
 Peranti teknologi
AI
Sepuluh kaedah pengukuran jarak yang biasa digunakan dalam pembelajaran mesin
Peranti teknologi
AI
Sepuluh kaedah pengukuran jarak yang biasa digunakan dalam pembelajaran mesin
Sepuluh kaedah pengukuran jarak yang biasa digunakan dalam pembelajaran mesin

Metrik jarak ialah asas algoritma pembelajaran diselia dan tidak diselia, termasuk jiran terhampir k, mesin vektor sokongan dan pengelompokan k-means, dsb.
Pilihan metrik jarak mempengaruhi hasil pembelajaran mesin kami, jadi adalah penting untuk mempertimbangkan metrik yang paling sesuai untuk masalah tersebut. Oleh itu, kita harus berhati-hati apabila memutuskan kaedah pengukuran yang akan digunakan. Tetapi sebelum kita membuat keputusan, kita perlu memahami cara pengukuran jarak berfungsi dan ukuran yang boleh kita pilih.
Artikel ini akan memperkenalkan secara ringkas kaedah pengukuran jarak yang biasa digunakan, cara ia berfungsi, cara mengiranya dalam Python dan masa untuk menggunakannya. Ini memperdalam pengetahuan dan pemahaman serta menambah baik algoritma dan hasil pembelajaran mesin.
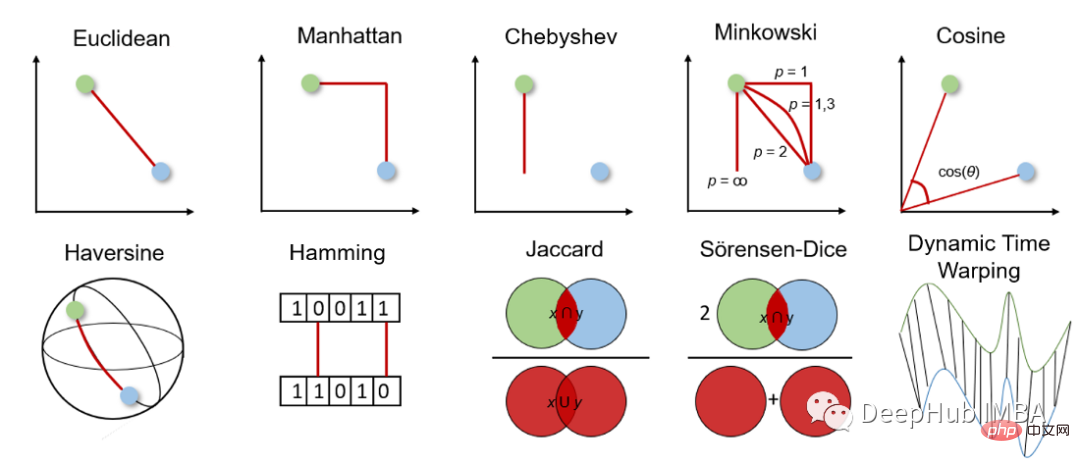
Sebelum kita melihat ukuran jarak yang berbeza dengan lebih mendalam, kita perlu terlebih dahulu mempunyai idea umum tentang cara ia berfungsi dan cara memilih ukuran yang sesuai.
Metrik jarak digunakan untuk mengira perbezaan antara dua objek dalam ruang masalah tertentu, iaitu ciri dalam set data. Jarak ini kemudiannya boleh digunakan untuk menentukan persamaan antara ciri, dengan semakin kecil jaraknya, semakin serupa ciri tersebut.
Untuk ukuran jarak, kita boleh memilih antara ukuran jarak geometri dan ukuran jarak statistik yang manakah perlu dipilih bergantung pada jenis data. Ciri mungkin daripada jenis data yang berbeza (cth., nilai sebenar, nilai Boolean, nilai kategori), dan data mungkin berbilang dimensi atau terdiri daripada data geospatial.
Ukuran jarak geometri
1. Jarak Euclidean Jarak Euclidean
Jarak Euclidean mengukur jarak terpendek antara dua vektor bernilai sebenar. Oleh kerana intuitif, kesederhanaan penggunaan dan hasil yang baik untuk banyak kes penggunaan, ia merupakan metrik jarak yang paling biasa digunakan dan metrik jarak lalai untuk banyak aplikasi.
