

Apache Kafka ialah sistem pemesejan terbitan-langganan edaran Takrifan kafka pada tapak web rasmi kafka ialah: sistem pemesejan terbitan-langganan yang diedarkan. Ia pada asalnya dibangunkan oleh LinkedIn, yang telah disumbangkan kepada Yayasan Apache pada tahun 2010 dan menjadi projek sumber terbuka teratas. Kafka ialah perkhidmatan log komit yang pantas, berskala dan diedarkan secara semula jadi, dibahagikan dan boleh ditiru.
Nota: Kafka tidak mengikut spesifikasi JMS (), ia hanya menyediakan kaedah komunikasi terbitkan dan langgan.
Broker: Nod Kafka, nod Kafka ialah broker, berbilang broker boleh membentuk gugusan Kafka
Topik: Satu jenis mesej Direktori tempat mesej disimpan ialah topik Sebagai contoh, log paparan halaman, log klik, dsb. boleh wujud dalam bentuk topik daripada berbilang topik pada masa yang sama
urutan: Objek penghantaran paling asas dalam Kafka.
Partition: Pengumpulan fizikal topik Sesuatu topik boleh dibahagikan kepada berbilang partition dan setiap partition ialah baris gilir tertib. Pemisahan dilaksanakan di Kafka, dan broker mewakili rantau.
Segmen: Pembahagian secara fizikal terdiri daripada berbilang segmen, setiap segmen menyimpan maklumat mesej
Pengeluar: Pengeluar, menghasilkan penghantaran mesej Kepada topik
Pengguna: pengguna, melanggan topik dan menggunakan mesej, pengguna menggunakan sebagai rangkaian
Kumpulan Pengguna: kumpulan pengguna, Kumpulan Pengguna mengandungi berbilang pengguna
Offset: offset, difahami sebagai kedudukan indeks mesej dalam partition mesej
bagi topik dan baris gilir Perbezaan:
Baris gilir ialah struktur data yang mengikut prinsip masuk dahulu, keluar dahulu
Pasang persekitaran jdk1.8 pada setiap pelayan
Pasang persekitaran kluster Zookeeper
Pasang persekitaran kluster kafka
Jalankan ujian persekitaran
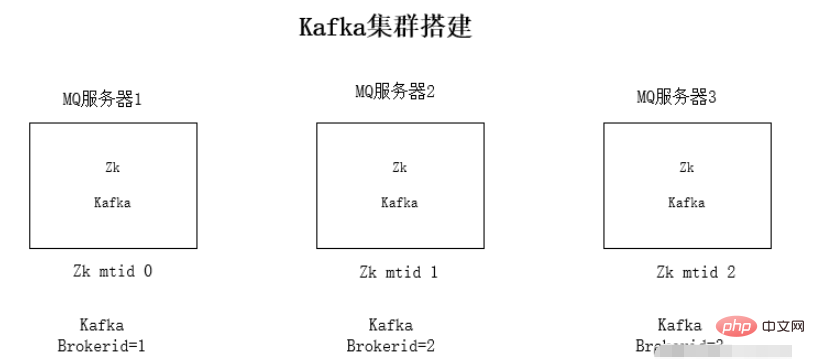
Pemasangan jdk environment dan zookeeper tidak akan diterangkan secara terperinci di sini.
Mengapa kafka bergantung pada zookeeper: kafka akan menyimpan maklumat mq pada zookeeper Untuk menjadikan keseluruhan kluster mudah dikembangkan, pemberitahuan acara zookeeper digunakan untuk mengesan satu sama lain.
Langkah pemasangan kluster kafka:
1 Muat turun pakej mampat kafka
2 Nyahzip pakej pemasangan
tar -zxvf kafka_2. 11 -1.0.0.tgz
3. Ubah suai konfigurasi fail config/server.properties kafka
Kandungan pengubahsuaian fail konfigurasi:
Alamat sambungan penjaga zoo: zookeeper.connect=192.168.1.19:2181
Ip pendengaran ditukar kepada ip tempatanlisteners=PLAINTEXT://192.168.1.19:9092
kafka brokerid, setiap ID broker semuanya berbeza broker.id=0
4 Mulakan kafka mengikut urutan
./kafka-server-start.sh -daemon config/server.properties
topik ialah konsep logik, manakala partition ialah konsep fizikal Setiap partition sepadan dengan fail log, dan fail log menyimpan data yang dijana oleh Pengeluar. Data yang dijana oleh Pengeluar akan ditambahkan secara berterusan pada penghujung fail log Untuk mengelakkan fail log daripada menjadi terlalu besar dan menyebabkan ketidakcekapan dalam kedudukan data, Kafka menggunakan mekanisme sharding dan pengindeksan untuk membahagikan setiap partition kepada berbilang segmen. . Setiap segmen termasuk: fail ".index", fail ".log" dan fail .timeindex. Fail ini terletak dalam folder, dan peraturan penamaan folder ialah: nama topik + nombor partition.
