
 Peranti teknologi
AI
genius muda Huawei Xie Lingxi: Pandangan peribadi tentang pembangunan bidang pengecaman visual
Peranti teknologi
AI
genius muda Huawei Xie Lingxi: Pandangan peribadi tentang pembangunan bidang pengecaman visual
genius muda Huawei Xie Lingxi: Pandangan peribadi tentang pembangunan bidang pengecaman visual

Baru-baru ini, saya telah menyertai beberapa aktiviti akademik berintensiti tinggi, termasuk seminar tertutup Jawatankuasa Visi Komputer CCF dan persidangan luar talian VALSE. Selepas berkomunikasi dengan cendekiawan lain, saya mendapat banyak idea, dan saya berharap dapat menyusunnya untuk rujukan oleh saya dan rakan-rakan saya. Sudah tentu, terhad oleh tahap peribadi dan skop penyelidikan, pasti akan terdapat banyak ketidaktepatan atau kesilapan dalam artikel Sudah tentu, adalah mustahil untuk merangkumi semua arahan penyelidikan yang penting. Saya berharap dapat berkomunikasi dengan sarjana yang berminat untuk menyempurnakan perspektif ini dan meneroka hala tuju masa depan dengan lebih baik.
Dalam artikel ini, saya akan memberi tumpuan kepada menganalisis kesukaran dan penyelidikan yang berpotensi dalam bidang penglihatan komputer, terutamanya ke arah persepsi visual (iaitu pengecaman) arah. Daripada menambah baik butiran algoritma tertentu, saya lebih suka meneroka batasan dan kesesakan algoritma semasa (terutamanya paradigma pra-latihan + penalaan halus berdasarkan pembelajaran mendalam), dan membuat kesimpulan perkembangan awal daripada ini, termasuk isu yang penting. , isu mana yang tidak penting, arah mana yang layak untuk kemajuan, arah mana yang kurang kos efektif, dsb.
Sebelum saya mulakan, saya lukis peta minda berikut. Untuk mencari titik masuk yang sesuai, saya akan bermula dengan perbezaan antara penglihatan komputer dan pemprosesan bahasa semula jadi (dua hala tuju penyelidikan paling popular dalam kecerdasan buatan), dan memperkenalkan tiga sifat asas isyarat imej: jarang maklumat, kepelbagaian antara domain , butiran tak terhingga, dan sepadan dengan beberapa hala tuju penyelidikan yang penting. Dengan cara ini, kita dapat memahami dengan lebih baik status setiap hala tuju penyelidikan: apakah masalah yang telah diselesaikan dan masalah penting yang belum diselesaikan, dan kemudian menganalisis arah aliran pembangunan masa depan dengan cara yang disasarkan.
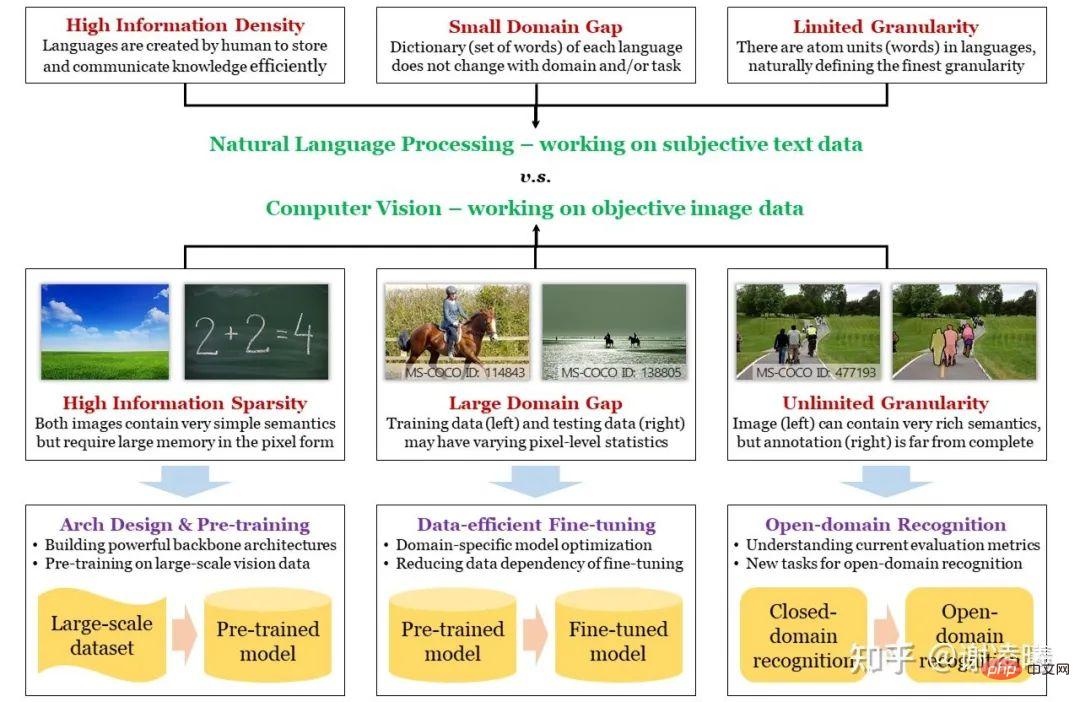
Peta: Perbezaan antara CV dan NLP, tiga cabaran CV utama dan cara menanganinya
Tiga kesukaran asas CV dan arahan penyelidikan yang sepadan
NLP sentiasa mendahului CV. Sama ada rangkaian saraf dalam mengatasi kaedah manual atau model besar yang telah dilatih mula menunjukkan trend penyatuan, perkara ini mula-mula berlaku dalam medan NLP dan tidak lama kemudian dipindahkan ke medan CV. Sebab penting di sini ialah NLP mempunyai titik permulaan yang lebih tinggi: unit asas bahasa semula jadi ialah perkataan, manakala unit asas imej ialah piksel; Secara asasnya, bahasa semula jadi adalah pembawa yang dicipta oleh manusia untuk menyimpan pengetahuan dan menyampaikan maklumat, jadi ia mesti mempunyai ciri-ciri kecekapan tinggi dan ketumpatan maklumat yang tinggi manakala imej adalah isyarat optik yang ditangkap oleh manusia melalui pelbagai sensor, yang boleh secara objektif Ia mencerminkan situasi sebenar, tetapi sewajarnya tidak mempunyai semantik yang kuat dan ketumpatan maklumat mungkin sangat rendah. Dari perspektif lain, ruang imej jauh lebih besar daripada ruang teks, dan struktur ruang juga jauh lebih kompleks. Ini bermakna jika anda ingin mengambil sampel sejumlah besar sampel dalam ruang dan menggunakan data ini untuk mencirikan taburan keseluruhan ruang, data imej sampel akan menjadi banyak tertib magnitud yang lebih besar daripada data teks sampel. Ngomong-ngomong, ini juga merupakan sebab penting mengapa model pra-latihan bahasa semula jadi lebih baik daripada model pra-latihan visual - kami akan menyebutnya kemudian.
