

ChatGPT ialah pemain teratas baharu dalam kalangan AI pada penghujung tahun ini Orang ramai kagum dengan keupayaan bahasa soal jawab dan pengetahuan pengaturcaraannya. Tetapi model yang lebih berkuasa, lebih tinggi keperluan teknikal di belakangnya.

ChatGPT adalah berdasarkan siri model GPT 3.5 dan memperkenalkan "data berlabel buatan + pembelajaran pengukuhan" (RLHF) untuk memperhalusi secara berterusan bahasa pra-latihan Model ini direka bentuk untuk membolehkan model bahasa besar (LLM) belajar memahami arahan manusia dan belajar memberikan jawapan yang optimum berdasarkan gesaan yang diberikan.
Idea teknikal ini ialah trend pembangunan model bahasa semasa. Walaupun model jenis ini mempunyai prospek pembangunan yang hebat, kos latihan model dan penalaan halus adalah sangat tinggi.
Menurut maklumat yang kini didedahkan oleh OpenAI, proses latihan ChatGPT dibahagikan kepada tiga peringkat:
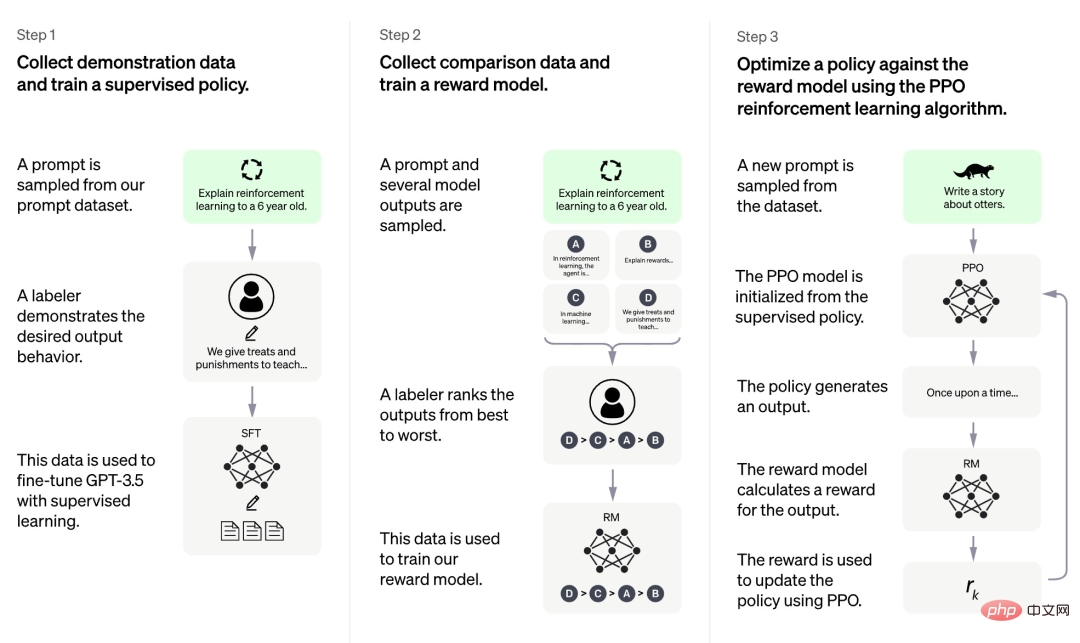
Pertama sekali, peringkat pertama ialah model dasar yang diselia serupa dengan GPT 3.5 Model asas ini sukar untuk memahami niat yang terkandung dalam pelbagai jenis arahan manusia, dan ia juga sukar untuk dinilai kualiti kandungan yang dihasilkan. Para penyelidik secara rawak memilih beberapa sampel daripada set data segera, dan kemudian meminta anotasi profesional untuk memberikan jawapan berkualiti tinggi berdasarkan gesaan yang ditentukan. Gesaan dan jawapan berkualiti tinggi sepadan yang diperoleh melalui proses manual ini digunakan untuk memperhalusi model dasar seliaan awal untuk memberikan pemahaman segera asas dan pada mulanya meningkatkan kualiti jawapan yang dijana.
Dalam fasa kedua, pasukan penyelidik mengekstrak berbilang output yang dihasilkan oleh model mengikut gesaan yang diberikan, kemudian meminta penyelidik manusia mengisih output ini, dan kemudian menggunakan data yang diisih untuk melatih model ganjaran RM). ChatGPT menggunakan kerugian berpasangan untuk melatih RM.
Dalam fasa ketiga, pasukan penyelidik menggunakan pembelajaran pengukuhan untuk meningkatkan keupayaan model pra-latihan, dan menggunakan model RM yang dipelajari dalam fasa sebelumnya untuk mengemas kini parameter model pra-latihan.
