

Contoh analisis prinsip penciptaan indeks MySQL

1 Sesuai untuk mencipta indeks
1. Nilai medan mempunyai sekatan keunikan
Menurut spesifikasi Alibaba, ia menunjukkan bahawa. terdapat keperluan perniagaan Medan dengan ciri unik, walaupun medan gabungan, mesti diindeks secara unik.

Contohnya, nombor pelajar dalam jadual pelajar ialah medan unik Mencipta indeks unik untuk medan ini boleh menanyakan maklumat pelajar tertentu Jika anda menggunakan nama Jika ya, mungkin terdapat kes dengan nama yang sama, yang akan memperlahankan kelajuan pertanyaan.
2 Medan yang kerap digunakan sebagai syarat pertanyaan Where
Medan tertentu sering digunakan dalam keadaan Where pada pernyataan Pilih, jadi anda perlu mencipta indeks untuk medan ini, terutamanya jika jumlah data adalah besar Dalam kes ini, mencipta indeks biasa boleh meningkatkan kecekapan pertanyaan.
Contohnya, jadual ujian student_info mempunyai 1 juta data Andaikan maklumat pengguna student_id=112322 disoal Jika tiada indeks dibuat pada medan student_id, hasil pertanyaan adalah seperti berikut:
select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费211ms
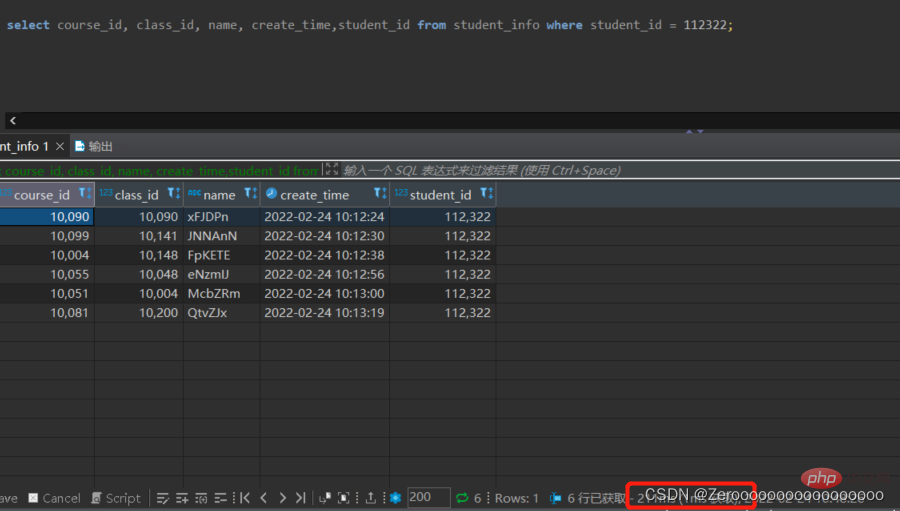
Selepas mencipta indeks untuk student_id, hasil pertanyaan adalah seperti berikut:
alter table student_info add index idx_sid(student_id); select course_id, class_id, name, create_time,student_id from student_info where student_id = 112322;# 花费3ms
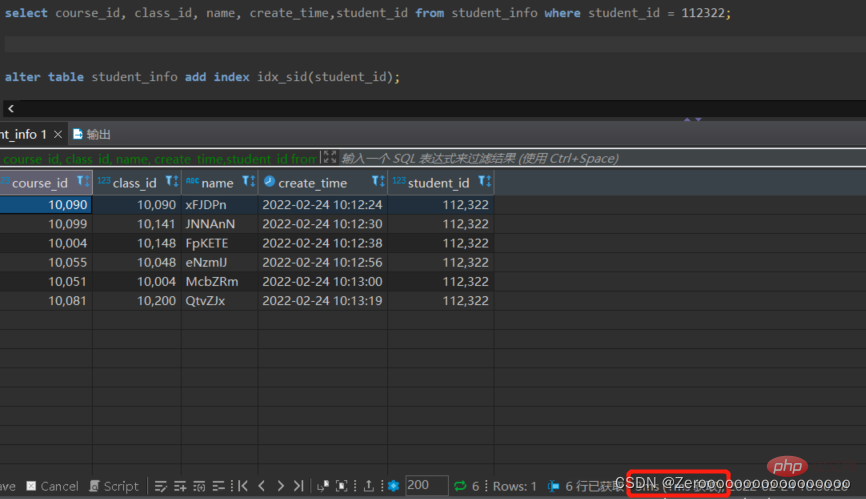
3 lajur yang selalunya Kumpulan mengikut dan Susun mengikut
Indeksnya ialah Biarkan data disimpan atau diambil dalam susunan tertentu, jadi apabila anda menggunakan Kumpulan mengikut untuk mengumpulkan data atau menggunakan Susun mengikut untuk mengisih data, anda perlu mengindeks medan yang dikumpulkan atau diisih. Jika terdapat berbilang lajur untuk diisih, indeks gabungan boleh dibina pada lajur ini.
