

Belanjakan 1 yuan untuk menjadikan tapak web anda menyokong ChatGPT

Artikel ini dicetak semula daripada akaun awam WeChat "Front-end Sinan", yang ditulis oleh Tusi. Untuk mencetak semula artikel ini, sila hubungi akaun awam Sinan bahagian hadapan.
ChatGPT telah menjadi begitu popular dalam kalangan teknikal baru-baru ini, dan kalangan pengundian juga telah dibanjiri. Saya juga memutuskan untuk menyertai keseronokan dan menambah fungsi perbualan ChatGPT pada blog saya.
Lampirkan pautan percubaan dahulu, kod sumber juga boleh didapati di bahagian bawah.
Terima kasih atas sokongan anda Kuota percuma akaun peribadi Open AI saya telah kehabisan. Saya minta maaf di bahagian belakang.
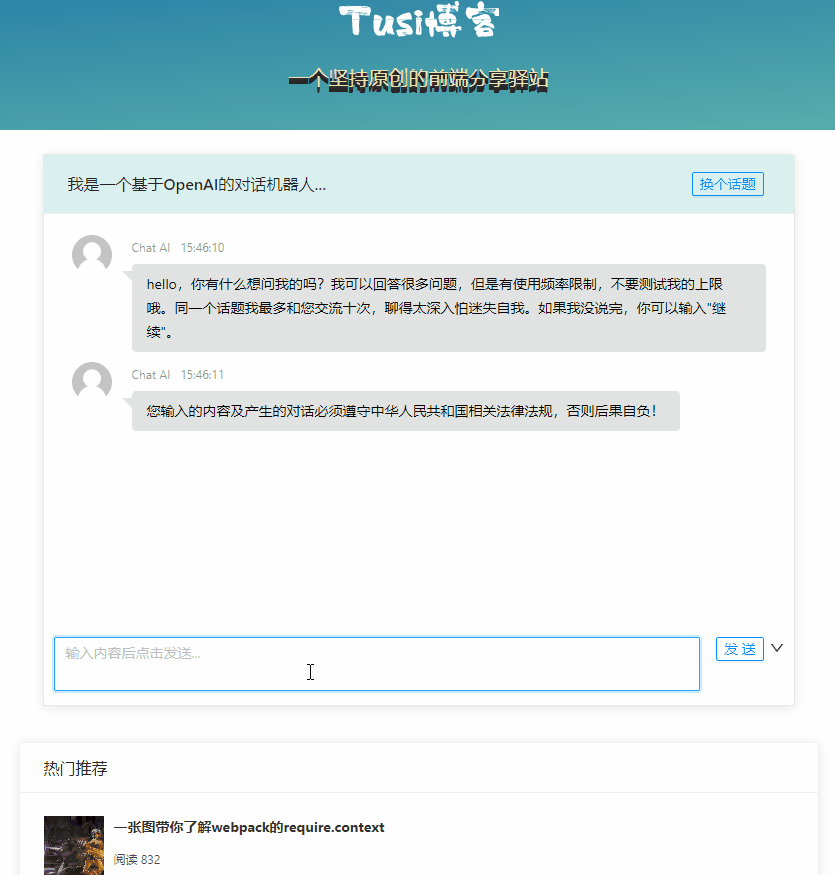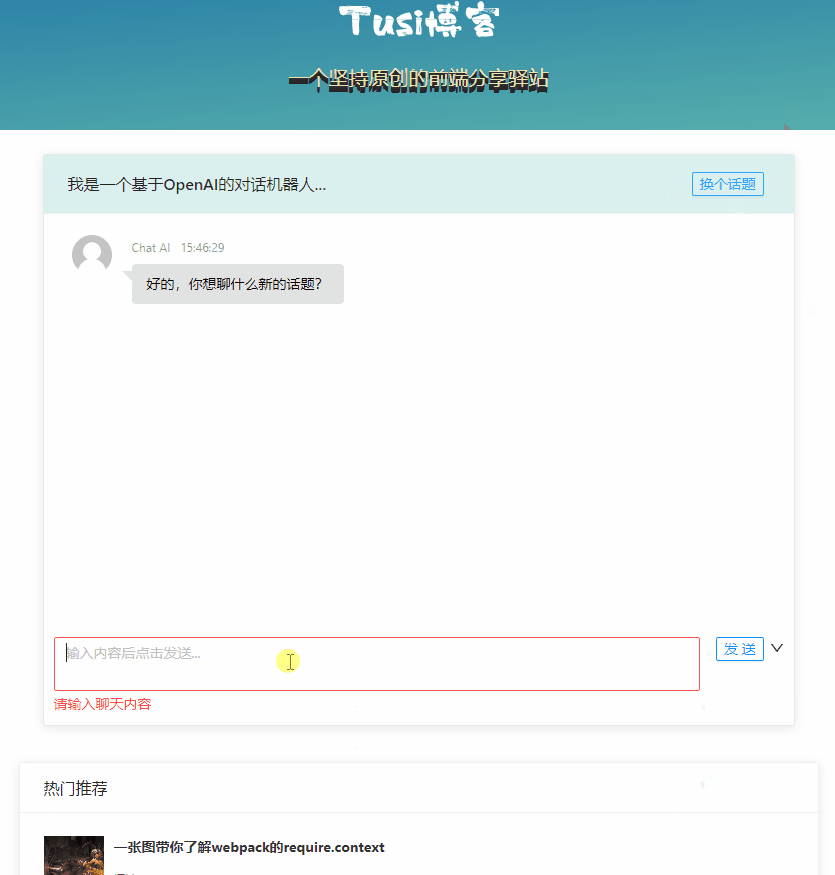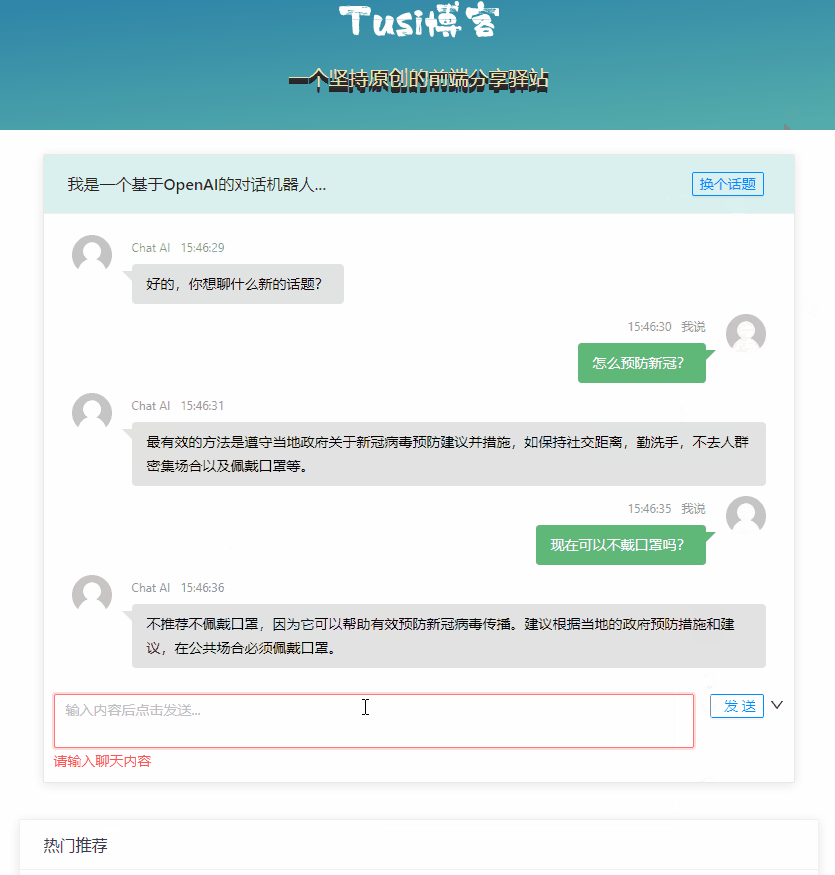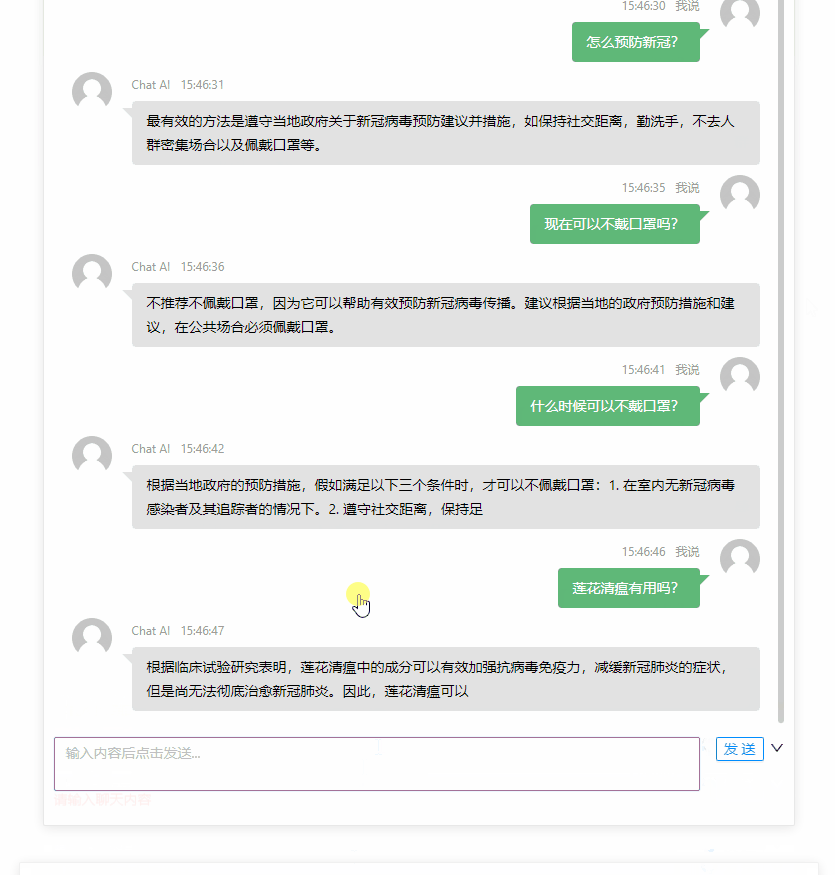
Alami ChatGPT
ChatGPT ialah model dialog AI yang dilatih oleh Open AI yang boleh menyokong dialog pintar dalam pelbagai senario.

