
 Peranti teknologi
AI
Universiti Harvard kacau: DALL-E 2 hanyalah 'raksasa gam', dan ketepatan penjanaannya hanya 22%
Peranti teknologi
AI
Universiti Harvard kacau: DALL-E 2 hanyalah 'raksasa gam', dan ketepatan penjanaannya hanya 22%
Universiti Harvard kacau: DALL-E 2 hanyalah 'raksasa gam', dan ketepatan penjanaannya hanya 22%

Apabila DALL-E 2 mula-mula dikeluarkan, lukisan yang dihasilkan hampir dapat menghasilkan semula teks input dengan resolusi definisi tinggi dan imaginasi lukisan yang kuat juga membuatkan pelbagai netizen memanggilnya "sangat keren".

Tetapi kertas penyelidikan baharu dari Universiti Harvard baru-baru ini menunjukkan bahawa walaupun imej yang dihasilkan oleh DALL-E 2 adalah indah, ia mungkin hanya melekatkan beberapa entiti dalam teks Diambil bersama , hubungan spatial yang dinyatakan dalam teks tidak juga difahami!

Pautan kertas: https://arxiv.org/pdf/2208.00005.pdf
Pautan data: https://osf.io/sm68h/
Sebagai contoh, diberi gesaan teks "A cup on a spoon", anda boleh melihat bahawa dalam imej yang dijana oleh DALL-E 2, anda boleh melihat bahawa sesetengah imej tidak memenuhi perhubungan "on" .
Tetapi dalam set latihan, gabungan cawan teh dan sudu yang DALL-E 2 mungkin nampak semuanya "masuk", manakala "hidup" agak jarang, jadi antara keduanya Dari segi penjanaan perhubungan ini, kadar ketepatan juga berbeza.

Jadi untuk meneroka sama ada DALL-E 2 benar-benar boleh memahami hubungan semantik dalam teks, penyelidik memilih 15 jenis hubungan, 8 daripadanya adalah hubungan ruang ( hubungan fizikal) ), termasuk dalam, pada, bawah, selimut, dekat, terhalang oleh, tergantung dan terikat kepada 7 hubungan tindakan (hubungan agen), termasuk menolak, menarik, menyentuh, memukul, menendang, membantu dan menyembunyikan.
Set entiti dalam teks adalah terhad kepada 12, dan item yang dipilih adalah item ringkas dan biasa dalam pelbagai set data, iaitu: kotak, silinder, selimut, mangkuk, cawan teh, pisau, lelaki, wanita, kanak-kanak , monyet dan iguana (iguana).

