
 Peranti teknologi
AI
Belajar = sesuai? Adakah pembelajaran mendalam dan statistik klasik adalah perkara yang sama?
Peranti teknologi
AI
Belajar = sesuai? Adakah pembelajaran mendalam dan statistik klasik adalah perkara yang sama?
Belajar = sesuai? Adakah pembelajaran mendalam dan statistik klasik adalah perkara yang sama?

Dalam artikel ini, Boaz Barak, seorang saintis komputer teori dan profesor terkenal di Universiti Harvard, membandingkan perbezaan antara pembelajaran mendalam dan statistik klasik secara terperinci Dia percaya bahawa "jika anda memahami pembelajaran mendalam semata-mata dari perspektif statistik , anda akan mengabaikan keputusannya yang berjaya." faktor utama".
Pembelajaran mendalam (atau pembelajaran mesin secara umum) sering dianggap sebagai statistik semata-mata, iaitu pada asasnya konsep yang sama yang dikaji oleh ahli statistik, tetapi diterangkan menggunakan istilah yang berbeza daripada statistik. Rob Tibshirani pernah merumuskan "perbendaharaan kata" yang menarik ini di bawah:

Adakah sesuatu dalam senarai ini benar-benar bergema? Hampir sesiapa sahaja yang terlibat dalam pembelajaran mesin tahu bahawa banyak istilah di sebelah kanan jadual yang disiarkan oleh Tibshiriani digunakan secara meluas dalam pembelajaran mesin.
Jika anda memahami pembelajaran mendalam semata-mata daripada perspektif statistik, anda akan mengabaikan faktor utama kejayaannya. Penilaian pembelajaran mendalam yang lebih sesuai ialah ia menggunakan istilah statistik untuk menerangkan konsep yang sama sekali berbeza.
Penilaian pembelajaran mendalam yang betul bukanlah kerana ia menggunakan perkataan yang berbeza untuk menerangkan istilah statistik lama, tetapi ia menggunakan istilah ini untuk menerangkan proses yang sama sekali berbeza.
Artikel ini akan menerangkan sebab asas pembelajaran mendalam sebenarnya berbeza daripada statistik, malah berbeza daripada pembelajaran mesin klasik. Artikel ini mula-mula membincangkan perbezaan antara tugas "penjelasan" dan tugas "ramalan" apabila menyesuaikan model kepada data. Dua senario proses pembelajaran kemudiannya dibincangkan: 1. Memasang model statistik menggunakan pengurangan risiko empirikal 2. Mengajar kemahiran matematik kepada pelajar; Kemudian, artikel membincangkan senario mana yang lebih dekat dengan intipati pembelajaran mendalam.
Walaupun matematik dan kod untuk pembelajaran mendalam hampir sama dengan model statistik yang sesuai. Tetapi pada tahap yang lebih mendalam, pembelajaran mendalam lebih seperti mengajar kemahiran matematik kepada pelajar. Dan sepatutnya ada sangat sedikit orang yang berani mendakwa: Saya telah menguasai teori pembelajaran mendalam yang lengkap! Malah, adalah diragui sama ada teori sedemikian wujud. Sebaliknya, aspek pembelajaran mendalam yang berbeza difahami dengan baik dari perspektif yang berbeza, dan statistik sahaja tidak dapat memberikan gambaran yang lengkap.
Artikel ini membandingkan pembelajaran mendalam dan statistik di sini secara khusus merujuk kepada "statistik klasik" kerana ia telah dikaji untuk masa yang paling lama dan telah berada dalam buku teks untuk masa yang lama. Ramai ahli statistik sedang mengusahakan pembelajaran mendalam dan kaedah teori bukan klasik, sama seperti ahli fizik abad ke-20 diperlukan untuk mengembangkan rangka kerja fizik klasik. Malah, mengaburkan garis antara saintis komputer dan ahli statistik memberi manfaat kepada kedua-dua pihak.
Ramalan dan pemasangan model
Para saintis sentiasa membandingkan hasil pengiraan model dengan hasil pemerhatian sebenar untuk mengesahkan ketepatan model. Ahli astronomi Mesir Ptolemy mencadangkan model cerdik gerakan planet. Model Ptolemy mengikuti geosentrisme tetapi mempunyai satu siri epicycle (lihat rajah di bawah), memberikan ketepatan ramalan yang sangat baik. Sebaliknya, model heliosentrik asal Copernicus adalah lebih mudah daripada model Ptolemaic tetapi kurang tepat dalam meramalkan pemerhatian. (Copernicus kemudiannya menambah epicyclesnya sendiri untuk setanding dengan model Ptolemy.)
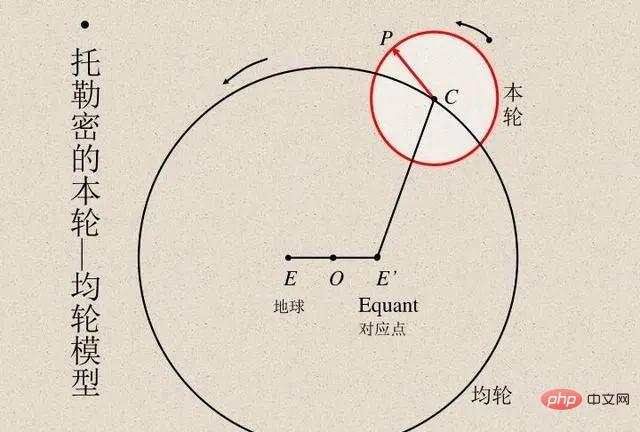
Kedua-dua model Ptolemy dan Copernicus tiada tandingannya. Jika kita ingin membuat ramalan dari "kotak hitam", maka model geosentrik Ptolemy adalah lebih unggul. Tetapi jika anda mahukan model mudah yang anda boleh "melihat ke dalam" (yang merupakan titik permulaan untuk teori yang menerangkan gerakan bintang), maka model Copernicus adalah cara untuk pergi. Kemudian, Kepler menambah baik model Copernicus kepada orbit elips dan mencadangkan tiga undang-undang pergerakan planet Kepler, yang membolehkan Newton menerangkan undang-undang planet dengan undang-undang graviti yang terpakai kepada bumi.
Oleh itu adalah penting bahawa model heliosentrik bukan sekadar "kotak hitam" yang menyediakan ramalan, tetapi diberikan oleh beberapa persamaan matematik mudah, tetapi dengan sangat sedikit "bahagian bergerak" dalam persamaan. Astronomi telah menjadi sumber inspirasi untuk membangunkan teknik statistik selama bertahun-tahun. Gauss dan Legendre secara bebas mencipta regresi kuasa dua terkecil sekitar tahun 1800 untuk meramalkan orbit asteroid dan jasad angkasa yang lain. Pada tahun 1847, Cauchy mencipta kaedah penurunan kecerunan, yang juga didorong oleh ramalan astronomi.
