baik . Akses yang lebih selamat dan lebih mudah kepada dunia keupayaan manusia.
Multimodaliti adalah masa depan
Banyak gergasi teknologi termasuk Microsoft dan Google secara mengejutkan konsisten dalam arah pembangunan kecerdasan buatan Mereka percaya bahawa "model pelbagai mod" adalah kunci untuk meningkatkan sistem kecerdasan buatan. Cara terbaik untuk mencapai keupayaan ialah model tunggal boleh memahami bahasa, imej, video dan audio, dsb. secara serentak dan boleh menyelesaikan tugasan yang tidak dapat diselesaikan oleh model mod tunggal, seperti menambah penerangan teks pada video.

Mengapa tidak menggabungkan beberapa model "modal tunggal" untuk mencapai tujuan yang sama, seperti menggunakan satu model untuk memahami imej dan model lain menggunakan Untuk memahami bahasa?
Sebab pertama ialah, dengan maklumat latar belakang yang disediakan oleh modaliti lain, model berbilang modal boleh berprestasi lebih baik daripada model mod tunggal pada tugas yang sama dalam beberapa situasi.
Sebagai contoh, pembantu AI yang memahami imej, data harga dan sejarah pembelian boleh memberikan pengesyoran produk diperibadikan yang lebih baik daripada AI yang "hanya memahami data harga".
Dan dari perspektif pengiraan, model berbilang modal selalunya lebih cekap, yang boleh meningkatkan kelajuan pemprosesan data dan mengurangkan kos bahagian belakang.
Tidak dinafikan bahawa semua syarikat perniagaan tidak sabar-sabar untuk mengurangkan kos dan meningkatkan kecekapan.
Florence boleh memahami imej, video dan bahasa dan hubungan antara modaliti ini, supaya ia boleh melakukan beberapa tugas yang tidak dapat diselesaikan dengan satu modaliti, seperti mengukur persamaan antara imej dan teks, membahagikan objek foto dan kemudian tampalkannya pada latar belakang yang lain.
Hampir semua latihan model AI menghadapi masalah hak cipta data John Montgomery, naib presiden korporat (CVP) Azure AI, tidak mendedahkan banyak maklumat semasa menjawab tentang "data latihan Florence". ialah sumber data yang "diperolehi secara bertanggungjawab", termasuk data daripada rakan kongsi sebagai tambahan, Montgomery berkata bahawa kandungan yang berpotensi bermasalah telah dialih keluar daripada data latihan, yang juga merupakan ciri biasa set data latihan awam.

Montgomery percaya bahawa apabila menggunakan model asas yang besar, perkara yang paling penting ialah memastikan kualiti set data latihan untuk mewujudkan asas bagi model penyesuaian bagi setiap penglihatan Microsoft menyasarkan Model yang ditala untuk setiap tugas visi diuji untuk kes-kes yang adil, bermusuhan dan mencabar, dan melaksanakan perkhidmatan penyederhanaan kandungan yang sama seperti Azure Open AI Service dan DALL-E.
Pada masa hadapan, pengguna boleh menggunakan Florence untuk melakukan lebih banyak lagi, seperti mengesan kecacatan dalam proses pembuatan dan membolehkan daftar keluar sendiri di kedai runcit.
Walau bagaimanapun, Montgomery menegaskan bahawa kes penggunaan ini sebenarnya tidak memerlukan model penglihatan pelbagai mod, tetapi beliau menegaskan bahawa pelbagai mod boleh menambah sesuatu yang berharga dalam proses itu.
Florence ialah model visual yang "difikirkan semula sepenuhnya" yang membuka dunia baharu kemungkinan yang tidak diketahui sebaik sahaja proses terjemahan mudah dan berkualiti tinggi dicapai antara imej dan teks.
Pelanggan boleh mengalami carian imej yang dipertingkatkan dengan ketara, melatih model imej dan penglihatan serta jenis model lain seperti bahasa dan pertuturan ke dalam jenis aplikasi yang sama sekali baharu dan dengan mudah meningkatkan kualiti model tersuai.
Atas ialah kandungan terperinci Microsoft menang! Berbilion latihan pasangan imej teks, Florence berbilang modal memulakan percubaan percuma, tersedia di Azure. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Alamat masuk versi antarabangsa Microsoft bing (pintu masuk enjin carian bing)
Mar 14, 2024 pm 01:37 PM
Alamat masuk versi antarabangsa Microsoft bing (pintu masuk enjin carian bing)
Mar 14, 2024 pm 01:37 PM
Bing ialah enjin carian dalam talian yang dilancarkan oleh Microsoft Fungsi carian sangat berkuasa dan mempunyai dua pintu masuk: versi domestik dan versi antarabangsa. Di manakah pintu masuk ke dua versi ini? Bagaimana untuk mengakses versi antarabangsa? Mari kita lihat butiran di bawah. Pintu masuk laman web versi Cina Bing: https://cn.bing.com/ Pintu masuk laman web versi antarabangsa Bing: https://global.bing.com/ Bagaimana untuk mengakses versi antarabangsa Bing? 1. Mula-mula masukkan URL untuk membuka Bing: https://www.bing.com/ 2. Anda boleh melihat bahawa terdapat pilihan untuk versi domestik dan antarabangsa Kami hanya perlu memilih versi antarabangsa dan masukkan kata kunci.