Jika anda ingin mengalami ChatGPT, anda mesti terlebih dahulu mendaftar akaun Namun, produk ini tidak boleh digunakan secara langsung pada rangkaian domestik, dan anda perlu menyelesaikan masalah rangkaian sendiri .
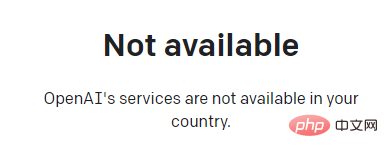
Selepas menyelesaikan masalah rangkaian, anda akan diminta untuk memberikan pengesahan e-mel semasa mendaftar
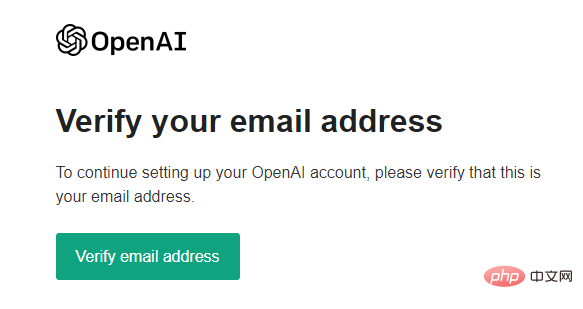
Kemudian anda perlu. untuk mengesahkan nombor telefon bimbit anda Malangnya, nombor telefon bimbit domestik tidak boleh digunakan.
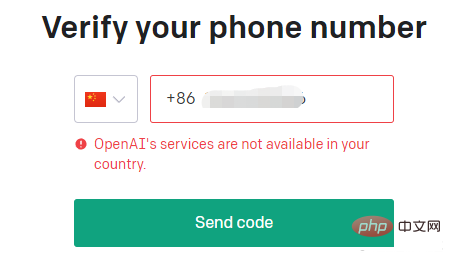
Anda juga boleh memilih untuk log masuk dengan akaun Google, tetapi anda masih perlu mengesahkan nombor telefon mudah alih anda pada akhirnya.
Jadi kita perlu cari dulu nombor telefon bimbit asing yang boleh menerima kod pengesahan SMS Pada masa ini, kita boleh menggunakan SMS-ACTIVATE.
Ini ialah tapak web untuk mendaftar akaun dengan berjuta-juta perkhidmatan di planet ini. Kami menawarkan nombor maya di kebanyakan negara di seluruh dunia supaya anda boleh menerima mesej teks dengan kod pengesahan dalam talian. Antara perkhidmatan kami juga ialah penyewaan nombor maya jangka panjang, sambungan pemajuan, pengesahan telefon dan banyak lagi.
Harga pada SMS-ACTIVATE ialah rubel. Kami perlu menggunakan nombor telefon mudah alih untuk pengesahan SMS. rubel.
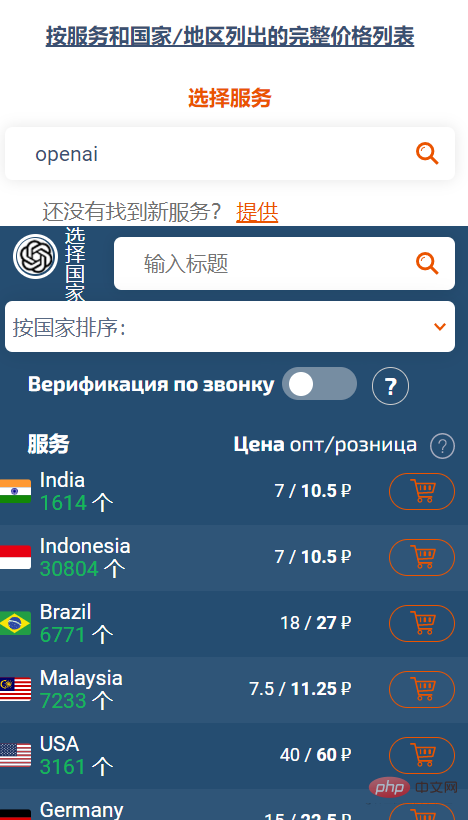
Mengikut kadar pertukaran, ia adalah kira-kira 1 RMB.
SMS-ACTIVATE menyokong pengecasan semula dengan harta tertentu Saya membeli akaun India dan boleh menerima kod pengesahan daripada Open AI.