Mengikut analisis di atas, kami telah memperkenalkan kesukaran asas pertama CV melalui perbezaan antara CV dan NLP, iaitu sparsity semantik. Dua lagi kesukaran, perbezaan antara domain dan butiran tak terhingga, juga agak berkaitan dengan perbezaan penting yang disebutkan di atas. Ia adalah tepat kerana semantik tidak diambil kira semasa persampelan imej bahawa apabila pensampelan domain yang berbeza (iaitu pengedaran berbeza, seperti siang dan malam, hari cerah dan hujan, dll.), hasil pensampelan (iaitu piksel imej) sangat berkorelasi dengan ciri domain, mengakibatkan perbezaan domain antara. Pada masa yang sama, kerana unit semantik asas imej sukar untuk ditakrifkan (sementara teks mudah ditakrifkan), dan maklumat yang dinyatakan oleh imej itu kaya dan pelbagai, manusia boleh memperoleh maklumat semantik yang hampir tidak terhingga daripada imej itu, jauh melebihi mana-mana medan CV semasa Keupayaan yang ditakrifkan oleh indeks penilaian ini ialah butiran tak terhingga. Mengenai butiran yang tidak terhingga, saya pernah menulis artikel khusus membincangkan isu ini. https://zhuanlan.zhihu.com/p/376145664
Dengan mengambil tiga kesukaran asas di atas sebagai panduan, kami meringkaskan hala tuju penyelidikan industri dalam beberapa tahun kebelakangan ini seperti berikut:
- Semantic sparsity: Penyelesaiannya adalah untuk membina model pengkomputeran yang cekap (rangkaian saraf) dan visual pra-latihan. Logik utama di sini ialah jika anda ingin meningkatkan ketumpatan maklumat data, anda mesti menganggap dan memodelkan pengedaran data yang tidak seragam (teori maklumat) (iaitu, mempelajari pengedaran data sebelumnya). Pada masa ini, terdapat dua jenis kaedah pemodelan yang paling cekap Salah satunya adalah menggunakan reka bentuk seni bina rangkaian saraf untuk menangkap pengedaran terdahulu yang bebas data (contohnya, modul konvolusi sepadan dengan pengedaran sebelumnya data imej tempatan, dan modul pengubah sepadan dengan. data imej sebelum); satu adalah untuk menangkap pengedaran terdahulu yang berkaitan dengan data melalui pra-latihan pada data berskala besar. Kedua-dua hala tuju penyelidikan ini juga merupakan yang paling asas dan paling prihatin dalam bidang pengecaman visual.
- Perbezaan antara domain : Penyelesaiannya ialah algoritma penalaan halus yang cekap data. Menurut analisis di atas, lebih besar saiz rangkaian dan lebih besar set data pra-latihan, lebih kuat sebelum disimpan dalam model pengiraan. Walau bagaimanapun, apabila terdapat perbezaan besar dalam pengagihan data antara domain pra-latihan dan domain sasaran, prior yang kukuh ini akan membawa keburukan, kerana teori maklumat memberitahu kita: meningkatkan ketumpatan maklumat bahagian tertentu (domain pra-latihan) akan pasti Mengurangkan ketumpatan maklumat bahagian lain (bahagian yang tidak termasuk dalam domain pra-latihan, iaitu bahagian yang dianggap tidak penting semasa proses pra-latihan). Pada hakikatnya, berkemungkinan sebahagian atau semua domain sasaran jatuh pada bahagian yang tidak terlibat, mengakibatkan pemindahan langsung yang lemah bagi model pra-latihan (iaitu, overfitting). Pada masa ini, adalah perlu untuk menyesuaikan diri dengan pengedaran data baharu dengan memperhalusi domain sasaran. Memandangkan volum data domain sasaran selalunya jauh lebih kecil daripada domain pra-latihan, kecekapan data adalah andaian penting. Tambahan pula, dari perspektif praktikal, model mesti dapat menyesuaikan diri dengan domain yang berubah-ubah, jadi pembelajaran sepanjang hayat adalah satu kemestian.
- Kebutiran tak terhingga : Penyelesaiannya ialah algoritma pengecaman domain terbuka. Butiran tak terhingga termasuk ciri domain terbuka dan merupakan matlamat mengejar yang lebih tinggi. Penyelidikan ke arah ini masih awal, terutamanya kerana tiada set data pengecaman domain terbuka dan penunjuk penilaian yang diterima umum dalam industri. Salah satu isu yang paling penting di sini ialah cara memperkenalkan keupayaan domain terbuka ke dalam pengecaman visual. Berita baiknya ialah dengan kemunculan kaedah pra-latihan silang modal (terutamanya CLIP pada tahun 2021), bahasa semula jadi semakin hampir untuk menjadi traktor pengiktirafan domain terbuka, saya percaya ini akan menjadi hala tuju arus perdana pada masa hadapan 2-3 tahun. Walau bagaimanapun, saya tidak bersetuju dengan pelbagai tugas pengecaman sifar tembakan yang telah muncul dalam usaha mengejar pengecaman domain terbuka. Saya fikir zero-shot itu sendiri adalah cadangan palsu. Tiada kaedah pengenalan sifar-shot di dunia dan tidak perlu untuk itu. Tugasan sifar pukulan sedia ada semuanya menggunakan kaedah yang berbeza untuk membocorkan maklumat kepada algoritma, dan kaedah kebocoran berbeza secara meluas, menjadikannya sukar untuk membuat perbandingan yang adil antara kaedah yang berbeza. Dalam arah ini, saya mencadangkan kaedah yang dipanggil pengecaman visual atas permintaan untuk mendedahkan dan meneroka butiran pengecaman visual yang tidak terhingga.
Penjelasan tambahan diperlukan di sini. Disebabkan oleh perbezaan dalam saiz ruang data dan kerumitan struktur, sekurang-kurangnya setakat ini, medan CV tidak dapat menyelesaikan masalah perbezaan antara domain secara langsung melalui model pra-terlatih, tetapi medan NLP hampir pada tahap ini. Oleh itu, kita telah melihat sarjana NLP menggunakan kaedah berasaskan segera untuk menyatukan berpuluh-puluh atau beratus-ratus tugas hiliran, tetapi perkara yang sama tidak berlaku dalam bidang CV. Di samping itu, intipati undang-undang penskalaan yang dicadangkan dalam NLP adalah menggunakan model yang lebih besar untuk mengatasi set data pra-latihan. Dalam erti kata lain, untuk NLP, overfitting tidak lagi menjadi masalah, kerana set data pra-latihan dengan gesaan kecil sudah cukup untuk mewakili pengedaran keseluruhan ruang semantik. Walau bagaimanapun, ini belum dicapai dalam bidang CV, jadi migrasi domain juga perlu dipertimbangkan, dan teras penghijrahan domain adalah untuk mengelakkan overfitting. Dalam erti kata lain, dalam 2-3 tahun akan datang, fokus penyelidikan CV dan NLP akan menjadi sangat berbeza. Oleh itu, sangat berbahaya untuk menyalin mod pemikiran mana-mana arah ke arah lain.