Dalam fizik, kadangkala sarjana boleh menguasai semua butiran untuk mencari teori "betul", mengoptimumkan ketepatan ramalan dan memberikan penjelasan terbaik tentang data. Ini adalah dalam skop idea seperti pisau cukur Occam, yang boleh dianggap sebagai mengandaikan bahawa kesederhanaan, kuasa ramalan dan kuasa penjelasan semuanya selaras antara satu sama lain.
Namun, dalam banyak bidang lain, hubungan antara dua matlamat penjelasan dan ramalan tidak begitu harmoni. Jika anda hanya ingin meramalkan pemerhatian, melalui "kotak hitam" mungkin adalah yang terbaik. Sebaliknya, jika seseorang ingin mendapatkan maklumat penjelasan, seperti model sebab akibat, prinsip umum, atau ciri penting, maka lebih mudah model yang boleh difahami dan dijelaskan, lebih baik.
Pilihan model yang betul bergantung pada tujuannya. Contohnya, pertimbangkan set data yang mengandungi ekspresi genetik dan fenotip bagi banyak individu (cth. beberapa penyakit jika matlamatnya adalah untuk meramalkan peluang seseorang untuk jatuh sakit, maka tidak kira betapa kompleksnya atau berapa banyak gen yang bergantung padanya, gunakan Model ramalan terbaik yang disesuaikan dengan tugas. Sebaliknya, jika tujuannya adalah untuk mengenal pasti beberapa gen untuk kajian lanjut, maka "kotak hitam" yang kompleks dan sangat tepat adalah penggunaan terhad.
Ahli statistik Leo Breiman menyatakan perkara ini dalam artikel 2001nya yang terkenal tentang Dua Budaya dalam Pemodelan Statistik. Yang pertama ialah "budaya pemodelan data" yang memfokuskan pada model generatif mudah yang boleh menerangkan data. Yang kedua ialah "budaya pemodelan algoritma" yang agnostik tentang cara data dijana dan memfokuskan pada mencari model yang boleh meramalkan data, tidak kira betapa rumitnya.

Tajuk kertas:
Pemodelan Statistik: Dua Budaya
Pautan kertas:
https://projecteuclid .
halang ahli statistik daripada mengkaji masalah baharu yang menarik
- Kertas Breiman menimbulkan beberapa kontroversi apabila ia keluar. Rakan perangkaan Brad Efron menjawab bahawa walaupun dia bersetuju dengan beberapa perkara, dia juga menekankan bahawa hujah Breiman nampaknya bertentangan dengan jimat cermat dan pandangan saintifik yang memihak kepada usaha keras untuk mencipta "kotak hitam" yang kompleks. Tetapi dalam artikel baru-baru ini, Efron meninggalkan pandangannya sebelum ini dan mengakui bahawa Breima lebih tepat kerana "fokus statistik pada abad ke-21 adalah pada algoritma ramalan, yang telah berkembang secara besar-besaran mengikut garis yang dicadangkan oleh Breiman."
- Model Ramalan Klasik dan Moden
Petikan daripada buku teks Duda dan Hart "Klasifikasi corak dan analisis adegan" dan kertas Highleyman 1962 "Reka Bentuk dan Analisis Eksperimen Pengecaman Corak".
Begitu juga, imej di bawah set data aksara tulisan tangan Highleyman dan seni bina yang digunakan untuk menyesuaikannya, Chow (1962) (ketepatan ~58%), akan bergema dengan ramai orang. 
Mengapa pembelajaran mendalam berbeza?
Pada tahun 1992, Geman, Bienenstock dan Doursat menulis artikel yang pesimis tentang rangkaian saraf, dengan alasan bahawa "rangkaian neural suapan semasa sebahagian besarnya tidak mencukupi untuk menyelesaikan masalah sukar dalam persepsi mesin dan pembelajaran mesin" . Secara khusus, mereka berpendapat bahawa rangkaian neural tujuan umum tidak akan berjaya mengendalikan tugas yang sukar, dan satu-satunya cara mereka boleh berjaya adalah melalui ciri yang direka bentuk secara buatan. Dalam kata-kata mereka: "Sifat penting mesti terbina dalam atau "berwayar keras"... dan bukannya dipelajari dalam apa-apa erti kata statistik Sekarang nampaknya Geman et al benar-benar salah, tetapi ia lebih menarik untuk difahami mengapa mereka Salah. 
(
ialah matriks;
ialah vektor berdimensi2. Gunakan data di atas untuk memuatkan model  dan gunakan algoritma pengoptimuman untuk meminimumkan risiko empirikal. Maksudnya, cari
dan gunakan algoritma pengoptimuman untuk meminimumkan risiko empirikal. Maksudnya, cari  sedemikian melalui algoritma pengoptimuman supaya
sedemikian melalui algoritma pengoptimuman supaya 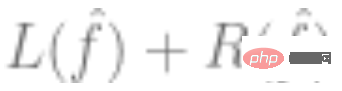 ialah yang terkecil,
ialah yang terkecil,  mewakili kerugian (menunjukkan betapa hampirnya nilai ramalan dengan nilai sebenar), dan
mewakili kerugian (menunjukkan betapa hampirnya nilai ramalan dengan nilai sebenar), dan  adalah pilihan istilah regularisasi.
adalah pilihan istilah regularisasi.
3. Lebih kecil kehilangan keseluruhan model, lebih baik, iaitu nilai ralat generalisasi 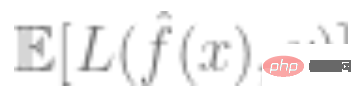 adalah agak minimum.
adalah agak minimum.