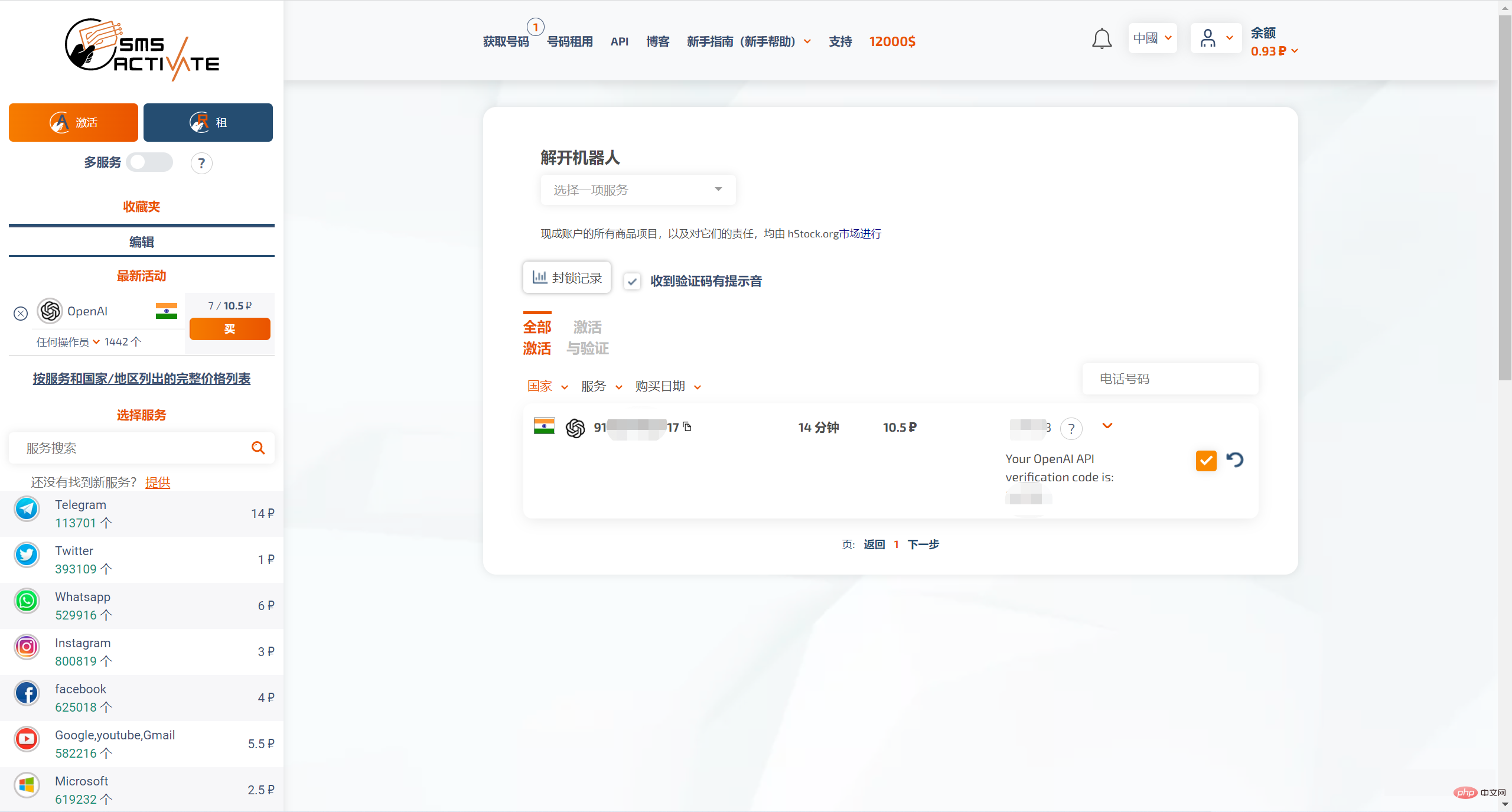
Perhatikan bahawa nombor ini hanya untuk disewa dan mempunyai had masa, jadi kami mesti cepat dan selesaikan proses pendaftaran Selepas 20 minit, nombor ini bukan lagi milik anda .
Selepas mendaftar akaun Open AI, anda boleh pergi ke meja kerja web ChatGPT untuk mengalami perbualan AI.