Berikut ialah analisis ringkas bagi setiap hala tuju penyelidikan
Arah 1a: Reka bentuk seni bina rangkaian saraf
AlexNet pada tahun 2012 meletakkan asas rangkaian neural dalam dalam bidang CV. Dalam 10 tahun berikutnya (sehingga kini), reka bentuk seni bina rangkaian saraf telah melalui proses daripada reka bentuk manual kepada reka bentuk automatik, dan kembali kepada reka bentuk manual (memperkenalkan modul pengkomputeran yang lebih kompleks):
- 2012-2017, membina rangkaian neural konvolusi yang lebih mendalam secara manual dan meneroka teknik pengoptimuman umum. Kata kunci: ReLU, Dropout, 3x3 convolution, BN, langkau sambungan, dsb. Pada peringkat ini, operasi lilitan ialah unit paling asas, yang sepadan dengan lokaliti sebelum ciri imej.
- 2017-2020, secara automatik membina rangkaian saraf yang lebih kompleks. Antaranya, Carian Seni Bina Rangkaian (NAS) popular buat seketika dan akhirnya ditubuhkan sebagai alat asas. Dalam mana-mana ruang carian tertentu, reka bentuk automatik boleh mencapai hasil yang lebih baik sedikit dan boleh menyesuaikan dengan cepat kepada kos pengiraan yang berbeza.
- Sejak 2020, modul transformer yang berasal daripada NLP telah diperkenalkan ke dalam CV, menggunakan mekanisme perhatian untuk melengkapkan keupayaan pemodelan jarak jauh rangkaian saraf. Hari ini, hasil optimum untuk kebanyakan tugas visual dicapai dengan bantuan seni bina yang termasuk transformer.
Penghakiman saya untuk masa depan ke arah ini adalah seperti berikut:
- Jika tugas pengecaman visual tidak berubah dengan ketara, maka reka bentuk automatik mahupun penambahan modul pengkomputeran yang lebih kompleks tidak akan dapat mendorong CV ke tahap yang lebih tinggi. Kemungkinan perubahan dalam tugas pengecaman visual boleh dibahagikan secara kasar kepada dua bahagian: input dan output. Kemungkinan perubahan dalam bahagian input, seperti kamera acara, boleh mengubah status quo pemprosesan biasa isyarat visual statik atau berurutan dan menimbulkan struktur rangkaian saraf tertentu yang mungkin berubah dalam bahagian output adalah beberapa jenis rangka kerja (arah) itu; menyatukan pelbagai tugas pengiktirafan.
- Jika anda perlu memilih antara lilitan dan pengubah, maka pengubah mempunyai potensi yang lebih besar, terutamanya kerana ia boleh menyatukan modaliti data yang berbeza, terutamanya Ia adalah teks dan imej, dua modaliti yang paling biasa dan penting.
- Kebolehtafsiran ialah hala tuju penyelidikan yang sangat penting, tetapi saya secara peribadi pesimis tentang kebolehtafsiran rangkaian saraf dalam. Kejayaan NLP bukan berdasarkan kebolehtafsiran, tetapi pada overfitting korpora berskala besar. Ini mungkin bukan petanda yang baik untuk AI sebenar.
Arah 1b: Visual pra-latihan
Sebagai topik hangat dalam bidang CV hari ini Ke arah ini, kaedah pra-latihan mempunyai harapan yang tinggi. Dalam era pembelajaran mendalam, pra-latihan visual boleh dibahagikan kepada tiga kategori: diawasi, tidak diawasi dan silang modaliti, yang secara kasarnya diterangkan seperti berikut:
- Diawasi Perkembangan pra-latihan adalah agak jelas. Memandangkan data klasifikasi peringkat imej adalah yang paling mudah diperoleh, lama sebelum tercetusnya pembelajaran mendalam, terdapat set data ImageNet yang akan meletakkan asas untuk pembelajaran mendalam pada masa hadapan, dan ia masih digunakan hari ini. Jumlah set data ImageNet melebihi 15 juta dan tidak diatasi oleh set data tidak terperingkat lain Oleh itu, ia masih merupakan data yang paling biasa digunakan dalam pra-latihan yang diselia. Sebab lain ialah data pengelasan peringkat imej memperkenalkan kurang berat sebelah, yang lebih bermanfaat kepada penghijrahan hiliran - mengurangkan lagi berat sebelah ialah pra-latihan tanpa pengawasan.
- Pra-latihan tanpa pengawasan telah mengalami proses pembangunan yang berliku-liku. Bermula pada tahun 2014, generasi pertama kaedah pra-latihan tanpa pengawasan berdasarkan geometri muncul, seperti menilai berdasarkan hubungan kedudukan tampalan, putaran imej, dsb., dan kaedah generatif juga sentiasa berkembang (kaedah generatif boleh dikesan kembali ke tempoh sebelumnya , yang tidak akan diterangkan di sini). Pada masa ini, kaedah pra-latihan tanpa pengawasan masih jauh lebih lemah daripada kaedah pra-latihan yang diselia. Menjelang 2019, selepas penambahbaikan teknikal, kaedah pembelajaran kontras untuk pertama kalinya menunjukkan potensi untuk mengatasi kaedah pra-latihan yang diselia dalam tugasan hiliran pembelajaran tanpa pengawasan telah benar-benar menjadi tumpuan dunia CV. Bermula pada tahun 2021, kebangkitan transformer visual telah menimbulkan jenis tugas generatif khas, MIM, yang secara beransur-ansur menjadi kaedah dominan.
- Selain pra-latihan yang diselia dan tanpa pengawasan, terdapat juga jenis kaedah di antaranya, iaitu pra-latihan silang modal. Ia menggunakan imej dan teks yang berpasangan lemah sebagai bahan latihan Dalam satu tangan, ia mengelakkan bias yang disebabkan oleh isyarat penyeliaan imej, dan sebaliknya, ia boleh mempelajari semantik yang lemah dengan lebih baik daripada kaedah tanpa pengawasan. Di samping itu, dengan bantuan transformer, integrasi bahasa visual dan semula jadi adalah lebih semula jadi dan munasabah.
Berdasarkan semakan di atas, saya membuat penghakiman berikut:
- Dari sudut aplikasi praktikal, tugas pra-latihan yang berbeza harus digabungkan. Maksudnya, set data bercampur harus dikumpul, yang mengandungi sejumlah kecil data berlabel (label yang lebih kuat seperti pengesanan dan pembahagian), jumlah sederhana data berpasangan teks imej dan sejumlah besar data imej tanpa sebarang label, dan dalam data bercampur tersebut Reka bentuk kaedah pra-latihan secara berpusat.