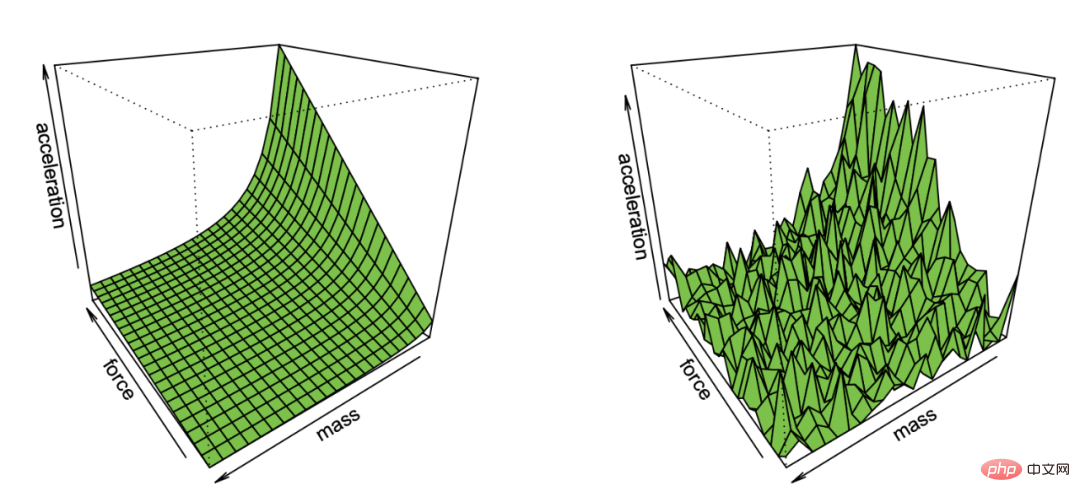
Ilustrasi Effron tentang memulihkan hukum pertama Newton daripada pemerhatian yang mengandungi hingar
Contoh yang sangat umum ini sebenarnya mengandungi banyak perkara, seperti kuasa dua terkecil Regresi linear, jiran terdekat , latihan rangkaian saraf dan banyak lagi. Dalam senario statistik klasik, kami biasanya menghadapi situasi berikut:
Perdagangan: Dengan mengandaikan koleksi model yang dioptimumkan (jika fungsi itu bukan cembung atau mengandungi istilah regularisasi, pilihan algoritma dan penetapan yang teliti boleh Dapatkan set model. Bias ialah anggaran yang paling hampir dengan nilai sebenar yang boleh dicapai oleh sesuatu elemen, semakin kecil set itu, dan mungkin 0 jika
. lebih besar varians model keluaran algoritma Ralat generalisasi keseluruhan adalah jumlah bias dan varians Oleh itu, pembelajaran statistik biasanya merupakan pertukaran Bias-Variance, dan kerumitan model yang betul adalah untuk meminimumkan ralat keseluruhan , Geman et al. menunjukkan pesimisme mereka tentang rangkaian saraf dengan berhujah bahawa had asas yang ditimbulkan oleh dilema Bias-Variance digunakan untuk semua model inferens bukan parametrik, termasuk rangkaian saraf
"Lebih banyak lagi meriah" tidak terpakai . Sentiasa benar: Dalam pembelajaran statistik, lebih banyak ciri atau data tidak semestinya meningkatkan prestasi Sebagai contoh, sukar untuk belajar daripada data yang mengandungi banyak ciri yang tidak berkaitan satu daripada dua pengedaran (seperti dan , adalah lebih sukar daripada mempelajari setiap pengedaran secara bebas.
Pulangan berkurangan: Dalam banyak kes, bilangan titik data yang diperlukan untuk mengurangkan hingar ramalan ke tahap adalah sama dengan jumlah parameter Berkaitan, iaitu, bilangan titik data adalah lebih kurang sama dengan . Dalam kes ini, kira-kira k sampel diperlukan untuk memulakan, tetapi sebaik sahaja anda melakukan ini, anda menghadapi pulangan yang semakin berkurangan, iaitu jika anda memerlukan 90% mata untuk mencapai ketepatan 90%. , Ia memerlukan kira-kira 10 mata tambahan untuk meningkatkan ketepatan kepada 95%. >
Pergantungan berat pada kehilangan, data: Apabila menyesuaikan model dengan data berdimensi tinggi, sebarang butiran kecil boleh membuat perbezaan besar dalam pilihan seperti L1 atau L2 regularizers Apatah lagi menggunakan set data yang berbeza pengoptimum berdimensi tinggi juga sangat berbeza antara satu sama lain Data ini secara relatifnya "naif": biasanya diandaikan bahawa data adalah bebas daripada beberapa sampel Walaupun titik yang hampir dengan sempadan keputusan adalah sukar untuk diklasifikasikan fenomena kepekatan pengukuran dalam dimensi tinggi, boleh dianggap bahawa jarak antara titik data adalah serupa dalam pengedaran data klasik Walau bagaimanapun, model campuran boleh menunjukkan perbezaan ini, jadi tidak seperti masalah lain di atas. perbezaan ini adalah perkara biasa dalam statistik Senario B: Pembelajaran Matematik Dalam senario ini, kami menganggap anda ingin mengajar pelajar matematik (seperti mengira terbitan) melalui beberapa arahan dan latihan senario ini , walaupun tidak ditakrifkan secara formal, mempunyai beberapa ciri kualitatif:Pelajari kemahiran daripada menghampiri taburan statistik: Dalam kes ini, pelajar mempelajari kemahiran dan bukannya anggaran/ramalan daripada sesuatu kuantiti. Khususnya, walaupun fungsi yang memetakan latihan kepada penyelesaian tidak boleh digunakan sebagai "kotak hitam" untuk menyelesaikan tugasan yang tidak diketahui tertentu, model mental yang dibangunkan pelajar semasa menyelesaikan masalah ini masih boleh berguna untuk tugasan yang tidak diketahui. 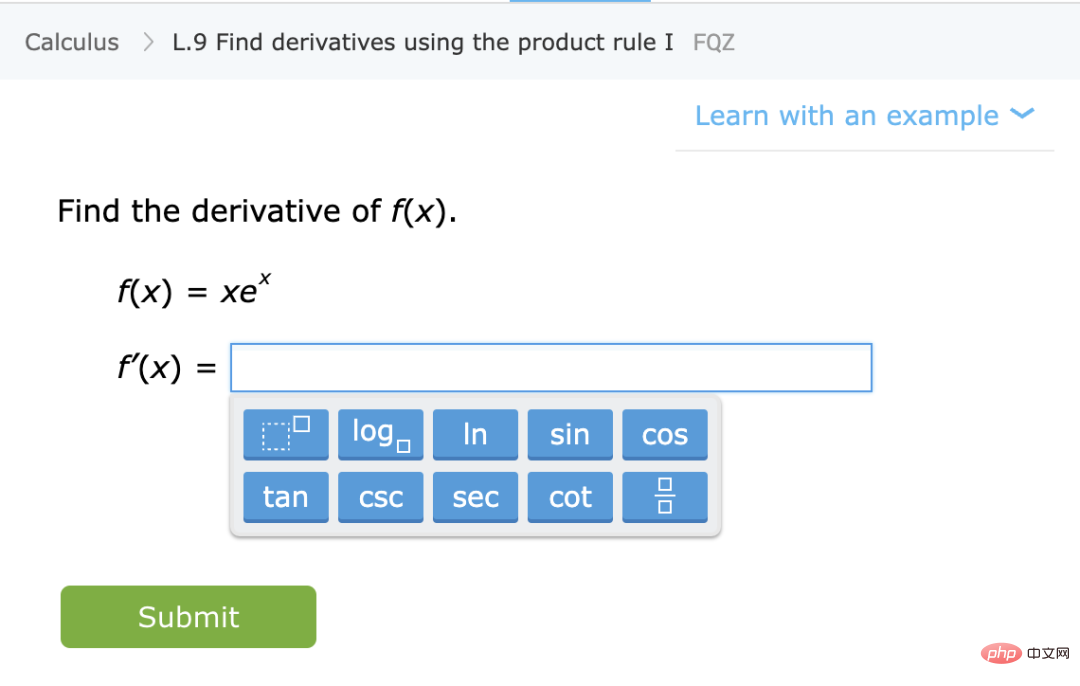
Daripada meningkatkan keupayaan kepada perwakilan automatik: Walaupun terdapat juga pengurangan pulangan kepada penyelesaian masalah dalam beberapa kes, pelajar belajar melalui beberapa peringkat. Terdapat peringkat di mana menyelesaikan beberapa masalah membantu memahami konsep dan membuka kunci kebolehan baharu. Di samping itu, apabila pelajar mengulangi jenis masalah tertentu, mereka akan membentuk proses penyelesaian masalah automatik apabila mereka melihat masalah yang serupa, berubah daripada peningkatan keupayaan sebelumnya kepada penyelesaian masalah automatik.
