

Pengembangan teknologi aplikasi TensorFlow—pengkelasan imej

1. Pengembangan operasi penggunaan persekitaran platform penyelidikan saintifik
Untuk latihan model dalam pembelajaran mesin, saya mengesyorkan anda mempelajari lebih banyak kursus atau sumber TensorFlow, seperti dua kursus mengenai MOOC Universiti Cina 《Kursus Praktikal Pengenalan TensorFlow》 dan 《Kursus Pengenalan TensorFlow - Deployment》. Untuk latihan model yang diedarkan yang terlibat dalam penyelidikan atau kerja saintifik, platform sumber mungkin selalunya sangat memakan masa dan tidak dapat memenuhi keperluan individu tepat pada masanya. Di sini, saya akan membuat pengembangan khusus mengenai penggunaan platform Jiutian Bisheng yang disebut dalam artikel sebelum ini "Pemahaman Awal Pembelajaran Rangka Kerja TensorFlow" untuk memudahkan pelajar dan pengguna Menjalankan latihan model dengan lebih cepat. Platform ini boleh melaksanakan tugas seperti pengurusan data dan latihan model, dan merupakan platform amalan yang mudah dan pantas untuk tugasan penyelidikan saintifik. Langkah khusus dalam latihan model ialah:
(1) Daftar dan log masuk ke platform Jiutian Bisheng Memandangkan tugas latihan seterusnya memerlukan penggunaan kacang kuasa pengkomputeran, bilangan kacang kuasa pengkomputeran untuk pengguna baharu adalah terhad. , tetapi mereka boleh dikongsi oleh Rakan dan tugas lain untuk menyelesaikan pemerolehan kacang kuasa pengkomputeran. Pada masa yang sama, untuk tugas latihan model berskala besar, untuk mendapatkan lebih banyak ruang storan latihan model, anda boleh menghubungi kakitangan platform melalui e-mel untuk menaik taraf konsol, sekali gus memenuhi keperluan storan latihan yang diperlukan pada masa hadapan. Butiran biji kuasa penyimpanan dan pengkomputeran adalah seperti berikut:

(2) Masukkan antara muka pengurusan data untuk menggunakan set data yang digunakan oleh model projek penyelidikan saintifik, dan tambah set data yang diperlukan untuk tugasan penyelidikan saintifik Pakej dan muat naik untuk melengkapkan penggunaan set data yang diperlukan untuk latihan model pada platform.
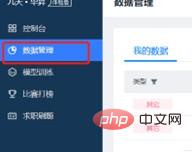
(3) Tambahkan contoh latihan projek baharu dalam tetingkap latihan model, pilih set data yang diimport sebelum ini dan sumber CPU yang diperlukan. Contoh yang dibuat ialah fail model tunggal yang perlu dilatih untuk penyelidikan saintifik. Butiran contoh projek baharu adalah seperti yang ditunjukkan di bawah:

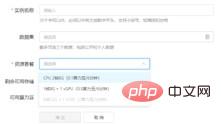
(4) Jalankan contoh projek baharu, iaitu jalankan persekitaran latihan projek , selepas berjalan dengan jayanya, anda boleh memilih editor jupyter untuk mencipta dan mengedit fail kod yang diperlukan.

(5) Penulisan kod dan latihan model seterusnya boleh dilakukan menggunakan editor jupyter.
2. Pengembangan teknologi pengelasan imej
Klasifikasi imej, seperti namanya, adalah untuk menilai kategori imej yang berbeza berdasarkan perbezaan antara imej. Mereka bentuk model diskriminasi berdasarkan perbezaan antara imej adalah pengetahuan yang perlu dikuasai dalam pembelajaran mesin. Untuk pengetahuan asas dan proses pengendalian klasifikasi imej, anda boleh merujuk kepada "Kursus Praktikal Pengenalan TensorFlow" di MOOC Universiti China untuk memahami dengan cepat aplikasi asas dan idea reka bentuk TensorFlow. . https://www.php.cn/link/b977b532403e14d6681a00f78f95506e
Bab ini bertujuan untuk memperkenalkan pelajar kepada kursus klasifikasi ini dengan meluaskan imej teknologi. Pengguna mendapat pemahaman yang lebih mendalam tentang klasifikasi imej.
2.1 Apakah kegunaan operasi lilitan?
Apabila ia melibatkan pemprosesan atau pengelasan imej, terdapat satu operasi yang tidak boleh dielakkan, dan operasi ini ialah konvolusi. Operasi lilitan khusus pada asasnya boleh difahami melalui video pembelajaran, tetapi lebih ramai pembaca mungkin hanya kekal pada tahap cara melaksanakan operasi lilitan, dan mengapa lilitan dilakukan dan apakah kegunaan operasi lilitan masih tidak jelas. Berikut ialah beberapa pengembangan untuk semua orang untuk membantu anda memahami konvolusi dengan lebih baik.