Contohnya, kumpulkan kursus yang dipilih oleh pelajar mengikut student_id, paparkan student_id yang berbeza dan bilangan kursus, dan paparkan 100 item. Jika anda tidak membuat indeks untuk student_id, keputusan pertanyaan adalah seperti berikut:
select student_id,count(*) as num from student_info group by student_id limit 100;#花费2.466s
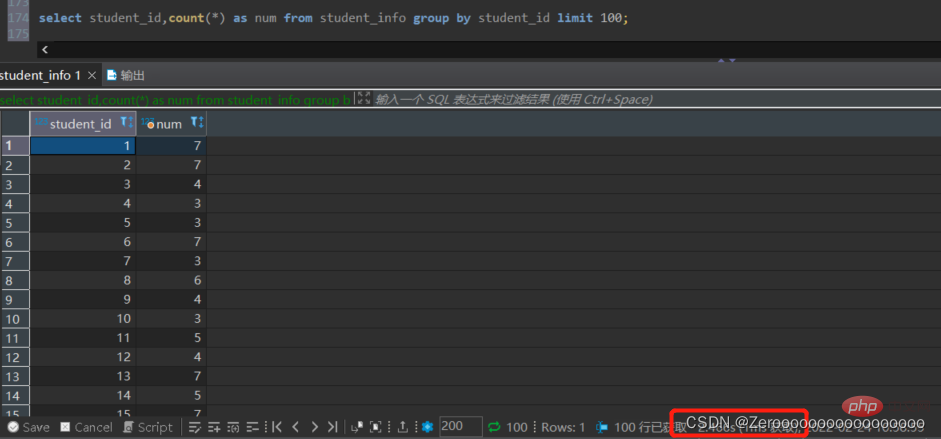
Selepas mencipta indeks untuk student_id, hasil pertanyaan adalah seperti berikut:
alter table student_info add index idx_sid(student_id); select student_id,count(*) as num from student_info group by student_id limit 100;#花费6ms
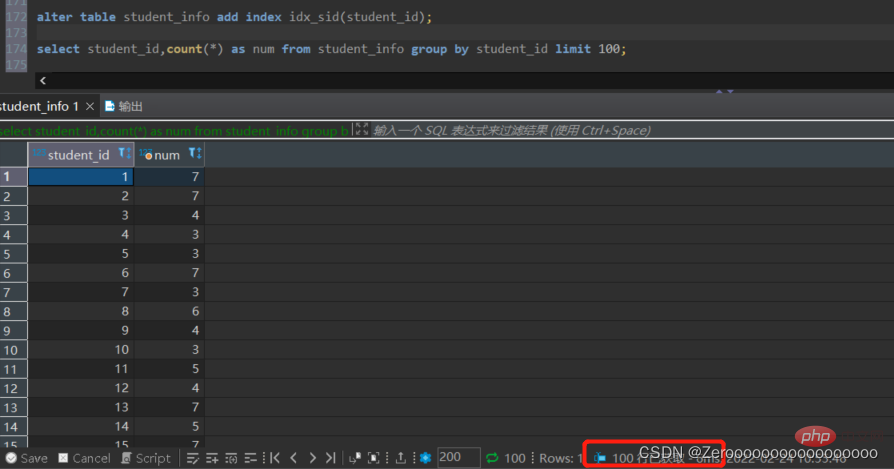
Untuk pernyataan pertanyaan yang merangkumi kedua-dua kumpulan mengikut dan susunan mengikut, adalah disyorkan untuk mencipta indeks bersama dan meletakkan medan dalam kumpulan oleh di hadapan susunan mengikut medan untuk memenuhi ‘prinsip Padanan awalan paling kiri', supaya kadar penggunaan indeks akan tinggi, dan kecekapan pertanyaan semula jadi akan tinggi pada masa yang sama, versi selepas 8.0 menyokong indeks menurun medan selepas tertib mengikut adalah dalam tertib menurun, anda boleh mempertimbangkan terus membuat indeks menurun, atau Akan meningkatkan kecekapan pertanyaan.
