

Dalam projek kerja sebenar, cache telah menjadi komponen utama seni bina berkonkurensi tinggi dan berprestasi tinggi Jadi mengapa Redis boleh digunakan sebagai cache? Pertama sekali, terdapat dua ciri utama caching:
berada dalam sistem hierarki dengan prestasi capaian memori/CPU yang baik,
caching data Tepu, dengan mekanisme penghapusan data yang baik
Oleh kerana Redis secara semula jadi mempunyai dua ciri ini, Redis adalah berdasarkan operasi memori, dan ia mempunyai mekanisme penghapusan data yang lengkap, yang sangat sesuai sebagai komponen cache.
Antaranya, berdasarkan operasi memori, kapasiti boleh menjadi 32-96GB, dan masa operasi adalah 100ns secara purata, dan kecekapan operasi adalah tinggi. Selain itu, terdapat banyak mekanisme penghapusan data, dan terdapat 8 daripadanya selepas Redis 4.0, yang menjadikan Redis boleh digunakan pada banyak senario sebagai cache.
Jadi mengapa cache Redis memerlukan mekanisme penghapusan data? Apakah 8 mekanisme penghapusan data?
Cache Redis adalah berdasarkan memori, jadi kapasiti cachenya terhad Apabila cache penuh, bagaimanakah Redis harus mengendalikannya?
Apabila cache penuh, Redis memerlukan mekanisme penghapusan data cache untuk memilih dan memadam beberapa data melalui peraturan penghapusan tertentu supaya perkhidmatan cache boleh digunakan semula. Jadi apakah strategi penghapusan yang Redis gunakan untuk memadam data?
Selepas Redis 4.0, terdapat 6+2 strategi penghapusan cache Redis, termasuk tiga kategori utama:
Tiada penyingkiran data
noeviction, tiada penghapusan data dilakukan Apabila cache penuh, Redis tidak menyediakan perkhidmatan dan mengembalikan ralat secara langsung.
Dalam pasangan nilai kunci yang menetapkan masa tamat tempoh,
rawak meruap, dalam kunci yang menetapkan masa tamat secara rawak Padamkan
tidak menentu-ttl daripada pasangan nilai Kunci-nilai yang menetapkan masa tamat akan dipadamkan berdasarkan masa tamat tempoh , lebih awal ia akan dipadamkan.
lru meruap, berdasarkan algoritma LRU (Paling Kurang Digunakan) untuk menapis pasangan nilai kunci dengan masa tamat tempoh, menapis data berdasarkan prinsip yang paling kurang digunakan baru-baru ini
volatile-lfu menggunakan algoritma LFU (Kurang Kerap Digunakan) untuk memilih pasangan nilai kunci dengan masa tamat tempoh ditetapkan dan menapis data menggunakan pasangan nilai kunci dengan kekerapan paling sedikit.
antara semua pasangan nilai kunci,
semua kunci-rawak, dipilih secara rawak daripada semua pasangan nilai kunci Dan padamkan data
allkeys-lru, gunakan algoritma LRU untuk menapis semua data
allkeys-lfu, gunakan algoritma LFU dalam semua data Penapis dalam
Nota: algoritma LRU (Paling Kurang Digunakan), LRU mengekalkan dua hala senarai terpaut Kepala dan ekor senarai terpaut masing-masing mewakili penghujung MRU dan penghujung LRU, masing-masing mewakili data yang paling terkini digunakan dan data paling terkini yang paling jarang digunakan.
Dalam pelaksanaan sebenar, algoritma LRU perlu menggunakan senarai terpaut untuk mengurus semua data cache, yang akan membawa ruang tambahan di atas kepala. Selain itu, apabila data diakses, data perlu dialihkan ke MRU pada senarai terpaut Jika sejumlah besar data diakses, banyak operasi pemindahan senarai terpaut akan berlaku, yang akan memakan masa yang lama dan mengurangkan prestasi cache Redis. .
Antaranya, LRU dan LFU dilaksanakan berdasarkan atribut lru dan refcount redisObject, struktur objek Redis:
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
// 对象最后一次被访问的时间
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
// 引用计数 * and most significant 16 bits access time). */
int refcount;
void *ptr;
} robj;LRU Redis akan menggunakan lru daripada redisObject untuk merekodkan akses terakhir Pada masa itu, nombor yang dikonfigurasikan dengan parameter maxmemory-samples dipilih secara rawak sebagai set calon, dan data dengan nilai atribut lru terkecil dipilih dan dihapuskan.
Dalam projek sebenar, bagaimana untuk memilih mekanisme penghapusan data?
Pilih algoritma allkeys-lru untuk menyimpan data yang paling terkini diakses dalam cache untuk meningkatkan prestasi capaian aplikasi.
Data teratas menggunakan algoritma volatile-lru. Data teratas tidak menetapkan masa tamat tempoh cache dan ditapis berdasarkan peraturan LRU.
Setelah memahami mekanisme penghapusan cache Redis, mari lihat berapa banyak mod yang ada pada Redis sebagai cache?
