
 Peranti teknologi
AI
Manusia tidak mempunyai korpus berkualiti tinggi yang mencukupi untuk AI belajar, dan mereka akan keletihan pada tahun 2026. Netizen: Projek penjanaan teks manusia berskala besar telah dilancarkan!
Peranti teknologi
AI
Manusia tidak mempunyai korpus berkualiti tinggi yang mencukupi untuk AI belajar, dan mereka akan keletihan pada tahun 2026. Netizen: Projek penjanaan teks manusia berskala besar telah dilancarkan!
Manusia tidak mempunyai korpus berkualiti tinggi yang mencukupi untuk AI belajar, dan mereka akan keletihan pada tahun 2026. Netizen: Projek penjanaan teks manusia berskala besar telah dilancarkan!

Selera AI terlalu besar, dan data korpus manusia tidak lagi mencukupi.
Sebuah kertas baharu daripada pasukan Epoch menunjukkan bahawa AI akan menggunakan semua korpus berkualiti tinggi dalam masa kurang daripada 5 tahun.

Anda mesti tahu bahawa ini adalah hasil yang diramalkan dengan mengambil kira kadar pertumbuhan data bahasa manusia Dalam erti kata lain, bilangan kertas yang baru ditulis dan yang baru disusun oleh manusia dalam beberapa tahun kebelakangan ini Walaupun semua kod diberikan kepada AI, ia tidak akan mencukupi.
Jika ini berterusan, model bahasa besar yang bergantung pada data berkualiti tinggi untuk meningkatkan prestasi mereka akan menghadapi kesesakan tidak lama lagi.
Sesetengah netizen tidak boleh duduk diam:
Ini mengarut. Manusia boleh melatih diri dengan berkesan tanpa membaca segala-galanya di Internet.
Kami memerlukan model yang lebih baik, bukan lebih banyak data.
Sesetengah netizen mengejek bahawa lebih baik membiarkan AI makan apa yang dimuntahkannya:
AI boleh menjananya dengan sendirinya Teks disalurkan kepada AI sebagai data berkualiti rendah.

Mari kita lihat, berapa banyak data yang ditinggalkan oleh manusia?
Bagaimanakah data teks dan imej "inventori"?
Kertas ini terutamanya meramalkan dua jenis data: teks dan imej.
Pertama ialah data teks.
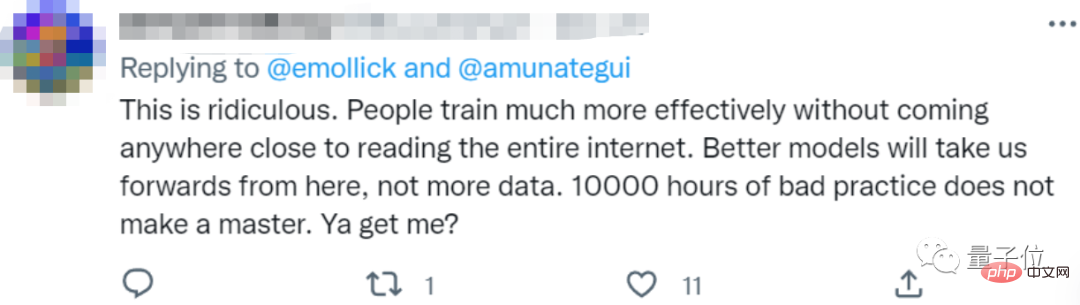
Kualiti data biasanya terdiri daripada baik hingga buruk. Pengarang membahagikan data teks yang tersedia kepada bahagian berkualiti rendah dan berkualiti tinggi berdasarkan jenis data yang digunakan oleh model besar sedia ada dan data lain.
Korpus berkualiti tinggi merujuk kepada set data latihan yang digunakan oleh model bahasa besar seperti Pile, PaLM dan MassiveText, termasuk Wikipedia, berita, kod pada GitHub, buku yang diterbitkan, dsb.
Korpus berkualiti rendah datang daripada tweet di media sosial seperti Reddit, serta fiksyen peminat tidak rasmi (fanfic).