- Dari bidang CV, pra-latihan tanpa pengawasan adalah hala tuju penyelidikan yang paling mencerminkan intipati visi. Walaupun latihan pra-latihan silang telah membawa impak yang besar kepada keseluruhan hala tuju, saya masih berpendapat bahawa pra-latihan tanpa pengawasan adalah sangat penting dan mesti diteruskan. Perlu ditegaskan bahawa idea pra-latihan visual sebahagian besarnya dipengaruhi oleh pra-latihan bahasa semula jadi, tetapi sifat kedua-duanya berbeza, jadi ia tidak boleh digeneralisasikan. Secara khusus, bahasa semula jadi itu sendiri adalah data yang dicipta oleh manusia, di mana setiap perkataan dan watak ditulis oleh manusia dan secara semula jadi mempunyai makna semantik Oleh itu, dalam erti kata yang ketat, tugas pra-latihan NLP tidak boleh dianggap sebagai Pra-latihan tanpa pengawasan yang sebenar. sebaik-baiknya latihan pra-latihan yang diselia dengan lemah. Tetapi penglihatan adalah berbeza. Isyarat imej adalah data mentah yang wujud secara objektif dan belum diproses oleh manusia. Pendek kata, walaupun latihan pra-modal silang boleh memajukan algoritma visual dalam kejuruteraan dan mencapai hasil pengiktirafan yang lebih baik, masalah penting penglihatan masih perlu diselesaikan oleh penglihatan itu sendiri.
- Pada masa ini, intipati pra-latihan tanpa pengawasan visual tulen adalah untuk belajar daripada kemerosotan. Degradasi di sini merujuk kepada mengalih keluar beberapa maklumat sedia ada daripada isyarat imej, yang memerlukan algoritma untuk memulihkan maklumat ini: kaedah geometri mengeluarkan maklumat pengedaran geometri (seperti kedudukan relatif tampalan kaedah kontras mengeluarkan imej Maklumat keseluruhan (dengan mengekstrak pandangan yang berbeza); ); kaedah penjanaan seperti MIM mengalih keluar maklumat setempat imej. Kaedah berdasarkan degradasi ini mempunyai kesesakan yang tidak dapat diatasi, iaitu konflik antara intensiti degradasi dan konsistensi semantik. Oleh kerana tiada isyarat yang diselia, pembelajaran perwakilan visual bergantung sepenuhnya pada degradasi, jadi degradasi mestilah cukup kuat apabila degradasi cukup kuat, tidak ada jaminan bahawa imej sebelum dan selepas degradasi adalah konsisten dari segi semantik, yang membawa kepada keadaan yang tidak baik; objektif pra-latihan. Sebagai contoh, jika dua pandangan yang diekstrak daripada imej dalam pembelajaran perbandingan tidak mempunyai hubungan, adalah tidak munasabah untuk mendekatkan ciri mereka jika tugas MIM mengalih keluar maklumat utama (seperti muka) dalam imej, adalah tidak munasabah untuk membina semula maklumat ini; . Melengkapkan tugasan ini secara paksa akan memperkenalkan kecenderungan tertentu dan melemahkan keupayaan generalisasi model. Pada masa hadapan, perlu ada tugas pembelajaran yang tidak memerlukan degradasi, dan saya secara peribadi percaya bahawa pembelajaran melalui pemampatan adalah laluan yang boleh dilaksanakan.
Arah 2: Model penalaan halus dan pembelajaran sepanjang hayat
Sebagai asas Masalahnya ialah sejumlah besar tetapan berbeza telah dibangunkan untuk penalaan halus model. Jika anda ingin menyatukan tetapan yang berbeza, anda boleh menganggapnya sebagai mempertimbangkan tiga set data, iaitu set data pra-latihan Dpre (tidak kelihatan), set latihan sasaran Dtrain dan set ujian sasaran Dtest (tidak kelihatan dan tidak dapat diramalkan). Bergantung pada andaian tentang hubungan antara ketiga-tiganya, tetapan yang lebih popular boleh diringkaskan seperti berikut:
- Pembelajaran pemindahan: Anggapkan bahawa pengedaran data Dpre atau Dtrain dan Dtest adalah sangat berbeza; pembelajaran: Andaikan bahawa Dtrain hanya menyediakan maklumat anotasi yang tidak lengkap;
- Belajar dengan bising: Diandaikan bahawa beberapa label data Dtrain mungkin salah; Diandaikan bahawa Dtrain boleh Melabel secara interaktif (memilih sampel yang paling sukar) untuk meningkatkan kecekapan pelabelan; jadi mereka mungkin terlupa semasa proses pembelajaran Apa yang perlu dipelajari daripada Dpre
- ...
- Dalam pengertian umum Seperti yang dinyatakan di atas, adalah sukar untuk mencari rangka kerja bersatu untuk menganalisis pembangunan dan genre kaedah penalaan halus model. Dari perspektif kejuruteraan dan praktikal, kunci kepada penalaan halus model terletak pada pertimbangan terlebih dahulu tentang saiz perbezaan antara domain. Jika anda berpendapat bahawa perbezaan antara Dpre dan Dtrain mungkin sangat besar, anda perlu mengurangkan perkadaran pemberat yang dipindahkan dari rangkaian pra-latihan ke rangkaian sasaran, atau menambah kepala khas untuk menyesuaikan diri dengan perbezaan ini jika anda fikir begitu perbezaan antara Dtrain dan Dtest mungkin sangat besar, anda perlu menambah penyusunan yang lebih kukuh semasa proses penalaan halus untuk mengelakkan overfitting, atau memperkenalkan beberapa statistik dalam talian semasa proses ujian untuk mengimbangi perbezaan sebanyak mungkin. Bagi pelbagai tetapan yang dinyatakan di atas, terdapat sejumlah besar kerja penyelidikan pada setiap satu, yang sangat disasarkan dan tidak akan dibincangkan secara terperinci di sini.
- Berkenaan arah ini, saya rasa ada dua isu penting:
- Dari suasana terpencil kepada perpaduan pembelajaran sepanjang hayat. Daripada akademik kepada industri, kita mesti meninggalkan pemikiran "model penghantaran sekali" dan memahami kandungan penyampaian sebagai rantai alat yang berpusat pada model dan dilengkapi dengan pelbagai fungsi seperti tadbir urus data, penyelenggaraan model dan penggunaan model. Dari segi industri, model atau satu set sistem mesti dijaga sepenuhnya semasa keseluruhan kitaran hayat projek. Ia mesti diambil kira bahawa keperluan pengguna boleh diubah dan tidak dapat diramalkan Hari ini, kamera mungkin ditukar, esok mungkin terdapat jenis sasaran baharu yang akan dikesan, dan sebagainya. Kami tidak mengejar AI untuk dapat menyelesaikan semua masalah secara bebas, tetapi algoritma AI harus mempunyai proses pengendalian yang standard supaya orang yang tidak memahami AI boleh mengikuti proses ini, menambah keperluan yang mereka inginkan dan menyelesaikan masalah yang biasanya mereka hadapi. Hanya dengan cara ini AI Really boleh membawanya kepada orang ramai dan menyelesaikan masalah praktikal. Untuk akademik, adalah perlu untuk menentukan tetapan pembelajaran sepanjang hayat yang konsisten dengan senario sebenar secepat mungkin, mewujudkan penanda aras yang sepadan dan mempromosikan penyelidikan ke arah ini.