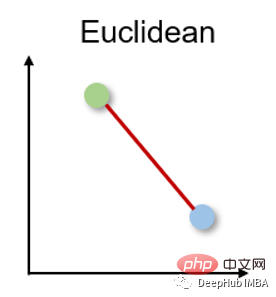
Jarak Euclidean juga boleh dipanggil norma l2, dan kaedah pengiraannya ialah:
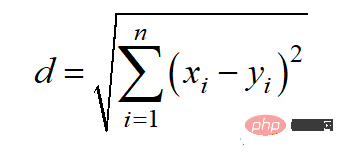
Kod Python adalah sebagai berikut
from scipy.spatial import distance distance.euclidean(vector_1, vector_2)
Jarak Euclidean mempunyai dua kelemahan utama. Pertama, ukuran jarak tidak berfungsi dengan data berdimensi lebih tinggi daripada ruang 2D atau 3D. Kedua, jika kita tidak menormalkan dan/atau menormalkan ciri, jarak mungkin terpesong mengikut unit.
2. Jarak Manhattan
Jarak Manhattan juga dipanggil jarak teksi atau blok bandar kerana jarak antara dua vektor bernilai sebenar adalah berdasarkan fakta bahawa seseorang hanya boleh bergerak pada sudut tepat Dikira . Ukuran jarak ini sering digunakan untuk atribut diskret dan binari supaya laluan benar boleh diperolehi.
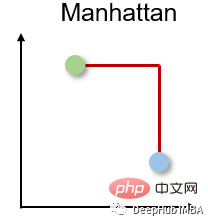
Jarak Manhattan adalah berdasarkan norma l1, dan formula pengiraan ialah:
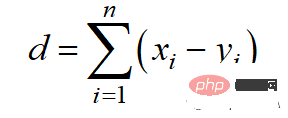
Kod Python adalah seperti berikut
from scipy.spatial import distance distance.cityblock(vector_1, vector_2)
Jarak Manhattan mempunyai dua kelemahan utama. Ia tidak seintuitif seperti jarak Euclidean dalam ruang dimensi tinggi, dan juga tidak menunjukkan laluan terpendek yang mungkin. Walaupun ini mungkin tidak menjadi masalah, kita harus sedar bahawa ini bukanlah jarak terpendek.
3. Jarak Chebyshev Jarak Chebyshev
Jarak Chebyshev juga dipanggil jarak papan dam kerana ia adalah jarak maksimum dalam mana-mana dimensi antara dua vektor bernilai sebenar. Ia biasanya digunakan dalam logistik gudang, di mana laluan terpanjang menentukan masa yang diperlukan untuk pergi dari satu titik ke titik lain.
Jarak Chebyshev dikira dengan norma l-infiniti:
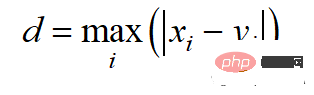
Kod Python adalah seperti berikut
from scipy.spatial import distance distance.chebyshev(vector_1, vector_2)
Jarak Chebyshev hanya mempunyai kes penggunaan yang sangat khusus dan oleh itu jarang digunakan.
4. Jarak Minkowski Jarak Minkowski
Jarak Minkowski ialah bentuk umum ukuran jarak di atas. Ia boleh digunakan untuk kes penggunaan yang sama sambil memberikan fleksibiliti yang tinggi. Kita boleh memilih nilai-p untuk mencari ukuran jarak yang paling sesuai.
Kaedah pengiraan jarak Minkowski ialah:
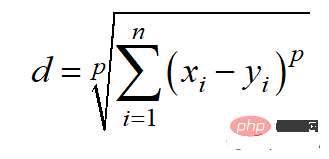
Kod Python adalah seperti berikut
from scipy.spatial import distance distance.minkowski(vector_1, vector_2, p)
Memandangkan jarak Minkowski mewakili ukuran jarak yang berbeza, ia mempunyai kelemahan utama yang sama sepertinya, seperti masalah dalam ruang berdimensi tinggi dan pergantungan pada unit ciri. Selain itu, fleksibiliti nilai-p juga boleh menjadi kelemahan, kerana ia boleh mengurangkan kecekapan pengiraan kerana pelbagai pengiraan diperlukan untuk mencari nilai-p yang betul.
5. Persamaan kosinus dan jarak Persamaan kosinus
Persamaan kosinus ialah ukuran arahnya ditentukan oleh kosinus antara dua vektor dan mengabaikan saiz vektor. Persamaan kosinus sering digunakan dalam dimensi tinggi di mana saiz data tidak penting, contohnya, sistem pengesyor atau analisis teks.