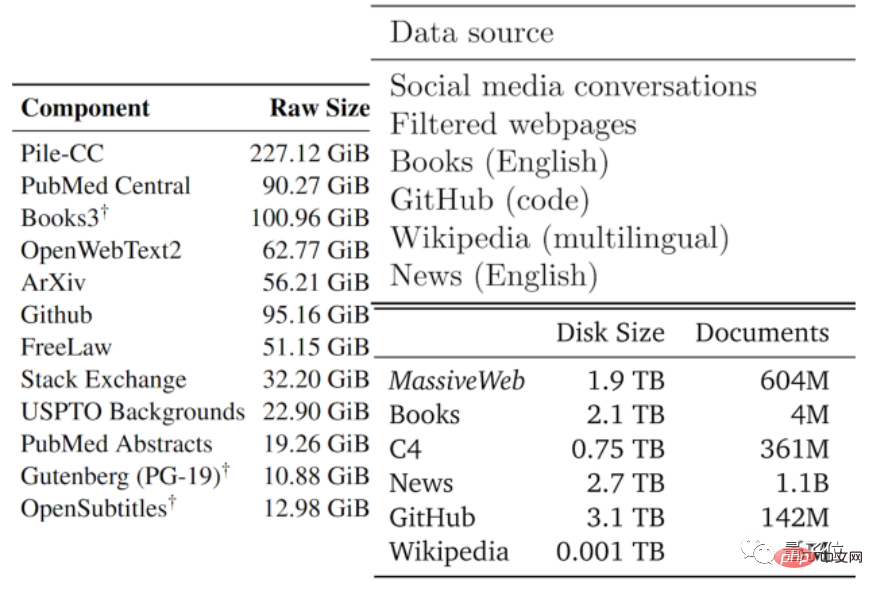
Menurut statistik, hanya tinggal kira-kira 4.6×10^12~1.7×10^13 perkataan dalam stok data bahasa berkualiti tinggi, iaitu kurang daripada susunan magnitud yang lebih besar daripada teks terbesar semasa set data.
Digabungkan dengan kadar pertumbuhan, makalah itu meramalkan bahawa data teks berkualiti tinggi akan dihabiskan oleh AI antara 2023 dan 2027, dengan anggaran nod sekitar 2026.
Nampaknya agak pantas...
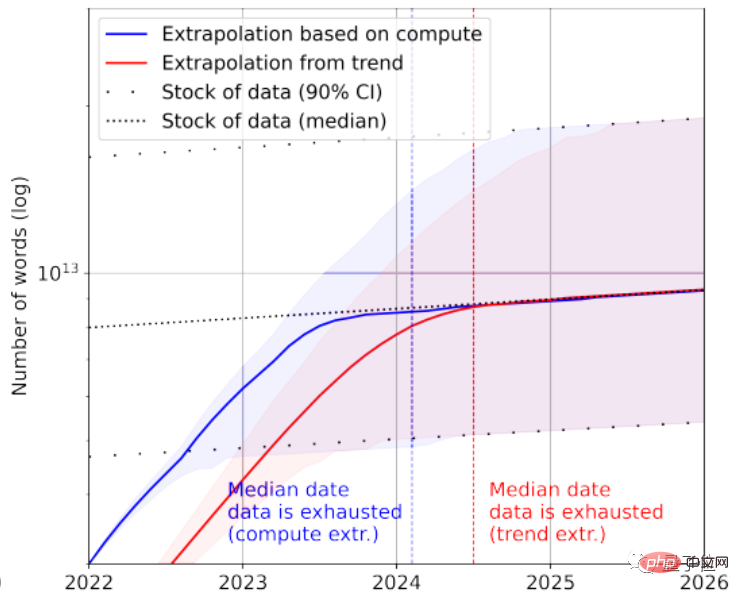
Sudah tentu, data teks berkualiti rendah boleh ditambah untuk menyelamatkan. Menurut statistik, pada masa ini terdapat 7×10^13~7×10^16 perkataan yang tinggal dalam keseluruhan stok data teks, iaitu 1.5~4.5 susunan magnitud lebih besar daripada set data terbesar.
Jika keperluan untuk kualiti data tidak tinggi, maka AI akan menggunakan semua data teks antara 2030 dan 2050.