4 lajur keadaan Di mana Kemas kini dan Padam
Soal data mengikut syarat tertentu dan kemudian lakukan operasi Kemas Kini atau Padam Jika indeks dibuat untuk medan Di mana , Boleh membalas untuk meningkatkan kecekapan. Sebabnya ialah rekod ini perlu diambil semula berdasarkan lajur keadaan Where dahulu, dan kemudian dikemas kini atau dipadamkan. Jika medan yang dikemas kini adalah medan bukan indeks semasa mengemas kini, peningkatan kecekapan akan menjadi lebih jelas Ini kerana kemas kini medan indeks tidak memerlukan penyelenggaraan.
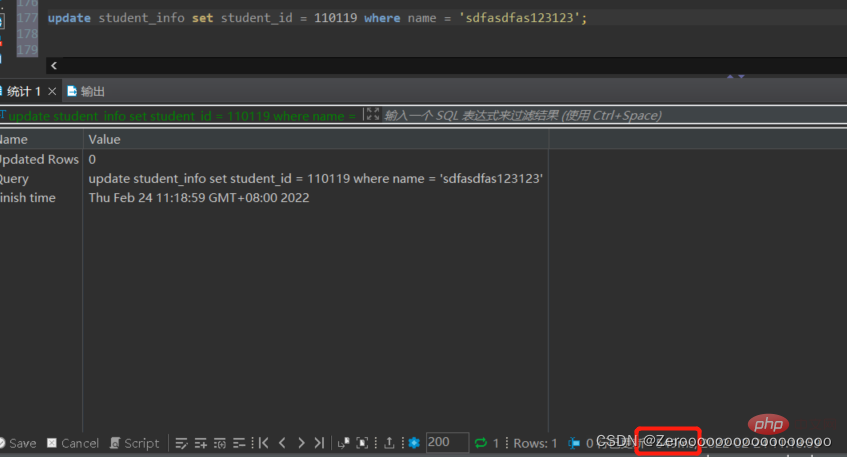
Contohnya, jika medan nama dalam jadual student_info ialah sdfasdfas123123, student_id diubah suai kepada 110119. Tanpa mengindeks medan nama, situasi pelaksanaan adalah seperti berikut:
update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费549ms
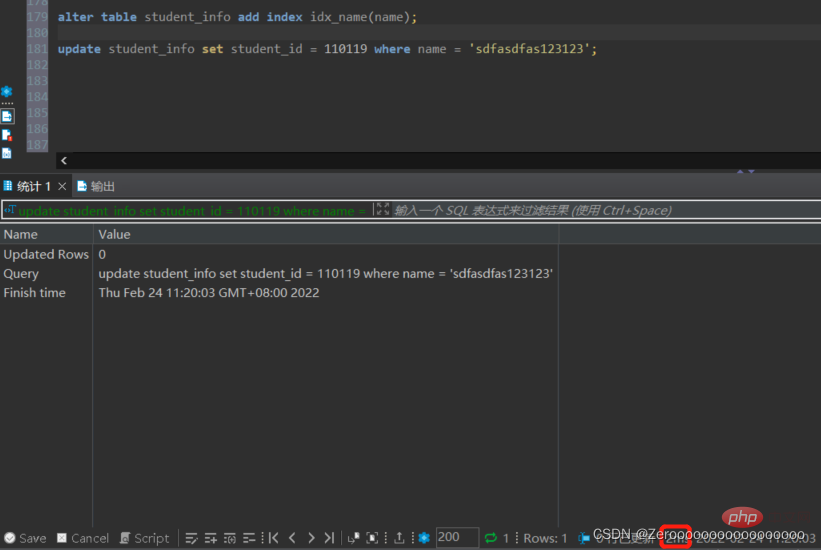
Selepas menambah indeks, situasi pelaksanaan adalah seperti berikut:
alter table student_info add index idx_name(name); update student_info set student_id = 110119 where name = 'sdfasdfas123123';#花费2ms
5 Medan Distinct perlu mencipta indeks
Kadang-kadang anda perlu mengindeks yang tertentu Untuk menyahduplikasi medan dan menggunakan Distinct, mencipta indeks untuk medan ini juga akan meningkatkan kecekapan pertanyaan.