Kita dapati bahawa antara tiga peringkat latihan ChatGPT, hanya peringkat ketiga tidak memerlukan anotasi manual data, manakala kedua-dua peringkat pertama dan kedua memerlukan sejumlah besar anotasi manual . Oleh itu, walaupun model seperti ChatGPT berprestasi sangat baik, untuk meningkatkan keupayaan mereka untuk mengikut arahan, kos buruh adalah sangat tinggi. Apabila skala model menjadi lebih besar dan skop keupayaan menjadi lebih luas dan lebih luas, masalah ini akan menjadi lebih serius dan akhirnya menjadi hambatan yang menghalang pembangunan model.
Sesetengah kajian telah cuba mencadangkan cara untuk menyelesaikan kesesakan ini Contohnya, Universiti Washington dan institusi lain baru-baru ini bersama-sama menerbitkan kertas kerja "INSTRUCT DIRI: Menjajarkan Model Bahasa dengan Dihasilkan Sendiri. Arahan", mencadangkan Rangka kerja baharu SELF-INSTRUCT menambah baik keupayaan mengikut arahan model bahasa pra-latihan dengan membimbing proses penjanaan model itu sendiri.

Alamat kertas: https://arxiv.org/pdf/2212.10560v1.pdf
INSTRUCT DIRI ialah proses separa automatik yang menggunakan isyarat arahan daripada model itu sendiri untuk melakukan pelarasan arahan pada LM yang telah dilatih. Seperti yang ditunjukkan dalam rajah di bawah, keseluruhan proses adalah algoritma bootstrap berulang.
INSTRUKSI KENDIRI bermula dengan set benih terhad dan membimbing keseluruhan proses binaan dengan arahan bertulis tangan. Dalam fasa pertama, model digesa ke dalam arahan penjanaan tugas baharu, satu langkah yang memanfaatkan set arahan sedia ada untuk mencipta arahan yang lebih luas untuk menentukan tugas baharu. INSTRUCT DIRI juga mencipta contoh input dan output untuk set arahan yang baru dijana untuk digunakan dalam menyelia pelarasan arahan. Akhir sekali, SELF-INSTRUCT juga memangkas arahan yang berkualiti rendah dan pendua. Keseluruhan proses dilakukan secara berulang, dan model akhir boleh menghasilkan arahan untuk sejumlah besar tugas.
Untuk mengesahkan keberkesanan kaedah baharu, kajian itu menggunakan rangka kerja INSTRUCT DIRI pada GPT-3, yang akhirnya menghasilkan kira-kira 52k arahan, 82k input contoh dan output sasaran. Kami mendapati bahawa GPT-3 mencapai peningkatan mutlak sebanyak 33.1% berbanding model asal pada tugas baharu dalam dataset SUPER-NATURALINSTRUCTIONS, yang setanding dengan prestasi InstructGPT_001 yang dilatih menggunakan data pengguna peribadi dan anotasi manusia.
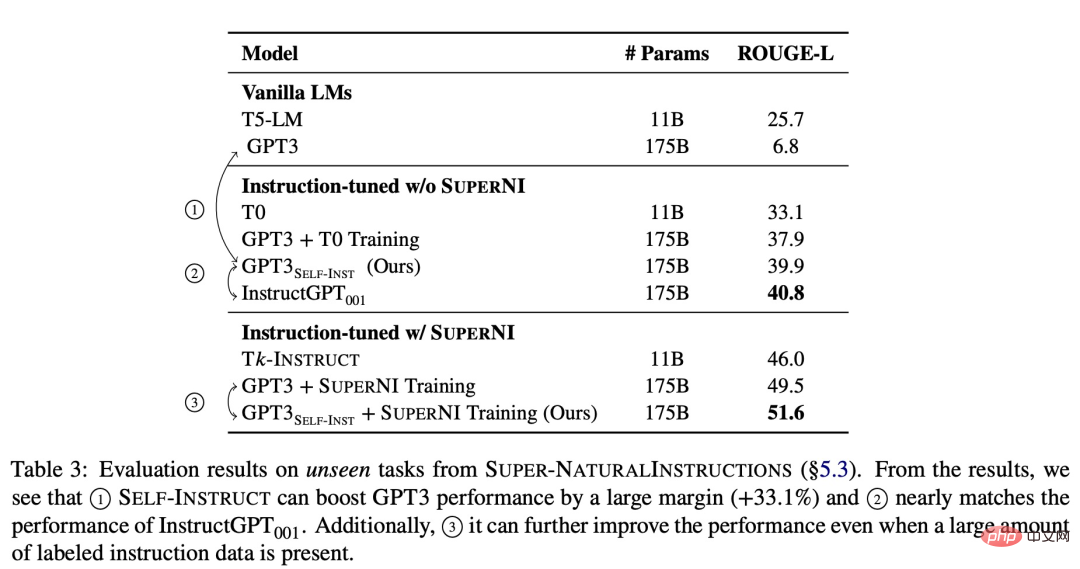
Untuk penilaian lanjut, kajian itu mengumpulkan satu set arahan bertulis pakar untuk tugasan baharu dan ditunjukkan melalui penilaian manusia , prestasi GPT-3 menggunakan SELF-INSTRUCT akan menjadi jauh lebih baik daripada model sedia ada yang menggunakan set data arahan awam, dan hanya 5% di belakang InstructGPT_001.