 Peningkatan Microsoft Edge: Fungsi penjimatan kata laluan automatik diharamkan? ! Pengguna terkejut!
Apr 19, 2024 am 08:13 AM
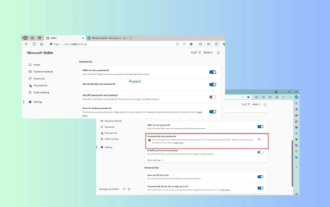
Peningkatan Microsoft Edge: Fungsi penjimatan kata laluan automatik diharamkan? ! Pengguna terkejut!
Apr 19, 2024 am 08:13 AM
Berita pada 18 April: Baru-baru ini, beberapa pengguna pelayar Microsoft Edge menggunakan saluran Canary melaporkan bahawa selepas menaik taraf kepada versi terkini, mereka mendapati bahawa pilihan untuk menyimpan kata laluan secara automatik telah dilumpuhkan. Selepas penyiasatan, didapati bahawa ini adalah pelarasan kecil selepas naik taraf penyemak imbas, bukannya pembatalan fungsi. Sebelum menggunakan penyemak imbas Edge untuk mengakses laman web, pengguna melaporkan bahawa penyemak imbas akan muncul tetingkap bertanya sama ada mereka mahu menyimpan kata laluan log masuk untuk tapak web tersebut. Selepas memilih untuk menyimpan, Edge secara automatik akan mengisi akaun dan kata laluan yang disimpan apabila anda log masuk seterusnya, memberikan pengguna kemudahan yang hebat. Tetapi kemas kini terkini menyerupai tweak, menukar tetapan lalai. Pengguna perlu memilih untuk menyimpan kata laluan dan kemudian menghidupkan pengisian automatik akaun yang disimpan dan kata laluan dalam tetapan.
 Microsoft mengeluarkan kemas kini kumulatif Win11 Ogos: meningkatkan keselamatan, mengoptimumkan skrin kunci, dsb.
Aug 14, 2024 am 10:39 AM
Microsoft mengeluarkan kemas kini kumulatif Win11 Ogos: meningkatkan keselamatan, mengoptimumkan skrin kunci, dsb.
Aug 14, 2024 am 10:39 AM
Menurut berita dari tapak ini pada 14 Ogos, semasa hari acara August Patch Tuesday hari ini, Microsoft mengeluarkan kemas kini kumulatif untuk sistem Windows 11, termasuk kemas kini KB5041585 untuk 22H2 dan 23H2, dan kemas kini KB5041592 untuk 21H2. Selepas peralatan yang disebutkan di atas dipasang dengan kemas kini kumulatif Ogos, perubahan nombor versi yang dilampirkan pada tapak ini adalah seperti berikut: Selepas pemasangan peralatan 21H2, nombor versi meningkat kepada Build22000.314722H2 Selepas pemasangan peralatan, nombor versi meningkat kepada Build22621.403723H2 Selepas pemasangan peralatan, nombor versi meningkat kepada Build22631.4037 Kandungan utama kemas kini KB5041585 untuk Windows 1121H2 adalah seperti berikut: Penambahbaikan.
 Fungsi Microsoft Win11 untuk memampatkan fail 7z dan TAR telah diturunkan daripada versi 24H2 kepada 23H2/22H2
Apr 28, 2024 am 09:19 AM
Fungsi Microsoft Win11 untuk memampatkan fail 7z dan TAR telah diturunkan daripada versi 24H2 kepada 23H2/22H2
Apr 28, 2024 am 09:19 AM
Menurut berita dari laman web ini pada 27 April, Microsoft mengeluarkan kemas kini versi pratonton Windows 11 Build 26100 ke saluran Canary dan Dev awal bulan ini, yang dijangka menjadi calon versi RTM bagi kemas kini Windows 1124H2. Perubahan utama dalam versi baharu ialah peneroka fail, penyepaduan Copilot, penyuntingan metadata fail PNG, penciptaan fail termampat TAR dan 7z, dsb. @PhantomOfEarth mendapati bahawa Microsoft telah menurunkan beberapa fungsi versi 24H2 (Germanium) kepada versi 23H2/22H2 (Nikel), seperti mencipta fail mampat TAR dan 7z. Seperti yang ditunjukkan dalam rajah, Windows 11 akan menyokong penciptaan asli TAR
 Pop timbul skrin penuh Microsoft menggesa pengguna Windows 10 untuk menyegerakan dan menaik taraf kepada Windows 11
Jun 06, 2024 am 11:35 AM
Pop timbul skrin penuh Microsoft menggesa pengguna Windows 10 untuk menyegerakan dan menaik taraf kepada Windows 11
Jun 06, 2024 am 11:35 AM