Prestasi bebas daripada data dan kerugian: Terdapat lebih daripada satu cara untuk mengajar konsep matematik. Pelajar yang belajar menggunakan buku yang berbeza, kaedah pendidikan atau sistem penggredan boleh akhirnya mempelajari kandungan yang sama dan mempunyai kebolehan matematik yang serupa.
Sesetengah masalah lebih sukar: Dalam latihan matematik kita sering melihat perkaitan yang kuat antara cara pelajar berbeza menyelesaikan masalah yang sama. Nampaknya terdapat tahap kesukaran yang wujud untuk masalah, dan perkembangan semula jadi kesukaran yang terbaik untuk pembelajaran.
Pembelajaran mendalam lebih kepada anggaran statistik atau kemahiran belajar pelajar?
Dari dua metafora di atas, yang manakah lebih sesuai untuk menggambarkan pembelajaran mendalam moden? Secara khusus, apakah yang menjadikannya berjaya? Pemasangan model statistik boleh dinyatakan dengan baik menggunakan matematik dan kod. Malah, gelung latihan Pytorch kanonik melatih rangkaian yang mendalam melalui pengurangan risiko empirikal:

Pada tahap yang lebih mendalam, hubungan antara kedua-dua senario ini tidak jelas. Untuk lebih spesifik, berikut adalah tugas pembelajaran khusus sebagai contoh. Pertimbangkan algoritma klasifikasi yang dilatih menggunakan pendekatan "pembelajaran diselia sendiri + pengesanan linear". Latihan algoritma khusus adalah seperti berikut:
1 Andaikan bahawa data ialah urutan, dengan  ialah titik data tertentu (seperti gambar) dan merupakan label.
ialah titik data tertentu (seperti gambar) dan merupakan label.
2. Mula-mula dapatkan rangkaian saraf dalam yang mewakili fungsi 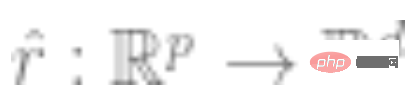 . Fungsi kehilangan yang diselia sendiri dari beberapa jenis dilatih dengan meminimumkannya hanya menggunakan titik data dan bukan label. Contoh fungsi kehilangan tersebut ialah pembinaan semula (memulihkan input dengan input lain) atau pembelajaran kontrastif (idea teras adalah untuk membandingkan sampel positif dan negatif dalam ruang ciri untuk mempelajari perwakilan ciri sampel).
. Fungsi kehilangan yang diselia sendiri dari beberapa jenis dilatih dengan meminimumkannya hanya menggunakan titik data dan bukan label. Contoh fungsi kehilangan tersebut ialah pembinaan semula (memulihkan input dengan input lain) atau pembelajaran kontrastif (idea teras adalah untuk membandingkan sampel positif dan negatif dalam ruang ciri untuk mempelajari perwakilan ciri sampel).
3. Pasangkan pengelas linear 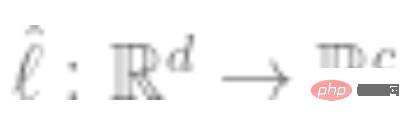 (ialah bilangan kelas) menggunakan data berlabel lengkap untuk meminimumkan kehilangan entropi silang. Pengelas akhir kami ialah:
(ialah bilangan kelas) menggunakan data berlabel lengkap untuk meminimumkan kehilangan entropi silang. Pengelas akhir kami ialah:
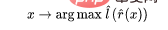
Langkah 3 hanya berfungsi untuk pengelas linear, jadi "keajaiban" berlaku dalam langkah 2 (pembelajaran rangkaian dalam yang diselia sendiri). Terdapat beberapa sifat penting dalam pembelajaran penyeliaan kendiri:
Pelajari kemahiran daripada menghampiri fungsi: Pembelajaran penyeliaan kendiri bukan tentang menghampiri fungsi, tetapi perwakilan pembelajaran yang boleh digunakan untuk pelbagai tugas hiliran (ini adalah paradigma dominan pemprosesan bahasa semula jadi). Mendapatkan tugas hiliran melalui probing linear, penalaan halus atau pengujaan adalah kedua.
Lebih banyak lagi meriah: Dalam pembelajaran penyeliaan kendiri, kualiti perwakilan bertambah baik apabila jumlah data meningkat dan tidak menjadi lebih teruk dengan mencampurkan data daripada beberapa sumber. Malah, lebih pelbagai data, lebih baik.
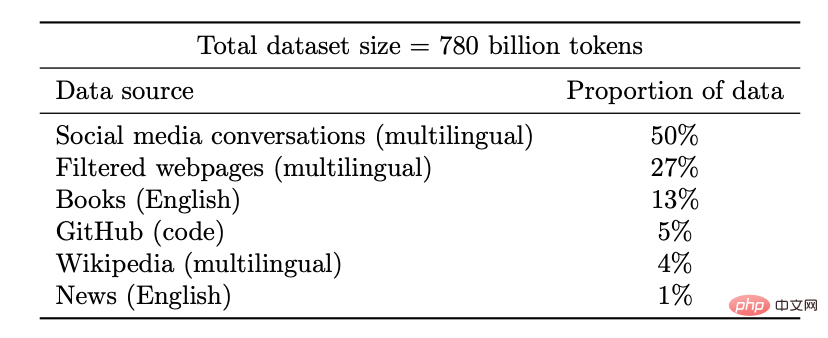
Set data model Coogle PaLM
Membuka kunci keupayaan baharu: Apabila pelaburan sumber (data, pengiraan, saiz model) meningkat, model pembelajaran mendalam juga bertambah baik secara tidak berterusan. Ini juga telah ditunjukkan dalam beberapa persekitaran gabungan.
