
 pembangunan bahagian belakang
Tutorial Python
Tiga puluh fungsi Python menyelesaikan 99% tugas pemprosesan data!
pembangunan bahagian belakang
Tutorial Python
Tiga puluh fungsi Python menyelesaikan 99% tugas pemprosesan data!
Tiga puluh fungsi Python menyelesaikan 99% tugas pemprosesan data!


Kami tahu bahawa Pandas ialah pustaka analisis dan manipulasi data yang paling banyak digunakan dalam Python. Ia menyediakan banyak fungsi dan kaedah untuk menyelesaikan masalah pemprosesan data dengan cepat dalam analisis data.
Untuk menguasai penggunaan fungsi Python dengan lebih baik, saya mengambil set data churn pelanggan sebagai contoh untuk berkongsi 30 fungsi dan kaedah yang paling biasa digunakan dalam proses analisis data. Data boleh dimuat turun di akhir artikel.
Data kelihatan seperti ini:
import numpy as np
import pandas as pd
df = pd.read_csv("Churn_Modelling.csv")
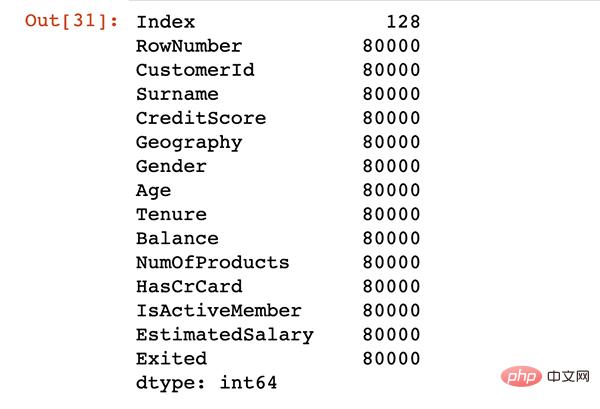
print(df.shape)
df.columns
Keluaran Hasil
(10000, 14) Index(['RowNumber', 'CustomerId', 'Surname', 'CreditScore', 'Geography','Gender', 'Age', 'Tenure', 'Balance', 'NumOfProducts', 'HasCrCard','IsActiveMember', 'EstimatedSalary', 'Exited'],dtype='object')
1. >
Penerangan: Parameter "paksi" ditetapkan kepada 1 untuk meletakkan lajur dan 0 untuk meletakkan baris. Tetapkan parameter "inplace=True" kepada True untuk menyimpan perubahan. Kami menolak 4 lajur, jadi bilangan lajur dikurangkan daripada 14 kepada 10.df.drop(['RowNumber', 'CustomerId', 'Surname', 'CreditScore'], axis=1, inplace=True) print(df[:2]) print(df.shape)
GeographyGenderAgeTenureBalanceNumOfProductsHasCrCard 0FranceFemale 42 20.011 IsActiveMemberEstimatedSalaryExited 0 1101348.88 1 (10000, 10)
df_spec = pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
df_spec.head()
df_partial = pd.read_csv("Churn_Modelling.csv", nrows=5000)
print(df_partial.shape)
df= pd.read_csv("Churn_Modelling.csv", usecols=['Gender', 'Age', 'Tenure', 'Balance'])
df_sample = df.sample(n=1000)
df_sample2 = df.sample(frac=0.1)
df.isna().sum()
- Kami mula-mula mencipta 20 indeks rawak untuk pemilihan.
missing_index = np.random.randint(10000, size=20)
df.loc[missing_index, ['Balance','Geography']] = np.nan
df.iloc[missing_index, -1] = np.nan
avg = df['Balance'].mean() df['Balance'].fillna(value=avg, inplace=True)
Cara lain untuk menangani nilai yang hilang adalah dengan memadamkannya. Kod berikut akan memadamkan baris dengan sebarang nilai yang hilang.
9. Pilih baris berdasarkan syarat Dalam sesetengah kes, kami memerlukan pemerhatian (iaitu baris) yang sesuai dengan syarat tertentudf.dropna(axis=0, how='any', inplace=True)
france_churn = df[(df.Geography == 'France') & (df.Exited == 1)] france_churn.Geography.value_counts()
df2 = df.query('80000 < Balance < 100000')
df2 = df.query('80000 < Balance < 100000'
df2 = df.query('80000 < Balance < 100000')
df[df['Tenure'].isin([4,6,9,10])][:3]
 Fungsi Pandas Groupby ialah fungsi serba boleh dan mudah digunakan yang membantu mendapatkan gambaran keseluruhan tentang anda data. Ia menjadikannya lebih mudah untuk meneroka set data dan mendedahkan hubungan asas antara pembolehubah.
Fungsi Pandas Groupby ialah fungsi serba boleh dan mudah digunakan yang membantu mendapatkan gambaran keseluruhan tentang anda data. Ia menjadikannya lebih mudah untuk meneroka set data dan mendedahkan hubungan asas antara pembolehubah.