Menurut berita pada 3 Jun, Microsoft sedang aktif menghantar pemberitahuan skrin penuh kepada semua pengguna Windows 10 untuk menggalakkan mereka menaik taraf kepada sistem pengendalian Windows 11. Langkah ini melibatkan peranti yang konfigurasi perkakasannya tidak menyokong sistem baharu. Sejak 2015, Windows 10 telah menduduki hampir 70% bahagian pasaran, dengan kukuh mengukuhkan penguasaannya sebagai sistem pengendalian Windows. Walau bagaimanapun, bahagian pasaran jauh melebihi bahagian pasaran 82%, dan bahagian pasaran jauh melebihi Windows 11, yang akan dikeluarkan pada 2021. Walaupun Windows 11 telah dilancarkan selama hampir tiga tahun, penembusan pasarannya masih perlahan. Microsoft telah mengumumkan bahawa ia akan menamatkan sokongan teknikal untuk Windows 10 selepas 14 Oktober 2025 untuk memberi tumpuan lebih kepada
 Kemas kini pelayar Microsoft Edge: Menambah fungsi 'zum dalam imej' untuk meningkatkan pengalaman pengguna
Mar 21, 2024 pm 01:40 PM
Kemas kini pelayar Microsoft Edge: Menambah fungsi 'zum dalam imej' untuk meningkatkan pengalaman pengguna
Mar 21, 2024 pm 01:40 PM
Menurut berita pada 21 Mac, Microsoft baru-baru ini mengemas kini pelayar Microsoft Edge dan menambah fungsi "besarkan imej" praktikal. Kini, apabila menggunakan pelayar Edge, pengguna boleh mencari ciri baharu ini dengan mudah dalam menu pop timbul dengan hanya mengklik kanan pada imej. Apa yang lebih mudah ialah pengguna juga boleh menuding kursor pada imej dan kemudian klik dua kali kekunci Ctrl untuk menggunakan fungsi mengezum masuk dengan cepat pada imej. Mengikut pemahaman editor, pelayar Microsoft Edge yang baru dikeluarkan telah diuji untuk ciri-ciri baru dalam saluran Canary. Versi pelayar yang stabil juga secara rasminya telah melancarkan fungsi "besarkan imej" praktikal, memberikan pengguna pengalaman menyemak imbas imej yang lebih mudah. Media sains dan teknologi asing turut memberi perhatian kepada perkara ini
 Microsoft Z1000 SSD muncul dalam talian, dilengkapi dengan pengawal CNEXLabs yang misteri
Mar 11, 2024 pm 01:50 PM
Microsoft Z1000 SSD muncul dalam talian, dilengkapi dengan pengawal CNEXLabs yang misteri
Mar 11, 2024 pm 01:50 PM
Menurut berita dari laman web ini pada 11 Mac, sumber Yuki Yasuo-YuuKi_AnS baru-baru ini berkongsi satu siri gambar sampel pemacu keadaan pepejal Microsoft Z1000 pada platform X. Daripada maklumat label, kami mengetahui bahawa Z1000 ini ialah Sampel Kejuruteraan (sampel kejuruteraan) dengan kapasiti 960GB Ia dihasilkan pada 18 Mei 2020. Ia dikuasakan oleh DC3.3V dan mempunyai penggunaan kuasa nominal sebanyak 15W. Menurut sumber, ia menyokong protokol NVMe1.2. ▲Foto hadapan Microsoft Z1000 SSD (dengan label) ▲Foto hadapan Microsoft Z1000 SSD (tanpa label) ▲Foto belakang Microsoft Z1000 SSD ▲Foto belakang Microsoft Z1000 SSD - rujukan dekat kawalan utama Yuuki Yasuho-YuuKi_An
 Microsoft merancang untuk menghapuskan NTLM secara berperingkat dalam Windows 11 pada separuh kedua 2024 dan beralih sepenuhnya kepada pengesahan Kerberos
Jun 09, 2024 pm 04:17 PM
Microsoft merancang untuk menghapuskan NTLM secara berperingkat dalam Windows 11 pada separuh kedua 2024 dan beralih sepenuhnya kepada pengesahan Kerberos
Jun 09, 2024 pm 04:17 PM
Pada separuh kedua 2024, Blog Keselamatan Microsoft rasmi menerbitkan mesej sebagai respons kepada panggilan daripada komuniti keselamatan. Syarikat itu merancang untuk menghapuskan protokol pengesahan Pengurus NTLAN (NTLM) dalam Windows 11, dikeluarkan pada separuh kedua 2024, untuk meningkatkan keselamatan. Menurut penjelasan sebelum ini, Microsoft telah pun membuat langkah serupa sebelum ini. Pada 12 Oktober tahun lepas, Microsoft mencadangkan pelan peralihan dalam siaran akhbar rasmi yang bertujuan untuk menghapuskan kaedah pengesahan NTLM secara berperingkat dan mendorong lebih banyak perusahaan dan pengguna beralih kepada Kerberos. Untuk membantu perusahaan yang mungkin mengalami masalah dengan aplikasi dan perkhidmatan berwayar tegar selepas mematikan pengesahan NTLM, Microsoft menyediakan IAKerb dan