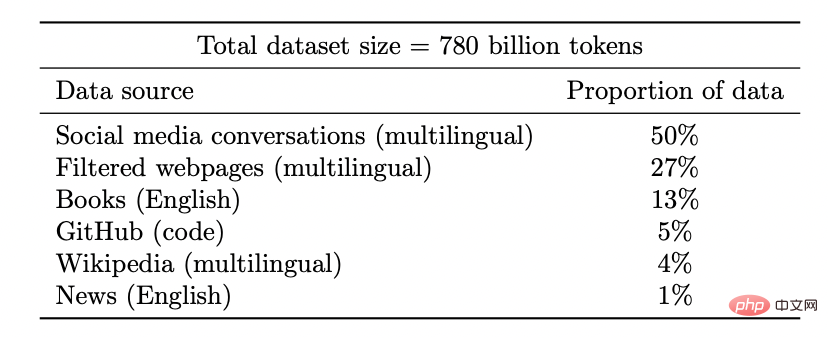
Apabila saiz model bertambah, PaLM menunjukkan peningkatan diskret dalam penanda aras dan membuka kunci ciri yang mengejutkan, seperti menerangkan sebab jenaka itu lucu.
Prestasi hampir bebas daripada kehilangan atau data: terdapat berbilang kerugian yang diselia sendiri, berbilang kontras dan kerugian pembinaan semula sebenarnya digunakan dalam penyelidikan imej, model bahasa menggunakan pembinaan semula satu sisi (meramalkan token seterusnya) atau menggunakan model topeng , ramalkan input topeng dari token kiri dan kanan. Anda juga boleh menggunakan set data yang sedikit berbeza. Ini mungkin menjejaskan kecekapan, tetapi selagi pilihan "munasabah" dibuat, selalunya sumber asal meningkatkan prestasi ramalan lebih daripada kehilangan atau set data khusus yang digunakan.
Sesetengah kes lebih sukar daripada yang lain: perkara ini tidak khusus untuk pembelajaran diselia sendiri. Titik data nampaknya mempunyai beberapa "tahap kesukaran" yang wujud. Sebenarnya, algoritma pembelajaran yang berbeza mempunyai "tahap kemahiran" yang berbeza, dan dian data yang berbeza mempunyai "tahap kesukaran" yang berbeza (kebarangkalian pengelas dengan betul mengelaskan sesuatu mata meningkat secara monoton dengan kemahiran dan menurun secara monoton dengan kesukaran).
Paradigma "kemahiran vs. kesukaran" ialah penjelasan paling jelas tentang fenomena "ketepatan pada baris" yang ditemui oleh Recht et al dan Miller et al. Makalah oleh Kaplen, Ghosh, Garg, dan Nakkiran juga menunjukkan bagaimana input yang berbeza dalam set data mempunyai "profil kesukaran" yang sedia ada yang secara amnya teguh kepada keluarga model yang berbeza.
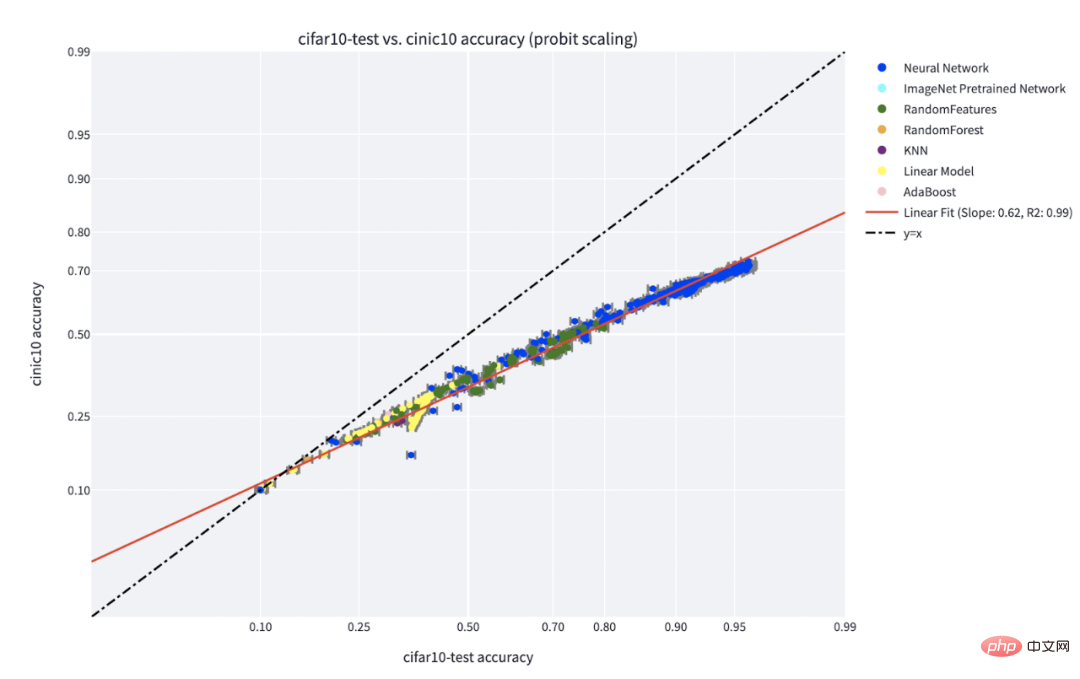
Ketepatan C** pada fenomena talian untuk pengelas yang dilatih pada IFAR-10 dan diuji pada CINIC-10. Sumber angka: https://millerjohnp-linearfits-app-app-ryiwcq.streamlitapp.com/
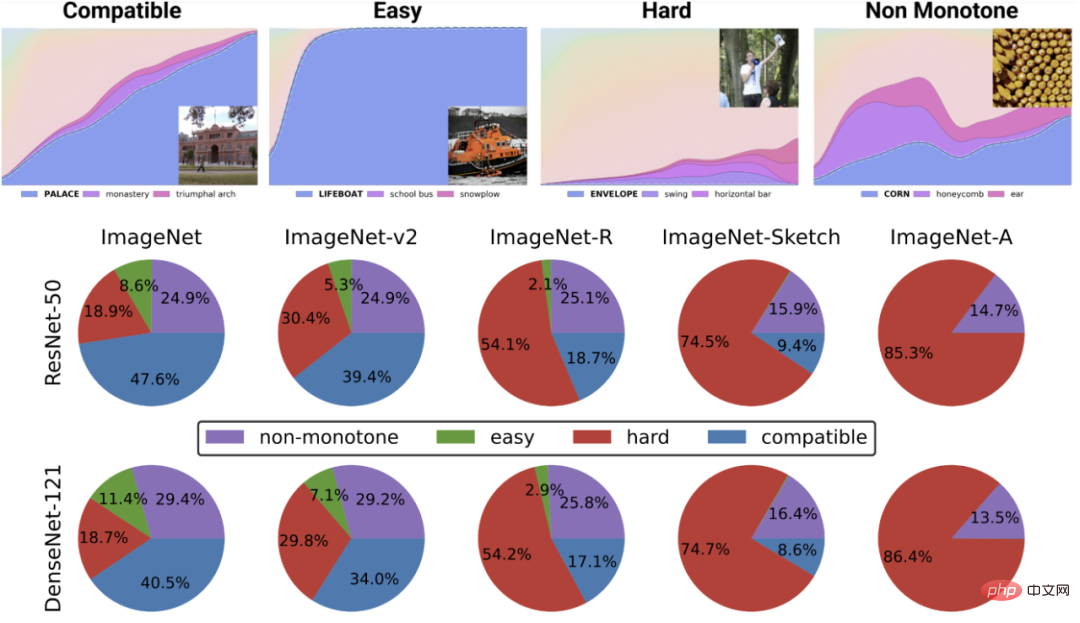
Angka teratas menggambarkan kebarangkalian softmax yang berbeza untuk kelas yang paling berkemungkinan, sebagai Fungsi ketepatan global pengelas untuk kelas yang diindeks mengikut masa latihan. Carta pai bawah menunjukkan penguraian set data yang berbeza kepada jenis titik yang berbeza (perhatikan bahawa penguraian ini adalah serupa untuk struktur saraf yang berbeza).