- Selesaikan konflik antara data besar dan sampel kecil apabila terdapat perbezaan yang jelas antara domain. Ini adalah satu lagi perbezaan antara CV dan NLP: NLP pada asasnya tidak perlu mempertimbangkan perbezaan antara domain antara tugas pra-latihan dan hiliran, kerana struktur tatabahasa adalah sama dengan perkataan biasa manakala CV mesti menganggap bahawa hulu dan hilir pengagihan data adalah berbeza dengan ketara, supaya huluan Apabila model tidak diperhalusi, ciri asas tidak boleh diekstrak daripada data hiliran (ia ditapis secara langsung oleh unit seperti ReLU). Oleh itu, menggunakan data kecil untuk memperhalusi model besar bukanlah masalah besar dalam medan NLP (arus perdana semasa hanya untuk memperhalusi gesaan), tetapi ia merupakan masalah besar dalam bidang CV. Di sini, mereka bentuk gesaan mesra visual mungkin merupakan arah yang baik, tetapi penyelidikan semasa masih belum mencapai isu teras.
Arah 3: Tugas pengecaman visual berbutir halus tak terhingga
Mengenai Pengecaman visual berbutir halus Infinite (dan konsep serupa) belum mempunyai banyak penyelidikan berkaitan lagi. Oleh itu, saya akan menerangkan isu ini dengan cara saya sendiri. Dalam laporan VALSE tahun ini, saya memberikan penjelasan terperinci tentang kaedah sedia ada dan cadangan kami. Saya memberikan penerangan teks di bawah Untuk penjelasan yang lebih terperinci, sila rujuk artikel khas saya atau laporan yang saya buat di VALSE:
- https://zhuanlan.zhihu.com/p / 546510418https://zhuanlan.zhihu.com/p/555377882
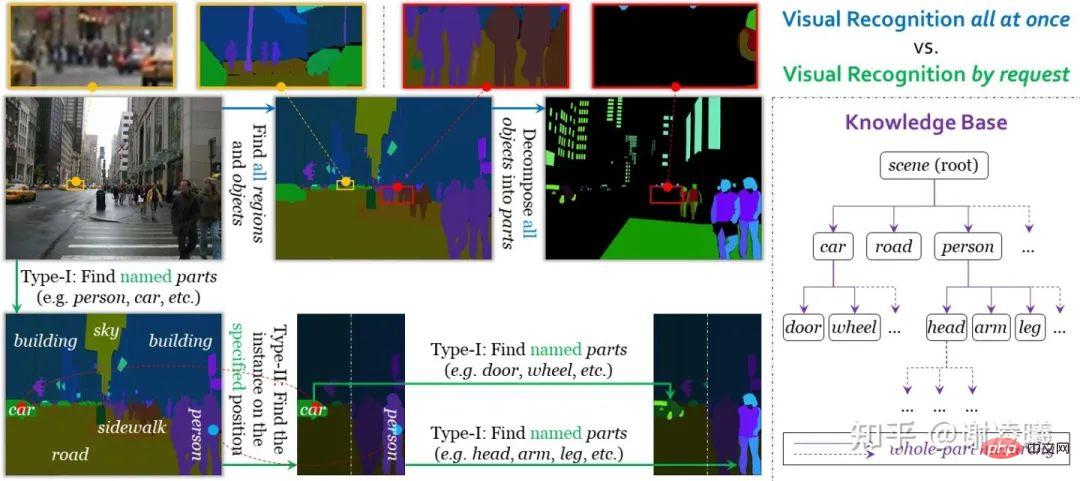
Pertama, saya ingin menerangkan maksud pengecaman visual berbutir halus yang tidak terhingga. Ringkasnya, imej mengandungi maklumat semantik yang sangat kaya tetapi tidak mempunyai unit semantik asas yang jelas. Selagi manusia bersedia, mereka boleh mengenal pasti maklumat semantik yang semakin halus daripada imej (seperti yang ditunjukkan dalam rajah di bawah); Bentuk set data yang lengkap secara semantik untuk pembelajaran algoritma.

Malah set data beranotasi halus seperti ADE20K tidak mempunyai sejumlah besar kandungan semantik yang boleh dikenali oleh manusia
Kami percaya bahawa pengecaman visual yang sangat halus adalah matlamat yang lebih sukar dan lebih penting daripada pengecaman visual domain terbuka. Kami meninjau kaedah pengecaman sedia ada, membahagikannya kepada dua kategori, iaitu kaedah berasaskan klasifikasi dan kaedah dipacu bahasa, dan membincangkan sebab mengapa kaedah tersebut tidak dapat mencapai butiran halus yang tidak terhingga.
- Kaedah berasaskan klasifikasi: Ini termasuk pengelasan, pengesanan, segmentasi dan kaedah lain dalam pengertian tradisional imej Unit semantik asas (imej, kotak, topeng, titik kekunci, dll.) diberikan label kategori. Kecacatan maut kaedah ini ialah apabila butiran pengecaman meningkat, kepastian pengecaman pasti berkurangan, iaitu kebutiran dan kepastian bercanggah. Sebagai contoh, dalam ImageNet, terdapat dua kategori utama: "perabot" dan "perkakas elektrik" jelas "kerusi" milik "perabot" dan "TV" milik "peralatan rumah", tetapi adakah "kerusi urut" milik " perabot" atau "Perkakas rumah", sukar untuk dinilai - ini ialah penurunan kepastian yang disebabkan oleh peningkatan butiran semantik. Jika terdapat "orang" dengan resolusi yang sangat kecil dalam foto itu, dan "kepala" atau pun "mata" "orang" ini dilabel secara paksa, maka penilaian annotator yang berbeza mungkin berbeza tetapi pada masa ini, walaupun ia adalah satu atau dua piksel Sisihan juga akan memberi kesan besar kepada penunjuk seperti IoU - ini ialah penurunan dalam kepastian yang disebabkan oleh peningkatan dalam butiran spatial.
- Kaedah dipacu bahasa: Ini termasuk kaedah kelas gesaan visual yang dipacu oleh CLIP, serta masalah pembumian visual yang lebih lama, dsb. Ciri asasnya adalah menggunakan bahasa untuk merujuk kepada maklumat semantik dalam imej dan mengenal pastinya. Pengenalan bahasa sememangnya telah meningkatkan fleksibiliti pengecaman dan membawa sifat domain terbuka semula jadi. Walau bagaimanapun, bahasa itu sendiri mempunyai keupayaan merujuk yang terhad (bayangkan merujuk kepada individu tertentu dalam adegan dengan ratusan orang) dan tidak dapat memenuhi keperluan pengecaman visual yang sangat halus. Dalam analisis akhir, dalam bidang pengecaman visual, bahasa harus memainkan peranan dalam membantu penglihatan, dan kaedah segera visual yang sedia ada terasa agak memberangsangkan.