Contohnya: laksanakan arahan untuk mencipta topik baharu, yang dibahagikan kepada tiga kawasan dan disimpan dalam tiga broker:
./kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic kaico
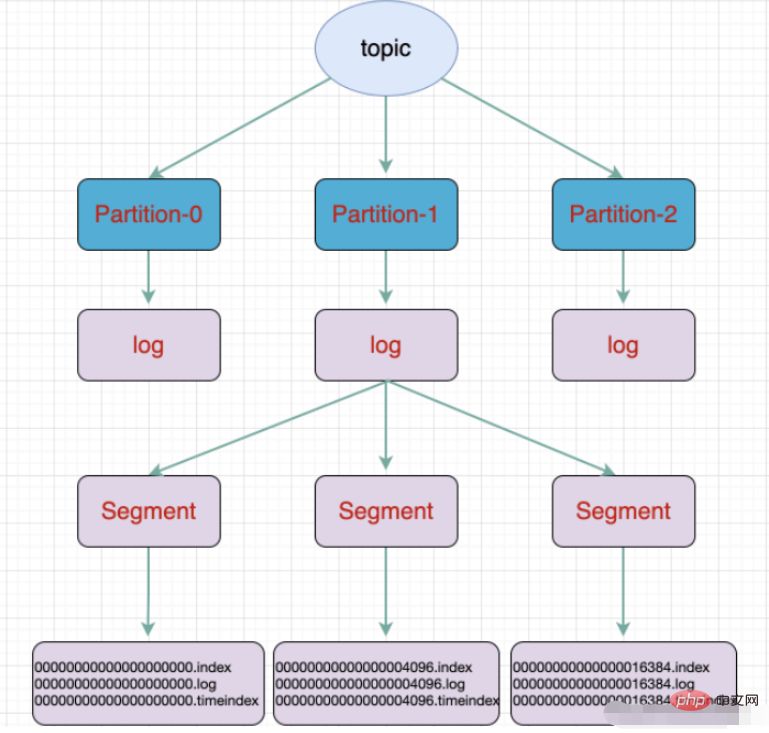
Sebuah partition dibahagikan kepada beberapa segmen
.fail log log
.fail indeks mengimbangi indeks
fail indeks cap waktu timeindex
Fail lain (partition.metadata, titik semakan leader-epoch )
pergantungan maven
<dependencies>
<!-- springBoot集成kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<!-- SpringBoot整合Web组件 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
</dependencies>konfigurasi yml
# kafka
spring:
kafka:
# kafka服务器地址(可以多个)
# bootstrap-servers: 192.168.212.164:9092,192.168.212.167:9092,192.168.212.168:9092
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094
consumer:
# 指定一个默认的组名
group-id: kafkaGroup1
# earliest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,从头开始消费
# latest:当各分区下有已提交的offset时,从提交的offset开始消费;无提交的offset时,消费新产生的该分区下的数据
# none:topic各分区都存在已提交的offset时,从offset后开始消费;只要有一个分区不存在已提交的offset,则抛出异常
auto-offset-reset: earliest
# key/value的反序列化
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
producer:
# key/value的序列化
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# 批量抓取
batch-size: 65536
# 缓存容量
buffer-memory: 524288
# 服务器地址
bootstrap-servers: www.kaicostudy.com:9092,www.kaicostudy.com:9093,www.kaicostudy.com:9094pengeluar
@RestController
public class KafkaController {
/**
* 注入kafkaTemplate
*/
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
/**
* 发送消息的方法
*
* @param key
* 推送数据的key
* @param data
* 推送数据的data
*/
private void send(String key, String data) {
// topic 名称 key data 消息数据
kafkaTemplate.send("kaico", key, data);
}
// test 主题 1 my_test 3
@RequestMapping("/kafka")
public String testKafka() {
int iMax = 6;
for (int i = 1; i < iMax; i++) {
send("key" + i, "data" + i);
}
return "success";
}
}Pengguna
@Component
public class TopicKaicoConsumer {
/**
* 消费者使用日志打印消息
*/
@KafkaListener(topics = "kaico") //监听的主题
public void receive(ConsumerRecord<?, ?> consumer) {
System.out.println("topic名称:" + consumer.topic() + ",key:" +
consumer.key() + "," +
"分区位置:" + consumer.partition()
+ ", 下标" + consumer.offset());
//输出key对应的value的值
System.out.println(consumer.value());
}
}Atas ialah kandungan terperinci Java mengedarkan analisis contoh baris gilir mesej Kafka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