Latihan ialah pengajaran: Latihan model besar moden kelihatan lebih seperti mengajar pelajar daripada membiarkan model itu sesuai dengan data Apabila pelajar tidak faham atau berasa letih, mereka "berehat" atau mencuba kaedah yang berbeza (latihan perbezaan). Log latihan model besar Meta adalah instruktif - sebagai tambahan kepada isu perkakasan, kami juga boleh melihat campur tangan seperti menukar algoritma pengoptimuman yang berbeza semasa latihan, dan juga mempertimbangkan fungsi pengaktifan "pertukaran panas" (GELU kepada RELU). Yang terakhir tidak masuk akal jika anda menganggap latihan model sebagai sesuai dengan data, dan bukannya mempelajari perwakilan.
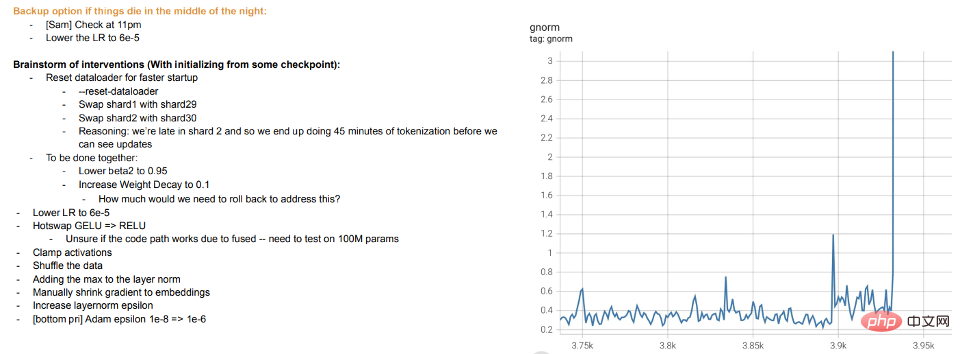
Petikan log latihan meta
4.1 Tetapi bagaimana pula dengan pembelajaran diselia?
Pembelajaran penyeliaan kendiri telah dibincangkan lebih awal, tetapi contoh tipikal pembelajaran mendalam adalah pembelajaran penyeliaan. Lagipun, "Momen ImageNet" pembelajaran mendalam datang daripada ImageNet. Jadi adakah perkara yang dibincangkan di atas masih terpakai pada tetapan ini?
Pertama, kemunculan pembelajaran mendalam berskala besar yang diselia agak tidak disengajakan, hasil daripada ketersediaan set data berlabel yang besar dan berkualiti tinggi (iaitu, ImageNet). Jika anda mempunyai imaginasi yang baik, anda boleh bayangkan sejarah alternatif di mana pembelajaran mendalam mula-mula membuat penemuan dalam pemprosesan bahasa semula jadi melalui pembelajaran tanpa pengawasan, sebelum beralih kepada pembelajaran visi dan diselia.
Kedua, terdapat bukti bahawa pembelajaran seliaan dan pembelajaran seliaan sendiri berkelakuan "secara dalaman" sama walaupun menggunakan fungsi kerugian yang berbeza sama sekali. Kedua-duanya biasanya mencapai prestasi yang sama. Khususnya, bagi setiap satu, seseorang boleh menggabungkan lapisan k pertama bagi model kedalaman d terlatih dengan penyeliaan diri dengan lapisan d-k terakhir model diselia dengan kehilangan prestasi yang sedikit.