Kami akan melakukan beberapa contoh fungsi nisbah kumpulan. Mari kita mulakan dengan mudah. Kod berikut akan mengumpulkan baris berdasarkan Geografi, gabungan Jantina, dan kemudian memberikan aliran purata setiap kumpulan
13.Groupby digabungkan dengan fungsi agregat fungsi agg membenarkan pada kumpulan Gunakan berbilang fungsi agregat, menghantar senarai fungsi sebagai argumen.df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).mean()
df[['Geography','Gender','Exited']].groupby(['Geography','Gender']).agg(['mean','count'])
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg({'Exited':'sum', 'Balance':'mean'})
df_summary.rename(columns={'Exited':'# of churned customers', 'Balance':'Average Balance of Customers'},inplace=True)
import pandas as pd
df_summary = df[['Geography','Exited','Balance']].groupby('Geography').agg(Number_of_churned_customers = pd.NamedAgg('Exited', 'sum'),Average_balance_of_customers = pd.NamedAgg('Balance', 'mean'))
print(df_summary)
 Adakah anda perasan format data dalam gambar di atas. Kita boleh mengubahnya dengan menetapkan semula indeks.
Adakah anda perasan format data dalam gambar di atas. Kita boleh mengubahnya dengan menetapkan semula indeks.
print(df_summary.reset_index())
 Dalam beberapa kes, kita perlu menetapkan semula indeks dan memadam indeks asal pada masa yang sama. masa.
Dalam beberapa kes, kita perlu menetapkan semula indeks dan memadam indeks asal pada masa yang sama. masa.
df[['Geography','Exited','Balance']].sample(n=6).reset_index(drop=True)
df_new.set_index('Geography')
group = np.random.randint(10, size=6) df_new['Group'] = group
df_new['Balance'] = df_new['Balance'].where(df_new['Group'] >= 6, 0)
df_new['rank'] = df_new['Balance'].rank(method='first', ascending=False).astype('int')
df.Geography.nunique
df.memory_usage()
23.数据类型转换
默认情况下,分类数据与对象数据类型一起存储。但是,它可能会导致不必要的内存使用,尤其是当分类变量具有较低的基数。
低基数意味着列与行数相比几乎没有唯一值。例如,地理列具有 3 个唯一值和 10000 行。
我们可以通过将其数据类型更改为"类别"来节省内存。
df['Geography'] = df['Geography'].astype('category')
24.替换值
替换函数可用于替换数据帧中的值。
df['Geography'].replace({0:'B1',1:'B2'})
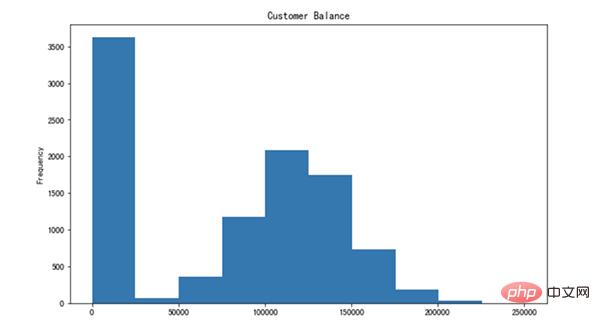
25.绘制直方图
pandas 不是一个数据可视化库,但它使得创建基本绘图变得非常简单。
我发现使用 Pandas 创建基本绘图更容易,而不是使用其他数据可视化库。
让我们创建平衡列的直方图。
26.减少浮点数小数点
pandas 可能会为浮点数显示过多的小数点。我们可以轻松地调整它。
df['Balance'].plot(kind='hist', figsize=(10,6), title='Customer Balance')
27.更改显示选项
我们可以更改各种参数的默认显示选项,而不是每次手动调整显示选项。
- get_option:返回当前选项
- set_option:更改选项 让我们将小数点的显示选项更改为 2。
pd.set_option("display.precision", 2)
可能要更改的一些其他选项包括:
- max_colwidth:列中显示的最大字符数
- max_columns:要显示的最大列数
- max_rows:要显示的最大行数
28.通过列计算百分比变化
pct_change用于计算序列中值的变化百分比。在计算时间序列或元素顺序数组中更改的百分比时,它很有用。
ser= pd.Series([2,4,5,6,72,4,6,72]) ser.pct_change()
29.基于字符串的筛选
我们可能需要根据文本数据(如客户名称)筛选观测值(行)。我已经在数据帧中添加了df_new名称。
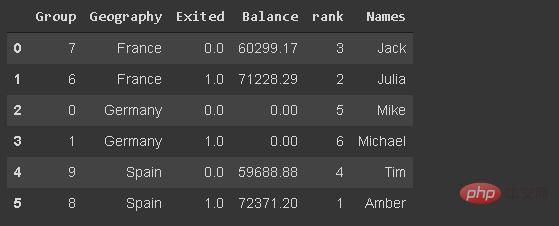
df_new[df_new.Names.str.startswith('Mi')]
我们可能需要根据文本数据(如客户名称)筛选观测值(行)。我已经在数据帧中添加了df_new名称。

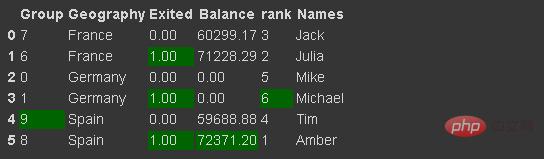
30.设置数据样式
我们可以通过使用返回 Style 对象的 Style 属性来实现此目的,它提供了许多用于格式化和显示数据框的选项。例如,我们可以突出显示最小值或最大值。
它还允许应用自定义样式函数。
df_new.style.highlight_max(axis=0, color='darkgreen')
Atas ialah kandungan terperinci Tiga puluh fungsi Python menyelesaikan 99% tugas pemprosesan data!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Bagaimana cara menyalin seluruh lajur satu data ke dalam data data lain dengan struktur yang berbeza di Python?