Proses lilitan asas ditunjukkan dalam rajah di bawah dengan mengambil imej sebagai contoh, matriks digunakan untuk mewakili imej Setiap elemen matriks adalah nilai piksel yang sepadan dalam imej . Operasi lilitan adalah untuk mendapatkan nilai eigen kawasan kecil ini dengan mendarab isirong lilitan dengan matriks yang sepadan. Ciri yang diekstrak akan berbeza disebabkan oleh kernel lilitan yang berbeza Inilah sebabnya mengapa seseorang akan melakukan operasi lilitan pada saluran imej yang berbeza untuk mendapatkan ciri saluran imej yang berbeza untuk melaksanakan tugas pengelasan berikutnya dengan lebih baik.
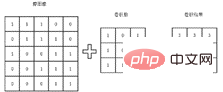
Dalam latihan model harian, kernel konvolusi khusus tidak perlu direka secara manual, tetapi dilatih secara automatik menggunakan rangkaian dengan memberikan label sebenar imej Walau bagaimanapun, proses ini tidak kondusif untuk pemahaman orang ramai tentang kernel konvolusi Proses kernel dan lilitan tidak intuitif. Oleh itu, untuk membantu semua orang lebih memahami maksud operasi lilitan, berikut ialah contoh operasi lilitan. Seperti yang ditunjukkan dalam matriks di bawah, nilai berangka mewakili piksel grafik Untuk kemudahan pengiraan, hanya 0 dan 1 diambil di sini separuh daripada grafik adalah terang dan separuh bahagian bawah grafik adalah hitam, jadi imej Terdapat garis pemisah yang sangat jelas, iaitu, ia mempunyai ciri mendatar yang jelas.

Oleh itu, untuk mengekstrak ciri mendatar matriks di atas dengan baik, kernel lilitan yang direka juga harus mempunyai sifat pengekstrakan ciri mendatar. Kernel lilitan yang menggunakan atribut pengekstrakan ciri menegak agak tidak mencukupi dalam kejelasan pengekstrakan ciri. Seperti yang ditunjukkan di bawah, kernel lilitan yang mengekstrak ciri mendatar digunakan untuk lilitan:
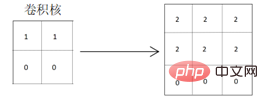
Ia boleh dilihat daripada matriks hasil lilitan yang diperolehi bahawa ciri mendatar grafik asal adalah diekstrak dengan baik, dan garis pemisah grafik akan menjadi lebih jelas, kerana nilai piksel bahagian berwarna grafik diperdalam, yang boleh mengekstrak dan menyerlahkan ciri mendatar grafik. Apabila berbelit menggunakan kernel lilitan yang mengekstrak ciri menegak:
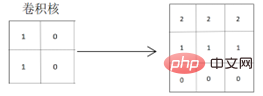
Ia boleh dilihat daripada matriks hasil lilitan yang diperoleh bahawa ciri mendatar grafik asal juga boleh diekstrak, tetapi Dua garis pemisah akan dijana Grafik berubah daripada sangat terang kepada terang dan kemudian kepada hitam, dan situasi yang dicerminkan pada grafik sebenar juga akan menjadi situasi dari terang ke gelap kepada hitam, yang berbeza daripada ciri mendatar sebenar. grafik asal.
Tidak sukar untuk mengetahui daripada contoh di atas bahawa kernel lilitan yang berbeza akan menjejaskan kualiti ciri grafik yang diekstrak akhir Pada masa yang sama, ciri yang ditunjukkan oleh grafik yang berbeza juga berbeza atribut ciri grafik yang berbeza kepada Ia juga amat penting untuk mereka bentuk model rangkaian untuk mempelajari dengan lebih baik dan mereka bentuk inti konvolusi. Dalam projek klasifikasi peta sebenar, adalah perlu untuk memilih dan mengekstrak ciri yang sesuai berdasarkan perbezaan dalam imej, dan selalunya terdapat pertukaran untuk dipertimbangkan.