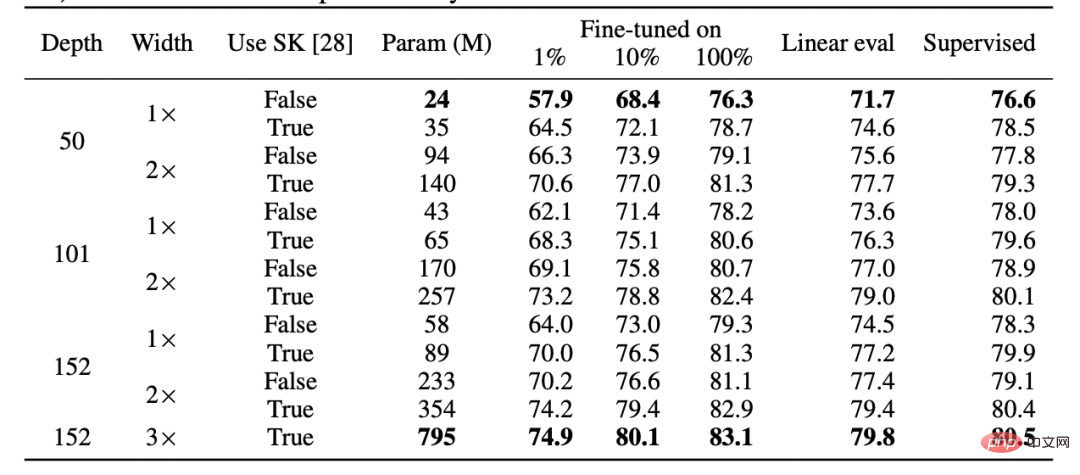
Jadual daripada kertas SimCLR v2. Perhatikan persamaan umum dalam prestasi antara pembelajaran diselia, penalaan halus (100%) penyeliaan sendiri dan pengesanan linear penyeliaan sendiri (Sumber: https://arxiv.org/abs/2006.10029)
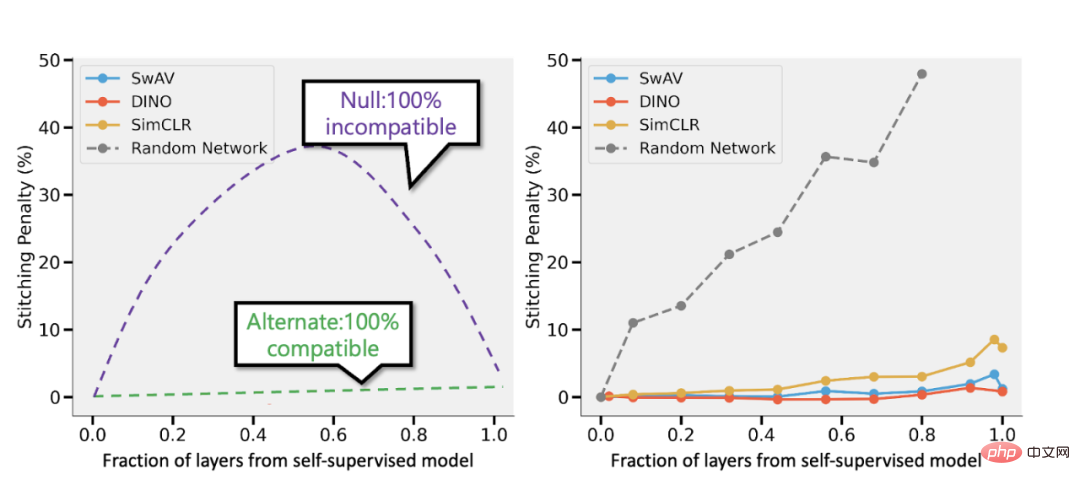
Sambungkan model seliaan sendiri dan model seliaan Bansal et al. (https://arxiv.org/abs/2106.07682). Kiri: Jika ketepatan model penyeliaan sendiri adalah (katakan) 3% lebih rendah daripada model diselia, maka perwakilan yang serasi sepenuhnya akan menghasilkan penalti penyambungan sebanyak p 3% apabila bahagian p lapisan datang daripada penyeliaan sendiri. model. Jika model tidak serasi sepenuhnya, maka kami menjangkakan ketepatan akan menurun secara mendadak apabila lebih banyak model digabungkan. Kanan: Hasil sebenar menggabungkan model yang diselia sendiri yang berbeza.
Kelebihan model penyeliaan sendiri + ringkas ialah model ini boleh menggabungkan pembelajaran ciri atau "sihir pembelajaran mendalam" (dilakukan oleh fungsi perwakilan mendalam) dengan pemasangan model statistik (dilakukan oleh pengelas linear atau "mudah" lain di sini Menunjukkan siap di atas) pemisahan.
Akhirnya, walaupun ini lebih kepada spekulasi, hakikatnya "pembelajaran meta" selalunya seolah-olah disamakan dengan perwakilan pembelajaran (lihat: https://arxiv.org/abs/1909.09157, https: //arxiv .org/abs/2206.03271), yang boleh dilihat sebagai bukti lain bahawa ini sebahagian besarnya dilakukan tanpa mengira matlamat pengoptimuman model.
4.2 Apa yang perlu dilakukan mengenai penparameteran berlebihan?
Artikel ini melangkau perkara yang dianggap sebagai contoh klasik perbezaan antara model pembelajaran statistik dan pembelajaran mendalam dalam amalan: kekurangan "pertukaran Bias-Variance" dan keupayaan model terparameter berlebihan untuk membuat generalisasi baiklah.
Mengapa ponteng? Terdapat dua sebab:
- Pertama sekali, jika pembelajaran penyeliaan sememangnya sama dengan pembelajaran penyeliaan sendiri + mudah, maka ini mungkin menjelaskan keupayaan generalisasinya.
- Kedua, penparameteran berlebihan bukanlah kunci kejayaan pembelajaran mendalam. Apa yang menjadikan rangkaian dalam istimewa bukan kerana ia besar berbanding bilangan sampel, tetapi ia besar secara mutlak. Malah, biasanya dalam pembelajaran tanpa pengawasan/penyeliaan kendiri, model tersebut tidak terlalu diparameterkan. Walaupun untuk model bahasa yang sangat besar, set data mereka lebih besar.

Kertas "deep bootstrap" Nakkiran-Neyshabur-Sadghi menunjukkan bahawa seni bina moden berkelakuan serupa dalam rejim "over-parameterized" atau "under-sampled" ( model dalam Latihan untuk berbilang zaman pada data terhad sehingga terlalu muat: "Dunia Sebenar" dalam rajah di atas), juga dalam keadaan "diparameterkan" atau "dalam talian" (model dilatih untuk satu zaman, dan setiap sampel adalah hanya dilihat sekali: "Dunia Ideal" gambar di atas). Sumber imej: https://arxiv.org/abs/2010.08127
Ringkasan
Pembelajaran statistik sememangnya memainkan peranan dalam pembelajaran mendalam. Walau bagaimanapun, walaupun menggunakan istilah dan kod yang serupa, melihat pembelajaran mendalam sebagai sekadar menyesuaikan model dengan lebih banyak parameter daripada model klasik terlepas banyak perkara yang penting untuk kejayaannya. Metafora untuk mengajar pelajar matematik juga tidak sempurna.
Seperti evolusi biologi, walaupun pembelajaran mendalam mengandungi banyak peraturan yang digunakan semula (seperti keturunan kecerunan dengan kehilangan pengalaman), ia boleh menghasilkan hasil yang sangat kompleks. Nampaknya pada masa yang berbeza, komponen rangkaian yang berbeza mempelajari perkara yang berbeza, termasuk pembelajaran perwakilan, pemasangan ramalan, penyusunan tersirat dan hingar tulen. Penyelidik masih mencari lensa yang sesuai untuk bertanya soalan tentang pembelajaran mendalam, apatah lagi menjawabnya.