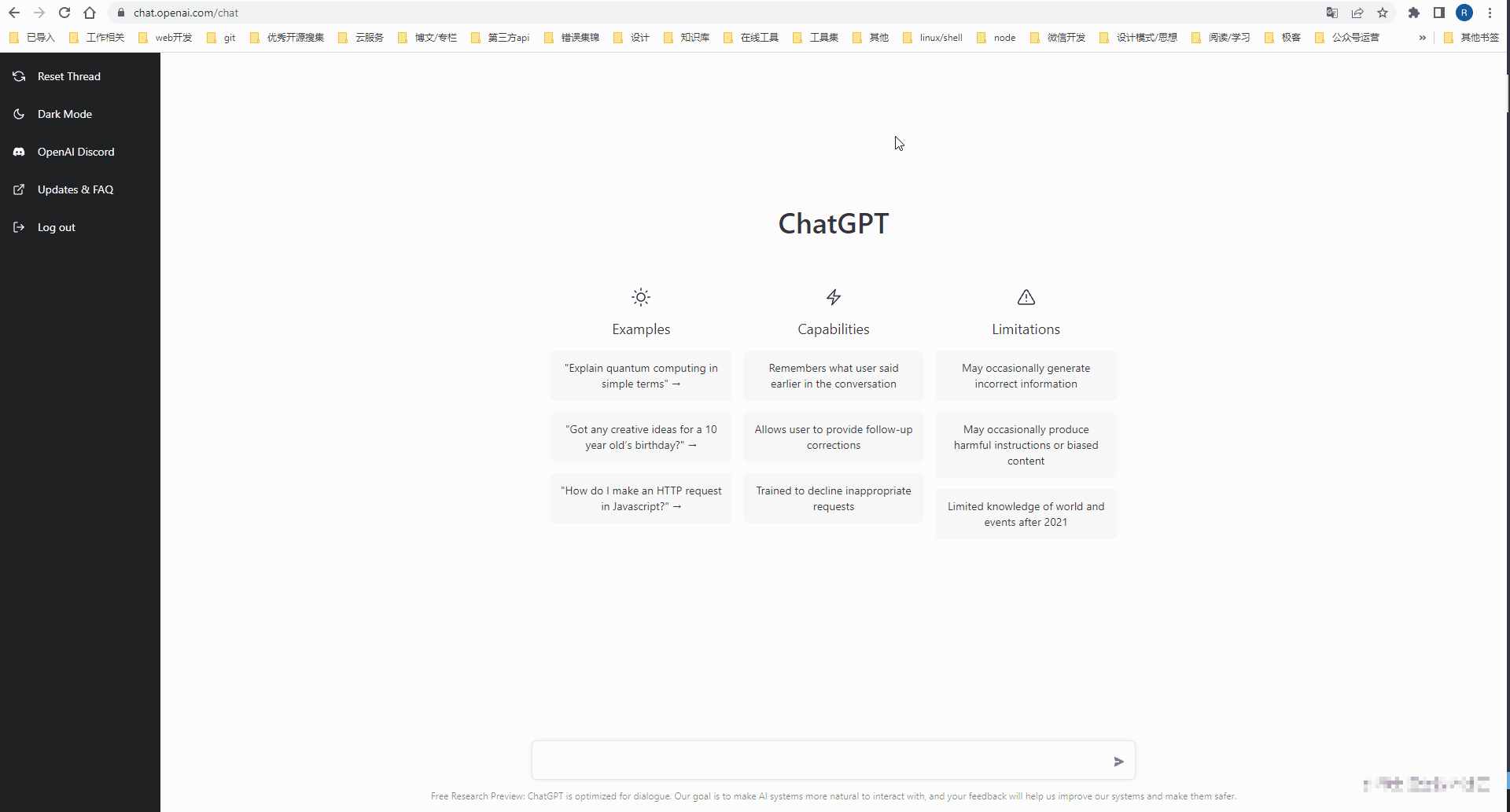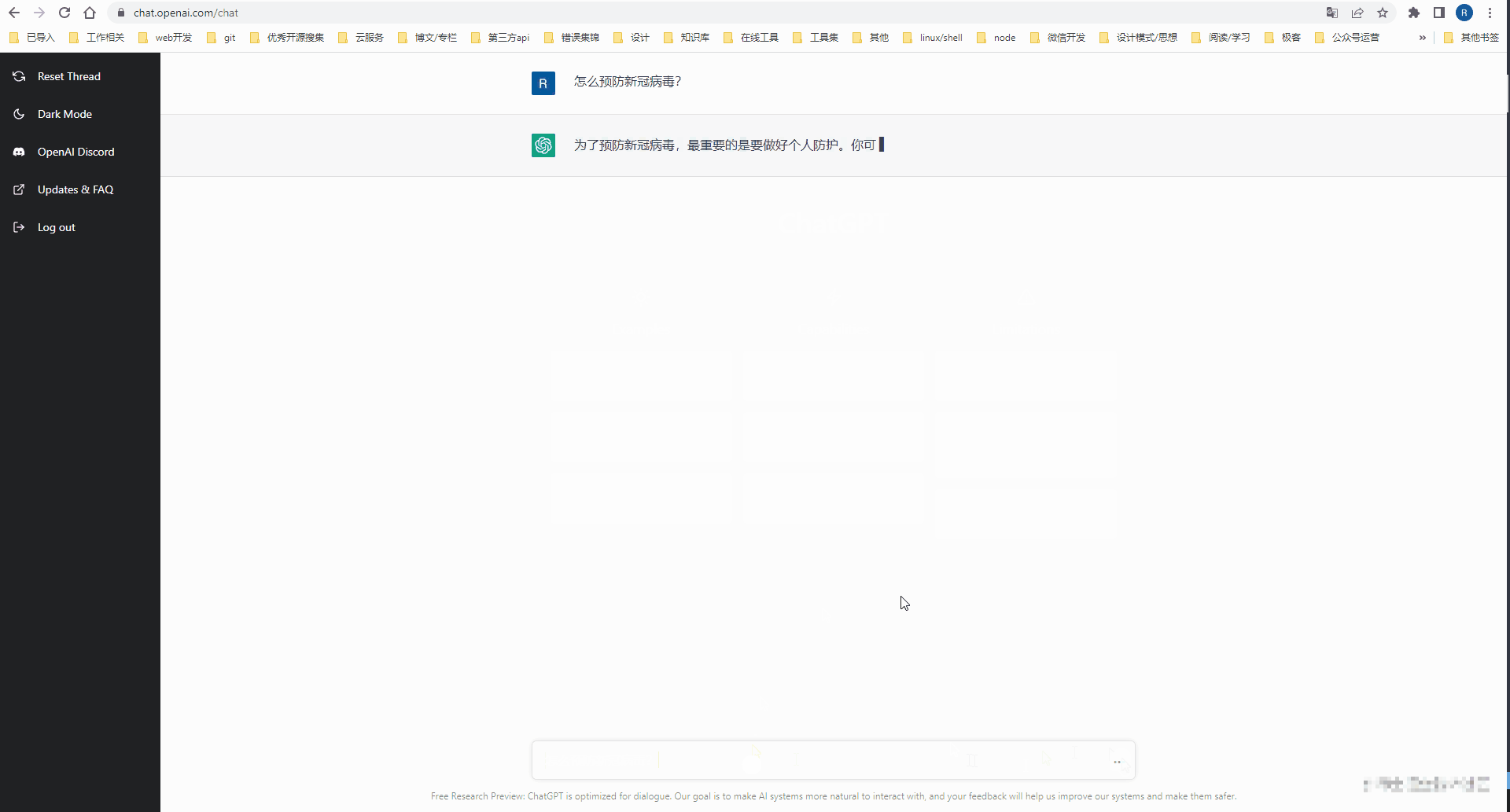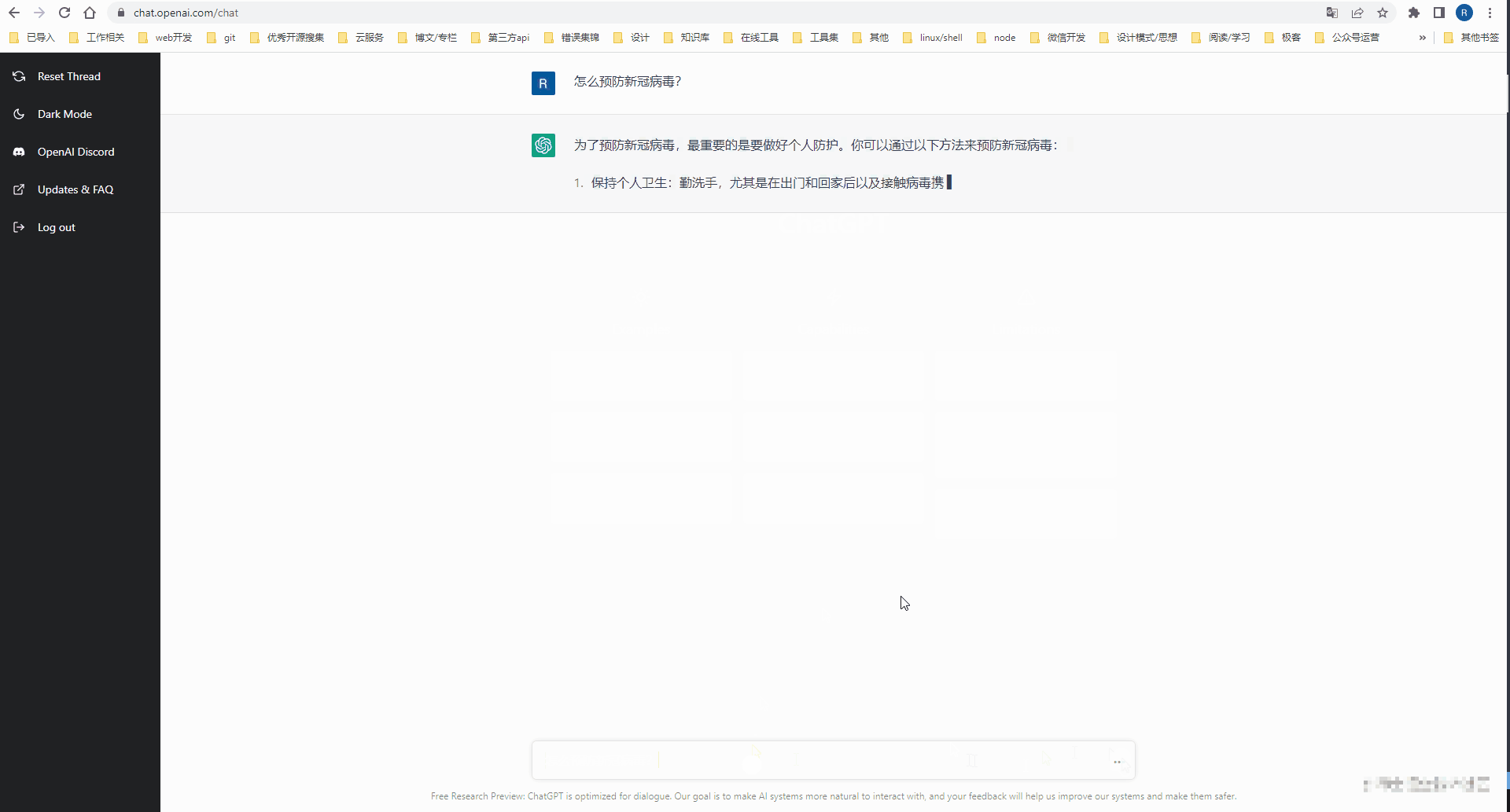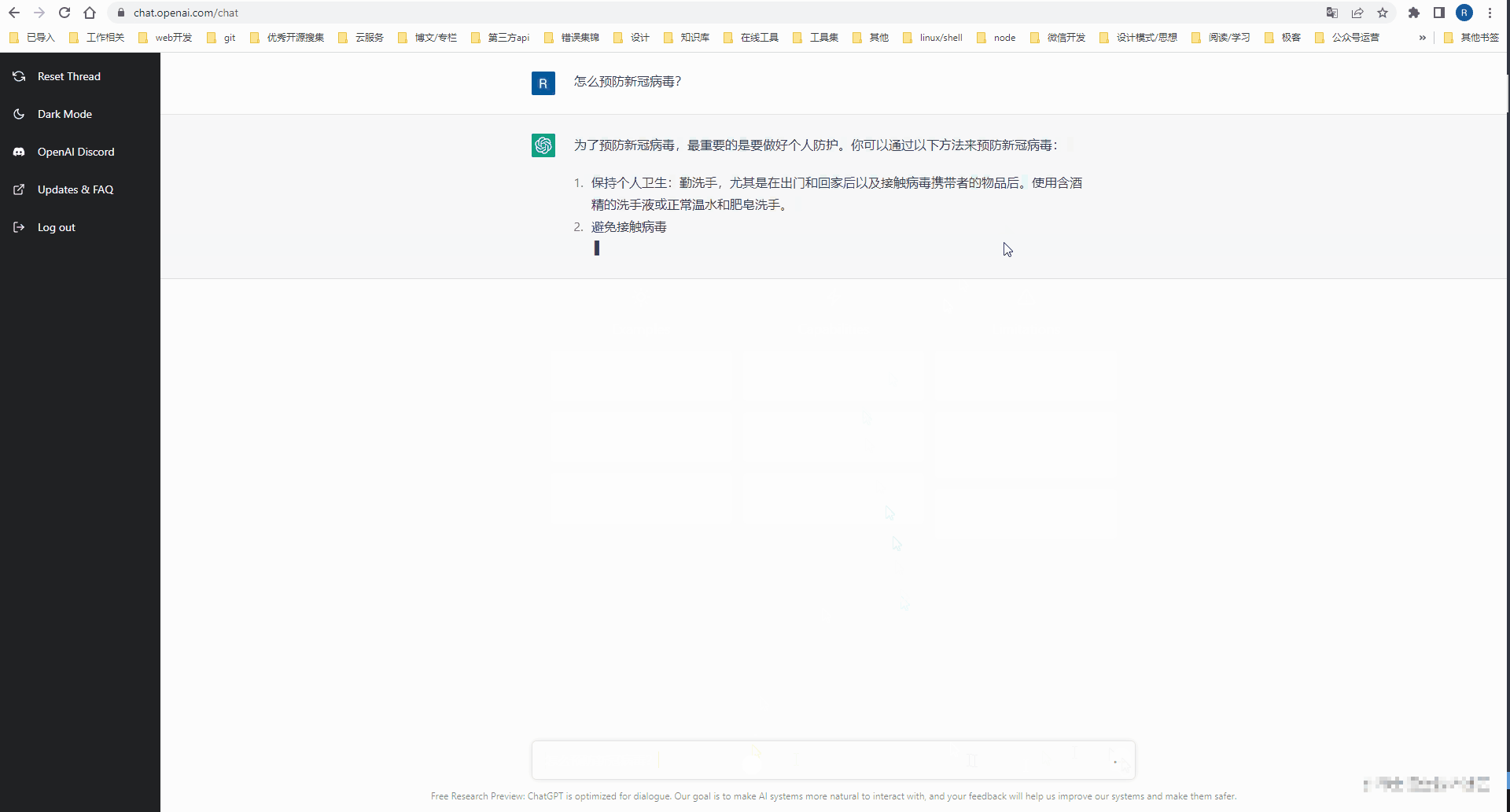
Akses keupayaan AI Terbuka melalui API
Selepas mengalami ChatGPT, bagi kita yang terlibat dalam teknologi, kita mungkin berfikir tentang cara mengintegrasikan ini keupayaan ke dalam produk anda sendiri.