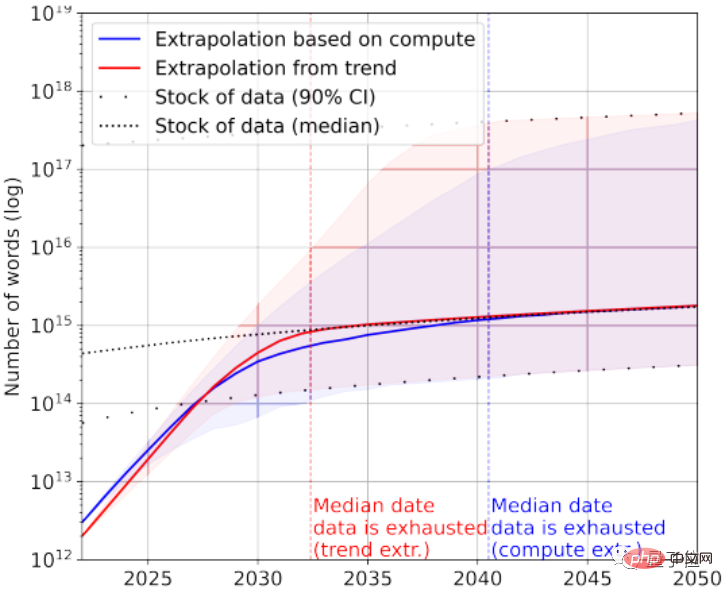
Melihat data imej sekali lagi, kertas di sini tidak membezakan kualiti imej.
Set data imej terbesar pada masa ini mempunyai imej 3×10^9.
Menurut statistik, jumlah bilangan imej semasa adalah lebih kurang 8.11×10^12~2.3×10^13, iaitu 3~4 susunan magnitud lebih besar daripada set data imej terbesar.
Makalah itu meramalkan bahawa AI akan kehabisan imej ini antara 2030 dan 2070.
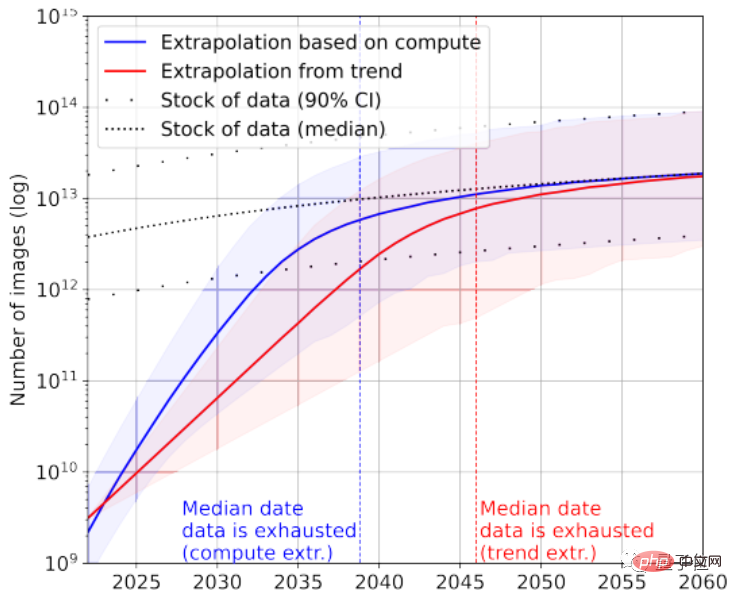
Jelas sekali, model bahasa besar menghadapi situasi "kekurangan data" yang lebih teruk berbanding model imej.
Jadi bagaimana kesimpulan ini dicapai?
Kira purata bilangan siaran harian yang disiarkan oleh netizen dan dapatkan hasilnya
Kertas tersebut menganalisis kecekapan penjanaan data imej teks dan pertumbuhan set data latihan daripada dua perspektif.
Perlu diambil perhatian bahawa statistik dalam kertas itu bukan semua data berlabel Memandangkan pembelajaran tanpa pengawasan agak popular, data tidak berlabel juga disertakan.
Ambil data teks sebagai contoh Kebanyakan data akan dijana daripada platform sosial, blog dan forum.
Untuk menganggarkan kelajuan penjanaan data teks, terdapat tiga faktor yang perlu dipertimbangkan, iaitu jumlah populasi, kadar penembusan Internet, dan jumlah purata data yang dijana oleh pengguna Internet.