Untuk setiap jenis perhubungan, 5 gesaan dibuat dan 2 entiti dipilih secara rawak untuk diganti setiap kali, akhirnya menghasilkan 75 gesaan teks . Selepas penyerahan kepada enjin pemaparan DALL-E 2, 18 imej terjana pertama telah dipilih, menghasilkan 1350 imej.
Para penyelidik kemudian memilih 169 daripada 180 anotasi melalui ujian penaakulan akal untuk mengambil bahagian dalam proses anotasi.
Hasil eksperimen mendapati bahawa konsistensi purata antara imej yang dihasilkan oleh DALL-E 2 dan gesaan teks yang digunakan untuk menjana imej hanya 22.2% antara 75 gesaan
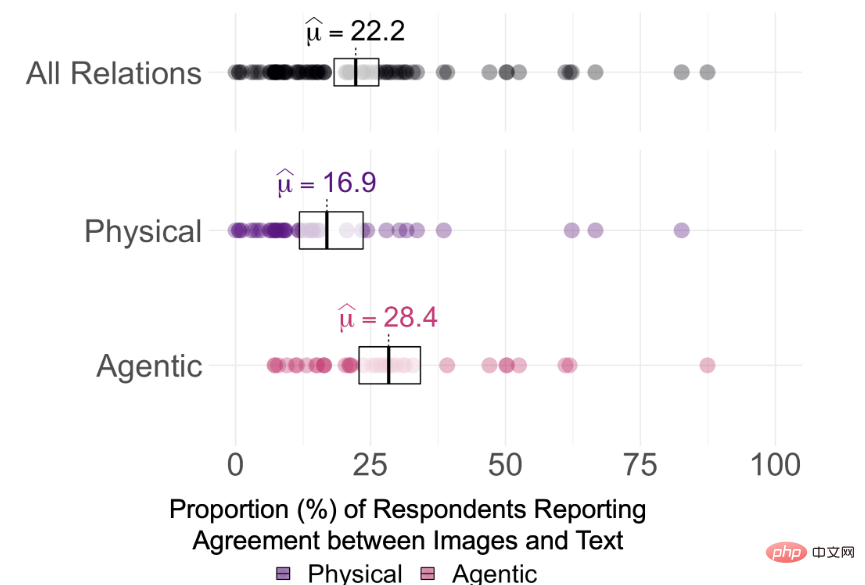
Walau bagaimanapun, adalah sukar untuk mengatakan sama ada DALL-E 2 benar-benar "memahami" perhubungan dalam teks Dengan memerhatikan skor ketekalan pencatat, berdasarkan ambang konsensus 0%, 25% dan 50%, Ujian keertian satu sampel yang diperbetulkan oleh Holm untuk setiap perhubungan menunjukkan bahawa persetujuan peserta adalah lebih tinggi secara signifikan daripada 0% pada α = 0.95 (pHolm
Jadi walaupun tanpa membetulkan beberapa perbandingan, hakikatnya imej yang dihasilkan oleh DALL-E 2 tidak memahami hubungan antara dua objek dalam teks.
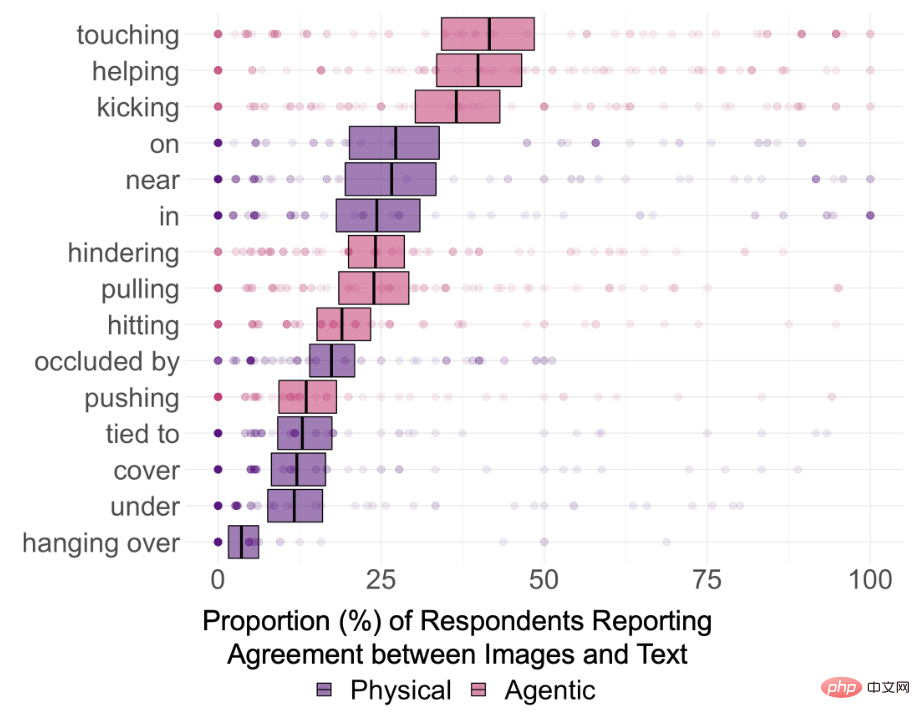
Keputusan juga menunjukkan bahawa keupayaan DALL-E untuk menyambung dua objek yang tidak berkaitan mungkin tidak sekuat yang dibayangkan, seperti "Seorang kanak-kanak menyentuh mangkuk" Konsistensi adalah 87 % kerana dalam imej dunia sebenar, kanak-kanak dan mangkuk kelihatan bersama dengan kerap.

Kadar ketekalan akhir imej yang dijana oleh "Monyet menyentuh iguana" hanya 11%, malah mungkin terdapat ralat spesies dalam imej yang diberikan.

Oleh itu, beberapa kategori imej dalam DALL-E 2 dibangunkan dengan agak baik, seperti kanak-kanak dan makanan, tetapi beberapa kategori data masih memerlukan latihan berterusan.
Walau bagaimanapun, pada masa ini DALL-E 2 masih memaparkan gaya definisi tinggi dan realistiknya di tapak web rasmi Ia masih belum jelas sama ada ia "menggabungkan dua objek" atau benar-benar memahami maklumat teks menjana imej.
Penyelidik menyatakan bahawa pemahaman hubungan ialah komponen asas kecerdasan manusia, dan prestasi lemah DALL-E 2 dalam hubungan ruang asas (seperti pada, daripada) menunjukkan bahawa ia belum lagi fleksibel dan fleksibel seperti manusia. Membina dan memahami dunia dengan teguh.
Namun, netizen berkata bahawa dapat membangunkan "gam" untuk melekatkan sesuatu sudah menjadi pencapaian yang hebat! DALL-E 2 bukan AGI dan masih banyak ruang untuk penambahbaikan pada masa hadapan Sekurang-kurangnya kami telah membuka pintu untuk menjana imej secara automatik!
Apakah masalah lain yang ada pada DALL-E 2?
Malah, sebaik sahaja DALL-E 2 dikeluarkan, sebilangan besar pengamal menjalankan analisis mendalam tentang kelebihan dan kekurangannya.