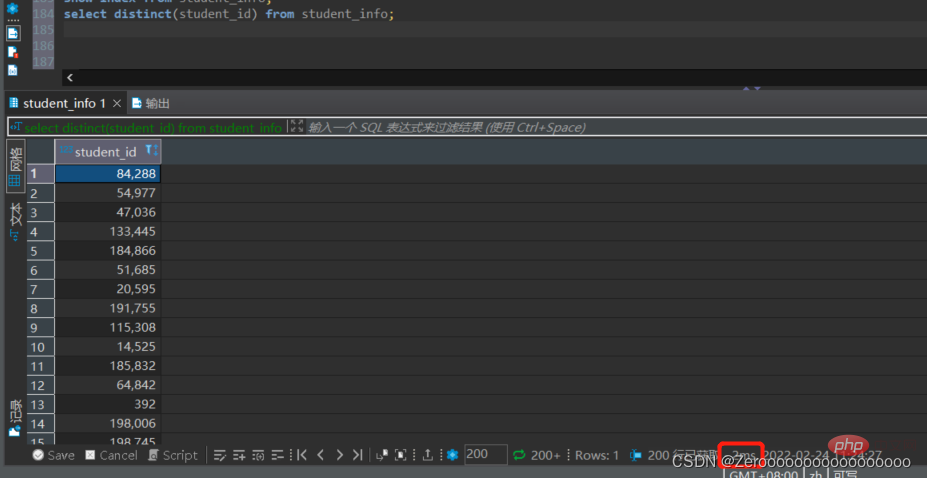
Contohnya, tanya student_id yang berbeza dalam jadual kursus Jika tiada indeks dibuat untuk student_id, situasi pelaksanaan adalah seperti berikut:
select distinct(student_id) from student_id;#花费2ms
alter table student_info add index idx_sid(student_id); select distinct(student_id) from student_id;#花费0.1ms

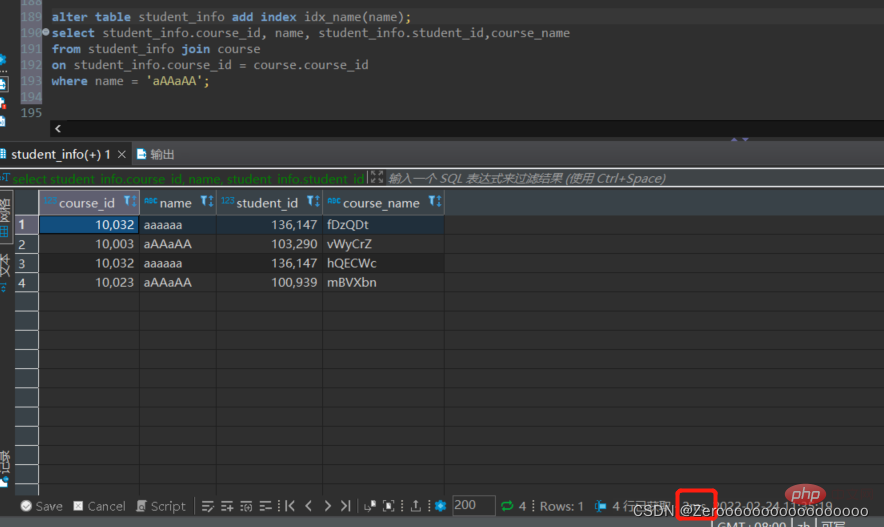
select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费176ms
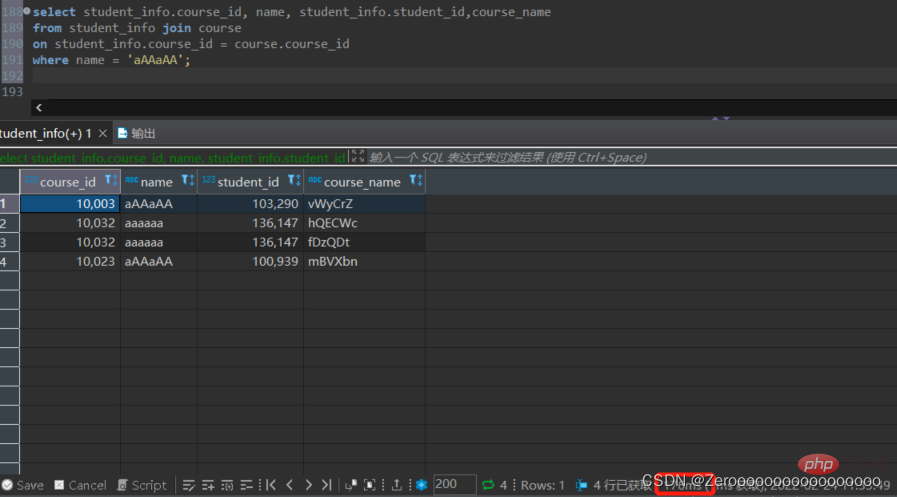
alter table student_info add index idx_name(name); select course_id, name, student_info.student_id,course_name from student_info join course on student_info.course_id = course.course_id where name = 'aAAaAA'; #花费2ms
7、使用列的类型小的创建索引
这里所说的类型小值意思是该类型表示的数据范围的大小。比如在定义表结构的时候要显示的指定列的类型,以整数类型为例,有TINYINT、MEDIUMINT、INT、BIGINT等,他们占用的存储空间依次递增,能表示的数据范围也是一次递增。如果相对某个整数列建立索引的话,在表示的整数范围允许的情况下,尽量让索引列使用较小的类型,例如能使用INT不要使用BIGINT,能使用MEDIUMINT不使用INT,原因如下:
数据类型越小,在查询时进行的比较操作越快
数据类型越小,索引占用的空间就越少,在一个数据页内就可以存下更多的记录,从而减少磁盘I/O带来的性能损耗,也就意味着可以存储更多的数据在数据页中,提高读写效率。
上述对于主键来说很合适,因为在聚簇索引中既存储了数据,也存储了索引,可以很好的减少磁盘I/O;而对于二级索引来说,还需要一次回表操作才能查到完整的数据,也就能加了一次磁盘I/O。
8、使用字符串前缀创建索引
根据Alibaba开发手册,在字符串上建立索引时,必须指定索引长度,没有必要对全字段建立索引。

比如有一张商品表,表中的商品描述字段较长,在描述字段上建立前缀索引如下:
create table product(id int, desc varchar(120) not null); alter table product add index(desc(12));
区分度的计算可以使用count(distinct left(列名, 索引长度))/count(*)来确定。
9、区分度高的列适合作为索引
列的基数值得时某一列中不重复数据的个数,比如说某个列包含值2,5,3,6,2,7,2,虽然有7条记录,但该列的基数却是5,也就是说,在记录行数一定的情况下,列的基数越大,该列中的值就越分散;列的基数越小,该列中的值就越集中。这里列的基数指标非常重要,直接影响是否能有效利用索引。最好为列的基数大的列建立索引,为基数太小的列建立索引效果反而不好。
可以使用公式select count(distinct col)/count(*) from table 来计算区分度,越接近1区分度越好。
10、使用最频繁的列放到联合索引的左侧
这条就是通常说的最左前缀匹配原则。 通俗来讲就是将Where条件后经常使用的条件字段放在索引的最左边,将使用频率相对低的放到右边。