Tinjauan di atas memberitahu kita bahawa kaedah pengecaman visual semasa tidak dapat mencapai matlamat butiran halus yang tidak terhingga, dan akan terdapat lebih banyak masalah pada cara untuk berbutir halus yang tidak terhingga menghadapi kesukaran yang tidak dapat diatasi. Oleh itu, kami ingin menganalisis bagaimana orang menyelesaikan masalah ini. Pertama sekali, manusia tidak perlu melakukan tugas pengelasan secara eksplisit dalam kebanyakan kes: kembali kepada contoh di atas, seseorang pergi ke pusat membeli-belah untuk membeli sesuatu, tidak kira sama ada pusat membeli-belah itu meletakkan "kerusi urut" dalam "perabot" bahagian atau bahagian "perkakas rumah" manusia boleh mencari kawasan di mana "kerusi urut" terletak melalui panduan mudah. Kedua, manusia tidak terhad menggunakan bahasa untuk merujuk kepada objek dalam imej Mereka boleh menggunakan kaedah yang lebih fleksibel (seperti menunjuk objek dengan tangan mereka) untuk melengkapkan rujukan dan menjalankan analisis yang lebih terperinci.
Menggabungkan analisis ini, untuk mencapai matlamat kehalusan yang tidak terhingga, tiga syarat berikut mesti dipenuhi.
- Keterbukaan: Pengecaman domain terbuka ialah submatlamat pengecaman terperinci yang tidak terhingga. Pada masa ini, memperkenalkan bahasa adalah salah satu penyelesaian terbaik untuk mencapai keterbukaan.
- Kekhususan: Apabila memperkenalkan bahasa, anda tidak harus terikat dengan bahasa, tetapi harus mereka bentuk skema rujukan yang mesra visual (iaitu tugas pengecaman).
- Butiran boleh ubah: Ia tidak selalu diperlukan untuk mengenali butiran terbaik, tetapi butiran pengecaman boleh diubah secara fleksibel mengikut keperluan.
Di bawah bimbingan tiga syarat ini, kami mereka bentuk tugas pengecaman visual atas permintaan. Berbeza daripada pengecaman visual bersatu dalam pengertian tradisional, pengecaman visual atas permintaan menggunakan permintaan sebagai unit untuk anotasi, pembelajaran dan penilaian. Pada masa ini, sistem menyokong dua jenis permintaan, yang merealisasikan pembahagian daripada contoh ke semantik dan pembahagian daripada semantik ke contoh Oleh itu, gabungan kedua-duanya boleh mencapai pembahagian imej dengan sebarang tahap kehalusan. Faedah lain pengecaman visual atas permintaan ialah berhenti selepas menyelesaikan sebarang bilangan permintaan tidak akan menjejaskan ketepatan anotasi (walaupun sejumlah besar maklumat tidak diberi anotasi), yang bermanfaat kepada kebolehskalaan domain terbuka (seperti menambah kategori Semantik baharu) mempunyai faedah yang besar. Untuk butiran khusus, sila rujuk artikel mengenai pengecaman visual atas permintaan (lihat pautan di atas).
Perbandingan identiti visual bersatu dan identiti visual atas permintaan
Selepas melengkapkan artikel ini, saya masih memikirkan tentang kesan pengecaman visual atas permintaan pada arah lain. Dua perspektif disediakan di sini:
- Permintaan dalam pengecaman visual atas permintaan pada dasarnya adalah gesaan yang mesra visual. Ia bukan sahaja dapat mencapai tujuan menyoal siasat model visual, tetapi juga mengelakkan kekaburan rujukan yang disebabkan oleh gesaan bahasa tulen. Memandangkan lebih banyak jenis permintaan diperkenalkan, sistem ini dijangka menjadi lebih matang.
- Pengecaman visual atas permintaan memberikan kemungkinan untuk menyatukan pelbagai tugas visual secara rasmi. Contohnya, tugas seperti pengelasan, pengesanan dan pembahagian disatukan di bawah rangka kerja ini. Ini boleh membawa inspirasi kepada pra-latihan visual. Pada masa ini, sempadan antara pra-latihan visual dan penalaan halus hiliran masih tidak jelas sama ada model pra-latihan harus sesuai untuk tugasan yang berbeza atau memberi tumpuan kepada penambahbaikan tugasan tertentu. Walau bagaimanapun, jika tugas pengiktirafan bersatu secara rasmi muncul, maka perdebatan ini mungkin tidak lagi relevan. Dengan cara ini, penyatuan rasmi tugas hiliran juga merupakan kelebihan utama yang dinikmati oleh bidang NLP.
Di luar arahan di atas
Saya membahagikan masalah dalam bidang CV kepada tiga kategori utama: pengiktirafan, penjanaan, interaksi, Pengenalan adalah yang paling mudah daripada kesemuanya. Mengenai ketiga-tiga sub-bidang ini, analisis ringkas adalah seperti berikut:
- Dalam bidang pengiktirafan, penunjuk pengiktirafan tradisional jelas ketinggalan zaman, jadi orang ramai memerlukan penunjuk penilaian yang lebih baharu. Pada masa ini, pengenalan bahasa semula jadi ke dalam pengecaman visual adalah trend yang jelas dan tidak dapat dipulihkan, tetapi ini masih jauh dari mencukupi. Industri memerlukan lebih banyak inovasi pada tahap tugas.
- Generasi ialah keupayaan yang lebih maju daripada pengiktirafan. Manusia boleh dengan mudah mengenali pelbagai objek biasa, tetapi hanya sedikit yang boleh melukis objek realistik. Daripada bahasa pembelajaran statistik, ini adalah kerana model generatif perlu memodelkan taburan bersama p(x,y), manakala model diskriminasi hanya perlu memodelkan taburan bersyarat p(y|x): yang pertama boleh memperoleh Yang terakhir. tidak boleh diperolehi daripada yang kedua, tetapi yang pertama tidak boleh diperolehi daripada yang kedua. Berdasarkan perkembangan industri, walaupun kualiti penjanaan imej terus bertambah baik, kestabilan dan kebolehkawalan kandungan yang dihasilkan (tanpa menghasilkan kandungan yang jelas tidak nyata) masih perlu dipertingkatkan. Pada masa yang sama, kandungan yang dijana masih agak lemah dalam membantu algoritma pengecaman, dan sukar untuk orang ramai menggunakan sepenuhnya data maya dan data sintetik untuk mencapai hasil yang setanding dengan latihan data sebenar. Untuk kedua-dua isu ini, pandangan kami ialah kami perlu mereka bentuk penunjuk penilaian yang lebih baik dan lebih penting untuk menggantikan penunjuk sedia ada (menggantikan FID, IS, dll. untuk tugas penjanaan, manakala tugas penjanaan dan pengenalan perlu digabungkan untuk menentukan indeks penilaian bersatu).