Pautan blog: https://www.lesswrong.com/posts/uKp6tBFStnsvrot5t/what-dall-e-2-can-and-cannot-do
Menulis novel dengan GPT-3 agak membosankan DALL-E 2 boleh menghasilkan beberapa ilustrasi untuk teks dan juga menghasilkan jalur komik untuk teks yang panjang.
Contohnya, DALL-E 2 boleh menambah ciri pada gambar, seperti "Seorang wanita di kedai kopi bekerja pada komputer ribanya dan memakai fon kepala, lukisan oleh Alphonse Mucha", yang boleh menjana gaya lukisan, kedai kopi dengan tepat , dan memakai fon kepala , komputer riba, dsb.

Tetapi jika perihalan ciri dalam teks melibatkan dua orang, DALL-E 2 mungkin terlupa ciri mana yang dimiliki oleh orang yang mana Contohnya, teks input ialah:
seorang budak lelaki muda berambut gelap berehat di atas katil, dan seorang wanita tua berambut kelabu duduk di kerusi di sebelah katil di bawah tingkap dengan matahari mengalir melalui, seni digital gaya Pixar.
Seorang budak lelaki muda berambut gelap berbaring di atas katil dan seorang wanita tua berambut kelabu duduk di atas kerusi di sebelah katil di bawah tingkap dengan cahaya matahari mengalir melalui, seni digital gaya Pixar.

Dapat dilihat bahawa DALL-E 2 boleh menjana tingkap, kerusi dan katil dengan betul, tetapi imej yang dihasilkan sedikit berbeza dalam kombinasi ciri umur, jantina dan rambut keliru.
Contoh lain ialah membiarkan "Captain America dan Iron Man berdiri berdampingan. Anda dapat melihat bahawa hasil yang dihasilkan jelas mempunyai ciri-ciri Captain America dan Iron Man, tetapi elemen khusus diletakkan pada orang yang berbeza". (Sebagai contoh, Iron Man memakai perisai Captain America).

Jika latar depan dan latar belakang sangat terperinci, model mungkin tidak dijana.
Sebagai contoh, teks input ialah:
Dua ekor anjing berpakaian seperti askar Rom di atas kapal lanun melihat New York City melalui kaca mata.
Dua anjing Anjing melihat New York City melalui kaca mata seperti askar Rom di atas kapal lanun.
Kali ini DALL-E 2 baru sahaja berhenti bekerja Pengarang blog mengambil masa setengah jam untuk memikirkannya Akhirnya, dia perlu bermain di "New York City dan kapal lanun" atau "a anjing dengan teleskop dan pakaian seragam askar Rom" Pilih antara.
Dall-E 2 boleh menjana imej menggunakan latar belakang generik, seperti bandar atau rak buku di perpustakaan, tetapi jika itu bukan fokus utama imej, mendapatkan butiran yang lebih halus selalunya menjadi sangat Bencana .
Walaupun DALL-E 2 boleh menjana objek biasa, seperti pelbagai kerusi mewah, jika anda memintanya menjana "basikal Alto", gambar yang terhasil akan agak serupa dengan basikal, tetapi tidak betul-betul.

Carian Basikal Otto di bawah Imej Google adalah seperti berikut.

DALL-E 2 juga tidak dapat mengeja, tetapi kadangkala akan mengeja perkataan dengan betul secara kebetulan, seperti memintanya menulis STOP pada tanda henti
Walaupun model itu sememangnya boleh menjana beberapa huruf Inggeris yang "boleh dikenali", semantik yang disambungkan masih berbeza daripada perkataan yang dijangkakan. Di sinilah DALL-E 2 tidak sebaik DALL-E generasi pertama.

Apabila menghasilkan imej yang berkaitan dengan alat muzik, DALL-E 2 seolah-olah mengingati kedudukan tangan manusia ketika bermain, tetapi tanpa tali, bermain agak janggal.