Sebagai contoh, ini ialah anggaran populasi masa hadapan dan trend pertumbuhan pengguna Internet berdasarkan data populasi sejarah dan bilangan pengguna Internet:
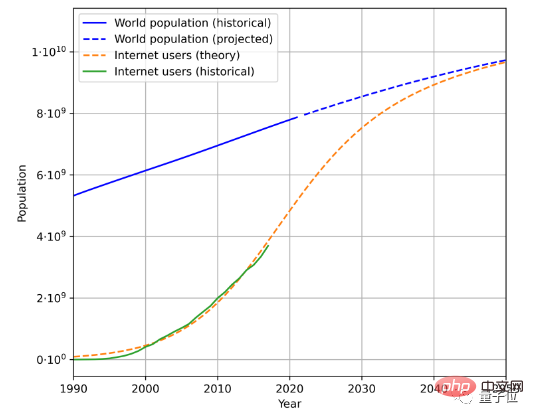
digabungkan dengan pengguna -dijana Dengan purata jumlah data, kadar di mana data dijana boleh dikira. (Disebabkan perubahan geografi dan masa yang kompleks, makalah ini memudahkan kaedah pengiraan jumlah purata data yang dijana oleh pengguna)
Mengikut kaedah ini, kadar pertumbuhan data bahasa dikira sekitar 7%. Walau bagaimanapun, kadar pertumbuhan ini akan meningkat dengan Berperingkat menurun dari semasa ke semasa.
Dianggarkan menjelang 2100, kadar pertumbuhan data bahasa kami akan menurun kepada 1%.
Kaedah yang sama digunakan untuk menganalisis data imej Kadar pertumbuhan semasa adalah kira-kira 8%.
Makalah ini percaya bahawa jika kadar pertumbuhan data tidak meningkat dengan ketara, atau sumber data baharu muncul, sama ada imej atau teks model besar yang dilatih dengan data berkualiti tinggi, ia mungkin membawa kepada tempoh kesesakan pada peringkat tertentu.
Sesetengah netizen bergurau tentang perkara ini, mengatakan bahawa sesuatu seperti jalan cerita fiksyen sains mungkin akan berlaku pada masa hadapan:
Untuk melatih AI, manusia telah melancarkan projek penjanaan teks berskala besar, dan semua orang sedang bekerja keras untuk menulis sesuatu untuk AI.
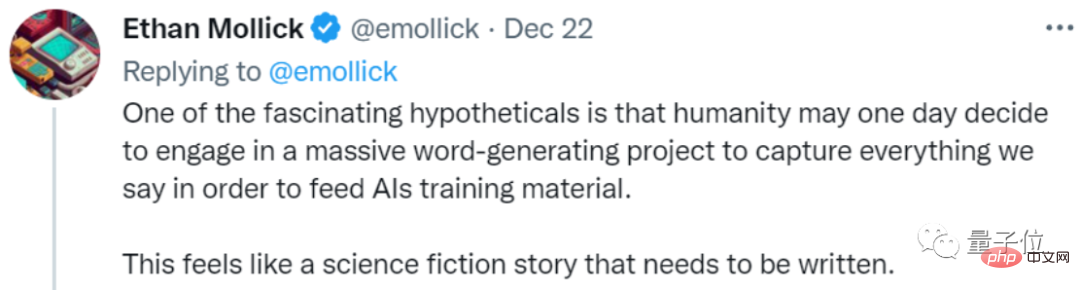
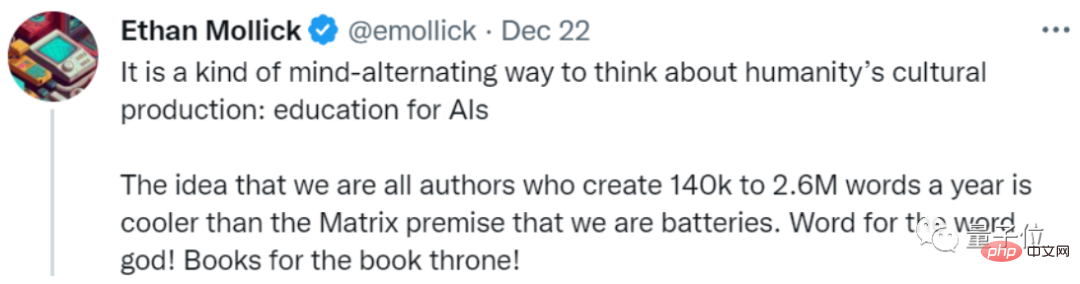
Dia menggelarnya sebagai sejenis "pendidikan untuk AI":
Kami memberi AI 140,000 hingga 2.6 juta perkataan setiap tahun Jumlah data teks, bunyi lebih sejuk daripada menggunakan manusia sebagai bateri?
Apa pendapat anda?