11、在多个字段都要创建索引的情况下,联合索引由于单值索引
二、不适合创建索引
1、在where中使用不到的字段不要设置索引
通常索引的建立是有代价的,如果建立索引的字段没有出现在where条件(包括group by、order by)中,建议一开始就不要创建索引或将索引删除,因为索引的存在也会占用空间。
2、数据量小的表最好不要使用索引
3、有大量重复数据的列上不要建立索引
在条件表达式中经常用到的不同值较多的列上建立索引,但字段中如果有大量重复数据,也不用创建索引。比如学生表中的性别字段,只有男和女两种值,因此无需建立索引。如果建立索引,不但不会提高查询效率,反而会严重降低数据更新速度。
4、避免对经常更新的表创建过多的索引
频繁更新的字段不一定要创建索引,因为更新数据的时候,索引也要跟着更新,如果索引太多,更新的时候会造成服务器压力,从而影响效率。
避免对经常更新的表创建过多的索引,并且索引中的列尽可能少。此时虽然提高了查询速度,同时也会降低更新表的速度。
5、不建议用无序的值作为索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
6、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
7、不要定义冗余或重复的索引
例如身份证、UUID(在索引比较时需要转为ASCII,并且插入时可能造成页分裂)、MD5、HASH、无序长字符串等。
8、删除不在使用或很少使用的索引
表中的数据被大量更新或者数据的使用方式被改变后,原有的一些索引可能不会被使用到。DBA应定期找出这些索引并将之删除,从而较少无用索引对更新操作的影响。
9. Jangan tentukan indeks berlebihan atau pendua
Atas ialah kandungan terperinci Contoh analisis prinsip penciptaan indeks MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 MySQL: Kemudahan Pengurusan Data untuk Pemula
Apr 09, 2025 am 12:07 AM
MySQL: Kemudahan Pengurusan Data untuk Pemula
Apr 09, 2025 am 12:07 AM
MySQL sesuai untuk pemula kerana mudah dipasang, kuat dan mudah untuk menguruskan data. 1. Pemasangan dan konfigurasi mudah, sesuai untuk pelbagai sistem operasi. 2. Menyokong operasi asas seperti membuat pangkalan data dan jadual, memasukkan, menanyakan, mengemas kini dan memadam data. 3. Menyediakan fungsi lanjutan seperti menyertai operasi dan subqueries. 4. Prestasi boleh ditingkatkan melalui pengindeksan, pengoptimuman pertanyaan dan pembahagian jadual. 5. Sokongan sokongan, pemulihan dan langkah keselamatan untuk memastikan keselamatan data dan konsistensi.