Atas ialah kandungan terperinci Belajar = sesuai? Adakah pembelajaran mendalam dan statistik klasik adalah perkara yang sama?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1392
1392
 52
52

 Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Bytedance Cutting melancarkan keahlian super SVIP: 499 yuan untuk langganan tahunan berterusan, menyediakan pelbagai fungsi AI
Jun 28, 2024 am 03:51 AM
Laman web ini melaporkan pada 27 Jun bahawa Jianying ialah perisian penyuntingan video yang dibangunkan oleh FaceMeng Technology, anak syarikat ByteDance Ia bergantung pada platform Douyin dan pada asasnya menghasilkan kandungan video pendek untuk pengguna platform tersebut Windows , MacOS dan sistem pengendalian lain. Jianying secara rasmi mengumumkan peningkatan sistem keahliannya dan melancarkan SVIP baharu, yang merangkumi pelbagai teknologi hitam AI, seperti terjemahan pintar, penonjolan pintar, pembungkusan pintar, sintesis manusia digital, dsb. Dari segi harga, yuran bulanan untuk keratan SVIP ialah 79 yuan, yuran tahunan ialah 599 yuan (nota di laman web ini: bersamaan dengan 49.9 yuan sebulan), langganan bulanan berterusan ialah 59 yuan sebulan, dan langganan tahunan berterusan ialah 499 yuan setahun (bersamaan dengan 41.6 yuan sebulan) . Di samping itu, pegawai yang dipotong juga menyatakan bahawa untuk meningkatkan pengalaman pengguna, mereka yang telah melanggan VIP asal
 Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Pembantu pengekodan AI yang ditambah konteks menggunakan Rag dan Sem-Rag
Jun 10, 2024 am 11:08 AM
Tingkatkan produktiviti, kecekapan dan ketepatan pembangun dengan menggabungkan penjanaan dipertingkatkan semula dan memori semantik ke dalam pembantu pengekodan AI. Diterjemah daripada EnhancingAICodingAssistantswithContextUsingRAGandSEM-RAG, pengarang JanakiramMSV. Walaupun pembantu pengaturcaraan AI asas secara semulajadi membantu, mereka sering gagal memberikan cadangan kod yang paling relevan dan betul kerana mereka bergantung pada pemahaman umum bahasa perisian dan corak penulisan perisian yang paling biasa. Kod yang dijana oleh pembantu pengekodan ini sesuai untuk menyelesaikan masalah yang mereka bertanggungjawab untuk menyelesaikannya, tetapi selalunya tidak mematuhi piawaian pengekodan, konvensyen dan gaya pasukan individu. Ini selalunya menghasilkan cadangan yang perlu diubah suai atau diperhalusi agar kod itu diterima ke dalam aplikasi
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Lima sekolah pembelajaran mesin yang anda tidak tahu
Jun 05, 2024 pm 08:51 PM
Pembelajaran mesin ialah cabang penting kecerdasan buatan yang memberikan komputer keupayaan untuk belajar daripada data dan meningkatkan keupayaan mereka tanpa diprogramkan secara eksplisit. Pembelajaran mesin mempunyai pelbagai aplikasi dalam pelbagai bidang, daripada pengecaman imej dan pemprosesan bahasa semula jadi kepada sistem pengesyoran dan pengesanan penipuan, dan ia mengubah cara hidup kita. Terdapat banyak kaedah dan teori yang berbeza dalam bidang pembelajaran mesin, antaranya lima kaedah yang paling berpengaruh dipanggil "Lima Sekolah Pembelajaran Mesin". Lima sekolah utama ialah sekolah simbolik, sekolah sambungan, sekolah evolusi, sekolah Bayesian dan sekolah analogi. 1. Simbolisme, juga dikenali sebagai simbolisme, menekankan penggunaan simbol untuk penaakulan logik dan ekspresi pengetahuan. Aliran pemikiran ini percaya bahawa pembelajaran adalah proses penolakan terbalik, melalui sedia ada
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 AlphaFold 3 dilancarkan, meramalkan secara menyeluruh interaksi dan struktur protein dan semua molekul hidupan, dengan ketepatan yang jauh lebih tinggi berbanding sebelum ini
Jul 16, 2024 am 12:08 AM
AlphaFold 3 dilancarkan, meramalkan secara menyeluruh interaksi dan struktur protein dan semua molekul hidupan, dengan ketepatan yang jauh lebih tinggi berbanding sebelum ini
Jul 16, 2024 am 12:08 AM
Editor |. Kulit Lobak Sejak pengeluaran AlphaFold2 yang berkuasa pada tahun 2021, saintis telah menggunakan model ramalan struktur protein untuk memetakan pelbagai struktur protein dalam sel, menemui ubat dan melukis "peta kosmik" setiap interaksi protein yang diketahui. Baru-baru ini, Google DeepMind mengeluarkan model AlphaFold3, yang boleh melakukan ramalan struktur bersama untuk kompleks termasuk protein, asid nukleik, molekul kecil, ion dan sisa yang diubah suai. Ketepatan AlphaFold3 telah dipertingkatkan dengan ketara berbanding dengan banyak alat khusus pada masa lalu (interaksi protein-ligan, interaksi asid protein-nukleik, ramalan antibodi-antigen). Ini menunjukkan bahawa dalam satu rangka kerja pembelajaran mendalam yang bersatu, adalah mungkin untuk dicapai
 Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Prestasi SOTA, kaedah AI ramalan pertalian protein-ligan pelbagai mod Xiamen, menggabungkan maklumat permukaan molekul buat kali pertama
Jul 17, 2024 pm 06:37 PM
Editor |. KX Dalam bidang penyelidikan dan pembangunan ubat, meramalkan pertalian pengikatan protein dan ligan dengan tepat dan berkesan adalah penting untuk pemeriksaan dan pengoptimuman ubat. Walau bagaimanapun, kajian semasa tidak mengambil kira peranan penting maklumat permukaan molekul dalam interaksi protein-ligan. Berdasarkan ini, penyelidik dari Universiti Xiamen mencadangkan rangka kerja pengekstrakan ciri berbilang mod (MFE) novel, yang buat pertama kalinya menggabungkan maklumat mengenai permukaan protein, struktur dan jujukan 3D, dan menggunakan mekanisme perhatian silang untuk membandingkan ciri modaliti yang berbeza penjajaran. Keputusan eksperimen menunjukkan bahawa kaedah ini mencapai prestasi terkini dalam meramalkan pertalian mengikat protein-ligan. Tambahan pula, kajian ablasi menunjukkan keberkesanan dan keperluan maklumat permukaan protein dan penjajaran ciri multimodal dalam rangka kerja ini. Penyelidikan berkaitan bermula dengan "S