Alamat kertas: https://arxiv.org/abs/2211.04325
Pautan rujukan: https://twitter.com/emollick/status/1605756428941246466
Atas ialah kandungan terperinci Manusia tidak mempunyai korpus berkualiti tinggi yang mencukupi untuk AI belajar, dan mereka akan keletihan pada tahun 2026. Netizen: Projek penjanaan teks manusia berskala besar telah dilancarkan!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1387
1387
 52
52

 Kongsi cara mudah untuk membungkus projek PyCharm
Dec 30, 2023 am 09:34 AM
Kongsi cara mudah untuk membungkus projek PyCharm
Dec 30, 2023 am 09:34 AM
Kongsi kaedah pembungkusan projek PyCharm yang mudah dan mudah difahami Dengan populariti Python, semakin ramai pembangun menggunakan PyCharm sebagai alat utama untuk pembangunan Python. PyCharm ialah persekitaran pembangunan bersepadu yang berkuasa yang menyediakan banyak fungsi mudah untuk membantu kami meningkatkan kecekapan pembangunan. Salah satu fungsi penting ialah pembungkusan projek. Artikel ini akan memperkenalkan cara untuk membungkus projek dalam PyCharm dengan cara yang mudah dan mudah difahami, dan memberikan contoh kod khusus. Mengapa projek pakej? Dibangunkan dalam Python
 Bolehkah AI menakluki teorem terakhir Fermat? Ahli matematik melepaskan 5 tahun kerjayanya untuk mengubah 100 halaman bukti menjadi kod
Apr 09, 2024 pm 03:20 PM
Bolehkah AI menakluki teorem terakhir Fermat? Ahli matematik melepaskan 5 tahun kerjayanya untuk mengubah 100 halaman bukti menjadi kod
Apr 09, 2024 pm 03:20 PM
Teorem terakhir Fermat, akan ditakluki oleh AI? Dan bahagian yang paling bermakna dari keseluruhannya ialah Teorem Terakhir Fermat, yang akan diselesaikan oleh AI, dengan tepat untuk membuktikan bahawa AI tidak berguna. Suatu ketika dahulu, matematik tergolong dalam alam kecerdasan manusia yang tulen kini, wilayah ini dihuraikan dan diinjak oleh algoritma canggih. Imej Teorem Terakhir Fermat ialah teka-teki "terkenal" yang telah membingungkan ahli matematik selama berabad-abad. Ia telah terbukti pada tahun 1993, dan kini ahli matematik mempunyai rancangan besar: untuk mencipta semula bukti menggunakan komputer. Mereka berharap bahawa sebarang ralat logik dalam versi bukti ini boleh disemak oleh komputer. Alamat projek: https://github.com/riccardobrasca/flt
 Regresi kuantil untuk ramalan kebarangkalian siri masa
May 07, 2024 pm 05:04 PM
Regresi kuantil untuk ramalan kebarangkalian siri masa
May 07, 2024 pm 05:04 PM
Jangan ubah maksud kandungan asal, perhalusi kandungan, tulis semula kandungan dan jangan teruskan. "Regression kuantil memenuhi keperluan ini, menyediakan selang ramalan dengan peluang yang dikira. Ia adalah teknik statistik yang digunakan untuk memodelkan hubungan antara pembolehubah peramal dan pembolehubah tindak balas, terutamanya apabila taburan bersyarat pembolehubah tindak balas adalah menarik Apabila. Tidak seperti regresi tradisional kaedah, regresi kuantil memfokuskan pada menganggar magnitud bersyarat pembolehubah bergerak balas dan bukannya min bersyarat "Rajah (A): Regresi kuantil Regresi kuantil ialah anggaran. Kaedah pemodelan untuk hubungan linear antara set regresi X dan kuantil. daripada pembolehubah yang dijelaskan Y. Model regresi yang sedia ada sebenarnya adalah kaedah untuk mengkaji hubungan antara pembolehubah yang dijelaskan dan pembolehubah penjelasan. Mereka memberi tumpuan kepada hubungan antara pembolehubah penjelasan dan pembolehubah yang dijelaskan
 Melihat lebih dekat pada PyCharm: cara cepat untuk memadamkan projek
Feb 26, 2024 pm 04:21 PM
Melihat lebih dekat pada PyCharm: cara cepat untuk memadamkan projek
Feb 26, 2024 pm 04:21 PM