Bermula dengan pantas
ChatGPT ialah model yang dilatih oleh Open AI Open AI juga menyediakan API untuk dihubungi oleh pembangun, dan dokumen serta kesnya juga agak komprehensif.
Langkah yang sangat penting dalam pembelajaran mesin ialah melaraskan parameter, tetapi untuk pembangun bahagian hadapan, kebanyakan orang pasti tidak tahu cara melaraskan parameter, jadi kami akan merujuk kepada kes rasmi yang paling sesuai dengan keperluan kami . Baguslah, kes Sembang ini sangat sesuai dengan keperluan senario kami.
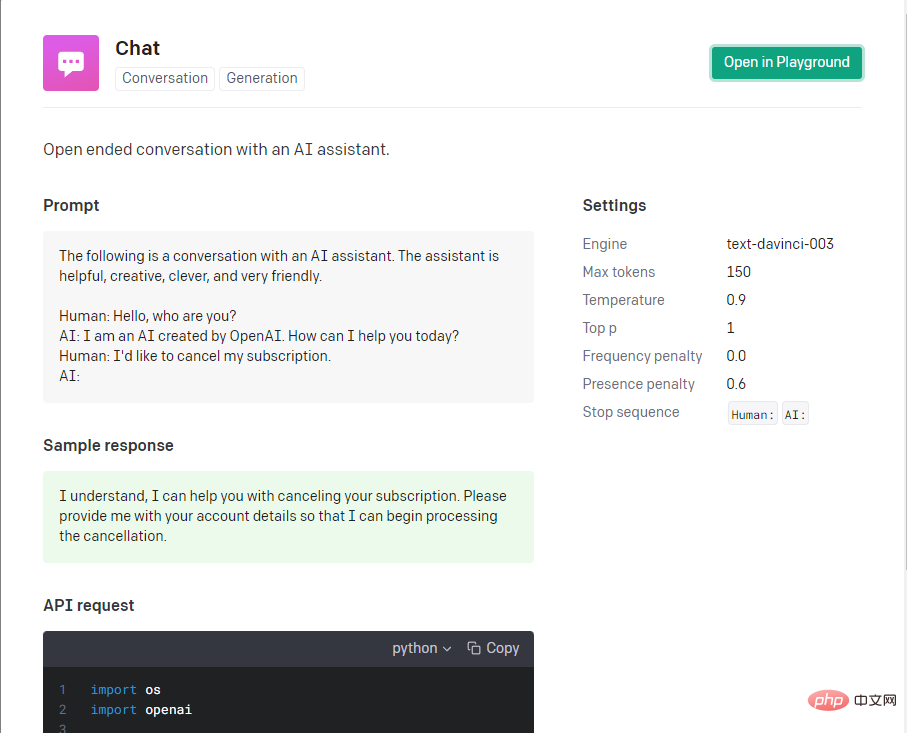
Pegawai rasmi menyediakan pemula nodejs, berdasarkan mana kami boleh memulakan dan mengujinya dengan cepat.
git clone https://github.com/openai/openai-quickstart-node.git
Kod terasnya ialah bahagian ini, dan openai yang digunakan di dalamnya ialah Perpustakaan NodeJS yang dikapsulkan secara rasmi.
const completion = await openai.createCompletion({
model: "text-davinci-003",
prompt: '提问内容',
temperature: 0.9,
max_tokens: 150,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0.6,
});Anda perlu menjana Kunci API dalam akaun Open AI anda sebelum memanggil API.
Pada masa ini, had percuma rasmi ialah 18 pisau, dan anda perlu membayar lebihan itu. Pengebilan dikira berdasarkan Token Bagi maksud Token, anda boleh merujuk kepada konsep Utama.

Mari kita ambil parameter kotak Sembang di atas dan gunakannya secara langsung, kami mempunyai 70-80% AI yang menjawab soalan ini kesannya tidak rumit.
Langkah seterusnya ialah mengkaji cara mengintegrasikan kod utama pemula ini ke dalam produk anda sendiri.
产品分析
我之前有在自己的博客中做过一个简单的 WebSocket 聊天功能,而在 AI 对话这个需求中,前端 UI 部分基本上可以参考着WebSocket 聊天功能改改,工作量不是很大,主要工作量还是在前后端的逻辑和对接上面。
ChatGPT 的这个产品模式,它不是一个常规的 WebSocket 全双工对话,而是像我们平常调接口一样,发生用户输入后,客户端发送请求到服务端,等待服务端响应,最后反馈给用户,它仅仅是从界面上看起来像是聊天,实际上不是一个标准的聊天过程。所以前后端交互主要还是靠 HTTP 接口对接。
核心要素 Prompt
在openai.createCompletion调用时有一个很重要的参数prompt,它是对话的上下文信息,只有这个信息足够完整,AI 才能正确地做出反馈。
举个例子,假设在对话过程中有2个回合。
// 回合1 你:爱因斯坦是谁? AI: 爱因斯坦(Albert Einstein)是20世纪最重要的物理学家,他被誉为“时空之父”。他发现了相对论,并获得诺贝尔物理学奖。
第一个回合中,传参prompt是爱因斯坦是谁?,机器人很好理解,马上能给出符合实际的回复。
// 回合2 你:他做了什么贡献? AI: 他为社会做出了许多贡献,例如改善公共卫生、建立教育基础设施、提高农业生产能力、促进经济发展等。
第二个回合传参prompt是他做了什么贡献?,看到机器人的答复,你可能会觉得有点离谱,因为这根本就是牛头不对马嘴。但是仔细想想,这是因为机器人不知道上下文信息,所以机器人不能理解他代表的含义,只能通过他做了什么贡献?整句话去推测,所以从结果上看就是符合语言的逻辑,但是不符合我们给出的语境。
如果我们把第二个回合的传参prompt改成你: 爱因斯坦是谁?nAI: 爱因斯坦(Albert Einstein)是20世纪最重要的物理学家,他被誉为“时空之父”。他发现了相对论,并获得诺贝尔物理学奖。n你: 他做了什么贡献?nAI:,机器人就能够理解上下文信息,给出接下来的符合逻辑的答复。
// 改进后的回合2 你:他做了什么贡献? AI: 爱因斯坦对科学有着重大的贡献,他发明了相对论,改变了人们对世界、物理定律和宇宙的认识,并为量子力学奠定了基础。他还发现了...