Apr 01, 2025 pm 11:15 PM
Bagaimana cara menyalin seluruh lajur satu data ke dalam data data lain dengan struktur yang berbeza di Python?
Apr 01, 2025 pm 11:15 PM
Apabila menggunakan Perpustakaan Pandas Python, bagaimana untuk menyalin seluruh lajur antara dua data data dengan struktur yang berbeza adalah masalah biasa. Katakan kita mempunyai dua DAT ...
 Bolehkah anotasi parameter Python menggunakan rentetan?
Apr 01, 2025 pm 08:39 PM
Bolehkah anotasi parameter Python menggunakan rentetan?
Apr 01, 2025 pm 08:39 PM
Penggunaan alternatif anotasi parameter python Dalam pengaturcaraan Python, anotasi parameter adalah fungsi yang sangat berguna yang dapat membantu pemaju memahami dan menggunakan fungsi ...
 Bagaimanakah skrip Python jelas output ke kedudukan kursor di lokasi tertentu?
Apr 01, 2025 pm 11:30 PM
Bagaimanakah skrip Python jelas output ke kedudukan kursor di lokasi tertentu?
Apr 01, 2025 pm 11:30 PM
Bagaimanakah skrip Python jelas output ke kedudukan kursor di lokasi tertentu? Semasa menulis skrip python, adalah perkara biasa untuk membersihkan output sebelumnya ke kedudukan kursor ...
 Mengapa kod saya tidak dapat mendapatkan data yang dikembalikan oleh API? Bagaimana menyelesaikan masalah ini?
Apr 01, 2025 pm 08:09 PM
Mengapa kod saya tidak dapat mendapatkan data yang dikembalikan oleh API? Bagaimana menyelesaikan masalah ini?
Apr 01, 2025 pm 08:09 PM
Mengapa kod saya tidak dapat mendapatkan data yang dikembalikan oleh API? Dalam pengaturcaraan, kita sering menghadapi masalah mengembalikan nilai null apabila panggilan API, yang bukan sahaja mengelirukan ...
 Bagaimanakah uvicorn terus mendengar permintaan http tanpa serving_forever ()?
Apr 01, 2025 pm 10:51 PM
Bagaimanakah uvicorn terus mendengar permintaan http tanpa serving_forever ()?
Apr 01, 2025 pm 10:51 PM
Bagaimanakah Uvicorn terus mendengar permintaan HTTP? Uvicorn adalah pelayan web ringan berdasarkan ASGI. Salah satu fungsi terasnya ialah mendengar permintaan HTTP dan teruskan ...
 Bagaimana secara dinamik membuat objek melalui rentetan dan panggil kaedahnya dalam Python?
Apr 01, 2025 pm 11:18 PM
Bagaimana secara dinamik membuat objek melalui rentetan dan panggil kaedahnya dalam Python?
Apr 01, 2025 pm 11:18 PM
Di Python, bagaimana untuk membuat objek secara dinamik melalui rentetan dan panggil kaedahnya? Ini adalah keperluan pengaturcaraan yang biasa, terutamanya jika perlu dikonfigurasikan atau dijalankan ...
 Bagaimana untuk menggunakan Go atau Rust untuk memanggil skrip Python untuk mencapai pelaksanaan selari yang benar?
Apr 01, 2025 pm 11:39 PM
Bagaimana untuk menggunakan Go atau Rust untuk memanggil skrip Python untuk mencapai pelaksanaan selari yang benar?
Apr 01, 2025 pm 11:39 PM
Bagaimana untuk menggunakan Go atau Rust untuk memanggil skrip Python untuk mencapai pelaksanaan selari yang benar? Baru -baru ini saya telah menggunakan python ...
 Di mana untuk memuat turun fail python .whl di bawah tingkap?
Apr 01, 2025 pm 08:18 PM
Di mana untuk memuat turun fail python .whl di bawah tingkap?
Apr 01, 2025 pm 08:18 PM
Kaedah muat turun Perpustakaan Python (.whl) Meneroka kesukaran banyak pemaju Python apabila memasang perpustakaan tertentu pada sistem Windows. Penyelesaian yang sama ...