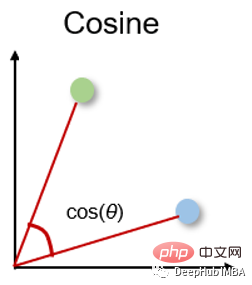
余弦相似度可以介于-1(相反方向)和1(相同方向)之间,计算方法为:
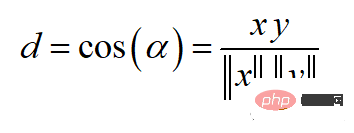
余弦相似度常用于范围在0到1之间的正空间中。余弦距离就是用1减去余弦相似度,位于0(相似值)和1(不同值)之间。
Python代码如下
from scipy.spatial import distance distance.cosine(vector_1, vector_2)
余弦距离的主要缺点是它不考虑大小而只考虑向量的方向。因此,没有充分考虑到值的差异。
6、半正矢距离 Haversine distance
半正矢距离测量的是球面上两点之间的最短距离。因此常用于导航,其中经度和纬度和曲率对计算都有影响。
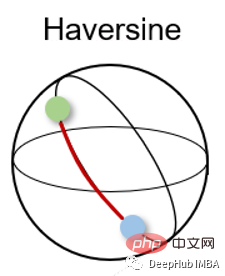
半正矢距离的公式如下:
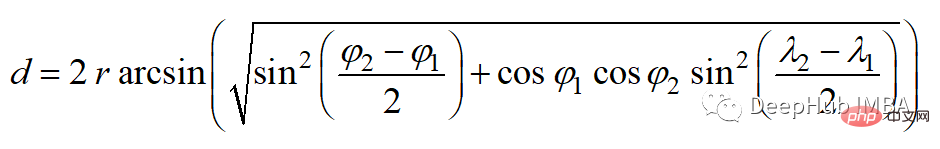
其中r为球面半径,φ和λ为经度和纬度。
Python代码如下
from sklearn.metrics.pairwise import haversine_distances haversine_distances([vector_1, vector_2])
半正矢距离的主要缺点是假设是一个球体,而这种情况很少出现。
7、汉明距离
汉明距离衡量两个二进制向量或字符串之间的差异。
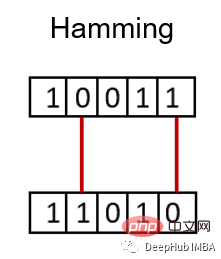
对向量按元素进行比较,并对差异的数量进行平均。如果两个向量相同,得到的距离是0之间,如果两个向量完全不同,得到的距离是1。
Python代码如下
from scipy.spatial import distance distance.hamming(vector_1, vector_2)
汉明距离有两个主要缺点。距离测量只能比较相同长度的向量,它不能给出差异的大小。所以当差异的大小很重要时,不建议使用汉明距离。
统计距离测量
统计距离测量可用于假设检验、拟合优度检验、分类任务或异常值检测。
8、杰卡德指数和距离 Jaccard Index
Jaccard指数用于确定两个样本集之间的相似性。它反映了与整个数据集相比存在多少一对一匹配。Jaccard指数通常用于二进制数据比如图像识别的深度学习模型的预测与标记数据进行比较,或者根据单词的重叠来比较文档中的文本模式。
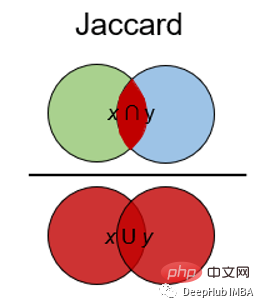
Jaccard距离的计算方法为:

Python代码如下
from scipy.spatial import distance distance.jaccard(vector_1, vector_2)
Jaccard指数和距离的主要缺点是,它受到数据规模的强烈影响,即每个项目的权重与数据集的规模成反比。
9、Sorensen-Dice指数
Sörensen-Dice指数类似于Jaccard指数,它可以衡量的是样本集的相似性和多样性。该指数更直观,因为它计算重叠的百分比。Sörensen-Dice索引常用于图像分割和文本相似度分析。
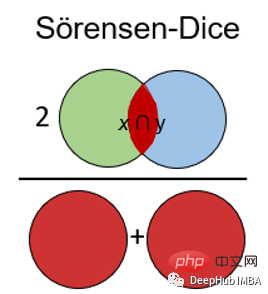
计算公式如下:
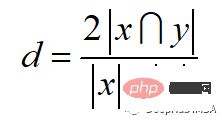
Python代码如下
from scipy.spatial import distance distance.dice(vector_1, vector_2)
它的主要缺点也是受数据集大小的影响很大。
10、动态时间规整 Dynamic Time Warping
动态时间规整是测量两个不同长度时间序列之间距离的一种重要方法。可以用于所有时间序列数据的用例,如语音识别或异常检测。
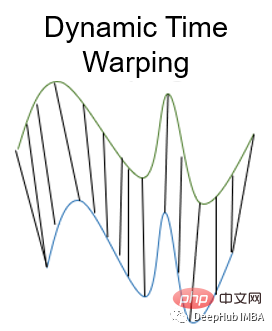
为什么我们需要一个为时间序列进行距离测量的度量呢?如果时间序列长度不同或失真,则上述面说到的其他距离测量无法确定良好的相似性。比如欧几里得距离计算每个时间步长的两个时间序列之间的距离。但是如果两个时间序列的形状相同但在时间上发生了偏移,那么尽管时间序列非常相似,但欧几里得距离会表现出很大的差异。
动态时间规整通过使用多对一或一对多映射来最小化两个时间序列之间的总距离来避免这个问题。当搜索最佳对齐时,这会产生更直观的相似性度量。通过动态规划找到一条弯曲的路径最小化距离,该路径必须满足以下条件:
- 边界条件:弯曲路径在两个时间序列的起始点和结束点开始和结束
- 单调性条件:保持点的时间顺序,避免时间倒流
- 连续条件:路径转换限制在相邻的时间点上,避免时间跳跃
- 整经窗口条件(可选):允许的点落入给定宽度的整经窗口
- 坡度条件(可选):限制弯曲路径坡度,避免极端运动
我们可以使用 Python 中的 fastdtw 包:
from scipy.spatial.distance import euclidean from fastdtw import fastdtw distance, path = fastdtw(timeseries_1, timeseries_2, dist=euclidean)
动态时间规整的一个主要缺点是与其他距离测量方法相比,它的计算工作量相对较高。
总结
在这篇文章中,简要介绍了十种常用的距离测量方法。本文中已经展示了它们是如何工作的,如何在Python中实现它们,以及经常使用它们解决什么问题。如果你认为我错过了一个重要的距离测量,请留言告诉我。