所以,我们的初步结论是:prompt参数应该包含此次对话主题的较完整内容,才能保证 AI 给出的下一次回答符合我们的基本认知。
前后端交互
对于前端来说,我们通常关注的是,我给后端发了什么数据,后端反馈给我什么数据。所以,前端关注点之一就是用户的输入,用上面的例子说,爱因斯坦是谁?和他做了什么贡献?这两个内容,应该分别作为前端两次请求的参数。而且,对于前端来说,我们也不需要考虑后端传给 Open AI 的prompt是不是完整,只要把用户输入的内容合理地传给后端就够了。
对于后端来说,我们要关注 session 问题,每个用户应该有属于自己和 AI 的私密对话空间,不能和其他的用户对话串了数据,这个可以基于 session 实现。前端每次传过来的信息只有简单的用户输入,而后端要关注与 Open AI 的对接过程,结合用户的输入以及会话中保留的一些信息,合并成一个完整的prompt传给 Open AI,这样才能得到正常的对话过程。
所以基本的流程应该是这个样子:
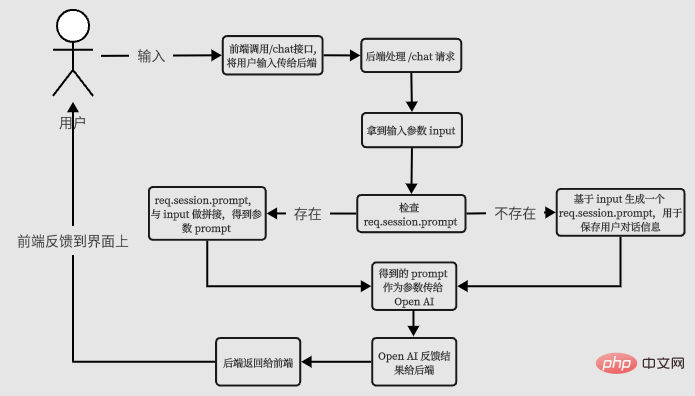
我们根据这个流程输出第一版代码。
后端V1版本代码
router.get('/chat-v1', async function(req, res, next) {
// 取得用户输入
const wd = req.query.wd;
// 构造 prompt 参数
if (!req.session.chatgptSessionPrompt) {
req.session.chatgptSessionPrompt = ''
}
const prompt = req.session.chatgptSessionPrompt + `n提问:` + wd + `nAI:`
try {
const completion = await openai.createCompletion({
model: "text-davinci-003",
prompt,
temperature: 0.9,
max_tokens: 150,
top_p: 1,
frequency_penalty: 0,
presence_penalty: 0.6,
stop: ["n提问:", "nAI:"],
});
// 调用 Open AI 成功后,更新 session
req.session.chatgptSessionPrompt = prompt + completion.data
// 返回结果
res.status(200).json({
code: '0',
result: completion.data.choices[0].text
});
} catch (error) {
console.error(error)
res.status(500).json({
message: "Open AI 调用异常"
});
}
});前端V1版本关键代码
const sendChatContentV1 = async () => {
// 先显示自己说的话
msgList.value.push({
time: format(new Date(), "HH:mm:ss"),
user: "我说",
content: chatForm.chatContent,
type: "mine",
customClass: "mine",
});
loading.value = true;
try {
// 调 chat-v1 接口,等结果
const { result } = await chatgptService.chatV1({ wd: chatForm.chatContent });
// 显示 AI 的答复
msgList.value.push({
time: format(new Date(), "HH:mm:ss"),
user: "Chat AI",
content: result,
type: "others",
customClass: "others",
});
} finally {
loading.value = false;
}
};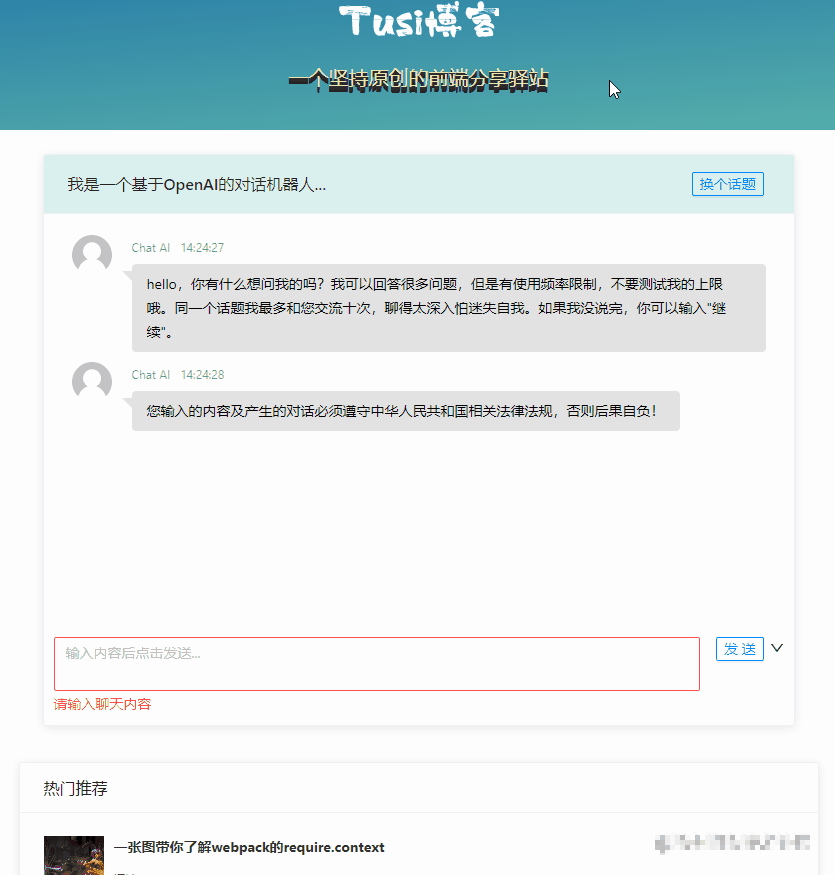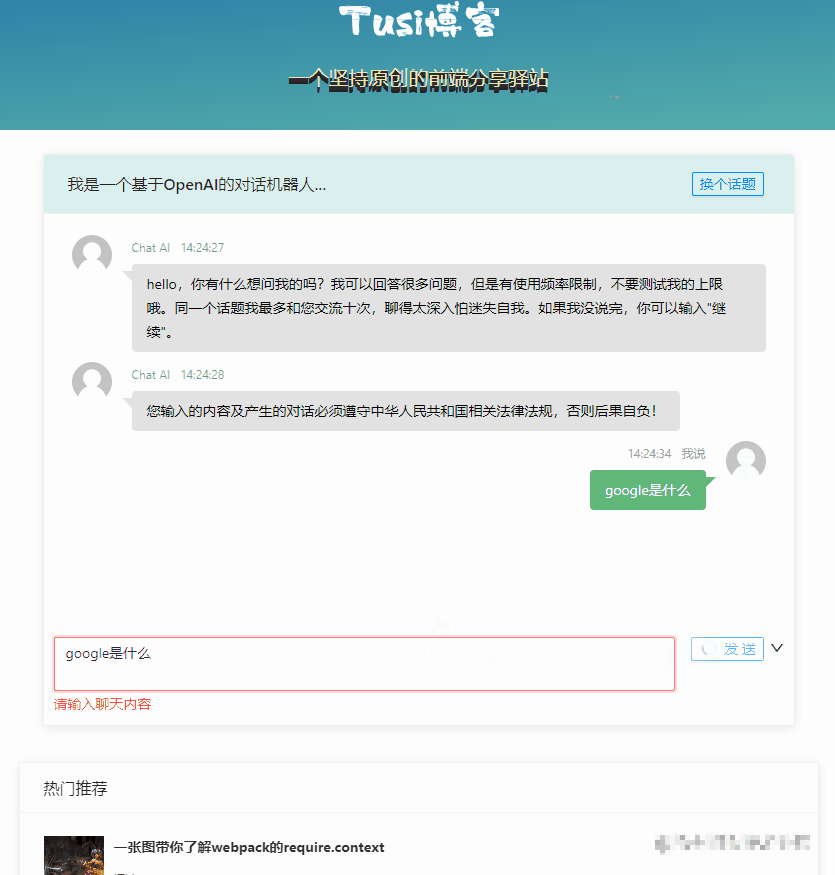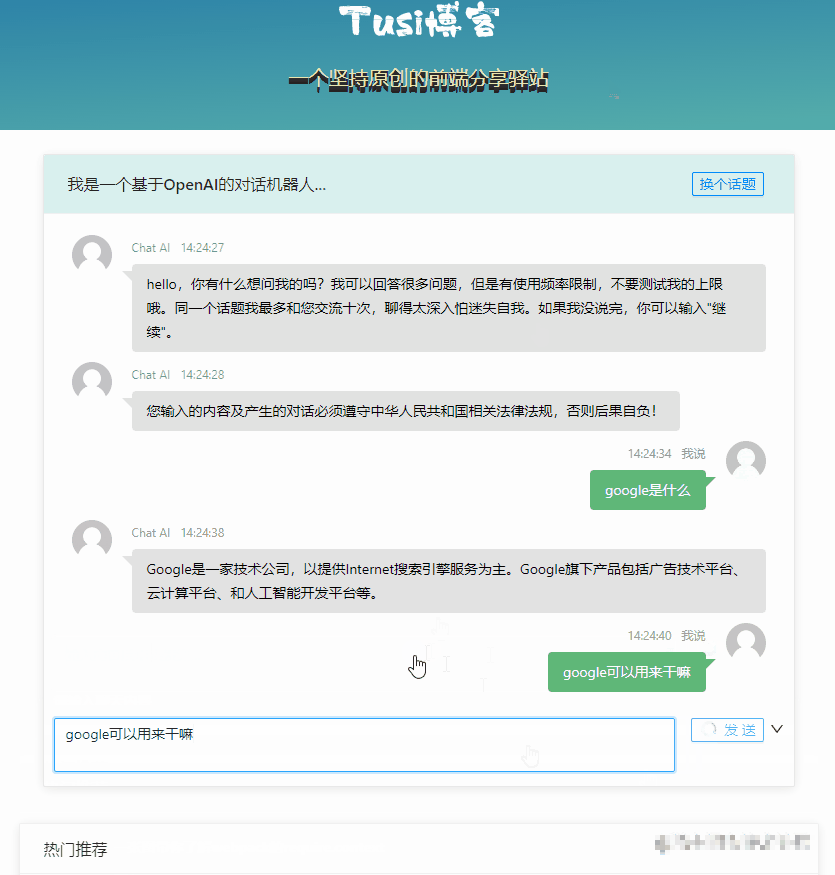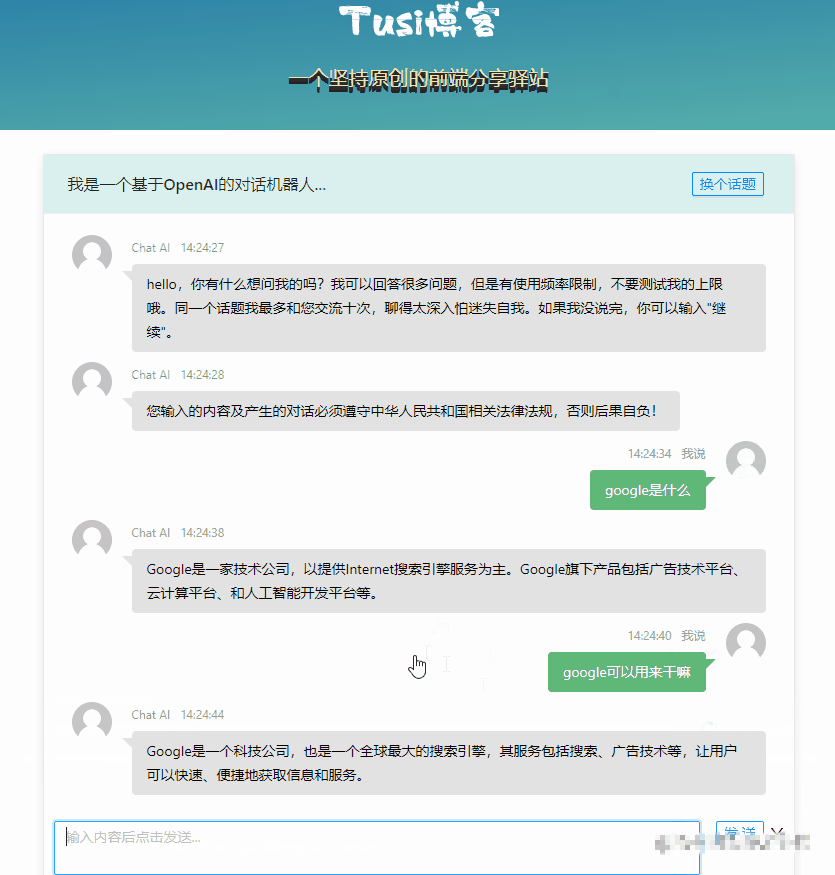
基本的对话能力已经有了,但是最明显的缺点就是一个回合等得太久了,我们希望他速度更快一点,至少在交互上看起来快一点。
流式输出(服务器推 + EventSource)
还好 Open AI 也支持 stream 流式输出,在前端可以配合 EventSource 一起用。
You can also set the stream parameter to true for the API to stream back text (as data-only server-sent events).
基本的数据流是这个样子的:

后端改造如下:
router.get('/chat-v2', async function(req, res, next) {
// ...省略部分代码
try {
const completion = await openai.createCompletion({
// ...省略部分代码
// 增加了 stream 参数
stream: true
}, { responseType: 'stream' });
// 设置响应的 content-type 为 text/event-stream
res.setHeader("content-type", "text/event-stream")
// completion.data 是一个 ReadableStream,res 是一个 WritableStream,可以通过 pipe 打通管道,流式输出给前端。
completion.data.pipe(res)
}
// ...省略部分代码
});前端放弃使用 axios 发起 HTTP 请求,而是改用 EventSource。
const sendChatContent = async () => {
// ...省略部分代码
// 先显示自己说的话
msgList.value.push({
time: format(new Date(), "HH:mm:ss"),
user: "我说",
content: chatForm.chatContent,
type: "mine",
customClass: "mine",
});
// 通过 EventSource 取数据
const es = new EventSource(`/api/chatgpt/chat?wd=${chatForm.chatContent}`);
// 记录 AI 答复的内容
let content = "";
// ...省略部分代码
es.onmessage = (e) => {
if (e.data === "[DONE]") {
// [DONE] 标志数据结束,调用 feedback 反馈给服务器
chatgptService.feedback(content);
es.close();
loading.value = false;
updateScrollTop();
return;
}
// 从数据中取出文本
const text = JSON.parse(e.data).choices[0].text;
if (text) {
if (!content) {
// 第一条数据来了,先显示
msgList.value.push({
time: format(new Date(), "HH:mm:ss"),
user: "Chat AI",
content: text,
type: "others",
customClass: "others",
});
// 再拼接
content += text;
} else {
// 先拼接
content += text;
// 再更新内容,实现打字机效果