Tajuk: Ketahui lebih lanjut tentang PyCharm: Cara yang cekap untuk memadamkan projek Dalam beberapa tahun kebelakangan ini, Python, sebagai bahasa pengaturcaraan yang berkuasa dan fleksibel, telah digemari oleh semakin ramai pembangun. Dalam pembangunan projek Python, adalah penting untuk memilih persekitaran pembangunan bersepadu yang cekap. Sebagai persekitaran pembangunan bersepadu yang berkuasa, PyCharm menyediakan pembangun Python dengan banyak fungsi dan alatan yang mudah, termasuk memadamkan direktori projek dengan cepat dan cekap. Berikut akan memberi tumpuan kepada cara menggunakan padam dalam PyCharm
 Petua Praktikal PyCharm: Tukar Projek kepada Fail EXE Boleh Laku
Feb 23, 2024 am 09:33 AM
Petua Praktikal PyCharm: Tukar Projek kepada Fail EXE Boleh Laku
Feb 23, 2024 am 09:33 AM
PyCharm ialah persekitaran pembangunan bersepadu Python yang berkuasa yang menyediakan pelbagai alatan pembangunan dan konfigurasi persekitaran, membolehkan pembangun menulis dan menyahpepijat kod dengan lebih cekap. Dalam proses menggunakan PyCharm untuk pembangunan projek Python, kadangkala kita perlu membungkus projek ke dalam fail EXE boleh laku untuk dijalankan pada komputer yang tidak mempunyai persekitaran Python yang dipasang. Artikel ini akan memperkenalkan cara menggunakan PyCharm untuk menukar projek kepada fail EXE boleh laku dan memberikan contoh kod khusus. kepala
 SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
SIMPL: Penanda aras ramalan gerakan berbilang ejen yang mudah dan cekap untuk pemanduan autonomi
Feb 20, 2024 am 11:48 AM
Tajuk asal: SIMPL: ASimpleandEfficientMulti-agentMotionPredictionBaselineforAutonomousDriving Paper pautan: https://arxiv.org/pdf/2402.02519.pdf Pautan kod: https://github.com/HKUST-Aerial-Robotics/SIMPL Unit pengarang: Universiti Sains Hong Kong dan Teknologi Idea Kertas DJI: Kertas kerja ini mencadangkan garis dasar ramalan pergerakan (SIMPL) yang mudah dan cekap untuk kenderaan autonomi. Berbanding dengan agen-sen tradisional
 Cara Membuat Senarai Beli-belah dalam Apl Peringatan iOS 17 pada iPhone
Sep 21, 2023 pm 06:41 PM
Cara Membuat Senarai Beli-belah dalam Apl Peringatan iOS 17 pada iPhone
Sep 21, 2023 pm 06:41 PM
Cara Membuat Senarai Runcit pada iPhone dalam iOS17 Mencipta Senarai Runcit dalam apl Peringatan adalah sangat mudah. Anda hanya menambah senarai dan mengisinya dengan item anda. Apl ini secara automatik mengisih item anda ke dalam kategori, dan anda juga boleh bekerjasama dengan pasangan anda atau rakan kongsi rata untuk membuat senarai barang yang anda perlu beli dari kedai. Berikut ialah langkah penuh untuk melakukan ini: Langkah 1: Hidupkan Peringatan iCloud Walaupun kedengaran pelik, Apple berkata anda perlu mendayakan peringatan daripada iCloud untuk mencipta Senarai Runcit pada iOS17. Berikut ialah langkah untuknya: Pergi ke apl Tetapan pada iPhone anda dan ketik [nama anda]. Seterusnya, pilih i
 Bagaimana untuk menggunakan pangkalan data MySQL untuk ramalan dan analitik ramalan?
Jul 12, 2023 pm 08:43 PM
Bagaimana untuk menggunakan pangkalan data MySQL untuk ramalan dan analitik ramalan?
Jul 12, 2023 pm 08:43 PM
Bagaimana untuk menggunakan pangkalan data MySQL untuk ramalan dan analitik ramalan? Gambaran Keseluruhan: Peramalan dan analitik ramalan memainkan peranan penting dalam analisis data. MySQL, sistem pengurusan pangkalan data hubungan yang digunakan secara meluas, juga boleh digunakan untuk tugasan ramalan dan analisis ramalan. Artikel ini akan memperkenalkan cara menggunakan MySQL untuk ramalan dan analisis ramalan, serta menyediakan contoh kod yang berkaitan. Penyediaan data: Pertama, kita perlu menyediakan data yang berkaitan. Katakan kita ingin membuat ramalan jualan, kita memerlukan jadual dengan data jualan. Dalam MySQL kita boleh gunakan