Atas ialah kandungan terperinci Sepuluh kaedah pengukuran jarak yang biasa digunakan dalam pembelajaran mesin. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Artikel ini akan membawa anda memahami SHAP: penjelasan model untuk pembelajaran mesin
Jun 01, 2024 am 10:58 AM
Dalam bidang pembelajaran mesin dan sains data, kebolehtafsiran model sentiasa menjadi tumpuan penyelidik dan pengamal. Dengan aplikasi meluas model yang kompleks seperti kaedah pembelajaran mendalam dan ensemble, memahami proses membuat keputusan model menjadi sangat penting. AI|XAI yang boleh dijelaskan membantu membina kepercayaan dan keyakinan dalam model pembelajaran mesin dengan meningkatkan ketelusan model. Meningkatkan ketelusan model boleh dicapai melalui kaedah seperti penggunaan meluas pelbagai model yang kompleks, serta proses membuat keputusan yang digunakan untuk menerangkan model. Kaedah ini termasuk analisis kepentingan ciri, anggaran selang ramalan model, algoritma kebolehtafsiran tempatan, dsb. Analisis kepentingan ciri boleh menerangkan proses membuat keputusan model dengan menilai tahap pengaruh model ke atas ciri input. Anggaran selang ramalan model
 Kenal pasti overfitting dan underfitting melalui lengkung pembelajaran
Apr 29, 2024 pm 06:50 PM
Kenal pasti overfitting dan underfitting melalui lengkung pembelajaran
Apr 29, 2024 pm 06:50 PM
Artikel ini akan memperkenalkan cara mengenal pasti pemasangan lampau dan kekurangan dalam model pembelajaran mesin secara berkesan melalui keluk pembelajaran. Underfitting dan overfitting 1. Overfitting Jika model terlampau latihan pada data sehingga ia mempelajari bunyi daripadanya, maka model tersebut dikatakan overfitting. Model yang dipasang terlebih dahulu mempelajari setiap contoh dengan sempurna sehingga ia akan salah mengklasifikasikan contoh yang tidak kelihatan/baharu. Untuk model terlampau, kami akan mendapat skor set latihan yang sempurna/hampir sempurna dan set pengesahan/skor ujian yang teruk. Diubah suai sedikit: "Punca overfitting: Gunakan model yang kompleks untuk menyelesaikan masalah mudah dan mengekstrak bunyi daripada data. Kerana set data kecil sebagai set latihan mungkin tidak mewakili perwakilan yang betul bagi semua data. 2. Underfitting Heru
 Telus! Analisis mendalam tentang prinsip model pembelajaran mesin utama!
Apr 12, 2024 pm 05:55 PM
Telus! Analisis mendalam tentang prinsip model pembelajaran mesin utama!