2.2 Bagaimana untuk mempertimbangkan konvolusi untuk mengklasifikasikan imej dengan lebih baik?
Seperti yang anda boleh lihat daripada peranan operasi lilitan dalam bahagian sebelumnya, adalah amat penting untuk mereka bentuk model rangkaian untuk mempelajari kernel lilitan yang menyesuaikan diri dengan imej dengan lebih baik. Walau bagaimanapun, dalam aplikasi praktikal, pembelajaran dan latihan automatik dilakukan dengan menukar label sebenar bagi kategori imej yang diberikan kepada data vektor yang boleh difahami oleh mesin. Sudah tentu, tidak mustahil untuk diperbaiki melalui tetapan manual. Walaupun label set data adalah tetap, kita boleh memilih model rangkaian yang berbeza berdasarkan jenis imej set data Memandangkan kelebihan dan kekurangan model rangkaian yang berbeza selalunya akan mempunyai hasil latihan yang baik.
Pada masa yang sama, apabila mengekstrak ciri imej, anda juga boleh mempertimbangkan untuk menggunakan kaedah pembelajaran berbilang tugas Dalam data imej sedia ada, gunakan data imej sekali lagi untuk mengekstrak beberapa ciri imej tambahan (seperti ciri saluran imej) dan ciri spatial, dsb.), dan kemudian menambah atau mengisi ciri yang diekstrak sebelum ini untuk menambah baik ciri imej yang diekstrak akhir. Sudah tentu, kadang-kadang operasi ini akan menyebabkan ciri yang diekstrak menjadi berlebihan, dan kesan klasifikasi yang diperoleh selalunya tidak produktif Oleh itu, ia perlu dipertimbangkan berdasarkan keputusan klasifikasi latihan yang sebenar.
2.3 Beberapa cadangan untuk pemilihan model rangkaian
Bidang klasifikasi imej telah lama berkembang, daripada model rangkaian AlexNet klasik asal kepada model rangkaian ResNet yang popular baru-baru ini tahun, dsb., teknologi pengelasan imej telah berkembang dengan agak baik, dan ketepatan klasifikasi untuk beberapa set data imej yang biasa digunakan cenderung 100%. Pada masa ini, dalam bidang ini, kebanyakan orang menggunakan model rangkaian terkini, dan dalam kebanyakan tugas pengelasan imej, menggunakan model rangkaian terkini sememangnya boleh membawa kesan klasifikasi yang jelas Oleh itu, ramai orang dalam bidang ini Orang sering mengabaikan model rangkaian sebelumnya dan pergi terus untuk mempelajari model rangkaian terkini dan popular.
Di sini, saya masih mengesyorkan agar pembaca membiasakan diri dengan beberapa model rangkaian klasik dalam bidang klasifikasi graf, kerana kemas kini teknologi dan lelaran sangat pantas, malah model rangkaian terkini akan digunakan pada masa hadapan mungkin dihapuskan, tetapi prinsip operasi model rangkaian asas adalah lebih kurang sama Dengan menguasai model rangkaian klasik, anda bukan sahaja boleh menguasai prinsip asas, tetapi juga memahami perbezaan antara model rangkaian yang berbeza dan kelebihan memproses tugas yang berbeza. . Contohnya, apabila set data imej anda agak kecil, latihan dengan model rangkaian terkini mungkin sangat kompleks dan memakan masa, tetapi kesan penambahbaikan adalah minimum, jadi pengorbanan kos masa latihan anda sendiri untuk kesan yang boleh diabaikan tidak berbaloi. . Oleh itu, untuk menguasai model rangkaian klasifikasi imej, anda perlu tahu apakah itu dan mengapa ia supaya anda benar-benar boleh disasarkan apabila memilih model klasifikasi imej pada masa hadapan.
Pengenalan pengarang:
Bubur, editor komuniti 51CTO, pernah bekerja di jabatan teknologi data besar sebuah pusat penyelidikan dan pembangunan kecerdasan buatan e-dagang, melakukan algoritma pengesyoran. Pada masa ini terlibat dalam penyelidikan ke arah pemprosesan bahasa semula jadi bidang kepakaran utamanya termasuk algoritma cadangan, NLP, dan bahasa pengekodan yang digunakan termasuk Java, Python, dan Scala. Menerbitkan satu kertas persidangan ICCC.