msgList.value[msgList.value.length - 1].content = content;
}
}
};
};从代码中可以发现前端在 EventSource message 接收结束时,还调用了一个 feedback 接口做反馈。这是因为在使用 Pipe 输出时,后端没有记录 AI 答复的文本,考虑到前端已经处理了文本,这里就由前端做一次反馈,把本次 AI 答复的内容完整回传给后端,后端再更新 session 中存储的对话信息,保证对话上下文的完整性。
feedback 接口的实现比较简单:
router.post('/feedback', function(req, res, next) {
if (req.body.result) {
req.session.chatgptSessionPrompt += req.body.result
res.status(200).json({
code: '0',
msg: "更新成功"
});
} else {
res.status(400).json({
msg: "参数错误"
});
}
});我这里只是给出一种简单的做法,实际产品中可能要考虑的会更多,或者应该在后端自行处理 session 内容,而不是依靠前端的反馈。
最终的效果大概是这个样子:

限制访问频次
由于 Open AI 也是有免费额度的,所以在调用频率和次数上也应该做个限制,防止被恶意调用,这个也可以通过 session 来处理。我这里也提供一种比较粗糙的处理方式,具体请往下看。实际产品中可能会写 Redis,写库,加定时任务之类的,这方面我也不够专业,就不多说了。
针对访问频率,我暂定的是 3 秒内最多调用一次,我们可以在调用 Open AI 成功之后,在 session 中记录时间戳。
req.session.chatgptRequestTime = Date.now()
当一个新的请求过来时,可以用当前时间减去上次记录的chatgptRequestTime,判断一下是不是在 3 秒内,如果是,就返回 HTTP 状态码 429;如果不在 3 秒内,就可以继续后面的逻辑。
if (req.session.chatgptRequestTime && Date.now() - req.session.chatgptRequestTime <= 3000) {
// 不允许在3s里重复调用
return res.status(429).json({
msg: "请降低请求频次"
});
}关于请求次数也是同样的道理,我这里也写得很简单,实际上还应该有跨天清理等逻辑要做。我这里偷懒了,暂时没做这些。
if (req.session.chatgptTimes && req.session.chatgptTimes >= 50) {
// 实际上还需要跨天清理,这里先偷懒了。
return res.status(403).json({
msg: "到达调用上限,欢迎明天再来哦"
});
}同一个话题也不能聊太多,否则传给 Open AI 的 prompt 参数会很大,这就可能会耗费很多 Token,也有可能超过 Open AI 参数的限制。
if (req.session.chatgptTopicCount && req.session.chatgptTopicCount >= 10) {
// 一个话题聊的次数超过限制时,需要强行重置 chatgptSessionPrompt,换个话题。
req.session.chatgptSessionPrompt = ''
req.session.chatgptTopicCount = 0
return res.status(403).json({
msg: "这个话题聊得有点深入了,不如换一个"
});
}切换话题
客户端应该也有切换话题的能力,否则 session 中记录的信息可能会包含多个话题的内容,可能导致与用户的预期不符。那我们做个接口就好了。
router.post('/changeTopic', function(req, res, next) {
req.session.chatgptSessionPrompt = ''
req.session.chatgptTopicCount = 0
res.status(200).json({
code: '0',
msg: "可以尝试新的话题"
});
});结语
总的来说,Open AI 开放出来的智能对话能力可以满足基本需求,但是还有很大改进空间。我在文中给出的代码仅供参考,不保证功能上的完美。
附上源码地址,可以点个 star 吗,球球了[认真脸]。
参考
[1]体验链接: https://blog.wbjiang.cn/chatgpt
[2]ChatGPT: https://openai.com/
[3]注册: https://beta.openai.com/login/
[4]SMS-ACTIVATE: https://sms-activate.org/cn
[5]Web工作台: https://chat.openai.com/chat
[6]文档: https://beta.openai.com/
[7]案例: https://beta.openai.com/examples
[8]openai: https://www.npmjs.com/package/openai
[9]生成一个 API Key: https://beta.openai.com/account/api-keys
[10]Key concepts: https://beta.openai.com/docs/introduction/key-concepts
[11]WebSocket 聊天功能: https://blog.wbjiang.cn/chat
[12]data-only server-sent events: https://developer.mozilla.org/en-US/docs/Web/API/Server-sent_events/Using_server-sent_events#Event_stream_format
[13]源码地址: https://github.com/cumt-robin/vue3-ts-blog-frontend
Atas ialah kandungan terperinci Belanjakan 1 yuan untuk menjadikan tapak web anda menyokong ChatGPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1375
1375
 52
52

 ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
DALL-E 3 telah diperkenalkan secara rasmi pada September 2023 sebagai model yang jauh lebih baik daripada pendahulunya. Ia dianggap sebagai salah satu penjana imej AI terbaik setakat ini, mampu mencipta imej dengan perincian yang rumit. Walau bagaimanapun, semasa pelancaran, ia adalah tidak termasuk
 Adakah terdapat laman web untuk mempelajari bahasa C?
Jan 30, 2024 pm 02:38 PM
Adakah terdapat laman web untuk mempelajari bahasa C?
Jan 30, 2024 pm 02:38 PM