Mod cache redis boleh dibahagikan kepada cache baca sahaja dan cache baca tulis berdasarkan sama ada untuk menerima permintaan tulis:
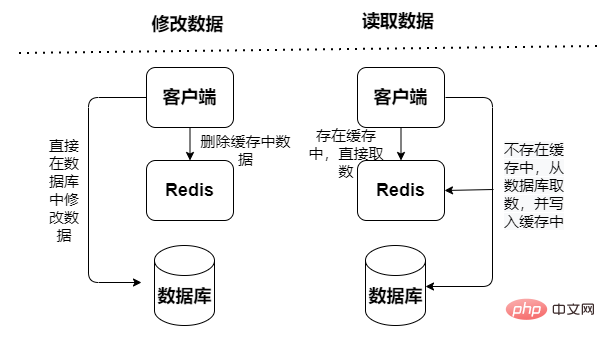
Cache baca sahaja: hanya mengendalikan operasi baca, semua Semua operasi kemas kini dilakukan dalam pangkalan data, jadi tiada risiko kehilangan data.
Mod Cache Aside
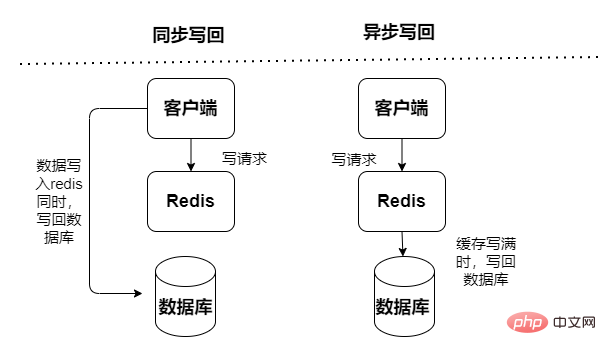
Baca dan tulis operasi cache, baca dan tulis dilakukan dalam cache , muncul Kegagalan Masa Henti akan membawa kepada kehilangan data. Data tulis balik cache ke pangkalan data dibahagikan kepada dua jenis: segerak dan tak segerak:
Segerak: prestasi capaian rendah dan ia lebih memfokuskan pada memastikan kebolehpercayaan data
Mod Baca Melalui
Mod Tulis Melalui
Asynchronous: Terdapat risiko kehilangan data, tumpuannya Untuk menyediakan akses kependaman rendah
Mod Tulis-Belakang
Pertanyaan Data dibaca terlebih dahulu daripada cache. Jika ia tidak wujud dalam cache, data akan dibaca daripada pangkalan data Selepas data diperolehi, ia dikemas kini ke dalam cache dalam pangkalan data akan dikemas kini terlebih dahulu. Kemudian membatalkan data cache.
Selain itu, terdapat risiko serentak dalam mod Cache Aside: operasi baca terlepas cache, dan kemudian pangkalan data ditanya untuk mengambil data Data telah disoal tetapi belum diletakkan ke dalam cache Pada masa yang sama, operasi tulis kemas kini membatalkan cache , dan kemudian operasi baca memuatkan data pertanyaan ke dalam cache, mengakibatkan data kotor yang dicache. Mod Baca/Tulis Melalui Kedua-dua data pertanyaan dan data kemas kini mengakses terus perkhidmatan cache,perkhidmatan cache mengemas kini data ke pangkalan data secara serentak . Kebarangkalian data kotor adalah rendah, tetapi ia sangat bergantung pada cache dan mempunyai keperluan yang lebih besar untuk kestabilan perkhidmatan cache Walau bagaimanapun, kemas kini segerak akan membawa kepada prestasi yang lemah.
Mod Tulis Di BelakangKedua-dua data pertanyaan dan mengemas kini data terus mengakses perkhidmatan cache,tetapi perkhidmatan cache menggunakan cara tak segerak untuk mengemas kini data ke pangkalan data (melalui tugas tak segerak) Kelajuan Ia pantas dan kecekapan akan menjadi sangat tinggi, tetapi konsistensi data agak lemah, mungkin terdapat kehilangan data, dan logik pelaksanaan juga agak kompleks.
Dalam pembangunan projek sebenar, mod cache dipilih mengikut keperluan senario perniagaan sebenar. Selepas memahami perkara di atas, mengapa kita perlu menggunakan cache redis dalam aplikasi kita? Menggunakan cache Redis dalam aplikasi boleh meningkatkan prestasi sistem dan keselarasan, terutamanya ditunjukkan dalam
Cache baca sahaja (mod Cache Aside)
Untukcache baca sahaja (mod Cache Aside), operasi baca semua berlaku dalam cache, dan ketidakkonsistenan data hanya berlaku dalam operasi pemadaman (baru Operasi tidak akan berlaku, kerana penambahan baharu hanya akan diproses dalam pangkalan data). Apabila operasi pemadaman berlaku, cache akan menandakan data sebagai tidak sah dan mengemas kini pangkalan data. Oleh itu, dalam proses mengemas kini pangkalan data dan memadamkan nilai cache, tanpa mengira susunan pelaksanaan kedua-dua operasi, selagi satu operasi gagal, ketidakkonsistenan data akan berlaku.
Atas ialah kandungan terperinci analisis contoh web java. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