Atas ialah kandungan terperinci Pengembangan teknologi aplikasi TensorFlow—pengkelasan imej. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1359
1359
 52
52

 Bagaimana untuk membuat asal Padam dari Skrin Utama dalam iPhone
Apr 17, 2024 pm 07:37 PM
Bagaimana untuk membuat asal Padam dari Skrin Utama dalam iPhone
Apr 17, 2024 pm 07:37 PM
Memadamkan sesuatu yang penting daripada skrin utama anda dan cuba mendapatkannya semula? Anda boleh meletakkan ikon apl kembali pada skrin dalam pelbagai cara. Kami telah membincangkan semua kaedah yang boleh anda ikuti dan meletakkan semula ikon aplikasi pada skrin utama Cara Buat Asal Alih Keluar dari Skrin Utama dalam iPhone Seperti yang kami nyatakan sebelum ini, terdapat beberapa cara untuk memulihkan perubahan ini pada iPhone. Kaedah 1 – Gantikan Ikon Apl dalam Pustaka Apl Anda boleh meletakkan ikon apl pada skrin utama anda terus daripada Pustaka Apl. Langkah 1 – Leret ke sisi untuk mencari semua apl dalam pustaka apl. Langkah 2 – Cari ikon apl yang anda padamkan sebelum ini. Langkah 3 – Hanya seret ikon apl dari pustaka utama ke lokasi yang betul pada skrin utama. Ini adalah gambar rajah aplikasi
 Peranan dan aplikasi praktikal simbol anak panah dalam PHP
Mar 22, 2024 am 11:30 AM
Peranan dan aplikasi praktikal simbol anak panah dalam PHP
Mar 22, 2024 am 11:30 AM
Peranan dan aplikasi praktikal simbol anak panah dalam PHP Dalam PHP, simbol anak panah (->) biasanya digunakan untuk mengakses sifat dan kaedah objek. Objek adalah salah satu konsep asas pengaturcaraan berorientasikan objek (OOP) dalam PHP Dalam pembangunan sebenar, simbol anak panah memainkan peranan penting dalam mengendalikan objek. Artikel ini akan memperkenalkan peranan dan aplikasi praktikal simbol anak panah, dan menyediakan contoh kod khusus untuk membantu pembaca memahami dengan lebih baik. 1. Peranan simbol anak panah untuk mengakses sifat sesuatu objek Simbol anak panah boleh digunakan untuk mengakses sifat objek. Apabila kita instantiate sepasang
 DualBEV: mengatasi BEVFormer dan BEVDet4D dengan ketara, buka buku!
Mar 21, 2024 pm 05:21 PM
DualBEV: mengatasi BEVFormer dan BEVDet4D dengan ketara, buka buku!
Mar 21, 2024 pm 05:21 PM
Kertas kerja ini meneroka masalah mengesan objek dengan tepat dari sudut pandangan yang berbeza (seperti perspektif dan pandangan mata burung) dalam pemanduan autonomi, terutamanya cara mengubah ciri dari perspektif (PV) kepada ruang pandangan mata burung (BEV) dengan berkesan dilaksanakan melalui modul Transformasi Visual (VT). Kaedah sedia ada secara amnya dibahagikan kepada dua strategi: penukaran 2D kepada 3D dan 3D kepada 2D. Kaedah 2D-ke-3D meningkatkan ciri 2D yang padat dengan meramalkan kebarangkalian kedalaman, tetapi ketidakpastian yang wujud dalam ramalan kedalaman, terutamanya di kawasan yang jauh, mungkin menimbulkan ketidaktepatan. Manakala kaedah 3D ke 2D biasanya menggunakan pertanyaan 3D untuk mencuba ciri 2D dan mempelajari berat perhatian bagi kesesuaian antara ciri 3D dan 2D melalui Transformer, yang meningkatkan masa pengiraan dan penggunaan.
 Daripada pemula hingga mahir: Terokai pelbagai senario aplikasi arahan tee Linux
Mar 20, 2024 am 10:00 AM
Daripada pemula hingga mahir: Terokai pelbagai senario aplikasi arahan tee Linux
Mar 20, 2024 am 10:00 AM
Perintah Linuxtee ialah alat baris arahan yang sangat berguna yang boleh menulis output ke fail atau menghantar output ke arahan lain tanpa menjejaskan output sedia ada. Dalam artikel ini, kami akan meneroka secara mendalam pelbagai senario aplikasi arahan Linuxtee, daripada kemasukan kepada kemahiran. 1. Penggunaan asas Mula-mula, mari kita lihat pada penggunaan asas arahan tee. Sintaks arahan tee adalah seperti berikut: tee[OPTION]...[FAIL]...Arahan ini akan membaca data daripada input standard dan menyimpan data ke
 Terokai kelebihan dan senario aplikasi bahasa Go
Mar 27, 2024 pm 03:48 PM
Terokai kelebihan dan senario aplikasi bahasa Go
Mar 27, 2024 pm 03:48 PM
Bahasa Go ialah bahasa pengaturcaraan sumber terbuka yang dibangunkan oleh Google dan pertama kali dikeluarkan pada tahun 2007. Ia direka bentuk untuk menjadi bahasa yang mudah, mudah dipelajari, cekap dan sangat bersesuaian, serta digemari oleh semakin ramai pembangun. Artikel ini akan meneroka kelebihan bahasa Go, memperkenalkan beberapa senario aplikasi yang sesuai untuk bahasa Go dan memberikan contoh kod khusus. Kelebihan: Konkurensi yang kuat: Bahasa Go mempunyai sokongan terbina dalam untuk benang-goroutine ringan, yang boleh melaksanakan pengaturcaraan serentak dengan mudah. Goroutin boleh dimulakan dengan menggunakan kata kunci go
 Semakan! Gabungan model mendalam (LLM/model asas/pembelajaran bersekutu/penalaan halus, dsb.)