 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Buat pangkalan data menggunakan Navicat Premium: Sambungkan ke pelayan pangkalan data dan masukkan parameter sambungan. Klik kanan pada pelayan dan pilih Buat Pangkalan Data. Masukkan nama pangkalan data baru dan set aksara yang ditentukan dan pengumpulan. Sambung ke pangkalan data baru dan buat jadual dalam penyemak imbas objek. Klik kanan di atas meja dan pilih masukkan data untuk memasukkan data.
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Anda boleh membuat sambungan MySQL baru di Navicat dengan mengikuti langkah -langkah: Buka aplikasi dan pilih Sambungan Baru (Ctrl N). Pilih "MySQL" sebagai jenis sambungan. Masukkan nama host/alamat IP, port, nama pengguna, dan kata laluan. (Pilihan) Konfigurasikan pilihan lanjutan. Simpan sambungan dan masukkan nama sambungan.
 Cara Memulihkan Data Selepas SQL Memadam Barisan
Apr 09, 2025 pm 12:21 PM
Cara Memulihkan Data Selepas SQL Memadam Barisan
Apr 09, 2025 pm 12:21 PM
Memulihkan baris yang dipadam secara langsung dari pangkalan data biasanya mustahil melainkan ada mekanisme sandaran atau transaksi. Titik Utama: Rollback Transaksi: Jalankan balik balik sebelum urus niaga komited untuk memulihkan data. Sandaran: Sandaran biasa pangkalan data boleh digunakan untuk memulihkan data dengan cepat. Snapshot Pangkalan Data: Anda boleh membuat salinan bacaan pangkalan data dan memulihkan data selepas data dipadam secara tidak sengaja. Gunakan Pernyataan Padam dengan berhati -hati: Periksa syarat -syarat dengan teliti untuk mengelakkan data yang tidak sengaja memadamkan. Gunakan klausa WHERE: Secara jelas menentukan data yang akan dipadam. Gunakan Persekitaran Ujian: Ujian Sebelum Melaksanakan Operasi Padam.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