- Pada tahun 1978, perintis visi komputer David Marr membayangkan bahawa fungsi utama penglihatan adalah untuk membina model tiga dimensi persekitaran dan mempelajari pengetahuan melalui interaksi. Berbanding dengan pengiktirafan dan penjanaan, interaksi lebih dekat dengan pembelajaran manusia, tetapi terdapat sedikit kajian dalam industri. Kesukaran utama dalam penyelidikan tentang interaksi terletak pada membina persekitaran interaksi sebenar - tepatnya, kaedah pembinaan semasa set data visual datang daripada pensampelan jarang persekitaran, tetapi interaksi memerlukan pensampelan berterusan. Jelas sekali, untuk menyelesaikan masalah penting penglihatan, interaksi adalah intipati. Walaupun terdapat banyak kajian berkaitan dalam industri (seperti kecerdasan yang terkandung), tiada matlamat pembelajaran yang didorong oleh tugas yang universal belum muncul. Kami sekali lagi mengulangi idea yang dikemukakan oleh perintis visi komputer David Marr: fungsi utama penglihatan adalah untuk membina model tiga dimensi persekitaran dan mempelajari pengetahuan melalui interaksi. Penglihatan komputer, termasuk arah AI yang lain, harus berkembang ke arah ini untuk menjadi benar-benar praktikal.
Ringkasnya, dalam sub-bidang yang berbeza, percubaan untuk bergantung semata-mata pada pembelajaran statistik (terutamanya pembelajaran mendalam) untuk mencapai keupayaan penyesuaian yang kukuh telah dicapai. had hasil. Pembangunan masa depan mesti berdasarkan pemahaman CV yang lebih penting, dan mewujudkan penunjuk penilaian yang lebih munasabah untuk pelbagai tugas adalah langkah pertama yang perlu kita ambil.
Kesimpulan
Selepas beberapa pertukaran akademik yang intensif, saya dapat merasakan dengan jelas kekeliruan dalam industri, sekurang-kurangnya untuk persepsi visual (pengiktirafan) Dalam am, semakin kurang soalan penyelidikan yang menarik dan bernilai, dan ambang semakin tinggi. Jika ini berterusan, ada kemungkinan dalam masa terdekat, penyelidikan CV akan mengambil laluan NLP dan secara beransur-ansur membahagikan kepada dua kategori:
Satu kategori menggunakan besar jumlah pengiraan Sumber telah dilatih dan sentiasa menyegarkan SOTA dengan sia-sia; Ini jelas bukan perkara yang baik untuk bidang CV. Untuk mengelakkan perkara seperti ini, selain sentiasa meneroka sifat penglihatan dan mencipta petunjuk penilaian yang lebih bernilai, industri juga perlu meningkatkan toleransi, terutamanya toleransi untuk arah bukan arus perdana Jangan mengeluh tentang keseragaman penyelidikan pada masa yang sama mengeluh tentang kehomogenan penyelidikan yang tidak mencapai SOTA adalah sakit di pantat. Kesesakan semasa adalah cabaran yang dihadapi oleh semua orang Jika pembangunan AI terbantut, tiada siapa yang boleh kebal. Terima kasih kerana menonton sehingga habis. Perbincangan mesra dialu-alukan.
Kenyataan Pengarang
Semua kandungan hanya mewakili pandangan pengarang sendiri dan boleh dibatalkan cetakan semula sekunder mesti disertakan dengan pernyataan tersebut. Terima kasih!

Atas ialah kandungan terperinci genius muda Huawei Xie Lingxi: Pandangan peribadi tentang pembangunan bidang pengecaman visual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Perbezaan antara algoritma pengesanan sasaran satu peringkat dan dwi peringkat
Jan 23, 2024 pm 01:48 PM
Perbezaan antara algoritma pengesanan sasaran satu peringkat dan dwi peringkat
Jan 23, 2024 pm 01:48 PM
Pengesanan objek adalah tugas penting dalam bidang penglihatan komputer, digunakan untuk mengenal pasti objek dalam imej atau video dan mencari lokasinya. Tugasan ini biasanya dibahagikan kepada dua kategori algoritma, satu peringkat dan dua peringkat, yang berbeza dari segi ketepatan dan keteguhan. Algoritma pengesanan sasaran satu peringkat Algoritma pengesanan sasaran satu peringkat menukarkan pengesanan sasaran kepada masalah klasifikasi Kelebihannya ialah ia pantas dan boleh menyelesaikan pengesanan hanya dalam satu langkah. Walau bagaimanapun, disebabkan terlalu memudahkan, ketepatan biasanya tidak sebaik algoritma pengesanan objek dua peringkat. Algoritma pengesanan sasaran satu peringkat biasa termasuk YOLO, SSD dan FasterR-CNN. Algoritma ini biasanya mengambil keseluruhan imej sebagai input dan menjalankan pengelas untuk mengenal pasti objek sasaran. Tidak seperti algoritma pengesanan sasaran dua peringkat tradisional, mereka tidak perlu menentukan kawasan terlebih dahulu, tetapi meramalkan secara langsung
 Cara menggunakan teknologi AI untuk memulihkan foto lama (dengan contoh dan analisis kod)
Jan 24, 2024 pm 09:57 PM
Cara menggunakan teknologi AI untuk memulihkan foto lama (dengan contoh dan analisis kod)
Jan 24, 2024 pm 09:57 PM
Pemulihan foto lama ialah kaedah menggunakan teknologi kecerdasan buatan untuk membaiki, menambah baik dan menambah baik foto lama. Menggunakan penglihatan komputer dan algoritma pembelajaran mesin, teknologi ini secara automatik boleh mengenal pasti dan membaiki kerosakan dan kecacatan pada foto lama, menjadikannya kelihatan lebih jelas, lebih semula jadi dan lebih realistik. Prinsip teknikal pemulihan foto lama terutamanya merangkumi aspek-aspek berikut: 1. Penyahnosian dan penambahbaikan imej Apabila memulihkan foto lama, foto itu perlu dibunyikan dan dipertingkatkan terlebih dahulu. Algoritma dan penapis pemprosesan imej, seperti penapisan min, penapisan Gaussian, penapisan dua hala, dsb., boleh digunakan untuk menyelesaikan masalah bunyi dan bintik warna, dengan itu meningkatkan kualiti foto. 2. Pemulihan dan pembaikan imej Dalam foto lama, mungkin terdapat beberapa kecacatan dan kerosakan, seperti calar, retak, pudar, dsb. Masalah ini boleh diselesaikan dengan algoritma pemulihan dan pembaikan imej
 Aplikasi teknologi AI dalam pembinaan semula resolusi super imej
Jan 23, 2024 am 08:06 AM
Aplikasi teknologi AI dalam pembinaan semula resolusi super imej
Jan 23, 2024 am 08:06 AM
Pembinaan semula imej resolusi super ialah proses menjana imej resolusi tinggi daripada imej resolusi rendah menggunakan teknik pembelajaran mendalam seperti rangkaian neural convolutional (CNN) dan rangkaian adversarial generatif (GAN). Matlamat kaedah ini adalah untuk meningkatkan kualiti dan perincian imej dengan menukar imej resolusi rendah kepada imej resolusi tinggi. Teknologi ini mempunyai aplikasi yang luas dalam banyak bidang, seperti pengimejan perubatan, kamera pengawasan, imej satelit, dsb. Melalui pembinaan semula imej resolusi super, kami boleh mendapatkan imej yang lebih jelas dan terperinci, membantu menganalisis dan mengenal pasti sasaran dan ciri dalam imej dengan lebih tepat. Kaedah pembinaan semula Kaedah pembinaan semula imej resolusi super secara amnya boleh dibahagikan kepada dua kategori: kaedah berasaskan interpolasi dan kaedah berasaskan pembelajaran mendalam. 1) Kaedah berasaskan interpolasi Pembinaan semula imej resolusi super berdasarkan interpolasi
 Algoritma Ciri Invarian Skala (SIFT).