Apr 12, 2024 pm 05:55 PM
Dalam istilah orang awam, model pembelajaran mesin ialah fungsi matematik yang memetakan data input kepada output yang diramalkan. Secara lebih khusus, model pembelajaran mesin ialah fungsi matematik yang melaraskan parameter model dengan belajar daripada data latihan untuk meminimumkan ralat antara output yang diramalkan dan label sebenar. Terdapat banyak model dalam pembelajaran mesin, seperti model regresi logistik, model pepohon keputusan, model mesin vektor sokongan, dll. Setiap model mempunyai jenis data dan jenis masalah yang berkenaan. Pada masa yang sama, terdapat banyak persamaan antara model yang berbeza, atau terdapat laluan tersembunyi untuk evolusi model. Mengambil perceptron penyambung sebagai contoh, dengan meningkatkan bilangan lapisan tersembunyi perceptron, kita boleh mengubahnya menjadi rangkaian neural yang mendalam. Jika fungsi kernel ditambah pada perceptron, ia boleh ditukar menjadi SVM. yang ini
 Evolusi kecerdasan buatan dalam penerokaan angkasa lepas dan kejuruteraan penempatan manusia
Apr 29, 2024 pm 03:25 PM
Evolusi kecerdasan buatan dalam penerokaan angkasa lepas dan kejuruteraan penempatan manusia
Apr 29, 2024 pm 03:25 PM
Pada tahun 1950-an, kecerdasan buatan (AI) dilahirkan. Ketika itulah penyelidik mendapati bahawa mesin boleh melakukan tugas seperti manusia, seperti berfikir. Kemudian, pada tahun 1960-an, Jabatan Pertahanan A.S. membiayai kecerdasan buatan dan menubuhkan makmal untuk pembangunan selanjutnya. Penyelidik sedang mencari aplikasi untuk kecerdasan buatan dalam banyak bidang, seperti penerokaan angkasa lepas dan kelangsungan hidup dalam persekitaran yang melampau. Penerokaan angkasa lepas ialah kajian tentang alam semesta, yang meliputi seluruh alam semesta di luar bumi. Angkasa lepas diklasifikasikan sebagai persekitaran yang melampau kerana keadaannya berbeza daripada di Bumi. Untuk terus hidup di angkasa, banyak faktor mesti dipertimbangkan dan langkah berjaga-jaga mesti diambil. Para saintis dan penyelidik percaya bahawa meneroka ruang dan memahami keadaan semasa segala-galanya boleh membantu memahami cara alam semesta berfungsi dan bersedia untuk menghadapi kemungkinan krisis alam sekitar
 Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Melaksanakan Algoritma Pembelajaran Mesin dalam C++: Cabaran dan Penyelesaian Biasa
Jun 03, 2024 pm 01:25 PM
Cabaran biasa yang dihadapi oleh algoritma pembelajaran mesin dalam C++ termasuk pengurusan memori, multi-threading, pengoptimuman prestasi dan kebolehselenggaraan. Penyelesaian termasuk menggunakan penunjuk pintar, perpustakaan benang moden, arahan SIMD dan perpustakaan pihak ketiga, serta mengikuti garis panduan gaya pengekodan dan menggunakan alat automasi. Kes praktikal menunjukkan cara menggunakan perpustakaan Eigen untuk melaksanakan algoritma regresi linear, mengurus memori dengan berkesan dan menggunakan operasi matriks berprestasi tinggi.
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Adakah Flash Attention stabil? Meta dan Harvard mendapati bahawa sisihan berat model mereka berubah-ubah mengikut urutan magnitud
May 30, 2024 pm 01:24 PM
Adakah Flash Attention stabil? Meta dan Harvard mendapati bahawa sisihan berat model mereka berubah-ubah mengikut urutan magnitud
May 30, 2024 pm 01:24 PM
MetaFAIR bekerjasama dengan Harvard untuk menyediakan rangka kerja penyelidikan baharu untuk mengoptimumkan bias data yang dijana apabila pembelajaran mesin berskala besar dilakukan. Adalah diketahui bahawa latihan model bahasa besar sering mengambil masa berbulan-bulan dan menggunakan ratusan atau bahkan ribuan GPU. Mengambil model LLaMA270B sebagai contoh, latihannya memerlukan sejumlah 1,720,320 jam GPU. Melatih model besar memberikan cabaran sistemik yang unik disebabkan oleh skala dan kerumitan beban kerja ini. Baru-baru ini, banyak institusi telah melaporkan ketidakstabilan dalam proses latihan apabila melatih model AI generatif SOTA Mereka biasanya muncul dalam bentuk lonjakan kerugian Contohnya, model PaLM Google mengalami sehingga 20 lonjakan kerugian semasa proses latihan. Bias berangka adalah punca ketidaktepatan latihan ini,
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