Laman web untuk mempelajari bahasa C: 1. Laman Web Bahasa C; 3. Forum Bahasa C 6. Tianji.com; 51 Rangkaian belajar kendiri; 9. Likou; Pengenalan terperinci: 1. Laman web bahasa C bahasa Cina, yang merupakan laman web khusus untuk menyediakan bahan pembelajaran bahasa C untuk pemula Ia kaya dengan kandungan, termasuk tatabahasa asas, petunjuk, tatasusunan, fungsi, struktur dan modul lain; Ini adalah laman web pembelajaran pengaturcaraan yang komprehensif dan banyak lagi.
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Langkah pemasangan: 1. Muat turun perisian ChatGTP dari laman web rasmi ChatGTP atau kedai mudah alih 2. Selepas membukanya, dalam antara muka tetapan, pilih bahasa sebagai bahasa Cina 3. Dalam antara muka permainan, pilih permainan mesin manusia dan tetapkan Spektrum bahasa Cina; 4 Selepas memulakan, masukkan arahan dalam tetingkap sembang untuk berinteraksi dengan perisian.
 Bagaimana untuk membangunkan chatbot pintar menggunakan ChatGPT dan Java
Oct 28, 2023 am 08:54 AM
Bagaimana untuk membangunkan chatbot pintar menggunakan ChatGPT dan Java
Oct 28, 2023 am 08:54 AM
Dalam artikel ini, kami akan memperkenalkan cara membangunkan chatbot pintar menggunakan ChatGPT dan Java, dan menyediakan beberapa contoh kod khusus. ChatGPT ialah versi terkini Generative Pre-training Transformer yang dibangunkan oleh OpenAI, teknologi kecerdasan buatan berasaskan rangkaian saraf yang boleh memahami bahasa semula jadi dan menjana teks seperti manusia. Menggunakan ChatGPT kami boleh membuat sembang adaptif dengan mudah
 Bolehkah chatgpt digunakan di China?
Mar 05, 2024 pm 03:05 PM
Bolehkah chatgpt digunakan di China?
Mar 05, 2024 pm 03:05 PM
chatgpt boleh digunakan di China, tetapi tidak boleh didaftarkan, begitu juga di Hong Kong dan Macao Jika pengguna ingin mendaftar, mereka boleh menggunakan nombor telefon mudah alih asing untuk mendaftar. Perhatikan bahawa semasa proses pendaftaran, persekitaran rangkaian mesti ditukar IP asing.
 Bagaimana untuk membina robot perkhidmatan pelanggan pintar menggunakan PHP ChatGPT
Oct 28, 2023 am 09:34 AM
Bagaimana untuk membina robot perkhidmatan pelanggan pintar menggunakan PHP ChatGPT
Oct 28, 2023 am 09:34 AM
Cara menggunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar Pengenalan: Dengan perkembangan teknologi kecerdasan buatan, robot semakin digunakan dalam bidang perkhidmatan pelanggan. Menggunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar boleh membantu syarikat menyediakan perkhidmatan pelanggan yang lebih cekap dan diperibadikan. Artikel ini akan memperkenalkan cara menggunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar dan menyediakan contoh kod khusus. 1. Pasang ChatGPTPHP dan gunakan ChatGPTPHP untuk membina robot perkhidmatan pelanggan yang pintar.
 SearchGPT: Open AI mengambil alih Google dengan enjin carian AInya sendiri
Jul 30, 2024 am 09:58 AM
SearchGPT: Open AI mengambil alih Google dengan enjin carian AInya sendiri
Jul 30, 2024 am 09:58 AM
Open AI akhirnya membuat cariannya. Syarikat San Francisco baru-baru ini telah mengumumkan alat AI baharu dengan keupayaan carian. Pertama kali dilaporkan oleh The Information pada Februari tahun ini, alat baharu ini dipanggil SearchGPT dan menampilkan c
 ChatGPT kini tersedia untuk macOS dengan keluaran apl khusus
Jun 27, 2024 am 10:05 AM
ChatGPT kini tersedia untuk macOS dengan keluaran apl khusus
Jun 27, 2024 am 10:05 AM
Aplikasi ChatGPT Mac Buka AI kini tersedia untuk semua orang, telah dihadkan kepada mereka yang mempunyai langganan ChatGPT Plus sahaja untuk beberapa bulan lepas. Apl ini dipasang sama seperti mana-mana apl Mac asli yang lain, selagi anda mempunyai Apple S yang terkini