Jan 22, 2024 pm 05:09 PM
Algoritma Ciri Invarian Skala (SIFT).
Jan 22, 2024 pm 05:09 PM
Algoritma Scale Invariant Feature Transform (SIFT) ialah algoritma pengekstrakan ciri yang digunakan dalam bidang pemprosesan imej dan penglihatan komputer. Algoritma ini telah dicadangkan pada tahun 1999 untuk meningkatkan pengecaman objek dan prestasi pemadanan dalam sistem penglihatan komputer. Algoritma SIFT adalah teguh dan tepat dan digunakan secara meluas dalam pengecaman imej, pembinaan semula tiga dimensi, pengesanan sasaran, penjejakan video dan medan lain. Ia mencapai invarian skala dengan mengesan titik utama dalam ruang skala berbilang dan mengekstrak deskriptor ciri tempatan di sekitar titik utama. Langkah-langkah utama algoritma SIFT termasuk pembinaan ruang skala, pengesanan titik utama, kedudukan titik utama, penetapan arah dan penjanaan deskriptor ciri. Melalui langkah-langkah ini, algoritma SIFT boleh mengekstrak ciri yang teguh dan unik, dengan itu mencapai pemprosesan imej yang cekap.
 Tafsiran konsep pengesanan sasaran dalam penglihatan komputer
Jan 24, 2024 pm 03:18 PM
Tafsiran konsep pengesanan sasaran dalam penglihatan komputer
Jan 24, 2024 pm 03:18 PM
Penjejakan objek ialah tugas penting dalam penglihatan komputer dan digunakan secara meluas dalam pemantauan trafik, robotik, pengimejan perubatan, pengesanan kenderaan automatik dan bidang lain. Ia menggunakan kaedah pembelajaran mendalam untuk meramal atau menganggarkan kedudukan objek sasaran dalam setiap bingkai berturut-turut dalam video selepas menentukan kedudukan awal objek sasaran. Penjejakan objek mempunyai pelbagai aplikasi dalam kehidupan sebenar dan sangat penting dalam bidang penglihatan komputer. Penjejakan objek biasanya melibatkan proses pengesanan objek. Berikut ialah gambaran ringkas tentang langkah-langkah pengesanan objek: 1. Pengesanan objek, di mana algoritma mengelaskan dan mengesan objek dengan mencipta kotak sempadan di sekelilingnya. 2. Berikan pengenalan unik (ID) kepada setiap objek. 3. Jejaki pergerakan objek yang dikesan dalam bingkai sambil menyimpan maklumat yang berkaitan. Jenis Sasaran Penjejakan Sasaran
 Pengenalan kepada kaedah anotasi imej dan senario aplikasi biasa
Jan 22, 2024 pm 07:57 PM
Pengenalan kepada kaedah anotasi imej dan senario aplikasi biasa
Jan 22, 2024 pm 07:57 PM
Dalam bidang pembelajaran mesin dan penglihatan komputer, anotasi imej ialah proses menggunakan anotasi manusia pada set data imej. Kaedah anotasi imej boleh dibahagikan terutamanya kepada dua kategori: anotasi manual dan anotasi automatik. Anotasi manual bermaksud anotasi manusia menganotasi imej melalui operasi manual. Kaedah ini memerlukan anotasi manusia untuk mempunyai pengetahuan dan pengalaman profesional serta dapat mengenal pasti dan menganotasi objek sasaran, adegan atau ciri dalam imej dengan tepat. Kelebihan anotasi manual ialah hasil anotasi boleh dipercayai dan tepat, tetapi kelemahannya ialah ia memakan masa dan kos yang tinggi. Anotasi automatik merujuk kepada kaedah menggunakan program komputer untuk menganotasi imej secara automatik. Kaedah ini menggunakan pembelajaran mesin dan teknologi penglihatan komputer untuk mencapai anotasi automatik oleh model latihan. Kelebihan pelabelan automatik adalah kelajuan pantas dan kos rendah, tetapi kelemahannya ialah keputusan pelabelan mungkin tidak tepat.
 Contoh aplikasi praktikal gabungan ciri cetek dan ciri mendalam
Jan 22, 2024 pm 05:00 PM
Contoh aplikasi praktikal gabungan ciri cetek dan ciri mendalam
Jan 22, 2024 pm 05:00 PM
Pembelajaran mendalam telah mencapai kejayaan besar dalam bidang penglihatan komputer, dan salah satu kemajuan penting ialah penggunaan rangkaian neural convolutional dalam (CNN) untuk klasifikasi imej. Walau bagaimanapun, CNN dalam biasanya memerlukan sejumlah besar data berlabel dan sumber pengkomputeran. Untuk mengurangkan permintaan untuk sumber pengiraan dan data berlabel, penyelidik mula mengkaji cara menggabungkan ciri cetek dan ciri mendalam untuk meningkatkan prestasi klasifikasi imej. Kaedah gabungan ini boleh mengambil kesempatan daripada kecekapan pengiraan yang tinggi bagi ciri cetek dan keupayaan perwakilan yang kuat bagi ciri mendalam. Dengan menggabungkan kedua-duanya, kos pengiraan dan keperluan pelabelan data boleh dikurangkan sambil mengekalkan ketepatan klasifikasi yang tinggi. Kaedah ini amat penting untuk senario aplikasi di mana jumlah data adalah kecil atau sumber pengkomputeran adalah terhad. Dengan kajian mendalam tentang kaedah gabungan ciri cetek dan ciri mendalam, kita boleh lebih lanjut
 Fahami definisi dan kefungsian model terbenam
Jan 24, 2024 pm 05:57 PM
Fahami definisi dan kefungsian model terbenam
Jan 24, 2024 pm 05:57 PM
Embedding ialah model pembelajaran mesin yang digunakan secara meluas dalam bidang seperti pemprosesan bahasa semula jadi (NLP) dan penglihatan komputer (CV). Fungsi utamanya adalah untuk mengubah data berdimensi tinggi kepada ruang benam berdimensi rendah sambil mengekalkan ciri dan maklumat semantik data asal, dengan itu meningkatkan kecekapan dan ketepatan model. Model terbenam boleh memetakan data yang serupa dengan ruang benam yang serupa dengan mempelajari korelasi antara data, supaya model dapat memahami dan memproses data dengan lebih baik. Prinsip model terbenam adalah berdasarkan idea perwakilan yang diedarkan, yang mengodkan maklumat semantik data ke dalam ruang vektor dengan mewakili setiap titik data sebagai vektor. Kelebihan ini ialah anda boleh memanfaatkan sifat ruang vektor Sebagai contoh, jarak antara vektor boleh