Apr 18, 2024 pm 09:43 PM
Semakan! Gabungan model mendalam (LLM/model asas/pembelajaran bersekutu/penalaan halus, dsb.)
Apr 18, 2024 pm 09:43 PM
Pada 23 September, kertas kerja "DeepModelFusion:ASurvey" diterbitkan oleh Universiti Teknologi Pertahanan Nasional, JD.com dan Institut Teknologi Beijing. Gabungan/penggabungan model dalam ialah teknologi baru muncul yang menggabungkan parameter atau ramalan berbilang model pembelajaran mendalam ke dalam satu model. Ia menggabungkan keupayaan model yang berbeza untuk mengimbangi bias dan ralat model individu untuk prestasi yang lebih baik. Gabungan model mendalam pada model pembelajaran mendalam berskala besar (seperti LLM dan model asas) menghadapi beberapa cabaran, termasuk kos pengiraan yang tinggi, ruang parameter berdimensi tinggi, gangguan antara model heterogen yang berbeza, dsb. Artikel ini membahagikan kaedah gabungan model dalam sedia ada kepada empat kategori: (1) "Sambungan corak", yang menghubungkan penyelesaian dalam ruang berat melalui laluan pengurangan kerugian untuk mendapatkan gabungan model awal yang lebih baik.
 Lebih daripada sekadar Gaussian 3D! Gambaran keseluruhan terkini teknik pembinaan semula 3D yang terkini
Jun 02, 2024 pm 06:57 PM
Lebih daripada sekadar Gaussian 3D! Gambaran keseluruhan terkini teknik pembinaan semula 3D yang terkini
Jun 02, 2024 pm 06:57 PM
Ditulis di atas & Pemahaman peribadi penulis ialah pembinaan semula 3D berasaskan imej ialah tugas mencabar yang melibatkan membuat inferens bentuk 3D objek atau pemandangan daripada set imej input. Kaedah berasaskan pembelajaran telah menarik perhatian kerana keupayaan mereka untuk menganggar secara langsung bentuk 3D. Kertas ulasan ini memfokuskan pada teknik pembinaan semula 3D yang canggih, termasuk menjana novel, pandangan ghaib. Gambaran keseluruhan perkembangan terkini dalam kaedah percikan Gaussian disediakan, termasuk jenis input, struktur model, perwakilan output dan strategi latihan. Cabaran yang tidak dapat diselesaikan dan hala tuju masa depan turut dibincangkan. Memandangkan kemajuan pesat dalam bidang ini dan banyak peluang untuk meningkatkan kaedah pembinaan semula 3D, pemeriksaan menyeluruh terhadap algoritma nampaknya penting. Oleh itu, kajian ini memberikan gambaran menyeluruh tentang kemajuan terkini dalam serakan Gaussian. (Leret ibu jari anda ke atas
 GPT-4o revolusioner: Membentuk semula pengalaman interaksi manusia-komputer
Jun 07, 2024 pm 09:02 PM
GPT-4o revolusioner: Membentuk semula pengalaman interaksi manusia-komputer
Jun 07, 2024 pm 09:02 PM
Model GPT-4o yang dikeluarkan oleh OpenAI sudah pasti satu kejayaan besar, terutamanya dalam keupayaannya untuk memproses berbilang media input (teks, audio, imej) dan menjana output yang sepadan. Keupayaan ini menjadikan interaksi manusia-komputer lebih semula jadi dan intuitif, meningkatkan kepraktisan dan kebolehgunaan AI. Beberapa sorotan utama GPT-4o termasuk: kebolehskalaan tinggi, input dan output multimedia, penambahbaikan selanjutnya dalam keupayaan pemahaman bahasa semula jadi, dsb. 1. Input/output merentas media: GPT-4o+ boleh menerima sebarang kombinasi teks, audio dan imej sebagai input dan terus menjana output daripada media ini. Ini memecahkan had model AI tradisional yang hanya memproses satu jenis input, menjadikan interaksi manusia-komputer lebih fleksibel dan pelbagai. Inovasi ini membantu kuasa pembantu pintar