DALL-E 2 juga menyediakan fungsi penyuntingan Sebagai contoh, selepas menghasilkan imej, anda boleh menggunakan kursor untuk menyerlahkan kawasannya dan menambah penerangan lengkap pengubahsuaian. .
Namun, fungsi ini tidak selalu berfungsi Sebagai contoh, jika anda ingin menambah "rambut pendek" pada imej asal, fungsi penyuntingan akan sentiasa menambah sesuatu di tempat yang pelik.

Teknologi masih dikemas kini dan dibangunkan, menantikan DALL-E 3!
Atas ialah kandungan terperinci Universiti Harvard kacau: DALL-E 2 hanyalah 'raksasa gam', dan ketepatan penjanaannya hanya 22%. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1379
1379
 52
52

 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Artikel ini menerangkan cara menyesuaikan tahap pembalakan pelayan Apacheweb dalam sistem Debian. Dengan mengubah suai fail konfigurasi, anda boleh mengawal tahap maklumat log yang direkodkan oleh Apache. Kaedah 1: Ubah suai fail konfigurasi utama untuk mencari fail konfigurasi: Fail konfigurasi apache2.x biasanya terletak di direktori/etc/apache2/direktori. Nama fail mungkin apache2.conf atau httpd.conf, bergantung pada kaedah pemasangan anda. Edit Fail Konfigurasi: Buka Fail Konfigurasi dengan Kebenaran Root Menggunakan Editor Teks (seperti Nano): Sudonano/ETC/APACHE2/APACHE2.CONF
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Dalam sistem Debian, panggilan sistem Readdir digunakan untuk membaca kandungan direktori. Jika prestasinya tidak baik, cuba strategi pengoptimuman berikut: Memudahkan bilangan fail direktori: Split direktori besar ke dalam pelbagai direktori kecil sebanyak mungkin, mengurangkan bilangan item yang diproses setiap panggilan readdir. Dayakan Caching Kandungan Direktori: Bina mekanisme cache, kemas kini cache secara teratur atau apabila kandungan direktori berubah, dan mengurangkan panggilan kerap ke Readdir. Cafh memori (seperti memcached atau redis) atau cache tempatan (seperti fail atau pangkalan data) boleh dipertimbangkan. Mengamalkan struktur data yang cekap: Sekiranya anda melaksanakan traversal direktori sendiri, pilih struktur data yang lebih cekap (seperti jadual hash dan bukannya carian linear) untuk menyimpan dan mengakses maklumat direktori
 Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Dalam sistem Debian, fungsi Readdir digunakan untuk membaca kandungan direktori, tetapi urutan yang dikembalikannya tidak ditentukan sebelumnya. Untuk menyusun fail dalam direktori, anda perlu membaca semua fail terlebih dahulu, dan kemudian menyusunnya menggunakan fungsi QSORT. Kod berikut menunjukkan cara menyusun fail direktori menggunakan ReadDir dan QSORT dalam sistem Debian:#termasuk#termasuk#termasuk#termasuk // fungsi perbandingan adat, yang digunakan untuk qSortintCompare (Constvoid*A, Constvoid*b) {Returnstrcmp (*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Cara Melakukan Pengesahan Tandatangan Digital dengan Debian Openssl
Apr 13, 2025 am 11:09 AM
Cara Melakukan Pengesahan Tandatangan Digital dengan Debian Openssl
Apr 13, 2025 am 11:09 AM
Menggunakan OpenSSL untuk Pengesahan Tandatangan Digital pada Sistem Debian, anda boleh mengikuti langkah -langkah berikut: Penyediaan untuk memasang OpenSSL: Pastikan sistem Debian anda telah dipasang. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasangnya: sudoaptdateudoaptininstallopenssl untuk mendapatkan kunci awam: Pengesahan tandatangan digital memerlukan kunci awam penandatangan. Biasanya, kunci awam akan disediakan dalam bentuk fail, seperti public_key.pe
 Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Dalam sistem Debian, OpenSSL adalah perpustakaan penting untuk pengurusan penyulitan, penyahsulitan dan sijil. Untuk mengelakkan serangan lelaki-dalam-pertengahan (MITM), langkah-langkah berikut boleh diambil: Gunakan HTTPS: Pastikan semua permintaan rangkaian menggunakan protokol HTTPS dan bukannya HTTP. HTTPS menggunakan TLS (Protokol Keselamatan Lapisan Pengangkutan) untuk menyulitkan data komunikasi untuk memastikan data tidak dicuri atau diganggu semasa penghantaran. Sahkan Sijil Pelayan: Sahkan secara manual Sijil Pelayan pada klien untuk memastikan ia boleh dipercayai. Pelayan boleh disahkan secara manual melalui kaedah perwakilan urlSession