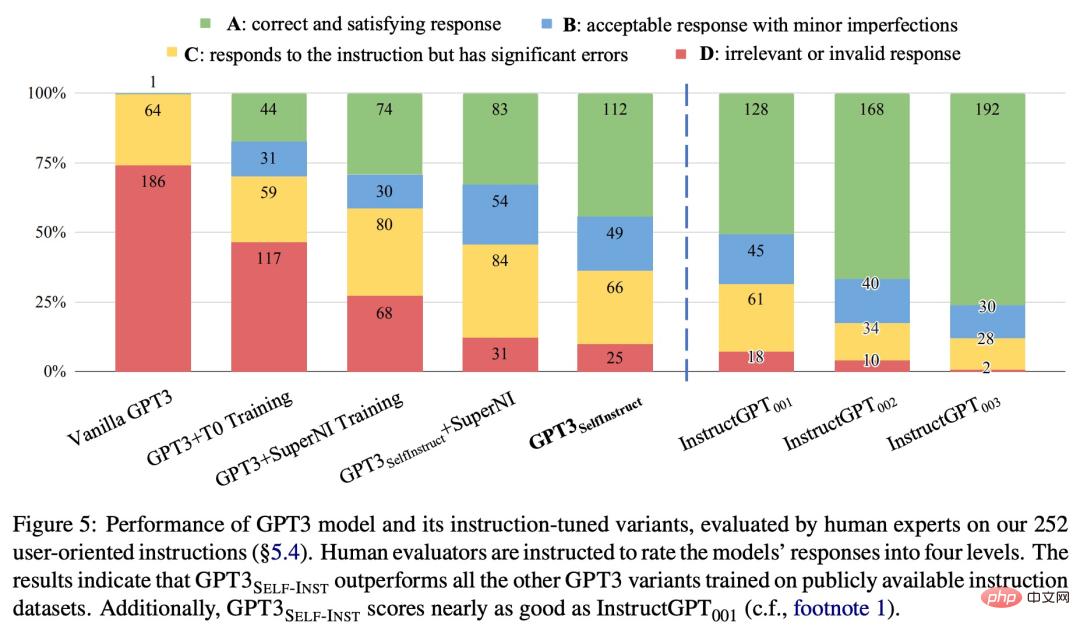
ARAHAN KENDIRI menyediakan kaedah yang hampir tidak memerlukan anotasi manual dan melaksanakan model bahasa yang telah terlatih dan Penjajaran arahan. Beberapa kerja telah dicuba dalam arah yang sama, dan semuanya telah mencapai hasil yang baik Ia dapat dilihat bahawa kaedah jenis ini sangat berkesan dalam menyelesaikan masalah kos pelabelan manual yang tinggi untuk model bahasa yang besar. Ini akan menjadikan LLM seperti ChatGPT lebih kukuh dan pergi lebih jauh.
Atas ialah kandungan terperinci Tiada anotasi manual diperlukan, rangka kerja arahan yang dijana sendiri memecahkan kesesakan kos LLM seperti ChatGPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Pendaftaran ChatGPT
Pendaftaran ChatGPT
 Ensiklopedia ChatGPT percuma domestik
Ensiklopedia ChatGPT percuma domestik
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Bagaimana untuk memasang chatgpt pada telefon bimbit
 Bolehkah chatgpt digunakan di China?
Bolehkah chatgpt digunakan di China?
 Apakah definisi tatasusunan?
Apakah definisi tatasusunan?
 Cara menggunakan fungsi math.round
Cara menggunakan fungsi math.round
 Apa yang perlu dilakukan jika penggunaan CPU terlalu tinggi
Apa yang perlu dilakukan jika penggunaan CPU terlalu tinggi
 Bagaimana untuk menyelesaikan ranap ribut web
Bagaimana untuk menyelesaikan ranap ribut web








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



